Definisjon av oppmerksomhetsmekanisme
Oppmerksomhetsmekanisme er en maskinlæringsteknikk som styrer dype læringsmodeller til å prioritere (eller “fokusere på”) de mest relevante delene av inndata når de gjør prediksjoner. I stedet for å behandle alle inndataelementer likt, beregner oppmerksomhetsmekanismer oppmerksomhetsvekter som reflekterer den relative viktigheten av hvert element for oppgaven, og bruker så disse vektene til dynamisk å fremheve eller nedtone spesifikke inndata. Denne grunnleggende innovasjonen har blitt hjørnesteinen i moderne transformer-arkitekturer og store språkmodeller (LLMs) som ChatGPT, Claude og Perplexity, og gjør det mulig å behandle sekvensielle data med enestående effektivitet og nøyaktighet. Mekanismen er inspirert av menneskelig kognitiv oppmerksomhet—evnen til selektivt å fokusere på viktige detaljer samtidig som irrelevant informasjon filtreres bort—og oversetter dette biologiske prinsippet til en matematisk streng og lærbar komponent i nevrale nettverk.
Historisk kontekst og utvikling
Konseptet oppmerksomhetsmekanismer ble først introdusert av Bahdanau og kolleger i 2014 for å løse kritiske begrensninger i rekurrente nevrale nettverk (RNNs) brukt til maskinoversettelse. Før oppmerksomhet ble introdusert, var Seq2Seq-modeller avhengig av en enkelt kontekstvektor for å kode hele kildesetninger, noe som skapte en informasjonsflaskehals som reduserte ytelsen betydelig på lengre sekvenser. Den originale oppmerksomhetsmekanismen lot dekoderen få tilgang til alle skjulte tilstander fra enkoderen, ikke bare den siste, og kunne dermed dynamisk velge hvilke deler av inndata som var mest relevante ved hvert dekodetrinn. Dette gjennombruddet forbedret oversettelseskvaliteten dramatisk, spesielt for lengre setninger. I 2015 introduserte Luong og kolleger dot-produkt oppmerksomhet, som erstattet den datamessig dyre additiv oppmerksomheten med effektiv matrise-multiplikasjon. Det avgjørende øyeblikket kom i 2017 med publiseringen av “Attention is All You Need”, som introduserte transformer-arkitekturen som forkastet rekurrens til fordel for ren oppmerksomhet. Denne artikkelen revolusjonerte dyp læring og la grunnlaget for BERT, GPT-modeller og hele det moderne generative AI-økosystemet. I dag er oppmerksomhetsmekanismer allestedsnærværende innen naturlig språkbehandling, datamaskinsyn og multimodale AI-systemer, med over 85% av toppmoderne modeller som inkluderer en eller annen form for oppmerksomhetsbasert arkitektur.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Teknisk arkitektur og komponenter
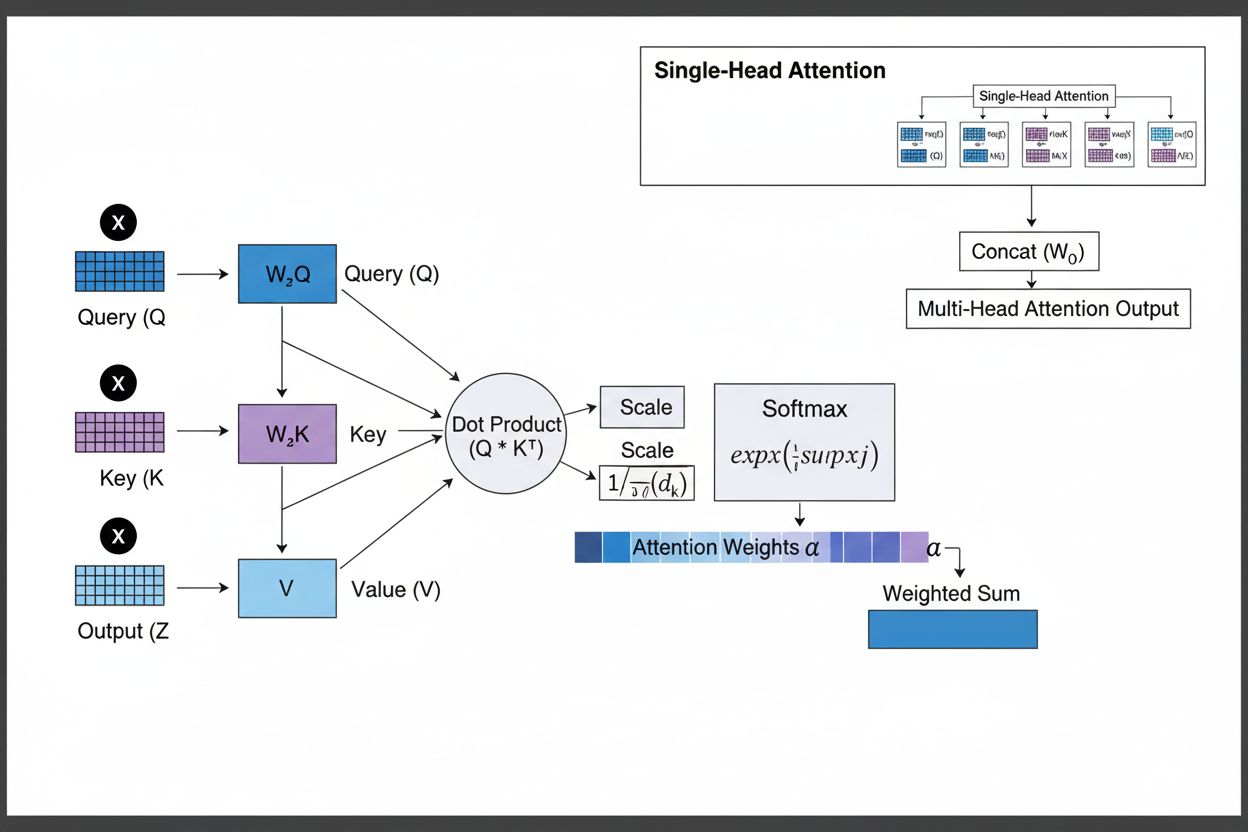
Oppmerksomhetsmekanismen fungerer gjennom et sofistikert samspill mellom tre kjernekomponenter: forespørsler (Q), nøkler (K) og verdier (V). Hvert inndataelement transformeres til disse tre representasjonene gjennom lærte lineære projeksjoner, og skaper en database-lignende struktur hvor nøkler fungerer som identifikatorer og verdier inneholder selve informasjonen. Mekanismen beregner justeringspoeng ved å måle likheten mellom en forespørsel og alle nøkler, vanligvis ved bruk av skalert dot-produkt oppmerksomhet hvor poenget beregnes som QK^T/√d_k. Disse rå poengene normaliseres med softmax-funksjonen, som gjør dem til en sannsynlighetsfordeling hvor alle vekter summerer til 1, slik at hvert element får en verdi mellom 0 og 1. Til slutt beregnes en vektet sum av verdi-vektorene basert på disse oppmerksomhetsvektene, og danner en kontekstvektor som representerer den mest relevante informasjonen fra hele inndatasekvensen. Denne kontekstvektoren kombineres så med den opprinnelige inndataen gjennom residualforbindelser og sendes gjennom feedforward-lag, slik at modellen gradvis kan forbedre forståelsen av inndata. Den matematiske elegansen i dette designet—kombinasjonen av lærbare transformasjoner, likhetsberegninger og sannsynlighetsvekting—gjør at oppmerksomhetsmekanismer kan fange opp komplekse avhengigheter og samtidig være fullt differensierbare for gradientbasert optimalisering.
Sammenligning av varianter av oppmerksomhetsmekanismer
| Oppmerksomhetstype | Beregning | Beregningstid | Beste brukstilfelle | Nøkkelfordel |
|---|
| Additiv oppmerksomhet | Feed-forward nettverk + tanh aktivering | O(n·d) per forespørsel | Kortere sekvenser, variable dimensjoner | Håndterer ulike query/key-dimensjoner |
| Dot-produkt oppmerksomhet | Enkel matrise-multiplikasjon | O(n·d) per forespørsel | Standardsekvenser | Regnemessig effektiv |
| Skalert dot-produkt | QK^T/√d_k + softmax | O(n·d) per forespørsel | Moderne transformere | Forhindrer gradientforvitring |
| Multi-head oppmerksomhet | Flere parallelle oppmerksomhetshoder | O(h·n·d) hvor h=hoder | Komplekse relasjoner | Fanger opp ulike semantiske aspekter |
| Selvoppmerksomhet | Forespørsler, nøkler, verdier fra samme sekvens | O(n²·d) | Intra-sekvensrelasjoner | Muliggjør parallell behandling |
| Kryssoppmerksomhet | Forespørsler fra én sekvens, nøkler/verdier fra en annen | O(n·m·d) | Encoder-decoder, multimodal | Tilpasser ulike modaliteter |
| Grouped Query Attention | Deler nøkler/verdier på tvers av query-hoder | O(n·d) | Effektiv inferens | Reduserer minne og beregning |
| Sparsom oppmerksomhet | Begrenset oppmerksomhet til lokale/stride posisjoner | O(n·√n·d) | Svært lange sekvenser | Håndterer ekstreme sekvenslengder |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Hvordan oppmerksomhetsmekanismer fungerer i praksis
Oppmerksomhetsmekanismen fungerer gjennom en nøye orkestrert sekvens av matematiske transformasjoner som gjør det mulig for nevrale nettverk å fokusere dynamisk på relevant informasjon. Når en inndatasekvens behandles, blir hvert element først kodet inn i et høy-dimensjonalt vektorrom som fanger semantisk og syntaktisk informasjon. Disse embeddingene projiseres så inn i tre separate rom gjennom lærte vektmatriser: forespørselsrommet (hva som søkes etter), nøkkelrommet (hva hvert element inneholder av informasjon) og verdirrommet (hvilken informasjon som skal aggregeres). For hver forespørsel beregnes et likhetspoeng med hver nøkkel gjennom dot-produkt, og gir en vektor med rå justeringspoeng. Disse poengene skaleres ved å dele på kvadratroten av nøkkeldimensjonen (√d_k)—et kritisk steg for å forhindre at dot-produktene blir for store ved høye dimensjoner, noe som ellers ville ført til at gradientene forsvinner under tilbakepropagering. De skalerte poengene sendes gjennom en softmax-funksjon som eksponentierer og normaliserer poengene slik at de summerer til 1, og danner en sannsynlighetsfordeling over alle inndataposisjoner. Til slutt brukes disse oppmerksomhetsvektene til å beregne et vektet gjennomsnitt av verdi-vektorene, hvor posisjoner med høyere oppmerksomhetsvekt gir større bidrag til den endelige kontekstvektoren. Denne kontekstvektoren kombineres så med original inndata gjennom residualforbindelser og prosesseres videre gjennom feedforward-lag, slik at modellen gradvis kan forbedre sine representasjoner. Hele prosessen er differensierbar, slik at modellen kan lære optimale oppmerksomhetsmønstre gjennom gradientbasert trening.
Oppmerksomhetsmekanismer utgjør grunnsteinen i transformer-arkitekturer, som har blitt det dominerende paradigmet innen dyp læring. I motsetning til RNNs som behandler sekvenser sekvensielt og CNNs som opererer på faste, lokale vinduer, bruker transformere selvoppmerksomhet slik at hver posisjon direkte kan fokusere på alle andre posisjoner samtidig, og muliggjør massiv parallellisering over GPU-er og TPU-er. Transformer-arkitekturen består av alternerende lag med multi-head selvoppmerksomhet og feedforward-nettverk, hvor hvert oppmerksomhetslag lar modellen forbedre forståelsen av inndata ved selektivt å fokusere på ulike aspekter. Multi-head oppmerksomhet kjører flere oppmerksomhetsmekanismer parallelt, hvor hvert hode lærer å fokusere på ulike typer relasjoner—ett kan spesialisere seg på grammatiske avhengigheter, et annet på semantiske sammenhenger, et tredje på langdistanse referanser. Utgangene fra alle hodene sammenkobles og projiseres, slik at modellen kan opprettholde bevissthet om mange språklige fenomener samtidig. Denne arkitekturen har vist seg svært effektiv for store språkmodeller som GPT-4, Claude 3 og Gemini, som bruker dekoder-bare transformerarkitekturer der hvert token kun kan fokusere på tidligere tokens (kausal maskering) for å opprettholde den autoregressive generasjonsegenskapen. Oppmerksomhetsmekanismens evne til å fange opp langtrekkende avhengigheter uten gradientproblemene som plaget RNN-er, har vært avgjørende for at disse modellene kan behandle kontekstvinduer på 100 000+ tokens og samtidig opprettholde sammenheng og konsistens gjennom store mengder tekst. Forskning viser at omtrent 92% av toppmoderne NLP-modeller nå er avhengige av transformerarkitekturer drevet av oppmerksomhetsmekanismer, noe som understreker deres fundamentale betydning for moderne AI-systemer.
Oppmerksomhetsmekanismer i AI-søk og overvåking
I sammenheng med AI-søkeplattformer som ChatGPT, Perplexity, Claude og Google AI Overviews spiller oppmerksomhetsmekanismer en avgjørende rolle i å avgjøre hvilke deler av hentede dokumenter og kunnskapsbaser som er mest relevante for brukerens forespørsel. Når disse systemene genererer svar, vekter oppmerksomhetsmekanismene dynamisk ulike kilder og avsnitt basert på relevans, slik at de kan syntetisere sammenhengende svar fra flere kilder og samtidig opprettholde faktanøyaktighet. Oppmerksomhetsvektene som beregnes under generering, kan analyseres for å forstå hvilken informasjon modellen prioriterte, og gir innsikt i hvordan AI-systemer tolker og besvarer spørsmål. For merkevareovervåking og GEO (Generative Engine Optimization) er forståelse av oppmerksomhetsmekanismer essensielt fordi de avgjør hvilket innhold og hvilke kilder som får fremhevet plass i AI-genererte svar. Innhold som er strukturert i tråd med hvordan oppmerksomhetsmekanismer vekter informasjon—gjennom tydelige enhetsdefinisjoner, autoritative kilder og kontekstuell relevans—er mer sannsynlig å bli sitert og fremhevet i AI-svar. AmICited utnytter innsikt i oppmerksomhetsmekanismer for å spore hvordan merkevarer og domener vises på tvers av AI-plattformer, fordi oppmerksomhetsvektede sitater representerer de mest innflytelsesrike referansene i AI-generert innhold. Etter hvert som virksomheter i økende grad overvåker sin tilstedeværelse i AI-svar, blir det kritisk å forstå at oppmerksomhetsmekanismer styrer siteringsmønsteret for å optimalisere innholdsstrategien og sikre merkevaresynlighet i den generative AI-æraen.
Viktige aspekter og implementeringshensyn
- Beregningseffektivitet: Skalert dot-produkt oppmerksomhet gir O(n²) kompleksitet med massiv parallellisering, noe som gjør det praktisk for sekvenser på tusenvis av tokens på moderne GPU-er
- Gradientflyt: Skaleringsfaktoren (1/√d_k) forhindrer gradientforvitring og muliggjør stabil trening av svært dype nettverk med mange oppmerksomhetslag
- Tolkbarhet: Oppmerksomhetsvekter gir tolkbare visualiseringer som viser hvilke inndataelementer som påvirket bestemte prediksjoner, og øker modellens transparens
- Posisjonskoding: Transformere krever eksplisitt posisjonsinformasjon gjennom sinusformede eller roterende kodinger siden oppmerksomhet ikke i seg selv bevarer rekkefølge
- Kausal maskering: Autoregressive modeller som GPT bruker kausal maskering for å forhindre at tokens fokuserer på fremtidige posisjoner, og opprettholder generasjonsegenskapen
- Minneeffektivitet: Varianter som grouped query attention og sparsom oppmerksomhet reduserer minnekrav fra O(n²) til O(n·√n) for svært lange sekvenser
- Multiskala oppmerksomhet: Ulike oppmerksomhetshoder lærer å fokusere på ulike kontekstskalaer, fra lokale ordrelasjoner til dokumentnivå-temaer
- Tverrmodal tilpasning: Kryssoppmerksomhet gjør det mulig for modeller som Stable Diffusion å tilpasse tekstforespørsler til bildegenerering, og synspråklige modeller å forankre språk i visuell informasjon
Utvikling og fremtidige retninger
Feltet oppmerksomhetsmekanismer utvikler seg raskt, med stadig mer sofistikerte varianter som adresserer beregningsbegrensninger og forbedrer ytelsen. Sparsomme oppmerksomhetsmønstre begrenser oppmerksomhet til lokale nabolag eller stride posisjoner, og reduserer kompleksiteten fra O(n²) til O(n·√n) samtidig som ytelsen opprettholdes på svært lange sekvenser. Effektive oppmerksomhetsmekanismer som FlashAttention optimaliserer minnetilgangen under oppmerksomhetsberegningen, og oppnår 2-4x hastighetsøkning gjennom bedre GPU-utnyttelse. Grouped query attention og multi-query attention reduserer antallet key-value-hoder uten å gå på bekostning av ytelse, og minsker minnekravene betydelig under inferens—et kritisk hensyn ved utrulling av store modeller i produksjon. Mixture of Experts-arkitekturer kombinerer oppmerksomhet med sparsom ruting, slik at modeller kan skalere til billioner av parametre og samtidig opprettholde regneffektiviteten. Fremvoksende forskning utforsker lærte oppmerksomhetsmønstre som tilpasser seg dynamisk basert på input, og hierarkisk oppmerksomhet som opererer på flere abstraksjonsnivåer. Integrasjon av oppmerksomhetsmekanismer med retrieval-augmented generation (RAG) muliggjør at modeller kan fokusere på relevant ekstern kunnskap, forbedrer faktaverdien og reduserer hallusinasjoner. Etter hvert som AI-systemer tas i bruk i stadig mer kritiske applikasjoner, forbedres oppmerksomhetsmekanismer med forklarbarhetsfunksjoner som gir tydeligere innsikt i modellens beslutninger. Fremtiden vil trolig involvere hybridarkitekturer som kombinerer oppmerksomhet med alternative mekanismer som state-space modeller (eksemplifisert av Mamba), som gir lineær kompleksitet og samtidig opprettholder konkurransedyktig ytelse. Å forstå disse utviklende oppmerksomhetsmekanismene er avgjørende for praktikere som bygger neste generasjons AI-systemer og for organisasjoner som overvåker sin tilstedeværelse i AI-generert innhold, siden mekanismene som avgjør siteringsmønstre og innholdssynlighet stadig utvikler seg.
Oppmerksomhetsmekanismer og AI-siteringsmønstre
For organisasjoner som bruker AmICited for å overvåke merkevaresynlighet i AI-svar, gir forståelse av oppmerksomhetsmekanismer viktig kontekst for å tolke siteringsmønstre. Når ChatGPT, Claude eller Perplexity siterer ditt domene i sine svar, har oppmerksomhetsvektene som ble beregnet under genereringen avgjort at ditt innhold var mest relevant for brukerens spørsmål. Høykvalitets, godt strukturert innhold som tydelig definerer entiteter og gir autoritativ informasjon får naturlig høyere oppmerksomhetsvekter, og er derfor mer sannsynlig å bli valgt for sitering. Oppmerksomhetsvisualisering i enkelte AI-plattformer viser hvilke kilder som fikk mest fokus under svargenereringen, og avslører hvilke sitater som var mest innflytelsesrike. Denne innsikten lar organisasjoner optimalisere innholdsstrategien ved å forstå at oppmerksomhetsmekanismer belønner klarhet, relevans og autoritativ kildebruk. Etter hvert som AI-søk vokser—med over 60% av virksomheter som nå investerer i generativ AI—blir evnen til å forstå og optimalisere for oppmerksomhetsmekanismer stadig mer verdifull for å opprettholde merkevaresynlighet og sikre nøyaktig representasjon i AI-generert innhold. Skjæringspunktet mellom oppmerksomhetsmekanismer og merkevareovervåking representerer en ny front innen GEO, hvor forståelse av de matematiske prinsippene bak hvordan AI-systemer vekter og siterer informasjon direkte gir bedre synlighet og innflytelse i det generative AI-økosystemet.