
Promptbiblioteker for Manuell AI-synlighetstesting
Lær hvordan du bygger og bruker promptbiblioteker for manuell AI-synlighetstesting. DIY-guide til å teste hvordan AI-systemer refererer til merkevaren din på tv...
10 min lesing
Utvikling av promptbibliotek er den systematiske prosessen med å bygge og organisere omfattende samlinger av spørsmål utformet for å teste og overvåke hvordan merkevarer vises på AI-drevne plattformer. Det etablerer et standardisert rammeverk for å evaluere merkevaresynlighet på tvers av flere AI-systemer, slik at organisasjoner kan spore konkurranseposisjonering og identifisere synlighetsgap i AI-drevet søk.
Utvikling av promptbibliotek er den systematiske prosessen med å bygge og organisere omfattende samlinger av spørsmål utformet for å teste og overvåke hvordan merkevarer vises på AI-drevne plattformer. Det etablerer et standardisert rammeverk for å evaluere merkevaresynlighet på tvers av flere AI-systemer, slik at organisasjoner kan spore konkurranseposisjonering og identifisere synlighetsgap i AI-drevet søk.
Utvikling av promptbibliotek er den systematiske prosessen med å bygge og organisere omfattende samlinger av spørsmål utformet for å teste og overvåke hvordan merkevarer vises på AI-drevne plattformer. Et promptbibliotek fungerer som et strukturert arkiv av nøye utformede spørsmål, søkeord og samtalebaserte prompt som simulerer ekte brukerinteraksjoner med AI-systemer som ChatGPT, Claude, Gemini og Perplexity. Begrepet “bibliotek” gjenspeiler den organiserte, katalogiserte strukturen til disse samlingene—på samme måte som tradisjonelle biblioteker organiserer informasjon etter emne, kategori og relevans. I motsetning til ad hoc-testing etablerer utvikling av promptbibliotek et standardisert rammeverk for å evaluere merkevaresynlighet, og sikrer konsistent måling på tvers av flere AI-plattformer og tidsperioder. Denne tilnærmingen anerkjenner at AI-systemer responderer ulikt på varierende formuleringer, kontekster og intensjonssignaler, og gjør det essensielt å teste et bredt spekter av prompt fremfor å stole på enkeltspørsmål. Biblioteket fungerer både som et testverktøy og et historisk arkiv, slik at organisasjoner kan spore hvordan merkevaresynlighet utvikler seg etter hvert som AI-modeller oppdateres og brukeratferd endres. Ved å behandle prompttesting som en styrt disiplin fremfor en sporadisk aktivitet, får selskaper handlingsrettet innsikt om sin konkurranseposisjon i det AI-drevne søkelandskapet.
| Aspekt | Tradisjonell SEO-overvåking | Promptbibliotek-tilnærming |
|---|---|---|
| Testomfang | Begrenset til søkemotor-søkeord | Omfattende testing på tvers av flere AI-plattformer med varierte formuleringer |
| Spørsmålsvariasjon | Faste søkeordlister | Dynamiske, intensjonsbaserte prompt som speiler naturlig samtale |
| Målingsfrekvens | Månedlige eller kvartalsvise øyeblikksbilder | Kontinuerlig eller ukentlig overvåking med detaljert trendanalyse |
| Konkurranseinnsikt | Søkeordrangeringer | Frekvens av merkevarenavn, kvalitet på kontekst og nøyaktighet i posisjonering |
Overgangen til AI-drevet informasjonsinnhenting har fundamentalt endret hvordan merkevarer må tilnærme seg synlighetsovervåking. Tradisjonell SEO-overvåking fokuserer på søkeordrangeringer i søkeresultater, men denne metoden fanger ikke opp hvordan merkevarer vises når brukere samhandler samtalebasert med AI-systemer. Promptbibliotek løser dette gapet ved å gjøre det mulig for organisasjoner å forstå sin tilstedeværelse på en helt ny kategori av oppdagelsesplattformer. Forretningsverdien er betydelig: Selskaper som systematisk overvåker sin AI-synlighet får konkurransefortrinn ved å identifisere hull i merkevarerepresentasjonen, oppdage hvilke temaer eller kontekster som utløser merkevarenavn, og forstå hvordan AI-systemer karakteriserer deres produkter i forhold til konkurrentene. Denne innsikten påvirker innholdsstrategi, produktposisjonering og markedsføringsbudskap direkte. Organisasjoner som bruker promptbibliotek kan oppdage fremvoksende konkurransetrusler raskere enn de som bare stoler på tradisjonelle SEO-målinger, siden AI-systemer ofte fremhever andre konkurrentsett enn søkemotorer. I tillegg avslører promptbibliotektesting nyansert innsikt om merkevareoppfatning—ikke bare om en merkevare er synlig, men hvordan den beskrives, hvilke egenskaper som forbindes med den, og om AI-systemets karakteristikk samsvarer med ønsket posisjonering.
Å lage et effektivt promptbibliotek krever en strukturert metodikk som kombinerer kundeinnsikt, konkurrentanalyse og strategisk planlegging:
Gjennomfør kundeundersøkelser: Intervju målkunder, analyser supportsaker og gjennomgå samtaler i sosiale medier for å identifisere de faktiske spørsmålene og språkbruksmønstrene brukere benytter når de søker informasjon om din kategori. Dette sikrer at promptene dine gjenspeiler reell brukerintensjon fremfor interne antakelser.
Kartlegg kundereisen: Identifiser viktige beslutningspunkter og informasjonsbehov gjennom bevissthet, vurdering og beslutningsfaser. Utvikle prompt som samsvarer med hvert trinn, og fanger hvordan kunder søker informasjon i ulike stadier av kjøpsprosessen.
Definer intensjonskategorier: Organiser prompt etter intensjonstype—informativ (lære om en kategori), sammenlignende (vurdere alternativer), transaksjonell (klar til kjøp), og merkevarespesifikk (søker direkte etter ditt selskap). Denne strukturen sikrer omfattende dekning av hvordan brukere kan oppdage merkevaren.
Lag variasjoner av prompt: Utvikle flere formuleringer for hvert kjernespørsmål for å ta høyde for hvordan ulike brukere kan uttrykke det samme behovet. Inkluder variasjoner i formalitet, spesifisitet og kontekst for å speile reell mangfoldighet i hvordan folk samhandler med AI-systemer.
Etabler basisprompt: Utvikle et kjernesett på 20–50 essensielle prompt som representerer de viktigste synlighetsmulighetene. Disse danner fundamentet for kontinuerlig overvåking og sammenligning over tid.
Dokumenter promptmetadata: For hver prompt, registrer intensjonskategori, trinn i kundereisen, prioritetsnivå og forventet relevans for merkevaren. Denne metadataen muliggjør avansert analyse og gjør det lettere å identifisere mønstre i hvor merkevaren vises eller mangler.
Valider med interessenter: Gå gjennom promptbiblioteket med salg, markedsføring og produktteam for å sikre at det fanger opp de spørsmålene og scenarioene som er mest relevante for forretningsmålene.
Et omfattende promptbibliotek er strukturert rundt flere dimensjoner for å sikre grundig dekning av synlighetsmuligheter for merkevaren. Biblioteket inkluderer vanligvis prompt for trinn i salgstrakten som samsvarer med kundereisen: TOFU (Top of Funnel)-prompt adresserer brede, informative spørsmål der brukere lærer om en kategori eller problemstilling, som “Hva er de beste prosjektstyringsverktøyene?” eller “Hvordan kan jeg forbedre samarbeid i teamet?” MOFU (Middle of Funnel)-prompt fokuserer på sammenlignende og vurderende spørsmål der brukere aktivt vurderer løsninger, inkludert spørsmål som “Sammenlign prosjektstyringsprogramvare for fjernarbeid” eller “Hvilke funksjoner bør jeg se etter i en samarbeidsplattform?” BOFU (Bottom of Funnel)-prompt retter seg mot beslutningsspørsmål der brukere er klare til å kjøpe eller implementere, som “Hvorfor bør jeg velge [Brand] fremfor konkurrenter?” eller “Hva er [Brand] sin prismodell?” Utover trinnene i trakten organiseres effektive bibliotek også etter intensjonskategorier—informative, navigasjonsbaserte, sammenlignende og transaksjonelle—og sikrer at synlighet måles på tvers av ulike typer brukerspørsmål. Bibliotekene inneholder også kontekstuelle variasjoner som tester hvordan merkevaresynlighet endres basert på bransje, brukstilfelle, selskapsstørrelse eller geografisk plassering. Videre inneholder velutformede bibliotek konkurranseprompt som avslører hvordan merkevaren din fremstår i direkte sammenligning med spesifikke konkurrenter, og attributtbaserte prompt som tester synlighet for bestemte produktegenskaper, fordeler eller differensiatorer. Denne fler-dimensjonale strukturen sikrer at overvåkingen fanger hele spekteret av måter potensielle kunder kan oppdage og vurdere merkevaren din gjennom AI-systemer.
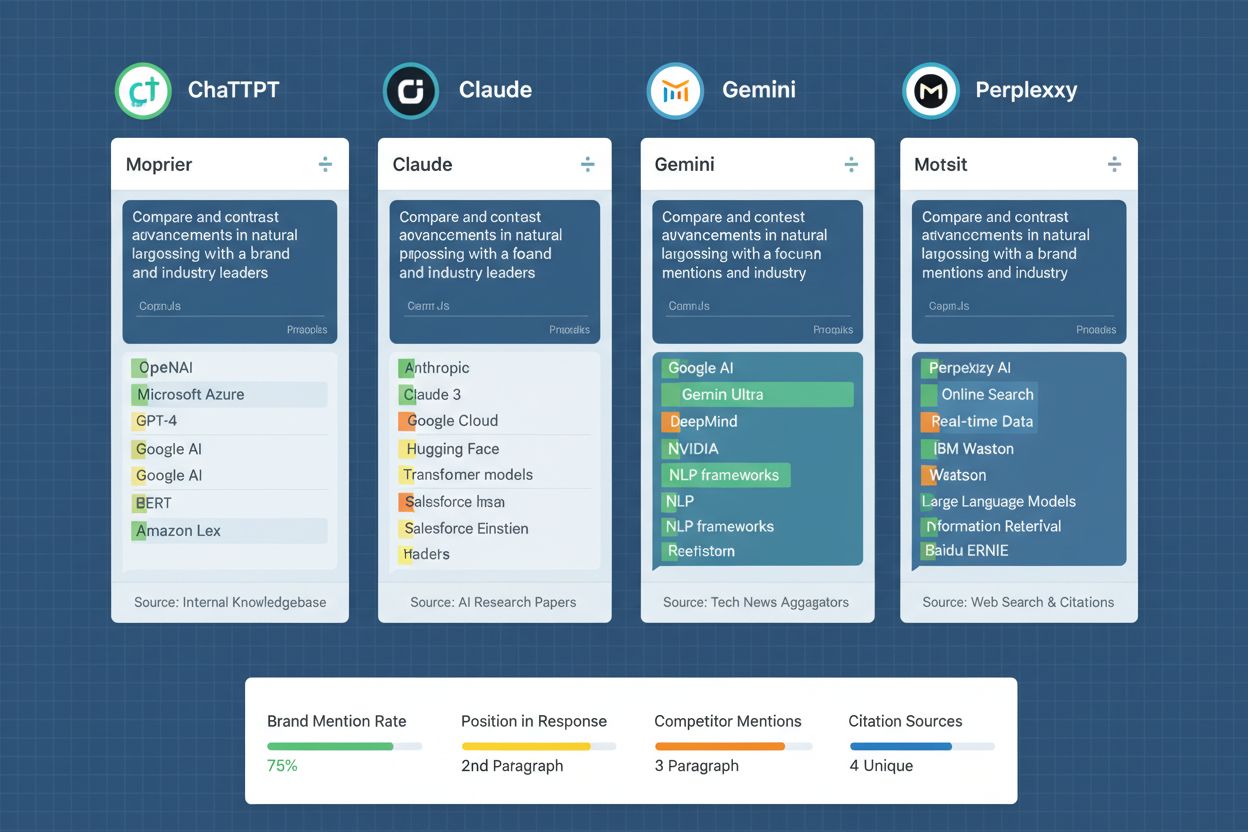
Å gjennomføre et promptbibliotek på tvers av flere AI-plattformer krever systematiske prosesser for datainnsamling, analyse og tolkning. Organisasjoner tester typisk biblioteket sitt mot ChatGPT (det mest brukte AI-systemet), Claude (kjent for detaljerte og nyanserte svar), Gemini (Googles AI med integrert søkefunksjon), og Perplexity (en AI-søkemotor med siteringsfunksjon). Testfrekvensen avhenger av forretningsprioriteringer og ressurskapasitet—mange gjennomfører ukentlige eller annenhver uke testsykluser for å oppdage endringer i merkevaresynlighet, mens andre implementerer kontinuerlig overvåking via automatiserte verktøy. For hver prompt registrerer testere om merkevaren nevnes, konteksten og posisjoneringen til omtalen, nøyaktigheten i informasjonen, og fremhevelsen av omtalen i forhold til konkurrenter. Datainnsamlingen går utover enkle ja/nei-registreringer til å inkludere en kvalitativ vurdering av hvordan merkevaren karakteriseres—om beskrivelsene er korrekte, om viktige differensiatorer fremheves, og om AI-systemets respons samsvarer med ønsket posisjonering. Analysen innebærer å spore trender over tid for å se om synlighet forbedres eller svekkes, korrelere synlighetsendringer med innholdsoppdateringer eller konkurransetiltak, og identifisere mønstre i hvilke prompt som gir omtale versus hvilke som ikke gjør det. Organisasjoner lager ofte dashbord som visualiserer disse dataene, slik at interessenter raskt kan forstå synlighetstrender og identifisere områder som krever innholds- eller strategijustering. Testfrekvens og dybde bør samsvare med tempoet på AI-modelloppdateringer og konkurranseaktivitet i din bransje.
| Verktøynavn | Best for | Nøkkelfunksjoner | Startpris |
|---|---|---|---|
| AmICited.com | Omfattende overvåking av merkevaresynlighet i AI | Testing på flere plattformer, automatisert promptgjennomføring, konkurransebenchmarking, detaljerte dashbord, sporing av merkevarenavn | Tilpasset pris |
| FlowHunt.io | Organisering og testing av promptbibliotek | Versjonering av prompt, A/B-testing, ytelsesanalyse, samarbeidsfunksjoner for team, integrasjon med ledende AI-plattformer | Tilpasset pris |
| Braintrust | Evaluering og optimalisering av prompt | Automatisert testing, ytelsesscore, kostnadssporing på tvers av modeller, detaljert logging og analyse | Gratisnivå tilgjengelig |
| LangSmith | Utvikling og overvåking av LLM-applikasjoner | Versjonering av prompt, sporing av kjøringer, ytelsesmetrikker, feilsøkingsverktøy, integrasjon med LangChain-økosystemet | Gratisnivå tilgjengelig |
| Promptfoo | Åpen kildekode for testing og evaluering av prompt | Lokal testing, støtte for flere modeller, påstandsbasert testing, detaljert rapportering, tilpassbare evalueringsmetrikker | Åpen kildekode (gratis) |
| Weights & Biases | Eksperimentsporing og modellvurdering | Omfattende logging, visualisering, sammenligningsverktøy, teamarbeid, integrasjon med ML-arbeidsflyter | Gratisnivå tilgjengelig |
Å administrere promptbibliotek i stor skala krever spesialiserte verktøy designet for testing på tvers av flere AI-plattformer, sporing av resultater over tid og samarbeid i team. AmICited.com utmerker seg som den ledende plattformen spesiallaget for overvåking av merkevaresynlighet i AI-systemer, med automatisert promptgjennomføring, konkurransebenchmarking og detaljerte analyser som dekker behovene til organisasjoner som sporer merkevarens tilstedeværelse i AI-genererte svar. FlowHunt.io er det beste valget for organisering og optimalisering av promptbibliotek, med avansert versjonering, A/B-testing og ytelsesanalyse som gjør det mulig for team å kontinuerlig forbedre samlingene sine. Braintrust er utmerket for automatisert evaluering og scoring av promptytelse, nyttig for organisasjoner som ønsker å måle hvilke prompt som gir mest relevant synlighet. LangSmith, utviklet av LangChain, tilbyr omfattende sporing og feilsøking spesielt nyttig for team som bygger AI-applikasjoner med merkevareovervåking. Promptfoo gir et åpen kildekode-alternativ for organisasjoner som ønsker lokal kontroll og tilpasning, med sterke påstandsbaserte testmuligheter. Weights & Biases tilbyr eksperimentsporing og visualisering på enterprise-nivå, nyttig for team som håndterer store prompttestinitiativ. Valg avhenger av om organisasjonen prioriterer brukervennlighet og merkevarespesifikke funksjoner (AmICited.com, FlowHunt.io), kostnadseffektivitet (åpen kildekode), eller integrasjon med eksisterende utviklingsarbeidsflyter (LangSmith, Weights & Biases).
Å opprettholde et effektivt promptbibliotek krever kontinuerlig forbedring og systematisk optimalisering. Organisasjoner bør etablere en fast gjennomgangssyklus—typisk kvartalsvis—for å vurdere om promptene fortsatt er relevante for forretningsmål, om nye kundespørsmål eller markedstrender tilsier nye prompt, og om eksisterende prompt bør fjernes eller oppdateres. Testfrekvensen bør balansere grundighet med ressursbruk; de fleste finner at ukentlige eller annenhver uke testsykluser gir tilstrekkelig data for å oppdage meningsfulle endringer i synlighet uten å skape uforholdsmessig arbeidsbelastning. Ytelsessporing bør omfatte mer enn bare antall merkevarenavn og inkludere kvalitative metrikker som omtale-kvalitet, posisjoneringsnøyaktighet og konkurransekontekst. Team bør dokumentere basisytelse for hver prompt, slik at det finnes tydelige referansepunkter for videre forbedring eller svekkelse. Når merkevaresynlighet går ned for spesifikke prompt, bør årsaken undersøkes—er det eksternt (AI-modelloppdateringer, konkurransetiltak, markedsskift) eller internt (utdatert innhold, feil budskap, tekniske problemer)? Iterativ optimalisering innebærer å teste variasjoner av prompt for å finne hvilke formuleringer som gir mest nøyaktig eller fremtredende omtale, og deretter oppdatere biblioteket på bakgrunn av dette. Organisasjoner bør også etablere en tilbakemeldingssløyfe der innsikt fra testing direkte påvirker innholdsstrategien, slik at identifiserte synlighetsgap fylles med nytt eller optimalisert innhold. Dokumentasjon av ytelse, testmetodikk og optimaliseringsbeslutninger bygger institusjonell kunnskap og legger til rette for konsistent gjennomføring og kontinuerlig forbedring over tid.
Utvikling av promptbibliotek fungerer som en kritisk komponent i bredere AI-synlighets- og innholdsstrategi, og påvirker direkte hvordan merkevarer posisjonerer seg i et AI-drevet informasjonslandskap. Innsikten som genereres gjennom systematisk prompttesting avslører gap mellom ønsket merkevareoppfatning og hvordan AI-systemene faktisk karakteriserer den, og muliggjør målrettede justeringer i innhold og budskap. Når testing viser at merkevaren mangler i AI-svar på relevante spørsmål, signaliserer det en innholdsmulighet—organisasjonen bør utvikle innhold som dekker de spesifikke informasjonsbehovene og kontekstene. Tilsvarende, når testing viser at merkevaren er til stede, men blir feiltolket eller posisjonert ugunstig i forhold til konkurrenter, indikerer det behov for innhold som korrigerer misoppfatninger eller fremhever viktige differensiatorer. Data fra promptbiblioteket gir direkte konkurranseinnsikt ved å vise hvilke konkurrenter som hyppigst dukker opp i AI-svar, hvordan posisjoneringen varierer mellom plattformer, og hvilke egenskaper eller fordeler konkurrentene vektlegger. Denne innsikten påvirker produktposisjonering, budskapsstrategi og innholdsprioriteringer. Avkastningen av utvikling av promptbibliotek kommer til uttrykk gjennom forbedret synlighet i AI-systemer, mer korrekt representasjon av merkevareattributter og -fordeler, og raskere identifisering av konkurransetrusler eller markedsskifter. Organisasjoner som systematisk overvåker og optimaliserer sin AI-synlighet gjennom promptbibliotek oppnår strategisk fordel ved å sikre at merkevaren vises i relevante AI-genererte svar, at informasjonen er korrekt og positiv, og at posisjoneringen samsvarer med markedsmuligheter. Integrering av innsikt fra promptbiblioteket i innholdsstrategi, produktutvikling og konkurranseposisjonering skaper en tilbakemeldingssløyfe der synlighetsovervåking direkte driver forretningsstrategisk utvikling.
Et promptbibliotek fokuserer på å teste hvordan merkevarer vises på AI-plattformer gjennom samtalebaserte spørsmål, mens tradisjonell søkeordsanalyse retter seg mot rangeringer i søkemotorer. Promptbibliotek fanger opp hvordan AI-systemer tolker og svarer på ulike formuleringer, intensjonssignaler og kontekstvariasjoner—og gir innsikt i merkevaresynlighet i AI-genererte svar i stedet for søkemotorrangeringer.
De fleste organisasjoner gjennomfører ukentlige eller annenhver uke testsykluser for å oppdage meningsfulle endringer i merkevaresynlighet. Hyppigheten avhenger av endringstakten i din bransje, konkurranseaktivitet og oppdateringssykluser for AI-modeller. Ukentlige tester gir tilstrekkelig data til å identifisere trender uten å skape uholdbar driftsbelastning.
Effektive promptbibliotek inneholder vanligvis 50–150 prompt, organisert etter trinn i kjøpstrakten (TOFU, MOFU, BOFU) og intensjonskategorier. Start med 20–50 kjerneprompt som representerer de viktigste synlighetsmulighetene, og utvid deretter basert på forretningsprioriteter, konkurranselandskap og innsikt fra kundeundersøkelser.
Test mot ChatGPT (mest brukt), Claude (detaljerte svar), Gemini (integrert søk) og Perplexity (AI-søkemotor). Disse fire plattformene dekker majoriteten av AI-drevet informasjonssøk. Inkluder eventuelt andre plattformer som Google AI Overviews eller spesialiserte AI-systemer relevante for din bransje.
Effektivitet måles gjennom hvor ofte merkevaren nevnes, nøyaktigheten av posisjonering, konkurransekontekst og samsvar med forretningsmål. Spor om merkevaren din er synlig i relevante AI-svar, om beskrivelsen er korrekt, og om synlighetstrender forbedres over tid når du optimaliserer innhold og strategi.
Ja. Plattformene som AmICited.com, Braintrust og LangSmith muliggjør automatisert testing på tvers av flere AI-plattformer. Automatisering håndterer gjennomføring, datainnsamling og grunnleggende analyse, slik at teamet ditt kan fokusere på strategisk tolkning og optimaliseringsbeslutninger.
Testing av promptbibliotek avdekker synlighetsgap og feiltolkninger som direkte påvirker innholdsprioriteringer. Når testing viser at merkevaren din mangler i relevante AI-svar, signaliserer det en innholdsmulighet. Når testing avdekker feiltolkninger, indikerer det et behov for korrigerende innhold.
Avkastningen viser seg gjennom forbedret merkevaresynlighet i AI-systemer, mer nøyaktig merkevarepresentasjon, raskere deteksjon av konkurransetrusler og datadrevet innholdsstrategi. Organisasjoner oppnår strategisk fordel ved å sikre korrekt merkevareposisjonering i AI-genererte svar, som i økende grad påvirker kunders oppdagelse og beslutningstaking.
Spor hvordan merkevaren din vises i ChatGPT, Claude, Gemini, Perplexity og Google AI Overviews med AmICiteds omfattende plattform for overvåking av merkevaresynlighet i AI.
Lær hvordan du bygger og bruker promptbiblioteker for manuell AI-synlighetstesting. DIY-guide til å teste hvordan AI-systemer refererer til merkevaren din på tv...

Lær hvordan du lager og organiserer et effektivt promptbibliotek for å spore merkevaren din på tvers av ChatGPT, Perplexity og Google AI. Trinnvis guide med bes...
Prompt engineering er kunsten å strukturere instruksjoner for å veilede generative KI-modeller. Lær teknikker, beste praksis og hvordan det påvirker KI-synlighe...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.