Treningowe crawlery AI vs. crawlery wyszukiwarek: Zrozum różnicę
Odkryj kluczowe różnice między crawlerami treningowymi AI a crawlerami wyszukiwarek. Dowiedz się, jak wpływają na widoczność Twoich treści, strategie optymalizacji i cytowania przez AI.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Crawlery wyszukiwarek, takie jak Googlebot i Bingbot, stanowią podstawę działania tradycyjnych wyszukiwarek internetowych. Te automatyczne boty systematycznie przeszukują internet, odkrywając i indeksując treści, aby decydować, co pojawi się na stronach wyników wyszukiwania (SERP). Najbardziej znanym i aktywnym crawlerem jest Googlebot (Google), następnie Bingbot (Microsoft) i YandexBot (Yandex). Crawlery te mają zaawansowane możliwości – potrafią wykonywać JavaScript, renderować dynamiczne treści i rozumieć złożone struktury stron. Odwiedzają witryny często, w zależności od autorytetu strony, aktualności treści i historii aktualizacji – witryny o wysokim autorytecie są przeszukiwane częściej. Głównym celem crawlerów wyszukiwarek jest indeksacja treści pod kątem pozycji, czyli ocena stron pod względem trafności, jakości i sygnałów doświadczenia użytkownika.
Typ crawlera
Główny cel
Obsługa JavaScript
Częstotliwość wizyt
Cel
Googlebot
Indeksacja pod pozycje w wyszukiwarce
Tak (z ograniczeniami)
Często, według autorytetu
Pozycjonowanie i widoczność
Bingbot
Indeksacja pod pozycje w wyszukiwarce
Tak (z ograniczeniami)
Regularnie, według aktualizacji
Pozycjonowanie i widoczność
YandexBot
Indeksacja pod pozycje w wyszukiwarce
Tak (z ograniczeniami)
Regularnie, według sygnałów
Pozycjonowanie i widoczność
Czym są treningowe crawlery AI?
Treningowe crawlery AI to zupełnie inna kategoria botów sieciowych, których zadaniem jest zbieranie danych do trenowania dużych modeli językowych (LLM), a nie do indeksacji pod wyszukiwanie. Najbardziej znanym crawlerem treningowym AI jest GPTBot (OpenAI), a także ClaudeBot (Anthropic), PetalBot (Huawei) oraz CCBot (Common Crawl). W przeciwieństwie do crawlerów wyszukiwarek, których celem jest pozycjonowanie treści, crawlery AI koncentrują się na gromadzeniu wysokiej jakości, bogatych kontekstowo informacji, aby ulepszać bazę wiedzy i możliwości generowania odpowiedzi przez modele AI. Crawlery te działają rzadziej niż crawlery wyszukiwarek – odwiedzają stronę zwykle raz na kilka tygodni lub miesięcy, priorytetowo traktując jakość treści, a nie ilość. To rozróżnienie jest kluczowe: Twoje treści mogą być dokładnie zindeksowane przez Googlebota pod kątem widoczności w wyszukiwarce, ale tylko częściowo lub sporadycznie pobrane przez GPTBota do treningu modeli AI.
Techniczne różnice między crawlerami wyszukiwarek a treningowymi crawlerami AI mają istotny wpływ na widoczność treści. Najważniejsza z nich to wykonywanie JavaScriptu: crawlery wyszukiwarek, takie jak Googlebot, potrafią wykonywać JavaScript (choć z ograniczeniami), co umożliwia im widzenie treści generowanych dynamicznie. Treningowe crawlery AI natomiast w ogóle nie wykonują JavaScriptu – analizują jedynie surowy HTML dostępny przy pierwszym załadowaniu strony. Oznacza to, że treści ładowane dynamicznie przez skrypty po stronie klienta są dla nich zupełnie niewidoczne. Ponadto crawlery wyszukiwarek respektują budżety indeksowania i priorytetyzują strony na podstawie architektury i linkowania wewnętrznego, podczas gdy crawlery AI stosują selektywne, jakościowe podejście. Crawlery wyszukiwarek generalnie ściśle przestrzegają wytycznych robots.txt, natomiast niektóre crawlery AI historycznie były mniej transparentne w tym zakresie. Częstotliwość wizyt również się różni: crawlery wyszukiwarek odwiedzają aktywne strony kilka razy w tygodniu lub nawet codziennie, podczas gdy crawlery AI jedynie raz na kilka tygodni lub miesięcy. Dodatkowo crawlery wyszukiwarek rozpoznają sygnały rankingowe i metryki UX, a crawlery AI koncentrują się na pobieraniu czystych, dobrze ustrukturyzowanych tekstów do uczenia modeli.
Cecha
Crawlery wyszukiwarek
Crawlery treningowe AI
Wykonywanie JavaScript
Tak (z ograniczeniami)
Nie
Częstotliwość wizyt
Wysoka (kilka razy w tygodniu)
Niska (raz na kilka tygodni)
Analiza treści
Pełne renderowanie strony
Tylko surowy HTML
Przestrzeganie robots.txt
Ścisłe
Zmienna
Priorytety indeksowania
Według autorytetu
Selekcja wg jakości
Obsługa treści dynamicznej
Może renderować i indeksować
Całkowicie omija
Główny cel
Pozycjonowanie i widoczność w wyszukiwarce
Zbieranie danych treningowych
Tolerancja na timeout
Dłuższa (umożliwia złożone renderowanie)
Krótka (1-5 sekund)
Problem z JavaScriptem
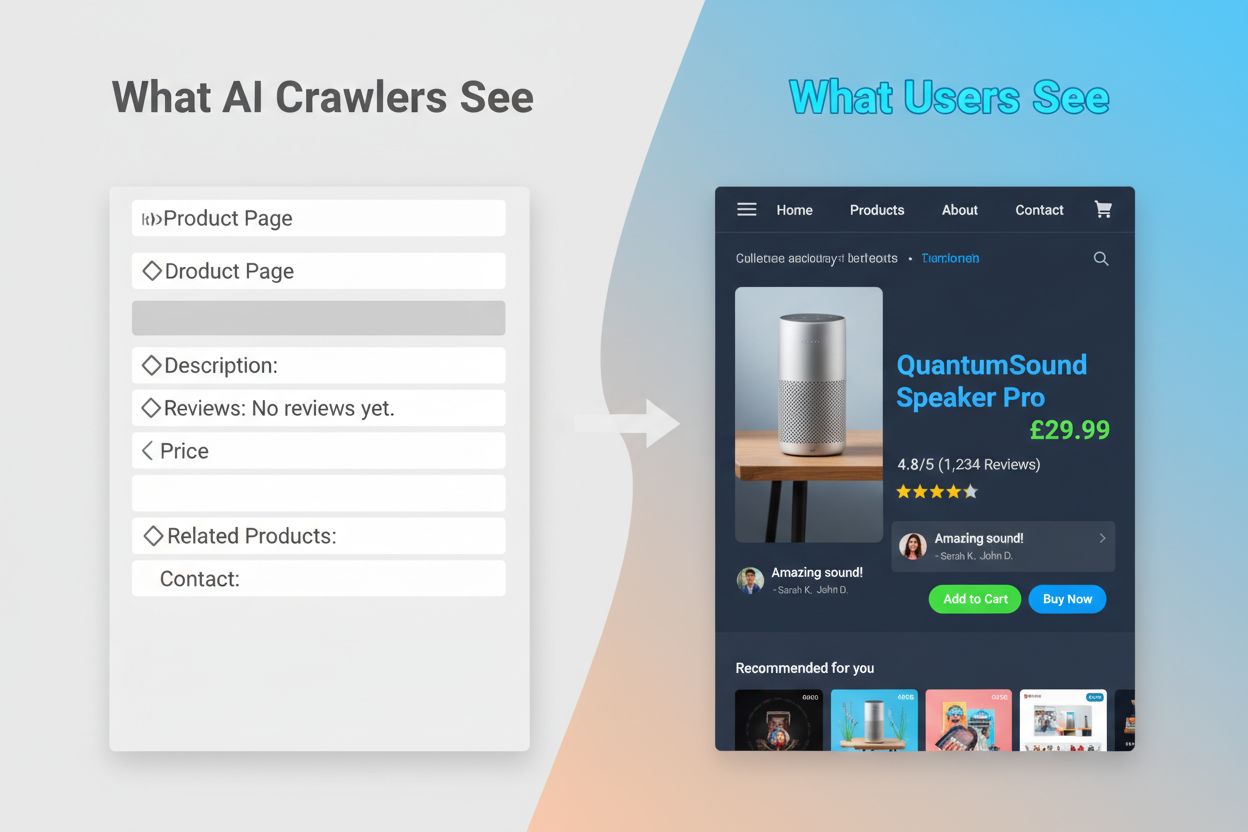
Nieumiejętność wykonywania JavaScriptu przez crawlery AI powoduje poważną lukę w widoczności, która dotyka wiele nowoczesnych stron. Gdy strona wykorzystuje JavaScript do dynamicznego ładowania treści – takich jak opisy produktów, opinie klientów, informacje o cenach czy obrazy – te treści stają się dla crawlerów AI niewidoczne. Jest to szczególnie problematyczne w przypadku aplikacji jednostronicowych (SPA) opartych na React, Vue lub Angular, gdzie większość treści ładowana jest po stronie klienta po pierwszym załadowaniu HTML. Przykładowo, sklep internetowy może prezentować dostępność i ceny produktów przez JavaScript – dla GPTBota widoczna będzie jedynie pusta strona lub szkielet HTML. Podobnie witryny korzystające z leniwego ładowania obrazów lub nieskończonego scrollowania będą miały te elementy całkowicie pominięte przez crawlery AI. Skutki biznesowe są poważne: jeśli szczegóły produktów, referencje klientów czy kluczowe treści są ukryte za JavaScriptem, systemy AI (np. ChatGPT, Perplexity) nie będą miały do nich dostępu przy generowaniu odpowiedzi. To oznacza, że możesz mieć wysoką pozycję w Google, a jednocześnie być całkowicie nieobecnym w odpowiedziach generowanych przez AI – stając się niewidocznym dla rosnącej grupy użytkowników korzystających z AI do wyszukiwania informacji.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Crawlery wyszukiwarek vs crawlery AI: praktyczne konsekwencje
Praktyczne konsekwencje tych różnic technicznych są głębokie i często niedoceniane przez właścicieli stron. Twoja witryna może mieć znakomite pozycje w Google, a jednocześnie być niemal niewidoczna dla ChatGPT, Perplexity i innych systemów AI. Powoduje to paradoks, w którym tradycyjny sukces SEO nie gwarantuje widoczności w AI. Gdy użytkownicy pytają ChatGPT o Twoją branżę lub produkty, system AI może cytować Twoją konkurencję, ponieważ ich treści były bardziej dostępne dla crawlerów AI. Związek między danymi treningowymi a cytowaniami wyszukiwarek dodaje kolejny poziom złożoności: treści użyte do uczenia modelu AI mogą być faworyzowane w jego wynikach, co oznacza, że blokowanie crawlerów AI może ograniczyć Twoją widoczność w odpowiedziach generowanych przez AI. Dla wydawców i twórców treści decyzja o dopuszczeniu lub blokowaniu crawlerów AI ma realny wpływ na przyszły ruch. Strona, która blokuje GPTBota, by chronić treści przed wykorzystaniem do treningu, może jednocześnie ograniczyć swoje szanse na pojawienie się w wynikach ChatGPT. Z drugiej strony, udostępnienie treści crawlerom AI zapewnia dane do treningu, ale nie gwarantuje cytowań ani ruchu – to prawdziwy dylemat strategiczny bez idealnego rozwiązania.
Monitorowanie i identyfikacja aktywności crawlerów
Zrozumienie, które crawlery odwiedzają Twoją stronę i jak często to robią, jest kluczowe dla optymalizacji strategii contentowej. Analiza plików logów to podstawowa metoda identyfikacji aktywności crawlerów – pozwala segmentować i analizować logi serwera, aby zobaczyć, które boty odwiedziły witrynę, jak często oraz które strony preferowały. Analizując ciągi User-Agent w logach serwera, możesz rozróżnić Googlebota, GPTBota, OAI-SearchBota i inne crawlery, uzyskując wgląd w ich zachowanie. Kluczowe metryki do monitorowania to częstotliwość wizyt (jak często dany crawler odwiedza stronę), głębokość indeksowania (ile poziomów struktury strony jest przeszukiwanych) oraz budżet indeksowania (ile stron jest przeszukiwanych w danym czasie). Narzędzia takie jak Google Search Console i Bing Webmaster Tools dają wgląd w aktywność crawlerów wyszukiwarek, a wyspecjalizowane rozwiązania, takie jak AmICited.com, umożliwiają kompleksowe monitorowanie aktywności crawlerów AI na wielu platformach, w tym ChatGPT, Perplexity i Google AI Overviews. AmICited.com śledzi, jak systemy AI cytują Twoją markę i treści, zapewniając wgląd, które platformy AI cytują Cię i jak często. Poznanie tych wzorców pozwala wcześnie wykryć problemy techniczne, zoptymalizować alokację budżetu indeksowania i podejmować świadome decyzje dotyczące dostępu crawlerów i optymalizacji treści.
Strategie optymalizacji dla crawlerów wyszukiwarek
Optymalizacja pod tradycyjne crawlery wyszukiwarek wymaga skupienia się na sprawdzonych podstawach technicznego SEO, które zapewniają wykrywalność i indeksowalność treści. Kluczowe strategie to:
Popraw crawlability poprzez czytelną strukturę linkowania wewnętrznego, eliminację niedziałających linków i unikanie osieroconych stron, do których boty nie mają dostępu
Przesyłanie map XML do wyszukiwarek, by skierować crawlery do najważniejszych treści i zapewnić pełną indeksację
Wdrażanie danych strukturalnych (schema markup), by pomóc wyszukiwarkom lepiej rozumieć kontekst i znaczenie treści
Optymalizacja szybkości strony w celu efektywnego przetwarzania przez crawlery bez timeoutów lub pomijania stron
Priorytetyzacja kluczowych treści w architekturze witryny, aby crawlery najpierw trafiały na najcenniejsze strony
Strategiczne użycie robots.txt do blokowania stron o niskiej wartości i zachowania budżetu indeksowania dla priorytetowych treści
Utrzymywanie świeżej, wysokiej jakości treści, sygnalizującej crawlerom, że strona jest aktywna i warta regularnych wizyt
Wyszukiwarki, takie jak Google, coraz większą wagę przywiązują do efektywności crawlów – przedstawiciele Google zapowiadają, że Googlebot będzie w przyszłości crawlować rzadziej. Oznacza to konieczność maksymalnego uproszczenia struktury strony i czytelnej hierarchii linkowania, by crawler szybko docierał do najważniejszych podstron.
Strategie optymalizacji dla treningowych crawlerów AI
Optymalizacja pod crawlery treningowe AI wymaga innego podejścia – tu najważniejsze są jakość treści, ich przejrzystość i dostępność, a nie sygnały rankingowe. Crawlery AI priorytetowo traktują dobrze ustrukturyzowane, bogate kontekstowo treści, więc strategia optymalizacji powinna skupiać się na kompletności i czytelności. Unikaj treści zależnych od JavaScriptu – kluczowe informacje (szczegóły produktów, ceny, opinie, dane) muszą być dostępne w surowym HTML. Twórz treści wyczerpujące, pogłębione, które szeroko omawiają temat i dostarczają kontekstu wartościowego do uczenia modeli AI. Stosuj czytelne formatowanie – nagłówki, listy punktowane i numerowane ułatwiają analizę treści. Pisz jasno, semantycznie, unikając nadmiernego żargonu. Zachowaj poprawną hierarchię nagłówków (H1, H2, H3), by crawlery AI rozumiały strukturę treści. Dodawaj istotne metadane i schema markup dla kontekstu. Dbaj o szybkie ładowanie strony, bo crawlery AI mają krótkie timeouty (zwykle 1–5 sekund) i mogą całkowicie pominąć wolno ładujące się strony.
Kluczowa różnica względem optymalizacji pod wyszukiwarki to fakt, że crawlery AI nie biorą pod uwagę sygnałów rankingowych, linków czy zagęszczenia słów kluczowych. Liczy się przejrzystość, organizacja i bogactwo informacji. Strona, która nie zajmuje wysokiej pozycji w Google, może być bardzo cenna dla modeli AI, jeśli zawiera wyczerpujące i uporządkowane informacje na dany temat.
Przyszłość zarządzania crawlerami
Krajobraz crawleryzacji stron www szybko się zmienia – crawlery AI stają się coraz ważniejsze dla widoczności treści i budowania świadomości marki. W miarę jak narzędzia wyszukiwania oparte na AI, takie jak ChatGPT, Perplexity czy Google AI Overviews, zyskują na popularności, możliwość bycia odnalezionym i cytowanym przez te systemy stanie się równie istotna, co pozycje w tradycyjnych wyszukiwarkach. Różnica między crawlerami treningowymi a crawlerami wyszukiwarek prawdopodobnie stanie się bardziej subtelna – firmy mogą zaoferować wyraźniejsze rozdzielenie zbierania danych i wyszukiwania, podobnie jak OpenAI z GPTBotem i OAI-SearchBotem. Właściciele stron będą musieli opracować strategie łączące tradycyjną optymalizację SEO z widocznością w AI, traktując oba kierunki jako uzupełniające się, a nie konkurencyjne. Rozwój specjalistycznych narzędzi monitorujących ułatwi śledzenie aktywności crawlerów zarówno tradycyjnych, jak i AI, umożliwiając podejmowanie decyzji opartych na danych w zakresie dostępu botów i optymalizacji treści. Ci, którzy już teraz zoptymalizują strony pod oba typy crawlerów, zyskają przewagę konkurencyjną, zwiększając szanse na odkrycie treści różnymi kanałami w miarę ewolucji krajobrazu wyszukiwania. Przyszłość widoczności treści zależy od zrozumienia i optymalizacji pod pełne spektrum crawlerów, które odnajdują i wykorzystują Twoje treści.
Najczęściej zadawane pytania
Jaka jest główna różnica między crawlerami wyszukiwarek a crawlerami treningowymi AI?
Crawlery wyszukiwarek, takie jak Googlebot, indeksują treści pod kątem pozycji w wynikach wyszukiwania i potrafią wykonywać JavaScript, by zobaczyć treści dynamiczne. Crawlery treningowe AI, takie jak GPTBot, zbierają dane do trenowania dużych modeli językowych i zazwyczaj nie wykonują JavaScriptu, przez co omijają dynamicznie ładowane treści. Ta podstawowa różnica oznacza, że Twoja strona może mieć wysoką pozycję w Google, a jednocześnie być prawie niewidoczna dla ChatGPT.
Czy mogę zablokować crawlery treningowe AI bez wpływu na pozycje w wyszukiwarce?
Tak, możesz użyć robots.txt, aby zablokować konkretne crawlery AI, takie jak GPTBot, jednocześnie pozwalając crawlerom wyszukiwarek na dostęp. Może to jednak ograniczyć widoczność Twoich treści w odpowiedziach i podsumowaniach generowanych przez AI. Wybór należy od tego, czy bardziej zależy Ci na ochronie treści, czy na potencjalnym ruchu z AI.
Dlaczego crawlery AI nie widzą moich treści ładowanych przez JavaScript?
Crawlery AI, takie jak GPTBot, analizują tylko surowy HTML wyświetlany przy pierwszym załadowaniu strony i nie wykonują JavaScriptu. Treści ładowane dynamicznie przez skrypty — jak szczegóły produktów, opinie czy obrazy — są dla nich całkowicie niewidoczne. To istotne ograniczenie dla nowoczesnych stron korzystających z renderowania po stronie klienta.
Jak często crawlery treningowe AI odwiedzają moją stronę?
Crawlery treningowe AI odwiedzają strony rzadziej niż crawlery wyszukiwarek, z dłuższymi przerwami między wizytami. Priorytetowo traktują treści o wysokim autorytecie i mogą indeksować stronę tylko raz na kilka tygodni lub miesięcy. Ten rzadki schemat odzwierciedla nacisk na jakość, a nie ilość.
Która treść jest najbardziej narażona na niewidoczność dla crawlerów AI?
Szczegóły produktów, opinie klientów, leniwie ładowane obrazy, elementy interaktywne (zakładki, karuzele, okna modalne), informacje o cenach oraz wszelkie treści ukryte za JavaScriptem są najbardziej narażone. W przypadku sklepów internetowych i stron typu SPA może to stanowić znaczną część kluczowych treści.
Jak zoptymalizować stronę zarówno pod crawlery wyszukiwarek, jak i AI?
Zadbaj, aby kluczowe treści były obecne w surowym HTML, popraw szybkość strony, stosuj przejrzystą strukturę z odpowiednią hierarchią nagłówków, wdrażaj schema markup i unikaj krytycznych treści zależnych od JavaScript. Celem jest uczynienie treści dostępnymi zarówno dla tradycyjnych, jak i AI-crawlerów.
Jakie narzędzia pomogą mi monitorować aktywność crawlerów na stronie?
Narzędzia do analizy logów, Google Search Console, Bing Webmaster Tools oraz wyspecjalizowane systemy monitoringu crawlerów, takie jak AmICited.com, pomagają śledzić zachowanie botów. AmICited.com monitoruje, jak systemy AI odnoszą się do Twojej marki w ChatGPT, Perplexity i Google AI Overviews.
Czy blokowanie crawlerów AI zaszkodzi mojemu ruchowi z AI?
Potencjalnie tak. Blokowanie crawlerów treningowych może chronić Twoje treści, ale może też ograniczyć ich widoczność w wynikach i podsumowaniach napędzanych przez AI. Dodatkowo, treści, które zostały zindeksowane przed blokadą, pozostają w wytrenowanych modelach. Decyzja wymaga wyważenia ochrony treści i potencjalnej utraty ruchu z AI.
Monitoruj aktywność crawlerów AI z AmICited
Śledź, jak systemy AI odnoszą się do Twojej marki w ChatGPT, Perplexity i Google AI Overviews. Uzyskaj wgląd w czasie rzeczywistym w swoją widoczność w AI i optymalizuj strategię contentową.
Jak zidentyfikować crawlery AI w logach serwera: Kompletny przewodnik po wykrywaniu
Dowiedz się, jak identyfikować i monitorować crawlery AI takie jak GPTBot, PerplexityBot i ClaudeBot w logach serwera. Poznaj ciągi user-agent, metody weryfikac...
Jakim Crawlerom AI Pozwolić na Dostęp? Kompletny Przewodnik na 2025
Dowiedz się, którym crawlerom AI pozwolić, a które zablokować w swoim pliku robots.txt. Kompleksowy przewodnik obejmujący GPTBot, ClaudeBot, PerplexityBot oraz ...
Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...
12 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.