
AI-Specific Robots.txt
Dowiedz się, jak skonfigurować robots.txt dla robotów AI, w tym GPTBot, ClaudeBot i PerplexityBot. Poznaj kategorie robotów AI, strategie blokowania oraz najlep...
9 min czytania

Dowiedz się, jak blokować lub zezwalać robotom AI, takim jak GPTBot i ClaudeBot, za pomocą robots.txt, blokowania na poziomie serwera oraz zaawansowanych metod ochrony. Kompletny przewodnik techniczny z przykładami.
Krajobraz cyfrowy fundamentalnie się zmienił – od tradycyjnej optymalizacji pod wyszukiwarki do zarządzania zupełnie nową kategorią automatycznych odwiedzających: robotami AI. W przeciwieństwie do klasycznych botów wyszukiwarek, które kierują ruch z powrotem na Twoją stronę poprzez wyniki wyszukiwania, roboty treningowe AI wykorzystują Twoje treści do budowy dużych modeli językowych, niekoniecznie generując ruch zwrotny. Ta różnica ma ogromne znaczenie dla wydawców, twórców treści i firm opierających się na ruchu z sieci jako źródle dochodu. Stawka jest wysoka — kontrola nad tym, które systemy AI mają dostęp do Twoich treści, bezpośrednio wpływa na Twoją przewagę konkurencyjną, prywatność danych i wyniki finansowe.
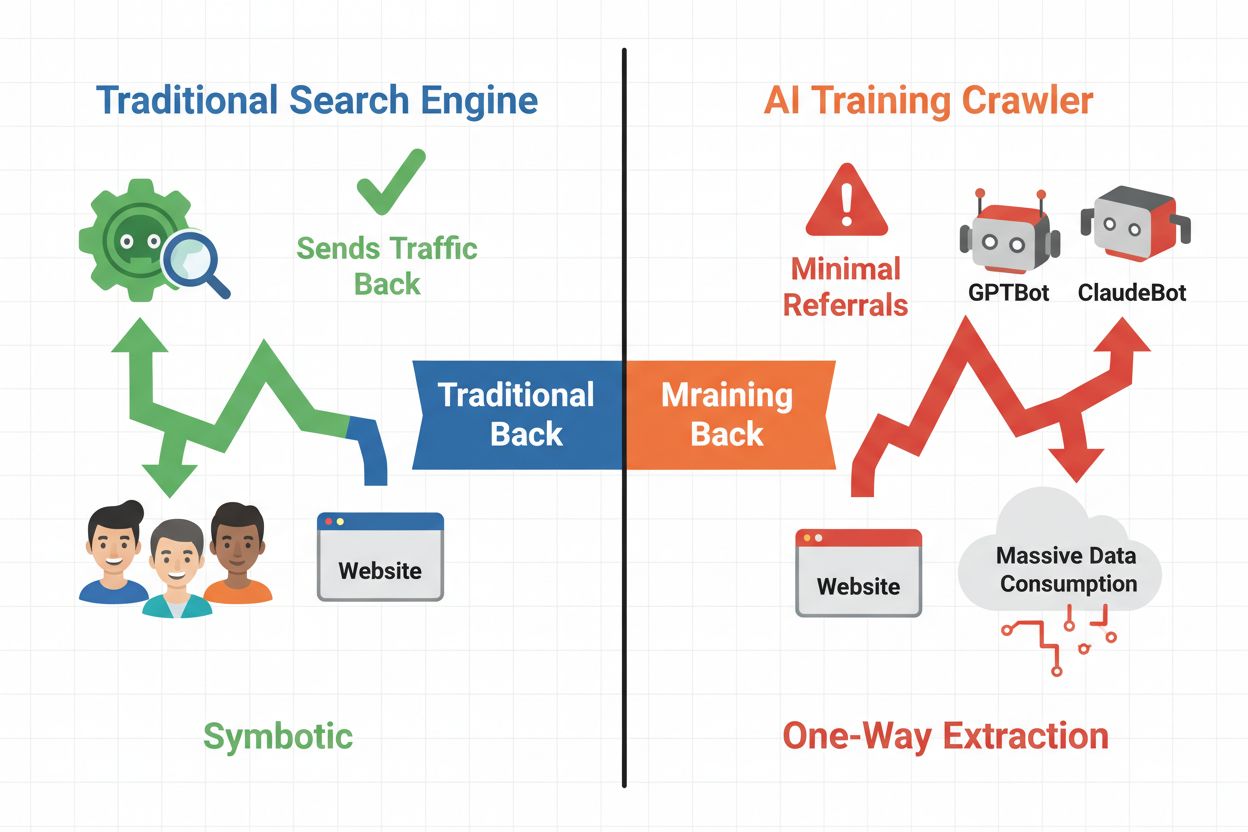
Roboty AI dzielą się na trzy odrębne kategorie, z których każda ma inne cele i wpływ na ruch. Roboty treningowe są wykorzystywane przez firmy AI do budowy i ulepszania modeli językowych, działając zwykle na dużą skalę, a ruch zwrotny jest minimalny. Roboty wyszukiwawcze i cytujące indeksują treści dla wyszukiwarek AI i systemów cytowań, często generując pewien ruch zwrotny dla wydawców. Roboty wywoływane przez użytkowników pobierają treści na żądanie, gdy użytkownik korzysta z aplikacji AI — to segment mniejszy, ale dynamicznie rosnący. Zrozumienie tych kategorii pomaga podejmować świadome decyzje, którym robotom zezwalać na dostęp, a które blokować w zależności od modelu biznesowego.
| Typ robota | Cel | Wpływ na ruch | Przykłady |
|---|---|---|---|
| Treningowy | Budowa/ulepszanie LLM | Minimalny lub żaden | GPTBot, ClaudeBot, Bytespider |
| Wyszukiwanie/Cytowanie | Indeksowanie dla AI search & cytowań | Umiarkowany ruch zwrotny | Googlebot-Extended, Perplexity |
| Wywoływany przez użytkownika | Pobieranie na żądanie | Niski, ale stały | Wtyczki ChatGPT, przeglądanie Claude |
Ekosystem robotów AI obejmuje roboty największych firm technologicznych na świecie, z różnymi user agentami i celami. GPTBot od OpenAI (user agent: GPTBot/1.0) pobiera treści do trenowania ChatGPT i innych modeli, podczas gdy ClaudeBot od Anthropic (user agent: Claude-Web/1.0) służy podobnym celom dla Claude. Googlebot-Extended od Google (user agent: Mozilla/5.0 ... Googlebot-Extended) indeksuje treści do AI Overviews i Bard, natomiast Meta-ExternalFetcher pobiera dane do inicjatyw AI Facebooka. Inni kluczowi gracze to:
Każdy robot działa na inną skalę i w różnym stopniu przestrzega zasad blokowania.
Plik robots.txt to pierwsza linia obrony w kontrolowaniu dostępu robotów AI, jednak należy pamiętać, że ma on charakter doradczy, a nie prawnie egzekwowalny. Znajduje się w głównym katalogu domeny (np. twojastrona.com/robots.txt) i wykorzystuje prostą składnię, by przekazać robotom, których części mają unikać. Aby całkowicie zablokować wszystkie roboty AI, dodaj następujące reguły:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Jeśli chcesz blokować selektywnie — zezwalając na roboty wyszukiwawcze, a blokując treningowe — zastosuj takie podejście:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
Częstym błędem jest używanie zbyt ogólnych reguł, np. Disallow: *, co może wprowadzać parsery w błąd, lub zapominanie o wskazaniu konkretnych robotów przy chęci blokady tylko niektórych. Główne firmy, takie jak OpenAI, Anthropic i Google, zwykle respektują dyrektywy robots.txt, choć niektóre roboty, jak Perplexity, są znane z ignorowania tych zasad.
Gdy robots.txt to za mało, kilka mocniejszych metod pozwala zyskać większą kontrolę nad dostępem robotów AI. Blokowanie po IP polega na identyfikacji zakresów IP robotów AI i blokowaniu ich na poziomie zapory lub serwera — to bardzo skuteczne, choć wymaga ciągłej aktualizacji, bo adresy IP się zmieniają. Blokowanie na poziomie serwera przez pliki .htaccess (Apache) lub konfigurację Nginx pozwala na bardziej szczegółową kontrolę i trudniej je obejść niż robots.txt. Na serwerach Apache zastosuj taki zapis:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Blokowanie metatagami przy użyciu <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> zapobiega indeksowaniu, ale nie zatrzyma robotów treningowych. Weryfikacja nagłówków żądań polega na sprawdzaniu, czy roboty rzeczywiście pochodzą z deklarowanego źródła, poprzez weryfikację odwrotnego DNS i certyfikatów SSL. Blokowanie na poziomie serwera stosuj, gdy zależy Ci na absolutnej pewności, że roboty nie uzyskają dostępu do Twoich treści, a dla maksymalnej ochrony łącz kilka metod.
Decyzja o blokowaniu robotów AI to rozważenie kilku sprzecznych interesów. Blokowanie robotów treningowych (GPTBot, ClaudeBot, Bytespider) chroni Twoje treści przed wykorzystaniem do trenowania modeli AI, zabezpieczając własność intelektualną i przewagę konkurencyjną. Jednak zezwalanie na roboty wyszukiwawcze (Googlebot-Extended, Perplexity) może generować ruch zwrotny i zwiększać widoczność w wynikach wyszukiwania opartych o AI — to rosnący kanał odkrywania treści. Kompromis jest trudny, bo niektóre firmy AI mają bardzo słaby stosunek liczby odwiedzin do wizyt zwrotnych: roboty Anthropic wykonują ok. 38 000 żądań na jedną wizytę zwrotną, a OpenAI ok. 400:1. Obciążenie serwera i transfer to kolejny czynnik — roboty AI zużywają dużo zasobów, a ich blokowanie może zmniejszyć koszty infrastruktury. Decyzję należy dostosować do modelu biznesowego: organizacje medialne i wydawcy mogą korzystać z ruchu zwrotnego, podczas gdy firmy SaaS i twórcy treści chronionych zwykle preferują blokadę.
Wdrożenie blokady to tylko połowa sukcesu — musisz sprawdzić, czy roboty rzeczywiście respektują Twoje zasady. Analiza logów serwera to podstawowe narzędzie weryfikacji; przeglądaj logi dostępu pod kątem user agentów i adresów IP robotów próbujących wejść na stronę po zablokowaniu. Użyj grep do przeszukania logów:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
To polecenie zlicza liczbę wejść tych robotów na Twoją stronę. Narzędzia testujące jak curl pozwalają symulować żądania robotów i sprawdzić, czy blokady działają prawidłowo:
curl -A "GPTBot/1.0" https://twojastrona.com/robots.txt
Monitoruj logi co tydzień przez pierwszy miesiąc po wdrożeniu blokad, potem co kwartał. Jeśli zauważysz, że roboty ignorują robots.txt, przejdź do blokowania na poziomie serwera lub skontaktuj się z zespołem nadużyć operatora robota.
Ekosystem robotów AI szybko się zmienia — pojawiają się nowe firmy i roboty, zmieniają się user agenty i zakresy IP. Przeglądaj listę blokowanych co kwartał, aby nie przeoczyć nowych robotów albo nie zablokować przypadkowo legalnego ruchu. Ekosystem robotów jest rozproszony i zdecentralizowany, więc nie istnieje trwała, kompletna lista blokad. Monitoruj te źródła:
Ustaw przypomnienia w kalendarzu, by co 90 dni przeglądać robots.txt i reguły serwerowe oraz subskrybuj mailing listy bezpieczeństwa śledzące nowe wdrożenia robotów.
Chociaż blokowanie robotów AI uniemożliwia im dostęp do Twoich treści, AmICited rozwiązuje komplementarne wyzwanie: monitorowanie, czy systemy AI cytują i wspominają Twoją markę oraz treści w swoich odpowiedziach. AmICited śledzi wzmianki o Twojej organizacji w odpowiedziach generowanych przez AI, zapewniając widoczność tego, jak Twoje treści wpływają na wyniki modeli AI oraz gdzie Twoja marka pojawia się w wynikach wyszukiwania AI. Tworzy to kompleksową strategię AI: kontrolujesz dostęp robotów przez robots.txt i blokady serwerowe, a AmICited pozwala zrozumieć rzeczywisty wpływ Twoich treści na systemy AI. Razem te narzędzia dają Ci pełną widoczność i kontrolę nad obecnością w ekosystemie AI — od zapobiegania niechcianemu wykorzystaniu do trenowania modeli po pomiar rzeczywistych cytowań i odniesień do Twoich treści na platformach AI.
Nie. Blokowanie robotów treningowych AI, takich jak GPTBot, ClaudeBot i Bytespider, nie wpływa na Twoje pozycje w Google lub Bing. Tradycyjne wyszukiwarki używają innych robotów (Googlebot, Bingbot), które działają niezależnie. Blokuj je tylko, jeśli chcesz całkowicie zniknąć z wyników wyszukiwania.
Główne roboty od OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) oraz Perplexity (PerplexityBot) oficjalnie deklarują, że respektują dyrektywy robots.txt. Jednak mniejsze lub mniej przejrzyste roboty mogą ignorować Twoją konfigurację, dlatego istnieją strategie wielowarstwowej ochrony.
To zależy od Twojej strategii. Blokowanie tylko robotów treningowych (GPTBot, ClaudeBot, Bytespider) chroni Twoje treści przed wykorzystaniem do trenowania modeli, jednocześnie pozwalając robotom wyszukiwawczym pomagać w pojawianiu się w wynikach wyszukiwania AI. Całkowite blokowanie wyklucza Cię z ekosystemów AI.
Przeglądaj swoją konfigurację co najmniej raz na kwartał. Firmy AI regularnie wprowadzają nowe roboty. Anthropic połączył swoje boty 'anthropic-ai' i 'Claude-Web' w 'ClaudeBot', dając nowemu botowi tymczasowy nieograniczony dostęp do stron, które nie zaktualizowały zasad.
Blokowanie uniemożliwia robotom dostęp do Twoich treści, chroniąc je przed zbieraniem do trenowania modeli lub indeksowaniem. Zezwolenie robotom daje im dostęp, ale może skutkować wykorzystaniem Twoich treści do trenowania modeli lub pojawieniem się w wynikach AI przy minimalnym ruchu zwrotnym.
Tak, robots.txt ma charakter doradczy, a nie prawnie egzekwowalny. Roboty od dużych firm zwykle respektują robots.txt, ale niektóre mogą je ignorować. Dla silniejszej ochrony wdrażaj blokowanie na poziomie serwera poprzez .htaccess lub reguły zapory sieciowej.
Sprawdź logi serwera pod kątem user agentów zablokowanych robotów. Jeśli widzisz żądania od robotów, które zablokowałeś, mogą one nie respektować robots.txt. Użyj narzędzi takich jak tester robots.txt w Google Search Console lub poleceń curl, by zweryfikować konfigurację.
Blokowanie robotów treningowych zwykle ma minimalny wpływ na ruch, ponieważ i tak generują mało wizyt. Jednak blokowanie robotów wyszukiwawczych może ograniczyć widoczność w platformach odkrywających treści przez AI. Monitoruj swoje statystyki przez 30 dni po wdrożeniu blokady, by zmierzyć rzeczywisty wpływ.
Chociaż kontrolujesz dostęp robotów przez robots.txt, AmICited pomaga śledzić, jak systemy AI cytują i odnoszą się do Twoich treści w swoich wynikach. Zyskaj pełną widoczność swojej obecności w AI.
Dowiedz się, jak skonfigurować robots.txt dla robotów AI, w tym GPTBot, ClaudeBot i PerplexityBot. Poznaj kategorie robotów AI, strategie blokowania oraz najlep...

Dowiedz się, jak podejmować strategiczne decyzje dotyczące blokowania robotów AI. Oceń typ treści, źródła ruchu, modele przychodów i pozycję konkurencyjną dzięk...

Poznaj kluczowe techniczne czynniki SEO wpływające na widoczność w wyszukiwarkach AI, takich jak ChatGPT, Perplexity i Google AI Mode. Dowiedz się, jak szybkość...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.