
Differensiell Crawler-tilgang
Lær hvordan du selektivt tillater eller blokkerer AI-crawlere basert på forretningsmål. Implementer differensiell crawler-tilgang for å beskytte innhold samtidi...
8 min lesing

Lær hvordan du bruker robots.txt for å kontrollere hvilke AI-roboter som får tilgang til innholdet ditt. Komplett guide til blokkering av GPTBot, ClaudeBot og andre AI-crawlere med praktiske eksempler og konfigurasjonsstrategier.
Krysspresset på web-crawling har endret seg fundamentalt de siste to årene, og har beveget seg forbi det kjente søkeindekseringslandskapet og inn i den komplekse verden av AI-modelltrening. Mens Googles Googlebot lenge har vært en forutsigbar gjest hos utgivere, ankommer nå en ny generasjon crawlere med dramatisk ulike hensikter og forbruksmønstre. OpenAI sin GPTBot har et crawl-to-refer-forhold på omtrent 1 700:1, noe som betyr at den crawler 1 700 sider for å generere kun én henvisning tilbake til nettstedet ditt, mens Anthropics ClaudeBot opererer på et enda mer ekstremt 73 000:1-forhold—i sterk kontrast til Googles 14:1-forhold hvor crawling faktisk gir meningsfull trafikk. Denne grunnleggende forskjellen skaper et akutt forretningsvalg for innholdsskapere: Lar du disse robotene ha fri tilgang, trener innholdet ditt AI-modeller som konkurrerer med din trafikk og inntektsstrømmer, mens nettstedet ditt får minimal kompensasjon eller trafikk tilbake. Utgivere må nå aktivt vurdere om verdiforslaget til AI-robottilgang er forenlig med forretningsmodellen, og gjøre robots.txt-konfigurasjon til et strategisk forretningsvalg snarere enn bare en teknisk vurdering.
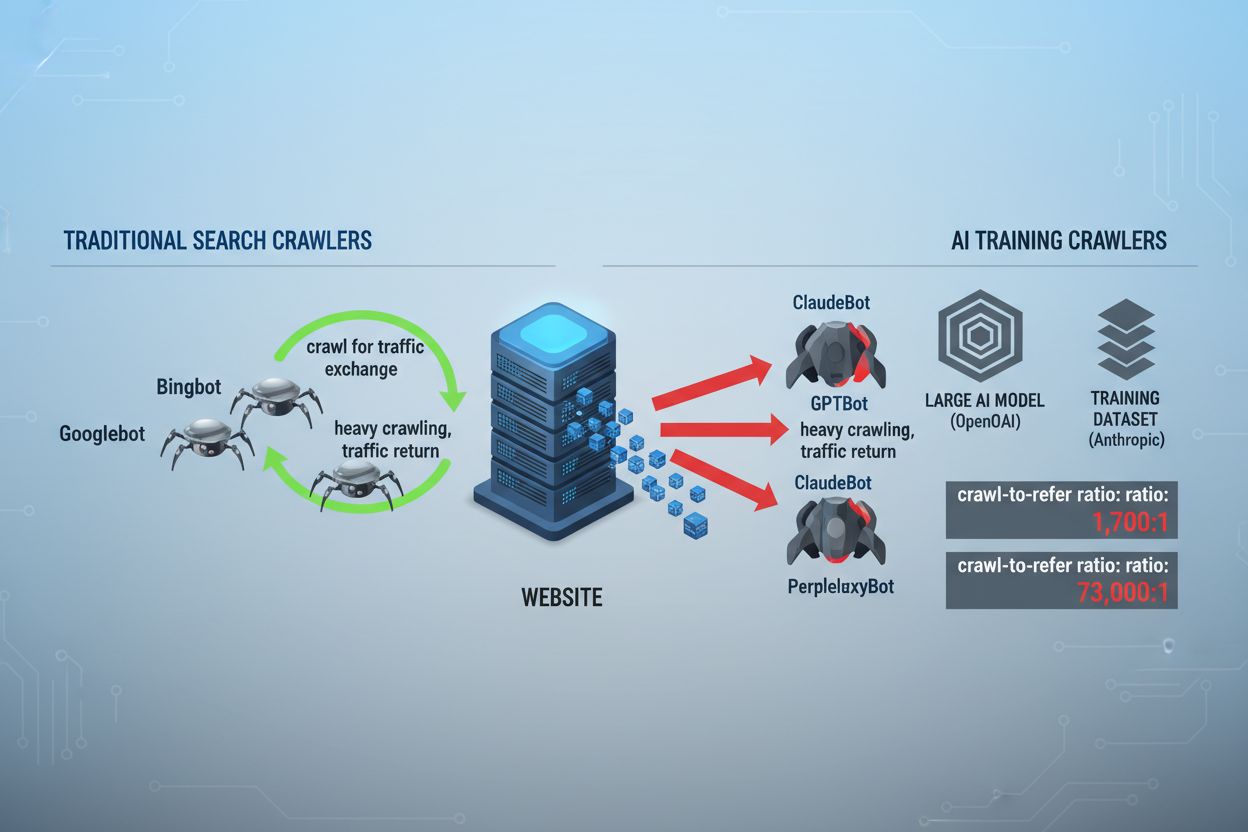
AI-crawlere opererer i tre distinkte kategorier, som hver tjener ulike formål og krever ulike blokkeringsstrategier. Treningscrawlere er laget for å konsumere store mengder innhold for å trene grunnleggende AI-modeller—disse inkluderer OpenAI sin GPTBot, Anthropics ClaudeBot, Googles Google-Extended, Perplexitys PerplexityBot, Metas Meta-ExternalAgent, Apples Applebot-Extended samt nye aktører som Amazonbot, Bytespider og cohere-ai. Søkecrawlere er derimot laget for å drive AI-drevne søkeopplevelser og returnerer vanligvis trafikk til utgivere; disse inkluderer OpenAI sin OAI-SearchBot, Anthropics Claude-Web og Perplexitys søkefunksjon. Brukerutløste agenter representerer en tredje kategori, der innhold hentes på forespørsel når en bruker eksplisitt ber om informasjon, slik som ChatGPT-User eller Claude-Web-interaksjoner startet direkte av sluttbrukere. Å forstå denne taksonomien er avgjørende fordi blokkeringsstrategien bør gjenspeile dine forretningsprioriteringer—du kan ønske søkecrawlere som gir trafikk, men blokkere treningscrawlere som forbruker innhold uten kompensasjon. Hvert stort AI-selskap har sin egen flåte med spesialiserte crawlere, og forskjellen mellom dem avgjøres ofte av user agent-strengen de bruker, noe som gjør nøyaktig identifisering og målrettet blokkering avgjørende for effektiv robots.txt-konfigurasjon.
| Selskap | Treningscrawler | Søkecrawler | Brukerutløst agent |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Bruker standard Googlebot) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Å opprettholde en nøyaktig, oppdatert liste over AI-roboters user agents er avgjørende for effektiv robots.txt-konfigurasjon, men dette landskapet endrer seg raskt etter hvert som nye modeller lanseres og selskaper justerer sine crawling-strategier. De viktigste treningscrawlerne du bør kjenne til inkluderer GPTBot (OpenAIs primære treningscrawler), ClaudeBot (Anthropics treningscrawler), anthropic-ai (Anthropics alternative identifikator), Google-Extended (Googles AI-treningstoken), PerplexityBot (Perplexitys crawler), Meta-ExternalAgent (Metas treningscrawler), Applebot-Extended (Apples AI-treningsvariant), CCBot (Common Crawl), Amazonbot (Amazons crawler), Bytespider (ByteDance), cohere-ai (Cohere), DuckAssistBot (DuckDuckGo), og YouBot (You.com). Søkefokuserte crawlere som typisk gir trafikk inkluderer OAI-SearchBot, Claude-Web og PerplexityBot i søkemodus. Den kritiske utfordringen er at denne listen ikke er statisk—nye AI-selskaper dukker stadig opp, eksisterende selskaper lanserer nye crawlere for nye produkter, og user agent-strenger endres eller utvides av og til. Utgivere bør derfor behandle robots.txt som et levende dokument som krever kvartalsvis gjennomgang og oppdatering, eventuelt abonnere på bransjesporingsressurser eller overvåke serverlogger for ukjente user agents som kan indikere nye AI-crawlere på nettstedet ditt. Unnlater du å holde listen oppdatert, risikerer du å tillate nye treningscrawlere du egentlig ønsket å blokkere, eller blokkere legitime søkecrawlere som kunne gitt verdifull trafikk.
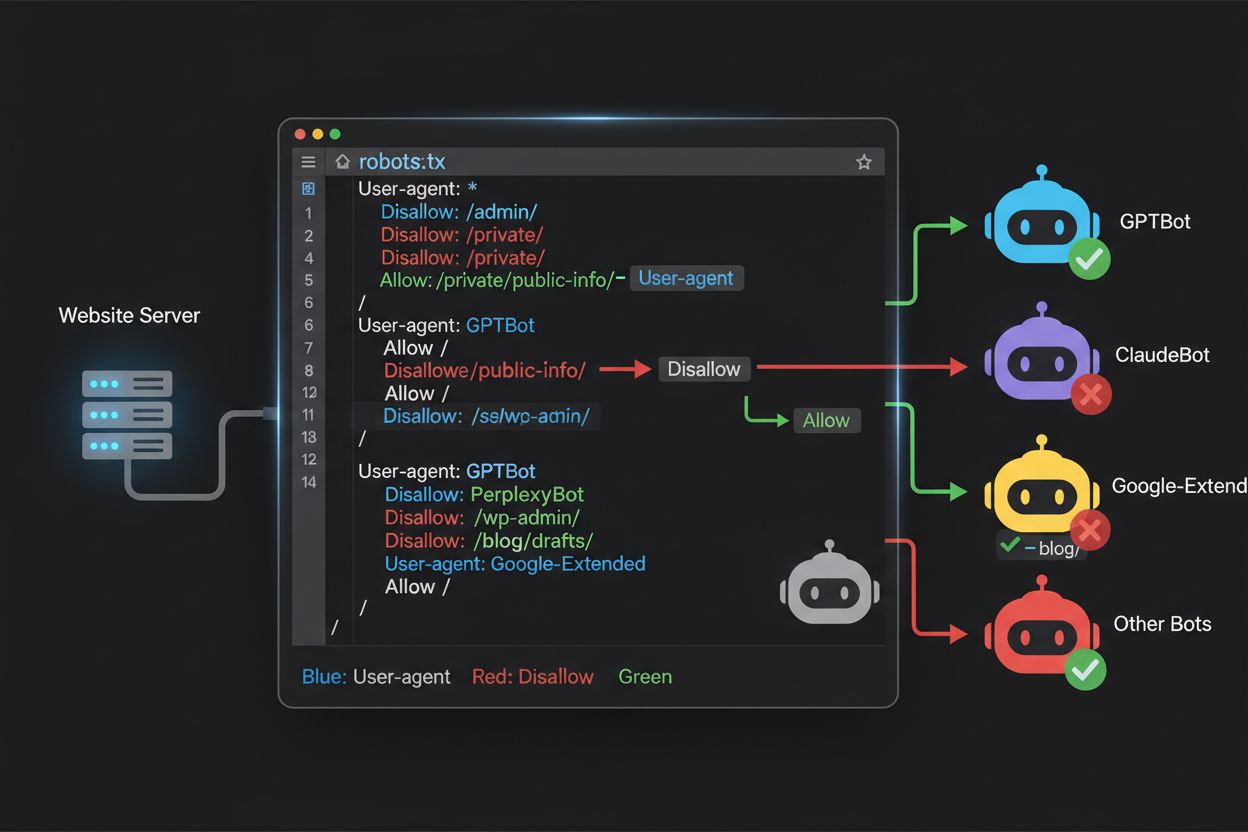
Robots.txt-filen, som ligger i rotmappen på domenet ditt (dittdomene.com/robots.txt), bruker en enkel syntaks for å kommunisere crawling-ønsker til roboter som respekterer protokollen. Hver regel begynner med en User-Agent-direktiv som spesifiserer hvilken robot regelen gjelder for, etterfulgt av én eller flere Disallow-direktiver for å angi hvilke stier roboten ikke skal ha tilgang til. For å blokkere alle store AI-treningscrawlere, men fortsatt tillate tradisjonelle søkemotorer, oppretter du egne User-Agent-blokker for hver treningscrawler du vil utelukke: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended og andre, hver med “Disallow: /” som hindrer dem i å crawlere noe innhold på nettstedet ditt. Samtidig sørger du for at legitime søkecrawlere som Googlebot, Bingbot og søkefokuserte varianter som OAI-SearchBot ikke blokkeres, slik at de fortsatt kan indeksere innholdet ditt og gi trafikk. En korrekt konfigurert robots.txt-fil bør også ha en sitemap-referanse som peker til din XML-sitemap, slik at søkemotorer lett kan finne og indeksere innholdet ditt effektivt. Viktigheten av korrekt konfigurasjon kan ikke overvurderes—en enkel syntaksfeil, feilplassert tegn eller feil user agent-streng kan gjøre hele blokkeringsstrategien din ineffektiv, slik at uønskede crawlere får tilgang til innholdet ditt, eller at legitime trafikkilder blokkeres. Test alltid konfigurasjonen før du tar den i bruk for å sikre ønsket effekt.
# Blokker AI-treningscrawlere
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Tillat tradisjonelle søkemotorer
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Sitemap-referanse
Sitemap: https://yoursite.com/sitemap.xml
Mange utgivere står overfor en nyansert avgjørelse: De ønsker å være synlige i AI-drevne søkeresultater og motta trafikken slike plattformer gir, men vil hindre at innholdet brukes til å trene grunnleggende AI-modeller som kan konkurrere mot forretningen. Denne selektive blokkeringsstrategien krever at man skiller mellom søkecrawlere og treningscrawlere fra samme selskap—for eksempel tillate OpenAIs OAI-SearchBot (som driver ChatGPT-søk og gir trafikk) men blokkere GPTBot (som trener modellen). Tilsvarende kan du tillate PerplexityBots søkecrawler, men blokkere treningsoperasjonene, eller tillate Claude-Web for brukerutløste søk og blokkere ClaudeBots trening. Forretningsbegrunnelsen er tydelig: Søkecrawlere har ofte langt lavere crawl-to-refer-forhold fordi de er laget for å gi trafikk tilbake til deg, mens treningscrawlere forbruker innhold i stor skala uten nevneverdig gjengjeld. Denne tilnærmingen krever nøye konfigurasjon og kontinuerlig overvåking, da selskaper tidvis endrer crawler-strategier eller introduserer nye user agents som visker ut skillet mellom søk og trening. Utgivere som følger denne strategien bør jevnlig sjekke serverlogger for å sikre at ønskede crawlere får tilgang og blokkerte crawlere blir effektivt utestengt, og justere robots.txt når AI-landskapet endrer seg eller nye aktører entrer markedet.
# Tillat AI-søkecrawlere
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Blokker treningscrawlere
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Selv erfarne webansvarlige gjør ofte konfigurasjonsfeil som undergraver hele robots.txt-strategien, og gjør innholdet sårbart for nettopp de crawlerne de ønsket å blokkere. Første vanlige feil er å lage frittstående User-Agent-linjer uten tilhørende Disallow-direktiver—for eksempel skrive “User-Agent: GPTBot” på én linje og så starte en ny regel uten å spesifisere hva GPTBot skal utestenges fra, noe som etterlater roboten helt ubeskyttet. Andre feil gjelder feil filplassering, navngivning eller store/små bokstaver; filen må hete nøyaktig “robots.txt” (små bokstaver), ligge i roten av domenet og serveres med HTTP 200-statuskode—legger du den i en undermappe eller kaller den “Robots.txt” eller “robots.TXT” blir den usynlig for crawlere. Tredje feil er å legge inn blanke linjer innenfor en regelblokk, som mange robots.txt-parsere tolker som slutten på regelen, slik at påfølgende direktiver ignoreres eller feiltolkes. Fjerde feil er feil bruk av store/små bokstaver i URL-stier; user agent-navn er ikke store/små-bokstavsfølsomme, men stier i Disallow-direktiver er det, så “Disallow: /Admin” vil ikke blokkere “/admin” eller “/ADMIN”. Femte feil er feilaktig bruk av wildcards—stjerne (*) matcher alle tegn, men mange bruker feil mønstre som “Disallow: .pdf” når de egentlig burde skrive “Disallow: /.pdf” eller “Disallow: /*pdf” for å matche filendelser. I tillegg lager noen for kompliserte regler med flere motstridende Disallow-direktiver, eller glemmer å ta hensyn til URL-parametere, noe som kan føre til at legitime sider blokkeres eller uønsket innhold blir tilgjengelig. Test konfigurasjonen med dedikerte robots.txt-validerere før produksjon for å oppdage slike feil før de påvirker nettstedets tilgjengelighet.
Vanlige feil å unngå:
Google-Extended er et spesielt tilfelle i robots.txt fordi det fungerer som et kontrolltoken snarere enn en tradisjonell crawler, og å forstå denne forskjellen er avgjørende for informerte blokkeringsvalg. I motsetning til Googlebot, som crawler nettstedet ditt for å indeksere innhold for Google Søk, er Google-Extended et signal som kontrollerer om innholdet ditt kan brukes til å trene Googles Gemini AI-modeller og drive Google AI Overviews i søkeresultatene. Ved å blokkere Google-Extended hindrer du at innholdet ditt brukes i Gemini-trening og AI Overviews, men det påvirker ikke synligheten din i vanlige Google-søk—Googlebot vil fortsatt indeksere innholdet. Avveiningen er betydelig: Blokkering av Google-Extended betyr at innholdet ditt ikke vises i AI Overviews, som blir stadig mer fremtredende i Google Søk og kan gi betydelig trafikk, men du beskytter også innholdet fra å bli brukt til å trene en konkurrerende AI-modell. Omvendt vil tillatelse til Google-Extended gjøre at innholdet kan vises i AI Overviews (og potensielt gir trafikk), men det bidrar også til Geminis treningsdata, som på sikt kan konkurrere med ditt eget innhold eller forretningsmodell. Utgivere bør nøye vurdere sin situasjon—nyhetsorganisasjoner og innholdsskapere med avhengighet av direkte trafikk kan ha fordel av å blokkere Google-Extended, mens andre kanskje ønsker økt synlighet og trafikkpotensial fra AI Overviews. Beslutningen bør være bevisst, ikke standard, da den har stor innvirkning på langsiktig synlighet og trafikkmønster i Googles søkeøkosystem.
Å teste robots.txt-konfigurasjonen før produksjonssetting er helt avgjørende, siden feil kan få store konsekvenser for både synlighet og innholdsbeskyttelse. Google Search Console har en innebygd robots.txt-tester som lar deg sjekke om spesifikke user agents kan få tilgang til bestemte URL-er—du kan skrive inn for eksempel “GPTBot” og en sti, og Google gir deg beskjed om boten tillates eller blokkeres i henhold til din konfigurasjon. Merkle Robots.txt Tester tilbyr lignende funksjonalitet med brukervennlig grensesnitt og detaljerte forklaringer. TechnicalSEO.com gir også et gratis testverktøy som validerer syntaksen din og viser hvordan ulike roboter behandles. For mer omfattende overvåking tilbyr Knowatoa AI Search Console spesialiserte verktøy for å spore AI-crawler-aktivitet og validere konfigurasjonen mot nettopp de robotene du prøver å blokkere. Din valideringsrutine bør inkludere å laste opp robots.txt til et staging-miljø først, deretter verifisere at kritiske sider du vil holde åpne ikke blokkeres, at AI-roboter du ønsker å blokkere faktisk ekskluderes, og å overvåke serverlogger for uventet crawler-aktivitet. Testfasen bør også inkludere sjekk av at sitemap-referansen er korrekt og at søkemotorer fortsatt får tilgang til innholdet—du vil blokkere AI-treningscrawlere uten å blokkere legitime søkemotorer. Først etter grundig testing bør du ta konfigurasjonen i bruk, og selv da bør du overvåke logger den første uken for å oppdage eventuelle problemer.
Testverktøy:
Selv om robots.txt er et nyttig første forsvar, er det viktig å forstå at det fungerer på tillit—roboter som respekterer protokollen følger reglene dine, men ondsinnede eller dårlig designede crawlere kan ignorere robots.txt fullstendig og likevel få tilgang til innholdet. Bransjetall viser at robots.txt stopper omtrent 40-60 % av uønsket crawler-trafikk, noe som betyr at 40-60 % av robotene enten ignorerer protokollen eller er laget for å omgå den. For utgivere med behov for sterkere beskyttelse kreves derfor ekstra lag. Cloudflares Web Application Firewall (WAF) lar deg lage regler for å blokkere trafikk basert på user agent-strenger, IP-adresser eller atferdsmønstre, og gir beskyttelse mot crawlere som ignorerer robots.txt. Serververktøy som .htaccess (på Apache-servere) eller tilsvarende på Nginx kan blokkere spesifikke user agents eller IP-intervaller før forespørsler når applikasjonen din. IP-blokkering kan være effektivt hvis du identifiserer IP-intervallene til bestemte crawlere, men dette krever løpende vedlikehold etter hvert som crawler-infrastrukturen endres. Fail2ban og lignende verktøy kan automatisk blokkere IP-er som viser mistenkelig atferd, som å gjøre forespørsler i unaturlig høyt tempo eller besøke sensitive stier. Men slike tiltak krever nøye konfigurasjon—overdreven blokkering kan uforvarende ekskludere legitim trafikk, som ekte brukere bak VPN eller bedriftsproxyer som deler IP med kjente crawlere. Den mest effektive tilnærmingen kombinerer robots.txt som høflig første anmodning, blokkering på servernivå for roboter som ignorerer robots.txt, og atferdsovervåking for å fange sofistikerte crawlere som forfalsker user agent eller bruker distribuerte IP-adresser. Utgivere bør implementere slike lag gradvis og teste hvert av dem for å sikre at de ikke blokkerer reell trafikk, samtidig som de oppnår ønsket innholdsbeskyttelse.
Å forstå hva som faktisk besøker nettstedet ditt er avgjørende for å validere at robots.txt fungerer etter hensikten og for å identifisere nye crawlere som bør blokkeres. Serverlogganalyse er den viktigste metoden for slik overvåking—webserverlogger (Apache access logs, Nginx-logger eller tilsvarende) inneholder detaljerte oppføringer over hver forespørsel, inkludert user agent-streng, IP-adresse, tidsstempel og forespurt ressurs. Du kan bruke kommandolinjeverktøy som grep for å søke etter spesifikke user agents; for eksempel “grep ‘GPTBot’ /var/log/apache2/access.log” viser alle forespørsler fra GPTBot, slik at du kan sjekke om blokkeringen din virker. Mer avansert analyse kan innebære å se på crawl-rate for ulike roboter, hvilke sider de besøker og om de respekterer robots.txt. Automatiserte overvåkingsløsninger kan hele tiden analysere logger og varsle deg når nye eller uventede crawlere dukker opp—noe som er svært verdifullt i et landskap der nye AI-crawlere dukker opp ofte. Noen utgivere bruker logg-aggregeringsplattformer som ELK Stack, Splunk eller skyløsninger for å sentralisere og analysere crawler-aktivitet på tvers av flere servere. Det hurtigskiftende AI-crawler-landskapet betyr at overvåking ikke er engangsjobb, men et løpende ansvar—nye roboter dukker stadig opp, eksisterende roboter endrer user agent-strenger, og crawler-atferd utvikler seg. Etablér derfor en rutine for regelmessig overvåking (ukentlig eller månedlig gjennomgang av logger) for å holde deg foran endringene og oppdatere robots.txt proaktivt.
Robots.txt-konfigurasjonen for AI-crawlere er i bunn og grunn en inntektsbeslutning, og fortjener samme strategiske vurdering som ethvert annet forretningsvalg med stor økonomisk betydning. Å gi treningscrawlere fri tilgang betyr at AI-modeller trent på din data kan ende opp med å konkurrere mot din trafikk og inntektsstrømmer—hvis forretningsmodellen din er avhengig av direkte trafikk, søkesynlighet eller annonseinntekter, gir du i praksis gratis treningsdata til selskaper som lager konkurrerende produkter. Omvendt betyr blokkering av alle AI-crawlere at du mister potensiell synlighet i AI-drevne søk og trafikk fra AI-assistenter, noe som blir en stadig viktigere måte brukere finner innhold på. Den optimale strategien avhenger av forretningsmodellen din: Annonsebaserte utgivere kan ha nytte av å tillate søkecrawlere (som gir trafikk og annonsevisninger) men blokkere treningscrawlere (som ikke gir trafikk). Abonnementsbaserte utgivere kan velge å blokkere de fleste AI-crawlere for å beskytte innholdet mot å bli oppsummert eller etterlignet av AI-systemer. Utgivere som fokuserer på synlighet og tankelederskap kan ønske AI-synlighet som distribusjonskanal. Nøkkelen er å ta dette valget bevisst, ikke la det bli standard—mange har aldri konfigurert robots.txt for AI-crawlere, og tillater dermed alle roboter som standard, altså har de passivt valgt å bidra med innhold til AI-trening uten å aktivt velge det. Vurder også å implementere schema-markering som gir korrekt attribusjon når innholdet brukes av AI-systemer, slik at trafikk og kreditering fortsatt kan komme tilbake til nettstedet selv når innhold refereres av AI-assistenter. Robots.txt-konfigurasjonen bør gjenspeile din bevisste forretningsstrategi, og gjennomgås og oppdateres jevnlig etter hvert som AI-landskapet og dine egne prioriteringer endrer seg.
AI-crawler-landskapet utvikler seg i et enestående tempo, med nye selskaper som lanserer AI-produkter, eksisterende selskaper som introduserer nye crawlere, og user agent-strenger som endres eller utvides jevnlig. Robots.txt-konfigurasjonen din bør derfor ikke være et sett-og-glem-dokument, men et levende dokument du bør gjennomgå og oppdatere minst kvartalsvis. Etabler en prosess for å følge med på bransjevarsler om nye AI-crawlere, abonner på relevante nyhetsbrev eller blogger som følger utviklingen, og gjennomgå serverloggene dine regelmessig for å identifisere ukjente user agents som kan indikere nye crawlere på nettstedet ditt. Når du finner nye crawlere, undersøk formålet og forretningsmodellen deres for å vurdere om de passer inn i din innholdsbeskyttelsesstrategi, og oppdater robots.txt deretter. Overvåk også effekten av konfigurasjonen ved å følge med på crawler-trafikkvolum, forholdet mellom crawler- og brukeratferd, og eventuelle endringer i organisk synlighet eller henvisningstrafikk fra AI-drevne søk. Noen utgivere finner at den opprinnelige blokkeringsstrategien må justeres etter noen måneders reelle data—kanskje oppdager de at blokkering av en bestemt crawler fikk uønskede konsekvenser, eller at tillatelse til visse crawlere gir mer verdifull trafikk enn forventet. Vær forberedt på å justere strategien etter faktiske resultater, ikke bare antakelser. Kommuniser også robots.txt-strategien til relevante interne aktører—SEO-team, innholdsteam og ledelse bør alle forstå hvorfor visse crawlere blokkeres eller tillates, slik at beslutninger forblir konsistente og bevisste etter hvert som organisasjonen utvikler seg. Denne løpende oppmerksomheten til crawler-håndtering sikrer at innholdsbeskyttelsesstrategien forblir effektiv og i tråd med forretningsmålene dine etter hvert som AI-landskapet endres.
Nei. Å blokkere AI-treningscrawlere som GPTBot, ClaudeBot og CCBot påvirker ikke dine Google- eller Bing-rangeringer. Tradisjonelle søkemotorer bruker egne crawlere (Googlebot, Bingbot) som opererer uavhengig. Blokker kun disse hvis du ønsker å forsvinne helt fra søkeresultatene.
Store crawlere fra OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) og Perplexity (PerplexityBot) oppgir offisielt at de respekterer robots.txt-direktiver. Mindre eller mindre transparente roboter kan derimot overse konfigurasjonen din, derfor finnes det lagvise beskyttelsesstrategier.
Det avhenger av strategien din. Ved å blokkere kun treningscrawlere (GPTBot, ClaudeBot, CCBot) beskytter du innholdet ditt fra modelltrening samtidig som søkefokuserte crawlere kan hjelpe deg å vises i AI-søkeresultater. Full blokkering fjerner deg helt fra AI-økosystemene.
Gå gjennom konfigurasjonen minst kvartalsvis. AI-selskaper introduserer jevnlig nye crawlere. Anthropic slo nylig sammen sine 'anthropic-ai' og 'Claude-Web'-roboter til 'ClaudeBot', noe som ga den nye roboten midlertidig ubegrenset tilgang til nettsteder som ikke hadde oppdatert reglene sine.
Robots.txt er en fil i rotdomenet ditt som gjelder for alle sider, mens meta robots-tagger er HTML-direktiver på individuelle sider. Robots.txt sjekkes først og kan forhindre crawlere i å få tilgang til en side, mens meta-tagger kun leses hvis siden allerede er besøkt. Bruk begge for fullstendig kontroll.
Ja. Du kan bruke stispesifikke Disallow-regler i robots.txt (f.eks. 'Disallow: /premium/' for å blokkere kun premiuminnhold) eller bruke meta robots-tagger på enkeltstående sider. Dette lar deg beskytte sensitivt innhold og fortsatt gi crawlere tilgang til andre deler av nettstedet.
Hvis en robot ignorerer robots.txt, trenger du ekstra beskyttelsesmetoder som blokkering på servernivå (.htaccess), IP-blokkering eller WAF-regler. Robots.txt stopper omtrent 40-60 % av uønskede crawlere, så lagvis beskyttelse er viktig for fullverdig forsvar.
Bruk testverktøy som Google Search Consoles robots.txt-tester, Merkle Robots.txt Tester eller TechnicalSEO.com for å validere konfigurasjonen din. Overvåk serverloggene dine for crawler-aktivitet for å bekrefte at blokkerte roboter utelates, og tillatte roboter får tilgang til innholdet ditt.
Robots.txt er bare første steg. Bruk AmICited for å spore hvilke AI-systemer som siterer innholdet ditt, hvor ofte de refererer til deg, og sikre korrekt attribusjon på tvers av GPTs, Perplexity, Google AI Overviews og mer.
Lær hvordan du selektivt tillater eller blokkerer AI-crawlere basert på forretningsmål. Implementer differensiell crawler-tilgang for å beskytte innhold samtidi...

Lær hvordan Web Application Firewall gir avansert kontroll over AI-roboter utover robots.txt. Implementer WAF-regler for å beskytte innholdet ditt mot uautorise...

Lær hvordan du tester om AI-crawlere som ChatGPT, Claude og Perplexity kan få tilgang til innholdet på nettstedet ditt. Oppdag testmetoder, verktøy og beste pra...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.