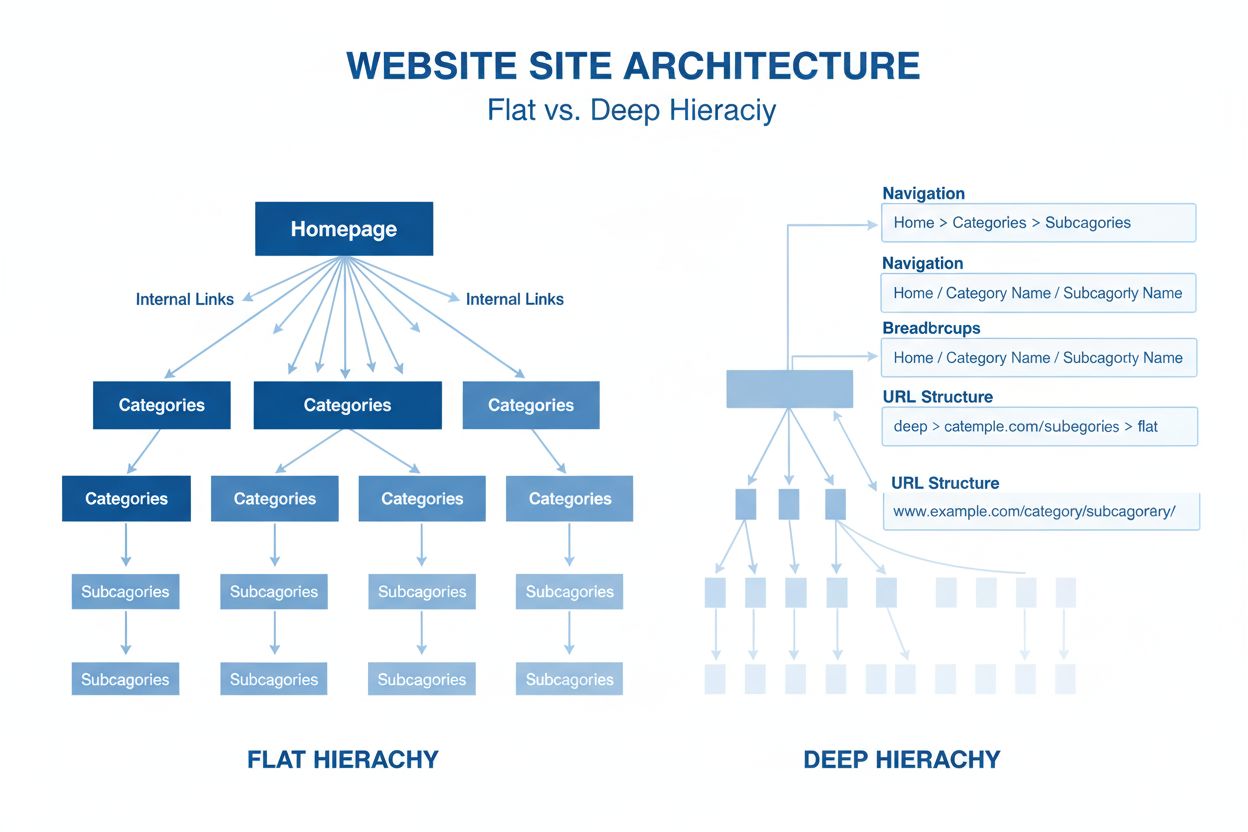
Nettstedsarkitektur
Nettstedsarkitektur er den hierarkiske organiseringen av nettsidens sider og innhold. Lær hvordan riktig struktur forbedrer SEO, brukeropplevelse og synlighet f...
8 min lesing

En nevralt nettverksarkitektur basert på multi-head selvoppmerksomhetsmekanismer som behandler sekvensielle data parallelt, og muliggjør utviklingen av moderne store språkmodeller som ChatGPT, Claude og Perplexity. Introdusert i 2017-artikkelen ‘Attention is All You Need’, har transformere blitt den grunnleggende teknologien bak praktisk talt alle toppmoderne AI-systemer.
En nevralt nettverksarkitektur basert på multi-head selvoppmerksomhetsmekanismer som behandler sekvensielle data parallelt, og muliggjør utviklingen av moderne store språkmodeller som ChatGPT, Claude og Perplexity. Introdusert i 2017-artikkelen 'Attention is All You Need', har transformere blitt den grunnleggende teknologien bak praktisk talt alle toppmoderne AI-systemer.
Transformer-arkitektur er et revolusjonerende nevralt nettverksdesign introdusert i 2017-artikkelen “Attention is All You Need” av forskere hos Google. Den er fundamentalt basert på multi-head selvoppmerksomhetsmekanismer som gjør det mulig for modeller å behandle hele sekvenser av data parallelt, i stedet for sekvensielt. Arkitekturen består av stablede enkoder- og dekoderlag, hvert med selvoppmerksomhetssublag og fremovermatende nevrale nettverk, koblet sammen gjennom residualforbindelser og lag-normalisering. Transformer-arkitektur har blitt den grunnleggende teknologien under praktisk talt alle moderne store språkmodeller (LLM-er), inkludert ChatGPT, Claude, Perplexity og Google AI Overviews, og gjør det til kanskje den viktigste innovasjonen innen nevrale nettverk det siste tiåret.
Betydningen av transformer-arkitektur strekker seg langt utover dens tekniske eleganse. 2017-artikkelen “Attention is All You Need” har blitt sitert over 208 000 ganger og er en av de mest innflytelsesrike forskningsartiklene i maskinlæringens historie. Denne arkitekturen endret grunnleggende hvordan AI-systemer prosesserer og forstår språk, og gjorde det mulig å utvikle modeller med milliarder av parametere som kan engasjere seg i sofistikert resonnering, kreativ skriving og komplekse problemløsningsoppgaver. Foretakets LLM-marked, nesten utelukkende bygget på transformer-teknologi, ble verdsatt til 6,7 milliarder dollar i 2024 og forventes å vokse med en årlig sammensatt vekstrate på 26,1 % frem til 2034, noe som demonstrerer arkitekturens kritiske betydning for moderne AI-infrastruktur.
Utviklingen av transformer-arkitektur representerer et avgjørende øyeblikk i dyp lærings historie, og vokste frem fra tiår med forskning på nevrale nettverk for sekvensiell databehandling. Før transformere dominerte rekurrente nevrale nettverk (RNN-er) og deres varianter, spesielt long short-term memory (LSTM) nettverk, naturlig språkprosessering. Disse arkitekturene hadde imidlertid grunnleggende begrensninger: de behandlet sekvenser sekvensielt, ett element om gangen, noe som gjorde dem trege å trene og dårlige til å fange opp avhengigheter mellom fjerne elementer i lange sekvenser. Problemet med forsvinnende gradient begrenset ytterligere RNN-ers evne til å lære fra langtrekkende relasjoner, siden gradientene ble eksponentielt mindre jo lenger de gikk bakover gjennom mange lag.
Introduksjonen av oppmerksomhetsmekanismer i 2014 av Bahdanau og kolleger ga et gjennombrudd, slik at modeller kunne fokusere på relevante deler av inndatasekvenser uavhengig av avstand. Oppmerksomhet ble imidlertid i utgangspunktet brukt som en forbedring til RNN-er heller enn som en erstatning. Transformer-artikkelen fra 2017 tok dette konseptet videre, og foreslo at attention is all you need—det vil si at en hel nevralt nettverksarkitektur kunne bygges kun med oppmerksomhetsmekanismer og fremovermatende lag, helt uten rekurrens. Dette viste seg å være transformativt. Ved å fjerne sekvensiell behandling gjorde transformere det mulig med massiv parallellisering, slik at forskere kunne trene på enestående mengder data ved hjelp av GPU-er og TPU-er. Den største transformermodellen i originalartikkelen, trent på 8 GPU-er i 3,5 dager, demonstrerte at skala og parallellisering kunne gi dramatisk forbedret ytelse.
Etter den opprinnelige transformer-artikkelen utviklet arkitekturen seg raskt. BERT (Bidirectional Encoder Representations from Transformers), utgitt av Google i 2019, demonstrerte at transformer-enkodere kunne forhåndstrenes på enorme tekstkorpus og finjusteres for ulike etterfølgende oppgaver. BERTs største modell inneholdt 345 millioner parametere og ble trent på 64 spesialiserte TPU-er i fire dager til en estimert kostnad på 7 000 dollar, og oppnådde likevel toppresultater på en rekke språkforståelsestester. Samtidig fulgte OpenAIs GPT-serie en annen vei, med kun dekoderbaserte transformer-arkitekturer trent på språkmodellering. GPT-2 med 1,5 milliarder parametere overrasket forskningsmiljøet ved å vise at språkmodellering alene kunne produsere bemerkelsesverdig kapable systemer. GPT-3, med 175 milliarder parametere, viste fremvoksende evner—ferdigheter som kun dukket opp i stor skala, inkludert fåskudds-læring og kompleks resonnering—som fundamentalt endret forventningene til hva AI-systemer kunne oppnå.
Transformer-arkitektur består av flere sammenkoblede tekniske komponenter som samarbeider for å muliggjøre effektiv parallell behandling og avansert kontekstforståelse. Inngraveringingslaget konverterer diskrete tokens (ord eller delord-enheter) til kontinuerlige vektorrepresentasjoner, vanligvis med dimensjon 512 eller mer. Disse inngravingene forsterkes deretter med posisjonskoding, som legger til informasjon om hver tokens posisjon i sekvensen ved hjelp av sinus- og cosinusfunksjoner med ulike frekvenser. Denne posisjonsinformasjonen er avgjørende fordi, i motsetning til RNN-er som iboende bevarer sekvensrekkefølge gjennom sin rekursive struktur, så behandler transformere alle tokens samtidig og trenger eksplisitte posisjonssignaler for å forstå ordrekkefølge og relative avstander.
Selvoppmerksomhetsmekanismen er den arkitektoniske nyheten som skiller transformere fra alle tidligere nevrale nettverksdesign. For hvert token i inndata-sekvensen beregner modellen tre vektorer: en Query-vektor (representerer hvilken informasjon tokenet søker), Key-vektorer (representerer hvilken informasjon hvert token inneholder), og Value-vektorer (representerer selve informasjonen som skal videreføres). Oppmerksomhetsmekanismen beregner et likhetspoeng mellom hvert tokens Query og alle tokens Key ved hjelp av prikkprodukter, normaliserer disse poengene med softmax for å lage oppmerksomhetsvekter mellom 0 og 1, og bruker deretter disse vektene til å lage en vektet sum av Value-vektorene. Denne prosessen gjør at hvert token selektivt kan fokusere på andre relevante tokens, slik at modellen kan forstå kontekst og relasjoner.
Multi-head attention utvider dette konseptet ved å kjøre flere parallelle oppmerksomhetsmekanismer samtidig, typisk 8, 12 eller 16 hoder. Hvert hode opererer på ulike lineære projeksjoner av Query-, Key- og Value-vektorene, slik at modellen kan rette oppmerksomheten mot ulike typer relasjoner og mønstre i ulike representasjonsunderrom. For eksempel kan ett oppmerksomhetshode fokusere på syntaktiske forhold mellom ord, mens et annet fokuserer på semantiske relasjoner eller langtrekkende avhengigheter. Utgangene fra alle hodene sammenkobles og transformeres lineært, noe som gir modellen rik, mangesidig kontekstuell informasjon. Denne tilnærmingen har vist seg å være svært effektiv, og forskning viser at ulike hoder lærer å spesialisere seg på forskjellige språklige fenomener.
Enkoder-dekoder-strukturen organiserer disse oppmerksomhetsmekanismene i en hierarkisk behandlingspipeline. Enkoderen består av flere stablede lag (typisk 6 eller flere), hver med et multi-head selvoppmerksomhetssublag etterfulgt av et posisjonsavhengig fremovermatende nettverk. Residualforbindelser rundt hvert sublag lar gradientene flyte direkte gjennom nettverket under trening, noe som forbedrer stabiliteten og muliggjør dypere arkitekturer. Lag-normalisering brukes etter hvert sublag, og normaliserer aktiveringer for å opprettholde konsistent skala gjennom nettverket. Dekoderen har en lignende struktur, men inkluderer et ekstra enkoder-dekoder oppmerksomhetslag som lar dekoderen rette oppmerksomheten mot enkoderens utdata, slik at modellen kan fokusere på relevante deler av inndataene når den genererer hvert utdatatoken. I kun dekoder-arkitekturer som GPT, genererer dekoderen utdatatokens autoregressivt, der hvert nye token er betinget av alle tidligere genererte tokens.
| Aspekt | Transformer-arkitektur | RNN/LSTM | Konvolusjonelle nevrale nettverk (CNN) |
|---|---|---|---|
| Behandlingsmetode | Parallell behandling av hele sekvenser med oppmerksomhet | Sekvensiell behandling, ett element om gangen | Lokale konvolusjonsoperasjoner på vinduer av fast størrelse |
| Langtrekkende avhengigheter | Utmerket; oppmerksomhet kan direkte koble fjerne tokens | Dårlig; begrenset av forsvinnende gradienter og sekvensielle flaskehalser | Begrenset; lokalt mottaksfelt krever mange lag |
| Treningshastighet | Veldig rask; massiv parallellisering på GPU/TPU | Treg; sekvensiell behandling forhindrer parallellisering | Rask for faste innganger; mindre egnet for variable sekvenser |
| Minnebehov | Høyt; kvadratisk i sekvenslengde pga. oppmerksomhet | Lavere; lineær i sekvenslengde | Moderat; avhenger av kjernestørrelse og dybde |
| Skalerbarhet | Utmerket; skaleres til milliarder parametere | Begrenset; vanskelig å trene svært store modeller | God for bilder; mindre egnet for sekvenser |
| Typiske bruksområder | Språkmodellering, maskinoversettelse, tekstgenerering | Tidsserier, sekvensiell prediksjon (mindre vanlig nå) | Bildeklassifisering, objektdeteksjon, datamaskinsyn |
| Gradientflyt | Stabil; residualforbindelser muliggjør dype nettverk | Problematisk; forsvinnende/eksploderende gradienter | Generelt stabil; lokale forbindelser hjelper gradientflyt |
| Posisjonsinformasjon | Eksplisitt posisjonskoding kreves | Implisitt gjennom sekvensiell behandling | Implisitt gjennom romlig struktur |
| Toppmoderne LLM-er | GPT, Claude, Llama, Granite, Perplexity | Sjelden brukt i moderne LLM-er | Ikke brukt til språkmodellering |
Forholdet mellom transformer-arkitektur og moderne store språkmodeller er grunnleggende og uatskillelig. Alle større LLM-er utgitt de siste fem årene—inkludert OpenAIs GPT-4, Anthropics Claude, Metas Llama, Googles Gemini, IBMs Granite og Perplexitys AI-modeller—er bygget på transformer-arkitektur. Arkitekturens evne til å skalere effektivt både med modellstørrelse og treningsdata har vist seg avgjørende for å oppnå egenskapene som definerer moderne AI-systemer. Da forskere økte modellstørrelsen fra millioner til milliarder og hundrevis av milliarder parametere, gjorde transformer-arkitekturens parallellisering og oppmerksomhetsmekanismer det mulig å skalere uten proporsjonale økninger i treningstid.
Den autoregressive dekoderprosessen som brukes av de fleste moderne LLM-er er en direkte anvendelse av transformer-dekoderarkitektur. Når de genererer tekst, behandler disse modellene inndataprompten gjennom enkoderen (eller i kun dekoder-modeller, gjennom hele dekoderen) og genererer deretter utdatatokens ett om gangen. Hvert nytt token genereres ved å beregne sannsynlighetsfordelinger over hele vokabularet med softmax, der modellen velger tokenet med høyest sannsynlighet (eller sampler fra fordelingen etter temperaturinnstillinger). Denne prosessen, gjentatt hundrevis eller tusenvis av ganger, produserer sammenhengende, kontekstuelt passende tekst. Selvoppmerksomhetsmekanismen gjør det mulig for modellen å opprettholde kontekst over hele den genererte sekvensen, slik at den kan produsere lange, sammenhengende avsnitt med konsistente temaer, karakterer og logisk flyt.
De fremvoksende egenskapene som observeres i store transformermodeller—ferdigheter som kun oppstår i tilstrekkelig stor skala, som fåskudds-læring, tankekjede-reasoning og læring i kontekst—er direkte konsekvenser av designet til transformer-arkitekturen. Multi-head oppmerksomhetsmekanismens evne til å fange opp ulike relasjoner, kombinert med modellens enorme parameterantall og trening på mangfoldige data, gjør at disse systemene kan utføre oppgaver de aldri eksplisitt er trent på. For eksempel kunne GPT-3 utføre aritmetikk, skrive kode og svare på trivia til tross for at den kun var trent på språkmodellering. Disse fremvoksende egenskapene har gjort transformerbaserte LLM-er til grunnlaget for den moderne AI-revolusjonen, med bruksområder fra samtale-AI og innholdsgenerering til kodegenerering og vitenskapelig forskningsassistanse.
Selvoppmerksomhetsmekanismen er den arkitektoniske innovasjonen som fundamentalt skiller transformere og forklarer deres overlegne ytelse sammenlignet med tidligere tilnærminger. For å forstå selvoppmerksomhet, vurder utfordringen med å tolke tvetydige pronomen i språket. I setningen “Troféet passer ikke i kofferten fordi det er for stort,” kan pronomenet “det” referere til enten troféet eller kofferten, men konteksten gjør det klart at det refererer til troféet. I setningen “Troféet passer ikke i kofferten fordi det er for lite,” refererer det samme pronomenet nå til kofferten. En transformermodell må lære å løse slike tvetydigheter ved å forstå relasjoner mellom ord.
Selvoppmerksomhet oppnår dette gjennom en matematisk elegant prosess. For hvert token i inndata-sekvensen beregner modellen en Query-vektor ved å multiplisere tokenets inngraving med en lært vektmatrise WQ. På samme måte beregnes Key-vektorer (med WK) og Value-vektorer (med WV) for alle tokens. Oppmerksomhetsscoren mellom én tokens Query og en annens Key beregnes som prikkproduktet av disse vektorene, normalisert med kvadratroten av nøkkeldimensjonen (vanligvis √64 ≈ 8). Disse råpoengene sendes deretter gjennom en softmax-funksjon, som gjør dem om til normaliserte oppmerksomhetsvekter som summerer seg til 1. Til slutt beregnes utdata for hvert token som en vektet sum av alle Value-vektorene, der vektene er oppmerksomhetsscorene. Denne prosessen gjør at hvert token selektivt kan aggregere informasjon fra alle andre tokens, med vektene lært under trening for å fange meningsfulle relasjoner.
Matematisk eleganse i selvoppmerksomhet muliggjør effektiv beregning. Hele prosessen kan uttrykkes som matriseoperasjoner: Attention(Q, K, V) = softmax(QK^T / √d_k)V, der Q, K og V er matriser som inneholder alle query-, key- og value-vektorer. Denne matriseformuleringen muliggjør GPU-akselerasjon, slik at transformere kan behandle hele sekvenser parallelt i stedet for sekvensielt. En sekvens på 512 tokens kan behandles omtrent like raskt som et enkelt token i en RNN, noe som gjør transformere flere størrelsesordener raskere å trene. Denne beregningseffektiviteten, kombinert med oppmerksomhetsmekanismens evne til å fange langtrekkende avhengigheter, forklarer hvorfor transformere har blitt den dominerende arkitekturen for språkmodellering.
Multi-head attention utvider selvoppmerksomhetsmekanismen ved å kjøre flere parallelle oppmerksomhetsoperasjoner, som hver lærer ulike aspekter ved token-relasjoner. I en typisk transformer med 8 oppmerksomhetshoder blir inngravingene lineært projisert til 8 ulike representasjonsunderrom, hver med sine egne Query-, Key- og Value-vektmatriser. Hvert hode beregner uavhengig oppmerksomhetsvekter og produserer utdata. Disse utdataene sammenkobles og lineært transformeres gjennom en siste vektmatrise, og produserer den endelige multi-head attention-utdataen. Denne arkitekturen gjør det mulig for modellen å samtidig rette oppmerksomheten mot informasjon fra ulike representasjonsunderrom på ulike posisjoner.
Forskning på trente transformermodeller har avslørt at ulike oppmerksomhetshoder spesialiserer seg på ulike språklige fenomener. Noen hoder fokuserer på syntaktiske relasjoner, og lærer å rette oppmerksomheten mot grammatisk tilknyttede ord (f.eks. verb mot sine subjekter og objekter). Andre hoder fokuserer på semantiske relasjoner, og lærer å rette oppmerksomheten mot ord med relaterte betydninger. Noen fanger til og med langtrekkende avhengigheter, og retter oppmerksomheten mot ord som er langt fra hverandre i sekvensen, men semantisk beslektet. Enkelte hoder lærer til og med å fokusere mest på det aktuelle tokenet, og fungerer nærmest som identitetsoperasjoner. Denne spesialiseringen oppstår naturlig under trening uten eksplisitt veiledning, og demonstrerer kraften i multi-head-arkitekturen til å lære mangfoldige, komplementære representasjoner.
Antall oppmerksomhetshoder er en viktig arkitektonisk hyperparameter. Større modeller bruker vanligvis flere hoder (16, 32 eller enda flere), slik at de kan fange opp flere ulike relasjoner. Dimensjonaliteten per hode blir da lavere, ettersom den totale dimensjonaliteten for oppmerksomhetsberegningen vanligvis holdes konstant. Dette designvalget balanserer fordelene med flere representasjonsunderrom mot beregningseffektivitet. Multi-head-tilnærmingen har vist seg så effektiv at den har blitt standard i praktisk talt alle moderne transformer-implementasjoner, fra BERT og GPT til spesialiserte arkitekturer for bilde, lyd og multimodale oppgaver.
Den opprinnelige transformer-arkitekturen, som beskrevet i “Attention is All You Need”-artikkelen, bruker en enkoder-dekoder-struktur optimalisert for sekvens-til-sekvens-oppgaver som maskinoversettelse. Enkoderen behandler inndatasekvensen og produserer en sekvens av kontekstrike representasjoner. Hvert enkoderlag inneholder to hovedkomponenter: et multi-head selvoppmerksomhetssublag som lar tokens rette oppmerksomheten mot andre tokens i inndataene, og et posisjonsavhengig fremovermatende nettverk som bruker samme ikke-lineære transformasjon på hver posisjon uavhengig. Disse sublagene er koblet sammen gjennom residualforbindelser (også kalt skip connections), som legger input til utdata fra hvert sublag. Dette designet, inspirert av residualnettverk i datasyn, gjør det mulig å trene svært dype nettverk ved å la gradienter flyte direkte gjennom nettverket.
Dekoderen genererer utgangssekvensen ett token om gangen, ved å bruke informasjon fra både enkoderen og tidligere genererte tokens. Hvert dekoderlag inneholder tre hovedkomponenter: et maskert selvoppmerksomhetssublag som lar hvert token rette oppmerksomheten kun mot tidligere tokens (slik at modellen ikke kan “jukse” ved å se fremover i sekvensen under trening), et enkoder-dekoder oppmerksomhetssublag som lar dekodertokens rette oppmerksomheten mot enkoderens utdata, og et posisjonsavhengig fremovermatende nettverk. Maskeringen i selvoppmerksomhetssublaget er avgjørende: den forhindrer informasjonsflyt fra fremtidige posisjoner til fortidige, og sikrer at prediksjoner for posisjon i kun avhenger av kjente utdata ved posisjoner mindre enn i. Denne autoregressive strukturen er essensiell for å generere sekvenser ett token om gangen.
Enkoder-dekoder-arkitekturen har vist seg spesielt effektiv for oppgaver der inn- og utdata har ulik struktur eller lengde, som maskinoversettelse (fra ett språk til et annet), oppsummering (kondensering av lange dokumenter) og spørsmålsbesvarelse (generere svar basert på kontekst). Moderne LLM-er som GPT bruker imidlertid kun dekoder-arkitekturer, der én enkelt stabel med dekoderlag prosesserer både inndataprompten og genererer utdata. Denne forenklingen reduserer modellkompleksiteten og har vist seg like eller mer effektiv for språkmodellering, sannsynligvis fordi modellen kan lære å bruke selvoppmerksomhet til å prosessere input og generere output i en samlet struktur.
En kritisk utfordring i transformer-arkitektur er å representere rekkefølgen av tokens i en sekvens. I motsetning til RNN-er, som iboende bevarer sekvensrekkefølge gjennom sin rekursive struktur, behandler transformere alle tokens parallelt og har ingen innebygd forståelse av posisjon. Uten eksplisitt posisjonsinformasjon ville en transformer betrakte sekvensen “Katten satt på matten” identisk med “matten på satt katten”, noe som ville vært katastrofalt for språkforståelsen. Løsningen er posisjonskoding, som legger til posisjonsavhengige vektorer til token-inngravingene før behandling.
Den opprinnelige transformer-artikkelen bruker sinusformede posisjonskodingsvektorer, der posisjonsvektoren for posisjon pos og dimensjon i beregnes slik:
Disse sinusformede funksjonene skaper et unikt mønster for hver posisjon, med ulike frekvenser for ulike dimensjoner. De lavere frekvensene (mindre i) varierer sakte med posisjon, og fanger opp langtrekkende posisjonsinformasjon, mens høyere frekvenser varierer raskt og fanger detaljer om posisjonen. Dette designet har flere fordeler: det generaliserer naturlig til sekvenser lengre enn de som er sett under trening, gir glatte posisjonsoverganger og gjør det mulig for modellen å lære relative posisjonsrelasjoner. Posisjonskodingsvektorene legges ganske enkelt til token-inngravingene før første oppmerksomhetslag, og modellen lærer å bruke denne posisjonsinformasjonen under trening.
Alternative posisjonskodingsmetoder har blitt foreslått og studert, inkludert relative posisjonsrepresentasjoner (som koder avstander mellom tokens i stedet for absolutte posisjoner) og roterende posisjonsinngraveringer (RoPE) (som roterer inngravingvektorer basert på posisjon). Disse alternativene har gitt forbedringer i visse scenarioer, spesielt for svært lange sekvenser eller ved finjustering på sekvenser som er lengre enn treningssekvensene. Valg av posisjonskoding kan ha stor innvirkning på modellens ytelse, og dette er fortsatt et aktivt forskningsområde innen optimalisering av transformer-arkitektur.
Forståelse av transformer-arkitektur er avgjørende for å forstå hvordan moderne AI-systemer genererer svar som vises i plattformer som ChatGPT, Claude, Perplexity og Google AI Overviews. Disse systemene, alle bygd på transformer-teknologi, behandler brukerforespørsler gjennom flere lag med selvoppmerksomhet, slik at de kan forstå kontekst og generere sammenhengende, relevante svar. Når en bruker
Transformer-arkitektur behandler hele sekvenser parallelt ved hjelp av selvoppmerksomhet, mens RNN-er og LSTM-er behandler sekvenser sekvensielt, ett element om gangen. Denne parallelliseringen gjør transformere betydelig raskere å trene og bedre til å fange opp langtrekkende avhengigheter mellom fjerne ord eller tokens. Transformere unngår også problemet med forsvinnende gradient som plaget RNN-er, og gjør dem i stand til å lære fra mye lengre sekvenser effektivt.
Selvoppmerksomhet beregner tre vektorer (Query, Key og Value) for hvert token i inndatasekvensen. Query-vektoren fra ett token sammenlignes med Key-vektorene til alle tokens for å bestemme relevanspoeng, som normaliseres ved hjelp av softmax. Disse oppmerksomhetsvektene brukes deretter på Value-vektorene for å lage kontekstavhengige representasjoner. Denne mekanismen gjør at hvert token kan 'fokusere på' eller rette oppmerksomheten mot andre relevante tokens i sekvensen, slik at modellen kan forstå kontekst og relasjoner.
Hovedkomponentene inkluderer: (1) Inngraveringer og posisjonskoding for å representere tokens og deres posisjoner, (2) Multi-head selvoppmerksomhetslag som beregner oppmerksomhet på tvers av flere representasjonsunderrom, (3) Fremovermatende nevrale nettverk brukt på hver posisjon uavhengig, (4) Enkoderstabel som behandler inndatasekvenser, (5) Dekoderstabel som genererer utdata, og (6) Residualforbindelser og lagnormalisering for treningsstabilitet. Disse komponentene samarbeider for å muliggjøre effektiv parallell behandling og kontekstforståelse.
Transformer-arkitektur utmerker seg for LLM-er fordi den muliggjør parallell behandling av hele sekvenser, noe som dramatisk reduserer treningstiden sammenlignet med sekvensielle RNN-er. Den fanger opp langtrekkende avhengigheter mer effektivt gjennom selvoppmerksomhet, slik at modeller kan forstå kontekst på tvers av hele dokumenter. Arkitekturen skalerer også effektivt med større datasett og flere parametere, noe som har vist seg å være avgjørende for å trene modeller med milliarder av parametere som viser fremvoksende evner.
Multi-head attention kjører flere parallelle oppmerksomhetsmekanismer (typisk 8 eller 16 hoder) samtidig, hvor hvert hode opererer på ulike representasjonsunderrom. Hvert hode lærer å fokusere på forskjellige typer relasjoner og mønstre i dataene. Utgangene fra alle hodene sammenkobles og transformeres lineært, slik at modellen kan fange opp mangfoldig kontekstuell informasjon. Denne tilnærmingen forbedrer modellens evne til å forstå komplekse relasjoner og forbedrer den totale ytelsen betydelig.
Posisjonskoding legger til informasjon om token-posisjoner til inngraveringsvektorene ved hjelp av sinus- og cosinusfunksjoner med ulike frekvenser. Siden transformere behandler alle tokens parallelt (i motsetning til sekvensielle RNN-er), trenger de eksplisitt posisjonsinformasjon for å forstå ordrekkefølgen. Posisjonskodingsvektorer legges til token-inngravinger før behandling, slik at modellen kan lære hvordan posisjon påvirker mening og muliggjør generalisering til sekvenser som er lengre enn de som er sett under trening.
Enkoderen behandler inndatasekvensen og skaper rike kontekstuelle representasjoner gjennom flere lag med selvoppmerksomhet og fremovermatende nettverk. Dekoderen genererer utgangssekvensen ett token om gangen, og bruker encoder-decoder attention for å fokusere på relevante deler av inndataene. Denne strukturen er spesielt nyttig for sekvens-til-sekvens-oppgaver som maskinoversettelse, men moderne LLM-er bruker ofte kun dekoder-arkitektur for tekstgenereringsoppgaver.
Transformer-arkitektur driver AI-systemene som genererer svar i plattformer som ChatGPT, Claude, Perplexity og Google AI Overviews. Å forstå hvordan transformere prosesserer og genererer tekst er avgjørende for AI-overvåkingsplattformer som AmICited, som sporer hvor merker og domener vises i AI-genererte svar. Arkitekturens evne til å forstå kontekst og generere sammenhengende tekst påvirker direkte hvordan merker nevnes og representeres i AI-utdata.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Nettstedsarkitektur er den hierarkiske organiseringen av nettsidens sider og innhold. Lær hvordan riktig struktur forbedrer SEO, brukeropplevelse og synlighet f...
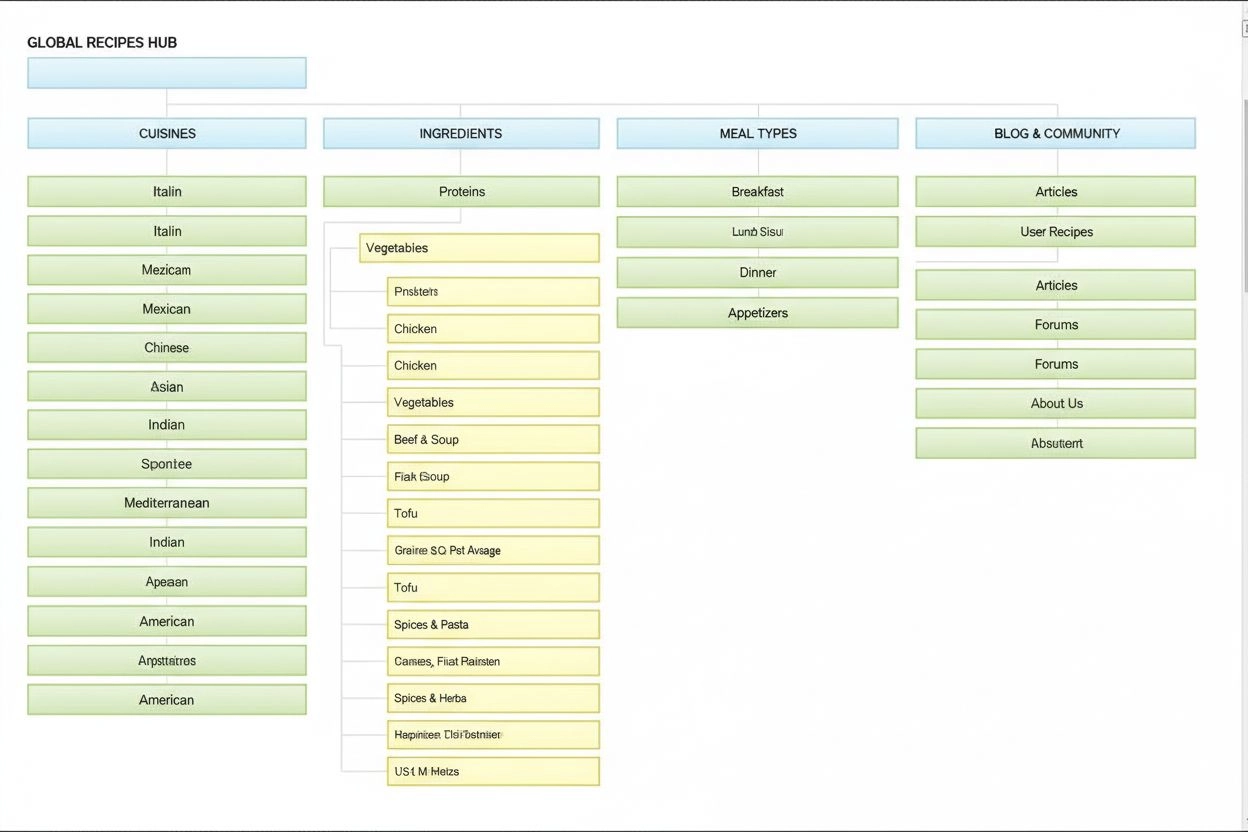
Informasjonsarkitektur er praksisen med å organisere og strukturere innhold for optimal brukervennlighet. Lær hvordan IA forbedrer søkbarhet, brukeropplevelse o...
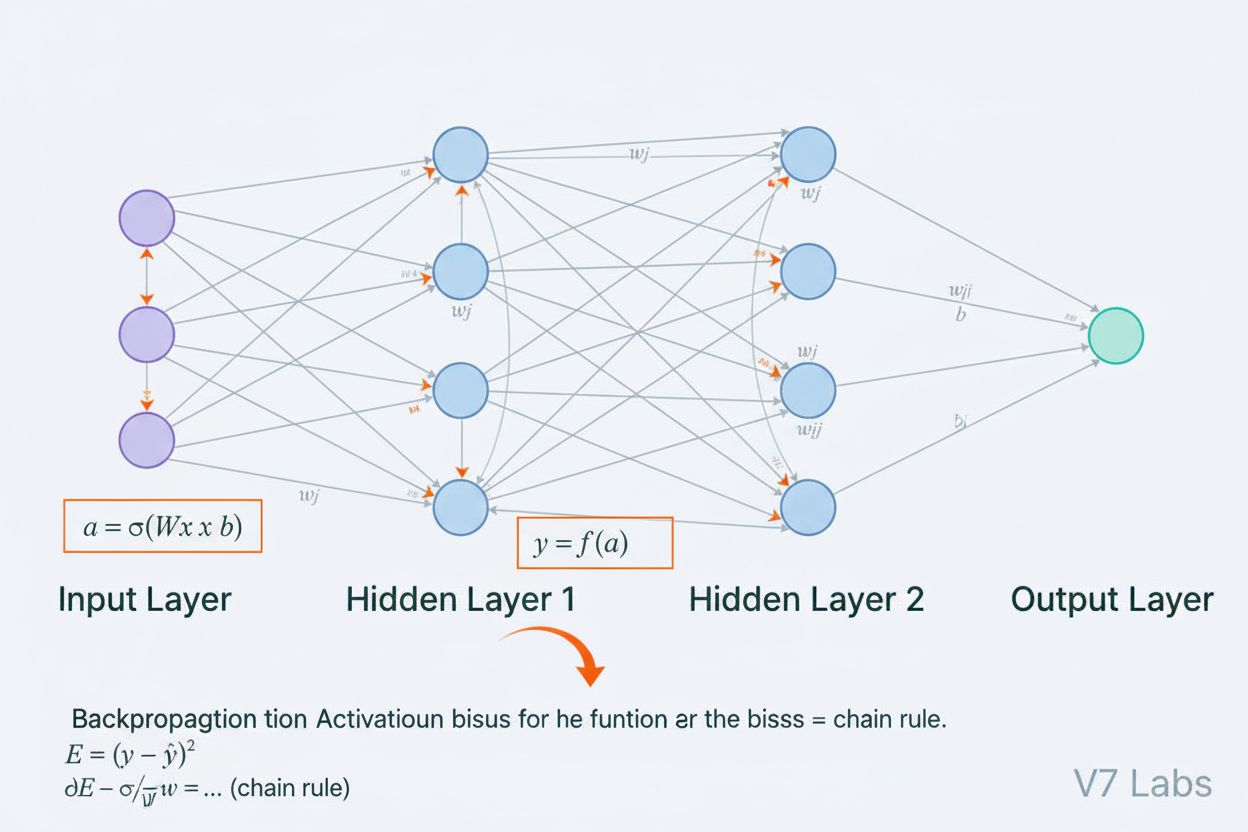
Omfattende definisjon av neurale nettverk som datasystemer inspirert av biologiske hjerner. Lær hvordan kunstige nevroner, lag og tilbakepropagering muliggjør A...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.