Poznaj, jak systemy AI rozpoznają i przetwarzają byty w tekście. Dowiedz się o modelach NER, architekturach transformerów oraz rzeczywistych zastosowaniach zrozumienia bytów.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Zrozumienie bytów stało się kluczową umiejętnością nowoczesnych systemów sztucznej inteligencji, umożliwiając maszynom identyfikację i rozumienie najważniejszych aktorów, miejsc oraz pojęć w nieustrukturyzowanym tekście. Od wyszukiwarek, które rozumieją intencje użytkownika, po chatboty mogące odpowiadać na złożone pytania dotyczące konkretnych osób i organizacji—rozpoznawanie bytów stanowi fundament sensownej interakcji człowieka z komputerem. Ta techniczna zdolność jest krytyczna w wielu branżach—instytucje finansowe używają jej do monitoringu zgodności, systemy opieki zdrowotnej do zarządzania dokumentacją pacjentów, a platformy e-commerce polegają na niej, by rozumieć wzmianki o produktach i opinie klientów. Zrozumienie, jak systemy AI wydobywają i interpretują byty, jest kluczowe dla każdego, kto buduje lub wdraża aplikacje NLP w środowiskach produkcyjnych.
Kluczowe Pojęcia: Czym Są Byty?
Rozpoznawanie Nazwanych Bytów (NER) to zadanie NLP polegające na identyfikacji i klasyfikacji nazwanych bytów—konkretnych, znaczących jednostek informacji—w tekście do z góry określonych kategorii. Byty te reprezentują konkretne podmioty niosące znaczenie semantyczne: osoby wykonujące działania, organizacje podejmujące decyzje, miejsca wydarzeń, wyrażenia czasowe osadzające zdarzenia w czasie, wartości pieniężne określające transakcje oraz produkty będące przedmiotem obrotu. Klasyfikacja bytów ma znaczenie, ponieważ przekształca surowy tekst w uporządkowaną wiedzę, którą maszyny mogą analizować i wykorzystywać; bez tego system nie odróżni “Apple jako firmy” od “apple jako owocu”, ani nie zrozumie, że “John Smith” i “J. Smith” to ta sama osoba. Zdolność do precyzyjnej klasyfikacji bytów umożliwia kolejne zastosowania, takie jak budowa grafów wiedzy, ekstrakcja informacji, odpowiadanie na pytania czy wykrywanie relacji.
Typ Bytu
Definicja
Przykład
PERSON
Pojedyncze osoby
“Steve Jobs”, “Maria Skłodowska-Curie”
ORGANIZATION
Firmy, instytucje, grupy
“Microsoft”, “Organizacja Narodów Zjednoczonych”, “Uniwersytet Harvarda”
LOCATION
Miejsca geograficzne i regiony
“Nowy Jork”, “Amazonka”, “Dolina Krzemowa”
DATE
Wyrażenia czasowe i okresy
“15 stycznia 2024”, “następny wtorek”, “III kwartał 2023”
Nowoczesne systemy AI przetwarzają byty przez zaawansowany, wieloetapowy pipeline, który zaczyna się od tokenizacji, czyli dzielenia surowego tekstu na pojedyncze tokeny będące podstawą dalszego przetwarzania. Każdy token zamieniany jest na reprezentację numeryczną za pomocą osadzeń słów—gęstych wektorów niosących znaczenie semantyczne—które następnie trafiają do architektur sieci neuronowych zaprojektowanych do rozumienia kontekstu i relacji. Modele oparte na transformerach, które stały się dominującą architekturą we współczesnym NLP, przetwarzają całe sekwencje równolegle, a nie sekwencyjnie, co pozwala uchwycić dalekozasięgowe zależności i złożone relacje kontekstowe kluczowe dla precyzyjnego rozpoznawania bytów. Mechanizm self-attention w Transformerach pozwala każdemu tokenowi dynamicznie ważyć znaczenie wszystkich innych tokenów w sekwencji, tworząc bogate reprezentacje kontekstowe—dzięki temu “bank” jest interpretowane inaczej w “river bank” i “savings bank”. Wstępnie wytrenowane modele językowe jak BERT i GPT uczą się ogólnych wzorców językowych na ogromnych korpusach tekstu przed dostrojeniem do zadania rozpoznawania bytów, dzięki czemu mogą wykorzystywać wiedzę o składni, semantyce i świecie. Ostatnia warstwa systemów rozpoznawania bytów zazwyczaj stosuje podejście etykietowania sekwencji—często za pomocą Conditional Random Field (CRF) lub prostej głowicy klasyfikacyjnej—która przypisuje etykiety bytów każdemu tokenowi na podstawie wyuczonych reprezentacji kontekstowych. Taka architektura pozwala AI nie tylko rozpoznawać obecność bytów, ale także ich wzajemne relacje i role w szerszym kontekście tekstu.
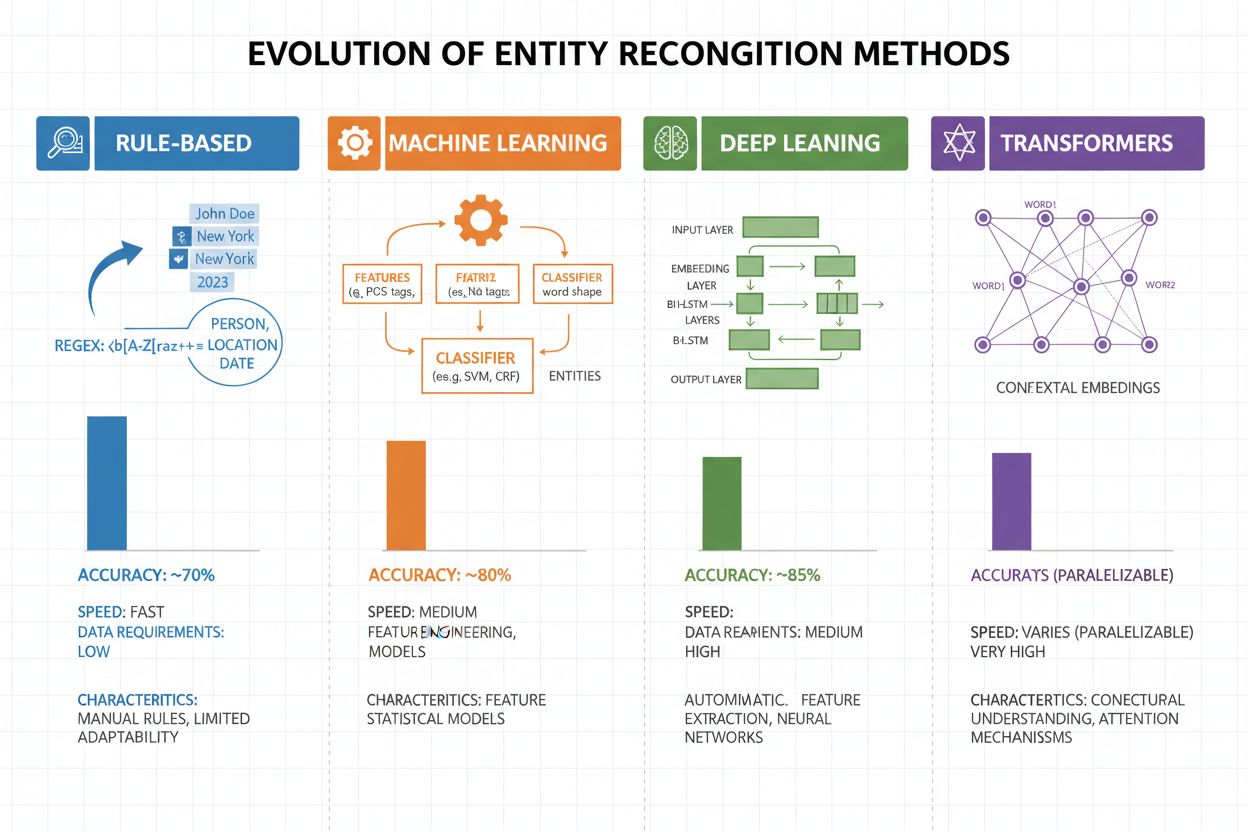
Ewolucja Metod Rozpoznawania Bytów
Rozpoznawanie bytów przeszło ogromną ewolucję na przestrzeni ostatnich dwóch dekad—od prostych podejść opartych na regułach po zaawansowane architektury neuronowe. Wczesne systemy opierały się na ręcznie tworzonych regułach i słownikach, wykorzystując wyrażenia regularne i dopasowania wzorców do wykrywania bytów—były interpretowalne i wymagały minimalnej ilości danych, lecz słabo się generalizowały i wymagały dużego nakładu pracy przy utrzymaniu. Pojawienie się uczenia maszynowego przyniosło podejścia nadzorowane, takie jak Support Vector Machines (SVM) i Conditional Random Fields (CRF), które uczyły się na oznaczonych danych przez inżynierię cech i znacznie poprawiły skuteczność, choć nadal wymagały wiedzy ekspertów do projektowania cech. Metody głębokiego uczenia, zwłaszcza LSTM i BiLSTM, zautomatyzowały ekstrakcję cech, ucząc się reprezentacji bezpośrednio z tekstu, osiągając wyższą skuteczność bez ręcznej inżynierii, ale wymagając większych zbiorów danych. Modele oparte na transformerach (BERT, RoBERTa) zrewolucjonizowały dziedzinę, wykorzystując mechanizm samo-uwagi do uchwycenia dalekozasięgowych zależności i niuansów kontekstowych, osiągając wyniki na poziomie światowym (BERT osiągnął 90,9% F1 na CoNLL-2003) i umożliwiając transfer learning z wielkich modeli pretrenowanych. Balans między złożonością a skutecznością przesunął się znacząco: systemy oparte na regułach nadal mają wartość w środowiskach z ograniczonymi zasobami i specjalistycznych domenach, ale tam, gdzie dostępne są odpowiednie zasoby i dane, dominują modele transformerowe, a lżejsze warianty, takie jak DistilBERT, stanowią kompromis dla systemów produkcyjnych z wymaganiami dotyczącymi opóźnień.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Modele Transformerowe i Nowoczesne Podejścia
Modele oparte na transformerach fundamentalnie zmieniły rozpoznawanie bytów, zastępując przetwarzanie sekwencyjne równoległymi mechanizmami samo-uwagi, które jednocześnie biorą pod uwagę wszystkie tokeny w zdaniu, zapewniając bogatsze rozumienie kontekstu niż wcześniejsze architektury. BERT i jego warianty (RoBERTa, DistilBERT, ALBERT) wykorzystują dwukierunkowe wstępne trenowanie na ogromnych, nieoznakowanych korpusach, ucząc się uniwersalnych reprezentacji językowych, które odzwierciedlają zarówno składnię, jak i semantykę, zanim zostaną dostrojone do NER z użyciem stosunkowo niewielkich zbiorów oznaczonych danych. Paradygmat pre-train & fine-tune jest szczególnie skuteczny dla rozpoznawania bytów: modele trenowane na miliardach tokenów rozwijają solidne reprezentacje struktury języka i wzorców bytów, które można dopasować do konkretnych domen już przy tysiącach oznaczonych przykładów, drastycznie zmniejszając zapotrzebowanie na dane w porównaniu do treningu od zera. Transformatory doskonale radzą sobie z rozumieniem bytów dzięki mechanizmowi wielogłowej uwagi, umożliwiającemu specjalizację różnych głów w różne typy relacji—jedne skupiają się na granicach składniowych, inne na powiązaniach semantycznych między bytami i kontekstem. Wielojęzyczne rozpoznawanie bytów zostało zrewolucjonizowane przez modele takie jak mBERT i XLM-RoBERTa, trenowane na ponad 100 językach jednocześnie, co umożliwia zero-shot i few-shot transfer do niskozasobowych języków oraz powiązywanie bytów międzyjęzykowych. Nowe modele, takie jak GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition), idą jeszcze dalej, umożliwiając rozpoznawanie bytów na podstawie instrukcji w języku naturalnym, bez potrzeby dostrajania zadaniowego, co stanowi krok w stronę bardziej elastycznych i generalizujących systemów rozumienia bytów.
Wyzwania w Zrozumieniu Bytów
Pomimo ogromnych postępów, systemy rozpoznawania bytów nadal napotykają poważne wyzwania praktyczne, z których niejednoznaczność i wrażliwość na kontekst należą do najbardziej uporczywych—słowo “Apple” wymaga zrozumienia, czy chodzi o owoc, czy firmę technologiczną na podstawie otoczenia, a nawet najnowocześniejsze modele mają z tym trudności w szumie lub niejednoznacznym tekście. Byty spoza słownika (OOV) to kolejne wyzwanie: modele trenowane na standardowych zbiorach mogą nigdy nie napotkać rzadkich bytów, nazw własnych z nowych dziedzin czy błędnie zapisanych wariantów, przez co mogą je błędnie klasyfikować lub całkowicie pomijać. Adaptacja do domeny pozostaje problematyczna, ponieważ modele trenowane na tekstach prasowych (np. CoNLL-2003) słabo radzą sobie w tekstach biomedycznych, prawnych czy z mediów społecznościowych, gdzie rozkłady bytów i wzorce językowe są zupełnie inne, wymagając kosztownej ponownej anotacji i dostrojenia dla każdej nowej domeny. Błędy w detekcji granic—gdy system poprawnie wykrywa obecność bytu, ale błędnie określa jego początek lub koniec—są szczególnie częste przy bytach wielowyrazowych i zagnieżdżonych, jak rozróżnianie “Nowy Jork” od “Nowy Jork City” czy obsługa bytów typu “Chief Executive Officer of Apple Inc.” Złożoności wielojęzyczne pogłębiają te wyzwania, bo różne języki mają inne konwencje kapitalizacji, morfologię i wzorce nazw, przez co modele trenowane na angielskim często zawodzą w innych językach. Niedobór danych w dziedzinach niszowych (np. rzadkie choroby, nowe technologie, terminologia firmowa) stanowi wąskie gardło, gdy koszt manualnej anotacji jest zaporowy, a praktycy muszą wybierać między niższą skutecznością a dużą inwestycją w zbieranie danych branżowych.
Praktyczne Zastosowania i Przykłady Użycia
Zrozumienie bytów stało się niezbędne w wielu branżach, zmieniając sposób, w jaki organizacje wydobywają wartość z nieustrukturyzowanego tekstu. W ekstrakcji informacji i budowie grafów wiedzy rozpoznawanie bytów umożliwia automatyczne wypełnianie baz danych na podstawie dokumentów, napędzając wyszukiwarki i systemy rekomendacyjne rozumiejące relacje między osobami, miejscami i pojęciami. Organizacje zdrowotne wykorzystują rozumienie bytów do identyfikacji nazw leków, dawek, objawów i danych demograficznych pacjentów z notatek klinicznych, poprawiając wspomaganie decyzji i umożliwiając systemom farmakowigilancji wykrywanie niepożądanych interakcji leków na dużą skalę. Instytucje finansowe stosują rozpoznawanie bytów do wydobywania symboli giełdowych, wartości pieniężnych i wydarzeń rynkowych z serwisów informacyjnych i raportów finansowych, umożliwiając systemom handlu algorytmicznego i platformom zarządzania ryzykiem szybkie reagowanie na istotne informacje. Firmy technologii prawnej wykorzystują rozumienie bytów do automatycznej identyfikacji stron, dat, zobowiązań i klauzul odpowiedzialności w umowach, skracając czas przeglądu dokumentów z tygodni do godzin. Obsługa klienta i platformy chatbotowe stosują rozpoznawanie bytów do ekstrakcji intencji użytkownika i kontekstu—takiego jak numery zamówień, nazwy produktów i typy zgłoszeń—umożliwiając precyzyjne kierowanie i szybszą obsługę. Platformy e-commerce wykorzystują rozumienie bytów do identyfikacji nazw produktów, marek, cech i specyfikacji w recenzjach klientów i zapytaniach wyszukiwania, poprawiając odkrywanie produktów i personalizację. Systemy rekomendacji treści używają rozpoznawania bytów do analizy, z jakimi bytami użytkownicy wchodzą w interakcje, umożliwiając bardziej zaawansowane filtrowanie i rekomendacje, które zwiększają zaangażowanie i przychody.
Wdrażanie Systemów Rozumienia Bytów
Implementacja systemu rozumienia bytów na poziomie produkcyjnym wymaga starannego przygotowania danych, wyboru modelu i ewaluacji. Zacznij od wysokiej jakości danych anotowanych: ustal jasne definicje typów bytów, używaj miar zgodności między anotatorami dla spójności i dąż do minimum 500-1000 oznaczonych przykładów na typ bytu, choć w specyficznych domenach potrzeba ich więcej. Wybór modelu zależy od ograniczeń: systemy oparte na regułach zapewniają interpretowalność i niskie opóźnienia w jasno zdefiniowanych domenach, klasyczne modele ML (CRF, SVM) oferują dobre wyniki przy umiarkowanej ilości danych, a modele transformerowe (BERT, RoBERTa) dają najlepszą skuteczność, lecz wymagają więcej zasobów. Strategie treningu i dostrajania powinny obejmować augmentację danych dla zrównoważenia klas, walidację krzyżową dla uniknięcia przeuczenia i staranną regulację hiperparametrów (learning rate, batch size). Oceń system przez precyzję (prawidłowo rozpoznane byty), recall (wykryte byty spośród wszystkich rzeczywistych) i F1 (harmoniczna średnia obu), z osobnymi metrykami dla każdego typu bytu, by zidentyfikować słabsze miejsca. Wdrożenie wymaga uwzględnienia wymagań dotyczących opóźnień (przetwarzanie wsadowe vs. w czasie rzeczywistym), skalowalności i integracji z istniejącymi pipeline’ami, a monitoring po wdrożeniu powinien śledzić dryf skuteczności, fałszywie pozytywne i opinię użytkowników, by uruchamiać cykle retreningu.
Narzędzia i Frameworki do Rozpoznawania Bytów
Ekosystem narzędzi do rozumienia bytów oferuje rozwiązania dla każdego celu i skali. Biblioteki open-source jak spaCy dają gotowe pipeline’y NER o wysokiej skuteczności (89,22% F1 na standardowych benchmarkach) i świetnej dokumentacji, idealne dla zespołów z wiedzą ML; NLTK nadaje się do nauki i podstawowych zastosowań NER; Hugging Face Transformers daje dostęp do najnowocześniejszych modeli pretrenowanych, które można łatwo dostroić do własnej domeny. Chmurowe usługi zarządzane eliminują potrzeby infrastrukturalne: Google Cloud Natural Language API, AWS Comprehend i IBM Watson NLP oferują gotowe rozpoznawanie bytów z obsługą wielu języków i typów, automatycznie skalują się i łatwo integrują z pipeline’ami w chmurze. Specjalistyczne frameworki jak Flair (oparty na PyTorch, świetny do etykietowania sekwencji) i DeepPavlov (pretrenowane modele dla wielu języków i domen) są dla badaczy i zespołów potrzebujących większej elastyczności niż ogólne biblioteki. Wybór między rozwiązaniami własnymi a gotowymi zależy od wrażliwości danych (on-premise vs. chmura), wymaganej skuteczności, specyfiki domeny i kompetencji zespołu: korzystaj z API dla zastosowań ogólnych, open-source dla personalizacji na danych wewnętrznych, a własne modele buduj tylko wtedy, gdy inne nie spełniają wymagań skuteczności lub opóźnień.
Przyszłe Trendy w Zrozumieniu Bytów
Przyszłość rozumienia bytów kształtują duże modele językowe zapewniające niespotykaną elastyczność i skuteczność. Modele takie jak GPT-4 i Claude wykazują imponujące zdolności few-shot i zero-shot w rozpoznawaniu bytów, umożliwiając identyfikację własnych typów bytów na podstawie kilku przykładów lub nawet opisu w języku naturalnym, znacząco zmniejszając koszty anotacji i przyspieszając wdrożenia. Multimodalne rozumienie bytów to kolejny przełom—łączenie tekstu, obrazów i danych strukturalnych do rozpoznawania bytów w dokumentach, fakturach czy stronach internetowych z bogatszym kontekstem, co umożliwia automatyczne przetwarzanie dokumentów czy wyszukiwanie wizualne. Postępy w przetwarzaniu w czasie rzeczywistym dzięki destylacji modeli i wdrożeniom brzegowym czynią zaawansowane rozpoznawanie bytów możliwym na urządzeniach mobilnych i IoT, otwierając nowe zastosowania w AR, tłumaczeniach na żywo czy systemach autonomicznych. Specjalistyczne dostrajanie do domen tworzy modele dedykowane biomedycynie, prawu czy finansom, które przewyższają ogólne modele, a techniki pre-treningu domenowego i transfer learning czynią to coraz bardziej dostępne. Wraz z dojrzewaniem tych technologii rozumienie bytów stanie się niewidoczną warstwą bazową systemów AI, umożliwiającą maszynom rozumienie świata na poziomie zbliżonym do ludzkiego i otwierającą zupełnie nowe możliwości.
Dlaczego Zrozumienie Bytów Jest Ważne dla Monitoringu AI
Wraz z coraz szerszą integracją systemów AI takich jak ChatGPT, Perplexity czy Google AI Overviews w proces odkrywania i konsumpcji informacji, zrozumienie, jak te systemy rozpoznają i odnoszą się do bytów—including your brand—nabiera kluczowego znaczenia. Rozumienie bytów to mechanizm, dzięki któremu systemy AI identyfikują i przetwarzają wzmianki o firmach, produktach, osobach i pojęciach. Monitorując, jak AI rozumie i odnosi się do Twojej marki przez rozpoznawanie bytów, zyskujesz wgląd w:
Jak Twoja marka jest kategoryzowana w systemach AI (jako firma, produkt, pojęcie)
Jaki kontekst AI kojarzy z Twoją marką
Jak precyzyjnie AI odróżnia Twoją markę od konkurencji
Jakie byty są często wzmiankowane razem z Twoją marką
To właśnie monitoruje AmICited—śledzi, jak systemy AI rozpoznają i odnoszą się do Twojej marki jako bytu w wielu platformach AI. Rozumiejąc rozpoznawanie bytów, lepiej zrozumiesz, jak systemy AI postrzegają i komunikują się o Twoim biznesie.
Najczęściej zadawane pytania
Jaka jest różnica między rozpoznawaniem bytów a ich powiązywaniem (entity linking)?
Rozpoznawanie bytów (NER) identyfikuje i klasyfikuje byty w tekście (np. 'Apple' jako ORGANIZACJA), podczas gdy powiązywanie bytów łączy te byty z bazami wiedzy lub referencjami kanonicznymi (np. powiązanie 'Apple' ze stroną Wikipedii firmy Apple Inc.). Rozpoznawanie bytów to pierwszy krok; powiązywanie bytów dodaje semantyczne zakotwiczenie.
Jak dokładne są współczesne systemy rozpoznawania bytów?
Nowoczesne modele oparte na transformerach, takie jak BERT, osiągają 90,9% F1 na standardowych benchmarkach, takich jak CoNLL-2003. Jednak dokładność znacznie się różni w zależności od domeny—modele trenowane na wiadomościach słabo radzą sobie z tekstami biomedycznymi lub z mediów społecznościowych. Rzeczywista skuteczność zależy silnie od adaptacji do domeny i jakości danych.
Czy rozpoznawanie bytów działa w wielu językach?
Tak, modele wielojęzyczne, takie jak mBERT i XLM-RoBERTa obsługują jednocześnie ponad 100 języków. Jednak skuteczność różni się w zależności od języka ze względu na różnice w konwencjach kapitalizacji, morfologii i dostępności danych treningowych. Modele dedykowane pod konkretne języki zazwyczaj przewyższają wielojęzyczne w krytycznych zastosowaniach.
Czym różni się rozpoznawanie bytów oparte na regułach od tego opartego na ML?
Systemy oparte na regułach używają ręcznie tworzonych wzorców i słowników (szybkie, interpretowalne, lecz kruche). Systemy oparte na ML uczą się na oznaczonych danych (bardziej elastyczne, lepiej generalizują, lecz wymagają danych treningowych i inżynierii cech). Nowoczesne podejścia deep learning automatyzują ekstrakcję cech, osiągając wyższą skuteczność.
Ile danych treningowych potrzeba do niestandardowego rozpoznawania bytów?
Systemy oparte na regułach wymagają jedynie definicji wzorców. Tradycyjne modele ML potrzebują 300-500 oznaczonych przykładów. Modele oparte na transformerach działają już przy 800+ przykładach, lecz korzystają z transfer learning—wstępnie wytrenowane modele mogą osiągać dobre wyniki przy 100-200 przykładach z danej domeny po dostrojeniu.
Jakie są główne wyzwania w zrozumieniu bytów?
Kluczowe wyzwania to: niejednoznaczność (to samo słowo oznacza różne rzeczy), byty spoza słownika, adaptacja do domeny (modele trenowane w jednej domenie zawodzą w innej), błędy w wykrywaniu granic, złożoności wielojęzyczne oraz niedobór danych dla wyspecjalizowanych dziedzin. Wymaga to przemyślanej architektury i dostrojenia do domeny.
Jak kontekst wpływa na skuteczność rozpoznawania bytów?
Kontekst jest kluczowy—'bank' oznacza co innego w 'river bank' i 'savings bank'. Nowoczesne transformatory używają mechanizmu samo-uwagi (self-attention), by ważyć kontekst wszystkich otaczających tokenów, umożliwiając rozróżnianie bytów na podstawie kontekstu językowego i semantycznego. Słabe radzenie sobie z kontekstem to istotne źródło błędów w rozpoznawaniu bytów.
Jaka jest przyszłość zrozumienia bytów w AI?
Przyszłość to: duże modele językowe umożliwiające rozpoznawanie bytów bez etykiet (zero-shot), rozumienie multimodalne łączące tekst i obrazy, przetwarzanie w czasie rzeczywistym na urządzeniach brzegowych oraz postępy w dostrajaniu do domen. Zrozumienie bytów stanie się niewidoczną warstwą bazową, umożliwiającą maszynom pojmowanie świata na poziomie zbliżonym do ludzkiego.
Monitoruj, Jak AI Odnosi się do Twojej Marki
AmICited śledzi wzmianki o bytach w systemach AI takich jak ChatGPT, Perplexity i Google AI Overviews. Zrozum, jak AI rozumie i odnosi się do Twojej marki w czasie rzeczywistym.
Jak systemy AI rozumieją byty i relacje? Próba optymalizacji pod tym kątem
Dyskusja społeczności na temat tego, jak systemy AI rozumieją byty i relacje. Praktyczne wskazówki dotyczące optymalizacji bytów dla lepszej widoczności w AI i ...
Unikanie sygnałów wykrywania AI: Pisanie autentycznych treści, które są cytowane
Dowiedz się, jak pisać autentyczne treści, które unikają wykrycia przez AI, korzystając jednocześnie z narzędzi AI w odpowiedzialny sposób. Poznaj sygnały, na k...
Rozpoznawanie encji to funkcja AI NLP, która identyfikuje i kategoryzuje nazwy własne w tekście. Dowiedz się, jak to działa, o jego zastosowaniach w monitoringu...
10 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.