
Kompletny przewodnik blokowania (lub zezwalania) na roboty AI
Dowiedz się, jak blokować lub zezwalać robotom AI, takim jak GPTBot i ClaudeBot, za pomocą robots.txt, blokowania na poziomie serwera oraz zaawansowanych metod ...
7 min czytania
Dowiedz się, jak wdrożyć selektywne blokowanie robotów AI, by chronić swoje treści przed botami treningowymi, jednocześnie utrzymując widoczność w wynikach wyszukiwarek AI. Strategie techniczne dla wydawców.
Wydawcy stoją dziś przed niemożliwym wyborem: zablokować wszystkie roboty AI i utracić cenny ruch z wyszukiwarek, albo dopuścić je wszystkie i patrzeć, jak ich treści zasilają zbiory treningowe bez rekompensaty. Rozwój generatywnej AI stworzył podzielony ekosystem robotów, gdzie te same reguły robots.txt stosuje się bez rozróżnienia zarówno do wyszukiwarek napędzających przychody, jak i robotów treningowych wyciągających wartość. Ten paradoks zmusił świadomych wydawców do opracowania strategii selektywnej kontroli robotów, które rozróżniają różne typy botów AI w oparciu o ich realny wpływ na wskaźniki biznesowe.
Krajobraz robotów AI dzieli się na dwie odrębne kategorie, o zupełnie różnych celach i skutkach biznesowych. Roboty treningowe — obsługiwane przez firmy takie jak OpenAI, Anthropic i Google — służą do pobierania ogromnych ilości tekstu w celu budowania i ulepszania dużych modeli językowych, natomiast roboty wyszukiwarkowe indeksują treści do późniejszego wyszukiwania i odkrywania. Roboty treningowe odpowiadają za około 80% całej aktywności botów AI, a mimo to nie generują wydawcom żadnych bezpośrednich przychodów, podczas gdy roboty wyszukiwarkowe, jak Googlebot czy Bingbot, dostarczają miliony wizyt i wyświetleń reklam rocznie. Rozróżnienie to jest istotne, bo pojedynczy robot treningowy może zużyć tyle transferu, co tysiące użytkowników, podczas gdy roboty wyszukiwarkowe są zoptymalizowane pod kątem wydajności i zwykle respektują limity.
| Nazwa robota | Operator | Główne zastosowanie | Potencjał ruchu |
|---|---|---|---|
| GPTBot | OpenAI | Trening modeli | Brak (ekstrakcja danych) |
| Claude Web Crawler | Anthropic | Trening modeli | Brak (ekstrakcja danych) |
| Googlebot | Indeksowanie wyszukiwarek | 243,8 mln wizyt (kwiecień 2025) | |
| Bingbot | Microsoft | Indeksowanie wyszukiwarek | 45,2 mln wizyt (kwiecień 2025) |
| Perplexity Bot | Perplexity AI | Wyszukiwanie + trening | 12,1 mln wizyt (kwiecień 2025) |
Dane są jednoznaczne: sam robot ChatGPT wygenerował 243,8 mln wizyt wydawcom w kwietniu 2025, ale te wizyty nie wygenerowały żadnych kliknięć, wyświetleń reklam ani przychodów. Tymczasem ruch Googlebota przekładał się na realne zaangażowanie użytkowników i możliwości monetyzacji. Zrozumienie tej różnicy to pierwszy krok do wdrożenia selektywnej strategii blokowania, która chroni treści, zachowując widoczność w wyszukiwarce.
Całkowite blokowanie wszystkich robotów AI jest ekonomicznie szkodliwe dla większości wydawców. Choć roboty treningowe pozyskują wartość bez rekompensaty, roboty wyszukiwarkowe pozostają jednym z najpewniejszych źródeł ruchu w coraz bardziej rozdrobnionym środowisku cyfrowym. Ekonomiczne uzasadnienie selektywnego blokowania opiera się na kilku kluczowych czynnikach:
Wydawcy wdrażający selektywne blokowanie zgłaszają utrzymanie lub wzrost ruchu z wyszukiwarek przy jednoczesnym ograniczeniu nieautoryzowanej ekstrakcji treści nawet o 85%. Takie podejście uznaje, że nie wszystkie boty AI są sobie równe, a zniuansowana polityka lepiej służy biznesowi niż podejście “spalonej ziemi”.
Plik robots.txt pozostaje podstawowym mechanizmem komunikowania uprawnień dla robotów i jest zaskakująco skuteczny w odróżnianiu typów botów, jeśli jest poprawnie skonfigurowany. Ten prosty plik tekstowy, umieszczony w katalogu głównym strony, wykorzystuje dyrektywy user-agent do określenia, które roboty mają dostęp do jakich treści. Przy selektywnej kontroli robotów AI możesz dopuścić wyszukiwarki, blokując jednocześnie roboty treningowe z chirurgiczną precyzją.
Oto praktyczny przykład blokowania robotów treningowych przy jednoczesnym dopuszczeniu wyszukiwarek:
# Blokowanie GPTBota OpenAI
User-agent: GPTBot
Disallow: /
# Blokowanie Claude crawlera Anthropic
User-agent: Claude-Web
Disallow: /
# Blokowanie innych robotów treningowych
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Zezwalanie wyszukiwarkom
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Takie podejście daje jasne wytyczne dobrze zachowującym się robotom, zachowując jednocześnie widoczność strony w wynikach wyszukiwania. Jednak robots.txt to standard dobrowolny — opiera się na dobrej woli operatorów botów. Wydawcy, którym zależy na przestrzeganiu zasad, potrzebują dodatkowych warstw egzekwowania.
Sam robots.txt nie gwarantuje zgodności, ponieważ około 13% robotów AI całkowicie ignoruje jego dyrektywy — z powodu niedbalstwa lub świadomego obchodzenia zasad. Egzekwowanie na poziomie serwera, za pomocą serwera WWW lub warstwy aplikacji, stanowi techniczną barierę, która uniemożliwia nieautoryzowany dostęp niezależnie od zachowania bota. Takie podejście blokuje żądania już na poziomie HTTP, zanim zużyją one transfer czy zasoby.
Wdrożenie blokowania na poziomie serwera za pomocą Nginx jest proste i bardzo skuteczne:
# W bloku serwera Nginx
location / {
# Blokowanie robotów treningowych na poziomie serwera
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Blokowanie po zakresie IP (dla botów podszywających się pod user-agenta)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Dalsze przetwarzanie żądania
proxy_pass http://backend;
}
Ta konfiguracja zwraca odpowiedź 403 Forbidden dla zablokowanych botów, zużywając minimalne zasoby serwera i jednoznacznie sygnalizując brak dostępu. W połączeniu z robots.txt, egzekwowanie na poziomie serwera tworzy dwuwarstwową ochronę, która obejmuje zarówno zgodnych, jak i nieposłusznych robotów. Wskaźnik obchodzenia blokad z 13% spada praktycznie do zera przy poprawnej konfiguracji na poziomie serwera.
Sieci dostarczania treści (CDN) i zapory aplikacji webowych (WAF) zapewniają dodatkową warstwę egzekwowania, działającą zanim żądania dotrą do serwera źródłowego. Usługi takie jak Cloudflare, Akamai czy AWS WAF pozwalają tworzyć reguły blokujące określone user-agenty lub zakresy IP już na brzegu, uniemożliwiając złośliwym lub niepożądanym botom zużywanie zasobów infrastruktury. Usługi te utrzymują na bieżąco listy znanych adresów IP i user-agentów robotów treningowych, automatycznie je blokując bez potrzeby ręcznej konfiguracji.
Kontrola na poziomie CDN ma kilka zalet względem blokowania na serwerze: zmniejsza obciążenie serwera źródłowego, umożliwia blokowanie geograficzne i oferuje analitykę na żywo dotycząca zablokowanych żądań. Wielu dostawców CDN oferuje dziś specjalne reguły blokowania AI jako standard, odpowiadając na powszechne zaniepokojenie wydawców nieautoryzowanym poborem danych. W przypadku Cloudflare wybranie opcji „Block AI Crawlers” w ustawieniach bezpieczeństwa daje jednoklikową ochronę przed głównymi robotami treningowymi, pozostawiając dostęp dla wyszukiwarek.
Efektywne selektywne blokowanie wymaga systematycznego podejścia do klasyfikowania botów pod kątem ich wpływu biznesowego i wiarygodności. Zamiast traktować wszystkie roboty AI jednakowo, wydawcy powinni wdrożyć trójstopniowy system odzwierciedlający realną wartość i ryzyko związane z każdym botem. Taki framework pozwala na zniuansowane decyzje, równoważąc ochronę treści z korzyściami biznesowymi.
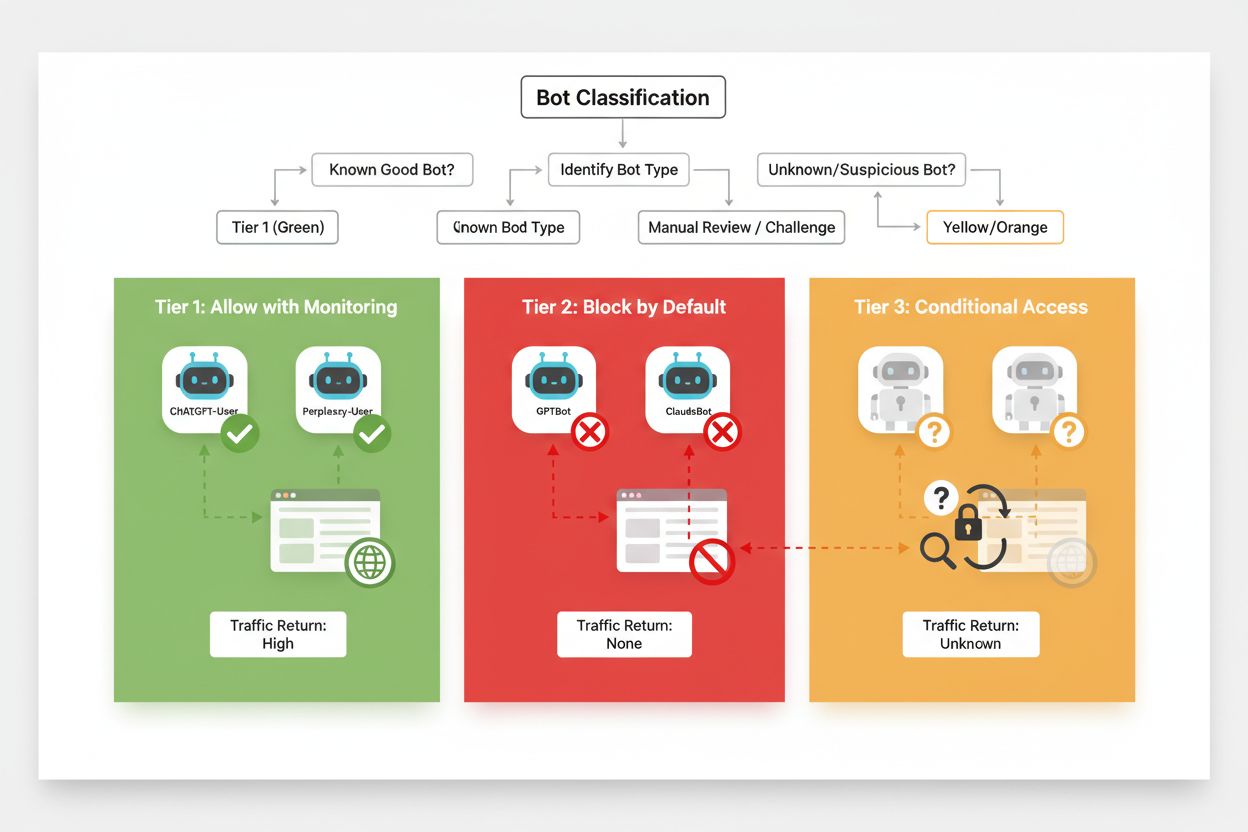
| Poziom | Klasyfikacja | Przykłady | Działanie |
|---|---|---|---|
| Poziom 1: Generatory przychodu | Wyszukiwarki i główne źródła ruchu | Googlebot, Bingbot, Perplexity Bot | Pełny dostęp; optymalizacja pod kątem indeksowania |
| Poziom 2: Neutralne/niepewne | Nowe lub wschodzące boty o niejasnych zamiarach | Mniejsze startupy AI, boty badawcze | Ścisła obserwacja; dopuszczenie z ograniczeniem tempa |
| Poziom 3: Ekstraktory wartości | Boty treningowe bez bezpośredniej korzyści | GPTBot, Claude-Web, CCBot | Całkowita blokada; egzekwowanie na wielu poziomach |
Wdrożenie takiego systemu wymaga ciągłego śledzenia nowych botów i ich modeli biznesowych. Wydawcy powinni regularnie przeglądać logi dostępu, by wykrywać nowe boty, analizować warunki świadczenia usług i polityki wynagradzania operatorów oraz odpowiednio aktualizować klasyfikacje. Bot uznany początkowo za poziom 3 może przejść na poziom 2, jeśli operator zaoferuje podział przychodów, a zaufany dotąd robot może spaść do poziomu 3, jeśli zacznie łamać limity lub ignorować robots.txt.
Selektywne blokowanie to nie konfiguracja typu „ustaw i zapomnij” — wymaga ciągłego monitorowania i dostosowywania wraz z ewolucją ekosystemu robotów. Wydawcy powinni wdrożyć kompleksowe logowanie i analizę, by śledzić, które roboty mają dostęp do treści, ile transferu zużywają i czy respektują ograniczenia. Te dane wspierają strategiczne decyzje, które roboty dopuszczać, blokować lub ograniczać.
Analiza logów dostępu ujawnia wzorce zachowań botów, które pomagają dostosowywać politykę:
# Identyfikacja wszystkich botów AI odwiedzających stronę
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Obliczanie transferu zużywanego przez konkretne roboty
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandwidth: " sum/1024/1024 " MB"}'
# Monitorowanie odpowiedzi 403 dla zablokowanych botów
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Regularna analiza tych danych — najlepiej co tydzień lub miesiąc — pokazuje, czy strategia blokowania działa, czy pojawiły się nowe boty i czy wcześniej zablokowane boty zmieniły zachowanie. Te informacje zasilają system klasyfikacji, zapewniając zgodność polityki z celami biznesowymi i realiami technicznymi.
Wydawcy wdrażający selektywne blokowanie robotów często popełniają błędy, które niweczą strategię lub prowadzą do niezamierzonych skutków. Znajomość tych pułapek pozwala uniknąć kosztownych błędów i od początku wdrożyć skuteczniejszą politykę.
Bezmyślne blokowanie wszystkich botów: Najczęstszy błąd to zbyt szerokie reguły blokujące, które obejmują także wyszukiwarki, niszcząc widoczność w wyszukiwarkach w imię ochrony treści.
Poleganie wyłącznie na robots.txt: Zakładanie, że robots.txt wystarczy do ochrony, ignoruje fakt, że 13% botów go nie respektuje i wciąż wyciąga treści.
Brak monitorowania i dostosowywania: Statyczna polityka blokowania, którą nigdy się nie aktualizuje, prowadzi do przeoczenia nowych botów, braku reakcji na zmiany modeli biznesowych i przypadkowego blokowania korzystnych botów.
Blokowanie wyłącznie po user-agencie: Zaawansowane boty podszywają się pod różne user-agenty lub często je zmieniają, więc blokowanie tylko po user-agencie jest nieskuteczne bez dodatkowych reguł IP i ograniczeń tempa.
Ignorowanie ograniczania tempa (rate limiting): Nawet dopuszczone boty mogą zużyć zbyt dużo transferu, jeśli nie mają narzuconych limitów, pogarszając wydajność dla ludzi i niepotrzebnie obciążając infrastrukturę.
Przyszłość relacji wydawca–roboty AI prawdopodobnie będzie opierać się na bardziej zaawansowanych negocjacjach i modelach wynagradzania, a nie na prostym blokowaniu. Do czasu wypracowania standardów branżowych selektywna kontrola robotów pozostaje najpraktyczniejszym sposobem ochrony treści przy jednoczesnym zachowaniu widoczności w wyszukiwarkach. Wydawcy powinni traktować swoją strategię blokowania jako dynamiczną politykę, ewoluującą wraz z ekosystemem botów, regularnie oceniając, które roboty zasługują na dostęp w oparciu o ich wpływ biznesowy i wiarygodność.
Najskuteczniejsi wydawcy to ci, którzy wdrażają wielowarstwową ochronę — łącząc reguły robots.txt, egzekwowanie na poziomie serwera, kontrolę na poziomie CDN i ciągłe monitorowanie w spójną strategię. Takie podejście chroni zarówno przed zgodnymi, jak i nieprzestrzegającymi zasad botami, zachowując przy tym ruch z wyszukiwarek, który napędza przychody i zaangażowanie użytkowników. W miarę jak firmy AI coraz bardziej doceniają wartość treści wydawców i zaczynają oferować rekompensaty czy licencje, framework zbudowany dziś łatwo dostosuje się do nowych modeli biznesowych, pozwalając utrzymać kontrolę nad cyfrowymi zasobami.
Roboty treningowe, takie jak GPTBot i ClaudeBot, zbierają dane do budowy modeli AI bez przekierowywania ruchu na Twoją stronę. Roboty wyszukiwarkowe, jak OAI-SearchBot czy PerplexityBot, indeksują treści na potrzeby wyszukiwarek AI i mogą generować znaczący ruch powrotny na Twoją stronę. Zrozumienie tej różnicy jest kluczowe dla wdrożenia skutecznej strategii selektywnego blokowania.
Tak, to właśnie sedno selektywnej kontroli robotów. Możesz użyć pliku robots.txt, by zablokować roboty treningowe i dopuścić roboty wyszukiwarkowe, a następnie wymusić to na poziomie serwera dla botów ignorujących robots.txt. Takie podejście chroni Twoje treści przed nieautoryzowanym treningiem, zachowując widoczność w wynikach wyszukiwania AI.
Większość dużych firm AI deklaruje respektowanie robots.txt, lecz jest to dobrowolne. Badania pokazują, że około 13% botów AI całkowicie ignoruje dyrektywy robots.txt. Dlatego egzekwowanie zasad na poziomie serwera jest kluczowe dla wydawców poważnie podchodzących do ochrony swoich treści przed nieprzestrzegającymi zasad robotami.
Znacząco i coraz więcej. ChatGPT wygenerował 243,8 miliona wizyt na 250 stronach newsowych i medialnych w kwietniu 2025 roku, wzrost o 98% względem stycznia. Blokowanie tych robotów oznacza utratę tego nowego źródła ruchu. Dla wielu wydawców ruch z wyszukiwarek AI to już 5-15% całego ruchu poleconego.
Regularnie analizuj logi serwera za pomocą poleceń grep, by zidentyfikować user-agenty botów, śledzić częstotliwość odwiedzin i monitorować przestrzeganie zasad robots.txt. Przeglądaj logi co najmniej raz w miesiącu, by wykryć nowe boty, nietypowe zachowania oraz sprawdzić, czy zablokowane boty faktycznie są blokowane. Te dane pomogą podejmować strategiczne decyzje dotyczące polityki wobec robotów.
Ochronisz swoje treści przed nieautoryzowanym treningiem, ale stracisz widoczność w wynikach AI, przegapisz nowe źródła ruchu i potencjalnie ograniczysz obecność marki w odpowiedziach generowanych przez AI. Wydawcy stosujący całkowite blokady często notują 40-60% spadki widoczności w wyszukiwarkach oraz tracą szanse na odkrycie marki przez platformy AI.
Co najmniej raz w miesiącu, bo ciągle pojawiają się nowe boty, a istniejące zmieniają swoje zachowania. Ekosystem robotów AI zmienia się bardzo szybko — nowi operatorzy uruchamiają roboty, a dotychczasowi łączą się lub zmieniają nazwy. Regularne przeglądy zapewniają zgodność polityki z celami biznesowymi i rzeczywistością techniczną.
To liczba stron przeszukanych w stosunku do liczby odwiedzających odesłanych na Twoją stronę. Anthropic przeszukuje 38 000 stron na jednego odesłanego użytkownika, OpenAI utrzymuje stosunek 1 091:1, a Perplexity 194:1. Niższy wskaźnik oznacza większą wartość z dopuszczenia robota. Ta metryka pomaga decydować, którym robotom warto pozwolić na dostęp, bazując na ich realnym wpływie na biznes.
AmICited śledzi, które platformy AI cytują Twoją markę i treści. Uzyskaj wgląd w swoją widoczność w AI i zadbaj o właściwe przypisanie autorstwa w ChatGPT, Perplexity, Google AI Overviews i innych.
Dowiedz się, jak blokować lub zezwalać robotom AI, takim jak GPTBot i ClaudeBot, za pomocą robots.txt, blokowania na poziomie serwera oraz zaawansowanych metod ...

Dowiedz się, jak podejmować strategiczne decyzje dotyczące blokowania robotów AI. Oceń typ treści, źródła ruchu, modele przychodów i pozycję konkurencyjną dzięk...

Dyskusja społeczności na temat tego, czy pozwolić GPTBot i innym robotom AI na indeksowanie strony. Właściciele stron dzielą się doświadczeniami, wpływem na wid...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.