
Optimalisering av crawl-budsjett for KI
Lær hvordan du optimaliserer crawl-budsjett for KI-boter som GPTBot og Perplexity. Oppdag strategier for å håndtere serverressurser, forbedre KI-synlighet og ko...
9 min lesing

Crawl budget er antallet sider søkemotorer tildeler ressurser til å gjennomsøke på et nettsted innenfor et bestemt tidsrom, bestemt av gjennomgangskapasitet og gjennomgangsetterspørsel. Det representerer de begrensede ressursene søkemotorer fordeler på milliarder av nettsteder for å oppdage, gjennomsøke og indeksere innhold effektivt.
Crawl budget er antallet sider søkemotorer tildeler ressurser til å gjennomsøke på et nettsted innenfor et bestemt tidsrom, bestemt av gjennomgangskapasitet og gjennomgangsetterspørsel. Det representerer de begrensede ressursene søkemotorer fordeler på milliarder av nettsteder for å oppdage, gjennomsøke og indeksere innhold effektivt.
Crawl budget er antallet sider som søkemotorer tildeler ressurser til å gjennomsøke på et nettsted innenfor et bestemt tidsrom, vanligvis målt daglig eller månedlig. Det representerer en begrenset tildeling av databehandlingsressurser som søkemotorer som Google, Bing og nye AI-crawlere fordeler på milliarder av nettsteder på internett. Konseptet oppsto fra den grunnleggende realiteten at søkemotorer ikke kan gjennomsøke hver side på hvert nettsted samtidig—de må prioritere og tildele sin begrensede infrastruktur strategisk. Crawl budget påvirker direkte om nettstedets sider blir oppdaget, indeksert og til slutt rangert i søkeresultatene. For store nettsteder med tusenvis eller millioner av sider kan effektiv håndtering av crawl budget bety forskjellen mellom omfattende indeksering og at viktige sider forblir uoppdaget i uker eller måneder.
Konseptet crawl budget ble formalisert innen søkemotoroptimalisering rundt 2009 da Google begynte å publisere retningslinjer for hvordan deres gjennomgangssystemer fungerer. I starten fokuserte de fleste SEO-eksperter på tradisjonelle rangeringsfaktorer som nøkkelord og tilbake-lenker, og overså stort sett den tekniske infrastrukturen som gjorde indeksering mulig. Etter hvert som nettsteder vokste eksponentielt i størrelse og kompleksitet, spesielt med fremveksten av nettbutikker og innholdstunge sider, sto søkemotorene overfor nye utfordringer med å gjennomsøke og indeksere alt tilgjengelig innhold effektivt. Google erkjente denne begrensningen og introduserte begrepet crawl budget for å hjelpe nettredaktører å forstå hvorfor ikke alle sidene deres ble indeksert til tross for teknisk tilgjengelighet. Ifølge Google Search Central overstiger nettet Googles evne til å utforske og indeksere hver tilgjengelig URL, noe som gjør håndtering av crawl budget avgjørende for store nettsteder. I dag, med AI-crawlertrafikk som har økt med 96 % mellom mai 2024 og mai 2025, og GPTBots andel hoppet fra 5 % til 30 %, har crawl budget blitt enda mer kritisk ettersom flere gjennomgangssystemer konkurrerer om serverressurser. Denne utviklingen gjenspeiler det bredere skiftet mot generativ engine optimization (GEO) og behovet for at merkevarer sikrer synlighet både i tradisjonelle søk og på AI-drevne plattformer.
Crawl budget bestemmes av to hovedkomponenter: crawl capacity limit og crawl demand. Crawl capacity limit representerer det maksimale antallet samtidige tilkoblinger og tidsforsinkelsen mellom hentingene som en søkemotor kan bruke uten å overbelaste et nettsteds servere. Denne grensen er dynamisk og justeres basert på flere faktorer. Dersom et nettsted svarer raskt på forespørsler fra crawlere og returnerer minimale serverfeil, øker kapasitetsgrensen, slik at søkemotorer kan bruke flere parallelle tilkoblinger og gjennomsøke flere sider. Motsatt, hvis et nettsted opplever treg respons, tidsavbrudd eller hyppige 5xx-serverfeil, reduseres kapasitetsgrensen som et beskyttelsestiltak for å unngå overbelastning av serveren. Crawl demand, den andre komponenten, reflekterer hvor ofte søkemotorer ønsker å besøke og gjennomsøke innhold basert på dets opplevde verdi og oppdateringsfrekvens. Populære sider med mange tilbake-lenker og høy søketrafikk får høyere crawl demand og blir gjennomsøkt oftere. Nyhetsartikler og hyppig oppdatert innhold får høyere crawl demand enn statiske sider, som for eksempel bruksvilkår. Kombinasjonen av disse to faktorene—hva serveren kan håndtere og hva søkemotorene ønsker å gjennomsøke—bestemmer ditt effektive crawl budget. Denne balanserte tilnærmingen sikrer at søkemotorene kan oppdage nytt innhold samtidig som de respekterer serverkapasiteten.
| Konsept | Definisjon | Måling | Innvirkning på indeksering | Primær kontroll |
|---|---|---|---|---|
| Crawl Budget | Totalt antall sider søkemotorer tildeler for gjennomsøking innenfor et tidsrom | Sider per dag/måned | Direkte—avgjør hvilke sider som blir oppdaget | Indirekte (autoritet, hastighet, struktur) |
| Crawl Rate | Faktisk antall sider gjennomsøkt per dag | Sider per dag | Informasjonsmessig—viser nåværende crawl-aktivitet | Serverens responstid, sidehastighet |
| Crawl Capacity Limit | Maksimalt antall samtidige tilkoblinger serveren kan håndtere | Tilkoblinger per sekund | Begrensning for crawl budget-tak | Serverinfrastruktur, hostingkvalitet |
| Crawl Demand | Hvor ofte søkemotorer ønsker å gjennomsøke innhold | Frekvens for gjennomsøking | Bestemmer prioritet innenfor budsjettet | Innholdsaktualitet, popularitet, autoritet |
| Index Coverage | Prosentandel av gjennomsøkte sider som faktisk indekseres | Indekserte sider / gjennomsøkte sider | Resultatmåling—viser suksess for indeksering | Innholdskvalitet, kanonisering, noindex-tagger |
| Robots.txt | Fil som styrer hvilke URL-er søkemotorer kan gjennomsøke | Blokkerte URL-mønstre | Beskyttende—hindrer sløsing av budsjett på uønskede sider | Direkte—du styrer via robots.txt-regler |
Crawl budget opererer gjennom et sofistikert system av algoritmer og ressursallokering som søkemotorene kontinuerlig justerer. Når Googlebot (Googles hovedcrawler) besøker nettstedet ditt, vurderer den flere signaler for å avgjøre hvor aggressivt den skal gjennomsøke. Crawleren vurderer først serverens helse ved å overvåke responstider og feilrater. Hvis serveren konsekvent svarer innen 200-500 millisekunder og returnerer minimale feil, tolker Google dette som en sunn, godt vedlikeholdt server som tåler økt crawl-trafikk. Crawleren øker da crawl capacity limit, og kan potensielt bruke flere parallelle tilkoblinger for å hente sider samtidig. Dette er grunnen til at optimalisering av sidehastighet er så kritisk—raskere sider lar søkemotorene gjennomsøke flere URL-er i samme tidsrom. Omvendt, hvis sider bruker 3-5 sekunder på å laste eller ofte får tidsavbrudd, reduserer Google kapasiteten for å beskytte serveren mot overbelastning. I tillegg til serverhelse analyserer søkemotorene nettstedets URL-inventar for å bestemme crawl demand. De ser på hvilke sider som har interne lenker, hvor mange eksterne tilbake-lenker hver side får, og hvor ofte innholdet oppdateres. Sider lenket fra forsiden får høyere prioritet enn sider dypt begravet i nettstedets hierarki. Sider med nylige oppdateringer og høy trafikk blir gjennomsøkt oftere. Søkemotorene bruker også sitemaps som veiledningsdokumenter for å forstå nettstedets struktur og innholdsprioriteringer, selv om sitemaps er forslag og ikke absolutte krav. Algoritmen balanserer kontinuerlig disse faktorene og justerer crawl budget dynamisk basert på sanntidsytelse og vurdering av innholdsverdi.
Den praktiske betydningen av crawl budget for SEO-ytelse kan ikke overdrives, spesielt for store nettsteder og raskt voksende plattformer. Når et nettsteds crawl budget er brukt opp før alle viktige sider blir oppdaget, kan disse uoppdagede sidene ikke indekseres og dermed ikke rangere i søkeresultatene. Dette har en direkte innvirkning på inntekter—sider som ikke er indeksert genererer ingen organisk trafikk. For nettbutikker med hundretusener av produktsider betyr ineffektiv håndtering av crawl budget at noen produkter aldri vises i søkeresultatene og dermed reduserer salget direkte. For nyhetspublisister betyr treg utnyttelse av crawl budget at nyhetssaker bruker dager på å bli synlige i søk i stedet for timer, og reduserer konkurransefortrinnet. Forskning fra Backlinko og Conductor viser at nettsteder med optimalisert crawl budget får betydelig raskere indeksering av nytt og oppdatert innhold. Ett dokumentert tilfelle viste at et nettsted som forbedret sidehastigheten med 50 % opplevde en firedobling i daglig crawl-volum—from 150 000 til 600 000 URL-er per dag. Denne dramatiske økningen førte til at nytt innhold ble oppdaget og indeksert i løpet av timer i stedet for uker. For AI-synlighet i søk blir crawl budget enda viktigere. Etter hvert som AI-crawlere som GPTBot, Claude Bot og Perplexity Bot konkurrerer om serverressurser sammen med tradisjonelle søkemotorcrawlere, kan nettsteder med dårlig crawl budget-optimalisering oppleve at innholdet ikke blir besøkt ofte nok av AI-systemer til å bli sitert i AI-genererte svar. Dette påvirker direkte synligheten i AI Overviews, ChatGPT-svar og andre generative søkeplattformer som AmICited overvåker. Organisasjoner som ikke optimaliserer crawl budget opplever ofte flere SEO-problemer: nye sider tar uker å indeksere, innholdsoppdateringer reflekteres sent i søkeresultater, og konkurrenter med bedre optimaliserte nettsteder kaprer søketrafikk som egentlig skulle tilfalt dem.
Å forstå hva som sløser med crawl budget er avgjørende for optimalisering. Duplikatinnhold representerer en av de største kildene til bortkastet crawl budget. Når søkemotorer møter flere versjoner av det samme innholdet—enten via URL-parametere, sesjons-ID-er eller flere domenevarianter—må de behandle hver versjon separat, noe som bruker crawl budget uten å tilføre verdi til indeksen. En enkelt produktside i en nettbutikk kan generere dusinvis av dupliserte URL-er via ulike filterkombinasjoner (farge, størrelse, prisklasse), som hver bruker crawl budget. Omdirigeringskjeder sløser crawl budget ved å tvinge søkemotorene til å følge flere hopp før de når den endelige destinasjonssiden. En omdirigeringskjede på fem eller flere hopp kan bruke betydelige crawl-ressurser, og søkemotorer kan slutte å følge kjeden helt. Brutte lenker og soft 404-feil (sider som returnerer statuskode 200 men ikke har reelt innhold) gjør at søkemotorene må gjennomsøke sider som ikke gir verdi. Sider med lav kvalitet—som tynne sider med lite tekst, autogenerert innhold eller sider som ikke gir unik verdi—bruker crawl budget som kunne vært brukt på høykvalitets, unikt innhold. Fasettert navigasjon og sesjons-ID-er i URL-er kan skape nærmest uendelige URL-rom som kan fange crawlere i looper. Ikke-indekserbare sider inkludert i XML-sitemaps villeder søkemotorene om hvilke sider som fortjener crawl-prioritet. Høye sidelasthastigheter og server-timeouts reduserer crawl-kapasiteten ved å signalisere til søkemotorene at serveren ikke tåler aggressiv crawling. Dårlig intern lenkestruktur gjør at viktige sider blir begravd dypt i hierarkiet og vanskeligere for crawlere å oppdage og prioritere. Hver av disse problemene reduserer crawl-effektiviteten; sammen kan de føre til at søkemotorene bare gjennomsøker en brøkdel av det viktige innholdet ditt.
Å optimalisere crawl budget krever en flerfasettert tilnærming som adresserer både teknisk infrastruktur og innholdsstrategi. Forbedre sidehastigheten ved å optimalisere bilder, minifisere CSS og JavaScript, bruke nettlesercaching og innholdsleveringsnettverk (CDN). Raskere sider lar søkemotorene gjennomsøke flere URL-er i samme tidsrom. Konsolider duplikatinnhold ved å implementere riktige omdirigeringer for domenevarianter (HTTP/HTTPS, www/ikke-www), bruke kanoniske tagger for å angi foretrukne versjoner, og blokkere interne søkeresultatsider fra crawling via robots.txt. Håndter URL-parametere ved å bruke robots.txt for å blokkere parameterbaserte URL-er som skaper duplikatinnhold, eller ved å implementere URL-parameterhåndtering i Google Search Console og Bing Webmaster Tools. Fiks brutte lenker og omdirigeringskjeder ved å gjennomgå nettstedet for brutte lenker og sørge for at omdirigeringer peker direkte til sluttmålet i stedet for å lage kjeder. Rydd opp i XML-sitemaps ved å fjerne ikke-indekserbare sider, utgått innhold og sider med feilkoder. Inkluder kun sider du ønsker skal indekseres og som gir unik verdi. Forbedre intern lenkestruktur ved å sikre at viktige sider har flere interne lenker til seg, og lag et flatt hierarki som distribuerer lenkeautoritet utover nettstedet. Blokker sider med lav verdi ved hjelp av robots.txt for å hindre crawlere i å sløse budsjett på admin-sider, dupliserte søkeresultater, handlekurvsider og annet ikke-indekserbart innhold. Overvåk crawl-statistikk regelmessig med Google Search Console’s Crawl Stats-rapport for å spore daglig crawl-volum, identifisere serverfeil og oppdage trender i crawl-adferd. Øk serverkapasiteten hvis du stadig ser crawl rate nå serverens kapasitetsgrense—dette signaliserer at søkemotorene ønsker å gjennomsøke mer, men infrastrukturen ikke tåler det. Bruk strukturert data for å hjelpe søkemotorene å forstå innholdet bedre, noe som kan øke crawl demand for høykvalitetssider. Hold sitemaps oppdatert med <lastmod>-tagg for å signalisere når innhold er oppdatert, slik at søkemotorene kan prioritere re-crawling av nytt innhold.
Ulike søkemotorer og AI-crawlere har forskjellige crawl budgets og adferd. Google er fortsatt mest åpen om crawl budget, og gir detaljerte Crawl Stats-rapporter i Google Search Console som viser daglig crawl-volum, serverens responstider og feilrater. Bing gir lignende data gjennom Bing Webmaster Tools, men vanligvis med mindre detalj. AI-crawlere som GPTBot (OpenAI), Claude Bot (Anthropic) og Perplexity Bot har egne crawl budgets og prioriteringer, ofte med fokus på høykvalitets og autoritetssterkt innhold. Disse AI-crawlerne har hatt eksplosiv vekst—GPTBots andel av crawlertrafikk hoppet fra 5 % til 30 % på bare ett år. For organisasjoner som bruker AmICited til å overvåke AI-synlighet, er det kritisk å forstå at AI-crawlere har egne crawl budgets, adskilt fra tradisjonelle søkemotorer. En side kan være godt indeksert av Google, men sjelden gjennomsøkt av AI-systemer hvis den mangler tilstrekkelig autoritet eller faglig relevans. Mobile-first indeksering betyr at Google primært gjennomsøker og indekserer mobilversjoner av sider, så crawl budget-optimalisering må ta hensyn til ytelsen til mobilnettstedet. Hvis du har separate mobil- og desktop-nettsteder, deler de et crawl budget på samme vert, så mobilhastighet påvirker direkte indeksering av desktop. JavaScript-tunge nettsteder krever ekstra crawl-ressurser fordi søkemotorene må gjengi JavaScript for å forstå innholdet, noe som bruker mer crawl budget per side. Nettsteder som bruker dynamisk rendering eller server-side rendering kan redusere forbruket av crawl budget ved å gjøre innholdet umiddelbart tilgjengelig uten gjengivelse. Internasjonale nettsteder med hreflang-tagger og flere språkversjoner bruker mer crawl budget fordi søkemotorene må gjennomsøke varianter for hvert språk og region. Riktig implementering av hreflang hjelper søkemotorene å forstå hvilken versjon som skal gjennomsøkes og indekseres for hvert marked, noe som forbedrer crawl-effektiviteten.
Fremtiden for crawl budget formes av den eksplosive veksten til AI-søk og generative søkemotorer. Etter hvert som AI-crawlertrafikken økte med 96 % mellom mai 2024 og mai 2025, og GPTBots andel hoppet fra 5 % til 30 %, står nettsteder nå overfor konkurranse om crawl-ressurser fra flere systemer samtidig. Tradisjonelle søkemotorer, AI-crawlere og nye generative engine optimization (GEO)-plattformer konkurrerer alle om serverbåndbredde og crawl-kapasitet. Denne trenden tyder på at optimalisering av crawl budget blir stadig viktigere, ikke mindre. Organisasjoner må overvåke ikke bare Googles crawl-mønstre, men også mønstre fra OpenAIs GPTBot, Anthropics Claude Bot, Perplexitys crawler og andre AI-systemer. Plattformer som AmICited som sporer merkementioner på tvers av AI-plattformer vil bli essensielle verktøy for å forstå om innholdet ditt blir oppdaget og sitert av AI-systemer. Definisjonen av crawl budget kan utvikle seg til å omfatte ikke bare tradisjonell søkemotorcrawling, men også crawling fra AI-systemer og LLM-treningssystemer. Noen eksperter spår at nettsteder vil måtte implementere separate optimaliseringsstrategier for tradisjonelt søk versus AI-søk, og potensielt tildele ulikt innhold og ressurser til hvert system. Fremveksten av robots.txt-utvidelser og llms.txt-filer (som lar nettsteder spesifisere hvilket innhold AI-systemer kan få tilgang til) tyder på at håndteringen av crawl budget blir mer granulær og bevisst. Etter hvert som søkemotorene fortsetter å prioritere E-E-A-T (Erfaring, Ekspertise, Autoritet, Tiltro), vil allokeringen av crawl budget i økende grad favorisere høykvalitets og autoritetssterkt innhold, og dermed potensielt øke forskjellen mellom godt optimaliserte nettsteder og mindre optimaliserte konkurrenter. Integreringen av crawl budget-konseptet i GEO-strategier innebærer at fremtidsrettede organisasjoner vil optimalisere ikke bare for tradisjonell indeksering, men for synlighet på tvers av hele spekteret av søke- og AI-plattformer som målgruppen deres bruker.
Crawl rate refererer til antallet sider en søkemotor gjennomsøker per dag, mens crawl budget er det totale antallet sider en søkemotor vil gjennomsøke i løpet av et bestemt tidsrom. Crawl rate er en målemetode, mens crawl budget er tildelingen av ressurser. For eksempel, hvis Google gjennomsøker 100 sider per dag på nettstedet ditt, er det crawl rate, men ditt månedlige crawl budget kan være 3 000 sider. Å forstå begge målinger hjelper deg å overvåke om søkemotorer bruker sine tildelte ressurser effektivt på nettstedet ditt.
Etter hvert som AI-crawlertrafikken økte med 96 % mellom mai 2024 og mai 2025, og GPTBots andel hoppet fra 5 % til 30 %, har crawl budget blitt stadig mer kritisk for AI-synlighet i søk. Plattformer som AmICited overvåker hvor ofte domenet ditt dukker opp i AI-genererte svar, noe som delvis avhenger av hvor ofte AI-crawlere får tilgang til og indekserer innholdet ditt. Et godt optimalisert crawl budget sikrer at søkemotorer og AI-systemer raskt kan oppdage innholdet ditt, noe som øker sjansen for å bli sitert i AI-svar og opprettholder synligheten både i tradisjonelle og generative søkeplattformer.
Du kan ikke øke crawl budget direkte via en innstilling eller forespørsel til Google. Du kan imidlertid øke det indirekte ved å forbedre nettstedets autoritet gjennom å skaffe flere lenker, øke sidens hastighet og redusere serverfeil. Googles tidligere sjef for webspam, Matt Cutts, bekreftet at crawl budget er omtrent proporsjonalt med nettstedets PageRank (autoritet). I tillegg signaliserer optimalisering av nettstedstruktur, fjerning av duplikatinnhold og eliminering av ineffektiv crawling til søkemotorer at nettstedet ditt fortjener flere crawl-ressurser.
Store nettsteder med over 10 000 sider, nettbutikker med hundretusener av produktsider, nyhetspublisister som legger til dusinvis av artikler daglig, og raskt voksende nettsteder bør prioritere optimalisering av crawl budget. Små nettsteder under 10 000 sider trenger vanligvis ikke bekymre seg for crawl budget-begrensninger. Men hvis du merker at viktige sider bruker uker på å bli indeksert eller ser lav indeksdekning i forhold til totalt antall sider, blir optimalisering av crawl budget kritisk uavhengig av nettstedets størrelse.
Crawl budget bestemmes av skjæringspunktet mellom crawl capacity limit (hvor mye crawling serveren din tåler) og crawl demand (hvor ofte søkemotorer ønsker å gjennomsøke innholdet ditt). Hvis serveren din svarer raskt og ikke har feil, øker kapasiteten, slik at flere samtidige tilkoblinger tillates. Crawl demand øker for populære sider med mange tilbake-lenker og ofte oppdatert innhold. Søkemotorer balanserer disse to faktorene for å fastsette ditt effektive crawl budget og sørger for at de ikke overbelaster serverne dine samtidig som viktig innhold oppdages.
Sidehastighet er en av de mest innflytelsesrike faktorene i optimalisering av crawl budget. Raskere sider gjør at Googlebot kan besøke og behandle flere nettadresser i løpet av samme tidsrom. Forskning viser at når nettsteder øker lastetiden med 50 %, kan crawl rate øke dramatisk—noen nettsteder har sett crawl-volumet øke fra 150 000 til 600 000 nettadresser per dag etter hastighetsoptimalisering. Trege sider bruker mer av crawl budget, slik at søkemotorene får mindre tid til å oppdage annet viktig innhold på nettstedet ditt.
Duplikatinnhold tvinger søkemotorer til å behandle flere versjoner av samme informasjon uten å tilføre verdi til indeksen. Dette sløser crawl budget som kunne vært brukt på unike, verdifulle sider. Vanlige kilder til duplikatinnhold inkluderer interne søkeresultatsider, bildevedleggssider, flere domenevarianter (HTTP/HTTPS, www/ikke-www) og fasetterte navigasjonssider. Ved å konsolidere duplikatinnhold via omdirigeringer, kanoniske tagger og robots.txt-regler frigjør du crawl budget slik at søkemotorene kan oppdage og indeksere flere unike, høykvalitets sider på nettstedet ditt.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Lær hvordan du optimaliserer crawl-budsjett for KI-boter som GPTBot og Perplexity. Oppdag strategier for å håndtere serverressurser, forbedre KI-synlighet og ko...

Lær hva crawl-budsjett for AI betyr, hvordan det skiller seg fra tradisjonelle søkemotorers crawl-budsjett, og hvorfor det er viktig for merkevarens synlighet i...
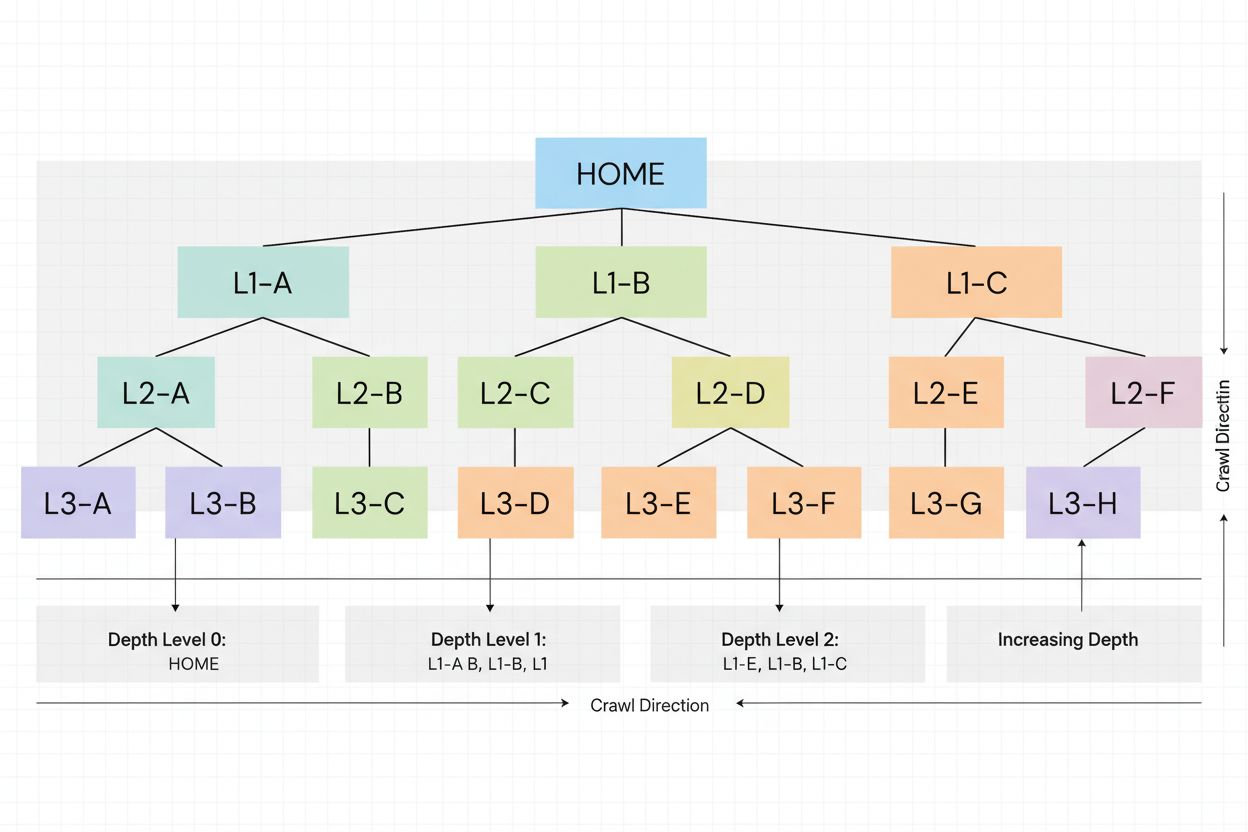
Crawl-dybde er hvor dypt søkemotor-roboter navigerer i din nettsides struktur. Lær hvorfor det er viktig for SEO, hvordan det påvirker indeksering, og strategie...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.