
Sonar-algoritmen i Perplexity: Sanntids søkemodell forklart
Lær hvordan Perplexitys Sonar-algoritme driver sanntids AI-søk med kostnadseffektive modeller. Utforsk Sonar, Sonar Pro og Sonar Reasoning-varianter.
8 min lesing
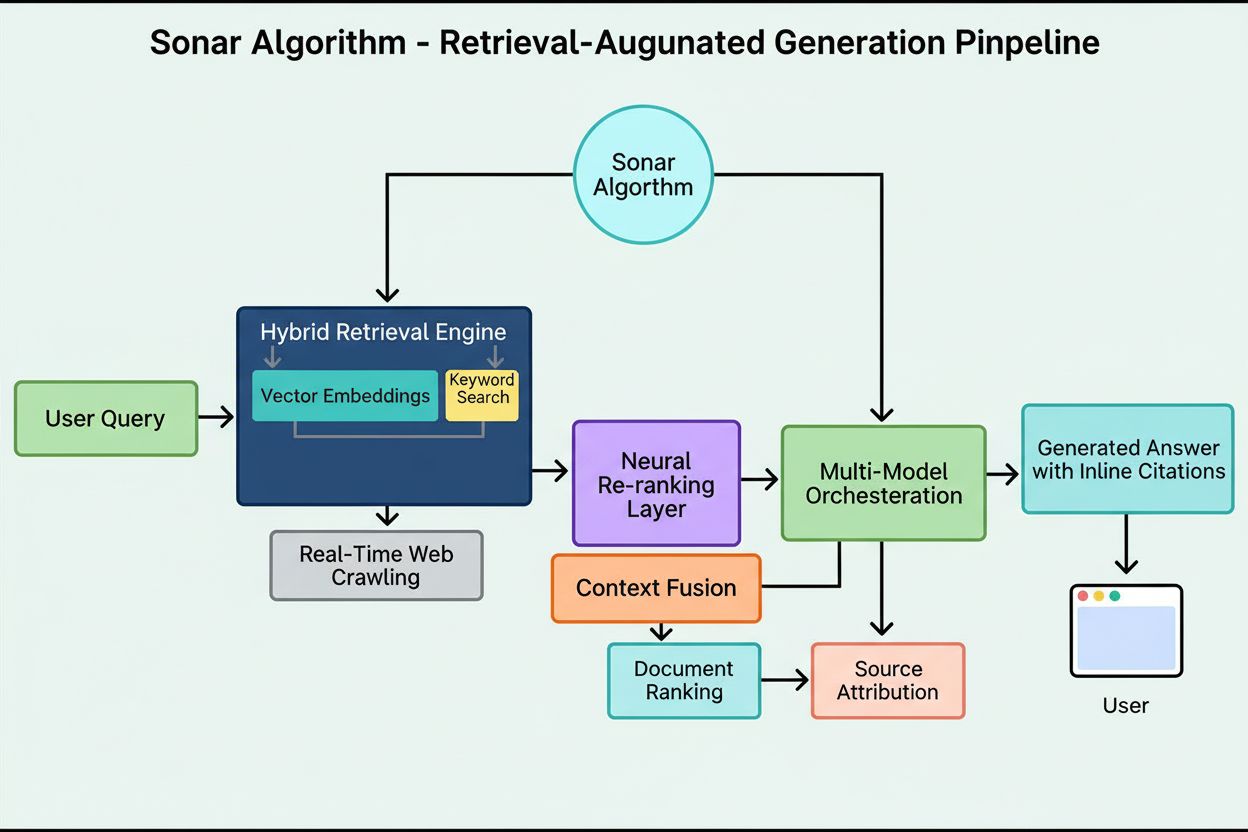
Sonar-algoritmen er Perplexitys proprietære retrieval-augmented generation (RAG) rangeringssystem som kombinerer hybrid semantisk og nøkkelordsøk med nevrale om-rangering for å hente, rangere og sitere nettbaserte kilder i sanntids AI-genererte svar. Den prioriterer innholdsaktualitet, semantisk relevans og siterbarhet for å levere begrunnede, kildebaserte svar samtidig som hallusinasjoner minimeres.
Sonar-algoritmen er Perplexitys proprietære retrieval-augmented generation (RAG) rangeringssystem som kombinerer hybrid semantisk og nøkkelordsøk med nevrale om-rangering for å hente, rangere og sitere nettbaserte kilder i sanntids AI-genererte svar. Den prioriterer innholdsaktualitet, semantisk relevans og siterbarhet for å levere begrunnede, kildebaserte svar samtidig som hallusinasjoner minimeres.
Sonar-algoritmen er Perplexitys proprietære retrieval-augmented generation (RAG) rangeringssystem som driver deres svarmotor ved å kombinere hybrid semantisk og nøkkelordsøk, nevrale om-rangeringer og sanntids siteringsgenerering. I motsetning til tradisjonelle søkemotorer som rangerer sider for visning i en resultatliste, rangerer Sonar innholdssnutter for syntese til ett samlet svar med innebygde kildehenvisninger til kildedokumentene. Algoritmen prioriterer innholdsaktualitet, semantisk relevans og siterbarhet for å levere begrunnede, kildebaserte svar og samtidig minimere hallusinasjoner. Sonar representerer et fundamentalt skifte i hvordan AI-systemer henter og rangerer informasjon—fra lenkebaserte autoritetssignaler til svarfokuserte nytteverdier som vektlegger om innholdet direkte tilfredsstiller brukerintensjon og kan siteres tydelig i syntetiserte svar. Dette skillet er avgjørende for å forstå hvordan synlighet i AI-svarmotorer skiller seg fra tradisjonell SEO, da Sonar vurderer innhold ikke for dets evne til å rangere i en liste, men for dets evne til å bli hentet ut, syntetisert og kreditert i et AI-generert svar.
Fremveksten av Sonar-algoritmen reflekterer et bredere bransjeskifte mot retrieval-augmented generation som dominerende arkitektur for AI-svarmotorer. Da Perplexity ble lansert sent i 2022, identifiserte selskapet et kritisk gap i AI-landskapet: Mens ChatGPT tilbød sterke samtaleegenskaper, manglet den tilgang til sanntidsinformasjon og kildehenvisning, noe som førte til hallusinasjoner og utdaterte svar. Perplexitys grunnleggerteam, som opprinnelig jobbet på et database-oversetterverktøy, dreide fullstendig om for å bygge en svarmotor som kunne kombinere live nettsøk med LLM-syntese. Dette strategiske valget preget Sonars arkitektur fra starten—algoritmen ble utviklet ikke for å rangere sider for menneskelig surfing, men for å hente ut og rangere innholdsfragmenter for maskinell syntese og sitering. De siste to årene har Sonar utviklet seg til et av de mest sofistikerte rangeringssystemene i AI-økosystemet, med Perplexitys Sonar-modeller som sikret plassene 1 til 4 i Search Arena Evaluation, og overgikk dermed modeller fra Google og OpenAI. Algoritmen behandler nå over 400 millioner søk hver måned, indekserer over 200 milliarder unike URL-er og opprettholder sanntidsaktualitet gjennom titusenvis av indeksoppdateringer per sekund. Denne skalaen og sofistikasjonen understreker Sonars betydning som et definerende rangeringsparadigme i AI-søkealderen.
Sonars rangeringssystem opererer gjennom en nøye orkestrert femtrinns retrieval-augmented generation-pipeline som forvandler brukerforespørsler til begrunnede, siterte svar. Første trinn, tolkning av forespørselsintensjon, bruker en LLM for å gå utover enkel nøkkelordmatching og oppnå semantisk forståelse av hva brukeren egentlig spør om, tolker kontekst, nyanser og underliggende intensjon. Andre trinn, live nettgjenfinning, sender den tolkede forespørselen til Perplexitys massive distribuerte indeks drevet av Vespa AI, som søker gjennom nettet etter relevante sider og dokumenter i sanntid. Dette gjenfinningssystemet kombinerer tett gjenfinning (vektorsøk med semantiske embeddinger) og spredt gjenfinning (leksikalsk/nøkkelordbasert søk), og slår sammen resultatene for å produsere cirka 50 ulike kandidatdokumenter. Tredje trinn, uttrekk og kontekstualisering av snutter, sender ikke hele sideteksten til genereringsmodellen; i stedet trekker algoritmer ut de mest relevante snuttene, avsnittene eller delene som direkte gjelder forespørselen og samler dem i et fokusert kontekstvindu. Fjerde trinn, syntetisert svargenerering med kildehenvisninger, sender denne kuraterte konteksten til en valgt LLM (enten fra Perplexitys proprietære Sonar-familie eller tredjepartsmodeller som GPT-4 eller Claude), som genererer et naturlig språk-svar basert utelukkende på hentet informasjon. Det viktigste er at innebygde kildehenvisninger knytter alle påstander tilbake til kildedokumentene, noe som gir transparens og muliggjør verifisering. Femte trinn, samtaleforfining, ivaretar samtalekonteksten over flere runder, slik at oppfølgingsspørsmål kan forbedre svar gjennom gjentatte nettsøk. Denne pipeline-ens grunnleggende prinsipp—“du skal ikke si noe du ikke har hentet”—sørger for at Sonar-drevne svar forankres i verifiserbare kilder og vesentlig reduserer hallusinasjoner sammenlignet med modeller som kun benytter treningsdata.
| Aspekt | Tradisjonelt søk (Google) | Sonar-algoritme (Perplexity) | ChatGPT-rangering | Gemini-rangering | Claude-rangering |
|---|---|---|---|---|---|
| Primærenhet | Rangert lenkeliste | Ett syntetisert svar med kildehenvisninger | Konsensusbaserte entitetsomtaler | E-E-A-T-tilpasset innhold | Nøytrale, faktabaserte kilder |
| Søksfokus | Nøkkelord, lenker, ML-signaler | Hybrid semantisk + nøkkelordsøk | Treningsdata + nettsurfing | Kunnskapsgrafintegrasjon | Konstitusjonelle sikkerhetsfiltre |
| Aktualitetsprioritet | Query-deserves-freshness (QDF) | Sanntidsnett, 37 % løft innen 48 t | Lavere prioritet, treningsdataavhengig | Moderat, integrert med Google-søk | Lav prioritet, vekt på stabilitet |
| Rangeringssignaler | Tilbakekoblinger, domeneautoritet, CTR | Innholdsaktualitet, semantisk relevans, siterbarhet, autoritetsløft | Entitetsgjenkjenning, konsensusomtaler | E-E-A-T, samtalejustering, strukturerte data | Transparens, verifiserbare kilder, nøytralitet |
| Siteringsmekanisme | URL-snutter i resultatene | Innebygde henvisninger med kildelenker | Implisitt, ofte uten sitat | AI-oversikt med kildeangivelse | Eksplisitt kildehenvisning |
| Innholdsmangfold | Flere resultater fra ulike nettsteder | Utvalgte kilder til syntese | Syntetisert fra flere kilder | Flere kilder i oversikt | Balanserte, nøytrale kilder |
| Personalisering | Subtil, mest implisitt | Eksplisitte fokusmoduser (Web, Akademisk, Finans, Skriving, Sosialt) | Implisitt basert på samtale | Implisitt etter forespørselstype | Minimal, vekt på konsistens |
| PDF-håndtering | Standard indeksering | 22 % siteringsfordel over HTML | Standard indeksering | Standard indeksering | Standard indeksering |
| Skjemaeffekt | FAQ-skjema i utvalgte utdrag | FAQ-skjema øker sitater med 41 %, reduserer tid til sitat med 6 timer | Minimal direkte effekt | Moderat effekt på kunnskapsgraf | Minimal direkte effekt |
| Latensoptimalisering | Millisekunder for rangering | Under ett sekund for henting + generering | Sekunder for syntese | Sekunder for syntese | Sekunder for syntese |
Det tekniske fundamentet for Sonar-algoritmen hviler på en hybrid gjenfinningsmotor som kombinerer flere søkestrategier for å maksimere både tilbakehenting og presisjon. Tett gjenfinning (vektorsøk) bruker semantiske embeddinger for å forstå den konseptuelle meningen bak forespørsler, og finner kontekstuelt lignende dokumenter selv uten eksakt nøkkelordmatch. Denne tilnærmingen bruker transformerbaserte embeddinger som plasserer forespørsler og dokumenter i høydimensjonale vektorrom hvor semantisk lignende innhold klustrer sammen. Spredt gjenfinning (leksikalsk søk) utfyller tett gjenfinning ved å gi presisjon for sjeldne termer, produktnavn, interne identifikatorer og spesifikke entiteter hvor semantisk tvetydighet er uønsket. Systemet bruker rangeringsfunksjoner som BM25 for nøyaktige treff på slike kritiske termer. Disse to metodene flettes sammen og dedupliseres for å gi omtrent 50 ulike kandidater, noe som hindrer domeneovertilpasning og gir bred dekning på tvers av autoritative kilder. Etter innledende gjenfinning bruker Sonars nevrale om-rangeringslag avanserte maskinlæringsmodeller (som DeBERTa-v3 cross-encodere) for å evaluere kandidater med et rikt sett av signaler, inkludert leksikalsk relevans, vektorsimilaritet, dokumentautoritet, aktualitet, brukerengasjement og metadata. Denne flerfase-rangeringsarkitekturen lar Sonar gradvis forbedre resultatene under stramme tidsfrister, slik at det endelige rangerte settet representerer de mest relevante og høyest rangerte kildene for syntese. Hele gjenfinningsinfrastrukturen er bygget på Vespa AI, en distribuert søkeplattform som håndterer web-skala indeksering (200+ milliarder URL-er), sanntidsoppdateringer (titusenvis per sekund) og avansert innholdsforståelse gjennom dokumentchunking. Dette arkitekturvalget gir Perplexitys relativt lille utviklerteam mulighet til å fokusere på differensierende komponenter—RAG-orchestrering, Sonar-modelljustering og inferensoptimalisering—i stedet for å bygge distribuert søk fra bunnen av.
Innholdsaktualitet er et av Sonars sterkeste rangeringssignaler, med empirisk forskning som viser at nylig oppdaterte sider får vesentlig høyere siteringsrater. I kontrollerte A/B-tester gjennomført over 24 uker på 120 URL-er, ble artikler oppdatert innenfor de siste 48 timene sitert 37 % oftere enn identisk innhold med eldre tidsstempel. Denne fordelen vedvarte på omtrent 14 % etter to uker, noe som viser at aktualitet gir en varig, men gradvis avtagende effekt. Mekanismen bak denne prioriteringen er forankret i Sonars designfilosofi: algoritmen anser utdatert innhold som høyere hallusinasjonsrisiko, og antar at foreldet informasjon kan være erstattet av nyere utvikling. Perplexitys infrastruktur håndterer titusenvis av indeksoppdateringsforespørsler per sekund, slik at sanntidsaktualitet sikres. En ML-modell forutsier om en URL må re-indekseres og planlegger oppdateringer basert på sidens viktighet og historiske oppdateringsfrekvens, slik at verdifullt innhold oppdateres mer aggressivt. Selv små kosmetiske endringer nullstiller aktualitetsklokken, forutsatt at CMS-et publiserer oppdatert tidsstempel. For utgivere betyr dette et strategisk imperativ: enten adoptere nyhetsrom-frekvens med ukentlige eller daglige oppdateringer, eller se eviggrønt innhold gradvis forsvinne fra søkeresultater. Konsekvensen er betydelig—i Sonar-æraen er innholdstempo ikke et forfengelighetsmål, men et overlevelseskrav. Merkevarer som automatiserer ukentlige mikrooppdateringer, legger til live endringslogger eller har kontinuerlig innholdsoptimalisering vil sikre seg en uforholdsmessig høy andel siteringer sammenlignet med konkurrenter som satser på statiske sider.
Sonar prioriterer semantisk relevans fremfor nøkkelordstetthet, og belønner innhold som direkte svarer på brukerens spørsmål i naturlig, samtalebasert språk. Algoritmens gjenfinningssystem bruker tette vektorembeddinger for å matche forespørsler til innhold på konseptnivå, slik at sider som bruker synonymer, relaterte begreper eller innholdsrikt språk kan rangere høyere enn nøkkelord-tunge sider uten semantisk dybde. Dette skiftet fra nøkkelord-sentrert til meningsbasert rangering har store konsekvenser for innholdsstrategi. Innhold som lykkes i Sonar har flere strukturelle kjennetegn: det starter med et kort, faktabasert sammendrag, bruker beskrivende H2/H3-overskrifter og korte avsnitt for enkel uttrekking, inkluderer tydelige kildehenvisninger og lenker til primærkilder, og har synlige tidsstempel og versjonsnotater for å signalisere aktualitet. Hvert avsnitt fungerer som en atomisk semantisk enhet, optimalisert for kopiering og LLM-forståelse. Tabeller, punktlister og merkede diagrammer er spesielt verdifulle fordi de gir informasjon i strukturerte, lett siterbare former. Algoritmen belønner også original analyse og unike data fremfor ren aggregering, ettersom Sonars syntesemotor ønsker kilder som gir nye vinklinger, primærdokumenter eller proprietær innsikt som skiller seg fra generiske oversikter. Denne vektleggingen av semantisk rikdom og svar-først-struktur er et fundamentalt brudd med tradisjonell SEO, hvor nøkkelordplassering og lenkeautoritet dominerte. I Sonar-æraen må innhold konstrueres for maskinell gjenfinning og syntese, ikke bare menneskelig lesing.
Offentlig tilgjengelige PDF-er utgjør en betydelig, ofte oversett fordel i Sonars rangeringssystem, med empiriske tester som viser at PDF-versjoner av innhold overgår HTML-ekvivalenter med omtrent 22 % i siteringsfrekvens. Denne fordelen skyldes at Sonars crawler behandler PDF-er gunstig sammenlignet med HTML-sider. PDF-er mangler cookie-bannere, krav til JavaScript-rendering, betalingsmurer og andre HTML-komplikasjoner som kan skjule eller forsinke innholdstilgang. Sonars crawler kan lese PDF-er rent og forutsigbart, og trekker ut tekst uten tolkningstvil som ofte oppstår med kompleks HTML. Utgivere kan utnytte denne fordelen strategisk ved å lagre PDF-er i offentlig tilgjengelige kataloger, bruke semantiske filnavn som reflekterer innholdet, og signalisere PDF-en som kanonisk med <link rel="alternate" type="application/pdf">-tagger i HTML-headen. Dette skaper det forskere kaller en “LLM-honningfelle”—et høysynlig aktivum som konkurrenters sporingsskript ikke lett kan oppdage eller overvåke. For B2B-selskaper, SaaS-leverandører og forskningsdrevne organisasjoner er denne strategien spesielt kraftig: publisering av whitepapers, forskningsrapporter, casestudier og teknisk dokumentasjon som PDF-er kan dramatisk øke Sonar-siteringsraten. Nøkkelen er å behandle PDF-en ikke som en nedlastbar ettertanke, men som en kanonisk kopi verdt like mye, eller mer, optimaliseringsinnsats enn HTML-versjonen. Dette har vist seg spesielt effektivt for bedriftsinnhold, hvor PDF-er ofte inneholder mer strukturert og autoritativ informasjon enn nettsider.
JSON-LD FAQ-skjema gir betydelig økt Sonar-siteringsrate, og sider med tre eller flere FAQ-blokker får 41 % flere siteringer enn kontrollsider uten skjema. Denne dramatiske økningen reflekterer Sonars preferanse for strukturert, chunk-basert innhold som passer med gjenfinnings- og synteselogikken. FAQ-skjema gir diskrete, selvstendige spørsmål-og-svar-enheter som algoritmen lett kan trekke ut, rangere og sitere som atomiske semantiske blokker. I motsetning til tradisjonell SEO, hvor FAQ-skjema var en “nice-to-have”-funksjon, ser Sonar på strukturert Q&A-oppsett som en sentral rangeringsdriver. I tillegg siterer Sonar ofte FAQ-spørsmål som ankertekst, og reduserer risikoen for kontekstdrift som kan oppstå når LLM-en summerer tilfeldige setninger midt i teksten. Skjemaet fremskynder også tid til første sitering med omtrent seks timer, noe som tyder på at Sonars parser prioriterer strukturerte Q&A-blokker tidlig i rangeringsprosessen. For utgivere er optimaliseringsstrategien enkel: legg inn tre til fem målrettede FAQ-blokker nederst på siden, med samtalebaserte spørsmål som speiler faktiske brukerforespørsler. Spørsmålene bør bruke long-tail søkeuttrykk og ha semantisk likhet med sannsynlige Sonar-spørsmål. Hvert svar bør være kort, faktabasert og direkte, uten fyllstoff eller markedsføringsspråk. Tilnærmingen har vist seg spesielt effektiv for SaaS-selskaper, klinikker og rådgivningstjenester, hvor FAQ-innhold naturlig samsvarer med brukerintensjon og Sonars syntesebehov.
Sonars rangeringssystem integrerer flere signaler i en samlet siteringsramme, og forskning identifiserer åtte primære faktorer som påvirker kildevalg og siteringshyppighet. Først, semantisk relevans til spørsmålet dominerer gjenfinningen, og algoritmen prioriterer innhold som tydelig svarer på spørsmålet i naturlig språk. For det andre, autoritet og troverdighet har stor betydning, med Perplexitys utgiverpartnerskap og algoritmiske løft til etablerte nyhetsorganisasjoner, akademiske institusjoner og anerkjente eksperter. For det tredje, aktualitet vektlegges sterkt, med nylige oppdateringer som gir 37 % økning i sitering. For det fjerde, mangfold og dekning verdsettes, da Sonar foretrekker flere høykvalitetskilder fremfor enslige svar, og reduserer hallusinasjonsrisiko gjennom kryssvalidering. For det femte, modus og omfang bestemmer hvilke indekser Sonar søker i—fokusmoduser som Akademisk, Finans, Skriving og Sosialt snevrer inn kildetyper, mens kildevelgeren (Web, Org Files, Web + Org Files, Ingen) avgjør om søket hentes fra åpent nett, interne dokumenter eller begge deler. For det sjette, siterbarhet og tilgjengelighet er avgjørende; dersom PerplexityBot kan krype og indeksere innholdet, er det lettere å sitere, noe som gjør robots.txt og sidehastighet essensielt. For det sjuende, tilpassede kildefiltre via API lar bedriftsimplementeringer begrense eller foretrekke visse domener, og endrer rangering innenfor hvitlistede samlinger. For det åttende, samtalekontekst påvirker oppfølgingsspørsmål, der sider som matcher endret intensjon rangerer høyere enn mer generiske referanser. Samlet skaper disse faktorene et flerdimensjonalt rangeringsrom hvor suksess krever optimalisering på flere områder samtidig, ikke bare ett grep som tilbakekoblinger eller nøkkelord.
Sonar-algoritmen utvikler seg raskt i takt med fremskritt innen LLM-inferens og gjenfinningsteknologi. Perplexitys utviklerblogg fremhevet nylig spekulativ dekoding, en teknikk som halverer token-latens ved å forutsi flere framtidige token samtidig. Raskere genereringsløkker gjør det mulig å bruke ferskere gjenfinningssett for hver forespørsel, noe som reduserer vinduet der utdaterte sider kan konkurrere. En rykteomspunnet Sonar-Reasoning-Pro-modell overgår allerede Gemini 2.0 Flash og GPT-4o Search i arenaevalueringer, noe som tyder på at Sonars rangeringssofistikasjon vil fortsette å øke. Når latens nærmer seg menneskelig tankehastighet, blir siteringskampen et høyfrekvent spill der innholdstempo er den avgjørende faktoren. Forvent infrastrukturinnovasjoner som “LLM aktualitets-API-er” som automatisk øker tids
**Sonar-algoritmen** er Perplexitys proprietære rangeringssystem som driver svarmotoren deres, fundamentalt forskjellig fra tradisjonelle søkemotorer som Google. Mens Google rangerer sider for visning i en liste med blå lenker, rangerer Sonar innholdssnutter for syntese til ett samlet svar med innebygde kildehenvisninger. Sonar bruker retrieval-augmented generation (RAG), som kombinerer hybrid søk (vektorembeddinger pluss nøkkelordmatching), nevrale om-rangeringer og sanntids nettgjenfinning for å forankre svar i verifiserbare kilder. Denne tilnærmingen prioriterer semantisk relevans og innholdsaktualitet fremfor eldre SEO-signaler som tilbakekoblinger, og utgjør et distinkt rangeringsparadigme optimalisert for AI-generert syntese fremfor lenkebasert autoritet.
Sonar implementerer en **hybrid gjenfinningsmotor** som kombinerer to komplementære søkestrategier: tett gjenfinning (vekorsøk med semantiske embeddinger) og spredt gjenfinning (leksikalsk/nøkkelordbasert søk med BM25). Tett gjenfinning fanger opp konseptuell mening og kontekst, slik at systemet kan finne semantisk lignende innhold selv uten eksakte nøkkelord. Spredt gjenfinning gir presisjon for sjeldne termer, produktnavn og spesifikke identifikatorer der semantisk tvetydighet er uønsket. Disse to gjenfinningsmetodene flettes sammen og dedupliseres for å produsere omtrent 50 ulike kandidater, noe som forhindrer domeneovertilpasning og sikrer bred dekning. Denne hybride tilnærmingen overgår enkeltmetodesystemer både i tilbakehenting og relevansnøyaktighet.
De primære rangeringsfaktorene for Sonar inkluderer: (1) **Innholdsaktualitet** – nylig oppdaterte eller publiserte sider får 37 % flere siteringer innen 48 timer etter oppdatering; (2) **Semantisk relevans** – innholdet må svare direkte på forespørselen i naturlig språk, med prioritet på klarhet fremfor nøkkelordstetthet; (3) **Autoritet og troverdighet** – kilder fra etablerte utgivere, akademiske institusjoner og nyhetsorganisasjoner får algoritmiske løft; (4) **Siterbarhet** – innholdet må være lett å sitere og strukturert med klare overskrifter, tabeller og avsnitt; (5) **Mangfold** – Sonar foretrekker flere høykvalitetskilder fremfor enslige svar; og (6) **Teknisk tilgjengelighet** – sider må kunne gjennomsøkes av PerplexityBot og lastes raskt for umiddelbar surfing.
**Aktualitet er et av Sonars viktigste rangeringssignaler**, spesielt for tidskritiske emner. Perplexitys infrastruktur behandler titusenvis av indeksoppdateringsforespørsler per sekund, slik at indeksen reflekterer den mest oppdaterte informasjonen som finnes. En ML-modell forutsier om en URL trenger re-indeksering og planlegger oppdateringer basert på sidens betydning og oppdateringsfrekvens. I empiriske tester fikk innhold oppdatert de siste 48 timene 37 % flere siteringer enn identisk innhold med eldre tidsstempel, og denne fordelen vedvarte på 14 % etter to uker. Selv mindre redigeringer nullstiller aktualitetsklokken, noe som gjør kontinuerlig innholdsoptimalisering avgjørende for å opprettholde synlighet i Sonar-drevne svar.
**PDF-er er en betydelig fordel i Sonars rangeringssystem**, og overgår ofte HTML-versjoner av samme innhold med 22 % i siteringsfrekvens. Sonars crawler favoriserer PDF-er fordi de mangler cookie-bannere, betalingsmurer, problemer med JavaScript-rendering og andre HTML-komplikasjoner som kan skjule innhold. Utgivere kan optimalisere PDF-synlighet ved å gjøre dem tilgjengelige i offentlige kataloger, bruke semantiske filnavn og signalisere PDF-en som kanonisk med ``-tagger i HTML-headen. Dette skaper det forskere kaller en "LLM-honningfelle" som konkurrenters sporingsskript ikke enkelt kan oppdage, og gjør PDF-er til en strategisk ressurs for å sikre Sonar-siteringer.
**JSON-LD FAQ-skjema gir en vesentlig økning i Sonar-siteringsfrekvens**, og sider med tre eller flere FAQ-blokker får 41 % flere siteringer enn kontrollsider uten skjema. FAQ-oppsett passer perfekt med Sonars chunk-baserte gjenfinningslogikk fordi det presenterer diskrete, selvstendige spørsmål-og-svar-enheter som algoritmen lett kan trekke ut og sitere. I tillegg siterer Sonar ofte FAQ-spørsmål som ankertekst, noe som reduserer risikoen for kontekstdrift når LLM-en summerer tilfeldige midt-avsnitt-setninger. Skjemaet fremskynder også tiden til første sitering med omtrent seks timer, noe som tyder på at Sonars parser prioriterer strukturerte Q&A-blokker tidlig i rangeringsprosessen.
Sonar implementerer en **tretrinns retrieval-augmented generation (RAG) pipeline** designet for å forankre svar i verifisert ekstern kunnskap. Første trinn henter relevante dokumenter med hybrid søk; andre trinn trekker ut og kontekstualiserer de mest relevante snuttene; tredje trinn syntetiserer et svar kun ved bruk av den gitte konteksten, med en streng regel: "du skal ikke si noe du ikke har hentet." Denne arkitekturen knytter gjenfinning og generering tett sammen, slik at alle påstander kan spores til en kilde. Innebygde kildehenvisninger lenker generert tekst tilbake til kildedokumenter, slik at brukere kan verifisere svaret. Denne forankrede tilnærmingen reduserer hallusinasjoner betydelig sammenlignet med modeller som kun baserer seg på treningsdata, og gjør Sonars svar mer faktabasert og pålitelig.
Mens **ChatGPT prioriterer entitetsgjenkjenning og konsensus** fra treningsdata, **fremhever Gemini E-E-A-T-signaler og samtalejustering**, og **Claude fokuserer på konstitusjonell sikkerhet og nøytralitet**, **prioriterer Sonar unikt sanntidsaktualitet og semantisk dybde**. Sonars trelags maskinlærings-omrangerer bruker strengere kvalitetsfiltre enn tradisjonelt søk og forkaster hele resultatsett dersom innholdet ikke møter kvalitetskrav. I motsetning til ChatGPTs avhengighet av historiske treningsdata, utfører Sonar live nettgjenfinning for hver forespørsel, slik at svarene alltid er oppdaterte. Sonar skiller seg også fra Geminis kunnskapsgrafintegrasjon ved å vektlegge semantisk relevans på avsnittsnivå, og fra Claudes nøytralitetsfokus ved å tillate autoritetsløft fra etablerte utgivere.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Lær hvordan Perplexitys Sonar-algoritme driver sanntids AI-søk med kostnadseffektive modeller. Utforsk Sonar, Sonar Pro og Sonar Reasoning-varianter.
Lær hva RAG (Retrieval-Augmented Generation) er i AI-søk. Oppdag hvordan RAG forbedrer nøyaktighet, reduserer hallusinasjoner og driver ChatGPT, Perplexity og G...

Lær hvordan du formaterer innhold for maksimal synlighet i Perplexity-siteringer. Bli ekspert på sitérbart innhold, schema markup og siteringsstrategier for å d...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.