Strukturerte data
Strukturerte data er standardisert oppmerking som hjelper søkemotorer å forstå innholdet på nettsider. Lær hvordan JSON-LD, schema.org og microdata forbedrer SE...
9 min lesing

Schema-markup spesielt utformet for å hjelpe AI-systemer med å forstå og sitere innhold nøyaktig. Strukturert data bruker standardiserte formater som JSON-LD for å gi eksplisitt kontekst om sideinnhold, slik at store språkmodeller kan tolke informasjon mer pålitelig og sitere kilder med større trygghet.
Schema-markup spesielt utformet for å hjelpe AI-systemer med å forstå og sitere innhold nøyaktig. Strukturert data bruker standardiserte formater som JSON-LD for å gi eksplisitt kontekst om sideinnhold, slik at store språkmodeller kan tolke informasjon mer pålitelig og sitere kilder med større trygghet.
Strukturert data for AI refererer til organisert, maskinlesbar informasjon formatert etter standardiserte skjemaer som gjør det mulig for kunstig intelligens å forstå, tolke og bruke innhold med presisjon. I motsetning til ustrukturert tekst, som krever kompleks naturlig språkprosessering for å tolke mening, gir strukturert data eksplisitt kontekst om hva informasjonen representerer. Denne klarheten er avgjørende fordi AI-systemer—spesielt store språkmodeller og søkemotorer—behandler milliarder av datapunkter daglig. Når innhold struktureres med standarder som schema.org, JSON-LD eller microdata, kan AI umiddelbart gjenkjenne enheter, relasjoner og attributter uten tvetydighet. Denne strukturerte tilnærmingen gir 300 % høyere nøyaktighet i AI-forståelse sammenlignet med ustrukturerte alternativer. For organisasjoner som ønsker synlighet i AI Overviews og andre AI-genererte resultater, har strukturert data blitt ikke-forhandlingsbar infrastruktur. Det forvandler rått innhold til intelligens som AI-systemer trygt kan sitere, referere og inkorporere i sine svar, og endrer fundamentalt hvordan digitalt innhold oppnår synlighet i en AI-drevet verden.

AI-systemer prosesserer strukturert data gjennom en sofistikert pipeline som gjør markert innhold om til handlingsrettet intelligens. Når et AI-system møter riktig formatert strukturert data, kan det umiddelbart hente ut nøkkelinformasjon uten den beregningsmessige belastningen naturlig språkforståelse krever. Den tekniske mekanismen følger disse viktige trinnene:
Denne prosessen gjør at AI gir 30 %+ høyere synlighet i AI Overviews for riktig strukturert innhold. Den strukturerte tilnærmingen reduserer risiko for hallusinasjoner ved å forankre AI-svar til eksplisitt, verifiserbar data i stedet for sannsynlighetsbasert tekstgenerering. Organisasjoner som implementerer omfattende strategier for strukturert data, opplever målbare forbedringer i hvordan AI-systemer oppdager, forstår og promoterer innholdet deres på tvers av flere plattformer og applikasjoner.
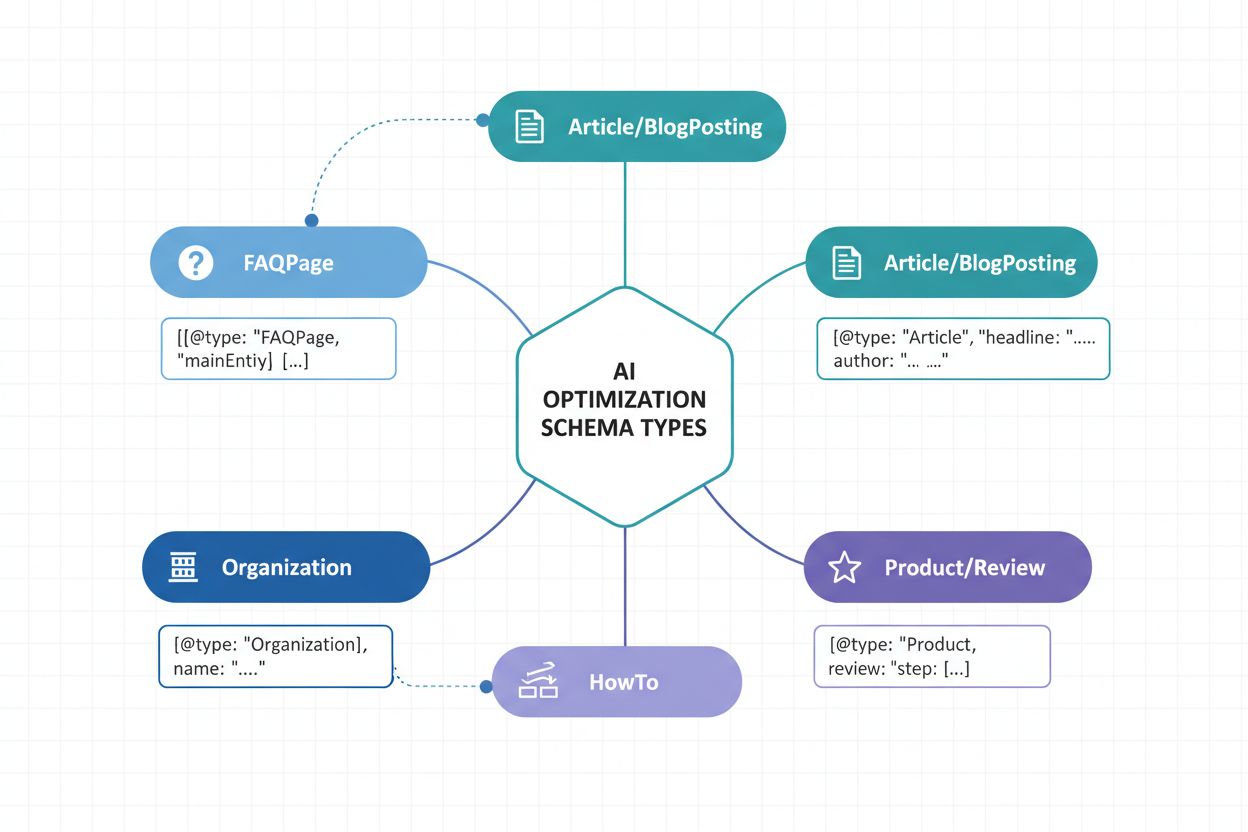
Implementering av riktige schema-typer er grunnleggende i en strategi for AI-synlighet. Ulike innholdstyper krever spesifikk strukturert data-markup for å kommunisere sin natur og verdi til AI-systemer. Her er de essensielle schema-typene for å maksimere AI-gjenkjenning:
Article schema – Markerer nyhetsartikler, blogginnlegg og langt innhold med overskrift, forfatter, publiseringsdato og brødtekst. Kritisk for AI-systemer som identifiserer autoritative innholdskilder og etablerer publiseringskredibilitet.
Organization schema – Definerer selskapsidentitet, inkludert navn, logo, kontaktinfo og sosiale profiler. Gjør at AI kan gjenkjenne og korrekt tilskrive organisasjonsinnhold i ulike sammenhenger.
Product schema – Strukturerer produktinformasjon inkludert navn, beskrivelse, pris, tilgjengelighet og omtaler. Essensielt for e-handelssynlighet i AI-shoppingassistenter og produktsystemer.
LocalBusiness schema – Marker opp bedriftslokasjon, åpningstider, kontaktinfo og tjenester. Viktig for lokale AI-spørringer og stedbaserte AI Overviews som dominerer søkeresultatene.
BreadcrumbList schema – Definerer nettstedets navigasjonshierarki, og hjelper AI å forstå innholdsstrukturen og relasjoner mellom sider i informasjonsarkitekturen din.
FAQPage schema – Strukturerer ofte stilte spørsmål med svar, slik at AI-systemer direkte kan hente ut og sitere spesifikke spørsmål og svar i sine svar.
NewsArticle og BlogPosting schema – Spesialiserte artikkeltyper som signaliserer innholdskategori til AI-systemer, og forbedrer kategorisering og relevansmatching.
Event schema – Markerer hendelsesdetaljer som dato, sted, beskrivelse og registreringsinformasjon, essensielt for AI-hendelsesoppdagelse og kalenderintegrasjon.
I dag bruker 45 millioner domener schema.org-markup, som utgjør 12,4 % av alle domener globalt. Organisasjoner som implementerer flere schema-typer samtidig ser sammensatte fordeler, siden AI-systemer får rikere kontekstuell forståelse av innholdsøkosystemet deres.
Vellykket implementering av strukturert data krever strategisk planlegging og teknisk presisjon. Organisasjoner bør følge disse etablerte beste praksisene for å maksimere AI-synlighet og sikre datanøyaktighet:
Her er et praktisk JSON-LD-eksempel for en artikkel:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Strukturert data for AI: Strategisk implementeringsguide",
"author": {
"@type": "Person",
"name": "Innholdsforfatter"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Full artikkeltekst her...",
"publisher": {
"@type": "Organization",
"name": "Din organisasjon",
"logo": "https://example.com/logo.png"
}
}
Riktig implementering gir 35 % forbedring i CTR fra rike resultater i tradisjonelt søk, med ytterligere fordeler etter hvert som AI Overviews blir primære kanaler for oppdagelse. Organisasjoner som overvåker strukturert data-ytelse gjennom løsninger som AmICited.com får konkurransefortrinn ved å identifisere hvilke innholdstyper og schema-implementeringer som gir høyest AI-synlighet.
Både strukturert data og llms.txt tjener AI-oppdagbarhet, men fungerer gjennom fundamentalt forskjellige mekanismer. Strukturert data bruker standardiserte schema (schema.org, JSON-LD) innebygd i HTML for å markere spesifikke innholdselementer med eksplisitt semantisk mening. Denne tilnærmingen integreres direkte på nettsider, slik at informasjon umiddelbart er tilgjengelig for både søkemotorer og AI-systemer under crawling. Strukturert data muliggjør detaljert markup av individuelle artikler, produkter, hendelser og organisasjoner, slik at AI kan forstå presise relasjoner og attributter.
llms.txt, på den andre siden, er en tekstfil plassert i nettstedets rotmappe med instruksjoner og retningslinjer for store språkmodeller. Den fungerer som en manifestfil som kommuniserer preferanser om hvordan AI-systemer skal samhandle med og sitere innholdet ditt. Mens llms.txt gir overordnet veiledning om bruk av innhold og siteringspreferanser, mangler den den semantiske presisjonen strukturert data gir. Strukturert data svarer på “hva er dette innholdet?” med eksplisitte maskinlesbare svar, mens llms.txt svarer på “hvordan skal du bruke dette innholdet?” som veiledning.
Den mest effektive strategien kombinerer begge tilnærminger: strukturert data sørger for at AI-systemer nøyaktig forstår og kan sitere innholdet ditt, mens llms.txt etablerer klare retningslinjer for bruk og attribusjon. Organisasjoner som implementerer begge har 36 % større sannsynlighet for å dukke opp i AI-genererte sammendrag sammenlignet med de som ikke bruker noen av delene. Strukturert data gir grunnlaget for AI-forståelse, mens llms.txt gir rammeverket for riktig bruk og attribusjon.
Måling av effektivitet for strukturert data krever sporingsspesifikke metrikker som viser hvordan AI-systemer oppdager, forstår og siterer innholdet ditt. Organisasjoner bør følge med på disse nøkkelindikatorene:
AmICited.com tilbyr spesialisert overvåkning av AI-siteringsytelse, slik at organisasjoner kan følge med på hvordan investeringene i strukturert data gir faktisk AI-synlighet og attribusjon. Plattformen viser hvilket innhold som får AI-siteringer, hvilke spørringer som utløser innholdet ditt, og hvordan siteringsfrekvensen din sammenlignes med konkurrenter. Denne datadrevne tilnærmingen gjør implementering av strukturert data til en målbar forretningsfordel.
Organisasjoner som implementerer omfattende strategier for strukturert data rapporterer at 93 % av spørringene besvares av AI uten klikk, noe som gjør siteringssynlighet stadig viktigere for å drive trafikk. Måling av siteringsytelse sikrer at investeringene i strukturert data gir målbare gevinster gjennom forbedret AI-oppdagbarhet og merkevareattribusjon.
Vellykket implementering av strukturert data følger en fasebasert tilnærming som bygger kapasitet gradvis og gir målbar verdi i hver fase. Organisasjoner bør strukturere implementeringstidslinjen slik:
Fase 1: Grunnlag (Måned 1–2)
Fase 2: Utvidelse (Måned 3–4)
Fase 3: Optimalisering (Måned 5–6)
Fase 4: Strategisk integrasjon (Måned 7+)
Denne tidslinjen gjør at organisasjoner kan oppnå betydelige forbedringer i AI-synlighet innen 2–3 måneder, samtidig som de bygger mot omfattende, virksomhetsomspennende strukturert data-infrastruktur. Tidlige brukere som følger denne planen får konkurransefortrinn etter hvert som AI Overviews blir primære kanaler for oppdagelse.
Strukturert data har utviklet seg fra å være et valgfritt SEO-tillegg til å bli kritisk strategisk infrastruktur i et AI-drevet digitalt landskap. Etter hvert som AI-systemer i økende grad bestemmer hvordan brukere oppdager informasjon, får organisasjoner uten omfattende strukturert data systematiske synlighetsulemper. Dette gjenspeiler grunnleggende endringer i informasjonsflyten: tradisjonelt søk krevde at brukere klikket seg inn på nettsteder, men AI Overviews gir svar direkte, slik at siteringssynlighet blir den nye konkurransearenaen.
Organisasjoner som implementerer strukturert data strategisk posisjonerer seg for langsiktig suksess på tvers av flere AI-plattformer og nye kanaler for oppdagelse. Infrastrukturinvesteringen gir gevinster utover umiddelbar AI-synlighet—strukturert data forbedrer intern innholdsstyring, muliggjør bedre personalisering, støtter optimalisering for talesøk og skaper dataressurser verdifulle for fremtidige AI-applikasjoner. Tidlige brukere som etablerer omfattende strukturert data får sammensatte fordeler etter hvert som AI-systemer i økende grad prioriterer godt markert innhold.
Konkurransefordelen ved tidlig implementering kan ikke overvurderes. Etter hvert som flere ser viktigheten av strukturert data, blir implementering en forutsetning for synlighet. Organisasjoner som etablerer robust strukturert data nå, vil dominere AI-genererte resultater når disse kanalene modnes. Omvendt vil organisasjoner som utsetter implementering møte økende vansker med å oppnå synlighet, ettersom AI-systemene lærer å foretrekke grundig markert innhold. Strukturert data er ikke bare en teknisk løsning, men en grunnleggende strategisk forpliktelse til å forbli synlig og sitérbar i et AI-formidlet informasjonssamfunn.
Strukturert data påvirker ikke Google-rangeringer direkte, men forbedrer utseendet i søkeresultater betydelig gjennom rike utdrag, noe som øker klikkfrekvensen med opptil 35 %. For AI-systemer har strukturert data en mer direkte innvirkning på om innholdet ditt blir sitert i AI-genererte svar.
Ja, AI-systemer prosesserer strukturert data både under opplæring og i sanntidsspørringer. Selv om OpenAI ikke har gitt offentlige uttalelser, tyder bevis på at GPTBot og andre AI-crawlere tolker JSON-LD-markup. Microsoft har offisielt bekreftet at Bings AI-systemer bruker schema markup for bedre å forstå innhold.
JSON-LD er det anbefalte formatet fordi det skiller schema fra HTML-innholdet, noe som gjør det enklere å implementere og vedlikeholde i stor skala. Google anbefaler eksplisitt JSON-LD, og det er mindre utsatt for implementeringsfeil enn Microdata eller RDFa.
Rike utdrag kan dukke opp innen 1–4 uker etter implementering. Forbedringer i CTR er ofte målbare innen 2 uker. Når det gjelder AI-siteringsforbedringer, bør du forvente at grunnarbeidet gir effekt etter 4–8 uker, med autoritetsbyggende fordeler som øker over 3–6 måneder.
Prioriter schema markup først—det er velprøvd og bredt støttet. llms.txt er fortsatt en fremvoksende standard med begrenset adopsjon blant AI-crawlere. Hvis du er et utviklerfokusert selskap med omfattende dokumentasjon, kan det være verdt det lille arbeidet å opprette llms.txt for fremtidssikring.
Start med Organization schema på forsiden din (med sameAs-egenskaper), deretter Article schema på viktige innholdssider. FAQPage schema bør komme neste—det er mest nyttig for AI-ekstraksjon. Deretter kan du legge til HowTo schema til guider og SoftwareApplication schema til produktsider.
Bare feil implementert markup skader ytelsen. Googles retningslinjer er klare: bruk relevante schema-typer som samsvarer med synlig innhold, hold priser og datoer nøyaktige, og ikke marker opp innhold brukerne ikke kan se. Valider alltid med Googles Rich Results Test før publisering.
Strukturert data gir eksplisitt kontekst som hjelper AI-systemer å forstå hva informasjon representerer—enheter, relasjoner, attributter. Denne klarheten gjør at AI trygt kan trekke ut og sitere innholdet ditt. LLM-er forankret i kunnskapsgrafer oppnår 300 % høyere nøyaktighet sammenlignet med de som kun bruker ustrukturert data.
Følg med på hvordan AI-systemer siterer innholdet ditt på ChatGPT, Perplexity, Google AI Overviews og andre plattformer. Få sanntidsinnsyn i din AI-tilstedeværelse.
Strukturerte data er standardisert oppmerking som hjelper søkemotorer å forstå innholdet på nettsider. Lær hvordan JSON-LD, schema.org og microdata forbedrer SE...
Lær hvordan AI-crawlere prosesserer strukturert data. Oppdag hvorfor JSON-LD-implementeringsmetoden er viktig for synlighet i ChatGPT, Perplexity, Claude og Goo...
Diskusjon i fellesskapet om hvorvidt tabeller og strukturert formatering forbedrer AI-sitatsrater. Virkelige testresultater fra markedsførere som eksperimentere...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.