Gęstość informacji
Dowiedz się, czym jest gęstość informacji i jak zwiększa ona szansę cytowania przez AI. Poznaj praktyczne techniki optymalizacji treści pod kątem systemów AI, t...
12 min czytania

Dowiedz się, jak tworzyć treści o wysokiej gęstości informacji, które preferują systemy AI. Opanuj hipotezę Jednolitej Gęstości Informacji i zoptymalizuj swoje treści pod kątem AI Overviews, LLM oraz lepszych cytowań.
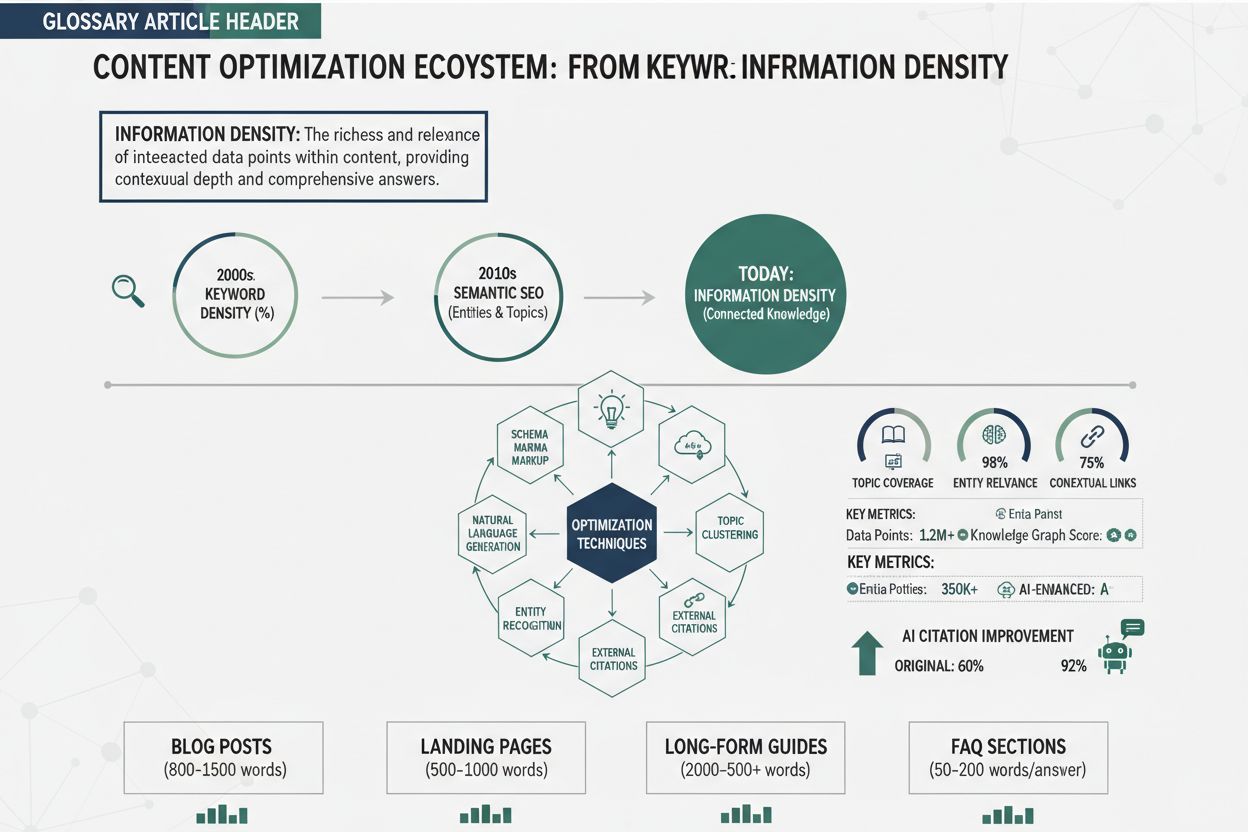
Gęstość informacji odnosi się do koncentracji istotnych, praktycznych wniosków w danym fragmencie treści — czyli tego, ile wartości zawiera każde słowo, zdanie lub akapit. To pojęcie zyskuje coraz większe znaczenie w erze wyszukiwania napędzanego przez AI, zwłaszcza wraz z rozwojem dużych modeli językowych (LLM) i AI Overviews. Hipoteza Jednolitej Gęstości Informacji (UID), zasada językoznawcza poparta najnowszymi badaniami z ArXiv, sugeruje, że zarówno ludzie, jak i systemy AI efektywniej przetwarzają informacje, gdy obciążenie poznawcze jest rozłożone równomiernie w całej treści, a nie skoncentrowane w wybranych fragmentach. Dla systemów AI oceniających treści, gęstość informacji bezpośrednio wpływa na to, jak duża jest szansa, że Twoja treść zostanie wybrana, zacytowana lub wyróżniona w wynikach wyszukiwania AI. Tworząc treści nasycone wartością, nie piszesz tylko dla czytelników — optymalizujesz sposób, w jaki LLM wyodrębniają, syntezują i referują informacje z Twojej pracy.
LLM oceniają gęstość treści poprzez wiele zaawansowanych mechanizmów, które wykraczają daleko poza proste liczenie słów czy częstotliwość słów kluczowych. Analizują metryki treści, wykorzystując obliczenia oparte na entropii, mierząc ile informacji przekazano względem długości tekstu, badając tzw. „jednolitość krokową” — czyli spójność rozkładu informacji w kolejnych fragmentach treści. Gdy LLM przetwarza Twój artykuł, oblicza przyrost informacji na każdym tokenie, oceniając, czy dostarczasz wartość w sposób konsekwentny, czy też niektóre sekcje są zbędne, poboczne lub mało wartościowe. Różne ramy oceny priorytetowo traktują różne aspekty jakości treści, jak pokazuje poniższe porównanie:
| Metryka | Co mierzy | Znaczenie dla AI | Najlepsze zastosowanie |
|---|---|---|---|
| BLEU Score | Precyzja dopasowania słów | Niskie znaczenie dla gęstości | Ocena tłumaczeń maszynowych |
| ROUGE Score | Pokrycie treści | Umiarkowane znaczenie | Jakość streszczeń |
| Perplexity | Przewidywalność sekwencji tekstu | Wysokie znaczenie | Ocena pewności LLM |
| Gęstość informacji | Wartościowa treść na jednostkę długości | Najwyższe znaczenie | Cytowanie i wybór przez AI |
Zrozumienie tych ram oceny LLM pozwala zauważyć, że systemy AI nie szukają tylko treści wyczerpujących temat — zależy im na tym, by wartość informacyjna była utrzymana konsekwentnie w całym tekście, unikając typowego problemu rozwlekania lub „waty”, która rozmywa przekaz.
Różnica między treścią gęstą a rozproszoną fundamentalnie wpływa na sposób, w jaki systemy AI odbierają Twoje materiały. Treść gęsta dostarcza wysoką wartość informacyjną przy minimalnej ilości wypełniaczy, natomiast treść rozproszona zawiera dużo powtórzeń, „waty” lub mało wartościowych rozwinięć. Kluczowe różnice to:
Przykład: rozproszony artykuł o optymalizacji treści AI może poświęcić trzy akapity na wyjaśnianie, czym jest AI, potem kolejne trzy na znaczenie treści, zanim przejdzie do technik optymalizacji. Wersja gęsta założy podstawową wiedzę, naturalnie wplata kontekst i przeznacza proporcjonalnie więcej miejsca na strategie praktyczne. Systemy AI rozpoznają i nagradzają tę efektywność, bo pokazuje ona, że autor dogłębnie rozumie temat i potrafi przekazać go zwięźle.
Gęstość informacji stała się kluczowym sygnałem rankingowym w środowisku wyszukiwania opartym na AI, bezpośrednio wpływając na to, czy Twoja treść pojawi się w AI Overviews i jak często będzie cytowana przez systemy AI. Badania BrightEdge dotyczące algorytmów AI pokazują, że treści wybierane do AI Overviews wykazują około 40% wyższe wskaźniki gęstości informacji niż treści nieuwzględniane, co sugeruje, że AI aktywnie preferuje materiały gęste, nasycone wartością przy syntezowaniu odpowiedzi. Związek między gęstością informacji a wskaźnikiem cytowań jest szczególnie istotny z perspektywy AmICited.com: gdy AI, takie jak Perplexity czy Google AI Overviews, musi odwołać się do źródeł, preferuje treści, które dostarczają skondensowaną wartość, bo to ogranicza potrzebę cytowania wielu źródeł do kompleksowej odpowiedzi. Treści o wysokiej gęstości informacji zwykle zajmują wyższe pozycje, bo lepiej realizują intencje użytkownika — AI rozpoznaje, że gęsta treść daje pełniejsze odpowiedzi, zmniejszając prawdopodobieństwo, że użytkownik będzie musiał szukać dalej. Ponadto, algorytmy AI Overviews specjalnie oceniają, czy treść można skutecznie streścić i zsyntetyzować, a gęsta treść z natury jest łatwiejsza do syntezy, ponieważ zawiera mniej zbędnych elementów do odfiltrowania.
Tworzenie treści nasyconych wartością wymaga świadomych decyzji strukturalnych i redakcyjnych, które priorytetowo traktują przekaz informacji nad liczbę słów. Zacznij od bezwzględnego audytu istniejących materiałów: zidentyfikuj każde zdanie, które nie rozwija głównego argumentu lub nie wnosi wartości praktycznej, a następnie je wyeliminuj lub zintegruj z innymi, spełniającymi kilka celów jednocześnie. Wykorzystuj strukturyzowane formaty treści — listy numerowane, tabele porównawcze, hierarchiczne nagłówki i sekcje definicji — które pozwalają czytelnikom i AI błyskawicznie wyłuskać kluczowe informacje bez konieczności przebijania się przez narrację. Wprowadź zasadę „jedna myśl na akapit”, by każdy fragment miał jasno określony cel i nie rozmywał przekazu pobocznymi informacjami; to bezpośrednio wspiera hipotezę UID, rozkładając obciążenie poznawcze równomiernie. Przy wyjaśnianiu złożonych zagadnień stosuj progresywne ujawnianie informacji: najpierw przedstaw istotę tematu, potem stopniowo dodawaj szczegóły, przykłady i niuanse — to służy zarówno czytelnikom, jak i LLM, które mogą wyodrębniać treść na różnym poziomie szczegółowości. Wprowadzaj konkretne dane liczbowe, statystyki i przykłady zamiast abstrakcyjnych ogólników; „około 40% wyższa gęstość informacji” jest dla AI cenniejsza niż „znacznie wyższa gęstość”. Wreszcie, optymalizuj swój proces optymalizacji treści, traktując gęstość informacji jako kluczowy wskaźnik obok tradycyjnych czynników SEO — sprawdzaj wersje robocze, zadając sobie pytanie, czy dany fragment można skrócić, połączyć lub usunąć bez straty wartości.
Pomiar gęstości informacji wymaga zrozumienia zarówno teorii, jak i praktycznych narzędzi dostępnych dla twórców treści. Najprostszą metodą jest obliczenie wskaźnika gęstości informacji przy użyciu metryk opartych na entropii: podziel całkowitą liczbę informacji (mierzonych w bitach lub za pomocą analizy semantycznej) przez liczbę słów, by określić, ile wartości przekazujesz na jednostkę tekstu. Pomocne będą tu różne narzędzia: platformy NLP analizujące różnorodność semantyczną i rozkład pojęć, narzędzia mierzące czytelność pomagające wykryć powtórzenia oraz własne skrypty w Pythonie (np. z użyciem NLTK) pozwalające obliczyć entropię tekstu. Przykład: jeśli artykuł na 2000 słów zawiera ok. 150 unikalnych pojęć semantycznych równomiernie rozłożonych, będzie miał wyższą gęstość informacji niż artykuł o tej samej długości z 80 pojęciami skupionymi w pierwszej połowie. Możesz też użyć wskaźników zastępczych, np. stosunek unikalnych terminów do liczby słów, średni przyrost informacji na akapit czy liczbę praktycznych wniosków na 500 słów — nie są to idealne miary, ale pokazują kierunek. Badania BrightEdge wskazują, aby monitorować częstotliwość cytowania treści przez AI jako praktyczny dowód na wysoką gęstość informacji; jeśli Twoje materiały regularnie pojawiają się w AI Overviews i są cytowane, prawdopodobnie trafiasz w odpowiedni poziom gęstości.
Najpowszechniejszym błędem w dążeniu do wysokiej gęstości informacji jest nadoptymalizacja, gdzie twórcy próbują tak bardzo zagęścić treść, że staje się ona trudna do czytania lub traci niezbędny kontekst i wyjaśnienia. Często objawia się to upychaniem słów kluczowych pod przykrywką optymalizacji — wstawianiem wielu fraz docelowych w miejsca, gdzie nie pasują, co w rzeczywistości obniża wartość informacyjną i uruchamia filtry AI. Innym problemem jest przeciążenie informacyjne poprzez próbę poruszenia zbyt wielu tematów w jednym materiale; to narusza hipotezę UID, koncentrując nadmierne obciążenie poznawcze w jednych fragmentach, a pozostawiając inne ubogie w treść. Kolejny błąd to zła organizacja strukturalna: nawet najgęstsza treść traci na skuteczności, jeśli nie jest zorganizowana hierarchicznie i brakuje wyraźnych połączeń między pojęciami, przez co zarówno czytelnicy, jak i AI muszą się „przebijać” przez materiał, by wydobyć wartość. Niektórzy twórcy mylą też gęstość ze zwięzłością, tworząc krótkie treści, które jednak nie mają odpowiedniej głębi, by zaspokoić intencje użytkownika lub dostarczyć kontekstu potrzebnego AI do syntezy i cytowania. Ostatecznie, brak utrzymania konsekwentnego rozkładu informacji powoduje nierówne obciążenie poznawcze — np. umieszczenie wszystkich danych i statystyk na początku, a potem już tylko narracji łamie zasadę UID i zmniejsza skuteczność wobec AI.
Zasady gęstości informacji dotyczą wszystkich formatów treści, ale optymalny poziom gęstości i strategia wdrożenia znacząco różnią się w zależności od typu materiału. Posty blogowe zwykle korzystają ze średnio-wysokiej gęstości oraz strategicznego użycia przykładów i wyjaśnień, które ułatwiają przyswajanie skondensowanych pojęć; techniczny wpis blogowy może utrzymać gęstość na poziomie 70-80%, podczas gdy tekst dla początkujących — 50-60%, by ułatwić przyswajanie. Dokumentacja techniczna wymaga najwyższej gęstości informacji, bo czytelnicy oczekują skondensowanej wartości i minimum „waty” — dokumentacja z gęstością powyżej 85% zwykle lepiej wypada w AI, bo łatwiej ją streścić i zacytować. Strony produktowe wymagają odmiennego podejścia, balansując gęstość informacji z elementami perswazyjnymi i doświadczeniem użytkownika; warto skondensować opisy cech i korzyści, ale nadmierna gęstość może przytłoczyć i obniżyć konwersję. Artykuły newsowe i dziennikarskie działają w innych realiach — narracja i budowanie kontekstu czasem wymuszają niższą gęstość, choć AI i tak preferuje newsy, które sprawnie przekazują fakty bez zbędnych komentarzy. Prace naukowe i whitepapers mogą utrzymać bardzo wysoką gęstość, bo odbiorcy oczekują głębi technicznej, choć nawet tu warto dbać o strukturę i podsumowania, by zachować zasady UID. Rozumienie tych różnic pozwala optymalizować gęstość informacji odpowiednio do typu treści, zachowując skuteczność wobec ludzi i AI.
Wraz z rozwojem systemów AI gęstość informacji prawdopodobnie stanie się jeszcze ważniejszym sygnałem rankingowym i cytacyjnym, zwłaszcza w miarę nasilającej się konkurencji o miejsce w AI Overviews. Najnowsze badania sugerują, że przyszłe LLM będą rozwijać coraz bardziej złożone metody oceny jakości i gęstości informacji, wychodząc poza entropię w kierunku zaawansowanej analizy semantycznej, która nagradza nie tylko koncentrację, ale i optymalną strukturę pod kątem syntezy i cytowań. Ewolucja wyszukiwania AI prawdopodobnie będzie sprzyjać twórcom, którzy rozumieją, że rozwój AI nie polega na „oszukiwaniu” algorytmów, lecz na rzeczywistym zaspokajaniu intencji użytkownika — gęste, dobrze ustrukturyzowane treści naturalnie to realizują, oferując AI bogatszy materiał do pracy. Twórcy powinni przygotować się na przyszłość, w której strategia treści coraz silniej stawia na jakość, gdzie artykuł na 1500 słów o wyjątkowej gęstości wyprzedza 5000-słowny tekst o przeciętnej gęstości, a umiejętność zwięzłego komunikowania złożonych idei będzie przewagą konkurencyjną. Organizacje monitorujące swoją obecność w AI Overviews i śledzące wskaźniki cytowań przez platformy takie jak AmICited.com zyskają przewagę, bo bezpośrednio zaobserwują, jak zmiany w gęstości informacji wpływają na widoczność w wyszukiwaniu AI. Ci, którzy już teraz inwestują w zrozumienie i optymalizację gęstości informacji, najlepiej odnajdą się w świecie, gdzie wyszukiwanie AI staje się głównym sposobem odkrywania treści w sieci.

Gęstość informacji odnosi się do koncentracji istotnych, praktycznych wniosków w treści — ile wartości zawiera każde słowo lub zdanie. Systemy AI oceniają ten wskaźnik, by zdecydować, które treści cytować i wyróżniać w AI Overviews. Wyższa gęstość informacji zwykle przekłada się na lepszą widoczność w wynikach wyszukiwania AI.
Hipoteza UID sugeruje, że skuteczna komunikacja utrzymuje stabilny przepływ informacji w całej treści. Systemy AI przetwarzają treści efektywniej, gdy obciążenie poznawcze jest równomiernie rozłożone, a nie skoncentrowane w wybranych sekcjach. Ta zasada bezpośrednio wpływa na to, jak LLM wybierają i cytują Twoje treści.
Treść gęsta dostarcza wysoką wartość informacyjną przy minimalnej ilości wypełniaczy, używając precyzyjnego języka i eliminując powtórzenia. Treść rozproszona zawiera dużo powtórzeń i mało wartościowych rozwinięć. Systemy AI preferują treści gęste, ponieważ łatwiej je syntezować i cytować, ograniczając potrzebę korzystania z wielu źródeł.
Możesz mierzyć gęstość informacji, obliczając stosunek istotnych informacji do całkowitej liczby słów przy użyciu metryk opartych na entropii. Praktyczne podejścia obejmują śledzenie unikalnych pojęć semantycznych na słowo, monitorowanie liczby praktycznych wniosków na 500 słów lub obserwowanie, jak często Twoje treści są cytowane w AI Overviews.
Tak, znacząco. Badania pokazują, że treści wybierane do AI Overviews wykazują około 40% wyższe wskaźniki gęstości informacji niż treści niewybrane. Systemy AI preferencyjnie cytują materiały gęste i pełne wartości, ponieważ dostarczają one kompleksowych odpowiedzi przy mniejszej liczbie odwołań do źródeł.
Najczęstsze błędy to nadmierna optymalizacja obniżająca czytelność, upychanie słów kluczowych maskowane jako gęstość, przeciążenie informacyjne poprzez poruszanie zbyt wielu tematów, słaba organizacja strukturalna, mylenie gęstości z zwięzłością oraz brak utrzymania równomiernego rozkładu informacji w całej treści.
Wymagania dotyczące gęstości informacji zależą od formatu: dokumentacja techniczna korzysta z gęstości powyżej 85%, posty blogowe sprawdzają się przy 70-80%, strony produktowe równoważą gęstość z perswazją na poziomie 50-70%, a artykuły newsowe mogą działać przy niższej gęstości ze względu na wymogi narracyjne. Optymalizuj gęstość odpowiednio do typu Twojej treści.
W miarę jak systemy AI będą coraz bardziej zaawansowane, gęstość informacji prawdopodobnie stanie się jeszcze ważniejszym sygnałem rankingowym. Przyszłe LLM rozwiną zapewne bardziej wyrafinowane metody oceny jakości informacji, faworyzując twórców, którzy rozumieją, że gęsta, dobrze ustrukturyzowana treść naturalnie lepiej realizuje intencje użytkownika.
Śledź, jak systemy AI takie jak ChatGPT, Perplexity czy Google AI Overviews cytują i referują Twoją markę. Uzyskaj wgląd w czasie rzeczywistym w widoczność Twojej marki w AI oraz efektywność treści.
Dowiedz się, czym jest gęstość informacji i jak zwiększa ona szansę cytowania przez AI. Poznaj praktyczne techniki optymalizacji treści pod kątem systemów AI, t...

Dowiedz się, czym jest głębokość treści dla wyszukiwarek AI. Poznaj zasady tworzenia kompleksowych materiałów na potrzeby AI Overviews, ChatGPT, Perplexity i in...
Odkryj, dlaczego gęstość słów kluczowych nie ma już znaczenia w wyszukiwaniu AI. Dowiedz się, co ChatGPT, Perplexity i Google AI Overviews naprawdę biorą pod uw...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.