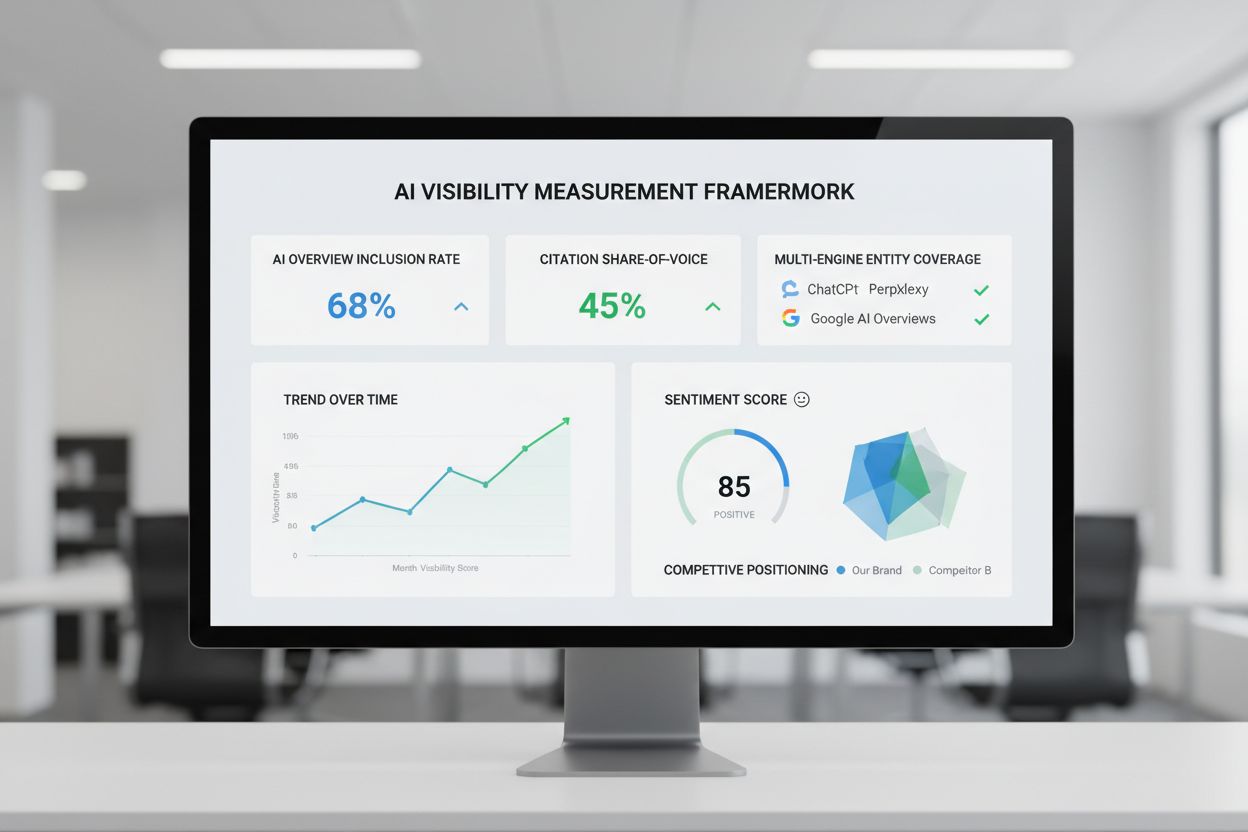
AI-synlighetsmålerammeverk
Lær hvordan du måler og optimaliserer merkevarens synlighet i AI-genererte svar. Oppdag nøkkelparametere, datainnsamlingsmetoder, konkurransebenchmarking og imp...
9 min lesing

Modellparametere er lærbare variabler i AI-modeller, som vekter og bias, som automatisk justeres under trening for å optimalisere modellens evne til å gjøre nøyaktige prediksjoner og definere hvordan modellen prosesserer inndata for å generere utdata.
Modellparametere er lærbare variabler i AI-modeller, som vekter og bias, som automatisk justeres under trening for å optimalisere modellens evne til å gjøre nøyaktige prediksjoner og definere hvordan modellen prosesserer inndata for å generere utdata.
Modellparametere er lærbare variabler i kunstige intelligensmodeller som automatisk justeres under treningsprosessen for å optimalisere modellens evne til å gjøre nøyaktige prediksjoner og definere hvordan modellen prosesserer inndata for å generere utdata. Disse parameterne fungerer som de grunnleggende “kontrollratt” i maskinlæringssystemer og bestemmer den presise atferden og beslutningsmønstrene til AI-modeller. I sammenheng med dyp læring og nevrale nettverk består parametere hovedsakelig av vekter og bias—numeriske verdier som styrer hvordan informasjon flyter gjennom nettverket og hvor sterkt ulike egenskaper påvirker prediksjoner. Hensikten med trening er å finne de optimale verdiene for disse parameterne som minimerer prediksjonsfeil og gjør det mulig for modellen å generalisere godt til nye, ukjente data. Å forstå modellparametere er avgjørende for å forstå hvordan moderne AI-systemer som ChatGPT, Claude, Perplexity og Google AI Overviews fungerer og hvorfor de gir ulike utdata for samme input.
Konseptet med lærbare parametere i maskinlæring stammer fra de tidlige dagene med kunstige nevrale nettverk på 1950- og 1960-tallet, da forskere først innså at nettverk kunne justere interne verdier for å lære fra data. Praktisk bruk av parametere var imidlertid begrenset frem til innføringen av tilbakepropagering på 1980-tallet, som ga en effektiv algoritme for å beregne hvordan parametere skulle justeres for å redusere feil. Eksplosjonen i antall parametere akselererte dramatisk med fremveksten av dyp læring på 2010-tallet. Tidlige konvolusjonsnettverk for bildeklassifisering inneholdt millioner av parametere, mens moderne store språkmodeller (LLM-er) inneholder hundrevis av milliarder eller til og med billioner av parametere. Ifølge forskning fra Our World in Data og Epoch AI har antallet parametere i kjente AI-systemer vokst eksponentielt, med GPT-3 som har 175 milliarder parametere, GPT-4o omtrent 200 milliarder, og noen anslag antyder at GPT-4 kan ha opp mot 1,8 billioner parametere når man tar høyde for mixture-of-experts-arkitektur. Denne dramatiske skaleringen har fundamentalt endret hva AI-systemer kan oppnå, og gjør det mulig å fange stadig mer komplekse mønstre i språk, bilde og resonneringsoppgaver.
Modellparametere opererer gjennom et matematisk rammeverk der hver parameter representerer en numerisk verdi som påvirker hvordan modellen transformerer input til output. I en enkel lineær regresjonsmodell består parametere av stigning (m) og konstantledd (b) i ligningen y = mx + b, hvor disse to verdiene bestemmer linjen som best tilpasser seg dataene. I nevrale nettverk blir situasjonen eksponentielt mer kompleks. Hvert nevron i et lag mottar input fra forrige lag, multipliserer hver input med en tilsvarende vekt-parameter, summerer disse vektede inputene, legger til en bias-parameter, og sender resultatet gjennom en aktiveringsfunksjon for å produsere et output. Dette outputet blir så input til nevroner i neste lag, og skaper en kjede av parameterstyrte transformasjoner. Under trening bruker modellen gradient descent og relaterte optimaliseringsalgoritmer for å beregne hvordan hver parameter bør justeres for å redusere tapfunksjonen—et matematisk mål på prediksjonsfeil. Gradientene av tapet med hensyn til hver parameter viser retning og størrelse på nødvendig justering. Gjennom tilbakepropagering flyter disse gradientene bakover gjennom nettverket, slik at optimalisatoren kan oppdatere alle parameterne samtidig på en koordinert måte. Denne iterative prosessen fortsetter over flere treningsrunder til parameterne konvergerer mot verdier som minimerer tapet på treningsdata og samtidig gir god generalisering til nye data.
| Aspekt | Modellparametere | Hyperparametere | Egenskaper (Features) |
|---|---|---|---|
| Definisjon | Lærbare variabler som justeres under trening | Konfigurasjonsinnstillinger definert før trening | Inndatakjennetegn som brukes av modellen |
| Når satt | Automatisk lært gjennom optimalisering | Manuelt konfigurert av fagpersoner | Ekstrahert eller konstruert fra rådata |
| Eksempler | Vekter, bias i nevrale nettverk | Læringsrate, batch-størrelse, antall lag | Pikselverdier i bilder, ordeembeddings i tekst |
| Innvirkning på modell | Bestemmer hvordan modellen kobler input til output | Kontrollerer treningsprosess og modellstruktur | Gir råinformasjon modellen lærer fra |
| Optimaliseringsmetode | Gradient descent, Adam, AdaGrad | Grid search, random search, Bayesiansk optimering | Feature engineering, feature selection |
| Antall i store modeller | Milliarder til billioner (f.eks. 200B i GPT-4o) | Typisk 5-20 nøkkelhyperparametere | Tusenvis til millioner avhengig av data |
| Beregningkostnad | Høy under trening; påvirker inferenshastighet | Minimal beregningskostnad å sette | Avhenger av datainnsamling og forhåndsbehandling |
| Overførbarhet | Kan overføres via finjustering og transfer learning | Må justeres for nye oppgaver | Kan kreve nyutvikling for nye domener |
Modellparametere har ulike former avhengig av arkitektur og type maskinlæringsmodell. I konvolusjonsnettverk (CNN) for bildeanalyse inkluderer parametere vektene i konvolusjonsfiltre (også kalt kjerner) som oppdager romlige mønstre som kanter, teksturer og former på ulike skalaer. Recurrent Neural Networks (RNN) og Long Short-Term Memory (LSTM)-nettverk har parametere som styrer informasjonsflyt over tid, inkludert porteringsparametere som avgjør hva som skal huskes eller glemmes. Transformer-modeller, som driver moderne store språkmodeller, har parametere i flere komponenter: oppmerksomhetsvekter som avgjør hvilke deler av inputen som skal fokuseres på, vekter i feed-forward-nettverk og parametere for lag-normalisering. I sannsynlighetsmodeller som Naive Bayes definerer parametere betingede sannsynlighetsfordelinger. Support Vector Machines bruker parametere som plasserer og orienterer beslutningsgrenser i egenskapsrommet. Mixture of Experts (MoE)-modeller, brukt i noen versjoner av GPT-4, har parametere for flere spesialiserte delnettverk samt rutingsparametere som avgjør hvilke eksperter som prosesserer hvert input. Denne arkitektoniske variasjonen betyr at natur og antall parametere varierer betydelig mellom ulike modelltyper, men det grunnleggende prinsippet er konstant: parametere er de lærte verdiene som gjør det mulig for modellen å utføre sin oppgave.
Vekter og bias er de to grunnleggende typene parametere i nevrale nettverk og utgjør grunnlaget for hvordan disse modellene lærer. Vekter er numeriske verdier tildelt forbindelser mellom nevroner, og bestemmer styrken og retningen på påvirkningen et nevron har på input til neste nevron. I et fullt tilkoblet lag med 1 000 input-nevroner og 500 output-nevroner vil det være 500 000 vektparametere—én for hver forbindelse. Under trening justeres vektene for å øke eller redusere påvirkningen spesifikke egenskaper har på prediksjoner. En stor positiv vekt betyr at egenskapen sterkt aktiverer neste nevron, mens en negativ vekt hemmer det. Bias er tilleggsparametere, én per nevron i et lag, som gir et konstant tillegg til nevronets inputsum før aktiveringsfunksjonen anvendes. Matematisk sett, hvis et nevron får vektede input som summerer til null, gjør bias det mulig for nevronet å produsere et ikke-null output, og gir viktig fleksibilitet. Denne fleksibiliteten gjør det mulig for nevrale nettverk å lære komplekse beslutningsgrenser og fange mønstre som ikke ville vært mulig kun med vekter. I en modell med 200 milliarder parametere som GPT-4o, er det store flertall vekter i oppmerksomhetsmekanismer og feed-forward-nettverk, med bias utgjør en mindre, men fortsatt betydelig andel. Sammen gjør vekter og bias det mulig for modellen å lære de intrikate mønstrene i språk, bilde eller andre domener som gjør moderne AI-systemer så kraftige.
Antall parametere i en modell har stor innvirkning på dens evne til å lære komplekse mønstre og dens samlede ytelse. Forskning viser at skaleringslover styrer forholdet mellom parameterantall, treningsdatas størrelse og modellens ytelse. Modeller med flere parametere kan representere mer komplekse funksjoner og fange flere nyanserte mønstre i data, noe som vanligvis gir bedre ytelse på krevende oppgaver. GPT-3 med 175 milliarder parametere viste bemerkelsesverdige evner til få-skudds-læring som mindre modeller ikke kunne matche. GPT-4o med 200 milliarder parametere viser ytterligere forbedringer i resonnering, kodegenerering og multimodal forståelse. Forholdet mellom parametere og ytelse er imidlertid ikke lineært og avhenger kritisk av mengde og kvalitet på treningsdata. En modell med for mange parametere i forhold til treningsdata vil overtilpasse, altså huske spesifikke eksempler fremfor å lære generaliserbare mønstre, noe som gir dårlig ytelse på nye data. Omvendt kan en modell med for få parametere undertilpasse, og ikke fange viktige mønstre, slik at ytelsen blir suboptimal selv på treningsdata. Det optimale parameterantallet for en gitt oppgave avhenger av faktorer som oppgavens kompleksitet, treningsdatas størrelse og variasjon, samt beregningsbegrensninger. Forskning fra Epoch AI viser at moderne AI-systemer har oppnådd bemerkelsesverdig ytelse gjennom massiv skalering, med noen modeller som inneholder billioner av parametere i mixture-of-experts-arkitekturer der ikke alle parametere er aktive for hvert input.
Selv om store modeller med milliarder av parametere oppnår imponerende ytelse, er det betydelige beregningskostnader knyttet til å trene og bruke slike modeller. Dette har drevet frem forskning på parameter-effektive finjusteringsmetoder som gjør det mulig å tilpasse forhåndstrente modeller til nye oppgaver uten å oppdatere alle parametere. LoRA (Low-Rank Adaptation) er en fremtredende teknikk som fryser de fleste forhåndstrente parametere og bare trener et lite sett med ekstra lav-rangs matriser, noe som reduserer antall trenbare parametere kraftig samtidig som ytelsen opprettholdes. For eksempel kan finjustering av en modell med 7 milliarder parametere med LoRA innebære å trene bare 1–2 millioner ekstra parametere i stedet for alle 7 milliarder. Adaptermoduler setter inn små trenbare nettverk mellom lagene i en frosset forhåndstrent modell, og legger bare til en liten prosentandel parametere mens de muliggjør oppgavespesifikk tilpasning. Prompt engineering og in-context learning representerer alternative tilnærminger som ikke endrer parametere i det hele tatt, men bruker modellens eksisterende parametere mer effektivt gjennom nøye utformede input. Disse parameter-effektive tilnærmingene har demokratisert tilgangen til store språkmodeller, slik at organisasjoner med begrensede ressurser kan tilpasse toppmodeller til sine behov. Avveiningen mellom parameter-effektivitet og ytelse er fortsatt et aktivt forskningsområde, hvor fagmiljøet balanserer ønsket om høy beregningseffektivitet mot behovet for oppgavespesifikk nøyaktighet.
Å forstå modellparametere er avgjørende for plattformer som AmICited som overvåker hvordan merkevarer og domener opptrer i AI-genererte svar på tvers av systemer som ChatGPT, Perplexity, Claude og Google AI Overviews. Ulike AI-modeller med ulike parameterkonfigurasjoner produserer forskjellige utdata for samme forespørsel, noe som påvirker hvor og hvordan merkevarer nevnes. De 200 milliardene parameterne i GPT-4o er konfigurert annerledes enn parameterne i Claude 3.5 Sonnet eller Perplexitys modeller, noe som gir variasjoner i svarene. Parametere lært under trening på ulike datasett og med forskjellige treningsmål gjør at modellene har ulik kunnskap, resonneringsmønstre og siteringsatferd. Når man overvåker merkevareomtale i AI-svar, hjelper forståelsen av at disse forskjellene kommer fra parameter-variasjon å forklare hvorfor en merkevare kan være fremtredende i ett AI-svar, men knapt nevnt i et annet. Parameterne som styrer oppmerksomhetsmekanismer avgjør hvilke deler av treningsdata som er mest relevante for en forespørsel og påvirker siteringsmønstre. Parametere i output-genereringslagene avgjør hvordan modellen strukturerer og presenterer informasjon. Ved å spore hvordan ulike AI-systemer med forskjellige parameterkonfigurasjoner nevner merkevarer, gir AmICited innsikt i hvordan parameterstyrt modellatferd påvirker merkevaresynlighet i AI-drevne søk.
Fremtiden for modellparametere formes av flere sammenfallende trender som fundamentalt vil endre hvordan AI-systemer designes og implementeres. Mixture of Experts (MoE)-arkitekturer representerer en betydelig utvikling, der modeller inneholder flere spesialiserte delnettverk (eksperter) med egne parametere, og en rutemekanisme avgjør hvilke eksperter som prosesserer hvert input. Denne tilnærmingen gjør det mulig å skalere til billioner av parametere samtidig som man opprettholder beregningseffektivitet under bruk, fordi ikke alle parametere er aktive for hvert input. Det rapporteres at GPT-4 bruker en MoE-arkitektur med 16 eksperter, hver med 110 milliarder parametere, totalt 1,8 billioner, men kun en brøkdel brukes ved inferens. Sparsifiserte parametere og beskjæringsteknikker utvikles for å identifisere og fjerne mindre viktige parametere, redusere modellstørrelse uten å ofre ytelse. Kontinuerlig læring har som mål å oppdatere parametere effektivt etter hvert som nye data blir tilgjengelig, slik at modeller kan tilpasse seg uten full nytrening. Federert læring fordeler parametertrening på flere enheter med personvern ivaretatt, slik at organisasjoner kan dra nytte av storskala trening uten å sentralisere sensitive data. Fremveksten av små språkmodeller (SLM-er) med milliarder i stedet for hundrevis av milliarder parametere antyder en fremtid der parametereffektivitet blir like viktig som antall. Etter hvert som AI-systemer integreres i kritiske applikasjoner, vil forståelse og kontroll av modellparametere bli stadig viktigere for å sikre sikkerhet, rettferdighet og samsvar med menneskelige verdier. Forholdet mellom parameterantall og modellatferd vil forbli et sentralt tema i AI-forskningen, med konsekvenser for alt fra bærekraftig databehandling til tolkbarhet og pålitelighet i AI-systemer.
Modellparametere er interne variabler som læres under trening gjennom optimaliseringsalgoritmer som gradient descent, mens hyperparametere er eksterne innstillinger som konfigureres før treningen starter. Parametere bestemmer hvordan modellen kobler inndata til utdata, mens hyperparametere styrer selve treningsprosessen, for eksempel læringsrate og antall epoker. For eksempel er vekter og bias i nevrale nettverk parametere, mens læringsrate er en hyperparameter.
Moderne store språkmodeller inneholder milliarder til billioner av parametere. GPT-4o inneholder omtrent 200 milliarder parametere, mens GPT-4o-mini har rundt 8 milliarder. Claude 3.5 Sonnet opererer også med hundrevis av milliarder parametere. Disse enorme mengdene av parametere gjør det mulig for modellene å fange opp komplekse mønstre i språk og generere avanserte, kontekstuelt relevante svar på tvers av ulike temaer.
Flere parametere øker modellens kapasitet til å lære komplekse mønstre og sammenhenger i data. Med flere parametere kan modeller representere mer nyanserte egenskaper og interaksjoner, noe som gir høyere nøyaktighet på treningsdata. Det finnes imidlertid en kritisk balanse: for mange parametere i forhold til treningsdata kan føre til overtilpasning, hvor modellen husker støy i stedet for å lære generaliserbare mønstre, noe som gir dårlig ytelse på nye, ukjente data.
Modellparametere oppdateres gjennom tilbakepropagering og optimaliseringsalgoritmer som gradient descent. Under trening gjør modellen prediksjoner, beregner tapet (feilen) mellom prediksjoner og faktiske verdier, og deretter beregnes gradienter som viser hvordan hver parameter bidro til denne feilen. Optimalisatoren justerer så parameterne i retning som reduserer tapet, og denne prosessen gjentas over mange treningsiterasjoner til modellen konvergerer mot optimale verdier.
Vekter bestemmer styrken på forbindelsene mellom nevroner i nevrale nettverk, og kontrollerer hvor sterkt inndata påvirker utdata. Bias fungerer som terskeljusteringer, slik at nevroner kan aktiveres selv når vektene gir null, og gir fleksibilitet slik at modellen kan lære grunnmønstre. Sammen utgjør vekter og bias de sentrale lærbare parameterne som gjør det mulig for nevrale nettverk å tilnærme seg komplekse funksjoner og gjøre nøyaktige prediksjoner.
Modellparametere påvirker direkte hvordan AI-systemer som ChatGPT, Perplexity og Claude prosesserer og svarer på forespørsler. Forståelse av parameterantall og -konfigurasjoner hjelper å forklare hvorfor ulike AI-modeller gir forskjellige utdata for samme prompt. For plattformer for merkevareovervåking som AmICited er det avgjørende å spore hvordan parametere påvirker modellens atferd for å forutsi hvor merkevarer vises i AI-svar og forstå konsistensen på tvers av ulike AI-systemer.
Ja, gjennom transfer learning kan parametere fra en forhåndstrent modell tilpasses nye oppgaver. Denne tilnærmingen, kalt finjustering, innebærer å ta en modell med lærte parametere og justere dem på nye data for spesifikke bruksområder. Parameter-effektive finjusteringsmetoder som LoRA (Low-Rank Adaptation) tillater selektiv oppdatering av parametere, noe som reduserer datakostnader og opprettholder ytelsen. Denne teknikken er mye brukt for å tilpasse store språkmodeller til spesialiserte domener.
Modellparametere påvirker direkte kravene til beregningsressurser under både trening og bruk. Flere parametere krever mer minne, prosessorkraft og tid for å trene og distribuere. En modell med 175 milliarder parametere (som GPT-3) krever betydelig mer ressurser enn en modell med 7 milliarder parametere. Dette forholdet er kritisk for organisasjoner som implementerer AI-systemer, fordi antall parametere påvirker infrastrukturkostnader, forsinkelse og energiforbruk i produksjonsmiljøer.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Lær hvordan du måler og optimaliserer merkevarens synlighet i AI-genererte svar. Oppdag nøkkelparametere, datainnsamlingsmetoder, konkurransebenchmarking og imp...

Lær hvordan produktspekifikasjoner forbedrer AI-anbefalingssystemer ved å gi strukturert data, øke nøyaktigheten og muliggjøre bedre personalisering for brukere...

Lær hvordan finjustering av AI-modeller tilpasser forhåndstrente modeller for spesifikke bransje- og merkevarerelaterte oppgaver, forbedrer nøyaktigheten og red...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.