
Czym są AI Crawlers: GPTBot, ClaudeBot i inni
Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...
12 min czytania

Dowiedz się, jak AI crawlery wpływają na zasoby serwera, przepustowość i wydajność. Poznaj prawdziwe statystyki, strategie łagodzenia skutków oraz rozwiązania infrastrukturalne do efektywnego zarządzania obciążeniem botów.
AI crawlery stały się znaczącą siłą w ruchu internetowym — największe firmy AI wdrażają zaawansowane boty do indeksowania treści na potrzeby uczenia i wyszukiwania. Działają one na ogromną skalę, generując około 569 milionów żądań miesięcznie w sieci i zużywając ponad 30TB przepustowości globalnie. Główne crawlery AI to GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) oraz Amazonbot (Amazon), każdy z własnymi wzorcami crawlów i wymaganiami zasobowymi. Zrozumienie zachowania i charakterystyki tych crawlerów jest kluczowe dla administratorów stron w celu właściwego zarządzania zasobami serwera i podejmowania świadomych decyzji dotyczących polityki dostępu.
| Nazwa Crawlera | Firma | Cel | Wzorzec żądań |
|---|---|---|---|
| GPTBot | OpenAI | Dane treningowe dla ChatGPT i modeli GPT | Agresywne, częste żądania |
| ClaudeBot | Anthropic | Dane treningowe dla modeli Claude AI | Umiarkowana częstotliwość, respektuje crawlery |
| PerplexityBot | Perplexity AI | Wyszukiwanie i generowanie odpowiedzi w czasie rzeczywistym | Umiarkowana do wysokiej częstotliwość |
| Google-Extended | Rozszerzone indeksowanie dla funkcji AI | Kontrolowane, przestrzega robots.txt | |
| Amazonbot | Amazon | Indeksowanie produktów i treści | Zmienna, skoncentrowana na handlu |
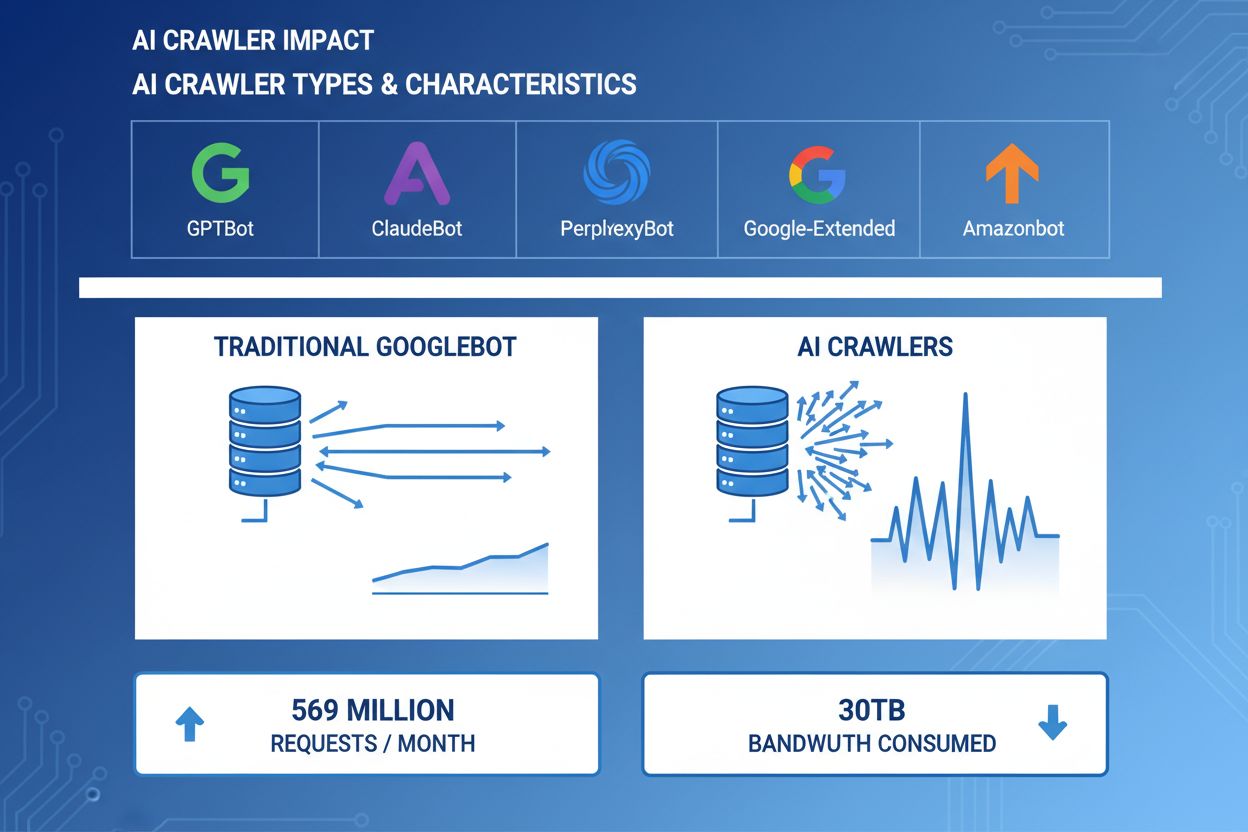
AI crawlery zużywają zasoby serwera na wielu płaszczyznach, wywołując mierzalny wpływ na wydajność infrastruktury. Użycie CPU może wzrosnąć o 300% i więcej podczas szczytu aktywności crawlerów, gdy serwery obsługują tysiące równoczesnych żądań i parsują zawartość HTML. Zużycie przepustowości to jeden z najbardziej widocznych kosztów — pojedyncza popularna strona może codziennie serwować crawlerom gigabajty danych. Zużycie pamięci RAM znacząco rośnie, gdy serwery utrzymują pule połączeń i buforują duże ilości danych do przetworzenia. Zapytań do bazy danych jest wielokrotnie więcej, ponieważ crawlery żądają stron generujących dynamiczne treści, co powoduje dodatkowe obciążenie I/O. Dysk I/O staje się wąskim gardłem, gdy serwer musi czytać z dysku, obsługując żądania crawlerów, zwłaszcza na stronach z dużą biblioteką treści.
| Zasób | Wpływ | Przykład z praktyki |
|---|---|---|
| CPU | Skoki 200-300% podczas szczytu crawlów | Średnie obciążenie serwera rośnie z 2.0 do 8.0 |
| Przepustowość | 15-40% miesięcznego zużycia | Strona 500GB wydaje 150GB crawlerom miesięcznie |
| Pamięć RAM | 20-30% wzrost zużycia RAM | Serwer 8GB wymaga 10GB podczas crawlów |
| Baza danych | 2-5x wzrost liczby zapytań | Czas odpowiedzi rośnie z 50ms do 250ms |
| Dysk I/O | Utrzymujące się wysokie odczyty | Wykorzystanie dysku wzrasta z 30% do 85% |
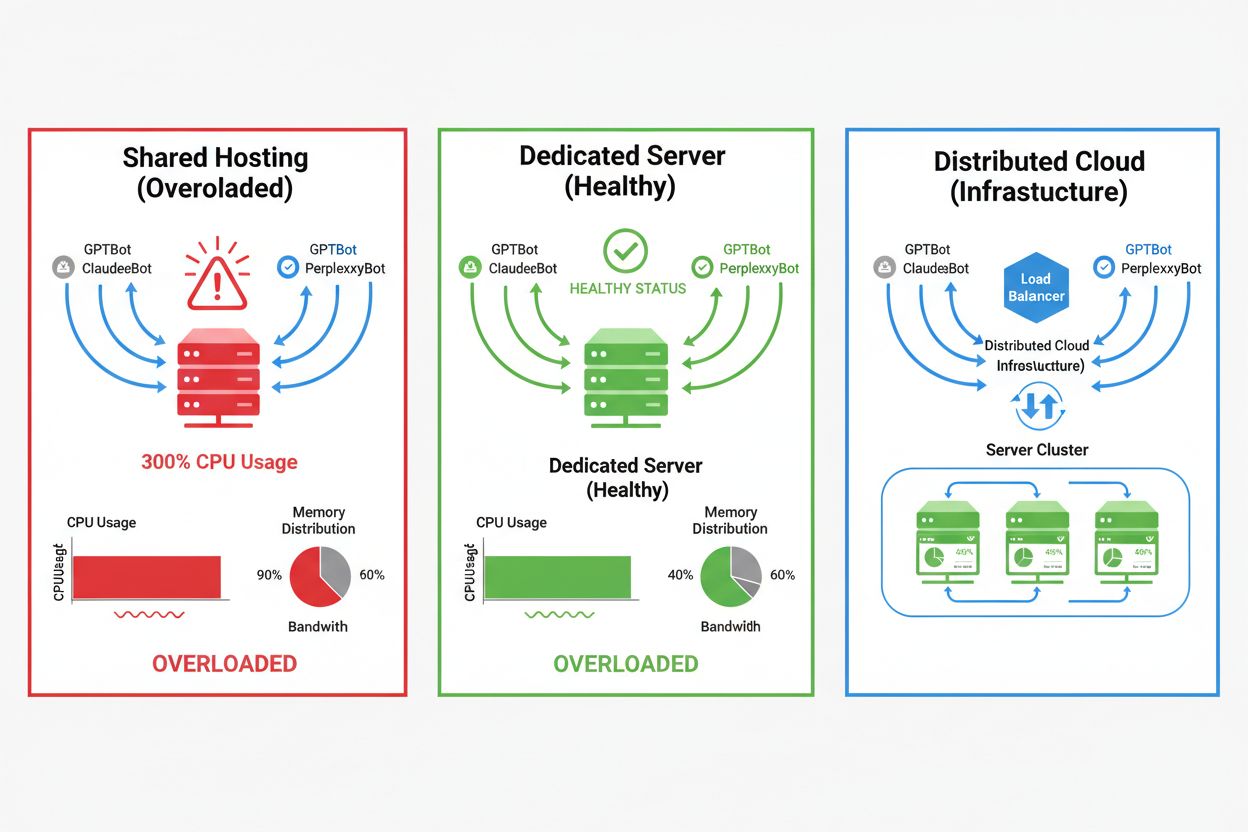
Wpływ AI crawlerów dramatycznie różni się w zależności od środowiska hostingowego — najpoważniejsze konsekwencje dotyczą hostingu współdzielonego. W takich scenariuszach szczególnie problematyczny jest „syndrom hałaśliwego sąsiada” — gdy jedna strona na wspólnym serwerze przyciąga intensywny ruch crawlerów, zużywa zasoby kosztem innych hostowanych witryn, co pogarsza wydajność wszystkim użytkownikom. Serwery dedykowane i infrastruktura chmurowa zapewniają lepszą izolację i gwarancje zasobów, pozwalając absorbowanie ruchu crawlerów bez wpływu na inne usługi. Jednak nawet infrastruktura dedykowana wymaga monitorowania i skalowania, aby sprostać skumulowanemu obciążeniu ze strony wielu jednocześnie działających crawlerów AI.
Kluczowe różnice między środowiskami hostingowymi:
Wpływ finansowy ruchu crawlerów AI wykracza poza zwykłe koszty transferu, obejmując zarówno bezpośrednie, jak i ukryte wydatki, które mogą istotnie obciążyć Twój budżet. Koszty bezpośrednie to wzrost opłat za transfer u dostawcy hostingu, który może wynosić setki lub tysiące dolarów miesięcznie w zależności od natężenia ruchu i intensywności crawlerów. Koszty ukryte pojawiają się poprzez zwiększone wymagania infrastrukturalne — możesz być zmuszony do przejścia na wyższe plany hostingowe, wdrożenia dodatkowych warstw cache lub inwestycji w usługi CDN specjalnie do obsługi ruchu crawlerów. Kalkulacja ROI staje się złożona, gdy weźmiemy pod uwagę, że crawlery AI dają minimalną wartość bezpośrednią dla Twojego biznesu, jednocześnie zużywając zasoby, które mogłyby obsłużyć płacących klientów lub poprawić doświadczenie użytkownika. Wielu właścicieli stron stwierdza, że koszt obsługi ruchu crawlerów przewyższa potencjalne korzyści z trenowania modeli AI czy widoczności w wynikach wyszukiwania opartych na AI.
Ruch crawlerów AI bezpośrednio pogarsza doświadczenie prawdziwych użytkowników, konsumując zasoby serwera, które mogłyby szybciej obsłużyć odwiedzających. Metryki Core Web Vitals pogarszają się zauważalnie — Largest Contentful Paint (LCP) wydłuża się o 200-500ms, a Time to First Byte (TTFB) pogarsza o 100-300ms podczas wzmożonej aktywności crawlerów. Takie pogorszenie wydajności powoduje lawinę negatywnych skutków: wolniejsze ładowanie stron zmniejsza zaangażowanie użytkowników, zwiększa współczynnik odrzuceń i ostatecznie obniża konwersję na stronach e-commerce i leadowych. Pozycja w wyszukiwarkach również spada, ponieważ algorytm Google bierze Core Web Vitals pod uwagę jako czynnik rankingowy, tworząc błędne koło, w którym ruch crawlerów pośrednio szkodzi SEO. Użytkownicy doświadczający wolnego ładowania częściej opuszczają stronę i wybierają konkurencję, co bezpośrednio wpływa na przychody i postrzeganie marki.
Efektywne zarządzanie ruchem AI crawlerów zaczyna się od kompleksowego monitorowania i detekcji, pozwalając zrozumieć skalę problemu przed wdrożeniem rozwiązań. Większość serwerów zapisuje ciągi user-agent identyfikujące crawlera w każdym żądaniu, co stanowi podstawę do analizy ruchu i decyzji filtrujących. Logi serwera, platformy analityczne oraz wyspecjalizowane narzędzia mogą analizować te user-agenty, by identyfikować i mierzyć wzorce ruchu crawlerów.
Kluczowe metody detekcji i narzędzia:
Pierwszą linią obrony przed nadmiernym ruchem crawlerów AI jest dobrze skonfigurowany plik robots.txt, który jednoznacznie kontroluje dostęp crawlerów do strony. Ten prosty plik tekstowy, umieszczony w katalogu głównym strony, pozwala blokować określone crawlery, ograniczać częstotliwość crawlów i kierować crawlery do sitemap z wybranymi treściami do indeksacji. Limitowanie częstotliwości na poziomie aplikacji lub serwera to kolejna warstwa ochrony, ograniczająca liczbę żądań z konkretnych adresów IP lub user-agentów, by zapobiec wyczerpaniu zasobów. Te strategie są odwracalne i nieblokujące, dlatego to dobre punkty wyjścia przed wdrożeniem bardziej agresywnych środków.
# robots.txt - Blokuj crawlery AI, zezwalaj na wyszukiwarki
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Zezwól Google i Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Ogranicz częstotliwość dla wszystkich pozostałych botów
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Web Application Firewalls (WAF) i Content Delivery Networks (CDN) zapewniają zaawansowaną, korporacyjną ochronę przed niechcianym ruchem crawlerów dzięki analizie behawioralnej i inteligentnemu filtrowaniu. Cloudflare i podobni dostawcy CDN oferują wbudowane funkcje zarządzania botami, które potrafią wykrywać i blokować crawlery AI na podstawie wzorców zachowań, reputacji IP i charakterystyki żądań bez potrzeby ręcznej konfiguracji. Reguły WAF można ustawić tak, by kwestionowały podejrzane żądania, limitowały konkretne user-agenty lub całkowicie blokowały ruch z określonych adresów IP crawlerów. Rozwiązania te działają na edge, filtrując szkodliwy ruch, zanim trafi on do Twojego serwera źródłowego, znacząco zmniejszając obciążenie infrastruktury. Ich przewagą jest także zdolność automatycznego wykrywania nowych crawlerów i ewoluujących wzorców ataków bez konieczności ręcznych aktualizacji konfiguracji.
Decyzja o blokowaniu crawlerów AI wymaga rozważenia kompromisów między ochroną zasobów serwera a zachowaniem widoczności w wynikach i aplikacjach opartych na AI. Całkowita blokada crawlerów AI eliminuje możliwość pojawienia się Twoich treści w wynikach wyszukiwania ChatGPT, odpowiedziach Perplexity AI czy innych mechanizmach odkrywania treści opartych na AI, potencjalnie ograniczając ruch referencyjny i widoczność marki. Z drugiej strony, nieograniczony dostęp crawlerów oznacza duże zużycie zasobów i może pogorszyć doświadczenie użytkowników bez wymiernych korzyści biznesowych. Optymalna strategia zależy od Twojej sytuacji: strony o dużym ruchu i zasobach mogą pozwolić crawlerom na dostęp, podczas gdy witryny z ograniczonymi zasobami powinny priorytetowo traktować użytkowników, blokując lub limitując crawlery. Decyzje strategiczne powinny uwzględniać branżę, grupę docelową, typ treści i cele biznesowe, zamiast stosować podejście uniwersalne.
Strony, które zdecydują się akceptować ruch crawlerów AI, mogą utrzymać wydajność poprzez skalowanie infrastruktury. Skalowanie pionowe (vertical scaling) — czyli rozbudowa serwerów o więcej CPU, RAM i przepustowości — to proste, lecz kosztowne rozwiązanie, które ostatecznie napotyka na fizyczne limity. Skalowanie poziome (horizontal scaling) — rozłożenie ruchu na wiele serwerów z użyciem load balancerów — oferuje lepszą skalowalność i odporność w dłuższej perspektywie. Platformy chmurowe jak AWS, Google Cloud czy Azure zapewniają autoskalowanie, automatycznie przydzielając zasoby w czasie szczytu i zwalniając je w okresach ciszy, co minimalizuje koszty. CDN mogą cache’ować treści statyczne na edge, odciążając serwer źródłowy i poprawiając wydajność zarówno dla użytkowników, jak i crawlerów. Optymalizacja bazy danych, cache zapytań i ulepszenia na poziomie aplikacji mogą również zmniejszyć zużycie zasobów na żądanie bez konieczności rozbudowy infrastruktury.
Stały monitoring i optymalizacja są niezbędne dla utrzymania optymalnej wydajności w obliczu stałego ruchu crawlerów AI. Wyspecjalizowane narzędzia dają wgląd w aktywność crawlerów, zużycie zasobów i metryki wydajności, umożliwiając podejmowanie decyzji opartych na danych odnośnie strategii zarządzania crawlerami. Wdrożenie kompleksowego monitoringu od początku pozwala ustalić punkty odniesienia, wykrywać trendy i mierzyć skuteczność wdrażanych strategii w czasie.
Podstawowe narzędzia i praktyki monitoringu:
Krajobraz zarządzania crawlerami AI stale się zmienia — pojawiają się nowe standardy branżowe i inicjatywy, które kształtują interakcję stron z firmami AI. Standard llms.txt to nowe podejście do przekazywania firmom AI informacji o prawach i preferencjach dotyczących wykorzystania treści — potencjalnie bardziej elastyczna alternatywa wobec całkowitej blokady czy otwarcia. Dyskusje branżowe na temat modeli rekompensat wskazują, że firmy AI w przyszłości mogą płacić za dostęp do danych treningowych, co zasadniczo zmieni ekonomię ruchu crawlerów. By zabezpieczyć przyszłość infrastruktury, śledź nowe standardy, monitoruj rozwój branży i zachowaj elastyczność w polityce zarządzania crawlerami. Budowanie relacji z firmami AI, udział w dyskusjach branżowych i promowanie uczciwych modeli rekompensat będą coraz ważniejsze w miarę, jak AI staje się centralnym elementem odkrywania i konsumpcji treści w internecie. Strony, które odniosą sukces w tym zmieniającym się krajobrazie, to te, które połączą innowacyjność z pragmatyzmem — chroniąc zasoby, a jednocześnie pozostając otwartymi na realne możliwości widoczności i współpracy.
Crawlery AI (GPTBot, ClaudeBot) pobierają treści do trenowania LLM, niekoniecznie kierując ruch z powrotem. Crawlery wyszukiwarek (Googlebot) indeksują treści dla widoczności w wyszukiwarce i zazwyczaj generują ruch referencyjny. Crawlery AI działają agresywniej, wykonując większe batchowe żądania i ignorując zalecenia oszczędzające przepustowość.
Przykłady z rzeczywistości pokazują ponad 30TB miesięcznie od pojedynczych crawlerów. Zużycie zależy od wielkości strony, ilości treści i częstotliwości crawlów. Sam GPTBot OpenAI wygenerował 569 milionów żądań w jednym miesiącu w sieci Vercel.
Blokowanie crawlerów trenujących AI (GPTBot, ClaudeBot) nie wpłynie na pozycję w Google. Jednak blokowanie crawlerów wyszukiwarek AI może zmniejszyć widoczność w wynikach wyszukiwania opartych na AI, takich jak Perplexity czy ChatGPT search.
Zwróć uwagę na niewyjaśnione skoki CPU (300%+), zwiększone zużycie przepustowości bez wzrostu liczby użytkowników, wolniejsze ładowanie stron i nietypowe ciągi user-agent w logach serwera. Metryki Core Web Vitals również mogą się znacząco pogorszyć.
Dla stron z dużym ruchem od crawlerów hosting dedykowany zapewnia lepszą izolację zasobów, kontrolę i przewidywalność kosztów. W środowiskach współdzielonych występuje 'syndrom hałaśliwego sąsiada', gdzie ruch od crawlera jednej strony wpływa na wszystkie hostowane strony.
Używaj Google Search Console do danych Googlebota, logów dostępu serwera do szczegółowej analizy ruchu, analiz CDN (Cloudflare) i wyspecjalizowanych platform takich jak AmICited.com do kompleksowego monitoringu i śledzenia crawlerów AI.
Tak, poprzez dyrektywy robots.txt, reguły WAF i filtrowanie IP. Możesz zezwolić korzystnym crawlerom jak Googlebot, blokując jednocześnie zasobożerne crawlery trenujące AI za pomocą reguł specyficznych dla user-agenta.
Porównaj metryki serwera przed i po wdrożeniu kontroli crawlerów. Monitoruj Core Web Vitals (LCP, TTFB), czasy ładowania stron, zużycie CPU i metryki doświadczenia użytkownika. Narzędzia takie jak Google PageSpeed Insights oraz platformy do monitoringu serwera dają szczegółowe wglądy.
Uzyskaj wgląd w czasie rzeczywistym, jak modele AI uzyskują dostęp do Twoich treści i wpływają na zasoby serwera dzięki specjalistycznej platformie monitorującej AmICited.
Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...

Dowiedz się, jak identyfikować i monitorować crawlery AI takie jak GPTBot, PerplexityBot i ClaudeBot w logach serwera. Poznaj ciągi user-agent, metody weryfikac...
Dowiedz się, którym crawlerom AI pozwolić, a które zablokować w swoim pliku robots.txt. Kompleksowy przewodnik obejmujący GPTBot, ClaudeBot, PerplexityBot oraz ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.