
Token
Lær hva tokens er i språkmodeller. Tokens er grunnleggende enheter for tekstbehandling i AI-systemer, og representerer ord, delord eller tegn som numeriske verd...
10 min lesing

Utforsk hvordan tokenbegrensninger påvirker AI-ytelse og lær praktiske strategier for innholdsoptimalisering, inkludert RAG, chunking og oppsummeringsteknikker.
Tokens er de grunnleggende byggeklossene som AI-modeller bruker for å behandle og forstå informasjon. I stedet for å jobbe med hele ord eller setninger, bryter store språkmodeller opp teksten i mindre enheter kalt tokens, som kan være individuelle tegn, delord eller hele ord avhengig av tokeniseringsalgoritmen. Hver token får en unik numerisk identifikator som modellen bruker internt for beregning. Denne tokeniseringsprosessen er essensiell fordi den gjør det mulig for AI-systemer å håndtere inndata med variabel lengde effektivt og opprettholde konsistent behandling på tvers av ulike innholdstyper. Å forstå tokens er avgjørende for alle som jobber med AI-systemer, siden de direkte påvirker ytelse, kostnad og kvaliteten på resultatene du kan oppnå.
Forskjellige AI-modeller har svært ulike tokenbegrensninger, som definerer hvor mye informasjon de kan behandle i én enkelt forespørsel. Disse grensene har utviklet seg dramatisk de siste årene, der nyere modeller støtter betydelig større kontekstvinduer. Tokenbegrensningen omfatter både input-tokens (prompten og dataene dine) og output-tokens (modellens svar), og skaper et delt budsjett som må håndteres nøye. Å forstå disse grensene er viktig for å velge riktig modell til ditt bruk, og for å planlegge applikasjonsarkitekturen din deretter.
| Modell | Tokenbegrensning | Primær bruk | Kostnadsnivå |
|---|---|---|---|
| GPT-3.5 Turbo | 4 096 | Korte samtaler, raske oppgaver | Lav |
| GPT-4 | 8 192 | Standardapplikasjoner, moderat kompleksitet | Middels |
| GPT-4 Turbo | 128 000 | Lange dokumenter, kompleks analyse | Høy |
| Claude 3.5 Sonnet | 200 000 | Utvidede dokumenter, omfattende analyse | Høy |
| Gemini 1.5 Pro | 1 000 000 | Massive datasett, hele bøker, videoanalyse | Svært høy |
Viktige hensyn når du vurderer tokenbegrensninger:
Tokenbegrensninger skaper betydelige begrensninger som direkte påvirker nøyaktighet, pålitelighet og kostnadseffektivitet i AI-applikasjoner. Hvis du overskrider modellens tokenbegrensning, feiler applikasjonen fullstendig—det finnes ingen gradvis forringelse eller delvis behandling. Selv innenfor grensene kan naive tilnærminger som enkel trunkering alvorlig redusere ytelsen ved å fjerne kritisk kontekst som modellen trenger for å generere nøyaktige svar. Dette er spesielt problematisk innenfor områder som juridisk analyse, medisinsk forskning og programvareutvikling, hvor det å gå glipp av én viktig detalj kan føre til feil konklusjoner. Utfordringen blir enda mer kompleks når du vurderer at ulike innholdstyper bruker tokens i ulikt tempo—strukturert data som kode eller JSON krever betydelig flere tokens enn vanlig engelsk tekst på grunn av symboler og formatering.
Trunkering er den enkleste metoden for å håndtere tokenbegrensninger—du kutter rett og slett av overflødig innhold når det overskrider modellens kapasitet. Selv om det er lett å implementere, innebærer denne tilnærmingen store risikoer. Når du trimmer bort tekst, mister du uunngåelig informasjon, og modellen har ingen måte å vite hva som er fjernet. Dette kan føre til ufullstendig analyse, manglende kontekst og hallusinasjoner der modellen fyller hullene i forståelsen med plausible, men feilaktige opplysninger.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
En mer sofistikert trunkeringsstrategi skiller mellom essensielt og valgfritt innhold. Du kan prioritere nødvendige elementer som brukerens nåværende spørsmål og kjerneinstruksjoner, og deretter legge til valgfri kontekst som samtalehistorikk bare hvis det er plass. Denne tilnærmingen bevarer kritisk informasjon og respekterer samtidig tokenbegrensningene.
I stedet for å trunkere, deler chunking innholdet ditt i mindre, håndterbare deler som kan behandles uavhengig eller selektivt. Fast chunking deler tekst i jevne segmenter, mens semantisk chunking bruker embeddinger for å identifisere naturlige delingspunkter basert på mening i stedet for vilkårlige tokenantall. Glidende vinduer med overlapp bevarer kontekst mellom chunkene, slik at viktig informasjon som går over chunkgrenser ikke går tapt.
Hierarkisk chunking lager flere abstraksjonsnivåer—enkeltavsnitt på det laveste nivået, seksjoner på neste og kapitler på det høyeste nivået. Denne tilnærmingen muliggjør avanserte hentingsstrategier der du raskt kan identifisere relevante seksjoner uten å behandle hele dokumentet. Kombinert med vektordatabaser og semantisk søk blir chunking et kraftig verktøy for å håndtere store kunnskapsbaser samtidig som relevans og nøyaktighet beholdes.
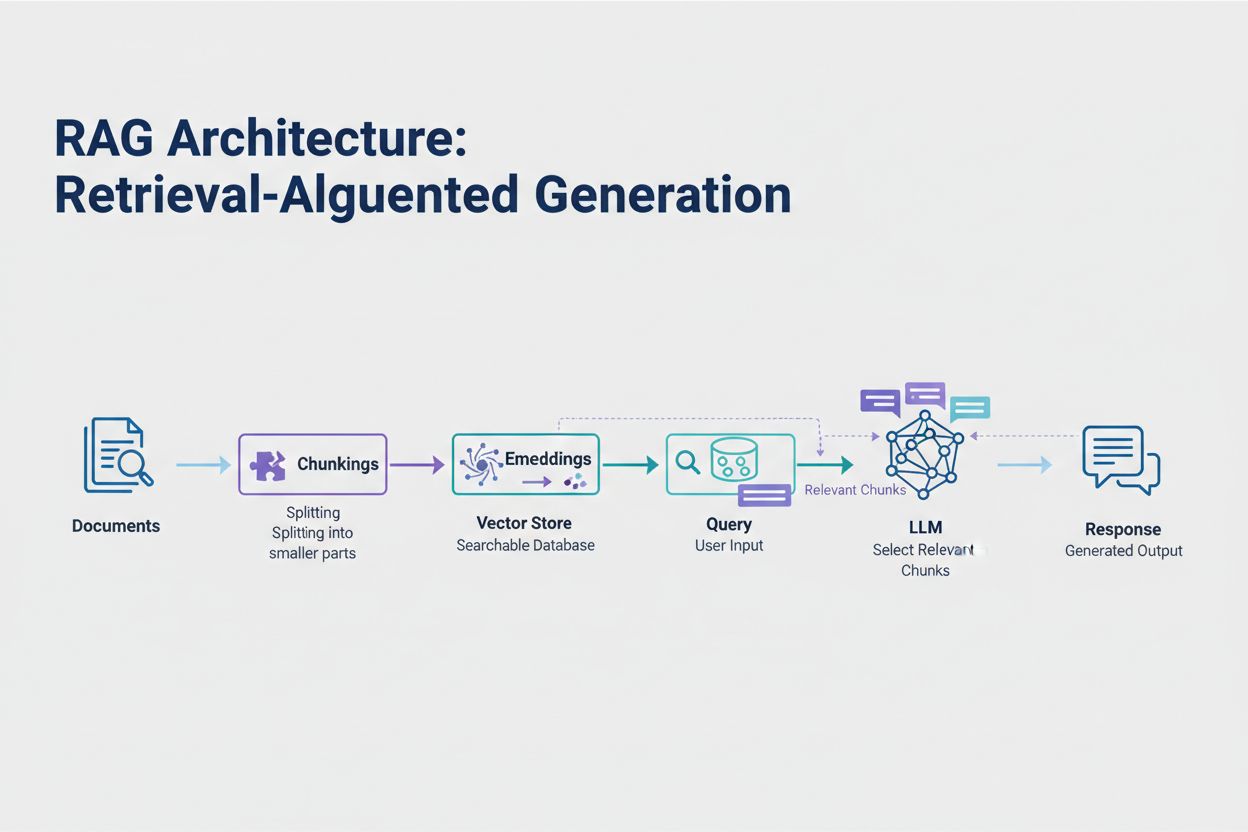
Retrieval-Augmented Generation (RAG) representerer den mest effektive moderne tilnærmingen til håndtering av tokenbegrensninger. I stedet for å forsøke å få plass til alle dataene dine i modellens kontekstvindu, henter RAG kun den mest relevante informasjonen ved spørring. Prosessen starter med å konvertere dokumentene dine til embeddinger—numeriske representasjoner som fanger semantisk mening. Disse embeddingene lagres i en vektordatabse, som gjør raske likhetssøk mulig.
Når en bruker sender inn en forespørsel, embeddes spørringen og de mest relevante dokumentchunkene hentes fra vektorbasen. Bare disse relevante bitene settes inn i prompten sammen med brukerens spørsmål, noe som dramatisk reduserer tokenforbruket og forbedrer nøyaktigheten. For eksempel kan analyse av en 100-siders juridisk kontrakt med RAG kreve bare 3-5 nøkkelparagrafer i prompten, sammenlignet med tusenvis av tokens for hele dokumentet.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Oppsummering kondenserer langt innhold samtidig som essensiell informasjon bevares, og reduserer effektivt tokenforbruket. Ekstraktiv oppsummering velger ut nøkkelsetninger fra originalteksten, mens abstraktiv oppsummering genererer ny, konsis tekst som fanger hovedpoengene. Hierarkisk oppsummering lager flere nivåer med sammendrag—først oppsummeres individuelle seksjoner, deretter kombineres disse til overordnede sammendrag. Denne tilnærmingen fungerer spesielt godt for strukturerte dokumenter som forskningsartikler eller tekniske rapporter.
Kontekstkomprimering tar en annen tilnærming ved å fjerne gjentakelser og fyllinnhold samtidig som den opprinnelige formuleringen beholdes. Kunnskapsgrafer trekker ut entiteter og relasjoner fra tekst, og rekonstruerer så konteksten med bare de mest relevante fakta. Slike teknikker kan gi 40–60 % reduksjon i tokens samtidig som semantisk nøyaktighet beholdes, noe som er verdifullt for kostnadsoptimalisering i produksjonssystemer.
Tokenhåndtering påvirker direkte kostnadene for AI-applikasjonen din. Hver token som brukes under inferens koster penger, og kostnadene øker proporsjonalt med tokenforbruket. Overvåking av tokenforbruk er essensielt for å forstå kostnadsstrukturen din og finne optimaliseringsmuligheter. Mange AI-plattformer tilbyr nå verktøy for telling av tokens og sanntidsdashbord som følger bruksmønstre og hjelper deg å identifisere hvilke forespørsler eller funksjoner som bruker flest tokens.
Effektiv overvåking avdekker optimaliseringsmuligheter—kanskje visse typer forespørsler konsekvent overskrider tokenbegrensningene, eller bestemte funksjoner bruker uforholdsmessig mye ressurser. Ved å følge disse mønstrene kan du ta informerte valg om hvilken optimaliseringsstrategi du skal implementere. Noen applikasjoner har nytte av å sende store forespørsler til mer kapable (men dyrere) modeller, mens andre har større utbytte av å implementere RAG eller oppsummering. Nøkkelen er å måle faktisk ytelse og kostnader for å validere valgene dine.
Valg av riktig strategi for tokenhåndtering avhenger av ditt spesifikke brukstilfelle, ytelseskrav og kostnadsbegrensninger. Applikasjoner som krever høy nøyaktighet med kildebaserte svar har størst nytte av RAG, som bevarer informasjonskvalitet samtidig som tokenforbruket styres. Langvarige samtaleapplikasjoner har nytte av minnebufferteknikker som oppsummerer samtalehistorikken og bevarer viktige beslutninger og kontekst. Dokumenttunge applikasjoner som juridisk analyse eller forskning har ofte fordel av hierarkisk oppsummering kombinert med semantisk chunking.
Testing og validering er kritisk før du ruller ut en strategi for tokenhåndtering i produksjon. Lag testtilfeller som overskrider modellens tokenbegrensning, og evaluer deretter hvordan ulike strategier påvirker nøyaktighet, latenstid og kostnad. Mål metrikker som svarrelevans, faktisk nøyaktighet og tokeneffektivitet for å sikre at valgt tilnærming møter kravene dine. Vanlige fallgruver inkluderer for aggressiv oppsummering som mister viktige detaljer, hentesystemer som overser relevant informasjon, og chunking-strategier som bryter innhold på semantisk upassende steder.
Tokenbegrensningene fortsetter å vokse etter hvert som modellene blir mer avanserte og effektive. Nye teknikker som sparse attention-mekanismer og effektive transformatorer lover å redusere de beregningsmessige kostnadene ved å behandle store kontekstvinduer. Multimodale modeller som håndterer tekst, bilder, lyd og video samtidig, introduserer nye utfordringer og muligheter for tokenisering. Resoneringstokens—spesielle tokens brukt av modeller for å “tenke gjennom” komplekse problemer—representerer en ny kategori for tokenbruk som muliggjør mer avansert problemløsning, men krever nøye håndtering.
Retningen er tydelig: Etter hvert som kontekstvinduer vokser og tokenprosessering blir mer effektiv, flyttes flaskehalsen fra rå kapasitet til intelligent utvelgelse av innhold. Fremtiden tilhører systemer som effektivt kan identifisere og hente ut den mest relevante informasjonen fra massive kunnskapsbaser, ikke systemer som bare prosesserer større datamengder. Dette gjør teknikker som RAG og semantisk søk stadig viktigere for å bygge skalerbare og kostnadseffektive AI-applikasjoner.
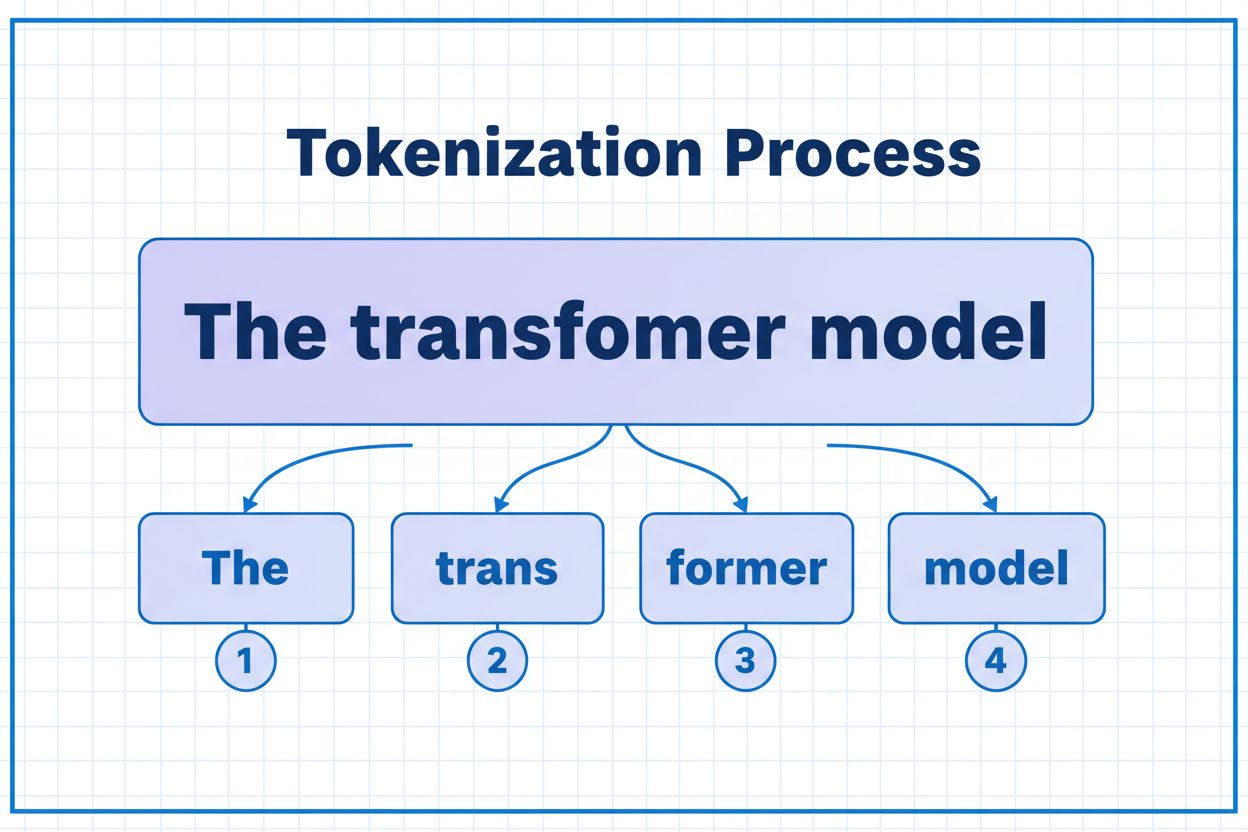
En token er den minste datainheten som en AI-modell behandler. Tokens kan være individuelle tegn, delord eller hele ord avhengig av tokeniseringsalgoritmen. For eksempel kan ordet 'transformer' deles opp i 'trans' og 'former' som to separate tokens. Hver token får en unik numerisk identifikator som modellen bruker internt for beregninger.
Tokenbegrensninger definerer hvor mye informasjon AI-modellen din kan behandle i én forespørsel. Hvis du overskrider denne grensen, feiler applikasjonen fullstendig. Selv innenfor grensene kan naive tilnærminger som trunkering redusere nøyaktigheten ved å fjerne kritisk kontekst. Tokenbegrensninger påvirker dessuten kostnadene direkte, siden du vanligvis betaler per token som forbrukes.
Input-tokens er tokens i prompten og dataene du sender til modellen, mens output-tokens er tokens modellen genererer i sitt svar. Disse deler et felles budsjett definert av modellens kontekstvindu. Hvis inputen din bruker 90% av et 128K token-vindu, har du bare 10% igjen til modellens output.
Trunkering er enkelt å implementere, men risikabelt. Det fjerner informasjon uten at modellen vet hva som gikk tapt, noe som kan føre til ufullstendig analyse og mulige hallusinasjoner. Selv om det kan være nyttig som siste utvei, er bedre tilnærminger som RAG, chunking eller oppsummering mer effektive for å bevare informasjonskvalitet og håndtere tokenbruk.
Retrieval-Augmented Generation (RAG) henter bare den mest relevante informasjonen ved spørring i stedet for å inkludere hele dokumenter. Dokumentene dine konverteres til embeddinger og lagres i en vektordatabse. Når en bruker spør, hentes kun relevante biter som settes inn i prompten, noe som dramatisk reduserer tokenforbruket og forbedrer nøyaktigheten.
De fleste AI-plattformer tilbyr verktøy for telling av tokens og sanntidsdashbord for å følge med på bruksmønstre. Overvåk hvilke forespørsler eller funksjoner som bruker flest tokens, og implementer deretter optimaliseringsstrategier som RAG for dokumenttunge applikasjoner, oppsummering for lange samtaler, eller ruting til større modeller for komplekse oppgaver. Mål faktisk ytelse og kostnader for å validere valgene dine.
AI-tjenester tar vanligvis betalt per token som brukes. Kostnader øker proporsjonalt med tokenforbruk, så optimalisering av tokens påvirker utgiftene dine direkte. En reduksjon på 20% i tokenforbruk betyr 20% lavere kostnader. Forståelse av tokeneffektivitet hjelper deg å velge riktig optimaliseringsstrategi innenfor budsjettet ditt.
Tokenbegrensningene fortsetter å øke etter hvert som modellene blir mer avanserte. Nye teknikker som sparse attention-mekanismer lover å redusere de beregningsmessige kostnadene ved å behandle store kontekster. Fremtiden vil handle mer om intelligent utvelgelse og henting av innhold enn rå prosesseringskapasitet, noe som gjør teknikker som RAG stadig viktigere for skalerbare AI-applikasjoner.
Forstå tokeneffektivitet og følg med på hvordan AI-modeller siterer merkevaren din med AmICiteds omfattende plattform for AI-sitasjonsovervåking.
Lær hva tokens er i språkmodeller. Tokens er grunnleggende enheter for tekstbehandling i AI-systemer, og representerer ord, delord eller tegn som numeriske verd...

Lær hvordan AI-modeller behandler tekst gjennom tokenisering, embedding, transformerblokker og nevrale nettverk. Forstå hele prosessen fra inn-data til ut-data....
Lær essensielle strategier for å optimalisere støtteinnholdet ditt for AI-systemer som ChatGPT, Perplexity og Google AI Overviews. Oppdag beste praksis for klar...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.