Avansert GEO-målretting: Funksjoner, Muligheter og Implementering
Oppdag hvordan avansert geotargeting ser ut i moderne digital markedsføring. Lær om sofistikerte stedsbaserte strategier, atferdsmålretting og hvordan du implem...
7 min lesing

Bli ekspert på GEO-eksperimenter med vår omfattende guide om kontrollgrupper og variabler. Lær hvordan du designer, gjennomfører og analyserer geografiske eksperimenter for nøyaktig markedsføringsmåling og AI-synlighets-sporing.
GEO-eksperimenter, også kjent som geo lift-tester eller geografiske eksperimenter, representerer et grunnleggende skifte i hvordan markedsførere måler den reelle effekten av sine kampanjer. Disse eksperimentene deler geografiske regioner inn i test- og kontrollgrupper, slik at markedsførere kan isolere den inkrementelle effekten av markedsføringstiltak uten å måtte stole på sporing på individnivå. I en tid hvor personvernreguleringer som GDPR og CCPA strammes inn, og tredjeparts informasjonskapsler fases ut, tilbyr GEO-eksperimenter et personvernsikkert og statistisk robust alternativ til tradisjonelle målemetoder. Ved å sammenligne utfall mellom regioner som utsettes for markedsføring og de som ikke gjør det, kan organisasjoner trygt besvare spørsmålet: “Hva ville skjedd uten kampanjen vår?” Denne metoden har blitt essensiell for merkevarer som ønsker å forstå reell økning og optimalisere markedsføringsbudsjettet med presisjon.
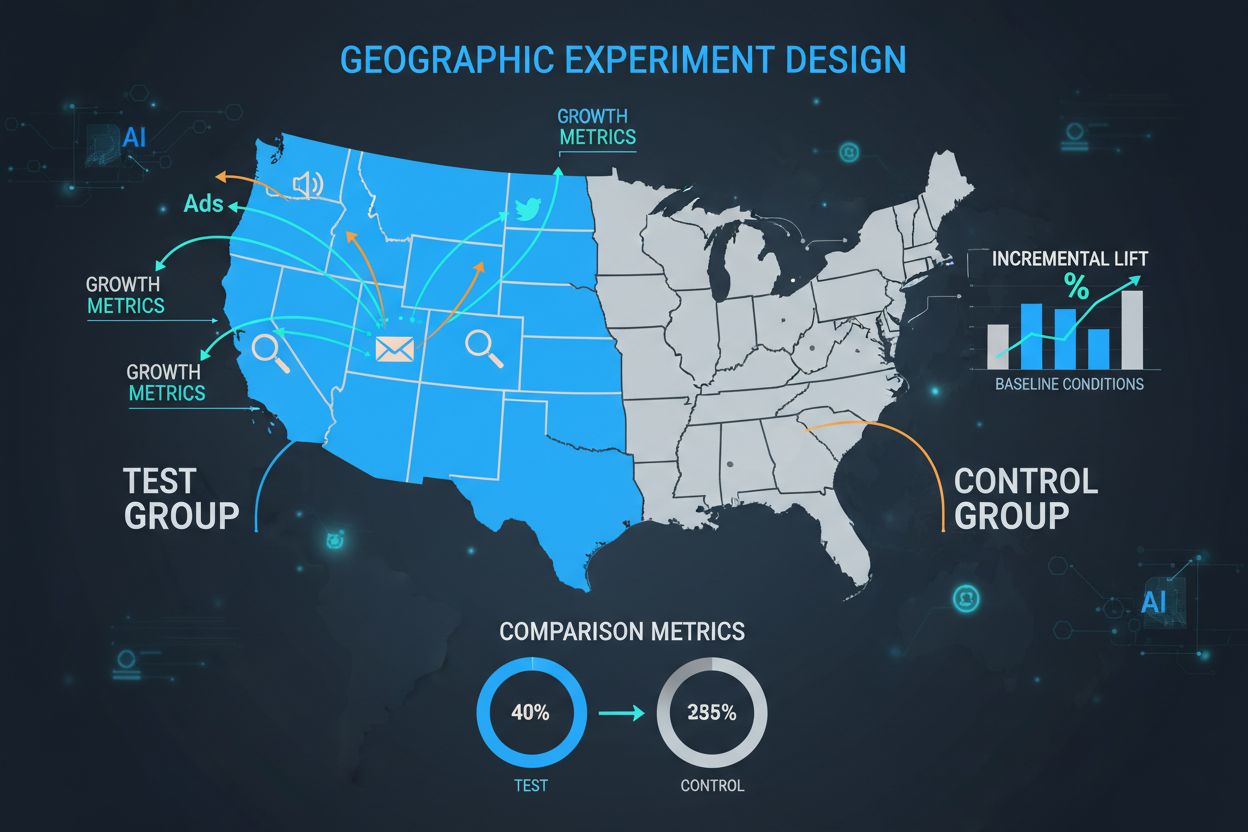
Kontrollgruppen er hjørnesteinen i ethvert GEO-eksperiment og fungerer som det kritiske utgangspunktet alle behandlingseffekter måles mot. En kontrollgruppe består av geografiske regioner som ikke mottar markedsføringstiltaket, slik at markedsførere kan observere hva som naturlig ville skjedd uten kampanjen. Kontrollgruppers styrke ligger i deres evne til å ta hensyn til eksterne faktorer – sesongvariasjoner, konkurrentaktiviteter, økonomiske forhold og markedstrender – som ellers ville forstyrret resultatene. Når de utformes riktig, gjør kontrollgrupper det mulig for forskere å isolere den reelle årsakseffekten av markedsføringen, fremfor kun å observere korrelasjon. Utvelgelsen av kontrollregioner krever nøye matching på flere dimensjoner, inkludert demografiske trekk, historiske resultatmålinger, markedsstørrelse og forbrukeratferd. Dårlig valg av kontrollgruppe fører til høy varians i resultatene, brede konfidensintervaller og til slutt upålitelige konklusjoner som kan føre til kostbare feilallokeringer av markedsføringsbudsjettet.
| Aspekt | Kontrollgruppe | Testgruppe |
|---|---|---|
| Markedsføringstiltak | Ingen (Business as Usual) | Aktiv kampanje |
| Formål | Etablere utgangspunkt | Måle effekt |
| Geografisk utvalg | Matchet til test | Primært fokus |
| Datainnsamling | Samme målinger | Samme målinger |
| Utvalgsstørrelse | Sammenlignbar | Sammenlignbar |
| Forstyrrende variabler | Minimert | Minimert |
Vellykkede GEO-eksperimenter krever nøye styring av flere typer variabler som påvirker utfall og tolkningsevne. Å forstå forskjellen mellom uavhengige, avhengige, kontroll- og forstyrrende variabler er essensielt for å designe eksperimenter som gir handlingsrettede innsikter.
Uavhengige variabler: Dette er markedsføringstiltakene du aktivt manipulerer og tester, som annonsebudsjett, kreative varianter, kanalvalg, målrettingsparametere eller kampanjetilbud. Den uavhengige variabelen er det du ønsker å måle effekten av.
Avhengige variabler: Dette er utfallene du måler for å vurdere effekten av markedsføringstiltaket, inkludert omsetning, konverteringer, kundeverving, merkevarebevissthet, nettsidetrafikk og – viktig for moderne markedsførere – AI-siteringssynlighet og merkevareomtaler i AI-systemer.
Kontrollvariabler: Dette er faktorer du holder konstante i både test- og kontrollgrupper for å sikre rettferdig sammenligning, slik som budskapskonsistens, tilbudsstruktur, kampanjevarighet og mediemikssammensetning.
Forstyrrende variabler: Dette er uventede eksterne faktorer som kan påvirke resultatene uavhengig av markedsføringstiltaket, inkludert konkurrentkampanjer, naturkatastrofer, store nyhetshendelser, sesongvariasjoner og økonomiske endringer.
Målingsvariabler: Dette er de spesifikke KPI-ene og målingene du sporer, inkludert inkrementell løft, inkrementell ROAS (iROAS), inkrementell CAC (iCAC) og konfidensintervaller rundt dine estimater.
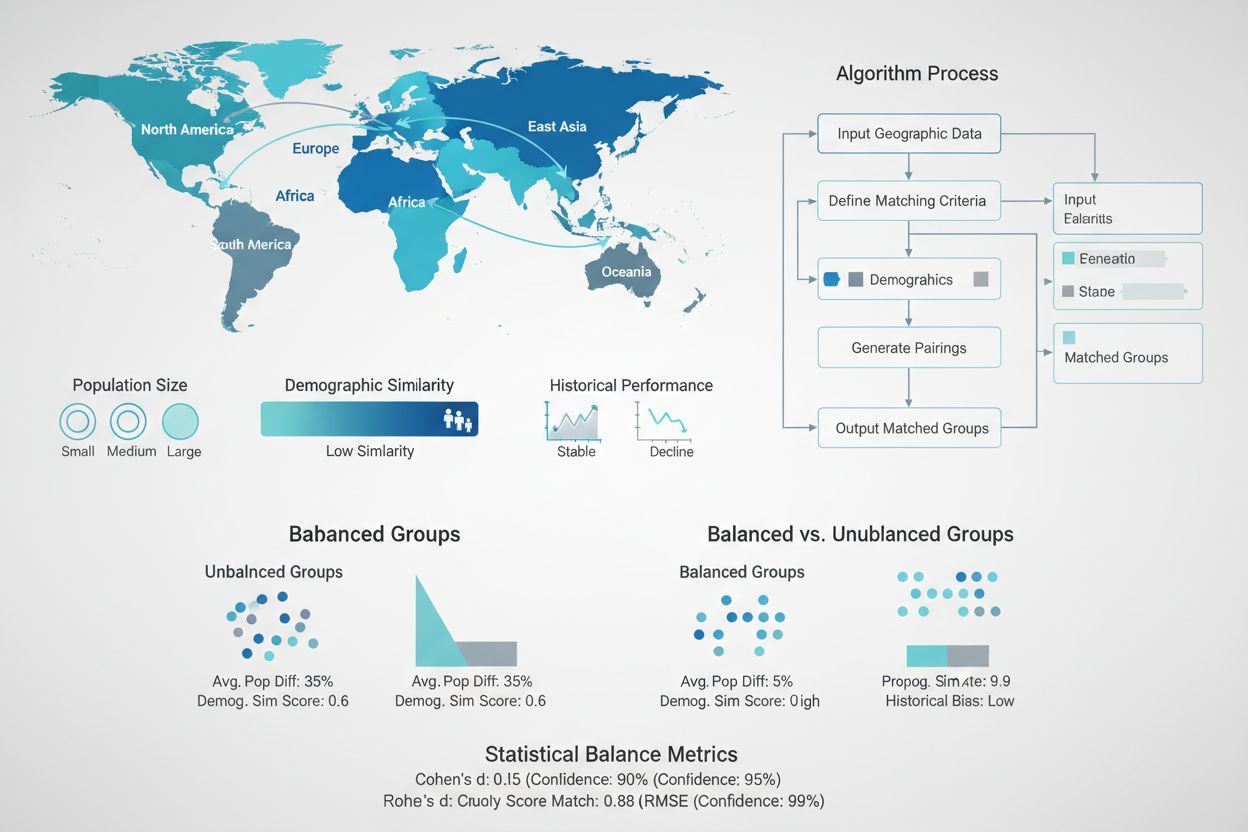
Å skape statistisk likeverdige test- og kontrollgrupper er en av de viktigste, men også mest krevende aspektene ved GEO-eksperimentdesign. I motsetning til randomiserte kontrollerte studier med millioner av individuelle brukere, jobber GEO-eksperimenter vanligvis med bare dusinvis til hundrevis av geografiske enheter, slik at tilfeldig tildeling ofte ikke er nok for å oppnå balanse. Avanserte matching-algoritmer og optimaliseringsteknikker har kommet for å løse denne utfordringen. Syntetiske kontrollmetoder, utviklet av økonometrikere og gjort populære av selskaper som Wayfair og Haus, bruker historiske data for å identifisere og vekte kontrollregioner som best matcher testregionenes egenskaper. Disse algoritmene vurderer flere dimensjoner samtidig – befolkningsstørrelse, demografisk sammensetning, historiske salgsmønstre, mediekonsum og konkurransesituasjon – for å lage kontrollgrupper som fungerer som nøyaktige motfaktiske sammenligninger. Målet er å minimere forskjellen mellom test- og kontrollgrupper på alle forhåndsmålte parametere, slik at eventuelle observerte forskjeller etter tiltaket trygt kan tilskrives markedsføringen – ikke eksisterende ulikheter.
Den statistiske grundigheten til GEO-eksperimenter skiller dem fra tilfeldige observasjoner eller anekdotiske bevis. Konfidensintervaller representerer området hvor den sanne behandlingseffekten sannsynligvis ligger, uttrykt med et bestemt sikkerhetsnivå (typisk 95 %). Et smalt konfidensintervall indikerer høy presisjon og stor sikkerhet i resultatene, mens et bredt intervall antyder stor usikkerhet. For eksempel, hvis et GEO-eksperiment viser et løft på 10 % med et 95 % konfidensintervall på ±2 %, kan du være ganske trygg på at den sanne effekten ligger mellom 8 % og 12 %. Omvendt gir et løft på 10 % med ±8 % konfidensintervall (fra 2 % til 18 %) langt mindre handlingsrettet informasjon. Bredden på konfidensintervaller avhenger av flere faktorer: utvalgsstørrelse (antall regioner), varians i utfall, testvarighet og forventet effektstørrelse. Minimum påvisbar effekt (MDE)-beregninger hjelper deg å avgjøre på forhånd om det foreslåtte eksperimentdesignet kan oppdage løftet du håper å måle. Power-analyse sikrer at du har tilstrekkelig statistisk styrke – typisk 80 % eller høyere – til å oppdage reelle effekter når de finnes, samtidig som du kontrollerer for type I-feil (falske positive) og type II-feil (falske negative).
Selv velmente GEO-eksperimenter kan gi misvisende resultater hvis vanlige fallgruver ikke unngås nøye. Å forstå disse og implementere sikringstiltak er avgjørende for pålitelig måling.
Ubalaanserte grupper: Når test- og kontrollregioner skiller seg betydelig på viktige forhåndsmålte parametere, øker variansen og det blir vanskelig å oppdage reelle effekter. Tiltak: Bruk matching-algoritmer og syntetiske kontrollmetoder for å sikre statistisk likeverdige grupper på alle viktige dimensjoner.
Overløpseffekter: Brukere og medieeksponering respekterer ikke alltid geografiske grenser. Folk reiser mellom regioner, og digital annonsering kan nå målgrupper utenfor tiltenkte områder. Tiltak: Bruk geografiske grenser som minimerer krysskontaminering, vurder pendlermønstre og benytt geofencing for presis kontroll.
For kort testvarighet: Kampanjer trenger tid for å gi resultater, og kundereiser varierer i lengde. Korte testvinduer går glipp av forsinkede konverteringseffekter og sesongmønstre. Tiltak: Kjør eksperimenter i minst 4–6 uker, lengre for produkter med lang vurderingssyklus, og ta høyde for post-treatment-vinduer.
Endringer i analyseplanen etterpå: Å endre analysemetodikk etter å ha sett foreløpige resultater introduserer bias og øker risikoen for falske positive. Tiltak: Forhåndsdefiner analysemetodikk, KPI-er og suksesskriterier før eksperimentstart.
Ignorering av eksterne sjokk: Naturkatastrofer, konkurrenttiltak, store nyhetshendelser og økonomiske skifter kan ugyldiggjøre resultater. Tiltak: Overvåk for forstyrrende hendelser gjennom hele testperioden og vær forberedt på å forlenge eller gjenta eksperimenter ved betydelige forstyrrelser.
For liten utvalgsstørrelse: For få regioner gir lav statistisk styrke og brede konfidensintervaller. Tiltak: Gjennomfør power-analyse på forhånd for å finne minimum antall regioner for forventet effektstørrelse.
Inkrementalitet representerer den reelle årsakseffekten av markedsføring – forskjellen mellom hva som faktisk skjedde og hva som ville skjedd uten tiltaket. Løft er det kvantitative målet på denne inkrementaliteten, beregnet som forskjellen i nøkkeltall mellom test- og kontrollgrupper. Hvis testregioner genererte 1 000 000 kr i omsetning mens matchede kontrollregioner genererte 900 000 kr, er det absolutte løftet 100 000 kr. Prosentvis løft vil være 11,1 % (100 000 / 900 000). Rå løft-tall tar imidlertid ikke hensyn til kostnaden ved markedsføringstiltaket. Inkrementell ROAS (iROAS) deler den inkrementelle inntekten på den inkrementelle utgiften, og viser avkastningen for hver ekstra investerte krone. Hvis testregionen brukte 50 000 kr ekstra på markedsføring for å generere 100 000 kr inkrementell inntekt, er iROAS 2,0x. På samme måte måler inkrementell CAC (iCAC) kostnaden for å verve hver inkrementelle kunde, noe som er avgjørende for å vurdere kanalens effektivitet. Disse målingene blir ekstra verdifulle når de kobles til merkevaresynlighetsmåling – å forstå ikke bare salgsøkning, men også hvordan markedsføringen påvirker AI-systemers siteringer og merkevareomtaler på tvers av GPT-er, Perplexity og Google AI Overviews.
Etter hvert som AI-systemer blir de viktigste oppdagelseskanalene for forbrukere, har det blitt avgjørende å måle hvordan markedsføring påvirker merkevarens synlighet i AI-svar. GEO-eksperimenter gir et robust rammeverk for å teste ulike innholdsstrategier og deres effekt på frekvens og nøyaktighet av AI-siteringer. Ved å gjennomføre eksperimenter hvor enkelte regioner får forbedret innholdsoptimalisering for AI-synlighet – forbedret strukturert data, tydeligere merkevarebudskap, optimaliserte innholdsformater – mens kontrollregioner beholder basispraksis, kan markedsførere kvantifisere den inkrementelle effekten på AI-omtaler. Dette er spesielt verdifullt for å forstå hvilke innholdsformater, budskapsmetoder og informasjonsstrukturer AI-systemer foretrekker når de siterer kilder. AmICited overvåker disse eksperimentene ved å spore hvor ofte din merkevare vises i AI-genererte svar på tvers av ulike geografiske regioner og tidsperioder, og gir datagrunnlaget for å måle synlighetsløft. Økningen i synlighet kan så kobles til forretningsresultater: viser regioner med høyere AI-siteringsfrekvens økt nettsidetrafikk, merkevaresøk eller konverteringer? Denne koblingen gjør AI-synlighet til en målbar driver for forretningsresultater – ikke bare en forfengelighetsmåling – og muliggjør trygg budsjettallokering til synlighetsfokuserte initiativer.
Utover enkel difference-in-differences-analyse har avanserte statistiske metoder kommet for å forbedre nøyaktighet og pålitelighet i GEO-eksperimenter. Syntetisk kontrollmetode konstruerer en vektet kombinasjon av kontrollregioner som best matcher forhåndsutviklingen til testregionene, og skaper et mer presist motfaktisk scenario enn noen enkelt kontrollregion kan gi. Denne tilnærmingen er spesielt kraftig når du har mange potensielle kontrollregioner og ønsker å utnytte all tilgjengelig informasjon. Bayesianske strukturelle tidsseriemodeller (BSTS), gjort populære av Googles CausalImpact-pakke, utvider syntetisk kontroll ved å inkludere usikkerhetskvantifisering og probabilistisk prognostisering. BSTS-modeller lærer det historiske forholdet mellom test- og kontrollregioner i forhåndsperioden, og prognostiserer deretter hvordan testregionen ville sett ut uten tiltak. Forskjellen mellom faktiske og prognostiserte verdier utgjør den estimerte behandlingseffekten, med sannsynlighetsintervaller som kvantifiserer usikkerheten. Difference-in-differences (DiD)-analyse sammenligner endringen i utfall før og etter behandling mellom test- og kontrollgrupper, og fjerner effektivt tidsinvariante forskjeller. Hver metode har sine fordeler og ulemper: syntetisk kontroll krever mange kontrollenheter, men forutsetter ikke parallelle trender; BSTS fanger opp komplekse tidsdynamikker, men krever nøye modellspesifikasjon; DiD er enkel og intuitiv, men sensitiv for brudd på antagelsen om parallelle trender. Moderne plattformer som Lifesight og Haus automatiserer disse metodene, slik at markedsførere kan dra nytte av avansert analyse uten statistisk ekspertise.
Ledende organisasjoner har vist styrken til GEO-eksperimenter gjennom imponerende resultater. Wayfair utviklet en heltallig optimaliseringstilnærming for å tildele hundrevis av geografiske enheter til test- og kontrollgrupper mens de balanserte nøyaktig på flere KPI-er samtidig, og muliggjorde mer følsomme eksperimenter med mindre holdout-andel. Polar Analytics’ analyse av hundrevis av geo-tester viste at syntetiske kontrollmetoder gir omtrent fire ganger mer presise resultater enn enkle matched market-tilnærminger, med smalere konfidensintervaller som gir tryggere beslutningsgrunnlag. Haus introduserte faste geo-tester spesielt utviklet for utendørs- og retailkampanjer, der markedsførere ikke kan tildele regioner tilfeldig, men må måle virkningen av forhåndsbestemte geografiske utrullinger. Deres casestudie med Jones Road Beauty viste hvordan faste geo-tester nøyaktig målte inkrementell effekt av billboardkampanjer i utvalgte markeder. Lifesights arbeid med store merkevarer innen retail, dagligvare og DTC viser at automatiserte geo-testingsplattformer kan redusere testvarighet fra 8–12 til 4–6 uker, samtidig som de forbedrer nøyaktighet gjennom avanserte matching-algoritmer. Disse casene viser at riktig utformede og gjennomførte GEO-eksperimenter ofte gir overraskende innsikt: kanaler antatt å være svært effektive viser ofte beskjeden økning, mens underinvesterte kanaler ofte gir sterk inkrementell avkastning – noe som gir store muligheter for budsjettomfordeling.
Å gjennomføre et vellykket GEO-eksperiment krever systematisk utførelse gjennom flere faser:
Definer klare mål og KPI-er: Identifiser hva du ønsker å måle (omsetning, konverteringer, merkevarebevissthet, AI-siteringer) og sett konkrete, målbare mål. Sikre samsvar med forretningsprioriteringer og realistiske forventninger til effektstørrelse.
Velg og match geografiske regioner: Velg regioner som representerer målmarkedet og har tilstrekkelig datavolum. Bruk matching-algoritmer for å finne kontrollregioner som ligner testregionene på historiske målinger.
Sikre datakvalitet: Kontroller at du nøyaktig kan spore KPI-ene i alle regioner gjennom hele testperioden. Gjennomfør datarevisjoner for kvalitet, fullstendighet og konsistens.
Design eksperimentparametere: Bestem testvarighet (minimum 4–6 uker), spesifiser markedsføringstiltaket presist, og dokumenter alle forutsetninger og suksesskriterier før start.
Kjør kampanjen samtidig: Start kampanjen i testregionene og oppretthold basisforhold i kontrollregionene samtidig. Koordiner på tvers av team for å sikre konsistent gjennomføring.
Overvåk underveis: Spor nøkkeltall daglig for å identifisere uventede mønstre, eksterne sjokk eller implementeringsproblemer som kan påvirke resultatene.
Samle inn og analyser data: Samle data fra alle regioner og bruk den forhåndsdefinerte analysemetodikken. Beregn løft, konfidensintervaller og sekundære målinger.
Tolk resultatene nøye: Vurder ikke bare statistisk, men også praktisk signifikans. Se på konfidensintervallbredde, effektstørrelse og forretningsmessig betydning når konklusjoner trekkes.
Dokumenter og del funn: Lag en grundig rapport som dokumenterer metode, resultater og læringspunkter. Del funnene med interessenter for å informere fremtidig strategi.
Planlegg neste eksperimenter: Bruk lærdommene til å informere neste testrunde og bygg en kontinuerlig eksperimenterings- og optimaliseringskultur.
Landskapet for GEO-eksperimentering har utviklet seg betydelig, med spesialiserte plattformer som nå automatiserer mye av kompleksiteten. Haus tilbyr GeoLift for standard randomiserte geo-tester og Fixed Geo Tests for forhåndsbestemte geografiske utrullinger, med særlig styrke innen omnichannel-måling. Lifesight gir ende-til-ende-automatisering fra design til analyse, med proprietære matching-algoritmer og syntetisk kontrollmetodikk som reduserer testvarighet samtidig som presisjonen øker. Polar Analytics fokuserer på inkrementalitetstesting med vekt på kausal løft-måling og nøyaktige konfidensintervaller. Paramark spesialiserer seg på markedsmikssmodellering forbedret med geo-eksperimentvalidering, og hjelper merkevarer å kalibrere MMM-forutsigelser mot reelle testresultater. Når du vurderer plattformer, se etter: automatisert regionmatching og balansering, støtte for både digitale og offline kanaler, sanntidsovervåking og mulighet for tidlig stopp, transparent metode- og konfidensintervallrapportering, og integrasjon med eksisterende datainfrastruktur. AmICited utfyller disse plattformene ved å levere synlighetsmålingslaget – sporing av hvordan merkevaren din vises i AI-genererte svar i test- og kontrollregioner slik at du kan måle økningen fra synlighetsfokuserte initiativer.
Vellykket GEO-eksperimentering forutsetter etterlevelse av dokumenterte beste praksiser som maksimerer pålitelighet og handlingskraft:
Start med klare hypoteser: Definer konkrete, testbare hypoteser før eksperimentstart. Unngå “fiskeekspedisjoner” der flere variabler testes uten tydelige forventninger.
Invester i god gruppering: Bruk tid på å sikre at test- og kontrollgrupper faktisk er sammenlignbare. Dårlig matching undergraver all videre analyse og sløser ressurser.
Kjør tester lenge nok: Motstå fristelsen til å stoppe tidlig når resultatene ser lovende ut. For tidlig stopp gir bias og øker risikoen for falske positive. Fullfør hele planlagte testperiode.
Overvåk for forstyrrende faktorer: Følg aktivt med på eksterne hendelser, konkurrenttiltak og markedsforhold under hele testen. Vær forberedt på å forlenge eller gjenta eksperimenter ved store forstyrrelser.
Dokumenter alt: Oppretthold grundige opptegnelser over eksperimentdesign, gjennomføring, analyser og resultater. Denne dokumentasjonen gjør læring, replikering og kunnskapsbygging mulig.
Bygg en testkultur: Gå utover enkeltstående eksperimenter og lag systematiske testprogrammer. Hvert eksperiment bør informere det neste, slik at du får en kontinuerlig lærings- og optimaliseringssyklus.
Koble til forretningsresultater: Sørg for at eksperimentene måler nøkkeltall som direkte påvirker forretningsmål. Unngå forfengelighetsmålinger som ikke gir verdi for omsetning eller strategi.
GEO-eksperimenter tester på geografisk/regionalt nivå for å måle økning av kampanjer som ikke kan testes på individnivå, mens A/B-tester randomiserer individuelle brukere for digital optimalisering. GEO-eksperimenter egner seg bedre for offline media, øvre-funnel kampanjer og for å måle reell årsakssammenheng, mens A/B-tester er best for å optimalisere digitale opplevelser med raskere resultater.
Vanligvis minimum 4–6 uker, men dette avhenger av konverteringssyklus og sesongvariasjoner. Lengre tester gir mer pålitelige resultater, men høyere kostnader. Testperioden bør være lang nok til å fange hele kundereisen og ta høyde for forsinkede konverteringseffekter.
Det finnes ingen fast minimum, men du trenger tilstrekkelig datavolum for å oppnå statistisk signifikans. Generelt trenger du nok regioner og transaksjoner til å oppdage forventet effektstørrelse med tilstrekkelig statistisk styrke (typisk 80 % eller høyere). Mindre markeder krever lengre testperioder.
Bruk geografiske grenser som minimerer krysskontaminering, vurder pendlermønstre og mediadekning, bruk geofencing-teknologi for presis kontroll, og velg regioner som er geografisk isolerte. Overløpseffekter oppstår når brukere eller medieeksponering krysser mellom test- og kontrollregioner, noe som utvanner resultatene.
Standard er 95 % konfidens (p < 0,05), noe som betyr at du kan være 95 % sikker på at den observerte effekten er reell og ikke tilfeldig. Vurder likevel forretningskonteksten – kostnadene ved falske positive kontra falske negative – når du bestemmer ditt konfidensnivå.
Ja, gjennom spørreundersøkelser, merkevareløftstudier og AI-siteringssporing. Du kan måle hvordan markedsføring påvirker merkevarebevissthet, preferanse og – viktigst – hvor ofte merkevaren din vises i AI-genererte svar på tvers av ulike regioner, slik at du kan måle økning i synlighet.
Naturkatastrofer, konkurrentkampanjer, store nyhetshendelser og økonomiske endringer kan ugyldiggjøre resultater ved å introdusere forstyrrende variabler. Overvåk dette gjennom hele testen og vær forberedt på å forlenge testperioden eller kjøre eksperimentet på nytt hvis betydelige forstyrrelser oppstår.
GEO-eksperimenter betaler seg vanligvis ved å hindre bortkastet bruk på ineffektive kanaler og muliggjøre trygg budsjettallokering til tiltak med høy ytelse. De gir fasit som forbedrer all videre måling og beslutningstaking, fra MMM-kalibrering til kanaloptimalisering.
GEO-eksperimenter avslører hvordan markedsføringen påvirker synlighet. AmICited sporer hvordan AI-systemer siterer merkevaren din på tvers av GPT-er, Perplexity og Google AI Overviews, og hjelper deg å måle den reelle økningen i synlighetsforbedringer.
Oppdag hvordan avansert geotargeting ser ut i moderne digital markedsføring. Lær om sofistikerte stedsbaserte strategier, atferdsmålretting og hvordan du implem...
Lær hvordan du måler effektiviteten av GEO-strategien din med AI-synlighetspoeng, attribusjonsfrekvens, engasjementsrater og geografisk ytelsesinnsikt. Oppdag e...
Diskusjon i fellesskapet om testing av hvor effektiv GEO-strategien er. Rammeverk og metoder for å måle om din Generative Engine Optimization-innsats faktisk fu...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.