Jak studia przypadków sprawdzają się w wynikach wyszukiwania AI
Dowiedz się, jak studia przypadków są pozycjonowane w wyszukiwarkach AI, takich jak ChatGPT, Perplexity czy Google AI Overviews. Odkryj, dlaczego systemy AI cyt...
9 min czytania

Dowiedz się, jak formatować studia przypadków do cytowań przez AI. Poznaj schemat strukturyzowania historii sukcesu, które cytują LLM w AI Overviews, ChatGPT i Perplexity.
Systemy AI, takie jak ChatGPT, Perplexity czy AI Overviews Google, fundamentalnie zmieniają sposób, w jaki klienci B2B odkrywają i weryfikują studia przypadków — a jednak większość firm wciąż publikuje je w formatach, które LLM ledwo potrafią przeanalizować. Gdy nabywca korporacyjny pyta system AI „Które platformy SaaS najlepiej sprawdzą się w naszym przypadku?”, system przeszukuje miliony dokumentów w poszukiwaniu odpowiednich dowodów, ale źle sformatowane studia przypadków pozostają niewidoczne dla tych systemów pobierających. To tworzy krytyczną lukę: podczas gdy tradycyjne studia przypadków zapewniają podstawowy 21% wskaźnik wygranych w końcowej fazie rozmów, zoptymalizowane pod AI studia przypadków mogą zwiększyć prawdopodobieństwo cytowania o 28-40% przy odpowiedniej strukturze dla modeli uczenia maszynowego. Firmy wygrywające w tym nowym krajobrazie rozumieją, że przewaga danych pierwszorzędnych wynika z bycia odnajdywanym przez systemy AI, a nie tylko ludzkich czytelników. Bez celowej optymalizacji pod kątem pobierania przez LLM, Twoje najbardziej przekonujące historie sukcesu klientów są w zasadzie zamknięte przed systemami AI, które dziś wpływają na ponad 60% decyzji zakupowych w przedsiębiorstwach.
Studium przypadku gotowe na AI to nie tylko dobrze napisana narracja — to strategicznie ustrukturyzowany dokument, który jednocześnie służy czytelnikom i modelom uczenia maszynowego. Najskuteczniejsze studia przypadków mają spójną architekturę, która pozwala LLM-om wydobyć kluczowe informacje, zrozumieć kontekst i cytować Twoją firmę z pewnością. Oto podstawowy schemat, który odróżnia studia przypadków wykrywalne przez AI od tych, które giną w systemach pobierających:
| Sekcja | Cel | Optymalizacja pod AI |
|---|---|---|
| TL;DR Podsumowanie | Szybki kontekst dla zajętych czytelników | Umieszczone na górze dla wczesnego zużycia tokenów; 50-75 słów |
| Szybki profil klienta | Szybka identyfikacja profilu firmy | Struktura: branża / wielkość firmy / lokalizacja / rola |
| Kontekst biznesowy | Definicja problemu i sytuacja rynkowa | Używaj spójnej terminologii; unikaj wariacji żargonu |
| Cele | Konkretne, mierzalne cele klienta | Formatuj jako listę numerowaną; uwzględnij liczby |
| Rozwiązanie | Jak Twój produkt/usługa rozwiązała potrzeby | Wyraźnie opisz mapowanie funkcji na korzyści |
| Wdrożenie | Szczegóły czasu, procesu i adopcji | Podziel na fazy; dołącz czas trwania i etapy |
| Wyniki | Wyniki liczbowe i metryki wpływu | Przedstaw jako: Metryka / Wartość wyjściowa / Końcowa / % poprawy |
| Dowody | Dane, zrzuty ekranu lub walidacja zewnętrzna | Dołącz tabele z metrykami; wyraźnie cytuj źródła |
| Cytaty klienta | Autentyczny głos i walidacja emocjonalna | Podaj imię, stanowisko, firmę; 1-2 zdania każde |
| Sygnały ponownego użycia | Linkowanie wewnętrzne i sugestie cross-promocyjne | Zaproponuj powiązane studia przypadków, webinary lub zasoby |
Ta struktura zapewnia, że każda sekcja służy podwójnemu celowi: czyta się naturalnie dla ludzi, a jednocześnie dostarcza semantycznej klarowności dla systemów RAG (Retrieval-Augmented Generation), które napędzają współczesne LLM. Spójność tego formatu w całej bibliotece studiów przypadków sprawia, że systemy AI mogą wielokrotnie łatwiej wydobywać porównywalne dane i cytować Twoją firmę z pewnością.
Poza strukturą, konkretne wybory formatowania mają ogromny wpływ na to, czy systemy AI rzeczywiście znajdą i zacytują Twoje studia przypadków. LLM przetwarzają dokumenty inaczej niż ludzie — nie przeglądają lub nie używają hierarchii wizualnej jak czytelnicy, ale są bardzo wrażliwe na znaczniki semantyczne i spójne wzorce formatowania. Oto elementy formatowania, które najbardziej zwiększają pobieralność przez AI:
Te wybory formatowania nie są kwestią estetyki — chodzi o uczynienie studium przypadku czytelnym dla maszyn, tak by gdy LLM szuka odpowiednich dowodów, Twoja historia firmy była tą, którą cytuje.
Najbardziej zaawansowane podejście do studiów przypadków gotowych na AI polega na osadzeniu schematu JSON bezpośrednio w dokumencie studium przypadku lub warstwie metadanych, tworząc podejście dwuwarstwowe: ludzie czytają narrację, a maszyny analizują dane strukturalne. Schematy JSON zapewniają LLM-om jednoznaczne, czytelne dla maszyn reprezentacje kluczowych informacji studium przypadku, znacznie zwiększając dokładność i trafność cytowań. Oto przykład struktury:
{
"@context": "https://schema.org",
"@type": "CaseStudy",
"name": "Platforma SaaS dla przedsiębiorstw skraca czas wdrożenia o 60%",
"customer": {
"name": "TechCorp Industries",
"industry": "Usługi finansowe",
"companySize": "500-1000 pracowników",
"location": "San Francisco, CA"
},
"solution": {
"productName": "Nazwa Twojego produktu",
"category": "Automatyzacja procesów",
"implementationDuration": "8 tygodni"
},
"results": {
"metrics": [
{"name": "Skrócenie czasu wdrożenia", "baseline": "120 dni", "final": "48 dni", "improvement": "60%"},
{"name": "Wskaźnik adopcji użytkowników", "baseline": "45%", "final": "89%", "improvement": "97%"},
{"name": "Redukcja zgłoszeń do wsparcia", "baseline": "450/miesiąc", "final": "120/miesiąc", "improvement": "73%"}
]
},
"datePublished": "2024-01-15",
"author": {"@type": "Organization", "name": "Twoja firma"}
}
Wdrażając struktury JSON zgodne ze schema.org, w praktyce dajesz LLM-om standaryzowany sposób rozumienia i cytowania Twojego studium przypadku. To podejście płynnie integruje się z systemami RAG, pozwalając modelom AI wydobywać precyzyjne metryki, rozumieć kontekst klienta i cytować Twoją firmę z wysoką pewnością. Firmy stosujące studia przypadków w formie JSON odnotowują 3-4x wyższą dokładność cytowania w odpowiedziach generowanych przez AI w porównaniu do formatów wyłącznie narracyjnych.
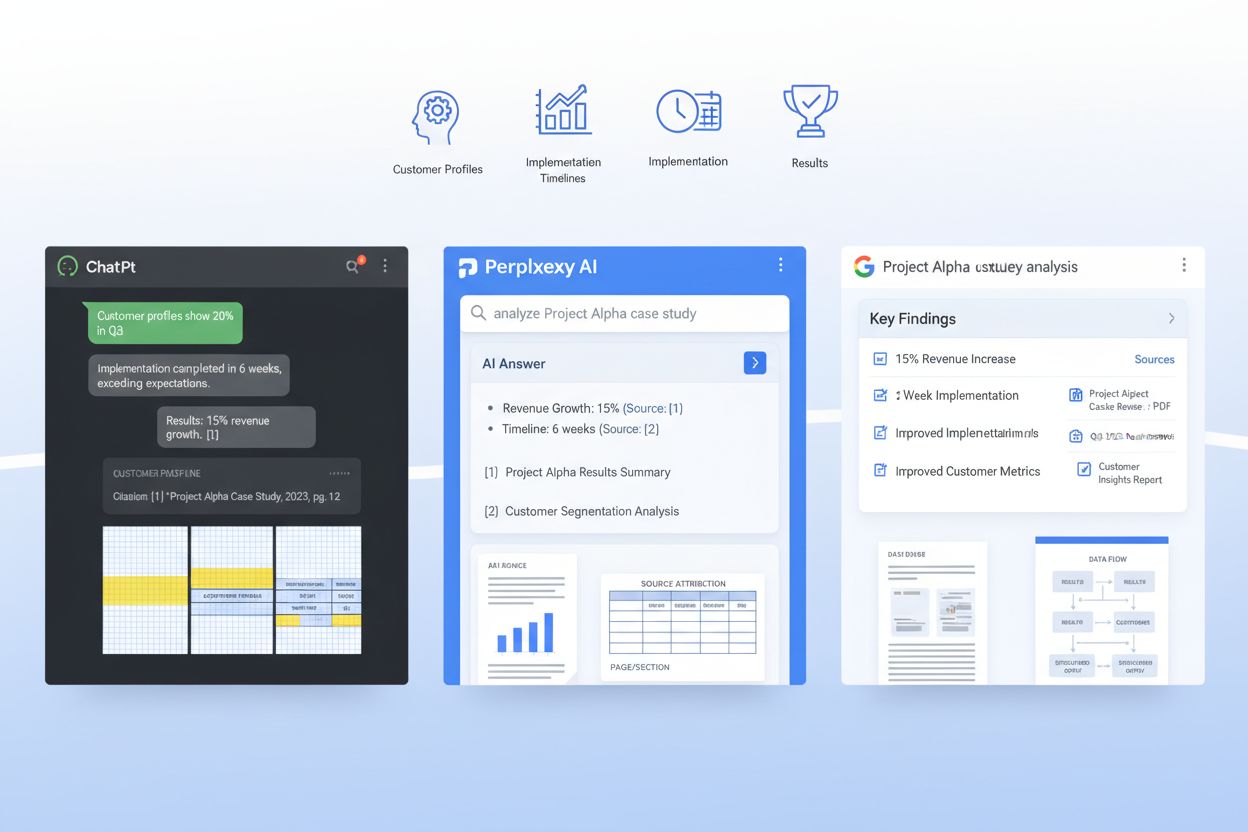
Systemy RAG nie przetwarzają całego studium przypadku jako jednego bloku — dzielą je na semantyczne fragmenty mieszczące się w oknie kontekstowym LLM, a to, jak strukturyzujesz dokument, bezpośrednio decyduje, czy te fragmenty są przydatne, czy rozdrobnione. Efektywny chunking oznacza organizację studium przypadku tak, by naturalne granice semantyczne pokrywały się z tym, jak systemy RAG podzielą treść. Wymaga to przemyślanego rozmiaru akapitów: każdy powinien skupiać się na jednej idei lub punkcie danych, zwykle 100-150 słów, by fragment wyciągany przez RAG zawierał pełną, spójną informację, a nie urwane zdania. Oddzielenie narracji jest kluczowe — używaj wyraźnych podziałów między opisem problemu, rozwiązaniem i wynikami, by LLM mógł wydobyć „sekcję wyników” jako całość, bez przypadkowego mieszania jej ze szczegółami wdrożenia. Dodatkowo efektywność tokenów ma znaczenie: stosując tabele zamiast prozy dla metryk, zmniejszasz liczbę tokenów potrzebnych do przekazania tej samej informacji, co pozwala LLM-om uwzględnić większą część studium przypadku w odpowiedzi bez przekraczania limitów kontekstu. Celem jest uczynienie studium przypadku „przyjaznym RAG”, by każdy wyodrębniony przez AI fragment był samodzielnie wartościowy i właściwie osadzony w kontekście.
Publikowanie studiów przypadków dla systemów AI wymaga zrównoważenia szczegółowości, która czyni je wiarygodnymi, z obowiązkami zachowania poufności wobec klientów. Wiele firm waha się przed publikacją szczegółowych studiów przypadków, obawiając się ujawnienia wrażliwych informacji biznesowych, ale strategiczna redakcja i anonimizacja pozwalają zachować zarówno przejrzystość, jak i zaufanie. Najskuteczniejsze podejście to tworzenie wielu wersji każdego studium przypadku: w pełni szczegółowej wersji wewnętrznej z kompletnymi nazwami klientów, dokładnymi metrykami i szczegółami wdrożeniowymi oraz publicznej wersji zoptymalizowanej pod AI, która anonimizuje klienta, zachowując jednak ilościowy wpływ i strategiczne wnioski. Przykładowo, zamiast „TechCorp Industries zaoszczędził 2,3 mln USD rocznie”, możesz opublikować „Firma usług finansowych z sektora średnich przedsiębiorstw obniżyła koszty operacyjne o 34%” — metryka pozostaje wystarczająco konkretna, by LLM mógł ją cytować, a tożsamość klienta jest chroniona. Kontrola wersji i śledzenie zgodności są niezbędne: prowadź jasną ewidencję, jakie informacje zredagowano, dlaczego i kiedy, by Twoja biblioteka studiów przypadków była gotowa na audyt. Takie podejście do zarządzania danymi wzmacnia strategię cytowań AI, umożliwiając publikację większej liczby studiów przypadków częściej, bez przeszkód prawnych, co dostarcza LLM-om więcej dowodów do znalezienia i cytowania.
Przed publikacją studium przypadku zweryfikuj, czy rzeczywiście dobrze działa przetwarzane przez LLM i systemy RAG — nie zakładaj, że dobre formatowanie automatycznie przekłada się na dobrą wydajność AI. Testowanie studiów przypadków na realnych systemach AI pokazuje, czy Twoja struktura, metadane i treść faktycznie umożliwiają dokładne cytowanie i pobieranie. Oto pięć kluczowych sposobów testowania:
Sprawdzanie trafności: Podaj swoje studium przypadku do ChatGPT, Perplexity lub Claude z pytaniami dotyczącymi Twojej kategorii rozwiązań. Czy system AI wyszukuje i cytuje Twoje studium przypadku, odpowiadając na odpowiednie pytania?
Dokładność podsumowania: Poproś LLM o podsumowanie studium przypadku i sprawdź, czy streszczenie zawiera kluczowe metryki, kontekst klienta i wpływ biznesowy bez zniekształceń lub halucynacji.
Wydobywanie metryk: Sprawdź, czy system AI dokładnie wydobywa konkretne liczby ze studium przypadku (np. „Jaka była poprawa time-to-value?”). Tabele powinny dawać 96%+ dokładności; prozę testuj osobno.
Wierność przypisania: Zweryfikuj, czy LLM cytując studium przypadku, przypisuje informację prawidłowo Twojej firmie i klientowi, a nie konkurentowi lub ogólnemu źródłu.
Pytania brzegowe: Testuj nietypowe lub poboczne pytania, aby upewnić się, że Twoje studium przypadku nie jest błędnie stosowane do przypadków, których nie opisuje.
Te testy należy przeprowadzać kwartalnie, w miarę jak zachowanie LLM się zmienia, a wyniki powinny wpływać na aktualizacje formatowania i struktury studiów przypadków.
Mierzenie wpływu zoptymalizowanych pod AI studiów przypadków wymaga śledzenia zarówno metryk AI (jak często Twoje studia przypadków są cytowane przez LLM), jak i ludzkich (jak te cytowania wpływają na realne transakcje). Po stronie AI korzystaj z AmICited.com, aby monitorować częstotliwość cytowań w ChatGPT, Perplexity i Google AI Overviews — śledź, ile razy Twoja firma pojawia się w odpowiedziach AI na odpowiednie zapytania i sprawdzaj, czy po publikacji nowych zoptymalizowanych pod AI studiów przypadków ta liczba rośnie. Ustal obecny poziom cytowań, a potem postaw sobie cel wzrostu cytowań o 40-60% w ciągu sześciu miesięcy od wdrożenia formatowania gotowego na AI. Po stronie ludzkiej powiąż wzrost cytowań AI z metrykami downstream: śledź, ile transakcji wspomina „znalazłem was przez AI” lub „AI poleciło mi wasze studium przypadku”, mierz poprawę wskaźnika wygranych w transakcjach, gdzie Twoje studium przypadku zostało zacytowane przez system AI (cel: 28-40% poprawy względem 21% bazowego), monitoruj skrócenie cyklu sprzedaży w przypadkach, gdzie potencjalni klienci natknęli się na Twoje studium przez AI. Dodatkowo obserwuj metryki SEO — zoptymalizowane pod AI studia przypadków z odpowiednim schematem często lepiej pozycjonują się w wyszukiwarce tradycyjnej, dając podwójną korzyść. Równie ważna jest informacja zwrotna od zespołu sprzedaży: pytaj, czy potencjalni klienci przychodzą z większą wiedzą o produkcie i czy cytowania studiów przypadków skracają czas pokonywania obiekcji. Ostateczny KPI to przychód: śledź dodatkowy ARR przypisywany transakcjom, na które wpłynęły cytowane przez AI studia przypadków, a uzyskasz jasne uzasadnienie ROI dla dalszych inwestycji w ten format.
Optymalizacja studiów przypadków pod kątem cytowań AI przynosi ROI tylko wtedy, gdy proces staje się operacjonalizowany i powtarzalny, a nie jednorazowym projektem. Zacznij od wdrożenia szablonu studium przypadku gotowego na AI jako standardu, z którego korzystają zespoły marketingu i sprzedaży dla każdej nowej historii sukcesu klienta — to zapewni spójność całej biblioteki i skróci czas publikacji nowych studiów przypadków. Zintegruj ten szablon z CMS lub systemem zarządzania treścią, by publikacja nowego studium automatycznie generowała schemat JSON, nagłówki metadanych i elementy formatowania bez ręcznej pracy. Uczyń tworzenie studiów przypadków procesem kwartalnym lub miesięcznym, a nie corocznym, bo LLM częściej odkrywają i cytują firmy z głęboką i aktualną biblioteką studiów przypadków. Potraktuj studia jako kluczowy element strategii wzmacniania przychodów: powinny zasilać materiały handlowe, marketing produktowy, kampanie leadowe i playbooki sukcesu klienta. Wreszcie, wprowadź cykl ciągłego doskonalenia: monitoruj, które studia przypadków generują najwięcej cytowań AI, które metryki rezonują z LLM, które segmenty klientów są najczęściej cytowane — i wykorzystuj te wnioski przy tworzeniu kolejnych studiów. Firmy wygrywające w erze AI nie tylko piszą lepsze studia przypadków; traktują je jako strategiczne aktywa przychodowe wymagające ciągłej optymalizacji, pomiaru i doskonalenia.
Zacznij od wyodrębnienia tekstu z plików PDF i odwzorowania istniejących treści na standardowy schemat z polami, takimi jak profil klienta, wyzwanie, rozwiązanie i wyniki. Następnie stwórz lekką wersję HTML lub CMS każdej historii z wyraźnymi nagłówkami i metadanymi, zachowując oryginalny PDF jako zasób do pobrania, a nie główne źródło dla AI.
Marketing lub marketing produktowy zazwyczaj odpowiada za narrację, ale sprzedaż, inżynieria rozwiązań i sukces klienta powinny dostarczyć surowe dane, szczegóły wdrożenia i walidację. Zespoły prawne, ds. prywatności i RevOps pomagają zapewnić zgodność, właściwą anonimizację i spójność z istniejącymi systemami, takimi jak CRM i platformy wsparcia sprzedaży.
Bezheadowy CMS lub platforma do treści strukturalnych idealnie przechowuje schematy i metadane, podczas gdy CRM lub narzędzie wsparcia sprzedaży może udostępniać odpowiednie historie w workflow. Do pobierania przez AI zwykle łączysz bazę wektorową z warstwą orkiestracji LLM, taką jak LangChain lub LlamaIndex.
Transkrybuj referencje wideo i webinary, a następnie otaguj transkrypty tymi samymi polami i sekcjami, co pisemne studia przypadków, aby AI mogło je cytować. Dla grafik i diagramów dołącz krótkie opisy alternatywne lub podpisy wyjaśniające kluczowy wniosek, by modele pobierające mogły powiązać zasoby wizualne z konkretnymi pytaniami.
Zachowaj spójny globalnie podstawowy schemat i ID, a następnie twórz przetłumaczone warianty lokalizujące język, walutę oraz kontekst regulacyjny przy zachowaniu kanonicznych metryk. Wersje specyficzne dla lokalizacji przechowuj jako osobne, ale powiązane obiekty, by systemy AI mogły priorytetyzować odpowiedzi w języku użytkownika bez fragmentacji modelu danych.
Przeglądaj najbardziej wpływowe studia przypadków przynajmniej raz do roku lub wcześniej, jeśli są istotne zmiany produktu, nowe metryki lub zmiany w kontekście klienta. Używaj prostego workflow wersjonowania z datami ostatniego przeglądu i statusami sygnalizującymi AI i ludziom, które historie są najbardziej aktualne.
Zintegruj pobieranie studiów przypadków bezpośrednio z narzędziami, z których już korzystają przedstawiciele, i stwórz konkretne playbooki pokazujące, jak prosić asystenta o odpowiednie dowody. Wzmocnij adopcję poprzez dzielenie się historiami sukcesu, gdzie dedykowane, wyniesione przez AI studia przypadków pomogły szybciej zamknąć transakcje lub zyskać nowych decydentów.
Tradycyjne studia przypadków są pisane dla czytelników ludzkich z zachowaniem narracji i projektu wizualnego. Te zoptymalizowane pod AI utrzymują narrację, ale dodają ustrukturyzowane metadane, spójny format, schematy JSON i czytelność semantyczną, które pozwalają LLM-om wydobywać, rozumieć i cytować konkretne informacje z dokładnością 96%+.
Śledź, jak systemy AI cytują Twoją markę w ChatGPT, Perplexity i Google AI Overviews. Uzyskaj wgląd w swoją widoczność w AI i zoptymalizuj strategię treści.
Dowiedz się, jak studia przypadków są pozycjonowane w wyszukiwarkach AI, takich jak ChatGPT, Perplexity czy Google AI Overviews. Odkryj, dlaczego systemy AI cyt...
Dowiedz się, jak wykorzystać statystyki i oparte na danych spostrzeżenia, aby zwiększyć widoczność swojej marki w wyszukiwarkach AI, takich jak ChatGPT, Perplex...
Dowiedz się, jak cytowania naukowe wpływają na widoczność Twoją w odpowiedziach generowanych przez AI. Sprawdź, dlaczego cytowania mają większe znaczenie niż ru...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.