
Samtalebaserte søk vs Nøkkelord-søk: Viktige forskjeller for AI-søk
Forstå hvordan samtalebaserte søk skiller seg fra tradisjonelle nøkkelord-søk. Lær hvorfor AI-søkemotorer prioriterer naturlig språk, brukerhensikt og kontekst ...
9 min lesing
Lær hvordan du optimaliserer spørsmålsbasert innhold for konversasjonelle AI-systemer som ChatGPT og Perplexity. Oppdag struktur, autoritet og overvåkningsstrategier for å maksimere AI-siteringer.
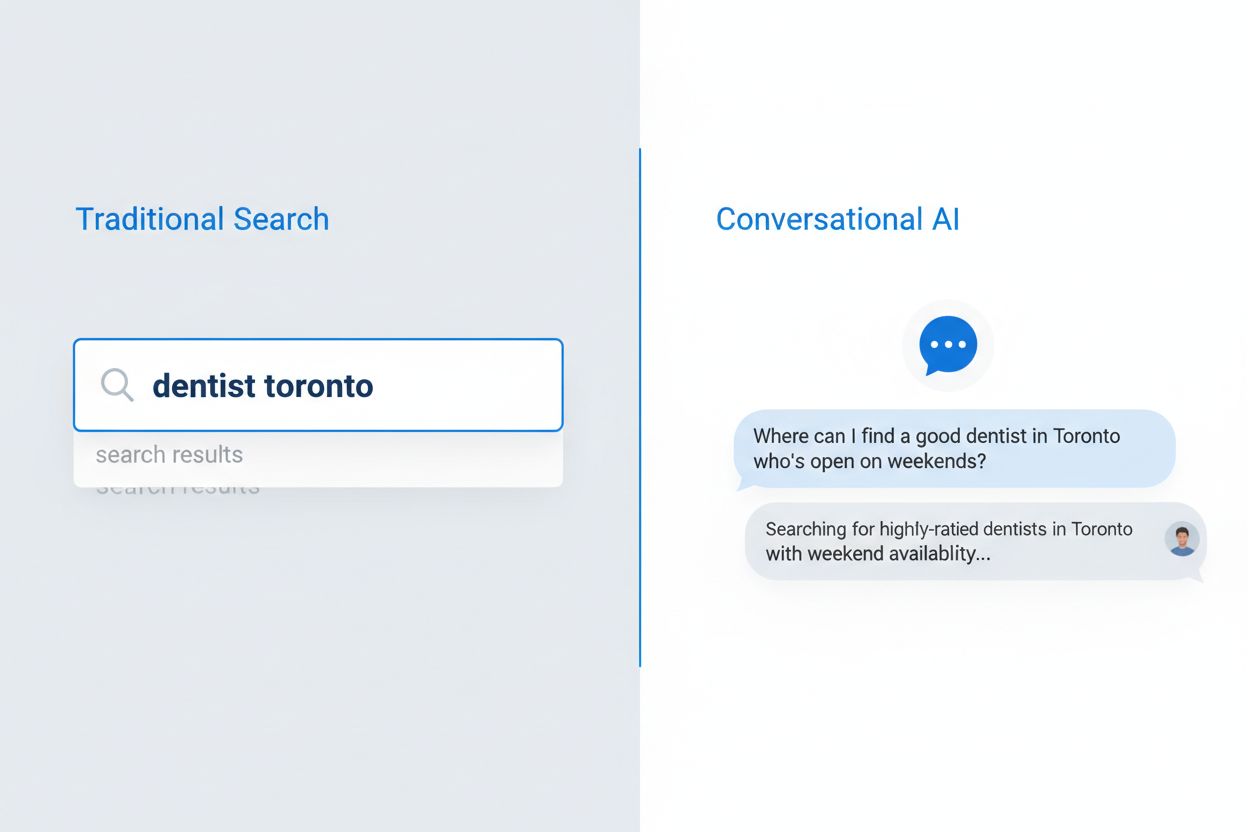
Brukeradferd ved søk har endret seg fundamentalt de siste fem årene, fra oppstykkede nøkkelordfrase til naturlige, konversasjonelle spørsmål. Dette har akselerert med utbredt bruk av talesøk, mobil-første bruksmønstre og betydelige algoritmeforbedringer som Googles BERT- og MUM-oppdateringer, som nå prioriterer semantisk forståelse fremfor eksakt nøkkelordmatching. Brukere søker ikke lenger etter isolerte ord; de stiller komplette spørsmål som speiler hvordan de faktisk snakker og tenker. Forskjellen er tydelig:
Bruken av talesøk har vært særlig innflytelsesrik, med 50 % av alle søk nå stemmebaserte, noe som tvinger søkemotorer og AI-systemer til å tilpasse seg lengre, mer naturlige språkmønstre. Mobilenheter har blitt den primære søkeplattformen for de fleste brukere, og konversasjonelle spørsmål føles mer naturlig på mobil enn å taste inn nøkkelord. Googles algoritmeoppdateringer har gjort det klart at forståelse av brukernes hensikt og kontekst er langt viktigere enn nøkkelordtetthet eller eksakt ordlyd, noe som fundamentalt endrer hvordan innhold må skrives og struktureres for å være synlig både i tradisjonelt søk og AI-drevne systemer.
Konversasjonelt AI-søk representerer et fundamentalt annet paradigme enn tradisjonelt nøkkelordbasert søk, med tydelige forskjeller i hvordan forespørsler behandles, resultater leveres og brukerhensikt tolkes. Mens tradisjonelle søkemotorer returnerer en liste over rangerte lenker brukeren kan bla i, analyserer konversasjonelle AI-systemer spørsmål i kontekst, henter relevant informasjon fra flere kilder og setter sammen helhetlige svar på naturlig språk. Den tekniske arkitekturen er markant forskjellig: tradisjonelt søk baseres på nøkkelordmatching og lenkeanalyse, mens konversasjonell AI bruker store språkmodeller med retrieval-augmented generation (RAG) for å forstå semantisk mening og generere kontekstuelle svar. Å forstå disse forskjellene er kritisk for innholdsskapere som ønsker synlighet i begge systemer, siden optimaliseringsstrategiene skiller seg på viktige områder.
| Dimensjon | Tradisjonelt søk | Konversasjonell AI |
|---|---|---|
| Input | Korte nøkkelord eller fraser (2–4 ord i snitt) | Hele konversasjonelle spørsmål (8–15 ord i snitt) |
| Output | Liste med rangerte lenker for brukeren å klikke | Syntetisert svar med kildehenvisninger |
| Kontekst | Begrenset til søkeord og brukers plassering | Hele samtalehistorikken og brukerpreferanser |
| Brukerhensikt | Utledet fra nøkkelord og klikkmønstre | Eksplicit forstått gjennom naturlig språk |
| Brukeropplevelse | Krever klikk til ekstern side | Svar gis direkte i grensesnittet |
Dette skillet har store konsekvenser for innholdsstrategi. I tradisjonelt søk betyr en plassering i topp 10 synlighet; i konversasjonell AI er det å bli valgt som kilde for sitering som teller. En side kan rangere høyt for et nøkkelord, men aldri bli sitert av en AI hvis den ikke oppfyller systemets krav til autoritet, grundighet og klarhet. Konversasjonelle AI-systemer vurderer innhold annerledes, og prioriterer direkte svar på spørsmål, tydelig informasjonsstruktur og dokumentert ekspertise fremfor kun nøkkelordoptimalisering og lenkeprofiler.
Store språkmodeller bruker en avansert prosess kalt Retrieval-Augmented Generation (RAG) for å velge hvilket innhold de vil sitere når de svarer på brukerspørsmål, og denne prosessen skiller seg vesentlig fra tradisjonell søkerangering. Når en bruker stiller et spørsmål, henter LLM-en først relevante dokumenter fra treningsdata eller indekserte kilder, og vurderer dem deretter ut fra flere kriterier før den bestemmer hvilke kilder som skal siteres i svaret. Utvelgelsesprosessen prioriterer flere nøkkelfaktorer innholdsskapere må forstå:
Autoritetssignaler – LLM-er gjenkjenner domeneautoritet via lenkeprofiler, domenets alder og historisk ytelse i tradisjonelt søk, og foretrekker etablerte, pålitelige kilder fremfor nye eller lite siterte domener.
Semantisk relevans – Innholdet må direkte besvare brukerens spørsmål med høy semantisk likhet, ikke bare nøkkelordmatching; LLM-er forstår mening og kontekst på måter tradisjonell matching ikke kan.
Innholdsstruktur og klarhet – Godt organisert innhold med tydelige overskrifter, direkte svar og logisk flyt velges oftere fordi LLM-er enklere kan hente ut relevant informasjon fra strukturert innhold.
Friskhet og aktualitet – Nylig oppdatert innhold vektes tyngre, særlig for temaer hvor oppdatert informasjon er viktig; utdatert innhold nedprioriteres selv om det tidligere var autoritativt.
Omfattende dekning – Innhold som grundig dekker et emne med flere vinkler, underbyggende data og ekspertperspektiver siteres oftere enn overfladisk eller ufullstendig dekning.
Selve siteringsprosessen er ikke tilfeldig; LLM-er trenes til å sitere kilder som best underbygger svarene sine, og de viser i økende grad siteringer til brukeren, noe som gjør kildevalget til en kritisk synlighetsmåling for innholdsskapere.
Innholdsstruktur har blitt en av de viktigste faktorene for AI-synlighet, men mange innholdsskapere optimaliserer fortsatt primært for menneskelige lesere uten å tenke på hvordan AI-systemer tolker og trekker ut informasjon. LLM-er behandler innhold hierarkisk, bruker overskrifter, seksjonsbrudd og formatering for å forstå informasjonsorganisering og hente ut relevante avsnitt for sitering. Optimal struktur for AI-lesbarhet følger bestemte retningslinjer: hver seksjon bør være 120–180 ord, slik at LLM-er kan hente meningsfulle biter uten at det blir for langt; H2- og H3-overskrifter skal tydelig vise temahierarki; og direkte svar bør komme tidlig i seksjonen, ikke gjemt i avsnitt.
Spørsmålsbaserte titler og FAQ-seksjoner er spesielt effektive fordi de passer perfekt til hvordan konversasjonelle AI-systemer tolker brukerens spørsmål. Når en bruker spør “Hva er beste praksis for innholdsmarkedsføring?”, kan et AI-system umiddelbart matche det spørsmålet til en seksjon med tittelen “Hva er beste praksis for innholdsmarkedsføring?” og hente ut relevant innhold. Denne strukturelle tilpasningen øker sjansen for sitering betraktelig. Her er et eksempel på riktig strukturert innhold:
## Hva er beste praksis for innholdsmarkedsføring?
### Definer målgruppen først
[120–180 ord med direkte, handlingsrettet innhold som svarer på dette spesifikke spørsmålet]
### Lag en innholdskalender
[120–180 ord med direkte, handlingsrettet innhold som svarer på dette spesifikke spørsmålet]
### Mål og optimaliser ytelse
[120–180 ord med direkte, handlingsrettet innhold som svarer på dette spesifikke spørsmålet]
Denne strukturen lar LLM-er raskt finne relevante seksjoner, hente ut komplette tanker uten oppstykking og sitere bestemte seksjoner trygt. Innhold som mangler denne strukturen—lange avsnitt uten tydelige overskrifter, gjemte svar eller uklar hierarki—blir langt sjeldnere valgt for sitering, uansett kvalitet.
Autoritet er fortsatt en kritisk faktor for AI-synlighet, selv om signalene som utgjør autoritet har utviklet seg utover tradisjonelle SEO-målinger. LLM-er gjenkjenner autoritet gjennom flere kanaler, og innholdsskapere må bygge troverdighet på flere dimensjoner for å maksimere siteringssjansen. Forskning viser at domener med over 32 000 henvisende domener får vesentlig høyere siteringsrater, og Domain Trust-score korrelerer sterkt med AI-synlighet. Likevel bygges autoritet ikke kun gjennom lenker; det er et sammensatt begrep som omfatter:
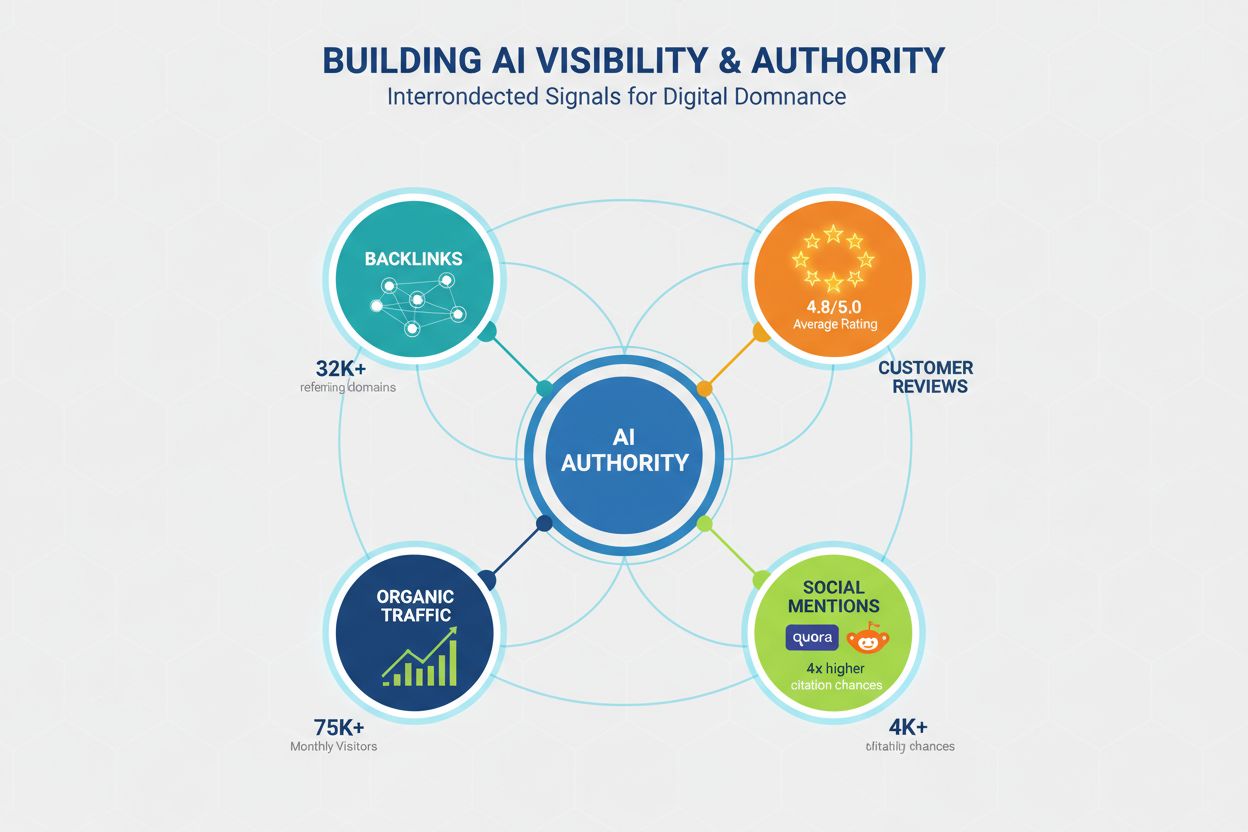
Lenkeprofil – Kvalitetslenker fra autoritative domener signaliserer ekspertise; 50+ høykvalitetslenker gir 4,8 ganger høyere siteringsrate enn domener med få lenker.
Sosialt bevis og samfunnstilstedeværelse – Omtaler på plattformer som Quora, Reddit og bransjefora signaliserer at innholdet ditt er betrodd og referert av ekte brukere; aktiv deltakelse i disse miljøene bygger troverdighet.
Vurderingsplattformer og anmeldelser – Tilstedeværelse på Trustpilot, G2, Capterra og lignende plattformer med gode anmeldelser gir troverdighetssignaler LLM-er gjenkjenner; merkevarer med 4,5+ stjerner har 3,2 ganger høyere siteringsrate.
Hjemmesidetrafikk og merkevarekjennskap – Direkte trafikk til hjemmesiden indikerer merkevarebevissthet og tillit; LLM-er vekter innhold fra kjente merkevarer høyere enn ukjente kilder.
Ekspertkreditering og bylines – Innhold skrevet av anerkjente eksperter med tydelige meritter og biografi vektes tyngre; forfatterekspertise er et eget autoritetssignal uavhengig av domeneautoritet.
Å bygge autoritet for AI-synlighet krever en langsiktig strategi som går ut over tradisjonell SEO, og inkluderer samfunnsengasjement, håndtering av anmeldelser og merkevarebygging i tillegg til teknisk optimalisering.
Innholdsdypde er en av de sterkeste indikatorene på AI-sitering, med forskning som viser at grundig, gjennomarbeidet innhold får langt flere siteringer enn overfladisk dekning. Minste terskel for konkurransedyktig synlighet er ca. 1 900 ord, men virkelig omfattende dekning som dominerer AI-siteringer når typisk 2 900+ ord. Det handler ikke om lengde for lengdens skyld; det handler om informasjonsdybde, antall underbyggende datapunkter og bredden av perspektiver som dekkes.
Tallene på innholdsdypde er tydelige:
Effekt av ekspertuttalelser – Innhold med 4+ ekspertuttalelser får i snitt 4,1 siteringer, mot 2,4 siteringer for innhold uten eksperters perspektiv; LLM-er gjenkjenner ekspertbidrag som et troverdighetssignal.
Tetthet av statistiske data – Innhold med 19+ statistiske datapunkter får i snitt 5,4 siteringer, mot 2,8 for innhold med lite data; LLM-er prioriterer påstander støttet av data.
Omfattende dekning – Innhold som dekker 8+ undertemaer innenfor hovedtemaet får i snitt 5,1 siteringer, mot 3,2 for innhold med bare 3–4 undertemaer; bredden i dekningen betyr mye.
Original forskning – Innhold med original forskning, undersøkelser eller egne data får i snitt 6,2 siteringer, og er den mest effektfulle innholdstypen for AI-synlighet.
Dybde er viktig fordi LLM-er er trent til å gi grundige, godt underbygde svar på brukerspørsmål, og de trekkes naturlig mot innhold som lar dem sitere flere perspektiver, datapunkter og ekspertuttalelser fra én og samme kilde.
Innholdsferskhet er en kritisk, men ofte oversett faktor for AI-synlighet. Forskning viser at nylig oppdatert innhold får langt flere siteringer enn utdatert materiale. Effekten er dramatisk: innhold oppdatert de siste tre månedene får i snitt 6,0 siteringer, mot bare 3,6 siteringer for materiale som ikke har blitt oppdatert på over ett år. Denne målingen reflekterer LLM-ers preferanse for oppdatert informasjon og deres evne til å gjenkjenne at friskt innhold oftere er korrekt og relevant.
En kvartalsvis oppdateringsstrategi bør bli standard for alt innhold rettet mot AI-synlighet. Dette betyr ikke nødvendigvis fullstendige omskrivinger; strategiske oppdateringer som legger til ny statistikk, fornyer eksempler, oppdaterer casestudier og inkluderer siste utvikling er nok for å signalisere friskhet. For tidskritiske temaer som teknologi, markedsføringstrender eller bransjenyheter kan månedlige oppdateringer være nødvendig for å beholde siteringskonkurranse. Oppdateringsprosessen bør inkludere:
Innhold som forblir statisk mens bransjen utvikler seg, vil gradvis miste AI-synlighet, selv om det en gang var autoritativt, fordi LLM-er gjenkjenner at foreldet informasjon har mindre verdi for brukeren.
Teknisk ytelse har blitt stadig viktigere for AI-synlighet, ettersom LLM-er og systemene som leverer dem prioriterer innhold fra raske, godt optimaliserte nettsteder. Core Web Vitals—Googles målinger for sideopplevelse—korrelerer sterkt med siteringsrater, noe som tyder på at LLM-er tar hensyn til brukeropplevelsessignaler når de velger kilder. Ytelseseffekten er betydelig: sider med First Contentful Paint (FCP) under 0,4 sekunder får i snitt 6,7 siteringer, mot bare 2,1 siteringer for sider med FCP over 2,5 sekunder.
Teknisk optimalisering for AI-synlighet bør fokusere på:
Largest Contentful Paint (LCP) – Sikt på under 2,5 sekunder; sider som oppfyller dette får i snitt 5,8 siteringer mot 2,9 for tregere sider.
Cumulative Layout Shift (CLS) – Hold scoren under 0,1; ustabile oppsett signaliserer lav kvalitet til LLM-er og reduserer siteringssannsynligheten.
Interaction to Next Paint (INP) – Optimaliser for respons under 200 ms; interaktive sider får i snitt 5,2 siteringer mot 3,1 for trege sider.
Mobilvennlighet – Mobil-første indeksering gjør mobil ytelse kritisk; sider med dårlig mobilopplevelse får 40 % færre siteringer.
Ren, semantisk HTML – Riktig overskriftshierarki, semantiske tags og ren kode gjør det enklere for LLM-er å tolke innholdet og øker siteringssannsynligheten.
Teknisk ytelse handler ikke bare om brukeropplevelse, men er et direkte signal til AI-systemer om innholdskvalitet og troverdighet.
Spørsmålsbasert optimalisering er den mest direkte måten å tilpasse innhold til konversasjonelle AI-søkemønstre, og effekten er særlig markant for mindre domener uten massiv autoritet. Forskning viser at spørsmålsbaserte titler har sju ganger større effekt for mindre domener (under 50 000 månedlige besøkende) sammenlignet med tradisjonelle nøkkelordtitler, noe som gjør denne strategien ekstra verdifull for nye merkevarer. FAQ-seksjoner er like kraftfulle, og dobler sjansen for sitering når de implementeres med tydelige spørsmål-svar-par.
Forskjellen mellom spørsmålsbaserte og tradisjonelle titler er stor:
Dårlig tittel: “Topp 10 markedsføringsverktøy”
God tittel: “Hva er de 10 beste markedsføringsverktøyene for små bedrifter?”
Dårlig tittel: “Innholdsmarkedsføringsstrategi”
God tittel: “Hvordan bør små bedrifter utvikle en innholdsmarkedsføringsstrategi?”
Dårlig tittel: “Beste praksis for e-postmarkedsføring”
God tittel: “Hva er beste praksis for e-postmarkedsføring for nettbutikker?”
Praktiske optimaliseringstips inkluderer:
Titteloptimalisering – Inkluder hovedspørsmålet innholdet ditt svarer på; bruk naturlig språk, ikke nøkkelordtunge fraser.
FAQ-seksjoner – Lag egne FAQ-seksjoner med 5–10 spørsmål og direkte svar; dette dobler siteringssannsynligheten for konkurranseutsatte søk.
Underoverskriftsjustering – Bruk H2- og H3-overskrifter som matcher vanlige spørsmålsmønstre; dette hjelper LLM-er å matche brukerspørsmål til innholdet ditt.
Plassering av direkte svar – Plasser direkte svar på spørsmål tidlig i seksjonen, ikke gjemt i avsnitt; LLM-er henter svar mer effektivt når de er synlige.
Spørsmålsbasert optimalisering handler ikke om å lure systemet; det handler om å tilpasse innholdsstruktur til hvordan brukere faktisk stiller spørsmål og hvordan AI-systemer tolker dem.
Mange innholdsskapere kaster bort tid og ressurser på optimaliseringstiltak som har liten eller ingen effekt på AI-synlighet, eller i verste fall reduserer sjansen for sitering. Å forstå disse misoppfatningene hjelper deg å fokusere på strategier som faktisk virker. En seiglivet myte er at LLMs.txt-filer har stor betydning for synlighet; forskning viser at disse filene har neglisjerbar effekt på siteringsrater, med domener som bruker LLMs.txt kun marginalt forskjellige (3,8 mot 4,1 siteringer i snitt) fra dem uten.
Vanlige misoppfatninger du bør styre unna:
FAQ-schema markup alene hjelper ikke – FAQ-schema er nyttig for tradisjonelt søk, men gir minimal fordel for AI-synlighet; den faktiske innholdsstrukturen betyr langt mer enn markup. Innhold med FAQ-schema, men dårlig struktur får i snitt 3,6 siteringer, mens godt strukturert innhold uten schema får 4,2 siteringer.
Overoptimalisering reduserer sitering – Sterkt optimaliserte URL-er, titler og metabeskrivelser reduserer faktisk siteringssannsynligheten; overoptimalisert innhold får i snitt 2,8 siteringer, mens naturlig skrevet innhold får 5,9 siteringer. LLM-er gjenkjenner og straffer åpenbare optimaliseringstriks.
Nøkkelordstapping hjelper ikke LLM-er – I motsetning til tradisjonelle søkemotorer forstår LLM-er semantisk mening og ser nøkkelordstapping som et kvalitetssignal; innhold skrevet i naturlig språk får vesentlig flere siteringer.
Bare lenker gir ikke garanti for synlighet – Autoritet betyr noe, men innholdskvalitet og struktur er viktigere; et høyauthoritetsdomene med dårlig strukturert innhold får færre siteringer enn et lavere autoritetsdomene med utmerket struktur.
Lengde uten substans virker ikke – Å fylle ut innhold bare for å nå et ordmål uten å tilføre verdi reduserer faktisk siteringssannsynligheten; LLM-er gjenkjenner og straffer fyllstoff.
Fokuser på ekte kvalitet, tydelig struktur og autentisk ekspertise fremfor optimaliseringstriks.
Å overvåke hvordan konversasjonelle AI-systemer siterer innholdet ditt er avgjørende for å forstå AI-synligheten din og finne optimaliseringsmuligheter, men de fleste innholdsskapere mangler innsikt i denne kritiske målingen. AmICited.com tilbyr en dedikert plattform for å spore hvordan ChatGPT, Perplexity, Google AI Overviews og andre konversasjonelle AI-systemer refererer til merkevaren og innholdet ditt. Denne overvåkningsmuligheten fyller et viktig hull i innholdsskaperens verktøykasse, og komplementerer tradisjonelle SEO-verktøy ved å gi innsikt i et helt annet søkeparadigme.
AmICited sporer flere nøkkelmålinger tradisjonelle SEO-verktøy ikke kan måle:
Siteringsfrekvens – Hvor ofte innholdet ditt siteres på ulike AI-systemer; dette viser hvilket innhold som treffer AI-algoritmene og hvilke temaer som bør forbedres.
Siteringsmønstre – Hvilke spesifikke sider og innholdsdeler som siteres oftest; dette hjelper deg å identifisere de sterkeste innholdspunktene og avdekker hull i dekningen din.
Konkurrenters AI-synlighet – Se hvordan din AI-siteringsrate sammenlignes med konkurrenters; denne benchmarking gir deg innsikt i din posisjon i AI-søkelandskapet.
Trendsporing – Følg med på hvordan AI-synligheten din endres over tid etter optimalisering; dette lar deg måle effekten av strategiendringer.
Kildemangfold – Spor siteringer på tvers av ulike AI-plattformer; synlighet i ChatGPT kan avvike fra Perplexity eller Google AI Overviews, og forståelse av disse forskjellene hjelper deg å optimalisere for spesifikke systemer.
Å integrere AmICited i innholdsovervåkingen din gir dataene du trenger for å optimalisere spesifikt for AI-synlighet, i stedet for å gjette om innsatsen gir resultater.
Å implementere en spørsmålsbasert innholdsstrategi for konversasjonell AI krever en systematisk tilnærming som bygger på eksisterende innhold samtidig som nye optimaliseringspraksiser etableres. Implementeringsprosessen bør være metodisk og datadrevet, med utgangspunkt i en gjennomgang av nåværende innhold og videre gjennom strukturell optimalisering, autoritetsbygging og kontinuerlig overvåking. Denne åtte-trinns rammen gir en praktisk plan for å transformere innholdsstrategien din for å maksimere AI-synlighet.
Revider eksisterende innhold – Analyser dine 50 beste sider for å forstå nåværende struktur, ordmengde, overskriftshierarki og oppdateringsfrekvens; identifiser hvilke sider som allerede er godt strukturert og hvilke som må optimaliseres.
Finn verdifulle spørsmålsnøkkelord – Undersøk konversasjonelle spørsmål i din bransje med verktøy som Answer the Public, Quora og Reddit; prioriter spørsmål med høyt søkevolum og kommersiell verdi.
Strukturer om med Q&A-seksjoner – Omorganiser eksisterende innhold for å inkludere spørsmålsbaserte overskrifter og direkte svar; gjør om tradisjonelle nøkkelordtitler til spørsmålsbaserte titler som matcher brukerspørsmål.
Innfør overskriftshierarki – Sørg for at alt innhold følger korrekt H2/H3-hierarki med tydelig temaorganisering; del opp lange seksjoner i 120–180 ord med beskrivende underoverskrifter.
Legg til FAQ-seksjoner – Lag egne FAQ-seksjoner for de 20 viktigste sidene, med 5–10 spørsmål og direkte svar; prioriter spørsmål som går igjen i søkedata og tilbakemeldinger fra brukere.
Bygg autoritet med lenker – Utvikle en lenkestrategi rettet mot høykvalitetsdomener i din bransje; fokuser på å opparbeide lenker fra autoritative kilder fremfor kvantitet.
Overvåk med AmICited – Sett opp overvåking for merkevaren og viktige innholdsdeler; etabler grunnverdier og følg utviklingen etter hvert som du implementerer optimaliseringene.
Kvartalsvise oppdateringer – Etabler en rutine for kvartalsvise oppfriskninger som legger til ny statistikk, oppdaterer eksempler og holder innholdet friskt; prioriter sider med mest trafikk og siteringer.
Denne implementeringsstrategien flytter innholdet ditt fra tradisjonell SEO-optimalisering til en helhetlig tilnærming som maksimerer synlighet både i tradisjonelt søk og konversasjonelle AI-systemer.
Spørsmålsbasert innhold er materiale strukturert rundt naturlige språkspørsmål som brukere stiller konversasjonelle AI-systemer. I stedet for å målrette mot nøkkelord som 'tannlege Oslo', retter det seg mot hele spørsmål som 'Hvor kan jeg finne en god tannlege i Oslo som har åpent i helgene?' Denne tilnærmingen tilpasser innholdet til hvordan folk naturlig snakker og hvordan AI-systemer tolker forespørsler.
Tradisjonelt søk returnerer en liste over rangerte lenker basert på nøkkelordmatching, mens konversasjonell AI setter sammen direkte svar fra flere kilder. Konversasjonell AI forstår kontekst, opprettholder samtalehistorikk og gir ett enkelt, syntetisert svar med referanser. Denne grunnleggende forskjellen krever andre strategier for innholdsoptimalisering.
LLM-er tolker innhold hierarkisk ved å bruke overskriftsstrukturer og seksjonsbrudd for å forstå informasjonsorganisering. Optimal struktur med seksjoner på 120–180 ord, klar H2/H3-hierarki og direkte svar tidlig i seksjonene gjør det enklere for AI-systemene å trekke ut og sitere innholdet ditt. Dårlig struktur reduserer sannsynligheten for sitering, uansett innholdskvalitet.
Forskning viser at omtrent 1 900 ord er minimumsterskelen for konkurransedyktig AI-synlighet, mens virkelig omfattende dekning når 2 900+ ord. Likevel er dybde viktigere enn lengde—innhold med ekspertuttalelser, statistikk og flere perspektiver får betydelig flere siteringer enn oppblåst innhold.
Innhold som er oppdatert de siste tre månedene får i gjennomsnitt 6,0 siteringer, mot 3,6 for utdatert innhold. Innfør en kvartalsvis oppdateringsstrategi som legger til ny statistikk, oppdaterer eksempler og inkluderer siste utvikling. Dette signaliserer friskhet til AI-systemene og opprettholder siteringskonkurranse.
Ja. Selv om store domener har autoritetsfordeler, kan mindre nettsteder konkurrere gjennom bedre innholdsstruktur, spørsmålsbasert optimalisering og samfunnsengasjement. Spørsmålsbaserte titler har sju ganger så stor effekt for mindre domener, og aktiv tilstedeværelse på Quora og Reddit kan gi fire ganger høyere siteringssjanse.
AmICited overvåker hvordan ChatGPT, Perplexity og Google AI Overviews siterer merkevaren og innholdet ditt. Det gir innsikt i siteringsmønstre, avdekker innholdshull, sporer konkurrenters AI-synlighet og måler effekten av dine optimaliseringer—målinger tradisjonelle SEO-verktøy ikke kan tilby.
Nei. Selv om schema markup er nyttig for tradisjonelt søk, gir det minimal fordel for AI-synlighet. Innhold med FAQ-schema får i gjennomsnitt 3,6 siteringer, mens godt strukturert innhold uten schema får 4,2 siteringer. Fokuser på faktisk innholdsstruktur og kvalitet fremfor kun markup.
Se hvordan ChatGPT, Perplexity og Google AI Overviews refererer til merkevaren din med AmICiteds AI-siteringssporing.
Forstå hvordan samtalebaserte søk skiller seg fra tradisjonelle nøkkelord-søk. Lær hvorfor AI-søkemotorer prioriterer naturlig språk, brukerhensikt og kontekst ...

Oppdag ubesvarte prompter i AI-søk og gjør dem om til innholdsmuligheter. Lær hvordan du identifiserer hull der konkurrenter er sitert, men ikke du.

Bli ekspert på optimalisering av stemmesøk for AI-assistenter med strategier for samtalenøkkelord, utvalgte utdrag, lokal SEO og schema markup for å øke synligh...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.