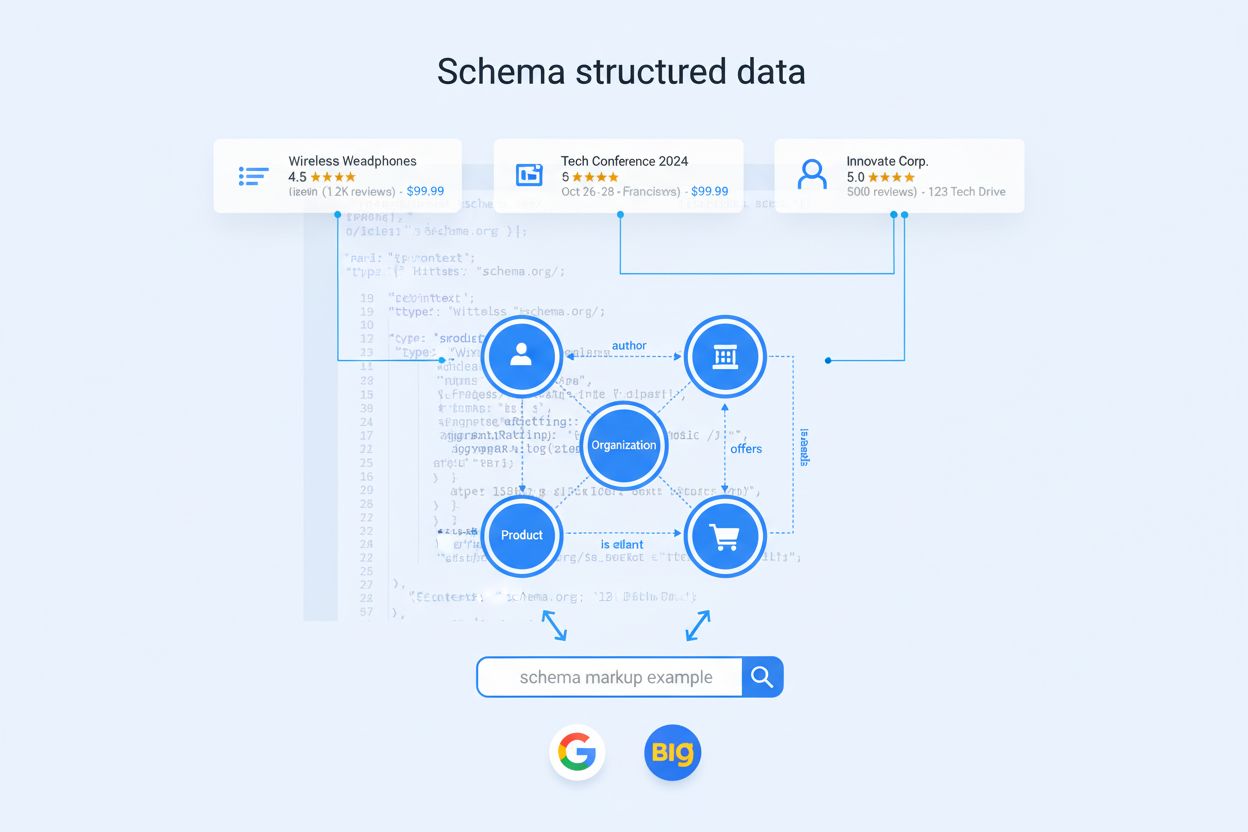
Schema Markup
Schema markup er standardisert kode som hjelper søkemotorer å forstå innhold. Lær hvordan strukturert data forbedrer SEO, muliggjør rike resultater og støtter A...
8 min lesing

Lær hvilke schema-typer som er viktigst for AI-synlighet. Oppdag hvordan LLM-er tolker strukturert data og implementer schema-strategier som får merkevaren din sitert i AI-svar.
I mange år handlet schema markup primært om å vinne rike resultater—de iøynefallende stjernerangeringene, produktkortene og FAQ-accordionene som dukket opp i tradisjonelle søkeresultater. I dag er denne oppskriften i ferd med å bli utdatert. Store språkmodeller og AI-svarmotorer tolker schema markup på fundamentalt andre måter, og bruker det ikke for kosmetiske forbedringer, men for å bygge kunnskapsgrafer og forstå entitetsrelasjoner i stor skala. Med omtrent 45 millioner nettsteder (12,4 % av alle registrerte domener) som nå implementerer en eller annen form for schema.org-markup, har AI-systemer tilgang til enestående mengder strukturert data å lære av og stole på. Skiftet er betydelig: schema markup påvirker nå om merkevaren din blir sitert i AI-genererte svar, hvor nøyaktig modeller representerer produktene og tjenestene dine, og om innholdet ditt blir en pålitelig kilde i et AI-først søkelandskap.
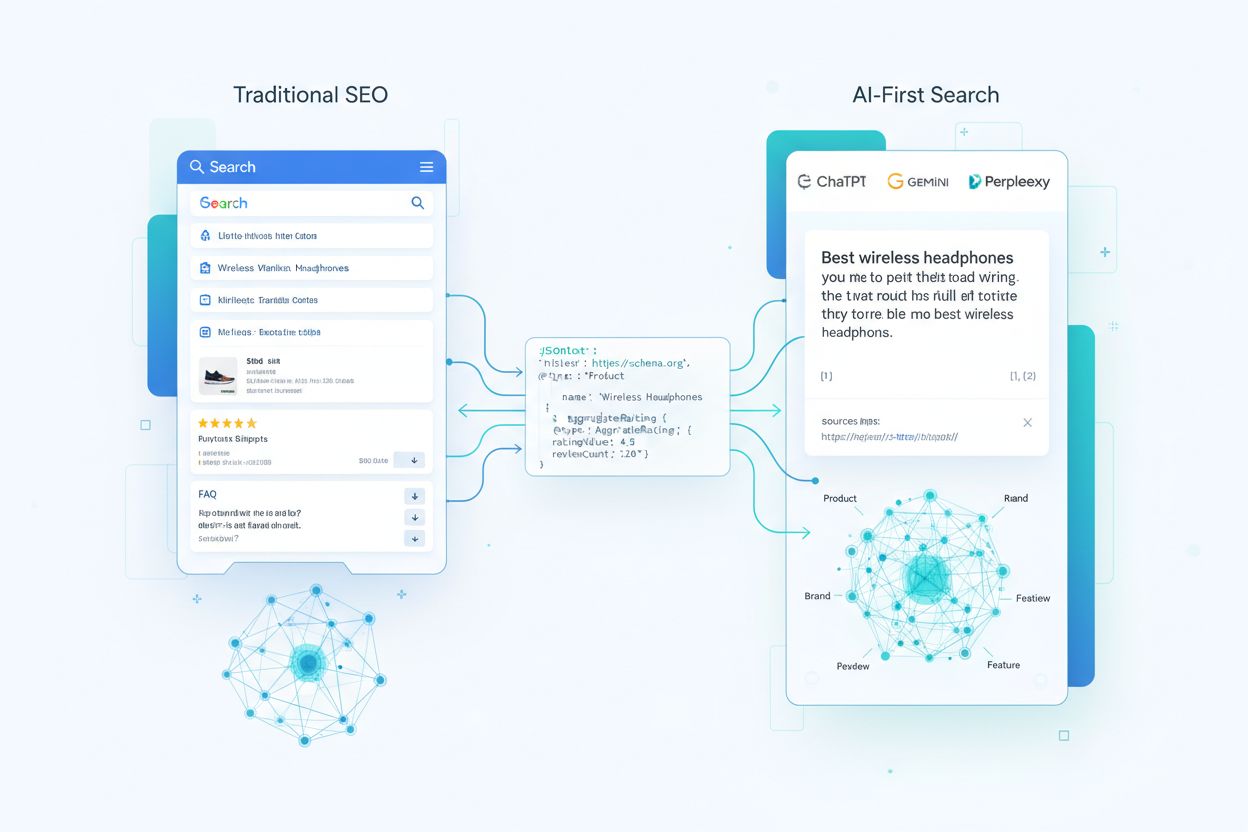
Å forstå hvordan AI-systemer konsumerer schema markup krever at man følger reisen til din strukturerte data fra første indeksering til LLM-genererte svar. Når en crawler besøker siden din, trekker den ut JSON-LD-, microdata- eller RDFa-blokker og normaliserer dem i en indeks sammen med ustrukturert tekst og media. Denne strukturerte dataen blir en del av en kunnskapsgraf i webskala, hvor entiteter kobles gjennom relasjoner og får embeddings for semantisk søk. I retrieval-augmented generation (RAG)-systemer kan schema flettes direkte inn i segmentene som fyller vektorindekser—ett segment kan inneholde både en produktbeskrivelse og dens JSON-LD-markup, og gir modeller både narrativ kontekst og strukturerte nøkkel-verdi-attributter. Ulike LLM-arkitekturer konsumerer schema forskjellig: noen legger modeller oppå eksisterende søkeindekser og kunnskapsgrafer, mens andre bruker multi-source henterør som trekker fra både strukturert og ustrukturert innhold. Det viktigste poenget er at velimplementert schema fungerer som en kontrakt med modellen, og sier i høyt strukturert form hvilke fakta på siden din du anser som kanoniske og pålitelige.
| Arkitekturstype | Bruk av schema | Siteringspåvirkning | Nøkkelattributter |
|---|---|---|---|
| Tradisjonelt søk + LLM-lag | Forbedrer eksisterende kunnskapsgraf | Høy – modeller siterer godt strukturerte kilder | Organization, Product, Article |
| Retrieval-Augmented Generation | Flettes inn i vektorsegmenter | Medium-Høy – schema hjelper med presisjon | Alle typer med detaljerte attributter |
| Multi-Source svarmotorer | Brukes for entitetsløsning | Medium – konkurrerer med andre signaler | Person, LocalBusiness, Service |
| Konversasjonell AI | Støtter kontekstforståelse | Variabel – avhenger av treningsdata | FAQPage, HowTo, BlogPosting |
Ikke alle schema-typer veier like tungt i AI-æraen. Organization-markup fungerer som ankeret for hele din entitetsgraf og hjelper modeller med å forstå merkevareidentitet, autoritet og relasjoner. Product-schema er essensielt for e-handel og detaljhandel, og gjør det mulig for AI-systemer å sammenligne funksjoner, priser og vurderinger på tvers av kilder. Article- og BlogPosting-markup hjelper modeller med å identifisere langtidsinnhold egnet for forklarende søk og tankelederskap. Person-schema er kritisk for å etablere forfattertroverdighet og ekspertattributtering i AI-genererte svar. FAQPage-markup samsvarer direkte med konversasjonelle søk som AI-assistenter er designet for å besvare. For SaaS- og B2B-selskaper er SoftwareApplication- og Service-typene like viktige, og dukker ofte opp i “beste verktøy for X”-sammenligninger og evalueringer. For lokale virksomheter og helseaktører gir LocalBusiness- og MedicalOrganization-typene geografisk presisjon og regulatorisk klarhet. Den virkelige forskjellen oppnås imidlertid ikke gjennom grunnleggende typebruk, men med avanserte attributter du legger oppå—konsistens på tvers av sider, tydelige entitetsidentifikatorer og eksplisitt relasjonskartlegging.
Grunnleggende schema-attributter som name, description og URL er nå forventet; 72,6 % av sidene som rangerer på Googles førsteside bruker allerede en form for schema markup. Attributtene som virkelig skaper forskjell for AI-synlighet er det forbindende vevet som hjelper modeller å løse entiteter, forstå relasjoner og avklare betydning. Her er de avanserte attributtene som betyr mest:
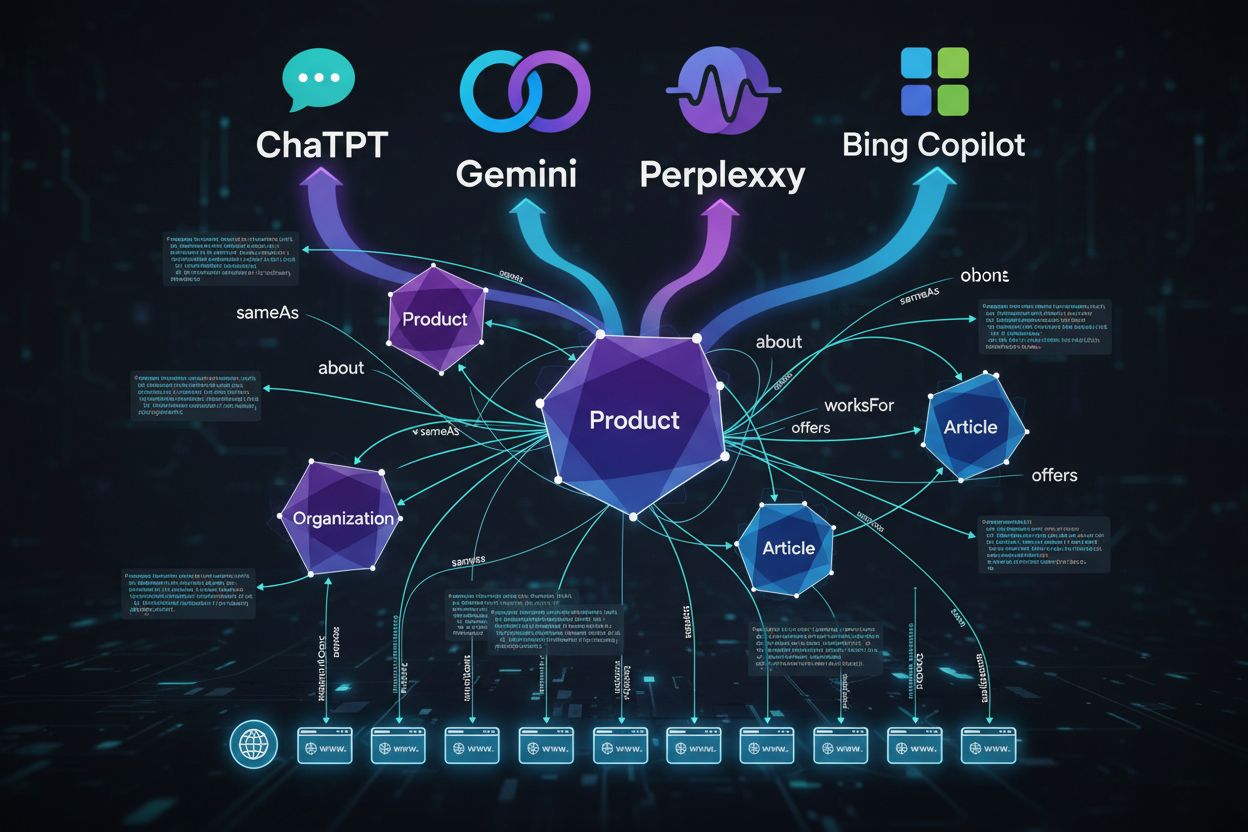
Disse attributtene forvandler schema fra en enkel databeholder til et semantisk kart modeller kan navigere trygt. Når du bruker sameAs for å knytte organisasjonen til Wikipedia-siden sin, legger du ikke bare til metadata—du forteller modellen “dette er den autoritative kilden for fakta om oss.” Når du bruker additionalProperty for å kode produktspecifikasjoner eller tjenestefunksjoner, gir du de nøyaktige attributtene AI-systemer ser etter når de setter sammen sammenligninger eller anbefalinger.
De fleste organisasjoner ser på schema markup som en engangsoppgave, men konkurransefortrinn i AI-drevet søk krever at du tenker på det som en pågående datastyringsdisiplin. En nyttig modell er et fire-nivås modningsrammeverk som hjelper team å forstå hvor de er og hvor de skal:
Nivå 1 – Grunnleggende schema for rike resultater fokuserer på minimal markup på utvalgte maler, hovedsakelig for å bli kvalifisert for stjerner, produktkort eller FAQ-snutter. Styring er løs, konsistensen lav, og målet er kosmetisk forbedring heller enn semantisk klarhet.
Nivå 2 – Entitets-sentrisk dekning standardiserer Organization-, Product-, Article- og Person-markup på nøkkelmaler, innfører konsekvent bruk av @id-verdier og legger til grunnleggende sameAs-lenker for å forhindre entitetsforveksling.
Nivå 3 – Kunnskapsgraf-integrert schema tilpasser schema-ID-er til interne datamodeller (CMS, PIM, CRM), bruker utstrakt omfang av about/mentions/additionalType-attributter og koder relasjoner på tvers av sider slik at modeller forstår hvordan innholdsnode henger sammen med hverandre og eksterne entiteter.
Nivå 4 – LLM-optimalisert & RAG-tilpasset schema strukturerer markup bevisst for konversasjonelle søk og AI-snuttformater, tilpasser schema til interne RAG-rør, og inkluderer måling og iterasjon som kjernepraksiser.
De fleste merkevarer stopper per i dag på nivå 1–2, hvilket betyr at grunnleggende bruk nå er hygiene, ikke et konkurransefortrinn. Å rykke opp til nivå 3–4 er der schema-LLM-optimalisering blir en varig konkurransebarriere, fordi modeller da pålitelig kan tolke entiteter på tvers av mange spørsmålsformuleringer og flater.
Ulike bransjer har ulike entiteter, risikoprofiler og brukerintensjoner, så avansert schema-bruk kan ikke være likt for alle. De grunnleggende prinsippene—entitetsklaring, relasjonsmodellering og samsvar med innhold på siden—er konstante, men schema-typene og -attributtene du fremhever bør reflektere hvordan folk faktisk søker i din sektor.
For e-handel og detaljhandel er de primære entitetene Product, Offer, Review og Organization. Hver produktside med høy intensjon bør vise detaljert Product-markup som inkluderer identifikatorer (SKU, GTIN), merke, modell, dimensjoner, materialer og differensierende attributter via additionalProperty. Kombiner dette med Offer som koder pris og tilgjengelighet, og AggregateRating-strukturer som gjør det lett for modeller å forstå sosialt bevis. Utover det grunnleggende, tenk på hvordan kjøpere stiller spørsmål: “Er dette vanntett?” “Følger det med garanti?” “Hva er returpolicyen?” Å kode disse svarene som FAQPage-markup på samme URL og sørge for at Product-attributter og FAQ-innhold er synkronisert gjør det mye enklere for svarmotorer å sitere riktig side.
For SaaS og B2B-tjenester er entitetene mer abstrakte, men passer godt til SoftwareApplication-, Service- og Organization-schema. For hvert kjerneprodukt eller tilbud, definer et SoftwareApplication- eller Service-entitet med klare beskrivelser av kategori, støttede plattformer, integrasjoner og prismodeller, og bruk additionalProperty-felt for å liste opp funksjoner som ofte dukker opp i “beste verktøy for X”-sammenligninger. Koble disse til Organization via provider- eller offers-relasjoner, og til ekspertene dine via Person-markup. På innholdssiden hjelper Article, BlogPosting, FAQPage og HowTo-strukturer LLM-er å finne dine beste ressurser for vurderende og forklarende søk.
For lokale aktører, helsevesen og regulerte bransjer kan LocalBusiness-, MedicalOrganization- og beslektede MedicalEntity-typer kode adresser, tjenesteområder, spesialiteter, akseptert forsikring og åpningstider langt mindre tvetydig enn fritekst. Dette er avgjørende når en AI-assistent blir bedt om å “finne barnekardiolog i nærheten som tar min forsikring” eller “anbefale legevakt som er åpen nå.” Vær spesielt nøye med at schema ikke overdriver eller eksponerer sensitive detaljer—merk bare opp fakta du er komfortabel med å få gjenbrukt i mange sammenhenger, og sørg for at juridisk og compliance gjennomgår medisinske eller regulerte attributter.
LLM-adferd er iboende stokastisk, så du vil ikke oppnå pikselperfekt attribusjon fra schema-endringer alene. Det du kan gjøre, er å bygge et lett overvåkningssystem som prøvetar AI-svar jevnlig for et definert sett med søk. Følg med på hvilke entiteter som nevnes, hvilke URL-er som siteres, hvordan merkevaren din beskrives, og om nøkkelfakta (priser, egenskaper, compliance-detaljer) er korrekte på tvers av ChatGPT, Gemini, Perplexity og Bing Copilot. Når noe går galt—hallusinerte funksjoner, manglende omtaler eller sitater som favoriserer aggregatorer fremfor dine hovedsider—start med å sjekke for motstridende eller ufullstendige signaler. Sier teksten på siden noe annet enn schema? Mangler sameAs-lenker eller peker de til utdaterte profiler? Hevder flere sider å være kanonisk kilde for samme entitet? Strategisk sett bør du planlegge schema-gjennomgang minst kvartalsvis i tråd med nye tilbud, innholdsklynger og endringer i hvordan AI-svarmotorer løfter frem merkevaren din.
Flere mønstre undergraver jevnlig effekten av schema for AI-systemer. Å merke opp innhold som ikke faktisk er synlig på siden skaper en tillitskløft—modeller lærer å overse kilder hvor schema og synlig innhold ikke stemmer overens. Bruk av altfor generiske typer uten spesifisitet (f.eks. å merke alt som “Thing” eller “CreativeWork”) gir ingen semantisk signal; modeller trenger presise typer for å forstå kontekst. Å kopiere standardisert schema mellom sider uten å oppdatere entitetsdetaljer er kanskje den vanligste feilen—når hver produktside har identisk Organization-markup eller hver artikkel hevder samme forfatter, får modellene problemer med å skille innholdet og kan nedprioritere det som lav-signal. Inkonsistente entitetsidentifikatorer på tvers av sider (ulike @id for samme organisasjon eller produkt) bryter entitetsoppløsning og får modeller til å behandle relaterte sider som separate entiteter. Manglende sameAs-lenker til autoritative profiler gjør det lettere for modeller å forveksle merkevaren din med navnebrødre. Endelig, motstridende informasjon mellom schema og tekst på siden signaliserer upålitelighet; hvis schema sier et produkt er på lager men teksten sier “utsolgt”, vil modeller stole på ingen av kildene.
Schema markup er i ferd med å gå fra å være et kosmetisk SEO-grep til å bli en grunnleggende teknologi for AI-først-søk. Sammenkoblet schema markup—der du eksplisitt definerer relasjoner mellom entiteter med egenskaper som sameAs, about og mentions—bygger kunnskapsgrafer AI-systemer kan navigere sikkert. Konkurransefortrinnet tilfaller ikke lenger de som spør “Hvilket minimums-schema trenger vi for rike resultater?” men de som spør “Hvilken strukturert representasjon gjør innholdet vårt entydig for maskiner, også utenfor SERP?” Dette skiftet driver organisasjoner mot mer komplette, sammenkoblede og entitets-sentriske schema-mønstre. Etter hvert som AI-drevet søk blir en primær kanal for oppdagelse, utvikler schema-LLM-optimalisering seg fra en teknisk kuriositet til en sentral SEO-disiplin. Organisasjoner som avanserer gjennom modenhetsnivåene—fra grunnleggende schema for rike resultater til kunnskapsgraf-integrerte og LLM-optimaliserte mønstre—vil bygge varige barrierer i AI-drevet synlighet, sikre at merkevarene deres siteres som autoriteter og at innholdet deres blir vist som pålitelige kilder.
Tradisjonell schema fokuserte på rike resultater (stjerner, snippets). For AI handler schema om entitetsklaring, relasjoner og kunnskapsgrafer. AI-systemer bruker schema for å forstå hva innholdet ditt handler om på et semantisk nivå, ikke bare for visuelle forbedringer.
Organization, Product, Article, Person og FAQPage er grunnleggende. For SaaS, legg til SoftwareApplication og Service. For lokale/helsetjenester, legg til LocalBusiness og MedicalOrganization. Viktigheten varierer etter bransje og brukerintensjon.
Nei. Start med Organization og dine mest verdifulle sider (produkter, tjenester, nøkkelartikler). Utvid dekningen gradvis basert på forretningsmodellen din og hvor AI-svar vil være mest verdifulle.
Endringer i schema kan påvirke AI-sitater i løpet av noen uker, men sammenhengen er probabilistisk. Planlegg kvartalsvise gjennomganger og kontinuerlig overvåkning på tvers av flere AI-plattformer for å følge med på effekten.
sameAs knytter din entitet til kanoniske profiler (Wikipedia, LinkedIn) for å forhindre forveksling med navnebrødre. about/mentions tydeliggjør hva siden din egentlig fokuserer på, og hjelper modellene å forstå nyanser og kontekst.
Nei. Schema fungerer best sammen med høykvalitets, godt strukturert innhold på siden. Modeller trenger både strukturert data og narrativ kontekst for å trygt sitere sidene dine.
Overvåk AI-svar på tvers av plattformer (ChatGPT, Gemini, Perplexity, Bing) for dine målrettede søk. Følg med på enhetsomtaler, URL-sitater, faktanøyaktighet og merkevarebeskrivelser. Se etter trender over uker/måneder.
JSON-LD er det anbefalte formatet for de fleste bruksområder. Det er enklere å implementere, vedlikeholde og forstyrrer ikke HTML. Microdata og RDFa er mindre vanlig i moderne implementasjoner.
Følg med på hvordan AI-systemer siterer merkevaren din i ChatGPT, Gemini, Perplexity og Google AI Overviews. Få innsikt i hvilke schema-typer som driver synligheten.
Schema markup er standardisert kode som hjelper søkemotorer å forstå innhold. Lær hvordan strukturert data forbedrer SEO, muliggjør rike resultater og støtter A...

Diskusjon i fellesskapet om schema markup for AI-synlighet. Ekte erfaringer fra utviklere og SEOs om hvilke typer strukturert data som forbedrer AI-sitater.
Lær hvordan du validerer schema markup og strukturert data ved hjelp av Google-verktøy, Schema.org-validatorer og beste praksis. Sørg for at din JSON-LD er mask...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.