Stack Overflow og AI-sitater: Synlighet i det tekniske fellesskapet
Oppdag hvordan Stack Overflow-innhold former AI-svar, og lær strategier for å maksimere din utviklersynlighet i ChatGPT, Gemini og andre AI-plattformer.
Publisert den Jan 3, 2026.Sist endret den Jan 3, 2026 kl. 3:24 am
Stack Overflows 50 millioner spørsmål og svar har blitt en hjørnestein i utviklingen av store språkmodeller. Store AI-selskaper som OpenAI, Google og Meta har inkorporert Stack Overflow-data i sine treningsdatasett fordi utviklerkunnskap representerer noe av det mest høyverdige, fagfellevurderte tekniske innholdet på internett. Utvikling av avanserte AI-systemer koster flere hundre millioner dollar, og mye av denne kostnaden går til anskaffelse og behandling av treningsdata. Historisk sett har AI-selskaper hentet disse dataene gratis, men Stack Overflows CEO Prashanth Chandrasekar kunngjorde i 2023 at plattformen ville begynne å ta betalt fra store AI-utviklere for tilgang til innholdet, i erkjennelse av at kunnskap generert av fellesskapet bør kompenseres. Dette skiftet gjenspeiler en bredere bransjetrend der plattformer med verdifulle data krever rettferdig kompensasjon fra selskaper som tjener penger på innholdet deres.
Attribusjon og Creative Commons-lisensiering
Stack Overflow-innhold er lisensiert under Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), som juridisk krever at alle som bruker innholdet gir attribusjon til de opprinnelige forfatterne. Denne lisensieringsrammen er ikke-forhandlingsbar for Stack Overflow, da plattformen mener attribusjon er grunnlaget for utviklernes tillit til AI-generert innhold. Når AI-selskaper trener modeller på Stack Overflow-data uten korrekt attribusjon, bryter de teknisk sett Creative Commons-lisensen, og derfor krever Stack Overflow nå at alle API-partnere inkluderer attribusjonskrav i sine kontrakter. Viktigheten av dette kan ikke understrekes nok: Ifølge Stack Overflow Developer Survey 2024 oppgir 65% av utviklere at manglende eller feil attribusjon er en av de største etiske bekymringene med AI-verktøy.
Aspekt
Krav
Påvirkning
Lisens
CC BY-SA 4.0
Attribusjon påkrevd
Utviklertillit
72% positiv
Kritisk for adopsjon
AI-etterlevelse
RAG-implementering
Sikrer korrekt kildebruk
Siteringsrate
65% bekymret
Topp etisk problem
Innholdseierskap
Brukerbeholdt
Fellesskapsvern
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Stack Overflows tilnærming til AI-lisensiering skiller mellom gratis og kommersiell bruk. Plattformen fortsetter å tilby gratis tilgang til sitt API og data-dumps for ikke-kommersielle formål, utdanningsbruk og open source-prosjekter, og opprettholder sin forpliktelse til utviklerfellesskapet. Selskaper som utvikler store språkmodeller for kommersiell bruk må imidlertid fremforhandle lisensavtaler med Stack Overflow, der prisen baseres på faktorer som modellstørrelse, bruksmengde og genererte inntekter. Stack Overflow-sjef Chandrasekar har understreket at selskapet kun søker kompensasjon fra organisasjoner som utvikler LLM-er for “store, kommersielle formål”, ikke fra enkeltutviklere eller små prosjekter. Denne dobbelte lisensmodellen gjør det mulig for Stack Overflow å skape nye inntektsstrømmer samtidig som interessene til fellesskapsmedlemmene – som ofte bidrar uten forventning om direkte betaling – ivaretas. Selskapet har også forpliktet seg til å reinvestere lisensinntektene i fellesskapsverktøy og funksjoner, og skaper en bærekraftig modell der utviklernes bidrag direkte finansierer forbedringer av plattformen.
Utviklersynlighet i AI-søkeresultater
Stack Overflow-innhold vises nå tydelig i AI-genererte svar på store plattformer som ChatGPT, Google Gemini, Perplexity og Microsoft Copilot. Googles Gemini Cloud Assist attribuerer eksplisitt Stack Overflow-svar når de gir kodeforslag, og viser det opprinnelige spørsmålet, svaret og forfatterinformasjon direkte i AI-svaret. OpenAIs ChatGPT viser Stack Overflow-lenker i samtaler om kode, og SearchGPT – OpenAIs søkeprototyp – inkluderer Stack Overflow-resultater både i samtalesvar og i søkeresultater. Denne synligheten er avgjørende for utviklere fordi det gir trafikk tilbake til deres svar og etablerer dem som anerkjente eksperter på sitt felt. Likevel gir ikke alle AI-plattformer lik attribusjon, og utviklere sliter ofte med å forstå hvilke av deres svar som blir sitert, hvor ofte og i hvilken sammenheng på tvers av ulike AI-systemer.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Tillitskrisen i AI-generert innhold
Stack Overflow Developer Survey 2024 viser en økende avstand mellom AI-adopsjon og tillit: Mens 76% av utviklere bruker eller planlegger å bruke AI-verktøy (opp fra 70% i 2023), har AIs popularitet falt fra 77% til 72%. Bare 43% av utviklere stoler på nøyaktigheten til AI-verktøy, og undersøkelsen identifiserte tre kritiske etiske bekymringer som utviklere prioriterer:
Risiko for feilinformasjon: 79% av utviklere er bekymret for at AI kan spre feilinformasjon
Attribusjon og kreditering: 65% er bekymret for manglende eller feil attribusjon for datakilder
Skjevhet og representasjon: 50% er bekymret for skjevhet som ikke representerer mangfoldige synspunkter
Dette tillitsunderskuddet påvirker direkte hvordan AI-selskaper tilnærmer seg datainnhenting og modelltrening. Utviklere krever i økende grad at AI-systemer siterer kildene sine, anerkjenner fellesskapsbidrag og opprettholder nøyaktighetsstandarder som gjenspeiler det fagfellevurderte innholdet på Stack Overflow. Presset for å bygge pålitelige AI-systemer har ført til økt fokus på innhenting av treningsdata av høy kvalitet, noe som gjør Stack Overflows verifiserte, fellesskapskuraterte kunnskap mer verdifull enn noen gang.
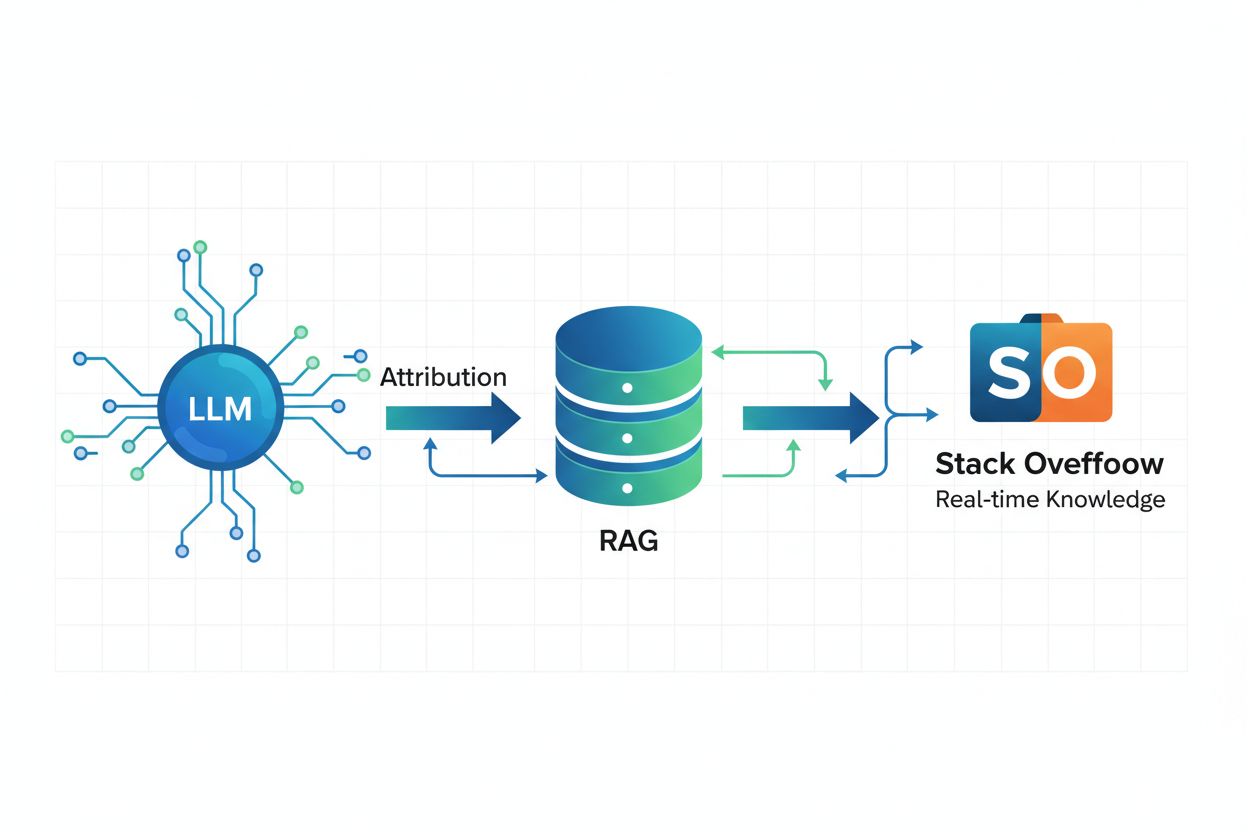
Retrieval Augmented Generation (RAG) og attribusjon
Retrieval Augmented Generation (RAG) er et AI-rammeverk som kombinerer store språkmodeller med tradisjonelle informasjonshentingssystemer for å levere aktuelle, nøyaktige og korrekt attribuerte svar. I stedet for å bare basere seg på treningsdata frosset til et bestemt tidspunkt, lar RAG AI-systemer hente sanntidsinformasjon fra eksterne kilder som Stack Overflow, slik at svarene gjenspeiler den nyeste kunnskapen og beste praksis. Alle Stack Overflows OverflowAPI-partnere har implementert RAG for å muliggjøre korrekt attribusjon, noe som betyr at når et AI-system genererer et svar basert på Stack Overflow-innhold, kan det identifisere og sitere de spesifikke innleggene som har påvirket svaret. Denne teknologien er spesielt kraftig for domenespesifikk kunnskap der nøyaktighet og aktualitet er viktig – for eksempel ved å be et AI-system skrive C#-kode basert på spesifikke eksempler fra din kodebase, sikres det at den genererte koden følger teamets standarder og konvensjoner. RAG reduserer risikoen for hallusinasjoner ved å forankre AI-svar i pålitelige, verifiserte fakta som brukerne selv identifiserer, og utgjør dermed det tekniske grunnlaget for ansvarlig AI-utvikling.
Overvåk din utviklersynlighet
Utviklere som bidrar til Stack Overflow bør aktivt overvåke hvordan innholdet deres vises i AI-genererte svar på ulike plattformer. Verktøy som AmICited.com, XFunnel, Profound og andre tilbyr nå synlighetssporing spesielt utviklet for å vise utviklere hvor deres svar blir sitert, hvor ofte og i hvilken sammenheng på tvers av ChatGPT, Gemini, Perplexity og andre AI-systemer. Viktige måleparametere å følge med på inkluderer siteringsfrekvens (hvor ofte innholdet ditt blir referert til), sentiment (om omtalen er positiv eller nøytral), plattformfordeling (hvilke AI-systemer siterer deg mest) og kildeattribusjon (om korrekt kreditering gis). Ved å følge med på disse målene kan utviklere identifisere hvilke av svarene deres som gir størst verdi til AI-systemene, forstå hvilke temaer som er mest etterspurt, og justere bidragsstrategien sin deretter. I tillegg hjelper overvåking av synlighet utviklere å oppdage unøyaktige eller ufullstendige siteringer, slik at de kan oppdatere sine opprinnelige svar eller kontakte AI-selskaper for å be om rettelser. Denne proaktive tilnærmingen gjør passiv innholdsproduksjon om til en aktiv strategi for å bygge autoritet og innflytelse i det AI-drevne informasjonsøkosystemet.
Beste praksis for fellesskapstilstedeværelse
For å maksimere synligheten i AI-søkeresultater og sikre at dine Stack Overflow-bidrag blir korrekt sitert, bør du fokusere på å lage omfattende, godt dokumenterte svar som dekker hele spørsmålet med tydelige forklaringer og fungerende kodeeksempler. Hold svarene dine oppdaterte ved å gjennomgå og oppdatere dem jevnlig etter hvert som teknologier utvikler seg, siden AI-systemer prioriterer ferskere innhold – i gjennomsnitt er innhold som siteres i AI-resultater 25,7% ferskere enn det som rangeres i Google. Bygg autoritet ved å levere svar av høy kvalitet innen flere relaterte temaer, da utviklere i topp 25% for nettomtale får 10x flere AI-siteringer enn andre. Delta aktivt i det bredere utviklerfellesskapet ved å delta i diskusjoner, svare på oppfølgingsspørsmål og hjelpe andre medlemmer å forbedre sine bidrag. Til slutt: vurder hvordan dine svar kan brukes av AI-systemer – strukturer svarene med klare overskrifter, inkluder relevante kodebiter og gi kontekst for når og hvorfor bestemte tilnærminger er hensiktsmessige, slik at innholdet ditt blir nyttig både for menneskelige lesere og AI-systemer som må hente ut og tilskrive informasjon nøyaktig.
Vanlige spørsmål
Hvordan brukes Stack Overflow-data i AI-trening?
Stack Overflows 50 millioner spørsmål og svar blir inkludert i store språkmodeller fordi de representerer teknisk innhold av høy kvalitet, vurdert av jevnaldrende. AI-selskaper som OpenAI, Google og Meta bruker disse dataene for å trene modellene sine til å forstå og generere kode og tekniske løsninger bedre. Historisk sett ble disse dataene hentet gratis, men Stack Overflow krever nå at kommersielle AI-utviklere lisensierer dataene gjennom betalte avtaler.
Hva er forskjellen mellom gratis og betalt Stack Overflow API-tilgang?
Stack Overflow tilbyr gratis API-tilgang for ikke-kommersielle formål, utdanningsbruk og open source-prosjekter. Selskaper som utvikler store språkmodeller for kommersiell bruk må imidlertid fremforhandle betalte lisensavtaler. Prisen baseres på faktorer som modellens omfang, bruksmengde og inntekter, slik at fellesskapsbidrag blir riktig kompensert.
Hvordan kan jeg sikre at mine Stack Overflow-svar blir sitert av AI?
Lag omfattende, godt dokumenterte svar med tydelige forklaringer og fungerende kodeeksempler. Hold svarene dine oppdaterte etter hvert som teknologier utvikler seg, siden AI-systemer prioriterer ferskere innhold. Bygg autoritet ved å levere svar av høy kvalitet innen flere temaer, og strukturer svarene dine med klare overskrifter og relevante kodebiter som AI-systemer enkelt kan hente ut og tilskrive.
Hva er RAG, og hvorfor er det viktig for attribusjon?
Retrieval Augmented Generation (RAG) er et AI-rammeverk som kombinerer språkmodeller med informasjonshentingssystemer for å gi aktuelle, nøyaktige og korrekt attribuerte svar. RAG lar AI-systemer hente sanntidsinformasjon fra kilder som Stack Overflow og sitere de spesifikke innleggene som har påvirket svaret, noe som sikrer korrekt attribusjon og reduserer risikoen for hallusinasjoner.
Hvordan overvåker jeg min synlighet i AI-søkeresultater?
Verktøy som AmICited.com, XFunnel, Profound og andre tilbyr synlighetssporing spesielt utviklet for å vise utviklere hvor deres svar blir sitert på tvers av ChatGPT, Gemini, Perplexity og andre AI-systemer. Disse verktøyene sporer siteringsfrekvens, sentiment, plattformfordeling og kildeattribusjon, og hjelper deg å forstå hvilke av svarene dine som gir mest verdi til AI-systemene.
Hva er de etiske bekymringene ved at AI bruker innhold fra fellesskapet?
Ifølge Stack Overflow Developer Survey 2024 har utviklere tre hovedetiske bekymringer: risiko for feilinformasjon (79% bekymret), manglende eller feil attribusjon (65% bekymret) og skjevhet som ikke representerer mangfoldige synspunkter (50% bekymret). Disse bekymringene understreker behovet for riktig lisensiering, attribusjonskrav og opplæringsdata av høy kvalitet fra verifiserte kilder som Stack Overflow.
Hvordan beskytter Stack Overflows lisensiering utviklere?
Stack Overflow-innhold er lisensiert under Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), som juridisk krever at alle som bruker innholdet gir attribusjon til opprinnelige forfattere. Stack Overflow krever nå at alle API-partnere inkluderer attribusjonskrav i sine kontrakter, slik at utviklere får riktig kreditering når AI-systemer bruker deres svar.
Hvilke verktøy kan jeg bruke for å spore AI-siteringer av mitt innhold?
Flere verktøy er tilgjengelige for å spore AI-siteringer, inkludert AmICited.com (spesialisert på AI-overvåking), XFunnel (enterprise LLM-overvåking), Profound (avansert GEO-sporing), Semrush AI Toolkit, BrightEdge og andre. Disse verktøyene hjelper deg å se hvilke AI-plattformer som siterer deg, hvor ofte, i hvilken sammenheng og om korrekt attribusjon er gitt.
Overvåk din Stack Overflow-synlighet i AI-søk
Følg med på hvordan din tekniske ekspertise blir sitert på tvers av ChatGPT, Gemini, Perplexity og andre AI-plattformer. Få innsikt i sanntid om din utviklersynlighet og optimaliser din tilstedeværelse i fellesskapet.
Wikipedias rolle i AI-treningsdata: Kvalitet, betydning og lisensiering
Oppdag hvordan Wikipedia fungerer som et kritisk AI-treningsdatasett, hvilken betydning den har for modellnøyaktighet, lisensavtaler og hvorfor AI-selskaper er ...
Kan du faktisk påvirke hva KI lærer om merkevaren din under trening? Er dette i det hele tatt mulig?
Diskusjon i fellesskapet om å påvirke KI-treningsdata om merkevaren din. Ekte innsikt i hvordan innholdsproduksjon påvirker hva KI-systemer lærer og husker om s...
Kontroll over AI-treningsdata: Hvem eier innholdet ditt?
Utforsk det komplekse juridiske landskapet rundt eierskap til AI-treningsdata. Lær hvem som kontrollerer innholdet ditt, opphavsrettslige implikasjoner og hvilk...
7 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.