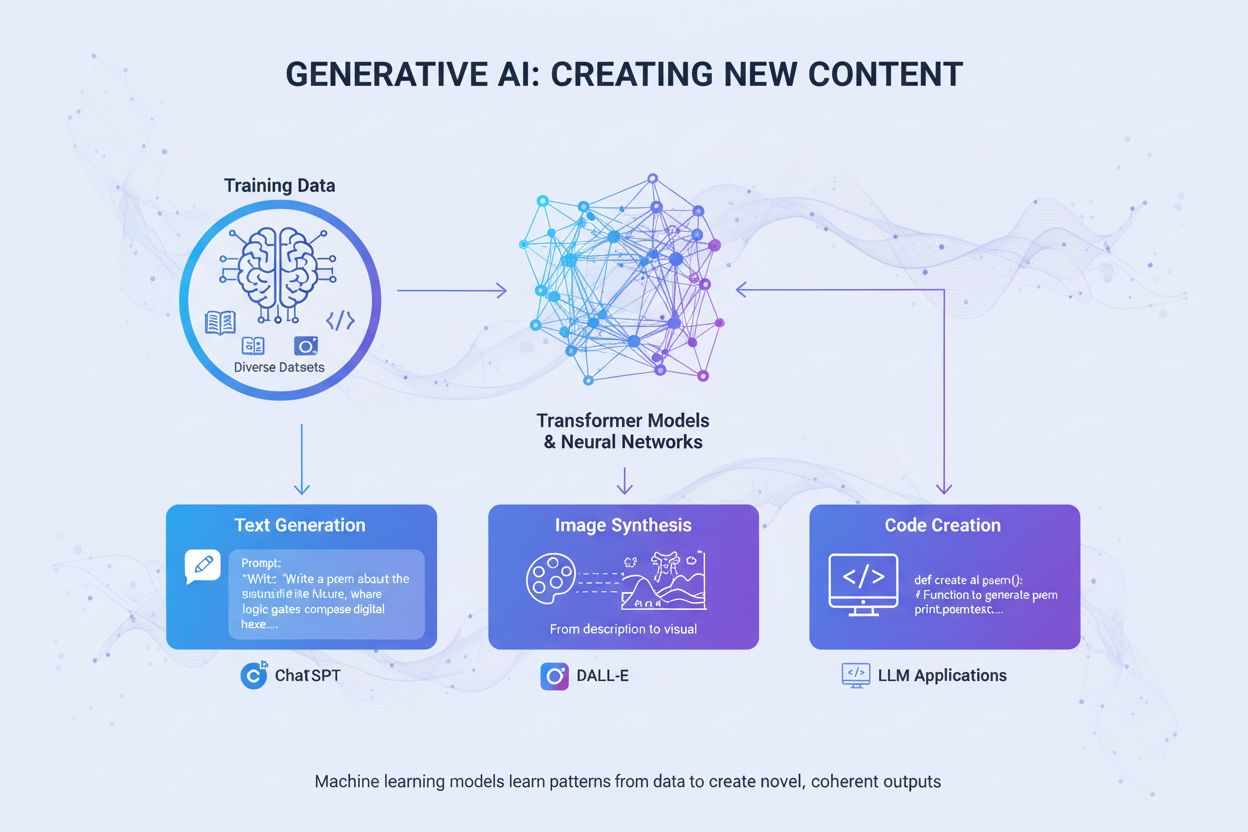
Generativ KI
Generativ KI lager nytt innhold fra treningsdata ved hjelp av nevrale nettverk. Lær hvordan det fungerer, bruksområder i ChatGPT og DALL-E, og hvorfor overvåkin...
11 min lesing
Et AI-generert bilde er et digitalt bilde som er laget av kunstig intelligens-algoritmer og maskinlæringsmodeller, i stedet for av menneskelige kunstnere eller fotografer. Disse bildene produseres ved å trene nevrale nettverk på store datasett med merkede bilder, noe som gjør det mulig for AI å lære visuelle mønstre og generere originale, realistiske visuelle uttrykk fra tekstbeskrivelser, skisser eller andre inndata.
Et AI-generert bilde er et digitalt bilde som er laget av kunstig intelligens-algoritmer og maskinlæringsmodeller, i stedet for av menneskelige kunstnere eller fotografer. Disse bildene produseres ved å trene nevrale nettverk på store datasett med merkede bilder, noe som gjør det mulig for AI å lære visuelle mønstre og generere originale, realistiske visuelle uttrykk fra tekstbeskrivelser, skisser eller andre inndata.
Et AI-generert bilde er et digitalt bilde laget av kunstig intelligens-algoritmer og maskinlæringsmodeller, i stedet for av menneskelige kunstnere eller fotografer. Disse bildene produseres gjennom sofistikerte nevrale nettverk trent på store datasett med merkede bilder, som gjør det mulig for AI å lære visuelle mønstre, stiler og sammenhenger mellom konsepter. Teknologien gjør det mulig for AI-systemer å generere originale, realistiske visuelle uttrykk fra ulike inndata—oftest tekstbeskrivelser, men også fra skisser, referansebilder eller andre datakilder. I motsetning til tradisjonell fotografering eller manuelt kunstverk kan AI-genererte bilder fremstille alt tenkelig, inkludert umulige scenarioer, fantasiverdener og abstrakte konsepter som aldri har eksistert fysisk. Prosessen er bemerkelsesverdig rask, ofte med høyoppløselige bilder produsert på sekunder, noe som gjør det til en transformativ teknologi for kreative bransjer, markedsføring, produktdesign og innholdsproduksjon.
Utviklingen av AI-bildegenerering startet med grunnleggende forskning innen dyp læring og nevrale nettverk, men teknologien ble først utbredt tidlig på 2020-tallet. Generative Adversarial Networks (GANs), introdusert av Ian Goodfellow i 2014, var blant de første vellykkede tilnærmingene, hvor to konkurrerende nevrale nettverk skapte realistiske bilder. Det virkelige gjennombruddet kom imidlertid med fremveksten av diffusjonsmodeller og transformerbaserte arkitekturer, som viste seg å være mer stabile og i stand til å produsere bilder av høyere kvalitet. I 2022 ble Stable Diffusion lansert som en åpen kildekode-modell, noe som demokratiserte tilgangen til AI-bildegenerering og førte til bred utbredelse. Kort tid etter fikk DALL-E 2 fra OpenAI og Midjourney stor oppmerksomhet, og brakte AI-bildegenerering inn i den allmenne bevisstheten. Ifølge ferske statistikker er 71 % av bilder på sosiale medier nå AI-genererte, og det globale markedet for AI-bildegeneratorer var verdt 299,2 millioner dollar i 2023, med forventet vekst på 17,4 % årlig frem til 2030. Denne eksplosive veksten reflekterer både teknologisk modning og utbredt forretningsadopsjon på tvers av bransjer.
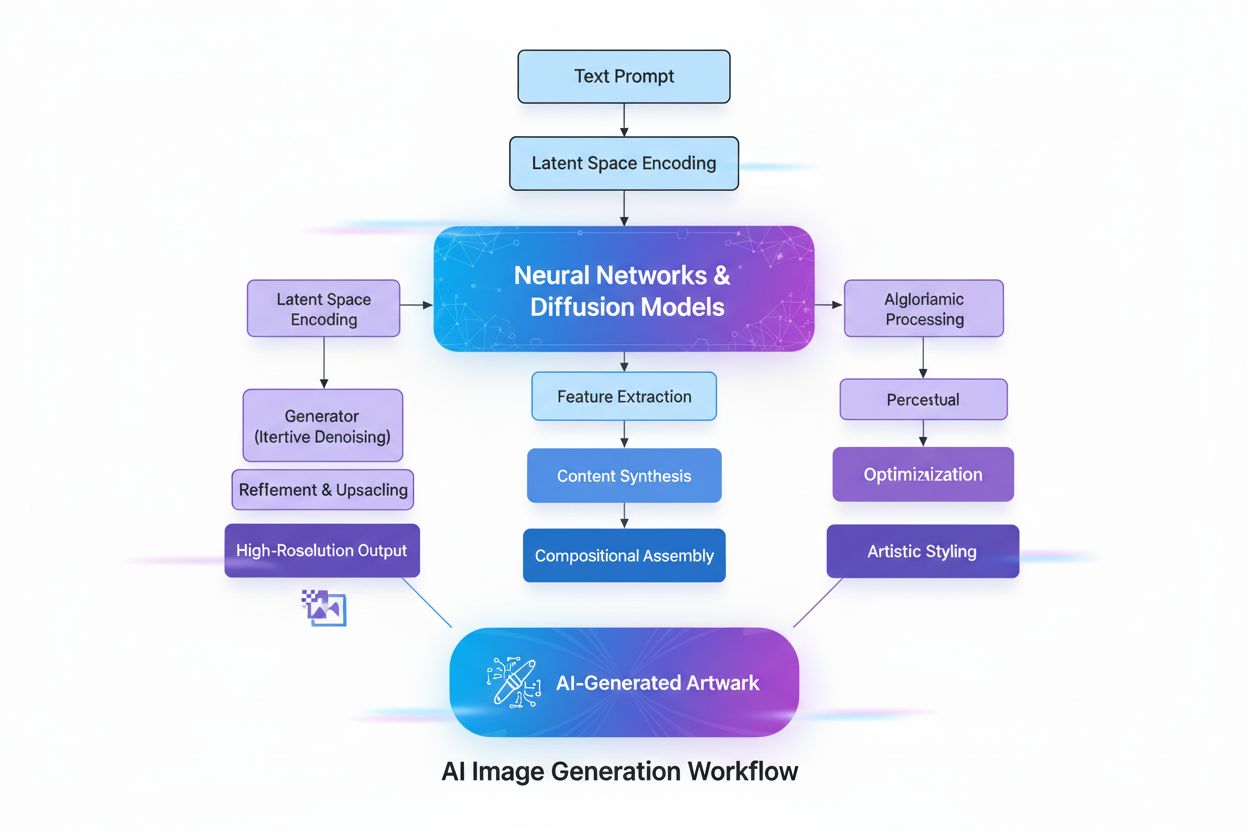
Å lage AI-genererte bilder innebærer flere avanserte tekniske prosesser som samarbeider for å omdanne abstrakte konsepter til visuell virkelighet. Prosessen begynner med tekstanalyse ved bruk av Natural Language Processing (NLP), hvor AI omgjør menneskespråk til numeriske representasjoner kalt embeddings. Modeller som CLIP (Contrastive Language-Image Pre-training) koder tekstbeskrivelser til høy-dimensjonale vektorer som fanger semantisk betydning og kontekst. For eksempel, når en bruker skriver “et rødt eple på et tre”, bryter NLP-modellen dette ned til numeriske koordinater som representerer “rødt”, “eple”, “tre” og deres romlige relasjoner. Dette numeriske kartet styrer deretter bildefremstillingsprosessen, og fungerer som en regelbok som forteller AI hvilke komponenter som skal inkluderes og hvordan de skal samhandle.
Diffusjonsmodeller, som driver mange moderne AI-bildegeneratorer inkludert DALL-E 2 og Stable Diffusion, fungerer gjennom en elegant iterativ prosess. Modellen starter med ren, tilfeldig støy—i praksis et kaotisk mønster av piksler—og forbedrer dette gradvis gjennom flere avstøyingssteg. Under trening lærer modellen å reversere prosessen med å legge til støy i bilder, og lærer dermed å “avstøye” korrupte versjoner tilbake til opprinnelig form. Når den genererer nye bilder, bruker modellen denne lærte avstøyingsprosessen omvendt, starter med støy og gjør det gradvis om til et sammenhengende bilde. Tekstbeskrivelsen styrer denne transformasjonen i hvert steg, slik at sluttresultatet samsvarer med brukerens beskrivelse. Denne steg-for-steg-forbedringen gir eksepsjonell kontroll og resulterer i svært detaljerte, høyoppløselige bilder.
Generative Adversarial Networks (GANs) benytter en grunnleggende annerledes tilnærming basert på spillteori. En GAN består av to konkurrerende nevrale nettverk: en generator som lager falske bilder fra tilfeldig input, og en diskriminator som forsøker å skille ekte bilder fra falske. Disse nettverkene konkurrerer i et spill der generatoren stadig forbedres for å lure diskriminatoren, mens diskriminatoren blir bedre til å oppdage forfalskninger. Denne konkurransedynamikken driver begge nettverk mot perfeksjon, og gir til slutt bilder som nesten ikke kan skilles fra ekte fotografier. GANs er spesielt effektive for å generere fotorealistiske menneskeansikter og utføre stiloverføringer, selv om de kan være mindre stabile å trene enn diffusjonsmodeller.
Transformerbaserte modeller utgjør en annen stor arkitektur og tilpasser transformer-teknologien opprinnelig utviklet for naturlig språkprosessering. Disse modellene er spesielt gode på å forstå komplekse sammenhenger i tekstbeskrivelser og kartlegge språktoken til visuelle trekk. De bruker self-attention-mekanismer for å fange kontekst og relevans, og gjør det mulig å håndtere nyanserte, sammensatte beskrivelser med høy presisjon. Transformere kan generere bilder som tett samsvarer med detaljerte tekstbeskrivelser, noe som gjør dem ideelle for applikasjoner som krever presis kontroll over resultatene.
| Teknologi | Hvordan det fungerer | Styrker | Svakheter | Beste bruksområder | Eksempelverktøy |
|---|---|---|---|---|---|
| Diffusjonsmodeller | Iterativt avstøyer tilfeldig støy til strukturerte bilder styrt av tekstbeskrivelser | Høyoppløselige detaljerte resultater, utmerket tekstsamsvar, stabil trening, fin kontroll over forbedring | Tregere generering, krever mer datakraft | Tekst-til-bilde-generering, høyoppløselig kunst, vitenskapelig visualisering | Stable Diffusion, DALL-E 2, Midjourney |
| GANs | To konkurrerende nevrale nettverk (generator og diskriminator) lager realistiske bilder via konkurranse | Rask generering, utmerket for fotorealisme, god for stiloverføring og bildeforbedring | Trening kan være ustabil, fare for mode collapse, mindre presis tekstkontroll | Fotorealistiske ansikter, stiloverføring, bildeoppskalering | StyleGAN, Progressive GAN, ArtSmart.ai |
| Transformere | Konverterer tekstbeskrivelser til bilder via self-attention og token-embeddings | Eksepsjonell tekst-til-bilde-syntese, håndterer komplekse beskrivelser godt, sterk semantisk forståelse | Krever mye datakraft, nyere teknologi med mindre optimalisering | Kreativ bildefremstilling fra detaljerte tekster, design og reklame, fantasifull konseptkunst | DALL-E 2, Runway ML, Imagen |
| Nevral stiloverføring | Fletter innhold fra ett bilde med kunstnerisk stil fra et annet | Kunstnerisk kontroll, bevarer innhold mens stil påføres, tolkningsbar prosess | Begrenset til stiloverføringsoppgaver, krever referansebilder, mindre fleksibel enn andre metoder | Kunstnerisk bildefremstilling, stilpåføring, kreativ forbedring | DeepDream, Prisma, Artbreeder |
Implementeringen av AI-genererte bilder på tvers av bransjer har vært bemerkelsesverdig rask og transformerende. Innen e-handel og detaljhandel bruker selskaper AI-bildefremstilling for å produsere produktbilder i stor skala, og eliminerer behovet for dyre fotoshoots. Ifølge ferske data forventer 80 % av detaljhandelsledere at virksomhetene deres tar i bruk AI-automatisering innen 2025, og detaljhandelsselskaper brukte 19,71 milliarder dollar på AI-verktøy i 2023, hvor bildegenerering utgjør en betydelig andel. Markedet for AI-bilderedigering er verdt 88,7 milliarder dollar i 2025 og forventes å nå 8,9 milliarder dollar innen 2034, med bedriftskunder som står for omtrent 42 % av all omsetning.
Innen markedsføring og reklame bruker 62 % av markedsførere AI til å lage nye bildeaktiva, og bedrifter som bruker AI til innholdsproduksjon for sosiale medier rapporterer om 15–25 % økning i engasjementsrater. Evnen til raskt å generere flere kreative varianter muliggjør A/B-testing i stor skala, og gir markedsførere mulighet til å optimalisere kampanjer med datadrevet presisjon. Cosmopolitan magazine vakte oppsikt i juni 2022 ved å utgi et omslag laget utelukkende av DALL-E 2, første gang et stort magasin brukte AI-generert bilde på forsiden. Beskrivelsen som ble brukt var: “A wide angle shot from below of a female astronaut with an athletic female body walking with swagger on Mars in an infinite universe, synthwave, digital art.”
Innen medisinsk bildediagnostikk utforskes AI-genererte bilder for diagnostikk og syntetisk datagenerering. Forskning har vist at DALL-E 2 kan generere realistiske røntgenbilder fra tekstbeskrivelser og til og med rekonstruere manglende elementer i radiologiske bilder. Denne evnen har stor betydning for medisinsk opplæring, personvernvennlig datadeling mellom institusjoner og akselerert utvikling av nye diagnostiske verktøy. Markedet for AI-drevne sosiale medier forventes å nå 12 milliarder dollar innen 2031, opp fra 2,1 milliarder dollar i 2021, noe som understreker teknologiens sentrale rolle i innholdsproduksjon på digitale plattformer.
Den raske utbredelsen av AI-genererte bilder har reist betydelige etiske og juridiske spørsmål som bransjen og myndighetene fortsatt jobber med å løse. Opphavsrett og immaterielle rettigheter er kanskje den mest omstridte utfordringen. De fleste AI-bildegeneratorer trenes på enorme datasett av bilder hentet fra internett, hvorav mange er opphavsrettslig beskyttede verk laget av kunstnere og fotografer. I januar 2023 reiste tre kunstnere et banebrytende søksmål mot Stability AI, Midjourney og DeviantArt, og hevdet at selskapene brukte opphavsrettsbeskyttede bilder til å trene AI-algoritmene uten samtykke eller kompensasjon. Denne saken illustrerer den større spenningen mellom teknologisk innovasjon og kunstneres rettigheter.
Spørsmålet om eierskap og rettigheter til AI-genererte bilder er fortsatt juridisk uklart. Da et AI-generert kunstverk vant førsteplass i Colorados statsmesse for kunst i 2022, sendt inn av Jason Allen ved bruk av Midjourney, oppstod betydelig kontrovers. Mange mente at siden AI genererte kunstverket, burde det ikke kvalifisere som original menneskelig skapelse. Det amerikanske opphavsrettskontoret har indikert at verk laget utelukkende av AI uten menneskelig kreativt bidrag kanskje ikke kvalifiserer for opphavsrettsbeskyttelse, selv om dette fortsatt er et område i utvikling med pågående rettssaker og regulatorisk utvikling.
Deepfakes og feilinformasjon er en annen kritisk bekymring. AI-bildegeneratorer kan lage svært realistiske bilder av hendelser som aldri har skjedd, og muliggjør spredning av falsk informasjon. I mars 2023 spredte AI-genererte deepfake-bilder av den falske arrestasjonen av tidligere president Donald Trump seg på sosiale medier, laget med Midjourney. Disse bildene ble i starten antatt å være ekte av enkelte brukere, noe som viser teknologiens potensial for ondsinnet misbruk. Den høye realismen i moderne AI-genererte bilder gjør det stadig vanskeligere å oppdage forfalskninger, og skaper utfordringer for sosiale medier og nyhetsorganisasjoner som forsøker å sikre innholdsautensitet.
Skjevhet i treningsdata er også et betydelig etisk problem. AI-modeller lærer fra datasett som kan inneholde kulturelle, kjønns- og raseskjevheter. Gender Shades-prosjektet ledet av Joy Buolamwini ved MIT Media Lab avdekket store skjevheter i kommersielle AI-systemer for kjønnsidentifikasjon, med feilrater for mørkhudede kvinner vesentlig høyere enn for lyshudede menn. Tilsvarende skjevheter kan oppstå i bildegenerering, og føre til forsterking av skadelige stereotyper eller underrepresentasjon av visse grupper. Å adressere slike skjevheter krever nøye kuratering av datasett, mangfoldige treningsdata og kontinuerlig evaluering av modellresultater.
Kvaliteten på AI-genererte bilder avhenger i stor grad av kvaliteten og presisjonen på innputtbeskrivelsen. Prompt engineering—kunsten å lage effektive tekstbeskrivelser—har blitt en avgjørende ferdighet for brukere som ønsker optimale resultater. Gode beskrivelser har flere fellestrekk: de er spesifikke og detaljerte heller enn vage, inkluderer stil- eller mediumnavn (som “digitalt maleri”, “akvarell” eller “fotorealistisk”), inneholder atmosfære- og lysinformasjon (som “gyllent kveldslys”, “filmlys” eller “dramatiske skygger”), og etablerer tydelige relasjoner mellom elementene.
For eksempel, i stedet for bare å be om “en katt”, vil en mer effektiv beskrivelse være: “en fluffy oransje tabbykatt som sitter på en vinduskarm i solnedgang, varmt gyllent lys strømmer gjennom vinduet, fotorealistisk, profesjonell fotografering.” Dette detaljnivået gir AI-en tydelig veiledning om utseende, miljø, lyssetting og ønsket estetikk. Forskning viser at strukturerte beskrivelser med klar informasjonsstruktur gir mer konsistente og tilfredsstillende resultater. Brukere benytter ofte teknikker som å spesifisere kunststiler, legge til beskrivende adjektiver, inkludere tekniske fototermer og til og med referere til spesifikke kunstnere eller kunstretninger for å styre AI mot ønsket resultat.
Ulike AI-bildegenereringsplattformer har forskjellige egenskaper, styrker og bruksområder. DALL-E 2, utviklet av OpenAI, lager detaljerte bilder fra tekstbeskrivelser med avanserte muligheter for innmaling og redigering. Den fungerer med et kredittbasert system, hvor brukere kjøper kreditter for hver bildegenerering. DALL-E 2 er kjent for sin allsidighet og evne til å håndtere komplekse, nyanserte beskrivelser, noe som gjør den populær blant profesjonelle og kreative brukere.
Midjourney fokuserer på kunstnerisk og stilisert bildefremstilling, og er foretrukket av designere og kunstnere for sin unike estetikk. Plattformen brukes via en Discord-bot, hvor brukere skriver inn beskrivelser med kommandoen /imagine. Midjourney er særlig kjent for å produsere visuelt tiltalende, maleriske bilder med komplementære farger, balansert lyssetting og skarpe detaljer. Plattformen tilbyr abonnement fra $10 til $120 per måned, med høyere nivåer som gir flere månedlige genereringer.
Stable Diffusion, utviklet i samarbeid mellom Stability AI, EleutherAI og LAION, er en åpen kildekode-modell som demokratiserer AI-bildegenerering. Den åpne naturen gjør det mulig for utviklere og forskere å tilpasse og implementere modellen, noe som er ideelt for eksperimentelle prosjekter og bedriftstilpasning. Stable Diffusion fungerer på latent diffusjonsarkitektur, som tillater effektiv generering på forbruker-grafikkort. Plattformen koster $0,0023 per bilde, med gratis prøveperiode for nye brukere.
Googles Imagen er en annen betydelig aktør og tilbyr tekst-til-bilde-diffusjonsmodeller med enestående fotorealisme og avansert språkforståelse. Disse plattformene viser samlet bredden av tilnærminger og forretningsmodeller i AI-bildegenerering, hvor hver tjener ulike brukerbehov og bruksområder.
Landskapet for AI-bildegenerering utvikler seg raskt, med flere viktige trender som former teknologiens fremtid. Modellforbedring og effektivisering skjer i høyt tempo, med nyere modeller som gir høyere oppløsning, bedre tekstsamsvar og raskere generering. Markedet for AI-bildegeneratorer forventes å vokse med 17,4 % årlig frem til 2030, som indikerer vedvarende investering og innovasjon. Nye trender inkluderer videogenerering fra tekst, der AI-systemer utvider bildefremstilling til å lage korte videoklipp; 3D-modellgenerering, som gjør det mulig for AI å skape tredimensjonale aktiva direkte; og sanntids bildegenerering, som reduserer ventetid og muliggjør interaktive kreative arbeidsflyter.
Regulatoriske rammeverk begynner å dukke opp globalt, hvor myndigheter og bransjeorganer utvikler standarder for åpenhet, opphavsrettsbeskyttelse og etisk bruk. NO FAKES Act og lignende lovgivning foreslår krav om vannmerking av AI-generert innhold og tydeliggjøring når AI er brukt. 62 % av globale markedsførere mener påkrevde etiketter for AI-generert innhold vil ha en positiv effekt på ytelsen i sosiale medier, noe som antyder at bransjen anerkjenner viktigheten av åpenhet.
Integrasjon med andre AI-systemer akselererer, og bildegenerering blir en del av større AI-plattformer og arbeidsflyter. Multimodale AI-systemer som kombinerer tekst, bilde, lyd og videogenerering blir stadig mer avanserte. Teknologien beveger seg også mot personalisering og tilpassing, hvor AI-modeller kan finjusteres til bestemte kunststiler, merkevareestetikk eller individuelle preferanser. Etter hvert som AI-genererte bilder blir vanligere på digitale plattformer, øker viktigheten av merkevareovervåking og siteringssporing i AI-responser, og gjør verktøy som sporer hvordan merkevarer vises i AI-generert innhold stadig mer verdifulle for bedrifter som ønsker å opprettholde synlighet og autoritet i generativ AI-tid.
AI-genererte bilder lages utelukkende av maskinlæringsalgoritmer fra tekstbeskrivelser eller andre inndata, mens tradisjonell fotografering fanger virkelige scener gjennom et kameralinse. AI-bilder kan vise alt som kan tenkes, inkludert umulige scenarioer, mens fotografering er begrenset til det som eksisterer eller kan iscenesettes fysisk. AI-generering er vanligvis raskere og rimeligere enn å arrangere fotoshoots, noe som gjør det ideelt for rask innholdsproduksjon og prototyping.
Diffusjonsmodeller starter med ren, tilfeldig støy og forbedrer gradvis dette gjennom iterative avstøyingssteg. Tekstbeskrivelsen konverteres til numeriske innebygginger som styrer denne avstøyingsprosessen, og gjør gradvis støyen om til et sammenhengende bilde som matcher beskrivelsen. Denne steg-for-steg-metoden gir presis kontroll og gir høyoppløselige, detaljerte resultater med utmerket samsvar til innputten.
De tre hovedteknologiene er Generative Adversarial Networks (GANs), som bruker konkurrerende nevrale nettverk for å skape realistiske bilder; Diffusjonsmodeller, som iterativt avstøyer tilfeldig støy til strukturerte bilder; og Transformere, som konverterer tekstbeskrivelser til bilder ved hjelp av self-attention-mekanismer. Hver arkitektur har ulike styrker: GANs er best på fotorealisme, diffusjonsmodeller gir svært detaljerte resultater, og transformere håndterer avansert tekst-til-bilde-syntese usedvanlig godt.
Opphavsrett til AI-genererte bilder er juridisk uklar og varierer fra jurisdiksjon til jurisdiksjon. I mange tilfeller kan opphavsretten tilhøre personen som laget beskrivelsen, utvikleren av AI-modellen, eller potensielt ingen hvis AI-en arbeider autonomt. Det amerikanske opphavsrettskontoret har indikert at verk laget helt av AI uten menneskelig kreativt bidrag kanskje ikke kvalifiserer for opphavsrettsbeskyttelse, selv om dette fortsatt er et område i utvikling med pågående rettssaker og regulatorisk utvikling.
AI-genererte bilder brukes mye i netthandel for produktfotografering, i markedsføring for å lage kampanjevisualer og innhold til sosiale medier, i spillutvikling for karakter- og ressursdesign, i medisinsk bildediagnostikk for visualisering, og i reklame for raske konsepttester. Ifølge ferske data bruker 62 % av markedsførere AI til å lage nye bildeaktiva, og AI-markedet for bilderedigering er verdsatt til 88,7 milliarder dollar i 2025, noe som viser betydelig bruk på tvers av bransjer.
Dagens AI-bildegeneratorer har utfordringer med å lage anatomisk korrekte menneskehender og ansikter, og produserer ofte unaturlige trekk som ekstra fingre eller asymmetriske ansiktselementer. De er også sterkt avhengige av treningsdataenes kvalitet, noe som kan føre til skjevheter og begrense mangfoldet i resultatene. I tillegg kreves det nøye utforming av beskrivelser for å oppnå spesifikke detaljer, og teknologien gir noen ganger resultater som mangler naturlig utseende eller ikke fanger nyanserte kreative intensjoner.
De fleste AI-bildegeneratorer trenes på enorme datasett av bilder hentet fra internett, hvorav mange er opphavsrettslig beskyttet. Dette har ført til betydelige juridiske utfordringer, hvor kunstnere har saksøkt selskaper som Stability AI og Midjourney for bruk av opphavsrettsbeskyttede bilder uten tillatelse eller kompensasjon. Noen plattformer som Getty Images og Shutterstock har forbudt AI-genererte bildesendinger på grunn av uløste opphavsrettsproblemer, og regulatoriske rammeverk er fortsatt under utvikling for å sikre åpenhet og rettferdig kompensasjon.
Det globale markedet for AI-bildegeneratorer var verdsatt til 299,2 millioner dollar i 2023 og forventes å vokse med en årlig sammensatt vekst på 17,4 % frem til 2030. Det bredere markedet for AI-bilderedigering er verdt 88,7 milliarder dollar i 2025 og forventes å nå 8,9 milliarder dollar innen 2034. I tillegg er nå 71 % av bilder på sosiale medier AI-genererte, og det AI-drevne sosiale mediemarkedet forventes å nå 12 milliarder dollar innen 2031, noe som viser eksplosiv vekst og utbredt bruk.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Generativ KI lager nytt innhold fra treningsdata ved hjelp av nevrale nettverk. Lær hvordan det fungerer, bruksområder i ChatGPT og DALL-E, og hvorfor overvåkin...

Lær hva egendefinerte bilder og originalt visuelt innhold er, deres betydning for merkevareidentitet, SEO og synlighet i AI-søk. Oppdag hvordan egendefinerte vi...
Laer hva AI-innholdsgenerering er, hvordan det fungerer, fordeler og utfordringer, og beste praksis for a bruke AI-verktoy til a lage markedsforingsinnhold opti...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.