
Hva er Large Language Model Optimization (LLMO)? Komplett guide
Lær hva LLMO er, hvordan det fungerer, og hvorfor det er viktig for AI-synlighet. Oppdag optimaliseringsteknikker for å få merkevaren din nevnt i ChatGPT, Perpl...
9 min lesing

Oppdag hvordan store språkmodeller velger og siterer kilder gjennom bevisvekting, entitetsgjenkjenning og strukturert data. Lær den 7-fasede siteringsbeslutningsprosessen og optimaliser innholdet ditt for AI-synlighet.
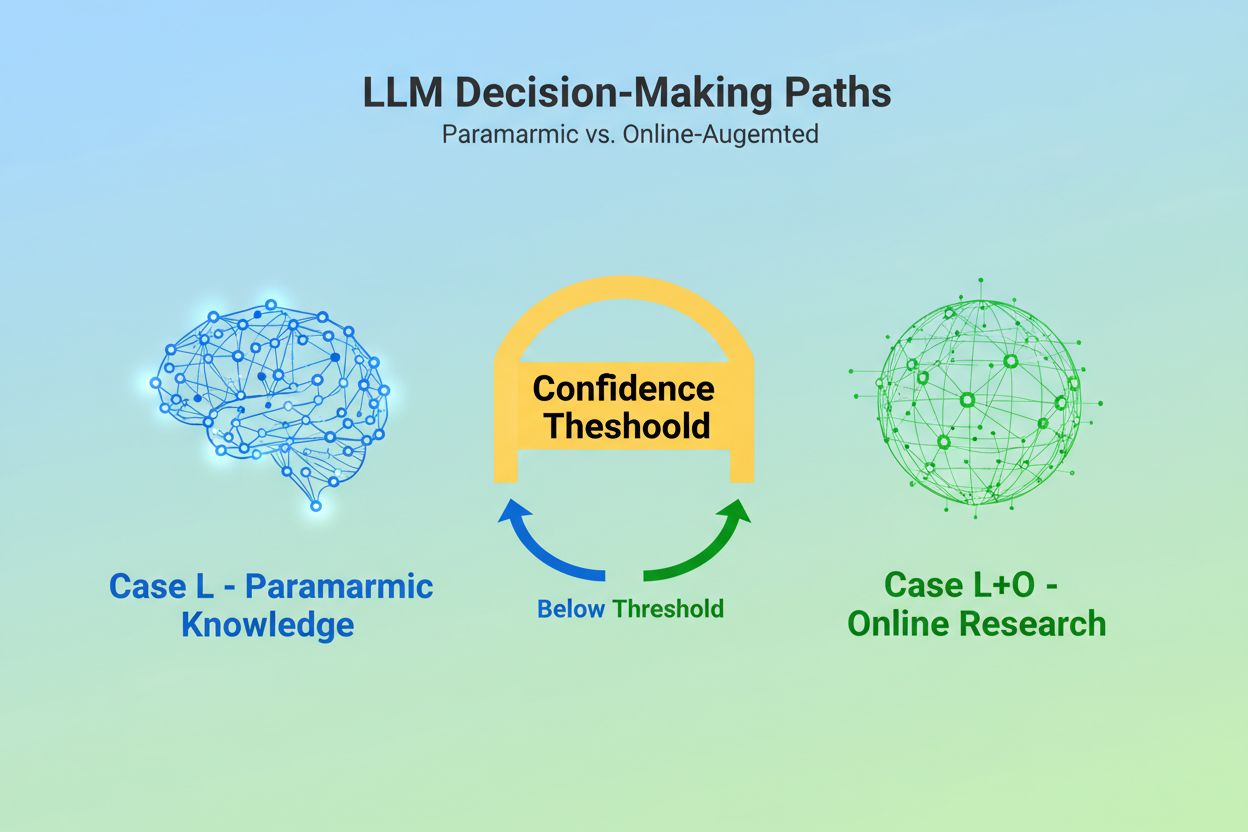
Når en stor språkmodell mottar en forespørsel, står den overfor et grunnleggende valg: skal den kun stole på kunnskap innebygd under trening, eller skal den søke på nettet etter oppdatert informasjon? Dette binære valget—det forskere kaller Case L (kun læringsdata) versus Case L+O (læringsdata pluss online research)—avgjør om en LLM i det hele tatt vil sitere kilder. I Case L-modus henter modellen utelukkende fra sin parametriske kunnskapsbase, en kondensert representasjon av mønstre lært under trening som vanligvis gjenspeiler informasjon fra flere måneder til over ett år før modellens utgivelse. I Case L+O-modus aktiverer modellen en selvtillitsterskel som utløser ekstern research, og åpner det forskere kaller “kandidatområdet” av URL-er og kilder. Dette beslutningspunktet er usynlig for de fleste overvåkingsverktøy, men det er her hele siteringsmekanismen starter—fordi uten å utløse søkefasen, kan ingen eksterne kilder vurderes eller siteres.
I det øyeblikket en LLM bestemmer seg for å søke etter eksterne kilder, går den inn i den mest kritiske fasen for siteringsutvalg: bevisvekting. Det er her skillet mellom en ren omtale og en autoritativ anbefaling blir gjort. Modellen teller ikke bare hvor mange ganger en kilde vises eller hvor høyt den rangerer i søkeresultater; i stedet vurderer den strukturell integritet i selve beviset. Den vurderer dokumentarkitektur—om kilder inneholder tydelige datarelasjoner, gjentakende identifikatorer og refererte lenker—og tolker dette som tegn på pålitelighet. Modellen konstruerer det forskere kaller en “bevisgraf”, der noder representerer entiteter og kanter representerer dokumentrelasjoner. Hver kilde vektes ikke bare etter innholdsrelevans, men etter hvor konsistent fakta bekreftes på tvers av flere dokumenter, hvor tematisk relevant informasjonen er, og hvor autoritativt domenet fremstår. Denne flerdimensjonale evalueringen skaper det som kalles en bevismatrise, en omfattende vurdering som avgjør hvilke kilder som er pålitelige nok til å bli sitert. Kritisk nok opererer denne fasen i resonnementslaget til LLM-en, noe som gjør den usynlig for tradisjonelle GEO-overvåkingsverktøy som kun måler hentingssignaler.
Strukturert data—særlig JSON-LD, Schema.org-merking og RDFa—fungerer som en multiplikator i bevisvektingen. Kilder som har riktig strukturert data får 2-3 ganger høyere vekt i bevismatrisen sammenlignet med ustrukturert innhold. Dette er ikke fordi LLM-er foretrekker formatert data estetisk; det er fordi strukturert data muliggjør entitetslenking, prosessen der omtaler på tvers av dokumenter kobles sammen gjennom maskinlesbare identifikatorer som @id, sameAs og Q-ID-er (Wikidata-identifikatorer). Når en LLM møter en kilde med Q-ID for en organisasjon, kan den umiddelbart verifisere denne entiteten på tvers av flere dokumenter, og skaper det forskere kaller “kryssdokument-entitetskoreferanse”. Denne verifiseringen øker dramatisk tilliten til kildens pålitelighet.
| Dataformat | Siteringsnøyaktighet | Entitetslenking | Kryssdokument-verifisering |
|---|---|---|---|
| Ustrukturert tekst | 62% | Ingen | Manuell slutning |
| Grunnleggende HTML-merking | 71% | Begrenset | Delvis samsvar |
| RDFa/Mikrodata | 81% | God | Mønsterbasert |
| JSON-LD med Q-ID-er | 94% | Utmerket | Verifiserte lenker |
| Knowledge Graph-format | 97% | Perfekt | Automatisk verifisering |
Effekten av strukturert data opererer på to tidsakser. Midlertidig, når en LLM søker online, leser den JSON-LD og Schema.org-merking i sanntid, og inkorporerer denne strukturerte informasjonen direkte i bevisvektingen for det aktuelle svaret. Vedvarende blir strukturert data som forblir konsistent over tid, integrert i modellens parametriske kunnskapsbase i fremtidige treningssykluser, og former hvordan modellen gjenkjenner og evaluerer entiteter selv uten nettbasert research. Denne doble mekanismen betyr at merkevarer som implementerer riktig strukturert data, sikrer både umiddelbar siteringssynlighet og langsiktig autoritet i modellens interne kunnskapsrom.
Før en LLM kan sitere en kilde, må den først forstå hva kilden handler om og hvem den representerer. Dette er jobben til entitetsgjenkjenning, en prosess som forvandler uklar menneskelig språkbruk til maskinlesbare entiteter. Når et dokument nevner “Apple”, må LLM-en avgjøre om dette refererer til Apple Inc., frukten eller noe helt annet. Modellen løser dette gjennom trente entitetsmønstre hentet fra Wikipedia, Wikidata og Common Crawl, kombinert med kontekstanalyse av omgivende tekst. I Case L+O-modus blir denne prosessen mer sofistikert: modellen verifiserer entiteter mot ekstern strukturert data, og sjekker etter @id-attributter, sameAs-lenker og Q-ID-er som gir entydig identifikasjon. Dette verifiseringstrinnet er avgjørende fordi tvetydige eller inkonsistente entitetsreferanser forsvinner i støyen av modellens resonnement. En merkevare som bruker inkonsistente navnekonvensjoner, ikke etablerer klare entitetsidentifikatorer eller ikke implementerer Schema.org-merking, blir semantisk uklar for maskinen—og fremstår som flere ulike entiteter i stedet for én sammenhengende kilde. Omvendt blir organisasjoner med stabile, konsekvent refererte entiteter på tvers av mange dokumenter gjenkjent som pålitelige noder i LLM-ens kunnskapsgraf, og øker sjansen for å bli sitert betydelig.
Reisen fra forespørsel til sitering følger en strukturert syv-faseprosess som forskere har kartlagt gjennom analyse av LLM-adferd. Fase 0: Intentfortolkning starter når modellen tokeniserer brukerens input, utfører semantisk analyse og lager en intensjonsvektor—en abstrakt representasjon av hva brukeren egentlig spør om. Denne fasen avgjør hvilke temaer, entiteter og relasjoner som i det hele tatt er relevante. Fase 1: Intern kunnskapshenting får tilgang til modellens parametriske kunnskap og beregner en selvtillitspoengsum. Hvis denne poengsummen overstiger en terskel, forblir modellen i Case L-modus; hvis ikke, går den videre til ekstern research. Fase 2: Fan-Out Forespørselsgenerering (kun Case L+O) lager flere semantisk varierte søk—vanligvis 1-6 tokens hver—for å åpne kandidatområdet så bredt som mulig. Fase 3: Bevisuthenting henter URL-er og utdrag fra søkeresultater, parser HTML og trekker ut JSON-LD, RDFa og mikrodata. Det er her strukturert data først blir synlig for siteringsmekanismen. Fase 4: Entitetslenking identifiserer entiteter i de innhentede dokumentene og verifiserer dem mot eksterne identifikatorer, og lager en midlertidig kunnskapsgraf over relasjoner. Fase 5: Bevisvekting vurderer styrken på beviset fra alle kilder, med hensyn til dokumentarkitektur, kildemangfold, bekreftelsesfrekvens og sammenheng på tvers av kilder. Fase 6: Resonnement & syntese kombinerer intern og ekstern evidens, løser motsetninger og avgjør om hver kilde fortjener omtale eller anbefaling. Fase 7: Endelig svar-konstruksjon oversetter det vektede beviset til naturlig språk, og integrerer siteringer der det er hensiktsmessig. Hver fase mater inn i den neste, med tilbakemeldingssløyfer som gjør at modellen kan raffinere søket eller revurdere bevis hvis det oppstår inkonsistenser.
Moderne LLM-er bruker i økende grad Retrieval-Augmented Generation (RAG), en teknikk som fundamentalt endrer hvordan siteringer velges og begrunnes. I stedet for å stole utelukkende på parametrisk kunnskap, henter RAG-systemer aktivt relevante dokumenter, trekker ut bevis og forankrer svarene i spesifikke kilder. Denne tilnærmingen gjør sitering fra et implisitt biprodukt av trening til en eksplisitt, sporbar prosess. RAG-implementasjoner bruker vanligvis hybrid søk, der nøkkelordbasert henting kombineres med vektorsøk for maksimal dekning. Når kandidatdokumenter er hentet, semantisk rangering gir nye poengsummer basert på mening, ikke bare nøkkelord, slik at de mest relevante kildene havner øverst. Denne eksplisitte henteprosessen gjør siteringsprosessen mer gjennomsiktig og reviderbar—hver sitert kilde kan spores tilbake til konkrete avsnitt som begrunner inkluderingen. For organisasjoner som overvåker AI-synlighet, er RAG-baserte systemer særlig viktige fordi de skaper målbare siteringsmønstre. Verktøy som AmICited sporer hvordan RAG-systemer refererer til merkevaren din på ulike AI-plattformer, og gir innsikt i om du vises som en sitert kilde eller kun som bakgrunnsmateriale i bevisuthentingsfasen.
Ikke alle siteringer er like. En LLM kan nevne en kilde som bakgrunn, mens den anbefaler en annen som autoritativ—og dette skillet avgjøres utelukkende av bevisvekting, ikke av henting. En kilde kan dukke opp i kandidatområdet (Fase 2-3), men ikke oppnå anbefalingsstatus hvis bevispoengsummen er for lav. Dette skillet mellom omtale og anbefaling er der tradisjonelle GEO-målinger kommer til kort. Standard overvåkingsverktøy måler fan-out—om innholdet ditt vises i søkeresultater—men de kan ikke måle om LLM-en faktisk anser innholdet ditt som pålitelig nok til å anbefale. En omtale kan lyde som “Noen kilder antyder…”, mens en anbefaling lyder som “Ifølge [Kilde] viser beviset at…”. Forskjellen ligger i poengsummen fra bevismatrisen i Fase 5. Kilder med konsistente Q-ID-er, velstrukturert dokumentarkitektur og bekreftelse på tvers av uavhengige kilder oppnår anbefalingsstatus. Kilder med uklare entitetsreferanser, dårlig struktur eller isolerte påstander forblir omtaler. For merkevarer er dette skillet kritisk: å bli hentet er ikke det samme som å bli sitert som autoritativ. Veien fra henting til anbefaling krever semantisk klarhet, strukturell integritet og bevisdensitet—faktorer tradisjonell SEO ikke adresserer.
Å forstå hvordan LLM-er velger kilder har umiddelbare, konkrete konsekvenser for innholdsstrategien. For det første: implementer Schema.org-merking konsekvent på nettstedet ditt, spesielt for organisasjonsinformasjon, artikler og nøkkelentiteter. Bruk JSON-LD-format med riktige @id-attributter og sameAs-lenker til Wikidata, Wikipedia eller andre autoritative kilder. Denne strukturerte dataen øker direkte bevisvekten din i Fase 5. For det andre: etabler klare entitetsidentifikatorer for organisasjonen, produkter og viktige konsepter. Bruk konsistente navnekonvensjoner, unngå forkortelser som skaper tvetydighet, og lenk relaterte entiteter gjennom hierarkiske relasjoner (isPartOf, about, mentions). For det tredje: skap maskinleselige bevis ved å publisere strukturert data om dine påstander, referanser og relasjoner. Ikke bare skriv “Vi er ledende leverandør av X”—strukturer denne påstanden med støttende data, siteringer og verifiserbare relasjoner. For det fjerde: oppretthold innholdskonsistens på tvers av plattformer og tidsperioder. LLM-er vurderer bevisdensitet ved å sjekke om påstander bekreftes på tvers av uavhengige kilder; isolerte påstander på én plattform veier mindre. For det femte: forstå at tradisjonelle SEO-målinger ikke forutser AI-sitering. Høy søkerangering garanterer ikke LLM-anbefalinger; fokuser heller på semantisk klarhet og strukturell integritet. For det sjette: overvåk dine siteringsmønstre med verktøy som AmICited, som sporer hvordan ulike AI-systemer refererer til merkevaren din. Dette avslører om du oppnår omtale- eller anbefalingsstatus, og hvilke innholdstyper som utløser siteringer. Til slutt: erkjenn at AI-synlighet er en langsiktig investering. Strukturert data du implementerer i dag former både umiddelbar siteringssannsynlighet (midlertidig effekt) og modellens interne kunnskapsbase i fremtidige treningssykluser (vedvarende effekt).
Etter hvert som LLM-er utvikler seg, blir siteringsmekanismene stadig mer sofistikerte og gjennomsiktige. Fremtidige modeller vil sannsynligvis implementere siteringsgrafer—eksplisitte kart som viser ikke bare hvilke kilder som ble sitert, men hvordan de påvirket spesifikke påstander i svaret. Noen avanserte systemer eksperimenterer allerede med probabilistiske selvtillitspoeng knyttet til siteringer, som indikerer hvor sikker modellen er på kildens relevans og pålitelighet. En annen trend er menneskelig-verifisering i loopen, der brukere kan utfordre siteringer og gi tilbakemeldinger som raffinerer modellens bevisvekting for fremtidige forespørsler. Integreringen av strukturert data i treningssykluser betyr at organisasjoner som implementerer riktig semantisk infrastruktur i dag i praksis bygger sin langsiktige autoritet i AI-systemer. I motsetning til søkemotorrangeringer, som kan svinge med algoritmeoppdateringer, gir den vedvarende effekten av strukturert data et mer stabilt grunnlag for AI-synlighet. Dette skiftet fra tradisjonell synlighet (å bli funnet) til semantisk autoritet (å bli stolt på) representerer en grunnleggende endring i hvordan merkevarer bør nærme seg digital kommunikasjon. Vinnerne i dette nye landskapet vil ikke være de med mest innhold eller høyest søkerangeringer, men de som strukturerer informasjonen slik at maskiner kan forstå, verifisere og anbefale pålitelig.
Case L bruker kun treningsdata fra modellens parametriske kunnskapsbase, mens Case L+O supplerer dette med sanntids nettsøk. Modellens terskel for selvtillit avgjør hvilken vei som velges. Dette skillet er avgjørende fordi det bestemmer om eksterne kilder i det hele tatt kan vurderes og siteres.
Bevisvekting avgjør dette skillet. Kilder med strukturert data, konsistente identifikatorer og bekreftelse på tvers av dokumenter blir opphøyet til 'anbefalinger' i stedet for bare omtaler. En kilde kan dukke opp i søkeresultater, men likevel ikke oppnå anbefalingsstatus hvis bevispoengsummen er utilstrekkelig.
Strukturert data (JSON-LD, @id, sameAs, Q-ID-er) får 2-3 ganger høyere vekt i bevismatriser. Denne merkingen muliggjør entitetslenking og verifisering på tvers av dokumenter, noe som dramatisk øker kildens pålitelighetspoeng. Kilder med riktig Schema.org-implementering er betydelig mer sannsynlig å bli sitert som autoritative.
Entitetsgjenkjenning er hvordan LLM-er identifiserer og skiller mellom ulike entiteter (organisasjoner, personer, konsepter). Tydelig entitetsidentifikasjon gjennom konsistent navngivning og strukturerte identifikatorer forhindrer forvirring og øker sannsynligheten for sitering. Uklare entitetsreferanser går tapt i modellens resonnement.
RAG-systemer henter og rangerer kilder aktivt i sanntid, noe som gjør siteringsutvalget mer gjennomsiktig og bevisbasert enn ren parametrisk kunnskap. Denne eksplisitte henteprosess skaper målbare siteringsmønstre som kan spores og analyseres gjennom overvåkingsverktøy som AmICited.
Ja. Implementer Schema.org-merking konsekvent, etabler klare entitetsidentifikatorer, skap maskinleselige bevis, oppretthold innholdskonsistens på tvers av plattformer, og overvåk dine siteringsmønstre. Disse faktorene påvirker direkte om innholdet ditt oppnår omtale- eller anbefalingsstatus i LLM-svar.
Tradisjonell synlighet måler rekkevidde og rangering i søkeresultater. AI-synlighet måler om innholdet ditt blir anerkjent som autoritativt bevis i LLM-ers resonnement. Å bli hentet er ikke det samme som å bli sitert som pålitelig—det siste krever semantisk klarhet og strukturell integritet.
AmICited sporer hvordan AI-systemer refererer til merkevaren din på tvers av GPT-er, Perplexity og Google AI Overviews. Det avslører om du oppnår omtale- eller anbefalingsstatus, hvilke typer innhold som utløser siteringer, og hvordan dine siteringsmønstre sammenlignes på ulike AI-plattformer.
Forstå hvordan LLM-er refererer til merkevaren din på tvers av ChatGPT, Perplexity og Google AI Overviews. Spor siteringsmønstre og optimaliser for AI-synlighet med AmICited.
Lær hva LLMO er, hvordan det fungerer, og hvorfor det er viktig for AI-synlighet. Oppdag optimaliseringsteknikker for å få merkevaren din nevnt i ChatGPT, Perpl...

Lær hvordan du identifiserer og målretter LLM-kildesider for strategiske tilbakekoblinger. Oppdag hvilke AI-plattformer som siterer kilder mest, og optimaliser ...
Lær hva LLMO er og oppdag dokumenterte teknikker for å optimalisere merkevaren din for synlighet i AI-genererte svar fra ChatGPT, Perplexity, Claude og andre LL...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.