
Hvordan identifisere AI-crawlere i serverloggene dine
Lær å identifisere og overvåke AI-crawlere som GPTBot, ClaudeBot og PerplexityBot i serverloggene dine. Komplett guide med user-agent-strenger, IP-verifisering ...
8 min lesing

Lær hvordan du sporer og overvåker AI-crawleraktivitet på nettstedet ditt ved hjelp av serverlogger, verktøy og beste praksis. Identifiser GPTBot, ClaudeBot og andre AI-boter.
Kunstig intelligens-boter står nå for over 51 % av den globale internett-trafikken, men de fleste nettstedeiere aner ikke at de får tilgang til innholdet deres. Tradisjonelle analyseverktøy som Google Analytics fanger ikke opp disse besøkende fordi AI-crawlere bevisst unngår å utløse JavaScript-basert sporingskode. Serverlogger fanger opp 100 % av bot-forespørsler, og er dermed den eneste pålitelige kilden for å forstå hvordan AI-systemer samhandler med siden din. Å forstå bot-adferd er kritisk for AI-synlighet, for hvis AI-crawlere ikke får tilgang til innholdet ditt på riktig måte, vil det ikke vises i AI-genererte svar når potensielle kunder stiller relevante spørsmål.

AI-crawlere oppfører seg fundamentalt annerledes enn tradisjonelle søkemotorboter. Mens Googlebot følger XML-sitemapet ditt, respekterer robots.txt-regler og crawler jevnlig for å oppdatere søkeindekser, kan AI-boter ignorere standardprotokoller, besøke sider for å trene språkmodeller og bruke egne identifikatorer. Store AI-crawlere inkluderer GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Googles AI-treningsbot), Bingbot-AI (Microsoft) og Applebot-Extended (Apple). Disse botene fokuserer på innhold som hjelper å svare på brukerspørsmål fremfor bare rangeringssignaler, noe som gjør crawl-mønstrene deres uforutsigbare og ofte aggressive. Å forstå hvilke boter som besøker siden din og hvordan de oppfører seg, er avgjørende for å optimalisere innholdsstrategien din for AI-tiden.
| Crawler-type | Typisk RPS | Adferd | Formål |
|---|---|---|---|
| Googlebot | 1-5 | Jevn, respekterer crawl-delay | Søkeindeksering |
| GPTBot | 5-50 | Burst-mønstre, høyt volum | AI-modelltrening |
| ClaudeBot | 3-30 | Målrettet innholdstilgang | AI-trening |
| PerplexityBot | 2-20 | Selektiv crawling | AI-søk |
| Google-Extended | 5-40 | Aggressiv, AI-fokusert | Google AI-trening |
Webserveren din (Apache, Nginx eller IIS) genererer automatisk logger som registrerer alle forespørsler til nettstedet ditt, inkludert de fra AI-boter. Disse loggene inneholder viktig informasjon: IP-adresser som viser forespørselsopprinnelse, user agents som identifiserer programvaren som gjør forespørselen, tidsstempler for når forespørselen skjedde, forespurte URL-er som viser tilgang til innhold og responskoder som indikerer serverens svar. Du kan få tilgang til logger via FTP eller SSH ved å koble deg til webhotellet og navigere til loggmappen (vanligvis /var/log/apache2/ for Apache eller /var/log/nginx/ for Nginx). Hver loggpost følger et standardformat som viser nøyaktig hva som skjedde under hver forespørsel.
Her er et eksempel på en loggpost med feltforklaringer:
192.168.1.100 - - [01/Jan/2025:12:00:00 +0000] "GET /blog/ai-crawlers HTTP/1.1" 200 5432 "-" "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"
IP-adresse: 192.168.1.100
User Agent: GPTBot/1.0 (identifiserer boten)
Tidsstempel: 01/Jan/2025:12:00:00
Forespørsel: GET /blog/ai-crawlers (siden som er besøkt)
Statuskode: 200 (vellykket forespørsel)
Responsstørrelse: 5432 bytes
Den enkleste måten å identifisere AI-boter på, er å søke etter kjente user agent-strenger i loggene. Vanlige user agent-signaturer for AI-boter inkluderer “GPTBot” for OpenAI sin crawler, “ClaudeBot” for Anthropics crawler, “PerplexityBot” for Perplexity AI, “Google-Extended” for Googles AI-treningsbot, og “Bingbot-AI” for Microsofts AI-crawler. Noen AI-boter identifiserer seg imidlertid ikke tydelig, noe som gjør dem vanskeligere å oppdage med enkle user agent-søk. Du kan bruke kommandolinjeverktøy som grep for raskt å finne bestemte boter: grep "GPTBot" access.log | wc -l teller alle GPTBot-forespørsler, mens grep "GPTBot" access.log > gptbot_requests.log lager en egen fil for analyse.
Kjente user agents for AI-boter å overvåke:
Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)Mozilla/5.0 (compatible; PerplexityBot/1.0; +https://www.perplexity.ai/bot)Mozilla/5.0 (compatible; Google-Extended; +https://www.google.com/bot.html)Mozilla/5.0 (compatible; Bingbot-AI/1.0)For boter som ikke identifiserer seg tydelig, bruk IP-ryktetjenester ved å kryssjekke IP-adresser mot publiserte områder fra store AI-selskaper.
Å overvåke de rette måleparametrene avslører botens hensikter og hjelper deg å optimalisere nettstedet deretter. Forespørselsrate (målt i forespørsler per sekund eller RPS) viser hvor aggressivt en bot crawler siden din—sunne crawlere holder seg til 1-5 RPS, mens aggressive AI-boter kan nå 50+ RPS. Ressursforbruk er viktig fordi en enkelt AI-bot kan bruke mer båndbredde på én dag enn hele den menneskelige brukerbasen din til sammen. Fordelingen av HTTP-statuskoder viser hvordan serveren svarer på botforespørsler: høye prosenter av 200 (OK) indikerer vellykket crawling, mens hyppige 404 antyder at boten følger ødelagte lenker eller leter etter skjulte ressurser. Crawl-frekvens og -mønstre viser om botene er jevnlige besøkende eller “burst-and-pause”-typer, mens geografisk opprinnelsessporing viser om forespørslene kommer fra legitim selskapsinfrastruktur eller mistenkelige steder.
| Måleparameter | Betydning | Sunt nivå | Varsellamper |
|---|---|---|---|
| Forespørsler/time | Botaktivitetens intensitet | 100-1000 | 5000+ |
| Båndbredde (MB/time) | Ressursforbruk | 50-500 | 5000+ |
| 200 Statuskoder | Vellykkede forespørsler | 70-90% | <50% |
| 404 Statuskoder | Brutte lenker besøkt | <10% | >30% |
| Crawl-frekvens | Hvor ofte boten besøker | Daglig-ukentlig | Flere ganger/time |
| Geografisk konsentrasjon | Forespørselsopprinnelse | Kjente datasentre | Bredbåndsleverandører (privat) |
Du har flere alternativer for å overvåke AI-crawleraktivitet, fra gratis kommandolinjeverktøy til bedriftsplattformer. Kommandolinjeverktøy som grep, awk og sed er gratis og kraftige for små til mellomstore nettsteder, og lar deg trekke ut mønstre fra logger på sekunder. Kommersiell plattformer som Botify, Conductor og seoClarity tilbyr sofistikerte funksjoner, inkludert automatisk bot-identifisering, visuelle dashbord og korrelasjon med rangeringer og trafikkdata. Logganalyseverktøy som Screaming Frog Log File Analyser og OnCrawl gir spesialiserte funksjoner for å behandle store loggfiler og identifisere crawl-mønstre. AI-drevne analyseplattformer bruker maskinlæring for automatisk å identifisere nye bot-typer, forutsi adferd og oppdage avvik uten manuell konfigurasjon.
| Verktøy | Kostnad | Funksjoner | Best egnet for |
|---|---|---|---|
| grep/awk/sed | Gratis | Kommandolinjemønster-søk | Tekniske brukere, små nettsteder |
| Botify | Bedrift | AI-botsporing, ytelseskorrelasjon | Store nettsteder, detaljert analyse |
| Conductor | Bedrift | Sanntidsovervåking, AI-crawleraktivitet | SEO-team i bedrifter |
| seoClarity | Bedrift | Loggfilanalyse, AI-botsporing | Omfattende SEO-plattformer |
| Screaming Frog | $199/år | Loggfilanalyse, crawlsimulering | Tekniske SEO-spesialister |
| OnCrawl | Bedrift | Skybasert analyse, ytelsesdata | Mellomstore til store virksomheter |
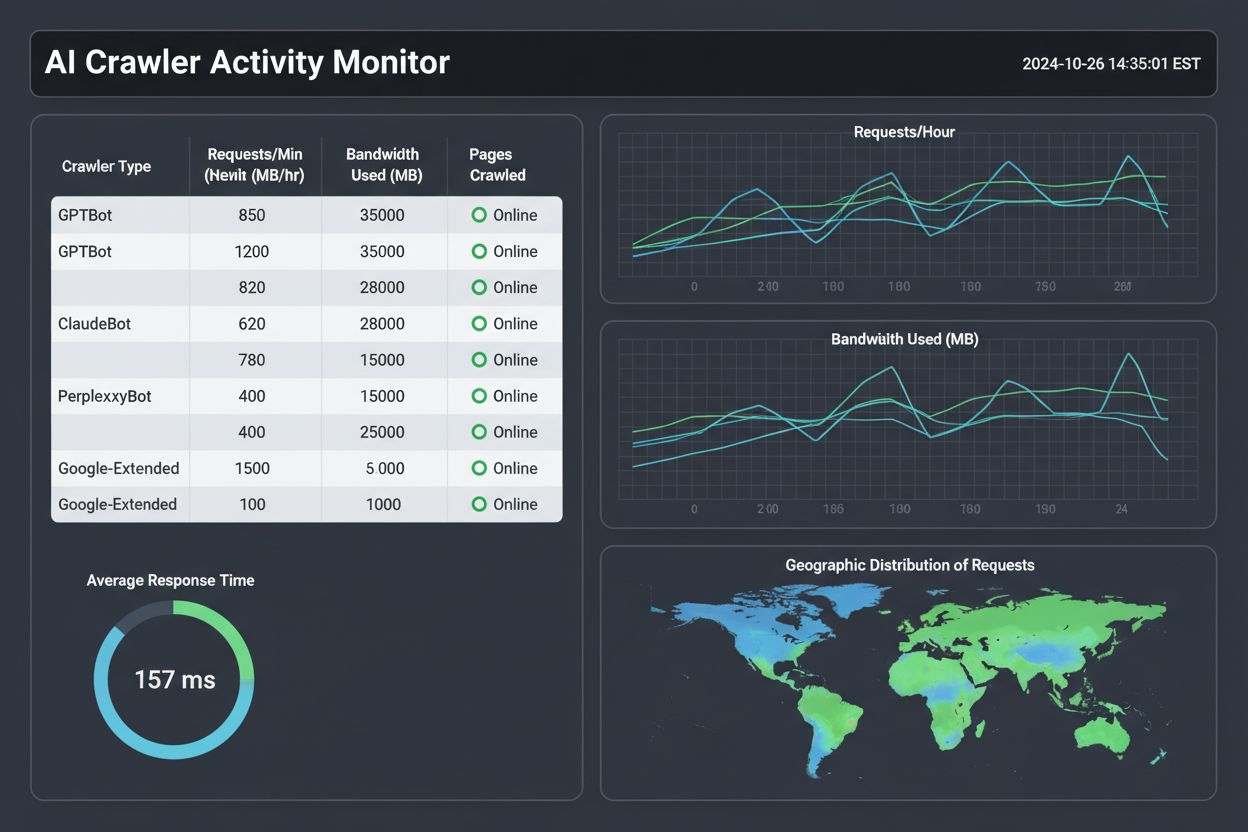
Å etablere grunnleggende crawl-mønstre er første steg mot effektiv overvåking. Samle minst to ukers loggdata (helst en måned) for å forstå normal bot-adferd før du trekker konklusjoner om avvik. Sett opp automatisert overvåking ved å lage skript som kjøres daglig for å analysere logger og generere rapporter, for eksempel med Python og pandas-biblioteket eller enkle bash-skript. Opprett varsler for uvanlig aktivitet, som plutselige topper i forespørselsrater, nye bott-typer eller boter som får tilgang til begrensede ressurser. Planlegg regelmessige logganmeldelser—ukentlig for trafikksterke nettsteder for tidlig avdekking av problemer, månedlig for mindre nettsteder for å oppdage trender.
Her er et enkelt bash-skript for kontinuerlig overvåking:
#!/bin/bash
# Daglig rapport om AI-botaktivitet
LOG_FILE="/var/log/nginx/access.log"
REPORT_FILE="/reports/bot_activity_$(date +%Y%m%d).txt"
echo "=== AI-botaktivitet rapport ===" > $REPORT_FILE
echo "Dato: $(date)" >> $REPORT_FILE
echo "" >> $REPORT_FILE
echo "GPTBot-forespørsler:" >> $REPORT_FILE
grep "GPTBot" $LOG_FILE | wc -l >> $REPORT_FILE
echo "ClaudeBot-forespørsler:" >> $REPORT_FILE
grep "ClaudeBot" $LOG_FILE | wc -l >> $REPORT_FILE
echo "PerplexityBot-forespørsler:" >> $REPORT_FILE
grep "PerplexityBot" $LOG_FILE | wc -l >> $REPORT_FILE
# Send varsel ved uvanlig aktivitet
GPTBOT_COUNT=$(grep "GPTBot" $LOG_FILE | wc -l)
if [ $GPTBOT_COUNT -gt 10000 ]; then
echo "VARSEL: Uvanlig GPTBot-aktivitet oppdaget!" | mail -s "Bot Alert" admin@example.com
fi
Robots.txt-filen din er første forsvarslinje for å kontrollere AI-bottilgang, og store AI-selskaper respekterer spesifikke direktiver for treningsbotene sine. Du kan lage egne regler for ulike bot-typer—gi Googlebot full tilgang, mens du begrenser GPTBot til bestemte seksjoner eller setter crawl-delay-verdier for å begrense forespørselsraten. Ratebegrensning sikrer at botene ikke overbelaster infrastrukturen din ved å implementere grenser på flere nivåer: per IP-adresse, per user agent og per ressurstype. Når en bot overskrider grensene, returner en 429 (Too Many Requests) med Retry-After-header; veloppdragne boter vil respektere dette og roe ned, mens scrapers vil ignorere det og bør IP-blokkeres.
Her er robots.txt-eksempler for å administrere AI-crawler-tilgang:
# Tillat søkemotorer, begrens AI-treningsboter
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Disallow: /private/
Disallow: /proprietary-content/
Crawl-delay: 1
User-agent: ClaudeBot
Disallow: /admin/
Crawl-delay: 2
User-agent: *
Disallow: /
Den nye LLMs.txt-standarden gir ytterligere kontroll ved å la deg kommunisere preferanser til AI-crawlere i et strukturert format, lik robots.txt, men spesielt utviklet for AI-applikasjoner.
Å gjøre nettstedet ditt vennlig for AI-crawlere forbedrer hvordan innholdet ditt vises i AI-genererte svar og sikrer at botene får tilgang til de mest verdifulle sidene dine. Tydelig nettstedstruktur med konsistent navigasjon, sterk intern lenking og logisk innholdsorganisering hjelper AI-boter å forstå og navigere innholdet effektivt. Implementer schema-markup med JSON-LD-format for å klargjøre innholdstype, nøkkelinformasjon, relasjoner mellom innholdselementer og virksomhetsdetaljer—dette hjelper AI-systemer å tolke og sitere innholdet ditt korrekt. Sørg for raske innlastingstider for å unngå timeout for boter, oppretthold mobiltilpasset design som fungerer for alle bot-typer, og lag innhold av høy kvalitet og originalitet som AI-systemer kan sitere nøyaktig.
Beste praksis for AI-crawleroptimalisering:
Mange nettstedeiere gjør kritiske feil når de administrerer AI-crawler-tilgang, noe som undergraver AI-synlighetsstrategien deres. Feilidentifisering av bottrafikk ved kun å stole på user agent-strenger overser sofistikerte boter som utgir seg for å være nettlesere—bruk adferdsanalyse inkludert forespørselsfrekvens, innholdspreferanser og geografisk fordeling for nøyaktig identifisering. Ufullstendig logganalyse som kun ser på user agents uten å vurdere andre datapunkter, overser viktig botaktivitet; omfattende sporing bør inkludere forespørselsfrekvens, innholdspreferanser, geografisk fordeling og ytelsesmålinger. Å blokkere for mye tilgang med for restriktive robots.txt-filer hindrer legitime AI-boter i å få tilgang til verdifullt innhold som kan gi synlighet i AI-genererte svar.
Vanlige feil å unngå:
AI-bot-økosystemet utvikler seg raskt, og overvåkingspraksisen din må utvikles tilsvarende. AI-boter blir stadig mer sofistikerte, kjører JavaScript, samhandler med skjemaer og navigerer komplekse nettstedarkitekturer—noe som gjør tradisjonelle botdeteksjonsmetoder mindre pålitelige. Forvent at nye standarder vil gi strukturerte måter å kommunisere preferanser til AI-boter, lik robots.txt, men med mer detaljert kontroll. Reguleringer er på vei, der myndigheter vurderer lover som krever at AI-selskaper oppgir treningsdatakilder og kompenserer innholdsskapere, noe som gjør loggfilene dine til potensielle juridiske bevis på botaktivitet. Tjenester for botformidling vil sannsynligvis dukke opp for å forhandle tilgang mellom innholdsskapere og AI-selskaper, og håndtere tillatelser, kompensasjon og teknisk implementering automatisk.
Bransjen beveger seg mot standardisering med nye protokoller og utvidelser til robots.txt som gir strukturert kommunikasjon med AI-boter. Maskinlæring vil i økende grad drive logganalyseverktøy, automatisk identifisere nye botmønstre og anbefale policyendringer uten manuell inngripen. Nettsteder som mestrer AI-crawlerovervåking nå, vil ha store fordeler når det gjelder å kontrollere innhold, infrastruktur og forretningsmodell ettersom AI-systemer blir stadig mer sentrale i informasjonsflyten på nettet.
Klar til å overvåke hvordan AI-systemer siterer og refererer til merkevaren din? AmICited.com utfyller serverlogganalyse ved å spore faktiske merkevareomtaler og siteringer i AI-genererte svar på tvers av ChatGPT, Perplexity, Google AI Overviews og andre AI-plattformer. Der serverlogger viser hvilke boter som crawler siden din, viser AmICited den reelle effekten—hvordan innholdet ditt faktisk brukes og siteres i AI-svar. Begynn å spore din AI-synlighet i dag.
AI-crawlere er roboter brukt av AI-selskaper for å trene språkmodeller og drive AI-applikasjoner. I motsetning til søkemotorboter som bygger indekser for rangering, fokuserer AI-crawlere på å samle inn variert innhold for å trene AI-modeller. De crawler ofte mer aggressivt og kan ignorere tradisjonelle robots.txt-regler.
Sjekk serverloggene dine for kjente brukernavnstrenger for AI-boter som 'GPTBot', 'ClaudeBot' eller 'PerplexityBot'. Bruk kommandolinjeverktøy som grep for å søke etter disse identifikatorene. Du kan også bruke logganalyseverktøy som Botify eller Conductor som automatisk identifiserer og kategoriserer AI-crawleraktivitet.
Det avhenger av forretningsmålene dine. Å blokkere AI-crawlere hindrer innholdet ditt i å vises i AI-genererte svar, noe som kan redusere synligheten. Men hvis du er bekymret for innholdstyveri eller ressursforbruk, kan du bruke robots.txt for å begrense tilgangen. Vurder å tillate tilgang til offentlig innhold, samtidig som du begrenser proprietær informasjon.
Spor forespørselsrate (forespørsler per sekund), båndbreddeforbruk, HTTP-statuskoder, crawl-frekvens og geografisk opprinnelse til forespørsler. Overvåk hvilke sider botene besøker oftest og hvor lenge de bruker på nettstedet ditt. Disse målene avslører botens hensikt og hjelper deg med å optimalisere nettstedet deretter.
Gratis alternativer inkluderer kommandolinjeverktøy (grep, awk) og åpen kildekode logganalysatorer. Kommersiell plattformer som Botify, Conductor og seoClarity tilbyr avanserte funksjoner som automatisk bot-identifisering og ytelseskorrelasjon. Velg basert på dine tekniske ferdigheter og budsjett.
Sørg for raske sideinnlastingstider, bruk strukturert data (schema markup), oppretthold tydelig nettstedstruktur og gjør innhold lett tilgjengelig. Implementer riktige HTTP-headere og robots.txt-regler. Lag innhold av høy kvalitet og originalitet som AI-systemer kan referere og sitere nøyaktig.
Ja, aggressive AI-crawlere kan bruke betydelige mengder båndbredde og serverressurser, noe som kan føre til tregheter eller økte hostingskostnader. Overvåk crawleraktivitet og implementer ratebegrensning for å forhindre ressursutmattelse. Bruk robots.txt og HTTP-headere for å kontrollere tilgang om nødvendig.
LLMs.txt er en ny standard som lar nettsteder kommunisere preferanser til AI-crawlere i et strukturert format. Selv om ikke alle roboter støtter det ennå, gir implementeringen deg ekstra kontroll over hvordan AI-systemer får tilgang til innholdet ditt. Det ligner robots.txt, men er spesielt designet for AI-applikasjoner.
Spor hvordan AI-systemer siterer og refererer innholdet ditt i ChatGPT, Perplexity, Google AI Overviews og andre AI-plattformer. Forstå din AI-synlighet og optimaliser innholdsstrategien din.
Lær å identifisere og overvåke AI-crawlere som GPTBot, ClaudeBot og PerplexityBot i serverloggene dine. Komplett guide med user-agent-strenger, IP-verifisering ...

Lær hvordan du identifiserer og overvåker AI-crawlere som GPTBot, PerplexityBot og ClaudeBot i serverloggene dine. Oppdag user-agent-strenger, IP-verifiseringsm...
Lær hvordan du sporer og overvåker AI-trafikk fra ChatGPT, Perplexity, Gemini og andre AI-plattformer i Google Analytics 4. Oppdag 4 dokumenterte metoder for å ...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.