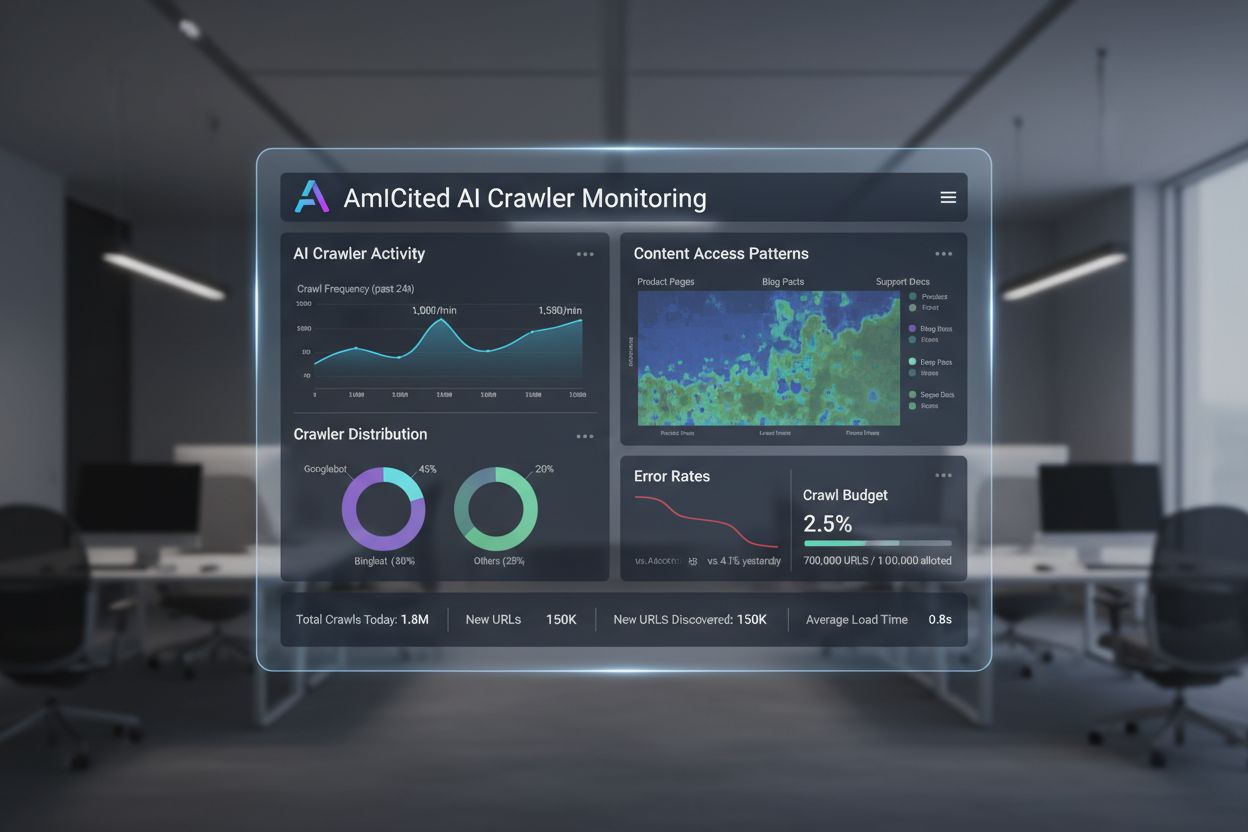
AI Crawl Analytics
Lær hva AI crawl analytics er og hvordan serverlogganalyse sporer AI-crawleres atferd, innholdstilgangsmønstre og synlighet i AI-drevne søkeplattformer som Chat...
9 min lesing

Loggfilanalyse er prosessen med å undersøke serverens tilgangslogger for å forstå hvordan søkemotorroboter og AI-boter samhandler med et nettsted, og avslører gjennomgangsmønstre, tekniske problemer og optimaliseringsmuligheter for SEO-ytelse.
Loggfilanalyse er prosessen med å undersøke serverens tilgangslogger for å forstå hvordan søkemotorroboter og AI-boter samhandler med et nettsted, og avslører gjennomgangsmønstre, tekniske problemer og optimaliseringsmuligheter for SEO-ytelse.
Loggfilanalyse er den systematiske gjennomgangen av serverens tilgangslogger for å forstå hvordan søkemotorroboter, AI-boter og brukere samhandler med et nettsted. Disse loggene genereres automatisk av webservere og inneholder detaljerte oppføringer over hver eneste HTTP-forespørsel til nettstedet ditt, inkludert forespørrerens IP-adresse, tidsstempel, forespurt URL, HTTP-statuskode og user-agent-streng. For SEO-fagfolk er loggfilanalyse den definitive sannhetskilden om robotatferd, og avslører mønstre som overfladiske verktøy som Google Search Console eller tradisjonelle crawlere ikke kan fange opp. I motsetning til simulerte gjennomsøk eller aggregerte analysedata gir serverlogger ufiltrert, førsteparts bevis på nøyaktig hva søkemotorer og AI-systemer gjør på nettstedet ditt i sanntid.
Betydningen av loggfilanalyse har økt eksponentielt i takt med den digitale utviklingen. Med over 51 % av global internett-trafikk nå generert av roboter (ACS, 2025), og AI-crawlere som GPTBot, ClaudeBot og PerplexityBot som faste besøkende på nettsteder, er det ikke lenger valgfritt å forstå robotatferd—det er avgjørende for å opprettholde synlighet både i tradisjonelle søk og på fremvoksende AI-drevne søkeplattformer. Loggfilanalyse bygger bro mellom det du tror skjer på nettstedet ditt og det som faktisk skjer, og muliggjør datadrevne beslutninger som direkte påvirker søkerangeringer, indekseringshastighet og organisk ytelse generelt.
Loggfilanalyse har vært en hjørnestein i teknisk SEO i flere tiår, men dens relevans har økt dramatisk de siste årene. Historisk har SEO-fagfolk hovedsakelig vært avhengige av Google Search Console og tredjeparts crawlere for å forstå søkemotoratferd. Disse verktøyene har imidlertid betydelige begrensninger: Google Search Console gir kun aggregerte, utvalgte data fra Googles roboter; tredjeparts crawlere simulerer robotatferd i stedet for å fange faktiske interaksjoner; og ingen av verktøyene sporer ikke-Google-søkemotorer eller AI-boter effektivt.
Fremveksten av AI-drevne søkeplattformer har fundamentalt endret landskapet. Ifølge Cloudflares forskning fra 2024 står Googlebot for 39 % av all AI- og søkerobot-trafikk, mens AI-spesifikke crawlere nå utgjør det raskest voksende segmentet. Metas AI-boter alene genererer 52 % av AI-robot-trafikken, mer enn dobbelt så mye som Google (23 %) eller OpenAI (20 %). Dette skiftet gjør at nettsteder nå får besøk av dusinvis av ulike robottype, hvorav mange ikke følger tradisjonelle SEO-protokoller eller respekterer vanlige robots.txt-regler. Loggfilanalyse er den eneste metoden som fanger dette komplette bildet, og gjør det uunnværlig for en moderne SEO-strategi.
Det globale markedet for loggadministrasjon er forventet å vokse fra $3 228,5 millioner i 2025 til betydelig høyere verdier innen 2029, med en årlig sammensatt vekstrate (CAGR) på 14,6 %. Denne veksten reflekterer økende erkjennelse i næringslivet av at logganalyse er kritisk for sikkerhet, ytelsesovervåking og SEO-optimalisering. Organisasjoner investerer tungt i automatiserte logganalyseverktøy og AI-drevne plattformer som kan behandle millioner av loggoppføringer i sanntid, og forvandle rådata til handlingsrettet innsikt som gir forretningsmessige resultater.
Når en bruker eller robot ber om å få se en side på nettstedet ditt, behandler webserveren denne forespørselen og logger detaljerte opplysninger om interaksjonen. Denne prosessen skjer automatisk og kontinuerlig, og skaper et omfattende revisjonsspor over all serveraktivitet. Å forstå hvordan dette fungerer er essensielt for å tolke loggdataene korrekt.
Den typiske flyten starter når en crawler (enten Googlebot, en AI-bot eller en brukers nettleser) sender en HTTP GET-forespørsel til serveren din, inkludert en user-agent-streng som identifiserer forespørreren. Serveren mottar forespørselen, behandler den og returnerer en HTTP-statuskode (200 for suksess, 404 for ikke funnet, 301 for permanent omdirigering, osv.) sammen med det forespurte innholdet. Hver av disse interaksjonene registreres i serverens tilgangsloggfil, og skaper en tidsstemplet oppføring med IP-adresse, forespurt URL, HTTP-metode, statuskode, responsstørrelse, henviser og user-agent-streng.
HTTP-statuskoder er spesielt viktige for SEO-analyse. En 200-statuskode indikerer vellykket sidelevering; 3xx-koder indikerer omdirigeringer; 4xx-koder indikerer klientfeil (som 404 Ikke funnet); og 5xx-koder indikerer serverfeil. Ved å analysere fordelingen av disse statuskodene i loggene dine kan du identifisere tekniske problemer som hindrer roboter i å få tilgang til innholdet ditt. For eksempel, hvis en robot mottar flere 404-responser når den prøver å få tilgang til viktige sider, signaliserer det et problem med ødelagte lenker eller manglende innhold som krever umiddelbar oppmerksomhet.
User-agent-strenger er like kritiske for å identifisere hvilke roboter som besøker nettstedet ditt. Hver crawler har en unik user-agent-streng som identifiserer den. Googlebots user-agent inkluderer “Googlebot/2.1”, mens GPTBot inkluderer “GPTBot/1.0”, og ClaudeBot inkluderer “ClaudeBot”. Ved å analysere disse strengene kan du segmentere loggdataene dine for å analysere atferd etter robottype, og avsløre hvilke roboter som prioriterer hvilket innhold og hvordan deres crawl-mønstre skiller seg fra hverandre. Denne detaljerte analysen muliggjør målrettede optimaliseringsstrategier for ulike søkeplattformer og AI-systemer.
| Aspekt | Loggfilanalyse | Google Search Console | Tredjeparts crawlere | Analyseverktøy |
|---|---|---|---|---|
| Datakilde | Serverlogger (førsteparts) | Googles crawl-data | Simulerte crawl | Brukeratferds-sporing |
| Fullstendighet | 100 % av alle forespørsler | Utvalgte, aggregerte data | Kun simulert | Kun menneskelig trafikk |
| Robotdekning | Alle crawlere (Google, Bing, AI-boter) | Kun Google | Simulerte crawlere | Ingen robotdata |
| Historiske data | Full historikk (varierer) | Begrenset tidsramme | Enkel crawl-snapshot | Historisk tilgjengelig |
| Sanntidsinnsikt | Ja (med automatisering) | Forsinket rapportering | Nei | Forsinket rapportering |
| Crawl-budsjettinnsikt | Eksakte crawl-mønstre | Oversiktsnivå | Anslått | Ikke relevant |
| Tekniske problemer | Detaljert (statuskoder, responstider) | Begrenset innsikt | Simulerte problemer | Ikke relevant |
| AI-bot-sporing | Ja (GPTBot, ClaudeBot, osv.) | Nei | Nei | Nei |
| Kostnad | Gratis (serverlogger) | Gratis | Betalte verktøy | Gratis/betalt |
| Oppsettkompleksitet | Moderat til høy | Enkel | Enkel | Enkel |
Loggfilanalyse har blitt uunnværlig for å forstå hvordan søkemotorer og AI-systemer samhandler med nettstedet ditt. I motsetning til Google Search Console, som kun gir Googles perspektiv og aggregerte data, fanger loggfiler det komplette bildet av all robotaktivitet. Denne omfattende oversikten er avgjørende for å identifisere sløsing med crawl-budsjett, der søkemotorer bruker ressurser på å crawle sider med lav verdi i stedet for viktig innhold. Forskning viser at store nettsteder ofte sløser bort 30–50 % av crawl-budsjettet på ikke-essensielle URLer som paginerte arkiver, filtreringsnavigasjon eller utdatert innhold.
Fremveksten av AI-drevne søk har gjort loggfilanalyse enda viktigere. Etter hvert som AI-boter som GPTBot, ClaudeBot og PerplexityBot blir faste besøkende på nettsteder, er det avgjørende å forstå deres atferd for å optimalisere synlighet i AI-genererte svar. Disse robotene oppfører seg ofte annerledes enn tradisjonelle søkeroboter—de kan ignorere robots.txt-regler, crawle mer aggressivt eller fokusere på spesifikke innholdstyper. Loggfilanalyse er den eneste metoden som avslører disse mønstrene, og gjør det mulig å optimalisere nettstedet ditt for AI-oppdagelse samtidig som du styrer robottilgang gjennom målrettede regler.
Tekniske SEO-problemer som ellers ikke ville blitt oppdaget, kan identifiseres gjennom logganalyse. Omdirigeringskjeder, 5xx-serverfeil, trege lastetider og JavaScript-rendering-problemer etterlater alle spor i serverlogger. Ved å analysere disse mønstrene kan du prioritere tiltak som direkte påvirker søkemotorenes tilgjengelighet og indekseringshastighet. For eksempel, hvis logger viser at Googlebot konsekvent får 503 Service Unavailable-feil når den crawler en bestemt seksjon av nettstedet ditt, vet du nøyaktig hvor du skal rette de tekniske ressursene dine.
Å skaffe serverloggene dine er første steg i loggfilanalyse, men prosessen varierer avhengig av hostingmiljøet ditt. For egeneide servere som kjører Apache eller NGINX, lagres logger vanligvis i /var/log/apache2/access.log eller /var/log/nginx/access.log henholdsvis. Du kan få tilgang til disse filene direkte via SSH eller gjennom serverens filbehandler. For administrerte WordPress-verter som WP Engine eller Kinsta, kan logger være tilgjengelige via kontrollpanelet eller SFTP, selv om noen tilbydere begrenser tilgangen for å beskytte serverytelsen.
Content Delivery Networks (CDN-er) som Cloudflare, AWS CloudFront og Akamai krever spesiell konfigurasjon for loggtilgang. Cloudflare tilbyr Logpush, som sender HTTP-forespørselslogger til angitte lagringsbøtter (AWS S3, Google Cloud Storage, Azure Blob Storage) for henting og analyse. AWS CloudFront gir standard logging som kan konfigureres til å lagre logger i S3-bøtter. Disse CDN-loggene er essensielle for å forstå hvordan roboter samhandler med nettstedet ditt når innhold serveres via CDN, da de fanger opp forespørsler ved kanten i stedet for på opprinnelsesserveren.
Delt hosting gir ofte begrenset loggtilgang. Tilbydere som Bluehost og GoDaddy kan tilby delvise logger via cPanel, men disse loggene roteres ofte hyppig og kan mangle viktige felter. Hvis du har delt hosting og trenger omfattende logganalyse, bør du vurdere å oppgradere til VPS eller administrert hosting som gir full loggtilgang.
Når du har skaffet loggene dine, er databearbeiding avgjørende. Rå loggfiler inneholder forespørsler fra alle kilder—brukere, roboter, scrapers og ondsinnede aktører. For SEO-analyse bør du filtrere ut ikke-relevant trafikk og fokusere på søkemotor- og AI-robotaktivitet. Dette innebærer typisk:
Loggfilanalyse avdekker innsikt som er usynlig for andre SEO-verktøy, og gir grunnlag for strategiske optimaliseringsbeslutninger. En av de mest verdifulle innsiktene er analyse av crawl-mønstre, som viser nøyaktig hvilke sider søkemotorene besøker og hvor ofte. Ved å spore crawl-frekvens over tid kan du se om Google øker eller reduserer oppmerksomheten til bestemte seksjoner av nettstedet ditt. Plutselige fall i crawl-frekvens kan indikere tekniske problemer eller endringer i sidens viktighet, mens økning tyder på at Google responderer positivt på optimaliseringstiltakene dine.
Effektivitet i crawl-budsjettet er en annen viktig innsikt. Ved å analysere forholdet mellom vellykkede (2xx) svar og feilsvar (4xx, 5xx), kan du identifisere deler av nettstedet der roboter støter på problemer. Hvis en spesiell katalog konsekvent returnerer 404-feil, sløses crawl-budsjettet på ødelagte lenker. På samme måte, hvis roboter bruker uforholdsmessig mye tid på paginerte URLer eller filtreringsnavigasjon, sløses budsjettet på innhold med lav verdi. Logganalyse kvantifiserer dette tapet, noe som gjør det mulig å beregne den potensielle effekten av optimaliseringstiltak.
Oppdagelse av foreldreløse sider er en unik fordel ved loggfilanalyse. Foreldreløse sider er URLer uten interne lenker og som ligger utenfor nettstedets struktur. Tradisjonelle crawlere overser ofte disse sidene fordi de ikke kan oppdages gjennom intern linking. Loggfiler viser imidlertid at søkemotorer likevel crawler dem—ofte fordi de er lenket eksternt eller finnes i gamle sitemaps. Ved å identifisere slike foreldreløse sider kan du bestemme om de skal reintegreres i nettstedet, omdirigeres eller fjernes helt.
Analyse av AI-bot-atferd blir stadig viktigere. Ved å segmentere loggdata etter AI-bot user-agents kan du se hvilket innhold disse robotene prioriterer, hvor ofte de besøker nettstedet og om de møter tekniske barrierer. For eksempel, hvis GPTBot konsekvent crawler FAQ-sidene dine, men sjelden besøker bloggen, indikerer det at AI-systemer vurderer FAQ-innhold som mer verdifullt for treningsdata. Denne innsikten kan påvirke innholdsstrategien din og hjelpe deg å optimalisere for AI-synlighet.
Vellykket loggfilanalyse krever både riktige verktøy og en strategisk tilnærming. Screaming Frogs Log File Analyzer er et av de mest populære dedikerte verktøyene, og tilbyr brukervennlige grensesnitt for å behandle store loggfiler, identifisere robotmønstre og visualisere crawl-data. Botify gir logganalyse på bedriftsnivå integrert med SEO-metrikker, slik at du kan korrelere robotaktivitet med rangeringer og trafikk. seoClaritys Bot Clarity integrerer logganalyse direkte i SEO-plattformen, noe som gjør det enkelt å koble crawl-data til andre SEO-metrikker.
For organisasjoner med høy trafikk eller kompleks infrastruktur tilbyr AI-drevne logganalyseplattformer som Splunk, Sumo Logic og Elastic Stack avanserte muligheter som automatisert mønstergjenkjenning, anomali-deteksjon og prediktiv analyse. Disse plattformene kan behandle millioner av loggoppføringer i sanntid, automatisk identifisere nye robottyper og flagge uvanlig aktivitet som kan indikere sikkerhetstrusler eller tekniske problemer.
Beste praksis for loggfilanalyse inkluderer:
Etter hvert som AI-drevne søk blir stadig viktigere, har overvåking av AI-boter gjennom loggfilanalyse blitt en kritisk SEO-funksjon. Ved å spore hvilke AI-boter som besøker nettstedet ditt, hvilket innhold de får tilgang til og hvor ofte de crawler, kan du forstå hvordan innholdet ditt brukes i AI-drevne søkeverktøy og generative AI-modeller. Disse dataene gjør det mulig å ta informerte beslutninger om hvorvidt du vil tillate, blokkere eller begrense spesifikke AI-boter via robots.txt-regler eller HTTP-headere.
Optimalisering av crawl-budsjett er kanskje det mest effektfulle bruksområdet for loggfilanalyse. For store nettsteder med tusenvis eller millioner av sider er crawl-budsjettet en begrenset ressurs. Ved å analysere loggfiler kan du identifisere sider som crawles for mye i forhold til viktigheten, og sider som burde crawles oftere men ikke blir det. Vanlige scenarioer for sløsing med crawl-budsjett inkluderer:
Ved å adressere disse problemene—gjennom robots.txt-regler, kanoniske tagger, noindex eller tekniske forbedringer—kan du omdirigere crawl-budsjettet til innhold med høy verdi, forbedre indekseringshastighet og søkesynlighet for sidene som betyr mest for virksomheten din.
Fremtiden for loggfilanalyse formes av den raske utviklingen innen AI-drevet søk. Etter hvert som flere AI-boter entrer økosystemet og atferden deres blir mer sofistikert, vil loggfilanalyse bli enda viktigere for å forstå hvordan innholdet ditt oppdages, aksesseres og brukes av AI-systemer. Fremvoksende trender inkluderer:
Sanntids logganalyse drevet av maskinlæring vil gjøre det mulig for SEO-eksperter å oppdage og svare på crawl-problemer på minutter i stedet for dager. Automatiserte systemer vil identifisere nye robottyper, flagge uvanlige mønstre og foreslå optimaliseringstiltak uten manuelle inngrep. Dette skiftet fra reaktiv til proaktiv analyse vil gjøre det mulig å opprettholde optimal crawlbarhet og indeksering kontinuerlig.
Integrasjon med AI-synlighetssporing vil koble loggdata med ytelsesmetrikker for AI-søk. I stedet for å analysere logger isolert, vil SEO-eksperter korrelere robotatferd med faktisk synlighet i AI-genererte svar, og forstå nøyaktig hvordan crawl-mønstre påvirker AI-rangeringer. Denne integrasjonen vil gi enestående innsikt i hvordan innhold flyter fra crawl til AI-treningsdata til brukerrettede AI-svar.
Etisk robotstyring vil bli stadig viktigere etter hvert som organisasjoner må ta stilling til hvilke AI-boter som bør ha tilgang til innholdet deres. Loggfilanalyse vil muliggjøre granulær kontroll over robottilgang, slik at utgivere kan tillate fordelaktige AI-crawlere samtidig som de blokkerer de som ikke gir verdi eller attribusjon. Standarder som det nye LLMs.txt-protokollet vil gi strukturerte måter å kommunisere robottilgang på, og logganalyse vil kunne verifisere etterlevelse.
Personvernsbevarende analyse vil utvikle seg for å balansere behovet for detaljert crawl-innsikt med personvernforordninger som GDPR. Avanserte anonymiseringsteknikker og personvernfokuserte analyseverktøy vil gjøre det mulig for organisasjoner å hente ut verdifull innsikt fra logger uten å lagre eller eksponere personidentifiserbare opplysninger. Dette vil bli spesielt viktig etter hvert som logganalyse blir mer utbredt og databeskyttelsesreguleringene blir strengere.
Konsolideringen av tradisjonell SEO og AI-søkeoptimalisering betyr at loggfilanalyse vil forbli en hjørnestein i teknisk SEO-strategi i mange år framover. Organisasjoner som behersker loggfilanalyse i dag, vil være best posisjonert for å opprettholde synlighet og ytelse etter hvert som søk utvikler seg.
Loggfilanalyse gir fullstendige, ikke-utvalgte data fra serveren din som fanger opp hver forespørsel fra alle roboter, mens Google Search Console's crawl-statistikk bare viser aggregerte, utvalgte data fra Googles roboter. Loggfiler tilbyr granulære historiske data og innsikt i ikke-Google-roboters atferd, inkludert AI-boter som GPTBot og ClaudeBot, noe som gjør dem mer omfattende for å forstå virkelig robotatferd og identifisere tekniske problemer som GSC kan gå glipp av.
For nettsteder med mye trafikk anbefales ukentlig loggfilanalyse for å fange problemer tidlig og overvåke endringer i crawl-mønster. Mindre nettsteder har nytte av månedlige gjennomganger for å etablere trender og identifisere ny robotaktivitet. Uavhengig av nettstedets størrelse hjelper kontinuerlig overvåking gjennom automatiserte verktøy med å oppdage avvik i sanntid, slik at du kan reagere raskt på sløsing med crawl-budsjett eller tekniske problemer som påvirker synligheten i søk.
Ja, loggfilanalyse er en av de mest effektive måtene å spore AI-bottrafikk på. Ved å undersøke user-agent-strenger og IP-adresser i serverloggene dine kan du identifisere hvilke AI-boter som besøker nettstedet ditt, hvilket innhold de får tilgang til og hvor ofte de crawler. Disse dataene er avgjørende for å forstå hvordan innholdet ditt brukes i AI-drevne søkeverktøy og generative AI-modeller, slik at du kan optimalisere for AI-synlighet og styre robottilgang gjennom robots.txt-regler.
Loggfilanalyse avdekker en rekke tekniske SEO-problemer, inkludert crawl-feil (4xx- og 5xx-statuskoder), omdirigeringskjeder, trege lastetider, foreldreløse sider uten interne lenker, sløsing med crawl-budsjett på lavverdi-URLer, problemer med JavaScript-rendering og duplisert innhold. Det identifiserer også forfalsket robotaktivitet og hjelper med å oppdage når legitime roboter møter tilgjengelighetsbarrierer, slik at du kan prioritere tiltak som direkte påvirker synlighet og indeksering i søkemotorer.
Loggfilanalyse viser nøyaktig hvilke sider søkemotorene crawler og hvor ofte, og avslører hvor crawl-budsjettet sløses bort på innhold med lav verdi, som paginerte arkiver, filtreringsnavigasjon eller utdaterte URLer. Ved å identifisere disse ineffektivitetene kan du justere robots.txt-filen din, forbedre intern lenking til prioriterte sider og implementere kanoniske tagger for å styre crawl-oppmerksomheten mot innhold med høy verdi, slik at søkemotorene fokuserer på sidene som betyr mest for virksomheten din.
Serverloggfiler registrerer vanligvis IP-adresser (som identifiserer forespørselskilder), tidsstempler (når forespørsler oppstod), HTTP-metoder (vanligvis GET eller POST), forespurte URLer (eksakte sider som ble aksessert), HTTP-statuskoder (200, 404, 301, osv.), responsstørrelser i bytes, henvisningsinformasjon og user-agent-strenger (som identifiserer roboten eller nettleseren). Disse omfattende dataene lar SEOs rekonstruere nøyaktig hva som skjedde under hver serverinteraksjon og identifisere mønstre som påvirker crawlbarhet og indeksering.
Forfalskede roboter utgir seg for å være legitime søkemotorroboter, men har IP-adresser som ikke samsvarer med søkemotorens publiserte IP-områder. For å identifisere dem, kryssjekk user-agent-strenger (som 'Googlebot') mot offisielle IP-områder publisert av Google, Bing og andre søkemotorer. Verktøy som Screaming Frogs Log File Analyzer validerer automatisk roboters ekthet. Forfalskede roboter sløser med crawl-budsjettet og kan belaste serveren din, så blokkering gjennom robots.txt eller brannmurregler anbefales.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Lær hva AI crawl analytics er og hvordan serverlogganalyse sporer AI-crawleres atferd, innholdstilgangsmønstre og synlighet i AI-drevne søkeplattformer som Chat...
SERP-analyse er prosessen med å undersøke søkeresultatsider for å forstå rangeringens vanskelighetsgrad, søkeintensjon og konkurrentstrategier. Lær hvordan du a...

Lær hva en AI-innholdsanalyse er, hvordan den skiller seg fra tradisjonelle innholdsanalyser, og hvorfor det er kritisk for din digitale strategi å overvåke mer...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.