
Crawlability
Crawlability er søkemotorenes evne til å få tilgang til og navigere nettsider. Lær hvordan crawlere fungerer, hva som blokkerer dem, og hvordan du optimaliserer...
12 min lesing
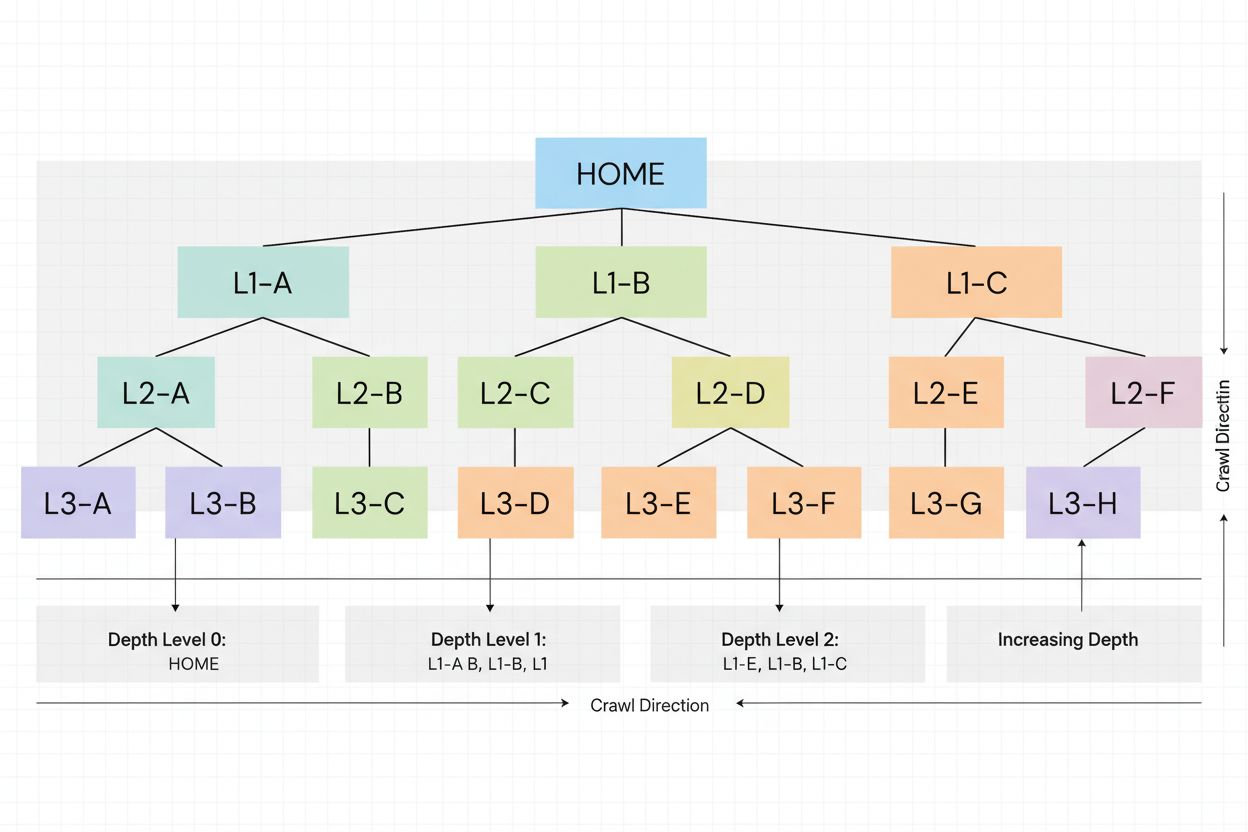
Crawl-dybde viser til hvor langt ned i et nettsteds hierarkiske struktur søkemotorenes crawlere kan komme under én crawl-økt. Det måler antall klikk eller steg som kreves fra forsiden for å nå en bestemt side, og påvirker direkte hvilke sider som blir indeksert og hvor ofte de blir crawlet innenfor nettstedets tildelte crawl-budsjett.
Crawl-dybde viser til hvor langt ned i et nettsteds hierarkiske struktur søkemotorenes crawlere kan komme under én crawl-økt. Det måler antall klikk eller steg som kreves fra forsiden for å nå en bestemt side, og påvirker direkte hvilke sider som blir indeksert og hvor ofte de blir crawlet innenfor nettstedets tildelte crawl-budsjett.
Crawl-dybde er et grunnleggende teknisk SEO-begrep som viser til hvor langt ned i et nettsteds hierarkiske struktur søkemotorcrawlere kan navigere under én crawl-økt. Mer spesifikt måler det antall klikk eller steg som kreves fra forsiden for å nå en bestemt side i nettstedets interne lenkestruktur. Et nettsted med høy crawl-dybde betyr at søkemotorroboter kan få tilgang til og indeksere mange sider over hele nettstedet, mens et nettsted med lav crawl-dybde indikerer at crawlere kanskje ikke når dypere sider før de har brukt opp de tildelte ressursene. Dette konseptet er kritisk fordi det direkte avgjør hvilke sider som blir indeksert, hvor ofte de crawles, og til slutt synligheten deres i søkemotorresultater (SERP).
Betydningen av crawl-dybde har økt de siste årene på grunn av den eksplosive veksten av nettinnhold. Med Googles indeks som inneholder over 400 milliarder dokumenter og økende mengder AI-generert innhold, står søkemotorer overfor store begrensninger på crawl-ressurser. Det betyr at nettsteder med dårlig crawl-dybdeoptimalisering kan oppleve at viktige sider ikke blir indeksert eller sjelden crawlet, noe som påvirker deres organiske synlighet betydelig. Å forstå og optimalisere crawl-dybde er derfor essensielt for ethvert nettsted som ønsker maksimal synlighet i søk.
Ideen om crawl-dybde stammer fra hvordan søkemotorcrawlere (også kalt nettspidere eller roboter) opererer. Når Googles Googlebot eller andre søkemotorcrawlere besøker et nettsted, følger de en systematisk prosess: de starter på forsiden og følger interne lenker for å oppdage flere sider. Crawl-boten får tildelt en begrenset mengde tid og ressurser til hvert nettsted, kjent som crawl-budsjett. Dette budsjettet bestemmes av to faktorer: crawl-kapasitet (hvor mye crawleren kan håndtere uten å overbelaste serveren) og crawl-etterspørsel (hvor viktig og ofte oppdatert nettstedet er). Jo dypere sider ligger i strukturen, desto mindre sannsynlig er det at crawlere rekker dem før budsjettet er brukt opp.
Historisk sett var nettsidestrukturer relativt enkle, med de viktigste sidene innen 2-3 klikk fra forsiden. Etter hvert som netthandel, nyhetsportaler og innholdstunge nettsteder vokste, skapte mange virksomheter dypt nestede strukturer med sider på 5, 6 eller enda flere nivåer. Forskning fra seoClarity og andre SEO-plattformer har vist at sider på dybde 3 og dypere vanligvis presterer dårligere i organiske søkeresultater sammenlignet med sider nærmere forsiden. Denne forskjellen skyldes at crawlere prioriterer sider nærmere roten, som også mottar mer lenkekraft (rankingstyrke) gjennom internlenking. Forholdet mellom crawl-dybde og indekseringsrate er spesielt tydelig på store nettsteder med tusenvis eller millioner av sider, der crawl-budsjettet blir en kritisk begrensning.
Fremveksten av AI-søkemotorer som Perplexity, ChatGPT og Google AI Overviews har gitt crawl-dybdeoptimalisering en ny dimensjon. Disse AI-systemene bruker egne spesialiserte crawlere (som PerplexityBot og GPTBot) med andre mønstre og prioriteringer enn tradisjonelle søkemotorer. Likevel er hovedprinsippet det samme: sider som er lett tilgjengelige og godt integrert i strukturen, blir oftere funnet, crawlet og sitert som kilder i AI-genererte svar. Dermed er crawl-dybdeoptimalisering relevant både for tradisjonell SEO og for AI-synlighet og generative engine optimization (GEO).
| Konsept | Definisjon | Perspektiv | Måling | Innvirkning på SEO |
|---|---|---|---|---|
| Crawl-dybde | Hvor langt ned i nettstedets hierarki crawlere navigerer basert på interne lenker og URL-struktur | Søkemotorcrawlerens syn | Antall klikk/steg fra forside | Påvirker indekseringsfrekvens og -dekning |
| Klikkdybde | Antall brukersklikk som trengs for å nå en side fra forsiden via korteste vei | Brukerens perspektiv | Faktiske klikk som kreves | Påvirker brukeropplevelse og navigasjon |
| Sidedybde | En sides posisjon i nettstedets hierarkiske struktur | Strukturelt syn | URL-nivå/nesting | Påvirker fordeling av lenkekraft |
| Crawl-budsjett | Totale ressurser (tid/båndbredde) tildelt for å crawle et nettsted | Ressursallokering | Sider crawlet per dag | Bestemmer hvor mange sider som blir indeksert |
| Crawl-effektivitet | Hvor effektivt crawlere navigerer og indekserer nettstedets innhold | Optimaliseringsperspektiv | Sider indeksert vs. brukt crawl-budsjett | Maksimerer indeksering innenfor budsjett |
For å forstå hvordan crawl-dybde fungerer, må man se på hvordan søkemotorcrawlere navigerer nettsteder. Når Googlebot eller en annen crawler besøker nettstedet ditt, starter den på forsiden (dybde 0) og følger interne lenker til flere sider. Hver side lenket fra forsiden har dybde 1, sider lenket fra dem har dybde 2, og så videre. Crawleren følger ikke nødvendigvis en lineær vei; den finner ofte flere sider på hvert nivå før den går dypere. Likevel begrenses crawlerens ferd av crawl-budsjettet, som setter en grense for hvor mange sider den kan besøke i løpet av en tidsperiode.
Forholdet mellom crawl-dybde og indeksering styres av flere faktorer. Først spiller crawl-prioritering en sentral rolle—søkemotorer crawlet ikke alle sider likt. De prioriterer sider basert på viktighet, ferskhet og relevans. Sider med flere interne lenker, høy autoritet og nylige oppdateringer crawles oftere. For det andre påvirker URL-strukturen crawl-dybden. En side på /kategori/underkategori/produkt/ har høyere crawl-dybde enn en på /produkt/, selv om begge er lenket fra forsiden. For det tredje er redirect-kjeder og brutte lenker hindringer som sløser med crawl-budsjettet. En redirect-kjede tvinger crawleren til å følge flere omdirigeringer før den når målsiden, noe som bruker opp ressurser.
Teknisk gjennomføring av crawl-dybdeoptimalisering innebærer flere viktige strategier. Internlenkingsstruktur er avgjørende—ved å lenke viktige sider fra forsiden og autoritetssider, reduserer du deres effektive crawl-dybde og øker sjansen for hyppig crawling. XML-sitemaps gir crawlere et kart over nettstedets struktur, slik at de kan oppdage sider mer effektivt uten å kun følge lenker. Nettstedshastighet er også viktig; raske sider lastes raskere inn, slik at crawlere rekker flere sider innenfor budsjettet. Til slutt gir robots.txt og noindex-tagger deg mulighet til å styre hvilke sider crawlere skal prioritere, og hindrer dem i å bruke budsjett på sider med lav verdi som duplikater eller admin-sider.
De praktiske konsekvensene av crawl-dybde strekker seg langt utover tekniske SEO-metrikker—de påvirker forretningsresultater direkte. For netthandelsnettsteder betyr dårlig crawl-dybdeoptimalisering at produktsider dypt inne i kategorihierarkier kanskje ikke blir indeksert, eller indekseres sjelden. Dette gir redusert organisk synlighet, færre produktvisninger i søk, og til slutt tapte salg. En studie fra seoClarity viste at sider med høyere crawl-dybde hadde betydelig lavere indekseringsrate, hvor sider på dybde 4+ ble crawlet opptil 50 % sjeldnere enn sider på dybde 1–2. For store forhandlere med tusenvis av produkter kan dette bety millioner av kroner i tapt organisk inntekt.
For innholdstunge nettsteder som nyhetssider, blogger og kunnskapsbaser påvirker crawl-dybdeoptimalisering hvor lett innholdet blir funnet. Artikler dypt inne i kategoristrukturen kan forbli uindeksert og dermed ikke skape organisk trafikk, uansett kvalitet. Dette er spesielt problematisk for nyhetssider der ferskhet er kritisk—hvis nye artikler ikke crawles og indekseres raskt, mister de muligheten til å rangere på aktuelle temaer. Publisister som optimaliserer crawl-dybde ved å gjøre strukturen flatere og forbedre internlenking, opplever markant økning i indekserte sider og organisk trafikk.
Forholdet mellom crawl-dybde og fordeling av lenkekraft har stor forretningsmessig betydning. Lenkekraft (også kalt PageRank eller rangeringskraft) flyter gjennom interne lenker fra forsiden og utover. Sider nærmere forsiden får mer lenkekraft og har derfor større sjanse til å rangere på konkurransedyktige søkeord. Ved å optimalisere crawl-dybde og sikre at viktige sider ligger 2–3 klikk fra forsiden, kan virksomheter konsentrere lenkekraften på de mest verdifulle sidene—typisk produktsider, tjenestesider eller hjørnesteinsinnhold. Denne strategiske fordelingen kan gi betydelig bedre rangeringer på prioriterte søkeord.
Videre påvirker crawl-dybdeoptimalisering effektiviteten av crawl-budsjettet, noe som blir stadig viktigere etter hvert som nettsteder vokser. Store nettsteder med millioner av sider har strenge crawl-budsjetter. Ved å optimalisere crawl-dybde, fjerne duplikatinnhold, reparere brutte lenker og eliminere redirect-kjeder, sikrer man at crawlere bruker budsjettet på verdifullt, unikt innhold i stedet for å sløse på lavverdisider. Dette er spesielt kritisk for store virksomheter og netthandelsplattformer hvor crawl-budsjettstyring kan bety forskjellen på 80 % vs. 40 % indekserte sider.
Fremveksten av AI-søkemotorer og generative AI-systemer har gitt crawl-dybdeoptimalisering nye utfordringer og muligheter. ChatGPT, drevet av OpenAI, bruker GPTBot til å finne og indeksere nettinnhold. Perplexity, en ledende AI-søkemotor, benytter PerplexityBot. Google AI Overviews (tidligere SGE) bruker Googles egne crawlere for å hente informasjon til AI-genererte sammendrag. Claude, Anthropics AI-assistent, crawler også nettinnhold for opplæring og informasjonsinnhenting. Alle disse systemene har egne crawl-mønstre, prioriteringer og ressursbegrensninger, ulikt tradisjonelle søkemotorer.
Hovedpoenget er at prinsippene for crawl-dybde også gjelder for AI-søkemotorer. Sider som er lett tilgjengelige, godt lenket og strukturelt fremtredende, blir oftere funnet av AI-crawlere og sitert som kilder i AI-genererte svar. Forskning fra AmICited og andre AI-overvåkingsplattformer viser at nettsteder med optimalisert crawl-dybde får flere siteringer i AI-søkeresultater. Dette er fordi AI-systemer prioriterer kilder som er autoritative, tilgjengelige og hyppig oppdatert—alle kjennetegn som henger sammen med lav crawl-dybde og god internstruktur.
Det er likevel noen forskjeller på hvordan AI-crawlere oppfører seg sammenlignet med Googlebot. AI-crawlere kan være mer aggressive og bruke mer båndbredde. De kan også ha andre preferanser for innholdstyper og ferskhet. Noen AI-systemer legger større vekt på nylig oppdatert innhold enn tradisjonelle søkemotorer, noe som gjør crawl-dybdeoptimalisering enda viktigere for å være synlig i AI-søk. I tillegg følger ikke alltid AI-crawlere direktiver som robots.txt eller noindex på samme måte som tradisjonelle søkemotorer, selv om dette er i utvikling etter hvert som AI-aktører tilpasser seg SEO-praksis.
For virksomheter med fokus på AI-synlighet og generative engine optimization (GEO) gir crawl-dybdeoptimalisering dobbel effekt: det forbedrer tradisjonell SEO samtidig som det øker sjansen for at AI-systemer finner, crawle og siterer innholdet ditt. Det gjør crawl-dybdeoptimalisering til en grunnleggende strategi for synlighet på tvers av både tradisjonelle og AI-drevne søkeplattformer.
Optimalisering av crawl-dybde krever en systematisk tilnærming som adresserer både strukturelle og tekniske aspekter ved nettstedet ditt. Følgende beste praksiser har vist seg effektive på tusenvis av nettsteder:
For store virksomhetsnettsteder med tusenvis eller millioner av sider blir crawl-dybdeoptimalisering enda mer kompleks og kritisk. Slike nettsteder har stramme crawl-budsjetter, og det er avgjørende å bruke avanserte strategier. Én tilnærming er allokering av crawl-budsjett, hvor du strategisk bestemmer hvilke sider som skal prioriteres ut fra forretningsverdi. Høyt verdsatte sider (produkt-, tjeneste- og hjørnesteinsinnhold) bør ligge grunt og ofte lenkes til, mens lavverdisider (arkiv, duplikater, tynt innhold) bør settes til noindex eller nedprioriteres.
En annen avansert strategi er dynamisk internlenking, hvor du bruker datadrevne innsikter for å finne ut hvilke sider som trenger flere interne lenker for å forbedre crawl-dybden. Verktøy som seoClaritys Internal Link Analysis kan identifisere sider med for stor dybde og få interne lenker, og avsløre muligheter for bedre crawl-effektivitet. I tillegg gir loggfilanalyse innsikt i hvordan crawlere faktisk navigerer på nettstedet, og avdekker flaskehalser og ineffektiv crawl-struktur. Ved å analysere crawleradferd kan du finne sider som crawles ineffektivt og forbedre tilgjengeligheten deres.
For flerspråklige og internasjonale nettsteder blir crawl-dybde enda viktigere. Hreflang-tagger og god URL-struktur for ulike språkversjoner påvirker crawl-effektiviteten. Ved å sørge for at hver språkversjon har optimal crawl-dybde, maksimerer du indeksering på tvers av markeder. Tilsvarende betyr mobile-first-indeksering at crawl-dybdeoptimalisering må ta hensyn til både desktop og mobil, slik at viktig innhold er tilgjengelig på begge plattformer.
Betydningen av crawl-dybde utvikler seg i takt med søketeknologien. Med fremveksten av AI-søkemotorer og generative AI-systemer blir crawl-dybdeoptimalisering relevant for et bredere publikum enn tradisjonelle SEO-eksperter. Etter hvert som AI-systemene blir mer avanserte, kan de utvikle egne crawl-mønstre og prioriteringer, noe som gjør crawl-dybdeoptimalisering enda viktigere. I tillegg skaper økt volum av AI-generert innhold press på Googles indeks, slik at crawl-budsjettstyring blir avgjørende.
Fremover kan vi forvente flere trender som former crawl-dybdeoptimalisering. For det første vil AI-drevet crawl-optimalisering bli mer avansert, med maskinlæring som identifiserer optimal crawl-struktur for ulike nettsteder. For det andre vil sanntidsovervåking av crawl bli standard, slik at eiere kan se nøyaktig hvordan crawlere navigerer og gjøre raske justeringer. For det tredje vil crawl-dybde-metrikker bli tettere integrert i SEO- og analyseverktøy, slik at ikke-tekniske markedsførere lettere kan forstå og optimalisere denne faktoren.
Forholdet mellom crawl-dybde og AI-synlighet vil sannsynligvis bli et hovedfokus for SEO-fagfolk. Etter hvert som flere brukere stoler på AI-søkemotorer for informasjon, må virksomheter optimalisere både for tradisjonelt søk og for å bli funnet av AI. Dette betyr at crawl-dybdeoptimalisering blir en del av en bredere generative engine optimization (GEO)-strategi som favner både tradisjonell SEO og AI-synlighet. Organisasjoner som mestrer crawl-dybdeoptimalisering tidlig, vil ha et konkurransefortrinn i den AI-drevne søkeverdenen.
Til slutt kan konseptet crawl-dybde endre seg etter hvert som søketeknologien utvikles. Fremtidige søkemotorer kan bruke andre metoder for å finne og indeksere innhold, noe som kan redusere betydningen av tradisjonell crawl-dybde. Likevel vil hovedprinsippet—at lett tilgjengelig og godt strukturert innhold lettere blir funnet og rangert—forbli relevant uansett hvordan søketeknologien utvikler seg. Å investere i crawl-dybdeoptimalisering i dag er derfor en solid, langsiktig strategi for å bevare synlighet på tvers av dagens og fremtidens søkeplattformer.
Crawl-dybde måler hvor langt søkemotor-roboter navigerer gjennom nettstedets hierarki basert på interne lenker og URL-struktur, mens klikkdybde måler hvor mange brukersklikk som kreves for å nå en side fra forsiden. En side kan ha klikkdybde 1 (lenket i bunntekst) men crawl-dybde 3 (liggende dypt i URL-strukturen). Crawl-dybde er fra søkemotorens perspektiv, mens klikkdybde er fra brukerens perspektiv.
Crawl-dybde påvirker ikke rangeringene direkte, men har stor innvirkning på om sider blir indeksert i det hele tatt. Sider som ligger dypt i strukturen blir sjeldnere crawlet innenfor det tildelte crawl-budsjettet, noe som betyr at de kanskje ikke blir indeksert eller oppdatert ofte. Mindre indeksering og ferskhet kan indirekte skade rangeringer. Sider nærmere forsiden får gjerne mer crawl-oppmerksomhet og lenkekraft, noe som gir dem bedre rangeringspotensial.
De fleste SEO-eksperter anbefaler at viktige sider bør være innenfor 3 klikk fra forsiden. Dette gjør dem lett tilgjengelige for både søkemotorer og brukere. For større nettsteder med tusenvis av sider er noe dybde nødvendig, men målet bør være å holde kritiske sider så grunne som mulig. Sider på dybde 3 og dypere presterer vanligvis dårligere i søkeresultater på grunn av redusert crawl-frekvens og lenkekraft.
Crawl-dybde påvirker direkte hvor effektivt du bruker crawl-budsjettet ditt. Google tildeler et spesifikt crawl-budsjett til hvert nettsted basert på crawl-kapasitet og etterspørsel. Hvis nettstedet ditt har stor crawl-dybde med mange sider dypt begravet, kan robotene bruke opp budsjettet før de når alle viktige sider. Ved å optimalisere crawl-dybde og redusere unødvendige lag, sikrer du at det mest verdifulle innholdet blir crawlet og indeksert innenfor budsjettet.
Ja, du kan forbedre crawl-effektivitet uten å omstrukturere hele nettsiden. Strategisk internlenking er det mest effektive—lenk viktige, dype sider fra forsiden, kategorisider eller sider med høy autoritet. Oppdater XML-sitemapet regelmessig, fiks brutte lenker og reduser redirect-kjeder for å hjelpe crawlere å nå sidene mer effektivt. Disse tiltakene forbedrer crawl-dybde uten strukturelle endringer.
AI-søkemotorer som Perplexity, ChatGPT og Google AI Overviews bruker egne spesialiserte crawlere (PerplexityBot, GPTBot, osv.) som kan ha andre crawl-mønstre enn Googlebot. Disse AI-crawlerne følger fortsatt prinsipper for crawl-dybde—sider som er lett tilgjengelige og godt lenket blir oftere funnet og brukt som kilder. Å optimalisere crawl-dybde gagner både tradisjonelle søkemotorer og AI-systemer, og øker synlighet på tvers av søkeplattformer.
Verktøy som Google Search Console, Screaming Frog SEO Spider, seoClarity og Hike SEO gir analyse og visualisering av crawl-dybde. Google Search Console viser crawl-statistikk og frekvens, mens spesialiserte SEO-crawlere visualiserer nettstedets hierarki og finner sider med for stor dybde. Disse verktøyene hjelper deg å identifisere optimaliseringsmuligheter og følge forbedringer av crawl-effektivitet over tid.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Crawlability er søkemotorenes evne til å få tilgang til og navigere nettsider. Lær hvordan crawlere fungerer, hva som blokkerer dem, og hvordan du optimaliserer...

Crawl budget er antallet sider søkemotorer gjennomsøker på nettstedet ditt innenfor et tidsrom. Lær hvordan du optimaliserer crawl budget for bedre indeksering ...
Gjennomgangsfrekvens er hastigheten søkemotorer gjennomgår nettstedet ditt med. Lær hvordan det påvirker indeksering, SEO-ytelse og hvordan du kan optimalisere ...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.