
PerplexityBot
Dowiedz się czym jest PerplexityBot, internetowy robot Perplexity, który indeksuje treści na potrzeby silnika odpowiedzi AI. Poznaj zasady działania, zgodność z...
6 min czytania

Kompletny przewodnik po robocie PerplexityBot – dowiedz się, jak działa, zarządzaj dostępem, monitoruj cytowania i optymalizuj widoczność w Perplexity AI. Poznaj obawy związane ze stealth crawlingiem i najlepsze praktyki.
PerplexityBot to oficjalny robot internetowy opracowany przez Perplexity AI, stworzony do indeksowania i prezentowania stron w wynikach wyszukiwania Perplexity opartych na AI. W przeciwieństwie do niektórych robotów AI zbierających dane do trenowania dużych modeli językowych, PerplexityBot ma określony cel: odkrywać, indeksować i linkować strony, które dostarczają trafnych odpowiedzi na zapytania użytkowników. Robot działa z jasno określonym stringiem agenta użytkownika (Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)) i publicznie publikuje swoje zakresy adresów IP, umożliwiając właścicielom stron identyfikację i zarządzanie ruchem robota. Zrozumienie działania PerplexityBot jest kluczowe dla właścicieli stron, którzy chcą kontrolować widoczność swoich treści w silniku odpowiedzi Perplexity, zachowując przejrzystość w zakresie dostępu do swoich stron.

PerplexityBot funkcjonuje jak standardowy robot internetowy, stale przeszukując sieć w celu odkrywania i indeksowania stron. Po napotkaniu witryny odczytuje plik robots.txt, aby sprawdzić, do jakich treści ma dostęp, a następnie systematycznie indeksuje strony, by wyodrębnić i zaindeksować ich treści. Zindeksowane informacje zasilają algorytm wyszukiwania Perplexity, który wykorzystuje je do udzielania cytowanych odpowiedzi na zapytania użytkowników. Perplexity faktycznie wykorzystuje dwa różne roboty o innych celach, z osobnymi agentami użytkownika i wzorcami zachowań. Zrozumienie różnicy między tymi robotami jest kluczowe dla właścicieli stron, którzy chcą precyzyjnie zarządzać polityką dostępu.
| Funkcja | PerplexityBot | Perplexity-User |
|---|---|---|
| Cel | Indeksuje strony do wyników wyszukiwania i cytowań | Pobiera konkretne strony w czasie rzeczywistym podczas odpowiadania na pytania użytkowników |
| String agenta użytkownika | PerplexityBot/1.0 | Perplexity-User/1.0 |
| Zgodność z robots.txt | Respektuje dyrektywy disallow w robots.txt | Zazwyczaj ignoruje robots.txt (żądania inicjowane przez użytkownika) |
| Zakresy IP | Opublikowane na perplexity.com/perplexitybot.json | Opublikowane na perplexity.com/perplexity-user.json |
| Częstotliwość | Ciągłe, zaplanowane indeksowanie | Na żądanie, wywoływane przez zapytania użytkownika |
| Zastosowanie | Budowa indeksu wyszukiwania | Pobieranie aktualnych informacji do odpowiedzi |
Rozróżnienie tych dwóch robotów jest istotne, ponieważ można nimi zarządzać osobno za pomocą reguł robots.txt i konfiguracji firewalla. Regularne indeksowanie PerplexityBot respektuje Twoje dyrektywy w robots.txt, podczas gdy Perplexity-User może je omijać, pobierając treści w odpowiedzi na konkretne żądanie użytkownika. Oba roboty publikują swoje zakresy adresów IP publicznie, umożliwiając właścicielom stron wdrożenie precyzyjnych reguł firewalla, jeśli chcą blokować lub zezwalać na określony ruch robota.
W 2025 roku Cloudflare opublikował szczegółowe dochodzenie wykazujące, że Perplexity używała niezadeklarowanych robotów do omijania ograniczeń stron internetowych. Według ich ustaleń, gdy oficjalne roboty (PerplexityBot i Perplexity-User) były blokowane przez robots.txt lub zasady firewalla, firma wdrażała dodatkowe roboty z ogólnymi agentami użytkownika przeglądarki (np. Chrome na macOS) oraz rotującymi adresami IP z różnych ASNum, aby nadal uzyskiwać dostęp do zastrzeżonych treści. Takie zachowanie stoi w sprzeczności ze standardami indeksowania opisanymi w RFC 9309, które kładą nacisk na przejrzystość i respektowanie preferencji właścicieli stron. Test polegał na utworzeniu nowych domen z wyraźnymi regułami disallow w robots.txt, jednak Perplexity nadal dostarczała szczegółowe informacje o ich treści, co sugeruje użycie niezadeklarowanych źródeł danych lub technik stealth crawlingu.
Jest to wyraźny kontrast wobec podejścia OpenAI do zarządzania robotami. GPTBot od OpenAI wyraźnie się identyfikuje, respektuje robots.txt i przestaje indeksować, gdy napotka blokadę — dowodząc, że przejrzyste i etyczne zachowanie robota jest możliwe i praktyczne. Ustalenia Cloudflare wzbudziły poważne obawy co do rzeczywistego przestrzegania przez Perplexity deklaracji o respektowaniu preferencji właścicieli stron, zwłaszcza dla tych, którzy wyraźnie nie chcą, by ich treści były indeksowane lub cytowane przez systemy AI. Dla właścicieli stron zaniepokojonych kontrolą i przejrzystością treści, ta kontrowersja podkreśla wagę monitorowania zachowania robotów i stosowania wielowarstwowej ochrony (robots.txt, reguły WAF i blokowanie IP), by skutecznie egzekwować swoje preferencje.
Decyzja o dopuszczeniu PerplexityBot na swojej stronie wymaga rozważenia kilku istotnych czynników. Z jednej strony umożliwienie indeksowania niesie istotne korzyści: Twoje treści mogą być cytowane w odpowiedziach Perplexity, co potencjalnie przekłada się na ruch referencyjny od użytkowników widzących Twoją stronę w generowanych odpowiedziach AI. Z drugiej strony pojawiają się uzasadnione obawy dotyczące zużycia przepustowości, kopiowania treści i utraty kontroli nad sposobem wykorzystania Twoich informacji. Ostateczna decyzja zależy od celów biznesowych, strategii treści i komfortu związanego z udostępnianiem danych systemom AI.
Kluczowe aspekty przy zezwalaniu PerplexityBot:
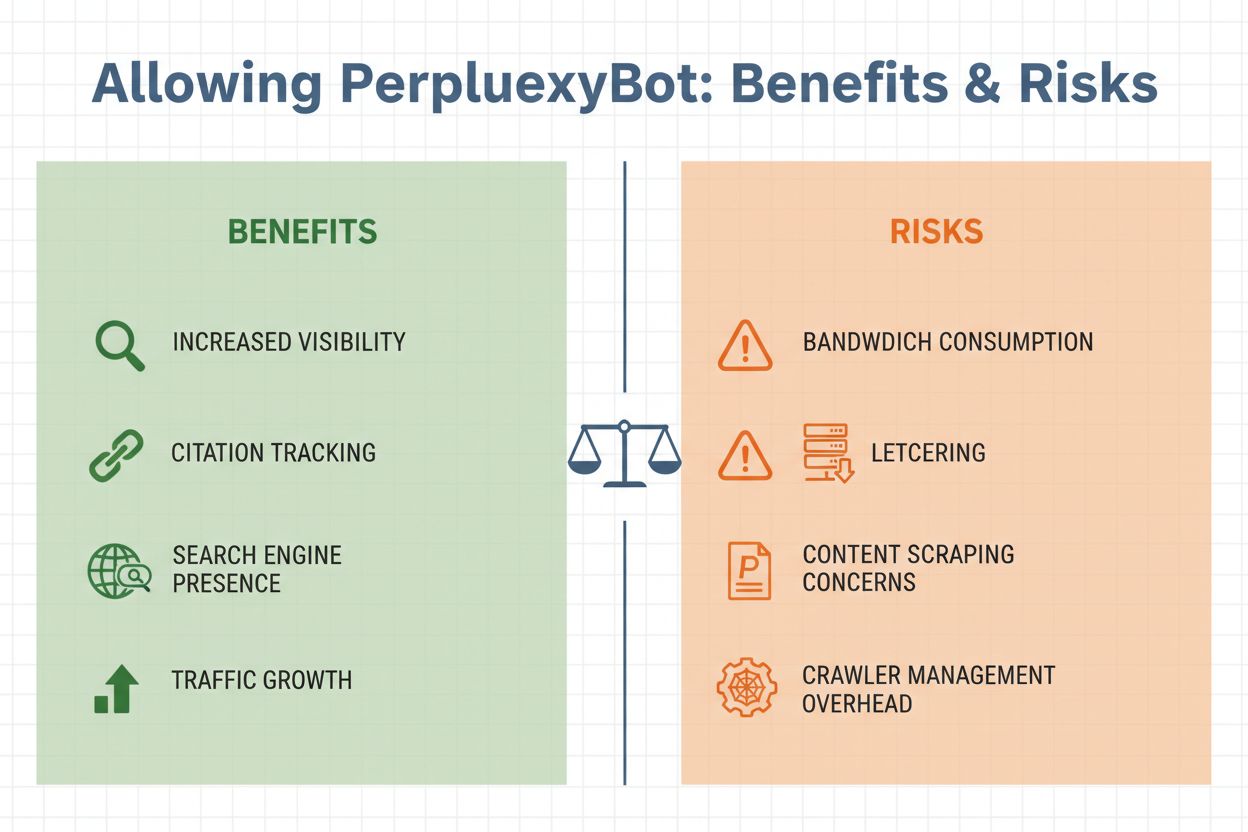
Zarządzanie dostępem PerplexityBot jest proste i można je realizować na kilka sposobów, zależnie od infrastruktury technicznej i wymagań. Najczęściej stosuje się plik robots.txt, który przekazuje jasne dyrektywy wszystkim dobrze zachowującym się robotom, do jakich treści mają dostęp.
Aby zezwolić PerplexityBot w pliku robots.txt:
User-agent: PerplexityBot
Allow: /
Aby zablokować PerplexityBot w pliku robots.txt:
User-agent: PerplexityBot
Disallow: /
Aby zablokować PerplexityBot tylko w określonych katalogach, a zezwolić w innych, możesz użyć bardziej szczegółowych reguł:
User-agent: PerplexityBot
Disallow: /admin/
Disallow: /private/
Allow: /public/
W celu uzyskania bardziej zaawansowanej ochrony, szczególnie w przypadku obaw o stealth crawling, wdroż reguły firewall na poziomie Web Application Firewall (WAF). Użytkownicy Cloudflare WAF mogą stworzyć niestandardowe reguły blokujące PerplexityBot poprzez połączenie warunków dla agenta użytkownika i adresu IP:
Użytkownicy AWS WAF powinni utworzyć zestawy IP na podstawie opublikowanych zakresów IP PerplexityBot z https://www.perplexity.com/perplexitybot.json, a następnie reguły dopasowujące zarówno zestaw IP, jak i string agenta użytkownika PerplexityBot. Zawsze korzystaj z oficjalnych zakresów IP publikowanych przez Perplexity, ponieważ są one regularnie aktualizowane i stanowią autorytatywne źródło dla legalnego ruchu robota.
Po podjęciu decyzji o polityce wobec PerplexityBot warto monitorować faktyczną aktywność robota, aby zweryfikować skuteczność reguł i zrozumieć wpływ na infrastrukturę. Żądania PerplexityBot można zidentyfikować w logach serwera po charakterystycznym stringu agenta użytkownika: PerplexityBot/1.0 lub ogólnym stringu przeglądarki, jeśli występuje stealth crawling. Większość platform analitycznych i narzędzi do analizy logów umożliwia filtrowanie ruchu według agenta użytkownika, co pozwala łatwo wyodrębnić żądania PerplexityBot i analizować ich wzorce.
Kluczowe metryki do monitorowania to częstotliwość odwiedzin robota, strony, które są odwiedzane, oraz wykorzystana przepustowość. Jeśli zauważysz nietypowe wzorce — jak szybkie indeksowanie poufnych stron lub żądania z adresów IP spoza opublikowanych zakresów Perplexity — może to świadczyć o stealth crawlingu. Poza podstawowym monitoringiem ruchu, specjalistyczne narzędzia takie jak AmICited.com dostarczają głębszych informacji o cytowaniach Twoich treści przez AI, w tym Perplexity. AmICited śledzi wzmianki o Twojej marce i treściach w odpowiedziach generowanych przez AI, pozwalając zmierzyć faktyczny wpływ zezwolenia na PerplexityBot i zrozumieć, które strony są najcenniejsze dla systemów AI. Te dane pomagają podejmować świadome decyzje dotyczące przyszłej polityki zarządzania robotami i strategii optymalizacji treści.
Efektywne zarządzanie PerplexityBot wymaga wyważonego podejścia, które chroni Twoje interesy, ale także pozwala korzystać z korzyści widoczności w AI. Po pierwsze, określ jasną politykę zgodną z celami biznesowymi: zdecyduj, czy potencjalny ruch i ekspozycja marki dzięki cytowaniom Perplexity przewyższają obawy o przepustowość i kontrolę nad treścią. Udokumentuj decyzję w pliku robots.txt i przekaż ją zespołowi, by wszyscy znali strategię zarządzania robotami.
Po drugie, wdrażaj ochronę warstwową, jeśli zdecydujesz się blokować PerplexityBot. Nie polegaj tylko na robots.txt, bo kontrowersje wokół stealth crawlingu pokazują, że niektóre roboty mogą ignorować te dyrektywy. Połącz reguły robots.txt z regułami WAF i blokowaniem IP dla ochrony w modelu defense-in-depth. Po trzecie, bądź na bieżąco z zachowaniem robotów poprzez regularną analizę logów i śledzenie branżowych dyskusji na temat etyki i przejrzystości AI. Sytuacja ewoluuje bardzo szybko i mogą pojawić się nowe roboty lub taktyki wymagające zmian polityki.
Na koniec, wykorzystuj narzędzia monitorujące strategicznie, aby mierzyć rzeczywisty wpływ swoich decyzji. Narzędzia takie jak AmICited.com dają wgląd w to, jak systemy AI cytują Twoje treści, pomagając ocenić, czy zezwolenie na PerplexityBot przynosi oczekiwane korzyści. Jeśli zezwalasz na robota, te dane pozwalają optymalizować treści pod kątem cytowań AI. Jeśli blokujesz, monitoring potwierdza skuteczność blokad i brak obecności Twoich treści w wynikach Perplexity inną drogą.
PerplexityBot działa w środowisku pełnym różnych robotów AI, z których każdy ma inne cele i standardy przejrzystości. GPTBot od OpenAI jest powszechnie uznawany za wzór przejrzystego zachowania robota — jasno się identyfikuje, respektuje robots.txt i przestaje indeksować w razie blokady. Roboty Google dla AI Overviews i innych funkcji AI również zachowują przejrzystość i respektują preferencje właścicieli stron. W przeciwieństwie do tego, udokumentowany przez Cloudflare stealth crawling Perplexity stanowi niepokojące odejście od tych standardów.
Kluczowa różnica to przejrzystość i szacunek dla preferencji właścicieli stron. Dobrze zachowujące się roboty, jak GPTBot, ułatwiają właścicielom stron zrozumienie swoich działań i zapewniają jasne mechanizmy kontroli. Wykorzystanie przez Perplexity niezadeklarowanych robotów i rotacji IP w celu obejścia ograniczeń podważa to zaufanie. Dla właścicieli stron oznacza to konieczność większej ostrożności wobec deklaracji Perplexity i wdrożenia silniejszych technicznych zabezpieczeń, jeśli naprawdę chcą mieć pewność, że ich preferencje są respektowane. W miarę dojrzewania ekosystemu robotów AI można spodziewać się rosnącej presji na firmy takie jak Perplexity, by przyjęły bardziej przejrzyste, etyczne praktyki zgodne z ustalonymi standardami sieci i szanowały autonomię właścicieli stron.
PerplexityBot to oficjalny robot internetowy Perplexity AI, zaprojektowany do indeksowania stron i prezentowania ich w wynikach wyszukiwania opartych na AI Perplexity. W przeciwieństwie do niektórych robotów AI zbierających dane do trenowania, PerplexityBot służy do odkrywania i linkowania stron, które dostarczają trafnych odpowiedzi na zapytania użytkowników. Działa transparentnie, publikując string agenta użytkownika oraz zakresy adresów IP.
Nie. Według oficjalnej dokumentacji Perplexity, PerplexityBot został stworzony do prezentowania i linkowania stron w wynikach wyszukiwania Perplexity. Nie jest wykorzystywany do pobierania treści na potrzeby modeli bazowych AI ani do celów treningowych. Jego jedyną funkcją jest indeksowanie treści do silnika odpowiedzi Perplexity.
Możesz zablokować PerplexityBot, dodając do pliku robots.txt wpis 'User-agent: PerplexityBot' oraz 'Disallow: /', aby całkowicie uniemożliwić dostęp. Dla silniejszej ochrony wdroż reguły WAF na Cloudflare lub AWS WAF, które blokują żądania pasujące do agenta użytkownika PerplexityBot oraz jego zakresów IP. Pamiętaj jednak, że stealth crawling może obejść te zabezpieczenia.
Perplexity publikuje oficjalne zakresy adresów IP dla PerplexityBot pod adresem https://www.perplexity.com/perplexitybot.json oraz dla Perplexity-User pod https://www.perplexity.com/perplexity-user.json. Zakresy te są regularnie aktualizowane i powinny być autorytatywnym źródłem do konfiguracji firewalla i WAF. Zawsze korzystaj z oficjalnych endpointów, a nie z nieaktualnych list IP.
PerplexityBot deklaruje przestrzeganie dyrektyw robots.txt, jednak dochodzenie Cloudflare z 2025 roku wykazało dowody na stealth crawling z użyciem niezadeklarowanych agentów użytkownika i rotujących adresów IP w celu obejścia ograniczeń robots.txt. Oficjalny robot PerplexityBot powinien przestrzegać Twoich zasad robots.txt, lecz jeśli chcesz mieć pewność, wdroż dodatkowe zabezpieczenia WAF.
Wykorzystanie przepustowości zależy od wielkości i ilości treści na stronie. PerplexityBot dokonuje ciągłego, zaplanowanego indeksowania, podobnie jak robot Google. Strony o dużym ruchu mogą zauważyć wymierne zużycie transferu. Rzeczywiste zużycie możesz monitorować, filtrując logi serwera pod kątem żądań PerplexityBot i analizując ilość przesłanych danych.
Tak. Możesz ręcznie wyszukiwać w Perplexity zapytania powiązane z Twoimi treściami, aby sprawdzić, czy Twoja strona jest cytowana w odpowiedziach. Dla szerszego monitoringu skorzystaj z narzędzi takich jak AmICited.com, które śledzą obecność Twojej marki i treści na platformach AI, w tym Perplexity, dostarczając wglądu w czasie rzeczywistym w widoczność i schematy cytowań.
PerplexityBot to zaplanowany robot, który stale indeksuje strony do indeksu wyszukiwarki Perplexity. Perplexity-User jest uruchamiany na żądanie, gdy użytkownicy zadają pytania i Perplexity musi pobrać konkretne strony w czasie rzeczywistym. PerplexityBot respektuje robots.txt, natomiast Perplexity-User zazwyczaj je ignoruje, ponieważ odpowiada na zapytania użytkowników. Oba mają oddzielne stringi agenta użytkownika i zakresy IP.
Śledź, jak Perplexity i inne platformy AI cytują Twoją markę. Uzyskaj wgląd w czasie rzeczywistym w swoją widoczność w AI i zoptymalizuj strategię treści pod kątem maksymalnego efektu w generatywnych wyszukiwarkach.
Dowiedz się czym jest PerplexityBot, internetowy robot Perplexity, który indeksuje treści na potrzeby silnika odpowiedzi AI. Poznaj zasady działania, zgodność z...

Perplexity AI to wyszukiwarka odpowiedzi z SI, która łączy wyszukiwanie w czasie rzeczywistym z LLM, aby dostarczać cytowane, dokładne odpowiedzi. Dowiedz się, ...
Dowiedz się, jak skonfigurować robots.txt, aby kontrolować dostęp botów AI, w tym GPTBot, ClaudeBot i Perplexity. Zarządzaj widocznością swojej marki w odpowied...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.