
Perpleksitetsscore
Perpleksitetsscore måler tekstforutsigbarhet i språkmodeller. Lær hvordan denne viktige NLP-metrikken kvantifiserer modellusikkerhet, dens beregning, anvendelse...
11 min lesing

Lær hva perpleksitetspoeng betyr i innhold og språkmodeller. Forstå hvordan det måler modellens usikkerhet, prediksjonspresisjon og vurdering av tekstkvalitet.
Perpleksitetspoeng er en måleenhet som vurderer hvor godt en språkmodell forutsier det neste ordet i en sekvens. Det kvantifiserer modellens usikkerhet i forutsigelser, hvor lavere poeng indikerer høyere selvtillit og bedre prediktiv ytelse.
Perpleksitetspoeng er en grunnleggende måleenhet brukt i naturlig språkprosessering og maskinlæring for å vurdere hvor godt en språkmodell presterer når den forutsier tekst. I hovedsak måler det graden av usikkerhet en modell har når den tildeler sannsynligheter til ord i en sekvens. Måleenheten er spesielt viktig for å forstå modellens ytelse i oppgaver som tekstgenerering, maskinoversettelse og konversasjons-AI. Når en språkmodell behandler tekst, tilordner den sannsynlighetsverdier til potensielle neste ord basert på konteksten fra de foregående ordene. Perpleksitet fanger opp hvor sikker modellen er i disse forutsigelsene, og gjør det til et essensielt evalueringsverktøy for utviklere og forskere som jobber med store språkmodeller.
Konseptet perpleksitet stammer fra informasjonsteori, hvor det representerer et mål på usikkerhet i sannsynlighetsfordelinger. I sammenheng med språkmodeller indikerer lavere perpleksitetspoeng at modellen er mer sikker på sine forutsigelser og derfor produserer mer sammenhengende og flytende tekst. Omvendt antyder høyere perpleksitetspoeng at modellen er usikker på hvilket ord som skal komme neste, noe som potensielt fører til mindre sammenhengende eller mindre relevante resultater. Å forstå denne måleenheten er avgjørende for alle som jobber med AI-drevet innholdsgenerering, ettersom det direkte påvirker kvaliteten og påliteligheten til generert tekst.
Beregningen av perpleksitetspoeng involverer flere matematiske trinn som omgjør rå sannsynlighetsforutsigelser til en enkelt tolkningsvennlig måleenhet. Den grunnleggende formelen er basert på entropien i modellens forutsigelser, som måler graden av usikkerhet i resultatet. Den matematiske representasjonen er: Perpleksitet = 2^H(p), hvor H(p) representerer entropien i modellens forutsigelser. Denne formelen viser at perpleksitet er direkte avledet fra entropi, hvor lavere entropiverdier gir lavere perpleksitetspoeng.
Den praktiske beregningsprosessen følger en strukturert tilnærming som involverer flere steg. Først forutsier språkmodellen sannsynligheten for neste token basert på inntekst og kontekst. Deretter anvendes logaritmisk transformasjon på disse sannsynlighetene, noe som hjelper å konvertere dem til en mer nyttig måleenhet for analyse. Deretter beregnes gjennomsnittlig log-sannsynlighet for alle forutsagte ord i testsettet over hele sekvensen. Til slutt utføres eksponentiering av gjennomsnittlig log-sannsynlighet for å oppnå det endelige perpleksitetspoenget. Den fullstendige formelen for å beregne perpleksitet for en sekvens av ord er: Perpleksitet = exp(-1/N × Σ log p(w_i | w_{i-1}, w_{i-2}, …, w_1)), hvor p(w_i | w_{i-1}, …, w_1) er den forutsagte sannsynligheten for det i-te ordet gitt alle foregående ord, og N er totalt antall ord i sekvensen.
| Beregningstrinn | Beskrivelse | Formål |
|---|---|---|
| Tokenforutsigelse | Modellen forutsier sannsynlighet for neste ord | Etablere grunnlag for forutsigelser |
| Logtransformasjon | Påfør logaritme på sannsynligheter | Konverter til nyttig måleenhet |
| Gjennomsnittsberegning | Beregn gjennomsnittlig log-sannsynlighet i sekvensen | Normaliser over tekstlengde |
| Eksponentiering | Opphøy e i negativt gjennomsnitt | Oppnå endelig perpleksitetspoeng |
Perpleksitetspoeng fungerer som en kritisk evalueringsmåleenhet for å vurdere språkmodellens ytelse på flere områder. Måleenheten er viktig fordi den gir direkte innsikt i prediksjonspresisjon, og hjelper utviklere å forstå hvor godt en modell kan forutsi ord og generere sammenhengende tekst. Lavt perpleksitetspoeng indikerer at modellen gjør trygge forutsigelser og sannsynligvis genererer flytende, kontekstuelt passende innhold. Dette er spesielt verdifullt for applikasjoner som chatboter, virtuelle assistenter og innholdsgenereringssystemer hvor tekstkvalitet direkte påvirker brukeropplevelse. I tillegg hjelper perpleksitet å vurdere modellens selvtillitsnivå i forutsigelsene—hvis perpleksiteten er høy, er modellen usikker på neste ord, noe som kan føre til usammenhengende eller irrelevant tekst.
Måleenheten er også avgjørende for modell-sammenligning og valg. Når man vurderer ulike språkmodeller eller sammenligner versjoner av samme modell under finjustering, gir perpleksitet et kvantifiserbart mål på forbedring eller forverring. Utviklere kan bruke perpleksitetspoeng for å avgjøre om en modell er egnet for spesifikke oppgaver som tekstgenerering, maskinoversettelse, oppsummering eller spørsmålsbesvarelse. Videre muliggjør perpleksitet sanntidsevaluering under modelltrening, slik at utviklere umiddelbart kan vurdere modellens ytelse og gjøre nødvendige justeringer. Denne muligheten er særlig verdifull under finjusteringsprosessen, hvor overvåking av perpleksitet hjelper til å sikre at modellen blir bedre til å gjøre trygge forutsigelser i stedet for å overtilpasse treningsdataene.
Å forstå hvordan man tolker perpleksitetspoeng er avgjørende for å ta informerte beslutninger om modellens ytelse og egnethet for spesifikke applikasjoner. Et lavt perpleksitetspoeng indikerer at modellen er mer sikker i sine forutsigelser og vanligvis genererer tekst av høyere kvalitet og bedre sammenheng. For eksempel antyder et perpleksitetspoeng på 15 at modellen velger mellom omtrent 15 mulige ord ved hver forutsigelse, noe som signaliserer relativt høy selvtillit. Til sammenligning antyder et høyere perpleksitetspoeng på 50 eller mer at modellen er usikker og vurderer mange flere muligheter, noe som ofte korrelerer med mindre sammenhengende eller mindre relevante resultater. Tolkningen av hva som utgjør et “godt” perpleksitetspoeng avhenger av den spesifikke oppgaven, datasettet og modellarkitekturen som vurderes.
Ulike typer innhold og modeller har ulike baseline-intervaller for perpleksitet. For eksempel oppnår modeller trent på velstrukturert, formell tekst som Wikipedia-artikler vanligvis lavere perpleksitetspoeng enn modeller trent på samtale- eller kreativt innhold. Når man sammenligner perpleksitetspoeng på tvers av ulike modeller, er det avgjørende å sikre at de er evaluert på samme datasett og med samme tokeniseringsmetode, ettersom disse faktorene påvirker resultatene betydelig. En modell med perpleksitetspoeng på 20 på ett datasett kan ikke sammenlignes direkte med en annen modell med poeng på 25 på et annet datasett. I tillegg påvirker sekvenslengde perpleksitetsberegninger—lengre sekvenser gir mer stabile perpleksitetspoeng, mens kortere sekvenser kan gi høyere variasjon og uteliggere som forvrenger resultatene.
Selv om perpleksitetspoeng er en verdifull måleenhet, har den viktige begrensninger som må forstås ved evaluering av språkmodeller. En betydelig begrensning er at perpleksitet ikke måler forståelse—en modell med lav perpleksitet kan fortsatt produsere usammenhengende, irrelevant eller faktuelt feil tekst. Måleenheten måler bare modellens evne til å forutsi neste ord basert på statistiske mønstre i treningsdataene, ikke om modellen virkelig forstår meningen eller konteksten i innholdet. Dette betyr at en modell kan oppnå utmerkede perpleksitetspoeng mens den genererer tekst som er grammatisk korrekt, men semantisk meningsløs eller faktuelt feil.
En annen viktig betraktning er at perpleksitet ikke effektivt fanger opp langtidssammenhenger. Måleenheten er basert på umiddelbare ordforutsigelser og kan ikke nødvendigvis reflektere hvor godt en modell opprettholder sammenheng og konsistens over lengre tekstsekvenser. Videre er tokeniseringsfølsomhet en kritisk faktor—ulike tokeniseringsmetoder kan påvirke perpleksitetspoeng betydelig, noe som gjør direkte sammenligninger mellom modeller med ulike tokeniserere problematisk. For eksempel kan tegn-nivå-modeller oppnå lavere perpleksitet enn ord-nivå-modeller, men dette betyr ikke nødvendigvis at de genererer bedre tekst. I tillegg er perpleksitet hovedsakelig designet for autoregressive eller kausale språkmodeller og er ikke veldefinert for maskerte språkmodeller som BERT, som bruker ulike prediksjonsmekanismer.
For å oppnå en helhetlig vurdering av språkmodellens ytelse bør perpleksitet brukes i kombinasjon med andre evalueringsmåleenheter og ikke som et enkeltstående mål. BLEU, ROUGE og METEOR er mye brukte måleenheter som sammenligner generert tekst med referansetekster, og er spesielt verdifulle for oppgaver som maskinoversettelse og oppsummering. Menneskelig evaluering av kvalifiserte dommere gir innsikt i aspekter automatiske måleenheter ikke kan fange, inkludert flyt, relevans, sammenheng og total kvalitet. Faktuell nøyaktighet vurderes ved hjelp av kunnskapsbaserte QA-systemer eller faktasjekkrammeverk for å sikre at generert innhold ikke bare er flytende, men også korrekt. Mangfolds- og kreativitetspoeng som repetisjonsrate, nyhetspoeng og entropi måler hvor variert og original den genererte teksten er, noe som er viktig for kreative applikasjoner.
I tillegg sikrer vurdering av modeller for skjevhet og rettferdighet trygg implementering i virkelige applikasjoner hvor skadelige skjevheter kan forårsake store problemer. Ved å kombinere perpleksitet med disse tilleggs-måleenhetene kan utviklere bedre vurdere modellens prediktive nøyaktighet, flyt og brukbarhet i praksis. Denne helhetlige tilnærmingen muliggjør identifikasjon av modeller som ikke bare forutsier riktig, men også gjør det med selvtillit, sammenheng og pålitelighet. Kombinasjonen av måleenheter gir et mer komplett bilde av modellens ytelse og hjelper til å sikre at valgte modeller oppfyller de spesifikke kravene til sine tiltenkte applikasjoner.
Perpleksitetspoeng er mye brukt på tvers av flere virkelige bruksområder hvor språkmodellens ytelse direkte påvirker brukeropplevelse og innholdskvalitet. I tekstgenereringsapplikasjoner hjelper perpleksitet å sikre at generert innhold er sammenhengende og flytende ved å bekrefte at modellens forutsigelser er trygge og kontekstuelt passende. For maskinoversettelsessystemer vurderer perpleksitet hvor godt oversettelsesmodellen forutsier neste ord på målspråket, noe som er avgjørende for å produsere oversettelser av høy kvalitet som bevarer mening og nyanser fra kildespråket. I chatboter og virtuelle assistenter sikrer lav perpleksitet at svarene er flytende og kontekstuelt riktige, noe som direkte forbedrer brukertilfredshet og engasjement.
Oppsummeringsmodeller drar nytte av perpleksitetsevaluering ved å sikre at produserte sammendrag er lesbare og sammenhengende, samtidig som de opprettholder essensiell informasjon fra kildeteksten. Innholdsskapere og AI-plattformer bruker perpleksitet for å vurdere kvaliteten på AI-generert innhold før publisering eller fremvisning for brukere. Etter hvert som AI-drevet innholdsgenerering blir stadig mer utbredt i søkemotorer og svarplattformer, hjelper forståelse og overvåking av perpleksitetspoeng å sikre at generert innhold oppfyller kvalitetsstandarder. Organisasjoner som jobber med AI-systemer kan bruke perpleksitetsmåleenheter til å identifisere når modeller trenger nytrening, finjustering eller utskifting for å opprettholde konsekvent innholdskvalitet og brukertillit til AI-genererte svar.
Følg med på hvordan innholdet ditt vises i AI-svar på tvers av ChatGPT, Perplexity og andre AI-søkemotorer. Sørg for at ditt merke får korrekt attribusjon i AI-genererte svar.
Perpleksitetsscore måler tekstforutsigbarhet i språkmodeller. Lær hvordan denne viktige NLP-metrikken kvantifiserer modellusikkerhet, dens beregning, anvendelse...
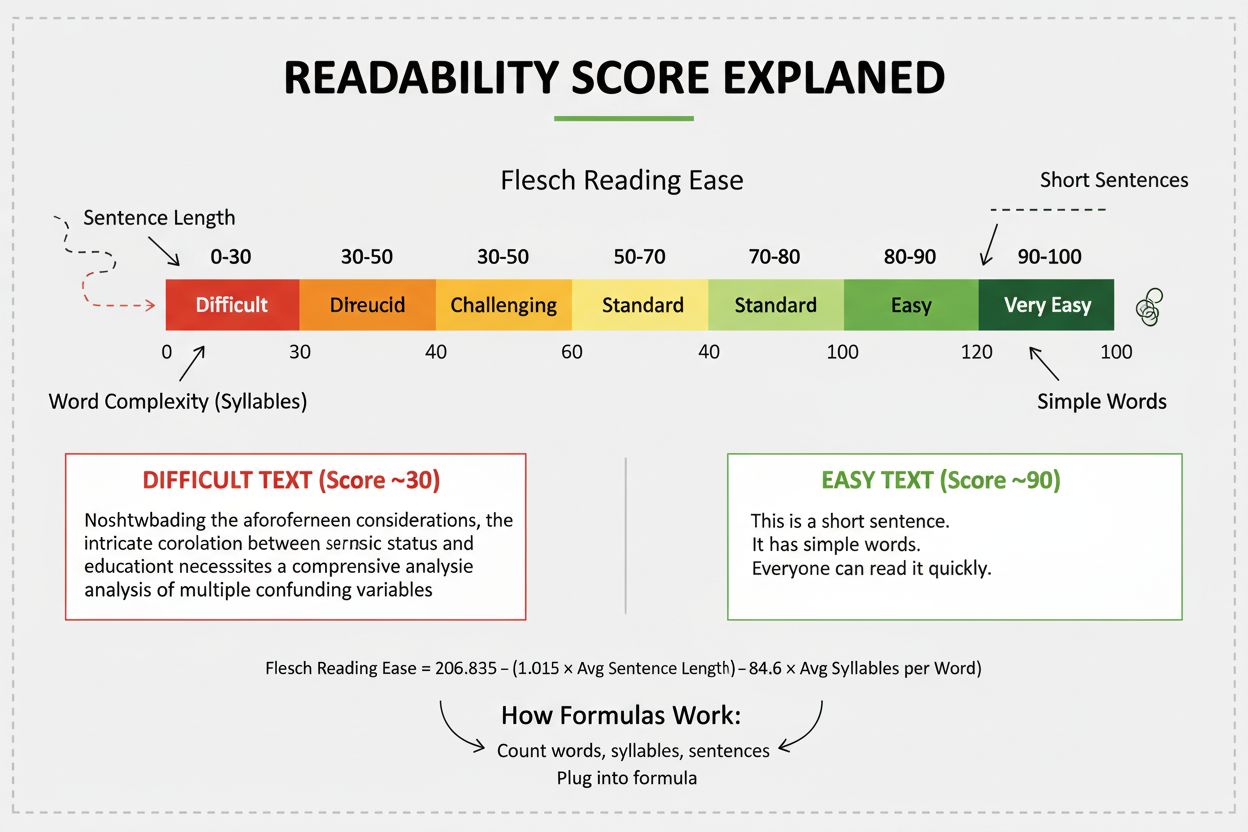
Lesbarhetspoeng måler hvor vanskelig innholdet er å forstå ved hjelp av språklig analyse. Lær hvordan Flesch, Gunning Fog og andre formler påvirker SEO, brukere...
Lær hva lesbarhetspoengsummer betyr for synlighet i AI-søk. Oppdag hvordan Flesch-Kincaid, setningsstruktur og innholdsformatering påvirker AI-siteringer i Chat...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.