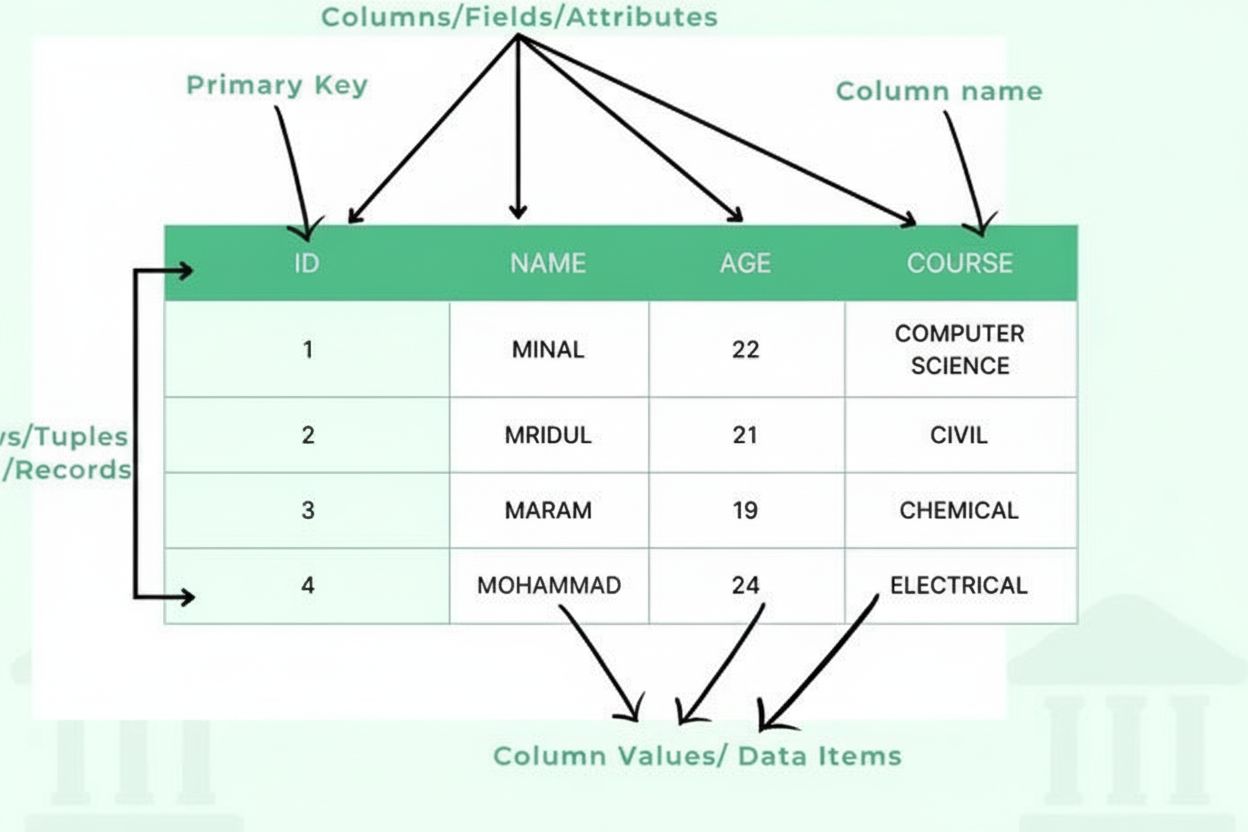
Definisjon av tabell: Organisert data i rader og kolonner
En tabell er en grunnleggende datastruktur som organiserer informasjon i et todimensjonalt rutenett bestående av horisontale rader og vertikale kolonner. I sin mest grunnleggende form representerer en tabell en samling av relaterte data ordnet på en strukturert måte der hvert krysningspunkt mellom rad og kolonne inneholder ett enkelt dataelement eller celle. Tabeller fungerer som hjørnesteinen i relasjonsdatabaser, regneark, datavarehus og praktisk talt alle systemer som krever organisert lagring og gjenfinning av informasjon. Styrken til tabeller ligger i deres evne til å muliggjøre rask visuell skanning, logisk sammenligning av data på tvers av flere dimensjoner, og programmessig tilgang til spesifikk informasjon gjennom standardiserte spørrespråk. Enten de brukes i forretningsanalyse, vitenskapelig forskning eller AI-overvåkingsplattformer, gir tabeller et universelt forstått format for presentasjon av strukturert data som enkelt kan tolkes av både mennesker og maskiner.
Historisk kontekst og utvikling av tabulær dataorganisering
Konseptet med å organisere informasjon i rader og kolonner går flere århundrer tilbake, lenge før moderne databehandling. Antikke sivilisasjoner brukte tabulære formater for å registrere lager, finansielle transaksjoner og astronomiske observasjoner. Den formelle utformingen av tabellstrukturer innen databehandling oppstod imidlertid med utviklingen av relasjonsdatabaseteorien av Edgar F. Codd i 1970, som revolusjonerte hvordan data kunne lagres og forespørres. Den relasjonelle modellen fastslo at data burde organiseres i tabeller med tydelig definerte relasjoner, noe som grunnleggende endret prinsippene for databasedesign. Gjennom 1980- og 1990-tallet demokratiserte regneark som Lotus 1-2-3 og Microsoft Excel bruken av tabeller, og gjorde tabulær dataorganisering tilgjengelig for ikke-tekniske brukere. I dag bruker omtrent 97 % av organisasjoner regneark for datahåndtering og analyse, noe som viser den varige betydningen av tabellbasert dataorganisering. Utviklingen fortsetter med moderne løsninger som kolonnedatabaser, NoSQL-systemer og datalakes, som utfordrer tradisjonelle rad-orienterte tilnærminger, men likevel opprettholder grunnleggende tabellignende strukturer for å organisere informasjon.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Kjernekomponenter og struktur i tabeller
En tabell består av flere vesentlige strukturelle komponenter som sammen skaper et organisert rammeverk for data. Kolonner (også kalt felter eller attributter) går vertikalt og representerer kategorier av informasjon, som “Kundenavn”, “E-postadresse” eller “Kjøpsdato”. Hver kolonne har en definert datatype som spesifiserer hvilken type informasjon den kan inneholde—heltall, tekststrenger, datoer, desimaler eller mer komplekse strukturer. Rader (også kalt poster eller tupler) går horisontalt og representerer individuelle dataoppføringer eller enheter, der hver rad inneholder én komplett post. Krysningen mellom en rad og en kolonne utgjør en celle eller et dataelement, som inneholder ett enkelt informasjonsstykke. Kolonneoverskrifter identifiserer hver kolonne og vises øverst i tabellen, og gir kontekst til dataene under. Primærnøkler er spesielle kolonner som entydig identifiserer hver rad, og sikrer at ingen duplikatposter eksisterer. Fremmednøkler etablerer relasjoner mellom tabeller ved å referere til primærnøkler i andre tabeller. Denne hierarkiske organiseringen gjør det mulig for databaser å opprettholde dataintegritet, hindre redundans og støtte komplekse spørringer som henter informasjon basert på flere kriterier.
Sammenligning av metoder for tabellorganisering
| Aspekt | Rad-orienterte tabeller | Kolonne-orienterte tabeller | Hybridtilnærminger |
|---|
| Lagringsmetode | Data lagres og aksesseres etter komplette poster | Data lagres og aksesseres etter individuelle kolonner | Kombinerer fordelene fra begge tilnærminger |
| Spørringsytelse | Optimalisert for transaksjonelle spørringer som henter hele poster | Optimalisert for analytiske spørringer på spesifikke kolonner | Balansert ytelse for blandede arbeidsbelastninger |
| Bruksområder | OLTP (Online Transaction Processing), forretningsdrift | OLAP (Online Analytical Processing), datavarehus | Sanntidsanalyse, operasjonell intelligens |
| Databaseeksempler | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Kompresjonseffektivitet | Lavere komprimeringsrate grunnet datamangfold | Høyere komprimeringsrate for like kolonneverdier | Optimalisert komprimering for spesifikke mønstre |
| Skriveytelse | Rask skriving av komplette poster | Tregere skriving som krever kolonneoppdateringer | Balansert skriveytelse |
| Skalerbarhet | Skalerer godt for transaksjonsvolum | Skalerer godt for datavolum og spørringskompleksitet | Skalerer for begge dimensjoner |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Teknisk implementering og databasestruktur
I relasjonsdatabasestyringssystemer (RDBMS) implementeres tabeller som strukturerte samlinger av rader hvor hver rad følger et forhåndsdefinert skjema. Skjemaet definerer tabellens struktur, og spesifiserer kolonnenavn, datatyper, begrensninger og relasjoner. Når data settes inn i en tabell, validerer databasestyringssystemet at hver verdi samsvarer med kolonnens datatype og oppfyller eventuelle definerte begrensninger. For eksempel vil en kolonne definert som INTEGER avvise tekstverdier, og en kolonne merket som NOT NULL vil avvise tomme oppføringer. Indekser opprettes på ofte forespurte kolonner for å akselerere datagjenfinning, og fungerer som organiserte referanser som lar databasen finne spesifikke rader uten å skanne hele tabellen. Normalisering er et designprinsipp som organiserer tabeller for å minimere dataredundans og forbedre dataintegritet ved å dele informasjon opp i relaterte tabeller koblet sammen via nøkler. Moderne databaser støtter transaksjoner, som sikrer at flere operasjoner på tabeller enten alle lykkes eller alle feiler samtidig, og dermed opprettholder konsistens selv ved systemfeil. Spørringsoptimaliseringen i database-motoren analyserer SQL-spørringer og avgjør den mest effektive måten å aksessere tabelldata på, med hensyn til tilgjengelige indekser og tabellstatistikk.
Datapresentasjon og visualisering i tabeller
Tabeller fungerer som den primære mekanismen for å presentere strukturert data til brukere både digitalt og på trykk. I forretningsanalyse og analyseapplikasjoner viser tabeller aggregerte måledata, ytelsesindikatorer og detaljerte transaksjonsposter som gjør beslutningstakere i stand til å forstå komplekse datasett på et øyeblikk. Forskning viser at 83 % av forretningsfolk bruker datatabeller som sitt primære verktøy for å analysere informasjon, ettersom tabeller tillater presis sammenligning av verdier og gjenkjenning av mønstre. HTML-tabeller på nettsider bruker semantisk oppmerking med <table>, <tr> (tabellrad), <td> (tabellcelle) og <th> (tabelloverskrift) for å strukturere data både for visuell presentasjon og programmessig tolkning. Regnearkapplikasjoner som Microsoft Excel, Google Sheets og LibreOffice Calc utvider grunnleggende tabellfunksjonalitet med formler, betinget formatering og pivottabeller som lar brukere utføre beregninger og omorganisere data dynamisk. Beste praksis for datavisualisering anbefaler bruk av tabeller når presise verdier er viktigere enn visuelle mønstre, når flere attributter for individuelle poster skal sammenlignes, eller når brukere må utføre oppslag eller beregninger. W3C Web Accessibility Initiative understreker at korrekt strukturerte tabeller med tydelige overskrifter og hensiktsmessig oppmerking er avgjørende for å gjøre data tilgjengelig for brukere med funksjonsnedsettelser, særlig for de som bruker skjermlesere.
Tabeller i AI-overvåking og innholdssporing
I sammenheng med AI-overvåkingsplattformer som AmICited spiller tabeller en kritisk rolle i å organisere og presentere data om hvordan innhold vises på tvers av ulike AI-systemer. Overvåkingstabeller sporer måledata som siteringsfrekvens, forekomstdatoer, AI-plattformkilder (ChatGPT, Perplexity, Google AI Overviews, Claude) og kontekstuell informasjon om hvordan domener og URL-er blir referert til. Disse tabellene gjør det mulig for organisasjoner å forstå sin merkesynlighet i AI-genererte svar og identifisere trender i hvordan ulike AI-systemer siterer eller refererer til innholdet deres. Den strukturerte naturen til overvåkingstabeller gjør det mulig å filtrere, sortere og aggregere siteringsdata, slik at man kan svare på spørsmål som “Hvilke av våre URL-er vises oftest i Perplexity-svar?” eller “Hvordan har vår siteringsrate endret seg den siste måneden?” Datatabeller i overvåkingssystemer muliggjør også sammenligning på flere dimensjoner—sammenligne siteringsmønstre mellom ulike AI-plattformer, analysere siteringsvekst over tid eller identifisere hvilke innholdstyper som får flest AI-referanser. Muligheten til å eksportere overvåkingsdata fra tabeller til rapporter, dashbord og videre analyserverktøy gjør tabeller uunnværlige for organisasjoner som ønsker å forstå og optimalisere sin tilstedeværelse i AI-generert innhold.
Effektiv tabellutforming krever nøye vurdering av struktur, navnekonvensjoner og prinsipper for dataorganisering. Kolonnenavn bør ha klare, beskrivende identifikatorer som nøyaktig reflekterer dataene de inneholder, og unngå forkortelser som kan forvirre brukere eller utviklere. Valg av datatype er kritisk—å velge riktige typer forhindrer ugyldig dataregistrering og muliggjør korrekt sortering og sammenligning. Primærnøkkel-definisjon sikrer at hver rad kan identifiseres entydig, noe som er avgjørende for dataintegritet og etablering av relasjoner til andre tabeller. Normalisering reduserer dataredundans ved å organisere informasjon i relaterte tabeller i stedet for å lagre duplikatdata flere steder. Indekseringsstrategi bør balansere spørringsytelse mot belastningen ved å vedlikeholde indekser ved datamodifikasjoner. Dokumentasjon av tabellstruktur, inkludert kolonndefinisjoner, datatyper, begrensninger og relasjoner, er essensiell for langsiktig vedlikehold. Tilgangskontroll bør implementeres for å sikre at sensitiv data i tabeller beskyttes mot uautorisert tilgang. Ytelsesoptimalisering innebærer å overvåke spørringstider og justere tabellstrukturer, indekser eller spørringer for å forbedre effektiviteten. Sikkerhetskopiering og gjenopprettingsrutiner må etableres for å beskytte tabelldata mot tap eller korrupsjon.
Viktige aspekter ved tabellorganisering og -administrasjon
- Strukturelle komponenter: Tabeller består av kolonner (felter), rader (poster), overskrifter, dataelementer (celler), datatyper, primærnøkler og fremmednøkler som sammen skaper organiserte datastrukturer
- Dataintegritet: Begrensninger, valideringsregler og nøkkelrelasjoner opprettholder datanøyaktighet og forhindrer inkonsekvenser eller duplikatposter
- Spørringseffektivitet: Riktig indeksering, normalisering og spørringsoptimalisering gir rask gjenfinning av spesifikk informasjon fra store tabeller
- Tilgjengelighet: Semantisk HTML-oppmerking, tydelige overskrifter og korrekt struktur gjør tabeller tilgjengelige for brukere med funksjonsnedsettelser og hjelpemidler
- Skalerbarhet: Velutformede tabeller kan effektivt håndtere økende datamengder gjennom hensiktsmessig indeksering, partisjonering og databaseoptimalisering
- Relasjonshåndtering: Fremmednøkler etablerer forbindelser mellom tabeller, og muliggjør komplekse spørringer som kombinerer informasjon fra flere kilder
- Datatypehåndhevelse: Definerte datatyper sikrer at kun gyldig informasjon lagres i hver kolonne, og forhindrer feil og muliggjør korrekt sortering
- Dokumentasjon og vedlikehold: Klar dokumentasjon av tabellstruktur og regelmessig vedlikehold sikrer langvarig brukbarhet og ytelse
Utvikling og fremtid for tabellbasert dataorganisering
Fremtiden for tabellbasert dataorganisering utvikles for å møte stadig mer komplekse datakrav, samtidig som de grunnleggende prinsippene som gjør tabeller effektive, opprettholdes. Kolonnelagrede formater som Apache Parquet og ORC blir standard i stordata-miljøer, og optimaliserer tabeller for analytiske arbeidsbelastninger samtidig som den tabulære strukturen bevares. Semistrukturert data i JSON- og XML-format lagres i økende grad i tabellkolonner, noe som gjør at tabeller kan romme både strukturert og fleksibel data. Maskinlæringsintegrasjon gjør det mulig for databaser å automatisk optimalisere tabellstrukturer og spørringsutførelse basert på bruksmønstre. Sanntidsanalyseplattformer utvider tabeller til å støtte strømmende data og kontinuerlige oppdateringer, og beveger seg forbi tradisjonelle batch-orienterte tabelloperasjoner. Skybaserte databaser redesigner tabellimplementasjoner for å utnytte distribuert databehandling, slik at tabeller kan skalere på tvers av flere servere og geografiske regioner. Datastyringsrammeverk legger økt vekt på tabellmetadata, slektssporing og kvalitetsmålinger for å sikre dataens pålitelighet. Fremveksten av AI-drevne dataplattformer skaper nye muligheter for at tabeller kan fungere som strukturerte kilder for maskinlæringstrening, samtidig som det reises spørsmål om hvordan tabeller skal utformes for å gi treningsdata av høy kvalitet. Etter hvert som organisasjoner fortsetter å generere eksponentielt mer data, forblir tabeller den grunnleggende strukturen for å organisere, forespørre og analysere informasjon, med innovasjoner som fokuserer på ytelse, skalerbarhet og integrasjon med moderne datateknologier.