Korrigering av AI-feilinformasjon
Lær hvordan du identifiserer og korrigerer feilaktig merkevareinformasjon i AI-systemer som ChatGPT, Gemini og Perplexity. Oppdag overvåkingsverktøy, strategier...
8 min lesing

Lær hvordan du kan be om korrigeringer fra AI-plattformer som ChatGPT, Perplexity og Claude. Forstå korrigeringsmekanismer, tilbakemeldingsprosesser og strategier for å påvirke AI-genererte svar om ditt merke.
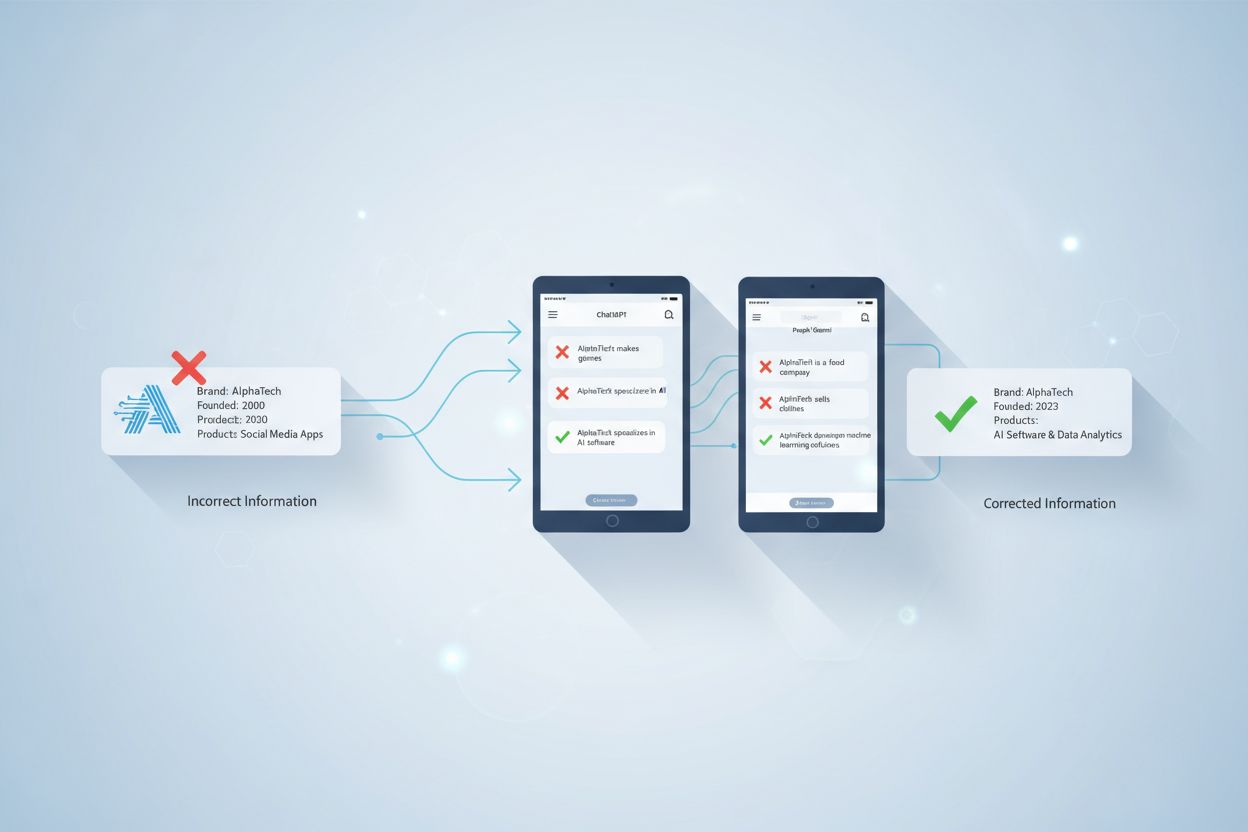
Selv om du ikke kan slette informasjon direkte fra AI-treningsdata, kan du be om korrigeringer via tilbakemeldingsmekanismer, adressere unøyaktigheter ved kilden, og påvirke fremtidige AI-svar ved å lage autoritativt, positivt innhold og samarbeide med plattformenes supportteam.
Å be om korrigeringer fra AI-plattformer krever forståelse for hvordan disse systemene fungerer i bunn og grunn. I motsetning til tradisjonelle søkemotorer, hvor du kan kontakte en nettsideeier for å fjerne eller oppdatere innhold, lærer AI-språkmodeller fra treningsdata i bestemte treningsfaser, hvor milliarder av nettsider, nyhetsartikler og tekstkilder inngår. Når negativ eller unøyaktig informasjon først har blitt en del av treningsdataene, kan du ikke direkte slette eller redigere det slik du kan be en nettsideeier om. AI-en har allerede lært mønstre og assosiasjoner fra flere kilder under treningssyklusen.
Korrigeringsprosessen er vesentlig forskjellig mellom statiske og sanntidsbaserte AI-systemer. Statiske modeller som GPT-4 er trent på data opp til en bestemt skjæringsdato (for eksempel desember 2023 for GPT-4-turbo), og når de først er trent, beholder de den kunnskapen til neste treningssyklus. Sanntids-AI-systemer som Perplexity og Claude.ai henter innhold fra nettet i sanntid, noe som betyr at korrigeringer ved kilden kan ha umiddelbar effekt på svarene deres. Å forstå hvilken type AI-plattform du har med å gjøre, er avgjørende for å finne den mest effektive korrigeringsstrategien.
De fleste store AI-plattformer tilbyr innebygde tilbakemeldingsmekanismer som lar brukere rapportere unøyaktigheter. ChatGPT har for eksempel tommel opp- og ned-knapper på svar, slik at brukere kan flagge problematiske svar. Når du gir negativ tilbakemelding på et unøyaktig svar, samles denne informasjonen inn og analyseres av plattformens team. Disse tilbakemeldingssløyfene hjelper AI-systemene med å forbedre ytelsen ved å lære av både vellykkede og feilaktige utfall. Tilbakemeldingen du sender inn blir en del av dataene utviklerne bruker for å identifisere feil og forbedre modellens nøyaktighet.
Perplexity og Claude tilbyr lignende tilbakemeldingsalternativer i sine grensesnitt. Du kan som regel rapportere når et svar er unøyaktig, misvisende eller inneholder foreldet informasjon. Noen plattformer lar deg også legge inn konkrete rettelser eller presiseringer. Effekten av denne tilbakemeldingen avhenger av hvor mange brukere som rapporterer det samme problemet, og hvor betydelig unøyaktigheten er. Plattformer prioriterer korrigeringer for utbredte problemer som påvirker mange brukere, så hvis flere personer rapporterer den samme unøyaktigheten om ditt merke, er det mer sannsynlig at plattformen undersøker og retter opp.
Den mest effektive langsiktige strategien for å korrigere AI-generert feilinformasjon er å adressere den opprinnelige kilden til den uriktige informasjonen. Fordi AI-systemer lærer fra nettinnhold, nyhetsartikler, Wikipedia-oppføringer og annet publisert materiale, vil korrigeringer hos disse kildene påvirke hvordan AI-plattformene presenterer informasjon i fremtidige treningssykluser. Be om korrigeringer eller oppdateringer fra de opprinnelige utgiverne der den feilaktige informasjonen finnes. Hvis et nyhetsmedium publiserte feil om ditt merke, kontakt redaksjonen med dokumentasjon på feilen og be om en rettelse eller presisering.
Wikipedia er en særlig viktig kilde for AI-treningsdata. Hvis unøyaktig informasjon om ditt merke eller domene finnes på Wikipedia, bør du bruke plattformens redaksjonelle kanaler for å rette det opp. Wikipedia har egne prosesser for å bestride informasjon og be om korrigeringer, men du må følge deres retningslinjer for nøytralitet og verifiserbarhet. Kilder med høy autoritet, som Wikipedia, store nyhetsorganisasjoner, utdanningsinstitusjoner og offentlige nettsteder har stor vekt i AI-treningsdatasett. Korrigeringer hos disse kildene blir oftere inkludert i fremtidige AI-modelloppdateringer.
For utdatert eller feilaktig informasjon på ditt eget nettsted eller andre kanaler du kontrollerer, sørg for å oppdatere eller fjerne det raskt. Dokumenter alle endringer du gjør, siden disse oppdateringene kan inkluderes i fremtidige treningssykluser. Når du korrigerer informasjon på ditt eget domene, gir du i praksis AI-systemene mer korrekt kildemateriale å lære av i fremtiden.
I stedet for å fokusere kun på å fjerne negativ eller unøyaktig informasjon, bør du utvikle sterke motfortellinger med autoritativt, positivt innhold. AI-modeller vektlegger informasjon delvis basert på frekvens og autoritetsmønstre i treningsdataene sine. Hvis du produserer betydelig mer positivt, nøyaktig og autoritativt innhold enn det finnes unøyaktig informasjon, vil AI-systemene støte på langt mer positiv informasjon når de genererer svar om ditt merke.
| Innholdstype | Autoritetsnivå | Effekt på AI | Tidslinje |
|---|---|---|---|
| Profesjonelle biografisider | Høy | Umiddelbar påvirkning på svar | Uker til måneder |
| Bransjepublikasjoner & tankelederskap | Svært høy | Sterk vekt i AI-svar | Måneder |
| Pressemeldinger via store nyhetstjenester | Høy | Betydelig påvirkning på narrativer | Uker til måneder |
| Casestudier og suksesshistorier | Middels-høy | Kontekstuell støtte for positive påstander | Måneder |
| Akademiske eller forskningspublikasjoner | Svært høy | Varig innflytelse i treningsdata | Måneder til år |
| Wikipedia-oppføringer | Svært høy | Kritisk for fremtidige AI-treningssykluser | Måneder til år |
Utvikle omfattende innhold på flere troverdige plattformer for å sikre at AI-systemene møter autoritativ, positiv informasjon. Denne metningsstrategien er særlig effektiv fordi den adresserer grunnårsaken til AI-feilinformasjon—mangel på positiv informasjon som kan veie opp for uriktige påstander. Når AI-systemene får tilgang til mer positiv, velfundert informasjon fra autoritative kilder, vil de naturlig generere mer fordelaktige svar om ditt merke.
Ulike AI-plattformer har ulike arkitekturer og oppdateringssykluser, og krever derfor tilpassede korrigeringsmetoder. ChatGPT og andre GPT-baserte systemer fokuserer på plattformer som var inkludert før treningsavgrensningen: store nyhetsnettsteder, Wikipedia, profesjonelle kataloger og mye siterte nettsider. Fordi disse modellene ikke oppdateres i sanntid, vil korrigeringer du gjør i dag påvirke fremtidige treningssykluser, vanligvis 12–18 måneder frem i tid. Perplexity og sanntidsbaserte AI-søk inkluderer direkte nettinnhold, så sterk SEO og jevn pressesynlighet har umiddelbar effekt. Når du fjerner eller retter opp innhold fra nettet, vil Perplexity vanligvis slutte å referere til det i løpet av dager eller uker.
Claude og Anthropic-systemer prioriterer faktabasert, velfundert informasjon. Anthropic legger vekt på faktamessig pålitelighet, så sørg for at positivt innhold om ditt merke er verifiserbart og lenket til troverdige kilder. Når du ber om korrigering fra Claude, bør du fokusere på å gi dokumenterte presiseringer og vise til autoritative kilder som støtter korrekt informasjon. Nøkkelen er å forstå at hver plattform har ulike datakilder, oppdateringshyppighet og kvalitetskrav. Tilpass korrigeringsstrategien din deretter.
Regelmessig testing av hvordan AI-systemer omtaler ditt navn eller merke er avgjørende for å spore effekten av korrigeringstiltak. Kjør søk i ChatGPT, Claude, Perplexity og andre plattformer med både positive og negative formuleringer (for eksempel “Er [merke] pålitelig?” versus “[merke] prestasjoner”). Registrer resultatene over tid og følg utviklingen for å identifisere unøyaktigheter og måle om dine korrigeringstiltak endrer fortellingen. Denne overvåkingen lar deg oppdage når nye unøyaktigheter dukker opp og reagere raskt. Hvis du ser at en AI-plattform fortsatt refererer til utdatert eller feil informasjon uker etter at du har rettet kilden, kan du eskalere saken via plattformens supportkanaler.
Dokumenter alle korrigeringer du ber om og svarene du mottar. Denne dokumentasjonen har flere formål: den gir bevis hvis du må eskalere saker, hjelper deg å se mønstre i hvordan ulike plattformer håndterer korrigeringer, og viser at du har gjort en god innsats for å holde informasjonen korrekt. Ta vare på når du sendte inn tilbakemelding, hvilken unøyaktighet du rapporterte, og eventuelle svar fra plattformen.
Fullstendig fjerning av unøyaktig informasjon fra AI-søk er sjelden mulig, men utvanning og kontekstbygging er oppnåelige mål. De fleste AI-selskaper oppdaterer treningsdata periodisk, vanligvis hver 12.–18. måned for store språkmodeller. Tiltak du gjør i dag vil påvirke fremtidige iterasjoner, men du bør forvente betydelig forsinkelse mellom tidspunktet du ber om en korrigering og når den vises i AI-genererte svar. Suksess krever tålmodighet og konsistens. Ved å fokusere på autoritativ innholdsproduksjon, adressere unøyaktigheter ved kilden og bygge troverdighet, kan du påvirke hvordan AI-plattformer fremstiller ditt merke over tid.
Sanntidsbaserte AI-søkeplattformer som Perplexity kan vise resultater i løpet av uker eller måneder, mens statiske modeller som ChatGPT kan bruke 12–18 måneder før korrigeringer reflekteres i grunnmodellen. Likevel kan du også med statiske modeller se forbedringer raskere hvis plattformen lanserer oppdaterte versjoner eller finjusterer spesifikke deler av modellen. Tidslinjen avhenger også av hvor utbredt unøyaktigheten er og hvor mange brukere som rapporterer den. Utbredte unøyaktigheter som påvirker mange brukere får raskere oppmerksomhet enn saker som bare gjelder noen få.
I noen jurisdiksjoner har du juridiske virkemidler mot uriktig eller ærekrenkende informasjon. Hvis en AI-plattform genererer falsk, ærekrenkende eller skadelig informasjon om ditt merke, kan du ha grunnlag for rettslige skritt. Rett-til-å-bli-glemt-lover i relevante jurisdiksjoner, særlig under GDPR i Europa, gir flere muligheter. Disse lovene lar deg be om fjerning av visse personopplysninger fra søkeresultater og i noen tilfeller fra AI-treningsdata.
Ta kontakt med AI-plattformens juridiske team hvis du mener informasjonen bryter med deres bruksvilkår eller gjeldende lover. De fleste plattformer har rutiner for håndtering av juridiske klager og forespørsler om fjerning. Legg ved tydelig dokumentasjon på unøyaktigheten og forklar hvorfor den bryter med lov eller plattformens retningslinjer. Dokumenter all kommunikasjon med plattformen, siden det gir en oversikt over dine forsøk på å løse saken i god tro.
Den mest bærekraftige måten å håndtere ditt omdømme i AI-søk er å overgå negativ informasjon med jevn, autoritativ positivitet. Publiser løpende ekspertinnhold, hold profesjonelle profiler oppdaterte, sørg for jevn medieomtale, bygg nettverk som fremhever prestasjoner og synliggjør samfunnsengasjement. Denne langsiktige tilnærmingen gjør at eventuell negativ eller unøyaktig omtale drukner som en ubetydelig fotnote i den større historien om ditt merke.
Implementer strategisk SEO for fremtidig AI-trening ved å sørge for at autoritativt innhold rangerer høyt i søkemotorer. Bruk strukturert datamerking og schema for å tydeliggjøre kontekst, hold NAP (navn, adresse, telefon) konsistent, og bygg sterke lenker til troverdig, positivt innhold. Disse tiltakene øker sjansen for at positiv informasjon blir den dominerende fortellingen i fremtidige AI-treningssykluser. Etter hvert som AI-systemer blir mer avanserte og integrert i hverdagen, vil viktigheten av korrekt, autoritativ informasjon på nettet bare øke. Invester i din digitale tilstedeværelse nå for å sikre at AI-plattformer har tilgang til riktig informasjon om ditt merke i årene som kommer.
Følg med på hvordan ditt merke, domene og dine URL-er vises på ChatGPT, Perplexity og andre AI-søkemotorer. Få varsler når korrigeringer er nødvendige og mål effekten av dine tiltak.
Lær hvordan du identifiserer og korrigerer feilaktig merkevareinformasjon i AI-systemer som ChatGPT, Gemini og Perplexity. Oppdag overvåkingsverktøy, strategier...

Fullstendig guide til hvordan du reserverer deg mot innsamling av AI-treningsdata på tvers av ChatGPT, Perplexity, LinkedIn og andre plattformer. Lær trinn-for-...
Lær hvordan du bruker statistikk og datadrevne innsikter for å forbedre merkevarens synlighet i AI-søkemotorer som ChatGPT, Perplexity og Google Gemini. Oppdag ...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.