
Hva er en kunnskapsgraf og hvorfor er den viktig? | AI-overvåkning FAQ
Oppdag hva kunnskapsgrafer er, hvordan de fungerer, og hvorfor de er essensielle for moderne databehandling, AI-applikasjoner og forretningsinnsikt.
8 min lesing
En kunnskapsgraf er en database med sammenkoblet informasjon som representerer virkelige enheter—som personer, steder, organisasjoner og konsepter—og illustrerer de semantiske relasjonene mellom dem. Søkemotorer som Google bruker kunnskapsgrafer for å forstå brukerintensjon, levere mer relevante resultater og drive AI-funksjoner som kunnskapspaneler og AI-oversikter.
En kunnskapsgraf er en database med sammenkoblet informasjon som representerer virkelige enheter—som personer, steder, organisasjoner og konsepter—og illustrerer de semantiske relasjonene mellom dem. Søkemotorer som Google bruker kunnskapsgrafer for å forstå brukerintensjon, levere mer relevante resultater og drive AI-funksjoner som kunnskapspaneler og AI-oversikter.
En kunnskapsgraf er en database med sammenkoblet informasjon som representerer virkelige enheter—som personer, steder, organisasjoner og konsepter—og illustrerer de semantiske relasjonene mellom dem. I motsetning til tradisjonelle databaser som organiserer informasjon i faste, tabellariske formater, strukturerer kunnskapsgrafer data som nettverk av noder (enheter) og kanter (relasjoner), noe som gjør det mulig for systemer å forstå mening og kontekst, ikke bare matche nøkkelord. Googles kunnskapsgraf, lansert i 2012, revolusjonerte søk ved å introdusere en enhetsbasert forståelse, som gjorde det mulig for søkemotoren å besvare faktaspørsmål som “Hvor høy er Eiffeltårnet?” eller “Hvor ble sommer-OL 2016 arrangert?” ved å forstå hva brukerne faktisk leter etter, ikke bare ordene de bruker. Per mai 2024 inneholder Googles kunnskapsgraf over 1,6 billioner fakta om 54 milliarder enheter, noe som representerer en enorm økning fra 500 milliarder fakta om 5 milliarder enheter i 2020. Denne veksten reflekterer den økende betydningen av strukturert, semantisk kunnskap for å drive moderne søk, AI-systemer og intelligente applikasjoner på tvers av bransjer.
Konseptet kunnskapsgraf har sitt utspring i flere tiår med forskning på kunstig intelligens, semantiske webteknologier og kunnskapsrepresentasjon. Begrepet fikk imidlertid bred anerkjennelse da Google introduserte sin kunnskapsgraf i 2012, noe som fundamentalt endret hvordan søkemotorer leverer resultater. Før kunnskapsgrafen brukte søkemotorer hovedsakelig nøkkelordmatching—hvis du søkte etter “seal”, ville Google returnere resultater for alle mulige betydninger av ordet uten å forstå hvilken enhet du faktisk ønsket å lære om. Kunnskapsgrafen endret dette paradigmet ved å anvende prinsipper fra ontologi—et formelt rammeverk for å definere enheter, deres attributter og relasjoner—i massiv skala. Dette skiftet fra “strenger til ting” representerte et grunnleggende fremskritt innen søketeknologi, hvor algoritmer kunne forstå at “seal” kunne referere til et sjøpattedyr, en artist, en militærenhet eller en sikkerhetsanordning, og avgjøre hvilken betydning som var mest relevant basert på konteksten. Det globale kunnskapsgrafmarkedet reflekterer denne betydningen, med prognoser som viser vekst fra 1,49 milliarder dollar i 2024 til 6,94 milliarder dollar innen 2030, noe som tilsvarer en årlig vekstrate på omtrent 35 %. Denne eksplosive veksten drives av bedriftsadopsjon i finans, helsevesen, detaljhandel og forsyningskjeder, hvor organisasjoner i økende grad ser at forståelse av enhetsrelasjoner er avgjørende for beslutningstaking, svindeldeteksjon og operasjonell effektivitet.
Kunnskapsgrafer opererer gjennom en sofistikert kombinasjon av datastrukturer, semantiske teknologier og maskinlæringsalgoritmer. I kjernen bruker kunnskapsgrafer en grafstrukturert datamodell bestående av tre grunnleggende komponenter: noder (representerer enheter som personer, organisasjoner eller konsepter), kanter (representerer relasjoner mellom enheter) og etiketter (beskriver forholdets natur). For eksempel, i en enkel kunnskapsgraf kan “Seal” være en node, “er-en” kan være en kantetikett, og “Artist” kan være en annen node, som skaper den semantiske relasjonen “Seal er-en Artist”. Denne strukturen er fundamentalt forskjellig fra relasjonsdatabaser, som tvinger data inn i rader og kolonner med forhåndsdefinerte skjemaer. Kunnskapsgrafer bygges enten med labeled property graphs (som lagrer egenskaper direkte på noder og kanter) eller RDF (Resource Description Framework) triple stores (som representerer all informasjon som subjekt-predikat-objekt-trekløver). Styrken til kunnskapsgrafer ligger i evnen til å integrere data fra flere kilder med ulike strukturer og formater. Når data importeres i en kunnskapsgraf, bruker semantisk berikelse naturlig språkprosessering (NLP) og maskinlæring for å identifisere enheter, trekke ut relasjoner og forstå kontekst. Dette gjør det mulig for kunnskapsgrafer å automatisk gjenkjenne at “IBM”, “International Business Machines” og “Big Blue” alle refererer til samme enhet, og forstå hvordan denne enheten er relatert til andre som “Watson”, “Skybasert databehandling” og “Kunstig intelligens”. Den resulterende sammenkoblede strukturen muliggjør avanserte spørringer og resonnementer som ville vært umulig i tradisjonelle databaser, og gjør det mulig for systemer å besvare komplekse spørsmål ved å traversere relasjoner og utlede ny kunnskap fra eksisterende forbindelser.
| Aspekt | Kunnskapsgraf | Tradisjonell relasjonsdatabase | Grafdatabase |
|---|---|---|---|
| Datastruktur | Noder, kanter og etiketter som representerer enheter og relasjoner | Tabeller, rader og kolonner med forhåndsdefinerte skjemaer | Noder og kanter optimalisert for relasjonstraversering |
| Skjemafleksibilitet | Svært fleksibel; utvikler seg etter hvert som ny informasjon oppdages | Rigid; krever skjema før datainnsending | Fleksibel; støtter dynamisk skjemaendring |
| Håndtering av relasjoner | Naturlig støtte for komplekse, flernivå relasjoner | Krever koblinger på tvers av flere tabeller; kostbart | Optimalisert for effektive relasjonsspørringer |
| Spørringsspråk | SPARQL (for RDF), Cypher (for property graphs), eller egne API-er | SQL | Cypher, Gremlin eller SPARQL |
| Semantisk forståelse | Vektlegger betydning og kontekst gjennom ontologier | Fokuserer på datalagring og uthenting | Fokuserer på effektiv traversering og mønstergjenkjenning |
| Bruksområder | Semantisk søk, kunnskapsoppdagelse, AI-systemer, enhetsoppløsning | Forretningstransaksjoner, rapportering, OLTP-systemer | Anbefalingsmotorer, svindeldeteksjon, nettverksanalyse |
| Dataintegrasjon | Utmerket til å integrere heterogene data fra flere kilder | Krever betydelig ETL og datatransformasjon | Bra for sammenkoblet data, men mindre semantisk fokus |
| Skalerbarhet | Skalerer til milliarder av enheter og billioner av fakta | Skalerer godt for strukturert, transaksjonell data | Skalerer godt for relasjonstunge spørringer |
| Inferensevner | Avanserte resonnementer og kunnskapsutledning via ontologier | Begrenset; krever eksplisitt programmering | Begrenset; fokus på mønstergjenkjenning |
Kunnskapsgrafer har blitt sentrale i moderne SEO- og AI-synlighetsstrategier fordi de i stor grad bestemmer hvordan informasjon vises i søkeresultater og AI-genererte svar. Når Google behandler et søk, er en av hovedoppgavene å identifisere enheten brukeren leter etter, for deretter å hente relevant informasjon fra kunnskapsgrafen for å fylle SERP-funksjoner. Denne enhetsbaserte tilnærmingen har ført til fremveksten av semantisk søk—Googles evne til å forstå mening og kontekst i søk, ikke bare matche nøkkelord. Kunnskapsgrafen driver flere synlige SERP-funksjoner som direkte påvirker klikkrater og merkevaresynlighet. Kunnskapspaneler vises tydelig på både desktop og mobil og viser utvalgte fakta om søkt enhet hentet fra kunnskapsgrafen. AI-oversikter (tidligere Search Generative Experience) sammenfatter informasjon fra flere kilder identifisert via kunnskapsgrafrelasjoner, og gir omfattende svar som ofte skyver tradisjonelle organiske oppføringer lenger ned på siden. Folk spør også-bokser bruker enhetsrelasjoner for å foreslå relaterte søk og emner. Å forstå disse funksjonene er kritisk for merkevarer fordi de representerer verdifull plassering i søkeresultatene, ofte over tradisjonelle organiske lister. For organisasjoner som overvåker sin tilstedeværelse i AI-systemer som Perplexity, ChatGPT, Claude og Google AI-oversikter, blir kunnskapsgrafoptimalisering essensielt. Disse AI-systemene er i økende grad avhengige av strukturert enhetsinformasjon og semantiske relasjoner for å generere nøyaktige, kontekstuelle svar. En merkevare som har optimalisert sin enhetstilstedeværelse i kunnskapsgrafer—via strukturert datamerking, krav på kunnskapspaneler og konsistent informasjon på tvers av kilder—har større sannsynlighet for å bli nevnt i AI-genererte svar om relevante emner. Motsatt kan merkevarer med ufullstendig eller inkonsekvent enhetsinformasjon bli oversett eller feiltolket i AI-systemer, noe som direkte påvirker synlighet og omdømme.
Googles kunnskapsgraf henter fra et mangfoldig økosystem av datakilder, hvor hver bidrar med ulike typer informasjon og har ulike formål. Åpne data og fellesskapsprosjekter som Wikipedia og Wikidata utgjør grunnlaget for mye av innholdet i kunnskapsgrafen. Wikipedia gir fortellende beskrivelser og sammendrag som ofte vises i kunnskapspaneler, mens Wikidata—en strukturert kunnskapsbase som støtter Wikipedia—gir maskinlesbar enhetsdata og relasjoner. Google brukte tidligere Freebase, sin egen fellesskapsredigerte database, men gikk over til Wikidata etter å ha lagt ned Freebase i 2016. Offentlige datakilder bidrar med autoritativ informasjon, spesielt for faktaspørsmål. CIA World Factbook gir informasjon om land, geografiske områder og organisasjoner. Data Commons, Googles strukturerte offentlige datainitiativ, samler data fra myndigheter og multilaterale organisasjoner som FN og EU, og gir statistikk og demografisk informasjon. Vær- og luftkvalitetsdata kommer fra nasjonale og internasjonale meteorologiske byråer og gjør det mulig for Google å tilby “nåværende” værfunksjoner. Lisensierte private data kompletterer kunnskapsgrafen med informasjon som endres ofte eller krever spesialisert ekspertise. Google lisensierer finansmarkedsdata fra leverandører som Morningstar, S&P Global og Intercontinental Exchange for å drive aksjekurser og markedsinformasjon. Sportsdata kommer fra samarbeid med ligaer, lag og aggregatører som Stats Perform, og gir sanntidsresultater og historiske statistikker. Strukturert data fra nettsteder bidrar betydelig til berikelse av kunnskapsgrafen. Når nettsteder bruker Schema.org-merking, gir de eksplisitt semantisk informasjon som Google kan trekke ut og bruke. Derfor er implementering av korrekt strukturert data—Organization-skjema, LocalBusiness-skjema, FAQPage-skjema og annen relevant merking—kritisk for merkevarer som vil påvirke sin fremstilling i kunnskapsgrafen. Google Books-data fra over 40 millioner skannede og digitaliserte bøker gir historisk kontekst, biografisk informasjon og detaljerte beskrivelser som beriker enhetskunnskapen. Brukertilbakemeldinger og krav på kunnskapspaneler gjør det mulig for enkeltpersoner og organisasjoner å påvirke informasjonen i kunnskapsgrafen direkte. Når brukere sender tilbakemelding på kunnskapspaneler eller når autoriserte representanter krever og oppdaterer paneler, behandles denne informasjonen og kan føre til oppdateringer i kunnskapsgrafen. Denne menneske-i-løkken-tilnærmingen sikrer at kunnskapsgrafen forblir nøyaktig og representativ, selv om Googles automatiserte systemer tar den endelige avgjørelsen om hva som vises.
Google har eksplisitt uttalt at selskapet prioriterer informasjon fra kilder som viser høy E-E-A-T (Erfaring, Ekspertise, Autoritet og Troværdighet) ved bygging og oppdatering av kunnskapsgrafen. Denne sammenhengen mellom E-E-A-T og inkludering i kunnskapsgrafen er ikke tilfeldig—den gjenspeiler Googles overordnede forpliktelse til å løfte frem pålitelig, autoritativ informasjon. Hvis innholdet på nettstedet ditt trekkes inn i SERP-funksjoner drevet av kunnskapsgrafen, er det ofte et sterkt signal om at Google anerkjenner nettstedet ditt som autoritativt for det aktuelle emnet. Hvis innholdet ditt ikke vises i kunnskapsgrafdrevne funksjoner, kan det indikere E-E-A-T-utfordringer som må adresseres. Å bygge E-E-A-T for synlighet i kunnskapsgrafen krever en helhetlig tilnærming. Erfaring innebærer å vise at du eller dine bidragsytere har reell erfaring med emnet. For et helsenettsted kan dette bety å presentere innhold fra autoriserte medisinske fagfolk med mange års klinisk erfaring. For et teknologiselskap gjelder det å synliggjøre kompetansen til ingeniører og forskere som har bygget produktene dere omtaler. Ekspertise handler om å lage dyptgående innhold som dekker temaer grundig og nøyaktig. Dette går ut over overfladiske forklaringer og viser en genuin forståelse av nyanser, spesielle tilfeller og avanserte konsepter. Autoritet krever anerkjennelse innen ditt fagfelt. Dette kan komme fra priser, sertifiseringer, omtale i media, foredrag og henvisninger fra andre autoritative kilder. For organisasjoner gjelder det å etablere merkevaren som en ledende aktør i bransjen. Troværdighet bygger på de tre andre elementene og vises gjennom åpenhet, nøyaktighet, riktige henvisninger, tydelig forfatterskap og god kundeservice. Organisasjoner som utmerker seg på E-E-A-T har større sjanse for at informasjonen deres inkluderes i kunnskapsgrafen og for å bli nevnt i AI-genererte svar, noe som skaper en positiv spiral hvor autoritet gir synlighet, som igjen forsterker autoriteten.
Fremveksten av store språkmodeller (LLM) og generativ AI har gitt kunnskapsgrafer økt betydning i AI-økosystemet. Selv om LLM-er som ChatGPT, Claude og Perplexity ikke er direkte trent på Googles proprietære kunnskapsgraf, er de i økende grad avhengige av lignende strukturert kunnskap og semantisk forståelse. Mange AI-systemer bruker retrieval-augmented generation (RAG), hvor modellen spør kunnskapsgrafer eller strukturerte databaser i sanntid for å forankre svarene i faktainformasjon og redusere hallusinasjoner. Offentlig tilgjengelige kunnskapsgrafer som Wikidata brukes til å finjustere modeller eller injisere strukturert kunnskap, noe som forbedrer evnen til å forstå enhetsrelasjoner og gi korrekte svar. For merkevarer og organisasjoner betyr dette at kunnskapsgrafoptimalisering har konsekvenser utover tradisjonelt Google-søk. Når brukere spør AI-systemer om din bransje, produkter eller organisasjon, avhenger AI-systemets evne til å gi nøyaktig informasjon delvis av hvor godt din enhet er representert i strukturerte kunnskapskilder. En organisasjon med en vedlikeholdt Wikidata-oppføring, krav på Google kunnskapspanel og konsistent strukturert data på sitt nettsted har større sannsynlighet for å bli korrekt fremstilt i AI-genererte svar. Motsatt kan organisasjoner med ufullstendig eller motstridende informasjon på tvers av kilder bli feiltolket eller oversett i AI-svar. Dette skaper en ny dimensjon av AI-synlighetsovervåking—sporing av ikke bare hvordan merkevaren din vises i tradisjonelle søkeresultater, men også hvordan den fremstilles i AI-genererte svar på ulike plattformer. Verktøy og tjenester for overvåking av merkevaretilstedeværelse i AI-systemer fokuserer i økende grad på forståelse av enhetsrelasjoner og kunnskapsgrafrepresentasjon, siden disse faktorene direkte påvirker AI-synlighet.
Organisasjoner som ønsker å optimalisere sin tilstedeværelse i kunnskapsgrafer bør følge en systematisk tilnærming som bygger på SEO-grunnprinsipper, men legger til enhetsspesifikke strategier. Første steg er implementering av strukturert datamerking ved å bruke Schema.org-vokabular. Dette innebærer å legge til JSON-LD, Microdata eller RDFa-merking på nettstedet som eksplisitt beskriver organisasjonen, produkter, personer og andre relevante enheter. Viktige skjema-typer inkluderer Organization (for selskapsinformasjon), LocalBusiness (for lokasjonsspesifikk informasjon), Person (for individuelle profiler), Product (for produktinformasjon) og FAQPage (for ofte stilte spørsmål). Etter implementering av skjema er det viktig å teste og validere merkingen med Googles verktøy for testing av strukturert data for å sikre korrekt format og gjenkjenning. Neste steg er revisjon og optimalisering av Wikidata og Wikipedia-informasjon. Hvis organisasjonen eller sentrale enheter har Wikipedia-sider, må disse være nøyaktige, omfattende og godt dokumentert. For Wikidata, verifiser at enheten eksisterer og at egenskaper og relasjoner er korrekt representert. Redigering av Wikipedia eller Wikidata krever imidlertid nøye oppmerksomhet til retningslinjer og fellesskapsnormer—direkte egenpromotering eller skjulte interessekonflikter kan føre til at endringer blir tilbakeført og skade omdømmet. Tredje steg er å kreve og optimalisere Google Bedriftsprofil (for lokale virksomheter) og kunnskapspaneler (for personer og organisasjoner). Et krav på kunnskapspanel gir deg større kontroll over hvordan enheten din vises i søkeresultater og lar deg foreslå endringer raskere. Fjerde steg er å sikre konsistens på tvers av alle eiendommer—nettsted, Google Bedriftsprofil, sosiale medier og tredjeparts bedriftskataloger. Motstridende informasjon på tvers av kilder forvirrer Googles systemer og kan hindre nøyaktig kunnskapsgrafrepresentasjon. Femte steg er å lage enhetsfokusert innhold i stedet for tradisjonelt nøkkelordfokusert innhold. I stedet for å skrive artikler rundt nøkkelord, organiser innholdsstrategien rundt enheter og deres relasjoner. For eksempel, i stedet for separate artikler om “beste CRM-programvare”, “Salesforce-funksjoner” og “HubSpot-priser”, lag en omfattende innholdsklynge som etablerer klare enhetsrelasjoner: Salesforce er en CRM-plattform, konkurrerer med HubSpot, integreres med Slack, osv. Denne enhetsbaserte tilnærmingen hjelper kunnskapsgrafer å forstå innholdets semantiske mening og relasjoner.
Kunnskapsgrafer utvikler seg raskt i takt med fremskritt innen kunstig intelligens, endrede søkevaner og fremveksten av nye plattformer og teknologier. En betydelig trend er utvidelsen av multimodale kunnskapsgrafer som integrerer tekst, bilder, lyd og video. Etter hvert som talesøk og visuelle søk blir mer utbredt, tilpasses kunnskapsgrafer for å forstå og representere informasjon på tvers av flere modaliteter. Googles arbeid med multimodalt søk gjennom produkter som Google Lens viser denne utviklingen—systemet må forstå ikke bare tekstsøk, men også visuelle innspill, noe som krever kunnskapsgrafer som kan representere og koble informasjon på tvers av ulike medietyper. En annen viktig utvikling er økende sofistikering innen semantisk berikelse og naturlig språkprosessering ved bygging av kunnskapsgrafer. Etter hvert som NLP-evner forbedres, kan kunnskapsgrafer trekke ut mer nyanserte semantiske relasjoner fra ustrukturert tekst, og redusere avhengigheten av manuelt kuratert eller eksplisitt merket data. Dette betyr at organisasjoner med innhold av høy kvalitet og god språkføring kan få informasjonen sin inkludert i kunnskapsgrafer selv uten eksplisitt strukturert datamerking, selv om merking fortsatt er viktig for korrekt fremstilling. Integrasjonen av kunnskapsgrafer med store språkmodeller og generativ AI utgjør kanskje den mest betydningsfulle utviklingen. Etter hvert som AI-systemer blir mer sentrale for hvordan folk finner informasjon, utvider viktigheten av kunnskapsgrafoptimalisering seg utover tradisjonelt søk til også å gjelde AI-synlighet på flere plattformer. Organisasjoner som forstår og optimaliserer for kunnskapsgrafer vil ha fordeler i både tradisjonelle søk og AI-genererte svar. Videre reflekterer veksten av bedriftsinterne kunnskapsgrafer en økende erkjennelse av at prinsipper fra kunnskapsgrafer også gjelder for intern kunnskapsforvaltning. Selskaper bygger interne kunnskapsgrafer for å bryte ned datasiloer, forbedre beslutningstaking og muliggjøre bedre AI-applikasjoner. Denne trenden antyder at kunnskapsgraflitterasitet vil bli stadig viktigere for ledere, dataforskere og markedsførere. Til slutt blir de regulatoriske og etiske dimensjonene av kunnskapsgrafer mer fremtredende. Etter hvert som kunnskapsgrafer påvirker hvordan informasjon presenteres for milliarder av brukere, får spørsmål om nøyaktighet, skjevhet, representasjon og hvem som kontrollerer kunnskapsgrafinformasjonen økt oppmerksomhet. Organisasjoner bør være klar over at deres enhetsrepresentasjon i kunnskapsgrafer har reelle konsekvenser for synlighet, omdømme og forretningsresultater, og bør tilnærme seg kunnskapsgrafoptimalisering med samme grundighet og etikk som andre deler av sin digitale tilstedeværelse.
En tradisjonell database lagrer data i faste, tabellariske formater med forhåndsdefinerte skjemaer, mens en kunnskapsgraf organiserer informasjon som sammenkoblede noder og kanter som representerer enheter og deres semantiske relasjoner. Kunnskapsgrafer er mer fleksible, selvbeskrivende og bedre egnet for å forstå komplekse relasjoner mellom ulike datatyper. De gjør det mulig for systemer å forstå mening og kontekst, ikke bare matche nøkkelord, noe som gjør dem ideelle for AI- og semantiske søkapplikasjoner.
Google bruker sin kunnskapsgraf for å drive flere SERP-funksjoner, inkludert kunnskapspaneler, AI-oversikter, 'Folk spør også'-bokser og relaterte enhetsforslag. Per mai 2024 inneholder Googles kunnskapsgraf over 1,6 billioner fakta om 54 milliarder enheter. Når en bruker søker, identifiserer Google den enheten de leter etter og viser relevant, sammenkoblet informasjon fra kunnskapsgrafen, og hjelper brukerne med å finne 'ting, ikke strenger', som Google beskriver det.
Kunnskapsgrafer samler data fra flere kilder, inkludert åpen kildekode-prosjekter som Wikipedia og Wikidata, offentlige databaser som CIA World Factbook, lisensierte private data for finans- og sportsinformasjon, strukturert datamerking fra nettsteder med Schema.org, Google Books-data og tilbakemeldinger fra brukere gjennom korrigeringer i kunnskapspaneler. Denne fler-kilde-tilnærmingen sikrer omfattende og nøyaktig enhetsinformasjon på tvers av milliarder av fakta.
Kunnskapsgrafer påvirker direkte hvordan merkevarer vises i søkeresultater og AI-systemer ved å etablere enhetsrelasjoner og tilkoblinger. Merkevarer som optimaliserer sin enhetstilstedeværelse gjennom strukturert data, krav på kunnskapspaneler og konsistent informasjon på tvers av kilder, får bedre synlighet i AI-genererte svar. Forståelse av kunnskapsgrafrelasjoner hjelper merkevarer med å overvåke sin tilstedeværelse i AI-systemer som ChatGPT, Perplexity og Claude, som i økende grad er avhengige av strukturert enhetsinformasjon.
Semantisk berikelse er prosessen der maskinlæring og naturlig språkprosessering (NLP)-algoritmer analyserer data for å identifisere individuelle objekter og forstå relasjonene mellom dem. Denne prosessen gjør det mulig for kunnskapsgrafer å gå utover enkel nøkkelordmatching til å forstå mening og kontekst. Når data blir importert, gjenkjenner semantisk berikelse automatisk enheter, deres attributter og hvordan de relaterer til andre enheter, noe som muliggjør mer intelligent søk og spørsmål-og-svar-funksjonalitet.
Organisasjoner kan optimalisere for kunnskapsgrafer ved å implementere strukturert datamerking med Schema.org, opprettholde konsistent informasjon på alle eiendommer (nettsted, Google Bedriftsprofil, sosiale medier), kreve og oppdatere kunnskapspaneler, bygge sterke E-E-A-T-signaler gjennom autoritativt innhold og sikre datanøyaktighet på tvers av kilder. Å lage innholdsklynger med fokus på enheter, i stedet for tradisjonelle nøkkelordklynger, hjelper også med å etablere sterkere enhetsrelasjoner som kunnskapsgrafer kan gjenkjenne og utnytte.
Kunnskapsgrafer gir det semantiske grunnlaget for AI-oversikter ved å hjelpe AI-systemer med å forstå enhetsrelasjoner og kontekst. Når de genererer søkeoppsummeringer, bruker AI-systemer data fra kunnskapsgrafer for å identifisere relevante enheter, forstå deres tilkoblinger og syntetisere informasjon fra flere kilder. Dette muliggjør mer nøyaktige, kontekstuelle svar som går utover enkel nøkkelordmatching, noe som gjør kunnskapsgrafer til essensiell infrastruktur for moderne generative søkeopplevelser.
En kunnskapsgraf er et designmønster og et semantisk lag som definerer hvordan enheter og relasjoner modelleres og forstås, mens en grafdatabase er den teknologiske infrastrukturen som brukes til å lagre og søke i dataene. Kunnskapsgrafer fokuserer på mening og semantiske relasjoner, mens grafdatabaser fokuserer på effektiv lagring og henting. En kunnskapsgraf kan implementeres med ulike grafdatabaser som Neo4j, Amazon Neptune eller RDF triple stores, men selve kunnskapsgrafen er den konseptuelle modellen.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Oppdag hva kunnskapsgrafer er, hvordan de fungerer, og hvorfor de er essensielle for moderne databehandling, AI-applikasjoner og forretningsinnsikt.
Diskusjon i fellesskapet som forklarer Knowledge Graphs og deres betydning for synlighet i AI-søk. Eksperter deler hvordan entiteter og relasjoner påvirker AI-s...
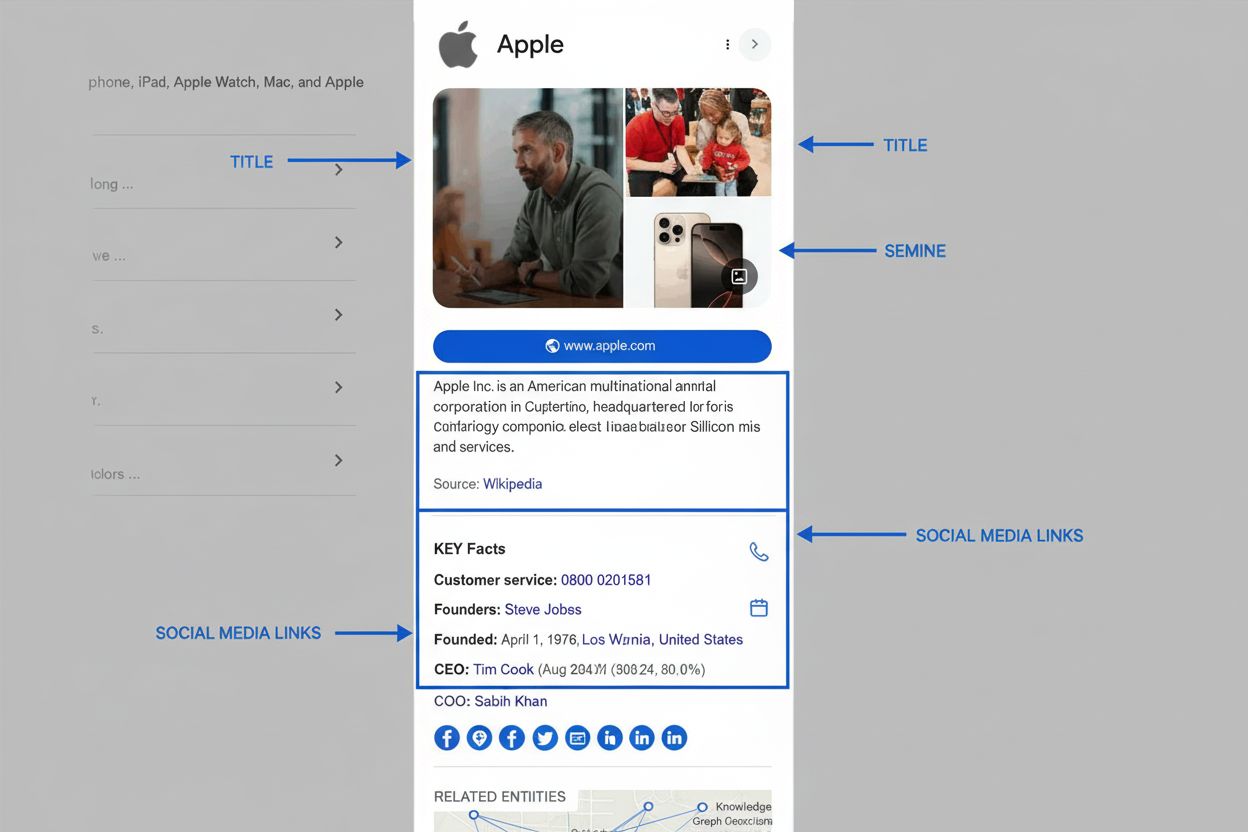
Lær hva et kunnskapspanel er, hvordan det fungerer, hvorfor det er viktig for SEO og AI-overvåkning, og hvordan du kan kreve eller optimalisere et for merkevare...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.