Meta AI
Meta AI er Metas AI-assistent integrert i Facebook, Instagram, WhatsApp og Messenger. Lær hvordan den fungerer, dens muligheter, og dens rolle i AI-overvåkning ...
11 min lesing
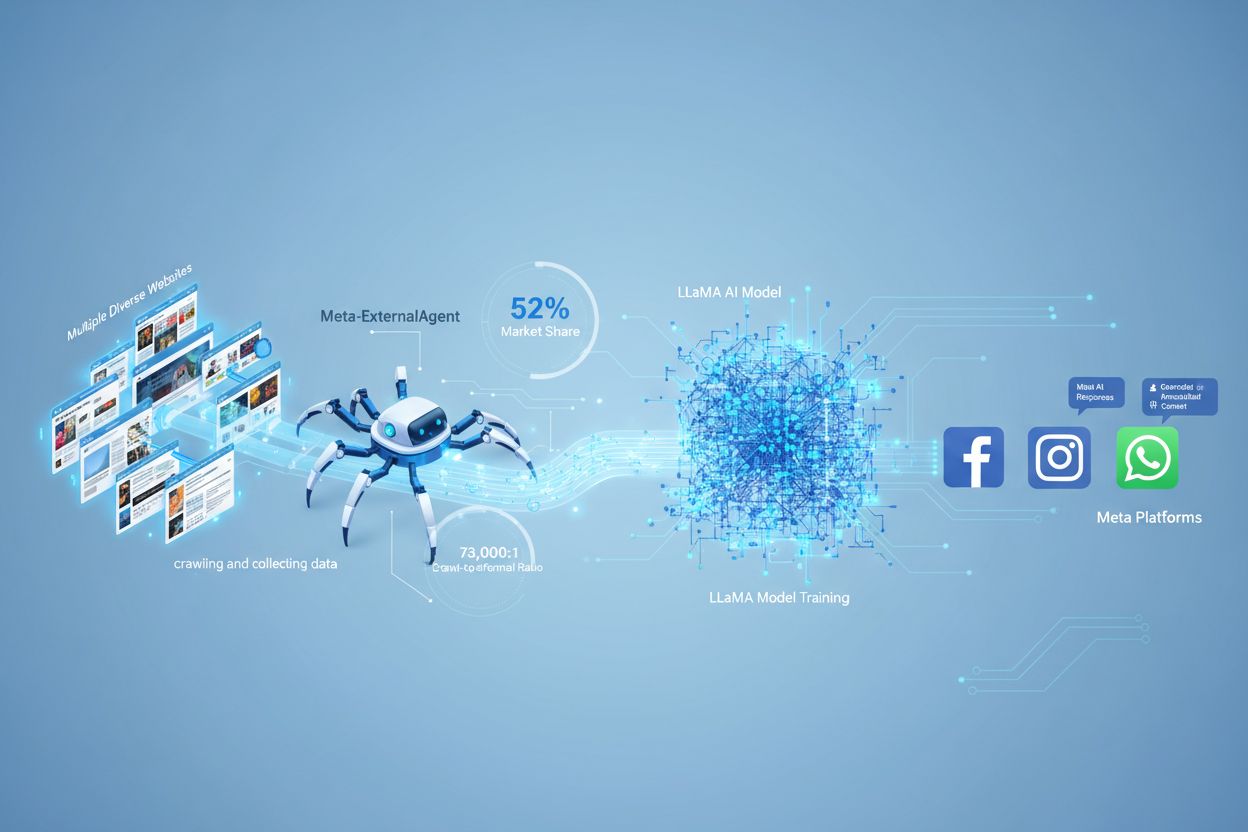
Meta-ExternalAgent er Metas nettleserbot lansert i juli 2024 for å samle offentlig tilgjengelig innhold til trening av KI-modeller som LLaMA. Den identifiserer seg med User-Agent-strengen meta-externalagent/1.1 og styrer om innhold vises i Meta AI-svar på tvers av Facebook, Instagram og WhatsApp. Utgivere kan blokkere den via robots.txt eller serverkonfigurasjon, men etterlevelse er frivillig og ikke juridisk bindende.
Meta-ExternalAgent er Metas nettleserbot lansert i juli 2024 for å samle offentlig tilgjengelig innhold til trening av KI-modeller som LLaMA. Den identifiserer seg med User-Agent-strengen meta-externalagent/1.1 og styrer om innhold vises i Meta AI-svar på tvers av Facebook, Instagram og WhatsApp. Utgivere kan blokkere den via robots.txt eller serverkonfigurasjon, men etterlevelse er frivillig og ikke juridisk bindende.
Meta-ExternalAgent er en nettleserbot driftet av Meta Platforms som ble lansert i juli 2024 for å samle inn data til trening av kunstig intelligens-modeller. Identifisert ved User-Agent-strengen meta-externalagent/1.1, skiller denne crawleren seg fra Metas eldre facebookexternalhit-crawler, som primært ble brukt til lenkeforhåndsvisninger og sosiale delingsfunksjoner. Meta-ExternalAgent markerer et betydelig skifte i hvordan Meta samler treningsdata til sine KI-initiativ, inkludert LLaMA-språkmodellene og Meta AI-chatboten integrert på tvers av Facebook, Instagram og WhatsApp. I motsetning til tidligere Meta-crawlere opererer denne agenten med minimal åpenhet og ble lansert uten formell offentlig kunngjøring.

Meta-ExternalAgent fungerer som en automatisert bot som systematisk crawler nettsteder over hele internett for å hente ut tekst og innhold til KI-modelltrening. Crawleren sender HTTP-forespørsler til webservere, identifiserer seg via en unik User-Agent-header og laster ned sideinnhold for videre behandling. Når innholdet er samlet, analyserer og tokenizer Metas systemer teksten, og omgjør den til treningsdata som bidrar til å forbedre språkmodellenes evner. Crawleren respekterer robots.txt-filen på frivillig basis, men dette er et æressystem snarere enn et juridisk krav. Ifølge Cloudflare-data står Meta-ExternalAgent for omtrent 52 % av all KI-crawlertrafikk på internett, noe som gjør den til en av de mest aggressive datainnsamlingsoperasjonene i KI-bransjen. Crawleren opererer kontinuerlig, og noen utgivere rapporterer crawl-frekvenser som tyder på at Meta prioriterer omfattende dekning av webinnhold fremfor selektiv, målrettet innsamling.
| Crawler-navn | User-Agent-streng | Hovedformål | Lanseringsdato | Dataanvendelse |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | KI-modelltrening (LLaMA, Meta AI) | Juli 2024 | Treningsdata for generativ KI |
| facebookexternalhit | facebookexternalhit/1.1 | Lenkeforhåndsvisninger og sosial deling | ~2010 | Open Graph-metadata, miniatyrbilder |
| Facebot | facebot/1.0 | Facebook app-innholdsverifisering | ~2015 | Innholdsvalidering for mobilapper |
| Applebot | Applebot/0.1 | Apple Siri og søkeindeksering | ~2015 | Søkeindeksering og stemmeassistent |
| Googlebot | Googlebot/2.1 | Google-søkeindeksering | ~1998 | Bygging av søkemotorindeks |
Meta-ExternalAgent representerer en kritisk bekymring for innholdsskapere og utgivere fordi den opererer i et hittil usett omfang, samtidig som den gir minimal innsikt i hvordan innholdet brukes. Ifølge Cloudflare-undersøkelser står Meta-ExternalAgent for 52 % av all KI-crawlertrafikk, langt mer enn konkurrenter som OpenAIs GPTBot og Googles KI-crawlere. Denne dominansen betyr at Meta samler inn mer treningsdata enn noe annet KI-selskap, men utgivere mottar ingen kompensasjon eller attribusjon når innholdet deres brukes til å trene Metas KI-modeller. Det 73 000:1 crawl-til-henvisningsforholdet viser at Meta henter ut enorme mengder innhold uten å sende nevneverdig trafikk tilbake til kildens nettsteder—en grunnleggende ubalanse i verdibyttet. Til tross for disse bekymringene blokkerer kun 2 % av nettsteder Meta-ExternalAgent aktivt, sammenlignet med 25 % som blokkerer GPTBot, noe som tyder på at mange utgivere ikke er klar over crawlerens tilstedeværelse eller konsekvenser. Med Meta sine investeringer på 40 milliarder dollar i KI-infrastruktur kommer selskapets satsing på aggressiv datainnsamling sannsynligvis til å øke, så det er essensielt for utgivere å forstå og aktivt styre forholdet til denne crawleren.
Utgivere kan styre Meta-ExternalAgent-tilgang via robots.txt-filen, men det er viktig å forstå at denne mekanismen er frivillig og ikke juridisk bindende. For å blokkere Meta-ExternalAgent, legg til følgende direktiv i robots.txt-filen din:
User-agent: meta-externalagent
Disallow: /
Alternativt, hvis du ønsker å tillate crawleren, men begrense den til bestemte kataloger, kan du bruke:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Noen utgivere har imidlertid rapportert at Meta-ExternalAgent fortsetter å crawlere nettstedene deres selv etter at de har implementert robots.txt-blokkering, noe som tyder på at Meta ikke alltid følger slike direktiver. For mer omfattende beskyttelse kan utgivere implementere blokkering basert på HTTP-headere eller bruke regler i Content Delivery Network (CDN) for å identifisere og avvise forespørsler fra Meta-ExternalAgent basert på User-Agent-strengen. Utgivere kan også overvåke serverloggene sine etter User-Agent-strengen meta-externalagent/1.1 for å sjekke om crawleren får tilgang til innholdet deres. Verktøy som AmICited.com kan hjelpe utgivere med å spore om innholdet deres blir sitert eller referert til i Meta AI-svar, og gir innsikt i hvordan arbeidet deres brukes av Metas KI-systemer.

Når brukere samhandler med Meta AI-chatboter på Facebook, Instagram eller WhatsApp, er svarene delvis basert på innhold samlet inn av Meta-ExternalAgent. Meta AI-svar inkluderer imidlertid vanligvis ikke synlige referanser eller attribusjon til kildens nettsteder, noe som betyr at brukere kanskje ikke vet hvilke utgiveres innhold som bidro til svaret de mottok. Denne mangelen på åpenhet skaper en betydelig utfordring for innholdsskapere som ønsker å forstå verdien arbeidet deres gir Metas KI-systemer. I motsetning til noen konkurrenter som inkluderer referanser i KI-genererte svar, prioriterer Metas tilnærming brukeropplevelsen over attribusjon til utgiver. Fraværet av synlige referanser betyr også at utgivere ikke enkelt kan spore hvor ofte innholdet deres påvirker Meta AI-svar, noe som gjør det vanskelig å vurdere den forretningsmessige verdien av at innholdet brukes til KI-trening. Dette synlighetsgapet er en av hovedgrunnene til at overvåkningsløsninger har blitt stadig viktigere for utgivere som ønsker å forstå sin rolle i KI-økosystemet.
Utgivere kan verifisere Meta-ExternalAgent-aktivitet gjennom analyse av serverlogger, som viser crawlerens IP-adresser, forespørselsmønstre og innholdstilgangsfrekvens. Ved å gjennomgå tilgangslogger kan utgivere identifisere forespørsler med User-Agent-strengen meta-externalagent/1.1 og se hvilke sider som blir crawlet hyppigst. Avanserte overvåkningsverktøy kan spore crawl-mønstre over tid og avdekke om Meta prioriterer visse innholdstyper eller deler av nettstedet. Utgivere bør også følge med på båndbreddebruken, da aggressiv crawling fra Meta-ExternalAgent kan bruke betydelige serverressurser, spesielt for nettsteder med store innholdsbiblioteker. I tillegg kan utgivere bruke verktøy som AmICited.com for å overvåke om innholdet deres vises i Meta AI-svar og spore siteringsmønstre på tvers av Metas plattformer. Å sette opp varsler for uvanlig crawl-aktivitet kan hjelpe utgivere å oppdage endringer i Metas datainnsamlingspraksis og handle proaktivt. Regelmessig revisjon av serverlogger bør være en del av enhver utgivers KI-crawlerhåndteringsstrategi, slik at de opprettholder bevissthet om hvordan innholdet deres blir brukt.
Den juridiske statusen til Meta-ExternalAgent er omstridt, med pågående søksmål fra innholdsskapere, kunstnere og utgivere som utfordrer Metas rett til å bruke arbeidet deres til KI-trening uten eksplisitt samtykke eller kompensasjon. Mens Meta hevder at crawling av nettet faller innenfor prinsippet om rimelig bruk, mener kritikere at det enorme omfanget og den kommersielle karakteren av datainnsamlingen, kombinert med manglende attribusjon, utgjør brudd på opphavsretten. robots.txt-filen er en bransjestandard, men har ingen juridisk kraft, noe som betyr at Meta ikke er forpliktet til å følge blokkeringer. Flere jurisdiksjoner utvikler nå reguleringer rundt datainnsamling til KI-trening, med EUs KI-forordning og foreslått lovgivning andre steder som potensielt kan stille strengere krav til selskaper som Meta. Etisk sett handler det grunnleggende spørsmålet om hvorvidt innholdsskapere bør ha rett til å bestemme hvordan arbeidet deres brukes til kommersiell KI-trening, og om systemet i dag gir tilstrekkelig kompensasjon for verdien innholdet gir. Utgivere bør holde seg oppdatert på utviklingen i lovverket og vurdere å rådføre seg med juridisk ekspertise om sine rettigheter og plikter når det gjelder KI-crawler-tilgang. Balansegangen mellom å muliggjøre KI-innovasjon og å beskytte skaperrettigheter er fortsatt uløst, og dette er et område i stadig juridisk og regulativ utvikling.
Landskapet for håndtering av KI-crawlere er i rask endring, ettersom utgivere, regulatorer og KI-selskaper forhandler om vilkårene for datainnsamling og -bruk. Metas aggressive utrulling av Meta-ExternalAgent signaliserer at store teknologiselskaper ser webinnhold som essensielt treningsmateriale for konkurransedyktige KI-systemer, og denne trenden vil sannsynligvis akselerere etter hvert som KI blir stadig viktigere for forretningsstrategi. Fremtidige utviklinger kan inkludere sterkere juridisk beskyttelse for innholdsskapere, obligatoriske lisensieringsordninger for KI-treningsdata og tekniske standarder som gjør det enklere for utgivere å styre og tjene penger på bruk av innholdet deres i KI-systemer. Fremveksten av verktøy som AmICited.com reflekterer økende etterspørsel etter åpenhet og ansvarlighet i hvordan KI-systemer bruker publisert innhold, noe som tyder på at overvåkning og verifisering vil bli standard for innholdsskapere. Etter hvert som KI-bransjen modnes, kan vi forvente mer sofistikerte forhandlinger mellom innholdsskapere og KI-selskaper, noe som potensielt kan føre til nye forretningsmodeller der utgivere får rettferdig kompensasjon for sitt bidrag til KI-trening.
Meta-ExternalAgent er Metas dedikerte KI-treningscrawler lansert i juli 2024, identifisert av User-Agent-strengen meta-externalagent/1.1. Den skiller seg fra facebookexternalhit, som genererer lenkeforhåndsvisninger for sosial deling. Meta-ExternalAgent samler spesifikt innhold for trening av LLaMA-modeller og Meta AI, mens facebookexternalhit har blitt brukt for sosiale funksjoner siden rundt 2010.
Du kan blokkere Meta-ExternalAgent ved å legge til direktiver i robots.txt-filen din. Legg til 'User-agent: meta-externalagent' etterfulgt av 'Disallow: /' for å blokkere den fullstendig. For mer omfattende beskyttelse, implementer blokkering på servernivå med .htaccess (Apache) eller Nginx-konfigurasjonsregler. Husk at robots.txt er frivillig og ikke juridisk bindende, så noen utgivere rapporterer fortsatt crawling til tross for blokkering.
Nei, blokkering av Meta-ExternalAgent vil ikke påvirke Facebook-lenkeforhåndsvisninger. Crawleren facebookexternalhit håndterer lenkeforhåndsvisninger og sosiale delingsfunksjoner. Du kan blokkere meta-externalagent og likevel la facebookexternalhit generere attraktive forhåndsvisninger når innholdet ditt deles på Meta-plattformer.
Meta-ExternalAgent har et crawl-til-henvisningsforhold på omtrent 73 000:1, noe som betyr at Meta henter ut innhold i enorm skala uten å sende nevneverdig trafikk tilbake til kildens nettsteder. Dette representerer en grunnleggende ubalanse sammenlignet med tradisjonelle søkemotorer, som crawler innhold i bytte mot henvisningstrafikk.
robots.txt er et æressystem og ikke juridisk bindende. Selv om mange crawlere respekterer robots.txt-direktiver, har noen utgivere rapportert at Meta-ExternalAgent fortsetter å crawlere sidene deres til tross for eksplisitte robots.txt-blokkeringer. For garantert beskyttelse bør du implementere blokkering på servernivå med HTTP-headere, CDN-regler eller brannmurkonfigurasjon.
Sjekk serverens tilgangslogger for forespørsler med User-Agent-strengen 'meta-externalagent/1.1'. Du kan også bruke overvåkningsverktøy som AmICited.com for å spore om innholdet ditt vises i Meta AI-svar. Verktøy som Dark Visitors og Cloudflare Analytics gir ytterligere innsikt i KI-crawleraktivitet på nettstedet ditt.
Ifølge data fra Cloudflare utgjør Meta-ExternalAgent omtrent 52 % av all KI-crawlertrafikk på internett, noe som gjør den til den mest aggressive KI-datasamleren. Dette overgår konkurrenter som OpenAI sin GPTBot og Googles KI-crawlere, noe som indikerer Metas dominerende posisjon innen innsamling av webinnhold til KI-trening.
Avgjørelsen avhenger av dine forretningsprioriteringer. Hvis Meta AI-trafikk er verdifull for ditt publikum, kan du vurdere å tillate den. Husk imidlertid at Meta ikke gir kompensasjon eller attribusjon for innhold brukt til KI-trening. Mange utgivere implementerer selektive blokkeringer som stopper KI-trening, men bevarer forhåndsvisningsfunksjon for sosiale delinger.
Følg med på hvordan innholdet ditt vises i Meta AI-svar på tvers av Facebook, Instagram og WhatsApp. Få innsyn i KI-henvisninger og forstå merkevarens tilstedeværelse i KI-genererte svar.
Meta AI er Metas AI-assistent integrert i Facebook, Instagram, WhatsApp og Messenger. Lær hvordan den fungerer, dens muligheter, og dens rolle i AI-overvåkning ...

Oppdag hvordan Meta AI-optimalisering forvandler annonsering på Facebook og Instagram med AI-drevet automatisering, sanntidsbudgivning og intelligent målretting...

Forstå hvordan AI-søkeboter som GPTBot og ClaudeBot fungerer, hvordan de skiller seg fra tradisjonelle søkeboter, og hvordan du optimaliserer nettstedet ditt fo...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.