
Różnicowany dostęp dla crawlerów
Dowiedz się, jak selektywnie zezwalać lub blokować crawlery AI w oparciu o cele biznesowe. Wdrażaj różnicowany dostęp crawlerów, by chronić treści i zachować wi...
8 min czytania

Dowiedz się, jak używać robots.txt do kontroli, które boty AI mają dostęp do Twoich treści. Kompletny przewodnik po blokowaniu GPTBot, ClaudeBot i innych crawlerów AI z praktycznymi przykładami i strategiami konfiguracji.
Krajobraz crawlowania stron www zasadniczo zmienił się w ciągu ostatnich dwóch lat, wychodząc poza znane terytorium indeksowania wyszukiwarek w kierunku skomplikowanego świata trenowania modeli AI. Podczas gdy Googlebot był od lat przewidywalnym gościem na stronach wydawców, nowa generacja crawlerów pojawia się z zupełnie innymi intencjami i wzorcami konsumpcji. GPTBot od OpenAI ma stosunek crawl-to-refer ok. 1700:1, czyli przegląda 1700 stron, aby wygenerować jedno przekierowanie na Twoją stronę, podczas gdy ClaudeBot od Anthropic działa na jeszcze bardziej ekstremalnym poziomie 73 000:1—diametralnie inaczej niż Google, gdzie stosunek wynosi 14:1 i crawl oznacza realny ruch. Ta fundamentalna różnica powoduje, że dla twórców treści pojawia się pilna decyzja biznesowa: pozwolenie tym botom na nieograniczony dostęp to szkolenie modeli AI, które konkurują z Twoim ruchem i przychodami, podczas gdy Twoja strona otrzymuje minimalne wynagrodzenie lub ruch w zamian. Wydawcy muszą teraz aktywnie decydować, czy propozycja wartości dostępu botów AI odpowiada ich modelowi biznesowemu, co sprawia, że konfiguracja robots.txt staje się nie tylko kwestią techniczną, ale strategicznym imperatywem biznesowym.
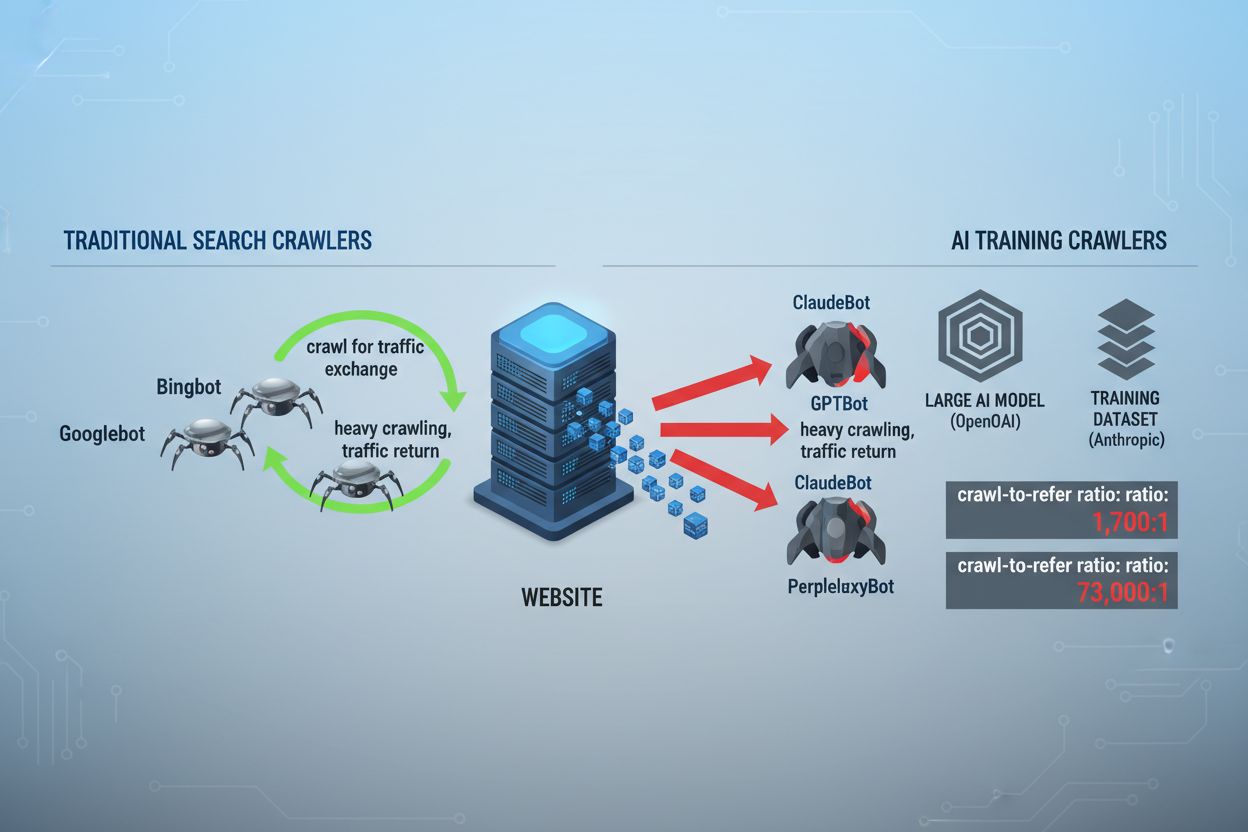
Crawlery AI działają w trzech odmiennych kategoriach, z których każda służy innym celom i wymaga odmiennych strategii blokowania. Crawlery trenujące służą do pobierania dużych ilości treści na potrzeby trenowania podstawowych modeli AI—należą do nich GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Google), PerplexityBot (Perplexity), Meta-ExternalAgent (Meta), Applebot-Extended (Apple) oraz nowi gracze jak Amazonbot, Bytespider i cohere-ai. Crawlery wyszukiwawcze z kolei służą do zasilania wyszukiwarek AI i zwykle kierują ruch do wydawców; obejmują one OAI-SearchBot (OpenAI), Claude-Web (Anthropic) oraz funkcję wyszukiwania Perplexity. Trzecią kategorię stanowią agenty wywoływane przez użytkownika, które pobierają treść na żądanie, gdy użytkownik wyraźnie o nią poprosi, np. ChatGPT-User czy Claude-Web uruchamiane przez użytkowników końcowych. Zrozumienie tej klasyfikacji jest kluczowe, ponieważ strategia blokowania powinna odzwierciedlać Twoje priorytety biznesowe—możesz chcieć dopuścić crawlery wyszukiwawcze generujące ruch, ale blokować crawlery trenujące, które konsumują treści bez wynagrodzenia. Każda duża firma AI utrzymuje własną flotę specjalistycznych crawlerów, a różnice między nimi sprowadzają się często do konkretnego ciągu User-Agent, co czyni precyzyjną identyfikację i blokowanie kluczowym elementem skutecznej konfiguracji robots.txt.
| Firma | Crawler trenujący | Crawler wyszukiwawczy | Agent wywoływany przez użytkownika |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Używa standardowego Googlebot) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Utrzymanie dokładnej, aktualnej listy user agentów botów AI jest niezbędne do skutecznej konfiguracji robots.txt, a krajobraz ten zmienia się bardzo dynamicznie wraz z pojawianiem się nowych modeli i ewolucją strategii crawlów poszczególnych firm. Najważniejsze crawlery trenujące, o których należy pamiętać, to GPTBot (główny crawler szkoleniowy OpenAI), ClaudeBot (treningowy crawler Anthropic), anthropic-ai (alternatywny identyfikator Anthropic), Google-Extended (token treningowy Google), PerplexityBot (crawler Perplexity), Meta-ExternalAgent (treningowy crawler Meta), Applebot-Extended (wariant AI Apple), CCBot (bot Common Crawl), Amazonbot (crawler Amazon), Bytespider (crawler ByteDance), cohere-ai (bot treningowy Cohere), DuckAssistBot (crawler asystenta AI DuckDuckGo) oraz YouBot (crawler You.com). Crawlery ukierunkowane na wyszukiwanie, które zazwyczaj generują ruch, to OAI-SearchBot, Claude-Web oraz PerplexityBot w trybie search. Podstawowym wyzwaniem jest to, że ta lista nie jest statyczna—nowe firmy AI pojawiają się regularnie, istniejące firmy wprowadzają nowe crawlery do nowych produktów, a ciągi user agentów czasem się zmieniają lub rozszerzają. Wydawcy powinni traktować robots.txt jako dokument żywy, wymagający przeglądu i aktualizacji co kwartał, a także rozważyć subskrypcję branżowych źródeł śledzących crawlery lub monitorowanie logów serwera pod kątem nieznanych user agentów, które mogą oznaczać pojawienie się nowych crawlerów AI. Zaniedbanie aktualizacji listy user agentów może oznaczać przypadkowe wpuszczenie nowych crawlerów trenujących, które chciałeś zablokować, albo niepotrzebne blokowanie legalnych crawlerów wyszukiwawczych, które mogłyby generować wartościowy ruch referencyjny.
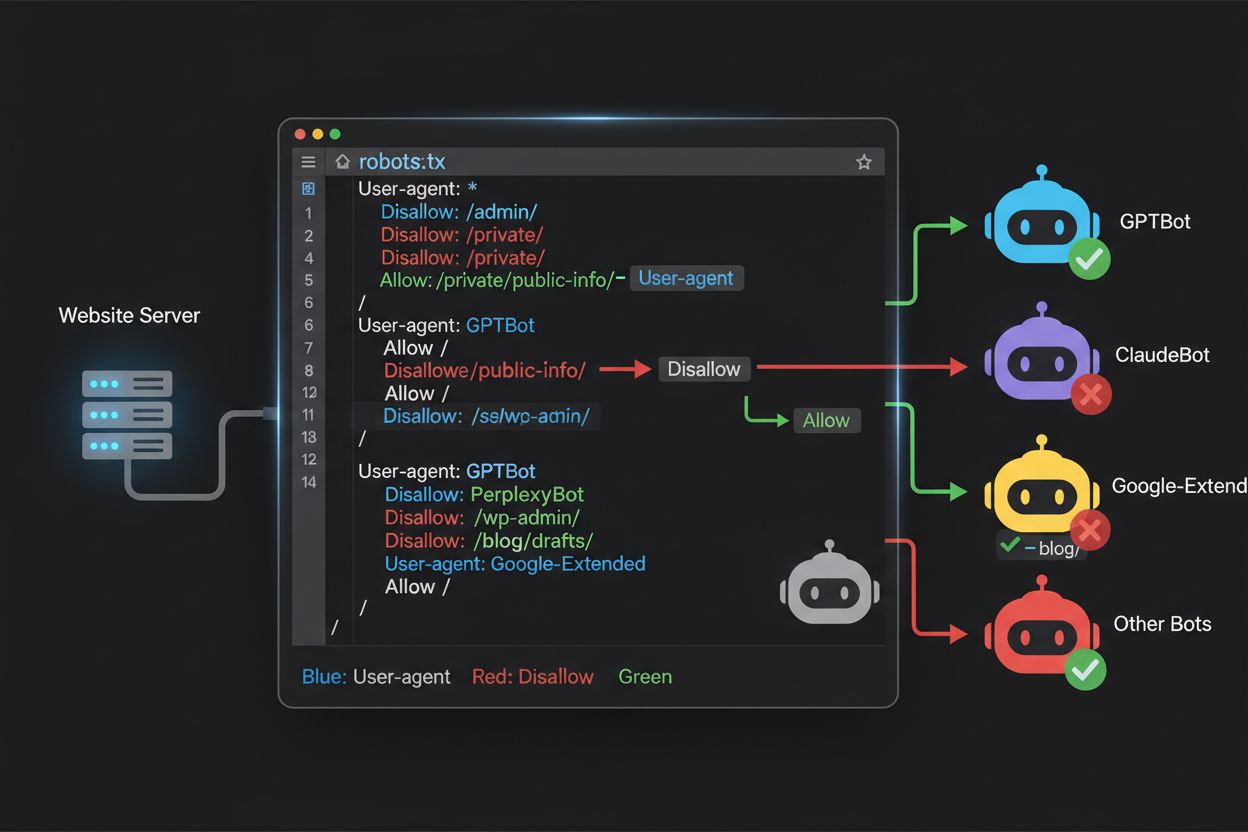
Plik robots.txt, umieszczony w katalogu głównym domeny (twojadomena.com/robots.txt), wykorzystuje prostą składnię do komunikowania preferencji crawlów botom, które respektują ten protokół. Każda reguła zaczyna się od dyrektywy User-Agent określającej, do którego bota odnosi się dana reguła, po której następuje jedna lub więcej dyrektyw Disallow wskazujących, do których ścieżek bot nie ma dostępu. Aby zablokować wszystkie główne crawlery trenujące AI, pozostawiając dostęp crawlerom wyszukiwarek, należy utworzyć osobne bloki User-Agent dla każdego crawlera szkoleniowego, którego chcesz wykluczyć: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended i inne, każda z dyrektywą “Disallow: /” uniemożliwiającą dostęp do jakiejkolwiek treści Twojej strony. Jednocześnie należy upewnić się, że legalne crawlery wyszukiwarek, takie jak Googlebot, Bingbot i warianty wyszukiwawcze jak OAI-SearchBot, nie są blokowane, aby mogły dalej indeksować Twoje treści i generować ruch. Poprawnie skonfigurowany robots.txt powinien także zawierać odwołanie do mapy witryny (Sitemap), co pomaga wyszukiwarkom skutecznie odkrywać i indeksować Twoje treści. Znaczenie poprawnej konfiguracji jest ogromne—jeden błąd składniowy, źle umieszczony znak lub nieprawidłowy user agent mogą uczynić całą strategię blokowania nieskuteczną, pozwalając niechcianym crawlerom na dostęp do treści i/lub blokując legalne źródła ruchu. Przetestowanie konfiguracji przed wdrożeniem jest zatem nie opcją, lecz koniecznością, aby robots.txt spełniał swoje zadanie.
# Blokuj crawlery trenujące AI
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Zezwól tradycyjnym wyszukiwarkom
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Odwołanie do mapy witryny
Sitemap: https://yoursite.com/sitemap.xml
Wielu wydawców staje przed subtelną decyzją: chcą zachować widoczność w wynikach wyszukiwania opartych na AI i otrzymywać ruch referencyjny z tych platform, ale nie chcą, aby ich treści były wykorzystywane do trenowania podstawowych modeli AI, które mogą z nimi konkurować. Ta selektywna strategia blokowania wymaga rozróżnienia crawlerów wyszukiwawczych i trenujących od tej samej firmy—na przykład zezwalając na dostęp OAI-SearchBot (który zasila funkcję wyszukiwania ChatGPT i generuje ruch) przy jednoczesnym blokowaniu GPTBot (który trenuje model bazowy). Podobnie możesz dopuścić crawler wyszukiwawczy PerplexityBot, a blokować jego operacje treningowe, lub dopuścić Claude-Web dla zapytań użytkowników, a blokować działania treningowe ClaudeBot. Racja biznesowa jest jasna: crawlery wyszukiwawcze pracują przy dużo niższych stosunkach crawl-to-refer, bo służą generowaniu ruchu na Twoją stronę, podczas gdy crawlery trenujące konsumują treści na masową skalę z minimalną wzajemną korzyścią. Takie podejście wymaga precyzyjnej konfiguracji i ciągłego monitorowania, ponieważ firmy czasem zmieniają strategie crawlerów lub wprowadzają nowe user agenty, które zacierają granicę między wyszukiwaniem a trenowaniem. Wydawcy stosujący tę strategię powinni regularnie analizować logi serwera, by upewnić się, że zamierzone crawlery mają dostęp do treści, a zablokowane są skutecznie wykluczane, dostosowując robots.txt wraz z ewolucją rynku AI.
# Zezwól na crawlery wyszukiwawcze AI
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Blokuj crawlery trenujące
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Nawet doświadczeni webmasterzy często popełniają błędy, które całkowicie niweczą strategię robots.txt, pozostawiając treści podatne na dostęp crawlerów, które miały być zablokowane. Pierwszym częstym błędem jest tworzenie pojedynczych linii User-Agent bez odpowiadającej dyrektywy Disallow—np. wpisanie “User-Agent: GPTBot” i natychmiastowe rozpoczęcie nowej reguły bez określenia, czego GPTBot nie powinien przeglądać, co oznacza brak jakiejkolwiek blokady dla tego bota. Drugim błędem jest nieprawidłowe umieszczenie lub nazwanie pliku lub błędy wielkości liter; plik musi nazywać się dokładnie “robots.txt” (małymi literami), być w katalogu głównym domeny i być obsługiwany z kodem 200 HTTP—umieszczenie go w podkatalogu lub nazwanie “Robots.txt” lub “robots.TXT” powoduje, że crawlerzy go nie widzą. Trzecim błędem są puste linie wewnątrz bloku reguł, które przez większość parserów robots.txt interpretowane są jako zakończenie danej reguły, przez co kolejne dyrektywy są ignorowane lub źle przypisywane. Czwarty błąd dotyczy wielkości liter w ścieżkach URL; nazwy user agentów są nieczułe na wielkość liter, ale ścieżki w Disallow są wrażliwe, więc “Disallow: /Admin” nie zablokuje “/admin” ani “/ADMIN”. Piąty błąd to błędne użycie wildcardów—gwiazdka (*) dopasowuje dowolny ciąg znaków, ale wielu wydawców myli się, pisząc np. “Disallow: .pdf” zamiast “Disallow: /.pdf” lub “Disallow: /*pdf”, by poprawnie zablokować rozszerzenia plików. Dodatkowo niektórzy tworzą zbyt skomplikowane reguły z wieloma sprzecznymi Disallow lub nie uwzględniają parametrów URL, co prowadzi do blokowania legalnych treści lub pozostawienia przypadkowo otwartych zasobów. Przetestowanie konfiguracji za pomocą dedykowanych walidatorów robots.txt przed wdrożeniem pozwala wykryć te błędy zanim odbiją się na dostępności i indeksowaniu strony.
Najczęstsze błędy:
Google-Extended to szczególny przypadek w konfiguracji robots.txt, ponieważ działa jako token kontrolny, a nie tradycyjny crawler. Zrozumienie tej różnicy jest kluczowe dla świadomych decyzji blokowania. W przeciwieństwie do Googlebota, który przegląda Twoją witrynę w celu indeksowania w wyszukiwarce Google, Google-Extended to sygnał kontrolujący, czy Twoje treści mogą być używane do trenowania modeli Gemini AI Google i zasilania funkcji AI Overviews w wynikach wyszukiwania. Blokowanie Google-Extended uniemożliwia wykorzystanie Twoich treści do szkolenia Gemini i tworzenia AI Overview, ale nie wpływa na widoczność w tradycyjnych wynikach Google—Googlebot nadal będzie indeksował Twoje treści bez zmian. To poważny kompromis: blokując Google-Extended, Twoje treści nie pojawią się w AI Overviews (coraz bardziej widocznych w Google), ale chronisz je przed wykorzystaniem do trenowania konkurencyjnego modelu AI. Z kolei pozwolenie Google-Extended oznacza, że Twoje treści mogą pojawiać się w AI Overviews (co może generować ruch), ale także zasilają dane treningowe Gemini, co potencjalnie prowadzi do konkurencji z Twoimi własnymi treściami lub modelem biznesowym. Wydawcy powinni starannie rozważyć swoją sytuację—organizacje newsowe i twórcy treści zarabiający na ruchu mogą skorzystać na blokadzie Google-Extended, inni mogą docenić potencjał ruchu z AI Overview. Ta decyzja powinna być podejmowana świadomie, a nie domyślnie, bo ma duży wpływ na widoczność i ruch w ekosystemie Google.
Testowanie konfiguracji robots.txt przed wdrożeniem na produkcji jest absolutnie kluczowe, ponieważ błędy mogą mieć poważne konsekwencje zarówno dla widoczności w wyszukiwarkach, jak i ochrony treści. Google Search Console oferuje wbudowany tester robots.txt, który pozwala sprawdzić, czy określone user agenty mają dostęp do konkretnych URL Twojej strony—możesz wpisać np. “GPTBot” i ścieżkę URL, a Google powie Ci, czy ten bot będzie miał dostęp czy nie. Merkle Robots.txt Tester oferuje podobną funkcjonalność z przyjaznym interfejsem i szczegółowymi wyjaśnieniami interpretacji reguł. TechnicalSEO.com to kolejne darmowe narzędzie walidujące składnię robots.txt i pokazujące, jak różne boty zostaną potraktowane. Bardziej zaawansowany monitoring zapewnia Knowatoa AI Search Console, które oferuje narzędzia do śledzenia aktywności crawlerów AI i walidacji konfiguracji względem konkretnych botów. Twój workflow testowy powinien obejmować wgranie robots.txt na środowisko testowe, sprawdzenie, że kluczowe strony są dostępne, potwierdzenie, że boty AI są skutecznie blokowane, oraz monitoring logów serwera pod kątem nieoczekiwanej aktywności crawlerów. Testowanie powinno objąć również sprawdzenie poprawności odwołania do Sitemap oraz dostępności treści dla wyszukiwarek—chcesz blokować crawlerów uczących AI, ale nie przypadkiem ruch organiczny. Dopiero po gruntownych testach wdrażaj konfigurację na produkcję i monitoruj logi przez pierwszy tydzień, by wykryć ewentualne problemy.
Narzędzia do testowania:
Choć robots.txt to przydatna linia obrony, warto wiedzieć, że działa ona na zasadzie honorowej—boty, które respektują protokół, będą przestrzegać reguł, ale złośliwe lub źle zaprojektowane crawlery mogą całkowicie zignorować robots.txt i uzyskać dostęp do Twoich treści. Branżowe dane sugerują, że robots.txt skutecznie powstrzymuje ok. 40-60% niechcianego ruchu crawlerów, a pozostałe 40-60% botów ignoruje protokół lub go obchodzi. Wydawcy wymagający silniejszej ochrony powinni wdrożyć dodatkowe warstwy zabezpieczeń. Web Application Firewall (WAF) Cloudflare pozwala na tworzenie reguł blokujących ruch na podstawie user agentów, adresów IP lub wzorców zachowań, chroniąc przed botami ignorującymi robots.txt. Narzędzia na poziomie serwera, jak .htaccess (na serwerach Apache) lub odpowiednia konfiguracja na Nginx, mogą blokować konkretne user agenty lub zakresy IP zanim żądania dotrą do aplikacji. Blokada IP sprawdza się, jeśli znasz zakresy używane przez crawlery, choć wymaga to ciągłej aktualizacji. Fail2ban i podobne narzędzia mogą automatycznie blokować IP wykazujące podejrzane zachowania, np. zbyt szybkie żądania lub dostęp do wrażliwych ścieżek. Jednak wdrożenie tych zabezpieczeń wymaga ostrożności—zbyt agresywne blokady mogą wykluczyć prawdziwych użytkowników, np. korzystających z VPN czy proxy współdzielących IP z crawlerami. Najskuteczniejsze podejście łączy robots.txt jako “grzeczną” prośbę, blokadę user agentów na poziomie serwera dla botów ignorujących robots.txt oraz monitorowanie zachowań w celu wykrycia zaawansowanych crawlerów podszywających się pod user agentów lub korzystających z rozproszonych adresów IP. Wydawcy powinni wdrażać te warstwy stopniowo, testując każdą z nich, by nie blokować przypadkowo legalnego ruchu i jednocześnie skutecznie chronić treści.
Zrozumienie, co faktycznie uzyskuje dostęp do Twojej strony, jest kluczowe dla potwierdzenia skuteczności konfiguracji robots.txt i identyfikacji nowych crawlerów wymagających blokady. Analiza logów serwera to podstawowa metoda takiego monitoringu—logi serwera WWW (Apache, Nginx lub inne) zawierają szczegółowy zapis każdego żądania, w tym user agent, adres IP, czas i żądaną stronę. Możesz użyć narzędzi linii poleceń, jak grep, by przeszukać logi pod kątem określonych user agentów; np. “grep ‘GPTBot’ /var/log/apache2/access.log” pokaże każde żądanie od GPTBot, pozwalając zweryfikować skuteczność blokad. Bardziej zaawansowana analiza obejmuje zliczanie crawl rate różnych botów, analizę odwiedzanych stron, a także sprawdzanie, czy respektują robots.txt. Zautomatyzowane rozwiązania mogą ciągle analizować logi i alarmować o pojawieniu się nowych lub niespodziewanych crawlerów, co jest szczególnie cenne przy szybkim rozwoju rynku botów AI. Niektórzy wydawcy korzystają z platform agregujących logi, jak ELK Stack, Splunk czy rozwiązania chmurowe, by centralizować i analizować ruch crawlerów na wielu serwerach. Dynamicznie zmieniający się krajobraz crawlerów AI oznacza, że monitoring to zadanie ciągłe—nowe boty pojawiają się regularnie, istniejące zmieniają user agenty, a zachowania crawlerów ewoluują wraz z polityką firm. Ustanowienie regularnej rutyny monitoringu (co tydzień lub co miesiąc) pozwala wyprzedzać zmiany i aktualizować robots.txt proaktywnie, a nie dopiero po negatywnych skutkach.
Konfiguracja robots.txt dla crawlerów AI to w istocie decyzja dotycząca przychodów i zasługuje na taką samą strategiczną uwagę jak każda decyzja biznesowa o dużym znaczeniu finansowym. Pozwolenie crawlerom trenującym na nieograniczony dostęp oznacza, że modele AI trenowane na Twoich danych mogą konkurować z Twoim ruchem i przychodami—jeśli Twój model biznesowy opiera się na ruchu bezpośrednim, widoczności w wyszukiwarkach czy reklamach, de facto dostarczasz darmowe dane treningowe firmom budującym konkurencyjne produkty. Z kolei blokując wszystkie crawlery AI, tracisz potencjalną widoczność w wynikach wyszukiwania AI i ruch referencyjny z asystentów AI, które stają się coraz ważniejszym źródłem pozyskiwania użytkowników. Optymalna strategia zależy od Twojego modelu biznesowego: wydawcy utrzymujący się z reklam mogą pozwolić na dostęp crawlerom wyszukiwawczym (generującym ruch i wyświetlenia), blokując crawlerów trenujących (nie generujących ruchu). Wydawcy subskrypcyjni mogą przyjąć ostrzejszą strategię, blokując większość crawlerów AI, by chronić treści przed streszczaniem lub kopiowaniem przez AI. Wydawcy stawiający na widoczność marki i pozycję eksperta mogą powitać obecność w wynikach AI jako formę dystrybucji. Kluczowe jest, by decyzję podjąć świadomie, nie domyślnie—wielu wydawców nigdy nie skonfigurowało robots.txt pod kątem AI, co oznacza, że domyślnie wpuszczają wszystkie boty i oddają treści na potrzeby treningu AI bez świadomego wyboru. Rozważ też wdrożenie schema markup zapewniającego odpowiednią atrybucję przy wykorzystaniu treści przez systemy AI, co może pomóc w przepływie ruchu i uznania nawet w przypadku cytowania przez asystentów AI. Konfiguracja robots.txt powinna odzwierciedlać świadomą strategię biznesową, podlegać regularnym przeglądom i aktualizacjom wraz ze zmianami w krajobrazie AI i Twoich własnych priorytetach.
Krajobraz crawlerów AI zmienia się w tempie niespotykanym dotąd w sieci—nowe firmy wypuszczają produkty AI, istniejące wprowadzają nowe crawlery, a ciągi user agentów zmieniają lub rozszerzają się regularnie. Twój robots.txt nie powinien być plikiem “ustaw i zapomnij”, lecz żywym dokumentem przeglądanym i aktualizowanym co najmniej raz na kwartał. Ustal proces monitorowania branżowych ogłoszeń o nowych crawlerach AI, subskrybuj odpowiednie newslettery i blogi śledzące te zmiany oraz regularnie analizuj logi serwera w poszukiwaniu nieznanych user agentów mogących świadczyć o pojawieniu się nowych botów. Gdy wykryjesz nowe crawlery, zbadaj ich cel i model biznesowy, by zdecydować, czy pasują do Twojej strategii ochrony treści, po czym zaktualizuj robots.txt. Monitoruj też skuteczność konfiguracji, śledząc wolumen ruchu crawlerów, stosunek liczby żądań crawlerów do ruchu użytkowników i wszelkie zmiany w organicznej widoczności lub ruchu referencyjnym z wyszukiwarek AI. Wielu wydawców odkrywa, że ich początkowa strategia blokowania wymaga korekty po kilku miesiącach—np. blokada określonego bota ma nieoczekiwane skutki lub dopuszczenie określonych crawlerów generuje bardziej wartościowy ruch niż przewidywano. Bądź gotów do iteracji strategii na podstawie realnych danych, nie założeń. Na koniec, komunikuj strategię robots.txt odpowiednim osobom w organizacji—Twój zespół SEO, redakcja i liderzy biznesowi powinni rozumieć powody blokad lub dopuszczeń botów, by decyzje były spójne i świadome wraz z rozwojem organizacji. Ta stała uwaga zapewni skuteczność ochrony treści i zgodność z celami biznesowymi w dynamicznie zmieniającym się świecie AI.
Nie. Blokowanie crawlerów uczących AI, takich jak GPTBot, ClaudeBot i CCBot, nie wpływa na Twoje pozycje w Google lub Bing. Tradycyjne wyszukiwarki używają innych crawlerów (Googlebot, Bingbot), które działają niezależnie. Zablokuj je tylko, jeśli chcesz całkowicie zniknąć z wyników wyszukiwania.
Główne crawlery od OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) i Perplexity (PerplexityBot) oficjalnie deklarują, że respektują dyrektywy robots.txt. Jednak mniejsze lub mniej przejrzyste boty mogą ignorować Twoją konfigurację, dlatego istnieją strategie warstwowej ochrony.
To zależy od Twojej strategii. Blokowanie tylko crawlerów trenujących (GPTBot, ClaudeBot, CCBot) chroni Twoje treści przed wykorzystaniem do trenowania modeli, jednocześnie pozwalając botom wyszukiwawczym promować Cię w wynikach AI. Całkowita blokada wyklucza Cię ze wszystkich ekosystemów AI.
Przeglądaj swoją konfigurację co najmniej raz na kwartał. Firmy AI regularnie wprowadzają nowe crawlery. Anthropic połączył boty 'anthropic-ai' i 'Claude-Web' w 'ClaudeBot', dając nowemu botowi tymczasowo nieograniczony dostęp na stronach, które nie zaktualizowały reguł.
Robots.txt to plik w katalogu głównym domeny, który dotyczy wszystkich stron, natomiast meta tagi robots to dyrektywy HTML na poszczególnych podstronach. Robots.txt jest sprawdzany jako pierwszy i może uniemożliwić crawlerom dostęp do strony, podczas gdy meta tagi są odczytywane tylko po wejściu na stronę. Używaj obu narzędzi dla pełnej kontroli.
Tak. Możesz użyć reguł Disallow dla konkretnych ścieżek w robots.txt (np. 'Disallow: /premium/', aby zablokować tylko treści premium) lub użyć meta tagów robots na wybranych stronach. Dzięki temu chronisz wrażliwe treści, jednocześnie udostępniając innym crawlerom dostęp do pozostałych części.
Jeśli bot zignoruje robots.txt, będziesz potrzebować dodatkowych metod ochrony, np. blokady na poziomie serwera (.htaccess), blokady IP lub reguł WAF. Robots.txt powstrzymuje ok. 40-60% niechcianych crawlerów, więc warstwowa ochrona jest kluczowa dla pełnej obrony.
Użyj narzędzi testujących, takich jak tester robots.txt w Google Search Console, Merkle Robots.txt Tester lub TechnicalSEO.com, aby zweryfikować konfigurację. Monitoruj logi serwera pod kątem aktywności crawlerów, aby upewnić się, że zablokowane boty są wykluczane, a dozwolone mają dostęp do Twoich treści.
Robots.txt to dopiero pierwszy krok. Skorzystaj z AmICited, aby śledzić, które systemy AI cytują Twoje treści, jak często się do Ciebie odwołują i zapewnić prawidłową atrybucję w GPT, Perplexity, Google AI Overviews i innych.
Dowiedz się, jak selektywnie zezwalać lub blokować crawlery AI w oparciu o cele biznesowe. Wdrażaj różnicowany dostęp crawlerów, by chronić treści i zachować wi...

Dowiedz się, jak przetestować, czy crawlery AI, takie jak ChatGPT, Claude i Perplexity, mogą uzyskać dostęp do treści Twojej strony internetowej. Poznaj metody ...

Kompletny przewodnik po AI crawlerach i botach. Identyfikuj GPTBot, ClaudeBot, Google-Extended oraz 20+ innych AI crawlerów z agentami użytkownika, tempem indek...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.