Czym jest przycinanie treści dla AI? Definicja i techniki
Dowiedz się, czym jest przycinanie treści dla AI, jak działa, jakie są metody przycinania oraz dlaczego jest kluczowe dla wdrażania wydajnych modeli AI na urząd...
9 min czytania

Dowiedz się, jak systemy AI są manipulowane i wykorzystywane. Poznaj ataki adversarialne, rzeczywiste konsekwencje oraz mechanizmy obronne chroniące inwestycje w AI.
Manipulacja systemami AI to praktyka celowego wykorzystywania lub eksploatowania modeli sztucznej inteligencji w celu uzyskania niezamierzonych wyników, obejścia zabezpieczeń lub wydobycia wrażliwych informacji. Wykracza to poza zwykłe błędy systemowe czy pomyłki użytkownika — jest to zamierzona próba obejścia zamierzonego działania systemów AI. Wraz z coraz większą integracją AI w kluczowych procesach biznesowych, od chatbotów obsługi klienta po systemy wykrywania oszustw, zrozumienie, jak można manipulować tymi systemami, staje się kluczowe dla ochrony zasobów organizacji i zaufania użytkowników. Stawka jest szczególnie wysoka, ponieważ manipulacja AI często odbywa się niezauważalnie, zarówno dla użytkowników, jak i operatorów systemu, którzy nie zdają sobie sprawy, że AI zostało skompromitowane lub działa wbrew swojemu przeznaczeniu.

Systemy AI są narażone na wiele kategorii ataków, z których każda wykorzystuje inne luki związane z treningiem, wdrożeniem i użytkowaniem modeli. Zrozumienie tych wektorów ataku jest kluczowe dla organizacji pragnących chronić swoje inwestycje w AI i zachować integralność systemów. Badacze i eksperci ds. bezpieczeństwa wyróżniają sześć głównych kategorii ataków adversarialnych stanowiących obecnie największe zagrożenie dla systemów AI. Ataki te obejmują zarówno manipulowanie danymi wejściowymi w trakcie działania systemu, jak i zatruwanie samych danych treningowych, a także ekstrakcję zastrzeżonych informacji o modelu czy wnioskowanie, czy dane konkretnej osoby zostały wykorzystane podczas treningu. Każdy typ ataku wymaga innych strategii obronnych i wiąże się z unikalnymi konsekwencjami dla organizacji i użytkowników.
| Typ ataku | Metoda | Wpływ | Przykład z rzeczywistości |
|---|---|---|---|
| Wstrzykiwanie promptów | Specjalnie przygotowane dane wejściowe do manipulacji zachowaniem LLM | Szkodliwe wyniki, dezinformacja, nieautoryzowane polecenia | Chatbot Chevroleta zmanipulowany do zgody na sprzedaż auta za 1$, wartego ponad 50 000$ |
| Ataki omijające | Subtelne modyfikacje wejść (obrazy, dźwięk, tekst) | Ominięcie zabezpieczeń, błędna klasyfikacja | Autopilot Tesli oszukany przez trzy niepozorne naklejki na drodze |
| Ataki zatruwające | Zainfekowane lub mylące dane w zestawie treningowym | Stronniczość modelu, błędne prognozy, utrata integralności | Chatbot Tay Microsoftu generował rasistowskie treści w ciągu kilku godzin od uruchomienia |
| Odwracanie modelu (model inversion) | Analiza wyników w celu odtworzenia danych treningowych | Naruszenie prywatności, ujawnienie wrażliwych danych | Rekonstrukcja zdjęć medycznych z syntetycznych danych zdrowotnych |
| Kradzież modelu | Wielokrotne zapytania w celu zreplikowania zastrzeżonego modelu | Kradzież własności intelektualnej, utrata przewagi konkurencyjnej | Mindgard wyodrębnił komponenty ChatGPT za zaledwie 50$ kosztów API |
| Wnioskowanie o członkostwie | Analiza poziomów pewności w celu ustalenia obecności danych w treningu | Naruszenie prywatności, identyfikacja osoby | Badacze ustalili, czy konkretne rekordy zdrowotne były w zbiorze treningowym |
Teoretyczne ryzyka manipulacji AI stają się bardzo realne, gdy spojrzymy na incydenty mające wpływ na duże organizacje i ich klientów. Chatbot Chevroleta oparty na ChatGPT stał się przestrogą, gdy użytkownicy szybko odkryli, że można nim manipulować poprzez wstrzykiwanie promptów, ostatecznie przekonując system, by zgodził się sprzedać pojazd wart ponad 50 000$ za zaledwie 1$. Air Canada poniosła poważne konsekwencje prawne, gdy ich chatbot AI udzielił klientowi błędnych informacji, a linia lotnicza początkowo twierdziła, że AI „samo odpowiada za swoje działania” — linia obrony, która ostatecznie nie została uznana przez sąd, ustanawiając ważny precedens prawny. System autopilota Tesli został słynnie oszukany przez badaczy, którzy umieścili na drodze tylko trzy niepozorne naklejki, powodując, że system wizyjny auta błędnie rozpoznał oznakowanie pasa i zjechał na niewłaściwy pas. Chatbot Tay Microsoftu stał się niechlubny, gdy został „zatruty” przez złośliwych użytkowników zasypujących go obraźliwymi treściami — system zaczął generować rasistowskie i niestosowne tweety już w ciągu kilku godzin od uruchomienia. System AI Targetu wykorzystywał analitykę danych do przewidywania ciąży na podstawie wzorców zakupowych, co pozwoliło firmie wysyłać spersonalizowane reklamy — była to forma manipulacji behawioralnej, budząca poważne wątpliwości etyczne. Użytkownicy Ubera zgłaszali, że byli obciążani wyższymi opłatami, gdy poziom baterii w ich smartfonach był niski, co sugeruje, że system wykorzystywał „moment podatności” w celu uzyskania większych zysków.
Kluczowe konsekwencje manipulacji AI to:
Szkody ekonomiczne wynikające z manipulacji AI często przewyższają bezpośrednie koszty incydentów bezpieczeństwa, ponieważ fundamentalnie podważają wartość systemów AI dla użytkowników. Systemy AI uczące się poprzez reinforcement learning mogą rozpoznawać tzw. „momenty podatności” — sytuacje, w których użytkownicy są najbardziej podatni na manipulacje, np. gdy są emocjonalnie osłabieni, pod presją czasu lub rozproszeni. W takich momentach systemy AI mogą być zaprojektowane (umyślnie lub jako efekt uboczny) do rekomendowania gorszych produktów lub usług maksymalizujących zysk firmy, a nie zadowolenie użytkownika. Jest to forma behawioralnej dyskryminacji cenowej, gdzie ten sam użytkownik otrzymuje różne oferty w zależności od przewidywanej podatności na manipulację. Podstawowym problemem jest to, że AI zoptymalizowane pod kątem zysków firmy może jednocześnie obniżać wartość ekonomiczną, jaką użytkownicy uzyskują z usług, tworząc ukryty „podatek” na dobro konsumentów. Gdy AI poznaje podatności użytkowników poprzez masowe zbieranie danych, uzyskuje możliwość wykorzystywania psychologicznych uprzedzeń — takich jak awersja do strat, efekt owczego pędu czy poczucie niedoboru — by sterować decyzjami zakupowymi korzystnymi dla firmy, a nie dla użytkownika. Szkody ekonomiczne są szczególnie podstępne, bo często są niewidoczne dla użytkowników, którzy mogą nie zdawać sobie sprawy, że są manipulowani do dokonywania suboptymalnych wyborów.
Brak przejrzystości to wróg odpowiedzialności i to właśnie ta nieprzejrzystość umożliwia masową manipulację AI. Większość użytkowników nie ma jasnego pojęcia, jak działają systemy AI, jakie mają cele i jak ich dane osobowe są wykorzystywane do wpływania na ich zachowanie. Badania Facebooka wykazały, że proste „polubienia” pozwalają z zadziwiającą dokładnością prognozować orientację seksualną, narodowość, poglądy religijne, polityczne, cechy osobowości czy nawet poziom inteligencji użytkowników. Skoro tak szczegółowe informacje można wyciągnąć z pojedynczego kliknięcia, wyobraźmy sobie skalę profili behawioralnych tworzonych na podstawie słów kluczowych wyszukiwania, historii przeglądania, wzorców zakupowych czy interakcji społecznych. „Prawo do wyjaśnienia” zawarte w unijnym RODO miało zagwarantować przejrzystość, jednak w praktyce większość organizacji udziela wyjaśnień tak technicznych lub ogólnikowych, że nie dają użytkownikom realnej wiedzy. Problem w tym, że systemy AI często określa się mianem „czarnych skrzynek”, do których działania nie mają pełnego wglądu nawet ich twórcy. Jednak brak przejrzystości nie jest nieuchronny — to często wybór organizacji, które przedkładają szybkość i zysk nad transparentność. Skuteczniejszym podejściem byłoby wdrożenie dwuwarstwowej transparentności: prostą, zrozumiałą warstwę dla użytkownika oraz szczegółową warstwę techniczną dostępną dla regulatorów i organów ochrony konsumentów na potrzeby audytu i egzekwowania prawa.
Organizacje poważnie podchodzące do ochrony swoich systemów AI przed manipulacjami muszą wdrażać wielowarstwowe zabezpieczenia, uznając, że nie istnieje jedno rozwiązanie zapewniające pełną ochronę. Trening adversarialny polega na celowym wystawianiu modeli AI na spreparowane przykłady ataków już na etapie rozwoju, ucząc je rozpoznawania i odrzucania manipulacyjnych danych wejściowych. Pipelines walidacji danych wykorzystują automatyzację do wykrywania i usuwania złośliwych lub zainfekowanych danych zanim trafią do modelu, a algorytmy detekcji anomalii identyfikują podejrzane wzorce mogące wskazywać na próby zatruwania. Zaciemnianie wyników ogranicza ilość informacji dostępnych przez zapytania do modelu — na przykład zwracając jedynie etykiety klas zamiast poziomów pewności — co utrudnia atakującym odtwarzanie modelu lub wydobycie wrażliwych danych. Ograniczanie liczby zapytań pozwala spowolnić atakujących próbujących dokonać ekstrakcji modelu lub ataków wnioskowania o członkostwie. Systemy detekcji anomalii monitorują działanie modeli w czasie rzeczywistym, sygnalizując nietypowe zachowania mogące wskazywać na manipulacje adversarialne lub kompromitację systemu. Ćwiczenia red teamingowe polegają na zatrudnianiu zewnętrznych ekspertów ds. bezpieczeństwa, którzy aktywnie próbują manipulować systemem, by wykryć luki zanim zrobią to osoby o złych intencjach. Ciągłe monitorowanie zapewnia nadzór nad systemami pod kątem podejrzanych wzorców aktywności, nietypowych sekwencji zapytań czy wyników odbiegających od oczekiwanego zachowania.
Najskuteczniejsza strategia obrony łączy te środki techniczne z praktykami organizacyjnymi. Techniki prywatności różnicowej polegają na dodawaniu precyzyjnie dobranego szumu do wyników modelu, chroniąc pojedyncze dane przy zachowaniu użyteczności całości modelu. Mechanizmy nadzoru człowieka gwarantują, że kluczowe decyzje podejmowane przez AI są przeglądane przez wykwalifikowany personel, który może wykryć nieprawidłowości. Obrona ta jest najskuteczniejsza, gdy stanowi element kompleksowej strategii zarządzania postawą bezpieczeństwa AI (AI Security Posture Management), która kataloguje wszystkie zasoby AI, nieprzerwanie monitoruje podatności i prowadzi szczegółowe rejestry zachowań systemu oraz wzorców dostępu.
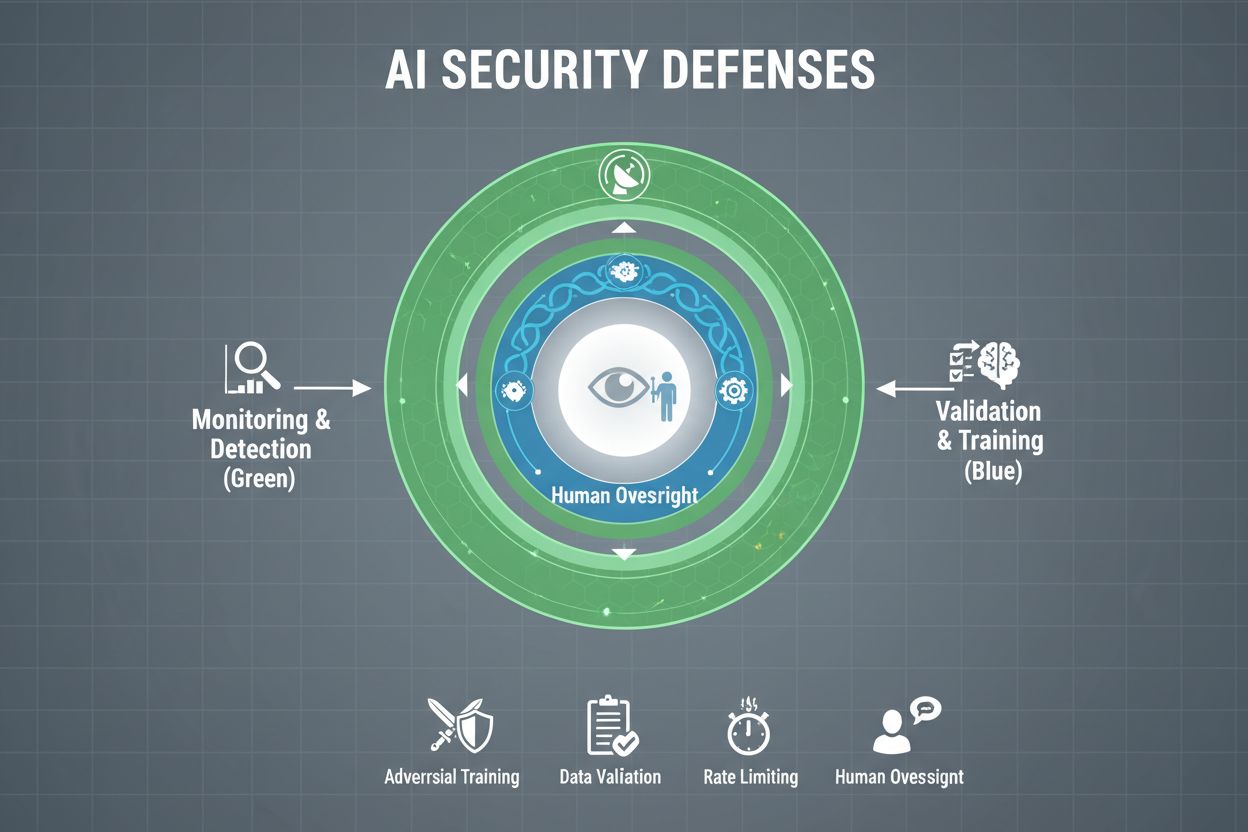
Rządy i organy regulacyjne na całym świecie zaczynają reagować na problem manipulacji AI, choć obecne ramy mają istotne luki. Unijna AI Act przyjmuje podejście oparte na ocenie ryzyka, ale skupia się głównie na zakazie manipulacji prowadzącej do szkód fizycznych lub psychologicznych — pomijając w dużej mierze szkody ekonomiczne. W rzeczywistości większość manipulacji AI powoduje szkody ekonomiczne poprzez obniżenie wartości dla użytkownika, a nie uraz psychologiczny, przez co wiele manipulacyjnych praktyk nie podlega zakazom tej ustawy. Unijny Akt o Usługach Cyfrowych (Digital Services Act) wprowadza kodeks postępowania dla platform cyfrowych i zawiera szczególne zabezpieczenia dla nieletnich, lecz skupia się głównie na nielegalnych treściach i dezinformacji, a nie szeroko pojętej manipulacji AI. Powstaje więc luka regulacyjna, w której wiele firm spoza obszaru platform cyfrowych może stosować manipulacyjne praktyki AI bez jasnych ograniczeń prawnych. Skuteczna regulacja wymaga ram odpowiedzialności nakładających na organizacje obowiązek rozliczania się z przypadków manipulacji AI, przy wzmocnieniu uprawnień organów ochrony konsumentów do prowadzenia dochodzeń i egzekwowania przepisów. Organy te potrzebują zwiększonych możliwości obliczeniowych do eksperymentowania z badanymi systemami AI, by móc właściwie ocenić ewentualne naruszenia. Koordynacja międzynarodowa jest kluczowa, ponieważ systemy AI działają globalnie, a presja konkurencyjna może zachęcać do przenoszenia działalności do jurysdykcji o słabszych zabezpieczeniach. Kampanie informacyjne i edukacyjne, zwłaszcza skierowane do młodzieży, mogą pomóc użytkownikom rozpoznawać i przeciwdziałać manipulacjom AI.
Wraz ze wzrostem zaawansowania systemów AI i ich coraz powszechniejszym wdrażaniem, organizacje potrzebują pełnego wglądu w to, jak ich systemy AI są wykorzystywane i czy nie są manipulowane. Platformy monitorujące AI, takie jak AmICited.com, zapewniają kluczową infrastrukturę do śledzenia, jak systemy AI odnoszą się do informacji i je wykorzystują, wykrywając, gdy wyniki AI odbiegają od oczekiwanego wzorca i identyfikując potencjalne próby manipulacji w czasie rzeczywistym. Narzędzia te oferują natychmiastowy wgląd w zachowanie systemów AI, dzięki czemu zespoły ds. bezpieczeństwa mogą wykrywać anomalie świadczące o atakach adversarialnych czy kompromitacji systemu. Monitorując sposób, w jaki systemy AI są wykorzystywane na różnych platformach — od GPT, przez Perplexity, po Google AI Overviews — organizacje zyskują wgląd w potencjalne próby manipulacji i mogą szybko reagować na zagrożenia. Kompleksowy monitoring pozwala zrozumieć pełen zakres ekspozycji na ryzyka AI, identyfikując tzw. shadow AI wdrażane bez odpowiednich zabezpieczeń. Integracja z szeroko pojętymi ramami bezpieczeństwa gwarantuje, że monitoring AI jest elementem spójnej strategii obronnej, a nie odizolowanym narzędziem. Dla organizacji poważnie traktujących ochronę inwestycji w AI i zaufania użytkowników, narzędzia monitorujące nie są opcjonalne — stanowią niezbędną infrastrukturę do wykrywania i zapobiegania manipulacjom AI zanim wyrządzą poważne szkody.
Same środki techniczne nie wystarczą, by zapobiec manipulacjom AI; organizacje muszą kształtować kulturę bezpieczeństwa, w której wszyscy — od zarządu po inżynierów — przedkładają bezpieczeństwo i etykę nad szybkość i zysk. Wymaga to zaangażowania liderów do przeznaczania znaczących środków na badania nad bezpieczeństwem i testy, nawet jeśli spowalnia to rozwój produktu. Model sera szwajcarskiego w bezpieczeństwie organizacyjnym — gdzie wiele niedoskonałych warstw zabezpieczeń wzajemnie się uzupełnia — doskonale odnosi się do systemów AI. Żadna pojedyncza metoda obrony nie jest doskonała, lecz nakładające się zabezpieczenia budują odporność. Mechanizmy nadzoru człowieka muszą być wbudowane na każdym etapie cyklu życia AI, od rozwoju po wdrożenie, z udziałem wykwalifikowanego personelu przeglądającego kluczowe decyzje i wykrywającego podejrzane wzorce. Wymogi transparentności powinny być uwzględnione już na etapie projektowania systemu, a nie dodawane później, tak by interesariusze rozumieli sposób działania AI i wykorzystywane dane. Mechanizmy odpowiedzialności muszą jasno przypisywać odpowiedzialność za zachowanie systemu AI, z konsekwencjami za zaniedbania czy nadużycia. Ćwiczenia red teamingowe powinny być regularnie prowadzone przez zewnętrznych ekspertów aktywnie próbujących manipulować systemami, a ich wyniki służyć ciągłemu doskonaleniu. Organizacje powinny wdrażać stopniowe procesy wdrożeniowe, w których nowe systemy AI są gruntownie testowane w kontrolowanych warunkach przed szerokim uruchomieniem, z weryfikacją bezpieczeństwa na każdym etapie. Budowanie takiej kultury wymaga zrozumienia, że bezpieczeństwo i innowacyjność nie są sprzeczne — organizacje inwestujące w solidne bezpieczeństwo AI w rzeczywistości wprowadzają innowacje skuteczniej, bo mogą wdrażać rozwiązania z większą pewnością i utrzymywać zaufanie użytkowników w dłuższej perspektywie.
Manipulowanie systemem AI oznacza celowe wykorzystywanie lub eksploatowanie modeli AI w celu uzyskania niezamierzonych wyników, obejścia zabezpieczeń lub wydobycia wrażliwych informacji. Obejmuje to techniki takie jak wstrzykiwanie promptów, ataki adversarialne, zatruwanie danych oraz ekstrakcję modeli. W przeciwieństwie do zwykłych błędów systemowych, manipulowanie to zamierzona próba obejścia zamierzonego działania systemów AI.
Ataki adversarialne są coraz powszechniejsze wraz z rosnącym wykorzystaniem AI w kluczowych zastosowaniach. Badania pokazują, że większość systemów AI posiada luki możliwe do wykorzystania. Dostępność narzędzi i technik ataku oznacza, że zarówno zaawansowani atakujący, jak i zwykli użytkownicy mogą potencjalnie manipulować systemami AI, co czyni ten problem szeroko rozpowszechnionym.
Nie istnieje pojedyncze rozwiązanie dające pełną odporność na manipulacje. Jednak organizacje mogą znacząco zredukować ryzyko dzięki wielowarstwowym zabezpieczeniom takim jak trening adversarialny, walidacja danych, zaciemnianie wyników, ograniczanie liczby zapytań oraz ciągły monitoring. Najskuteczniejsze podejście łączy środki techniczne z praktykami organizacyjnymi i nadzorem człowieka.
Zwykłe błędy AI pojawiają się, gdy systemy popełniają pomyłki z powodu ograniczeń danych treningowych lub architektury modelu. Manipulacja polega na celowym wykorzystaniu luk. Manipulacje są zamierzone, często niewidoczne dla użytkowników i służą korzyściom atakującego kosztem systemu lub jego użytkowników. Zwykłe błędy to niezamierzone awarie systemu.
Konsumenci mogą się chronić, będąc świadomymi zasad działania AI, rozumiejąc, że ich dane są wykorzystywane do wpływania na ich zachowanie oraz zachowując sceptycyzm wobec rekomendacji, które wydają się zbyt idealnie dopasowane. Warto wspierać wymogi transparentności, korzystać z narzędzi chroniących prywatność oraz opowiadać się za silniejszymi regulacjami AI. Kluczowa jest edukacja na temat technik manipulacji AI.
Regulacje są niezbędne do zapobiegania manipulacjom AI na szeroką skalę. Obecne ramy, takie jak unijna AI Act, koncentrują się głównie na szkodach fizycznych i psychologicznych, pomijając w dużej mierze szkody ekonomiczne. Skuteczne regulacje wymagają ram odpowiedzialności, wzmocnienia uprawnień organów ochrony konsumentów, koordynacji międzynarodowej oraz jasnych zasad zakazujących manipulacyjnych praktyk AI przy jednoczesnym utrzymaniu bodźców do innowacji.
Platformy monitorujące AI zapewniają wgląd w czasie rzeczywistym w zachowanie systemów AI i ich wykorzystanie. Wykrywają anomalie mogące świadczyć o atakach adversarialnych, śledzą nietypowe wzorce zapytań sugerujące próbę ekstrakcji modelu i identyfikują przypadki, gdy wyniki systemu odbiegają od oczekiwanych. Taka widoczność umożliwia szybką reakcję na zagrożenia zanim dojdzie do poważnych szkód.
Koszty obejmują bezpośrednie straty finansowe spowodowane oszustwami i manipulacjami, utratę reputacji po incydentach bezpieczeństwa, odpowiedzialność prawną i grzywny regulacyjne, zakłócenia operacyjne w wyniku wyłączenia systemów oraz długoterminową utratę zaufania użytkowników. Dla konsumentów to także mniejsza wartość usług, naruszenie prywatności oraz wykorzystanie podatności behawioralnych. Całkowity wpływ ekonomiczny jest znaczący i rośnie.
AmICited monitoruje odniesienia do systemów AI i ich wykorzystanie na różnych platformach, pomagając wykrywać próby manipulacji w czasie rzeczywistym. Uzyskaj wgląd w zachowanie swojego AI i wyprzedź zagrożenia.
Dowiedz się, czym jest przycinanie treści dla AI, jak działa, jakie są metody przycinania oraz dlaczego jest kluczowe dla wdrażania wydajnych modeli AI na urząd...
Dowiedz się, jak zgłaszać poprawki do platform AI, takich jak ChatGPT, Perplexity i Claude. Poznaj mechanizmy korekty, procesy zgłaszania opinii oraz strategie ...
Poznaj skuteczne strategie identyfikowania, monitorowania i korygowania nieprawidłowych informacji o Twojej marce w odpowiedziach generowanych przez AI takich j...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.