Jak testować skuteczność strategii GEO: Kluczowe metryki i narzędzia
Dowiedz się, jak mierzyć skuteczność strategii GEO za pomocą wyników widoczności w AI, częstotliwości przypisywania treści, wskaźników zaangażowania oraz analiz...
7 min czytania

Opanuj eksperymenty GEO dzięki naszemu kompleksowemu przewodnikowi po grupach kontrolnych i zmiennych. Dowiedz się, jak projektować, przeprowadzać i analizować eksperymenty geograficzne dla dokładnego pomiaru efektów marketingowych oraz śledzenia widoczności w AI.
Eksperymenty GEO, znane także jako geo lift tests lub eksperymenty geograficzne, stanowią fundamentalną zmianę w sposobie mierzenia rzeczywistego wpływu kampanii marketingowych. Eksperymenty te dzielą regiony geograficzne na grupy testowe i kontrolne, umożliwiając marketerom izolowanie inkrementalnego efektu działań marketingowych bez polegania na śledzeniu na poziomie użytkownika. W czasach, gdy przepisy dotyczące prywatności, takie jak GDPR i CCPA, są coraz bardziej restrykcyjne, a pliki cookie firm trzecich są wycofywane, eksperymenty GEO oferują bezpieczną dla prywatności, statystycznie solidną alternatywę dla tradycyjnych metod pomiaru. Porównując wyniki w regionach objętych działaniami marketingowymi z tymi, które nie były na nie eksponowane, organizacje mogą z przekonaniem odpowiedzieć na pytanie: „Co by się stało, gdyby nie nasza kampania?” Ta metodologia stała się niezbędna dla marek, które chcą zrozumieć prawdziwą inkrementalność i precyzyjnie optymalizować wydatki marketingowe.
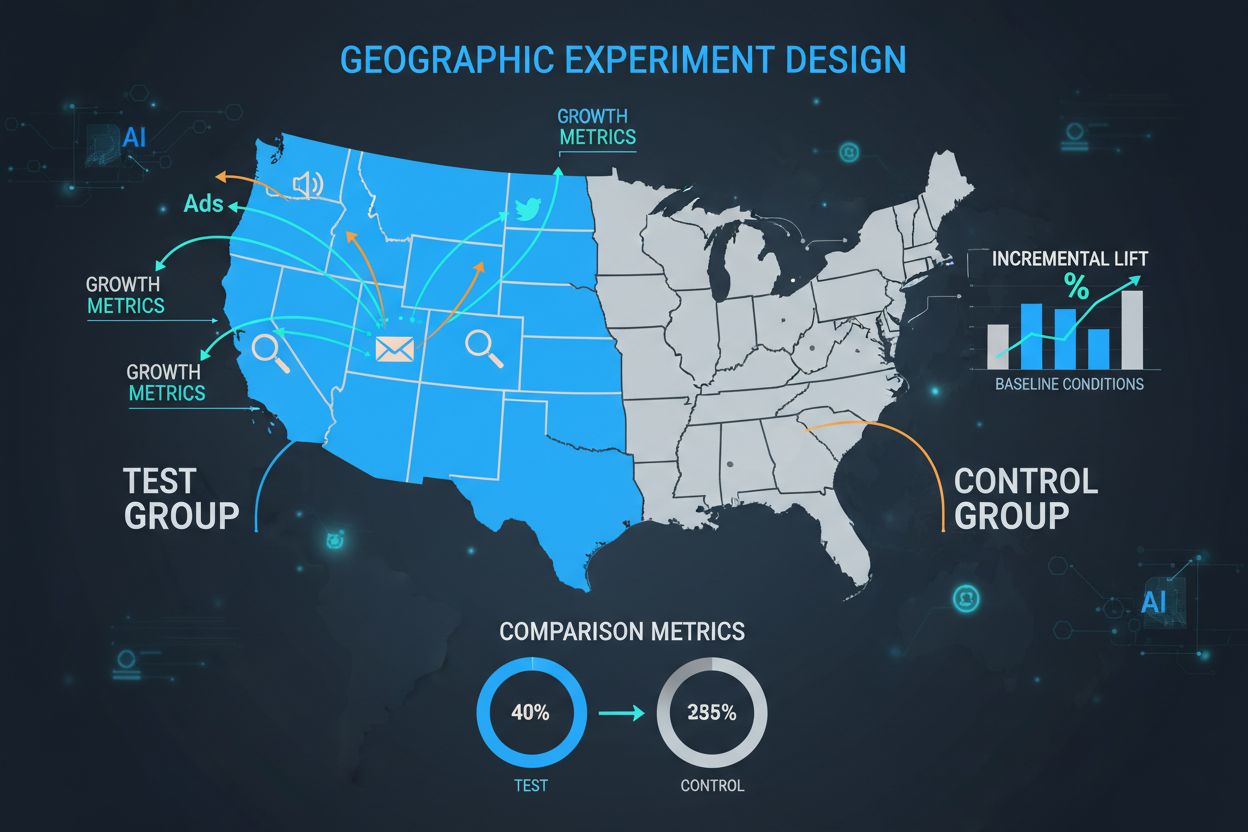
Grupa kontrolna to fundament każdego eksperymentu GEO, stanowiący kluczowy punkt odniesienia do pomiaru wszystkich efektów działania. Grupa kontrolna składa się z regionów geograficznych, które nie otrzymują interwencji marketingowej, umożliwiając marketerom obserwację, co wydarzyłoby się naturalnie bez kampanii. Siła grup kontrolnych polega na zdolności do uwzględnienia czynników zewnętrznych — sezonowości, aktywności konkurencji, warunków gospodarczych i trendów rynkowych — które w innym przypadku mogłyby zakłócić wyniki. Odpowiednio zaprojektowane grupy kontrolne pozwalają badaczom wyizolować rzeczywisty wpływ przyczynowy działań marketingowych, zamiast jedynie obserwować korelację. Wybór regionów kontrolnych wymaga starannego dopasowania pod wieloma względami, w tym cech demograficznych, historycznych wskaźników efektywności, wielkości rynku i wzorców zachowań konsumenckich. Zły dobór grupy kontrolnej prowadzi do dużej zmienności wyników, szerokich przedziałów ufności i ostatecznie niewiarygodnych wniosków, które mogą skutkować kosztownym błędnym alokowaniem budżetu marketingowego.
| Aspekt | Grupa kontrolna | Grupa testowa |
|---|---|---|
| Interwencja marketingowa | Brak (Biznes jak zwykle) | Aktywna kampania |
| Cel | Ustalenie punktu odniesienia | Pomiar wpływu |
| Dobór geograficzny | Dopasowany do testowej | Główny przedmiot testu |
| Zbieranie danych | Te same wskaźniki | Te same wskaźniki |
| Wielkość próby | Porównywalna | Porównywalna |
| Zmienne zakłócające | Zminimalizowane | Zminimalizowane |
Udane eksperymenty GEO wymagają starannego zarządzania wieloma typami zmiennych wpływających na wyniki i ich interpretację. Zrozumienie różnicy między zmiennymi niezależnymi, zależnymi, kontrolowanymi a zakłócającymi jest kluczowe dla projektowania eksperymentów dających praktyczne wnioski.
Zmienne niezależne: To taktyki marketingowe, które aktywnie manipulujesz i testujesz, takie jak poziomy wydatków reklamowych, warianty kreacji, wybór kanału, parametry targetowania czy oferty promocyjne. Zmienna niezależna to ta, której wpływ próbujesz zmierzyć.
Zmienne zależne: To wyniki, które mierzysz, aby ocenić wpływ interwencji marketingowej, w tym przychody, konwersje, pozyskanie klientów, świadomość marki, ruch na stronie internetowej, a także, szczególnie dziś, widoczność i cytowania marki w systemach AI.
Zmienne kontrolowane: To czynniki utrzymywane na stałym poziomie w obu grupach, testowej i kontrolnej, by zapewnić uczciwe porównanie, np. spójność komunikatów, konstrukcja oferty, czas trwania kampanii, skład mediów.
Zmienne zakłócające: To nieoczekiwane czynniki zewnętrzne mogące wpłynąć na wyniki niezależnie od działań marketingowych, w tym kampanie konkurencji, katastrofy naturalne, ważne wydarzenia medialne, wahania sezonowe i zmiany gospodarcze.
Zmienne pomiarowe: To konkretne KPI i wskaźniki, które śledzisz: inkrementalny lift, inkrementalny ROAS (iROAS), inkrementalny CAC (iCAC) oraz przedziały ufności wokół szacunków.
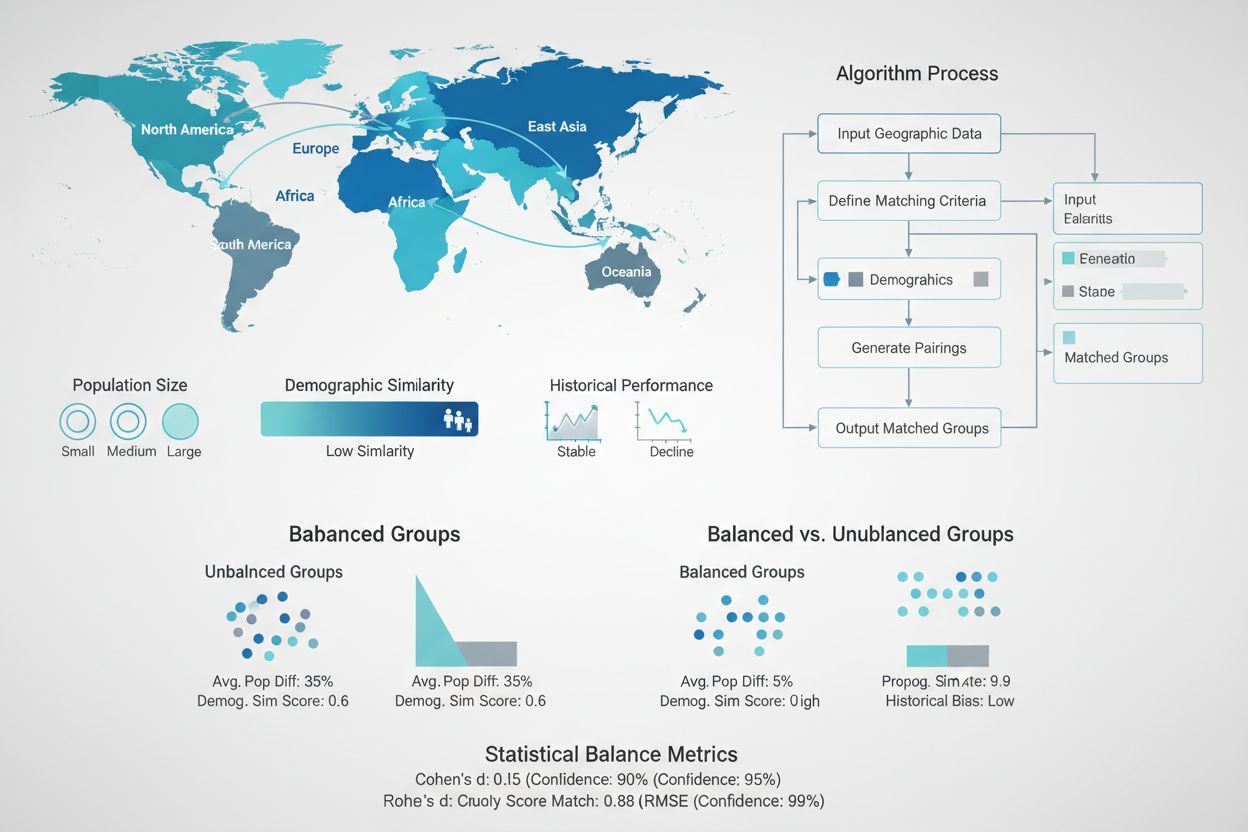
Stworzenie statystycznie równoważnych grup testowych i kontrolnych jest jednym z najważniejszych, a zarazem najtrudniejszych aspektów projektowania eksperymentów GEO. W przeciwieństwie do randomizowanych testów z milionami indywidualnych użytkowników, eksperymenty GEO operują zwykle na kilkunastu do kilkuset jednostkach geograficznych, co czyni losowy przydział niewystarczającym do osiągnięcia równowagi. W odpowiedzi pojawiły się zaawansowane algorytmy dopasowujące i techniki optymalizacyjne. Metody kontroli syntetycznej, rozwinięte przez ekonometryków i spopularyzowane przez firmy takie jak Wayfair i Haus, wykorzystują dane historyczne do identyfikacji i ważenia regionów kontrolnych najlepiej dopasowanych do cech regionów testowych. Algorytmy te biorą pod uwagę wiele wymiarów jednocześnie — wielkość populacji, skład demograficzny, historyczne wzorce sprzedaży, konsumpcję mediów i krajobraz konkurencyjny — aby stworzyć grupy kontrolne będące dokładnym kontrfaktycznym punktem odniesienia. Celem jest minimalizacja różnic między grupami na wszystkich wskaźnikach sprzed testu, by wszelkie zaobserwowane różnice po interwencji można było z pewnością przypisać działaniom marketingowym, a nie istniejącym wcześniej różnicom.
Rzetelność statystyczna odróżnia eksperymenty GEO od zwykłych obserwacji czy dowodów anegdotycznych. Przedziały ufności pokazują zakres, w jakim z określonym poziomem pewności (zwykle 95%) mieści się prawdziwy efekt działania. Wąski przedział oznacza wysoką precyzję i pewność wyników, szeroki — znaczną niepewność. Na przykład, jeśli eksperyment GEO pokazuje 10% lift z 95% przedziałem ufności ±2%, możesz być niemal pewny, że rzeczywisty efekt mieści się między 8% a 12%. Odwrotnie, 10% lift przy ±8% (od 2% do 18%) daje znacznie mniej użytecznych danych. Szerokość przedziałów zależy od kilku czynników: wielkości próby (liczby regionów), zmienności wyników, długości testu oraz spodziewanego efektu. Obliczenia minimalnego wykrywalnego efektu (MDE) pozwalają z góry ocenić, czy proponowany projekt testu może wiarygodnie wykryć oczekiwany lift. Analiza mocy statystycznej zapewnia, że masz wystarczającą moc (zwykle 80% lub więcej), by wykryć rzeczywiste efekty, kontrolując jednocześnie błędy I rodzaju (fałszywe pozytywy) i II rodzaju (fałszywe negatywy).
Nawet najlepiej zaplanowane eksperymenty GEO mogą dać mylące wyniki, jeśli nie uniknie się typowych błędów. Zrozumienie tych pułapek i wdrożenie zabezpieczeń jest kluczowe dla wiarygodnego pomiaru.
Niezrównoważone grupy: Gdy regiony testowe i kontrolne znacznie się różnią pod względem kluczowych wskaźników sprzed testu, dodatkowa zmienność utrudnia wykrycie rzeczywistych efektów. Rozwiązanie: Użyj algorytmów dopasowujących i metod kontroli syntetycznej, by zapewnić statystyczną równoważność grup na wszystkich istotnych wymiarach.
Efekty przenikania: Użytkownicy i ekspozycja mediów nie przestrzegają granic geograficznych. Ludzie podróżują między regionami, a reklama cyfrowa może dotrzeć poza zamierzony obszar. Rozwiązanie: Wybieraj granice minimalizujące kontaminację, uwzględniaj wzorce dojazdów i stosuj geofencing dla precyzyjnej kontroli.
Zbyt krótki czas testu: Kampanie potrzebują czasu na wygenerowanie efektów, a ścieżki klienta są zróżnicowane. Krótkie okna testowe pomijają opóźnione konwersje i wzorce sezonowe. Rozwiązanie: Prowadź eksperymenty przez co najmniej 4-6 tygodni (dłużej dla produktów o długim cyklu decyzyjnym) i uwzględnij okno po zakończeniu kampanii.
Zmiany analizy post-hoc: Modyfikowanie planu analizy po obejrzeniu wstępnych wyników wprowadza stronniczość i zwiększa odsetek fałszywych pozytywów. Rozwiązanie: Zdefiniuj metodologię analizy, KPI i kryteria sukcesu przed rozpoczęciem eksperymentu.
Ignorowanie szoków zewnętrznych: Katastrofy naturalne, działania konkurencji, istotne wydarzenia medialne i zmiany gospodarcze mogą unieważnić wyniki. Rozwiązanie: Monitoruj zmienne zakłócające przez cały okres testu i bądź gotowy wydłużyć lub powtórzyć eksperyment w przypadku poważnych zakłóceń.
Niewystarczająca wielkość próby: Zbyt mała liczba regionów ogranicza moc statystyczną i powoduje szerokie przedziały ufności. Rozwiązanie: Przeprowadź analizę mocy przed rozpoczęciem, by określić minimalną liczbę regionów dla oczekiwanego efektu.
Inkrementalność oznacza rzeczywisty wpływ przyczynowy marketingu — różnicę między tym, co się wydarzyło, a co by się wydarzyło bez interwencji. Lift to ilościowy wskaźnik tej inkrementalności, liczony jako różnica kluczowych wskaźników między grupą testową a kontrolną. Jeśli regiony testowe wygenerowały 1 000 000 zł przychodu, a dopasowane kontrolne 900 000 zł, absolutny lift to 100 000 zł. Procentowy lift wynosi 11,1% (100 000 zł / 900 000 zł). Jednak surowe wartości liftu nie uwzględniają kosztu działań marketingowych. Inkrementalny ROAS (iROAS) dzieli inkrementalny przychód przez dodatkowe wydatki, pokazując zwrot z każdej dodatkowej złotówki. Jeśli region testowy wydał dodatkowe 50 000 zł, by wygenerować 100 000 zł inkrementalnego przychodu, iROAS wynosi 2,0x. Podobnie inkrementalny CAC (iCAC) mierzy koszt pozyskania każdego dodatkowego klienta — kluczowe dla oceny efektywności kanałów akwizycji. Wskaźniki te są szczególnie wartościowe, gdy są powiązane z pomiarem widoczności marki — pozwalają zrozumieć nie tylko lift sprzedaży, ale także wpływ marketingu na cytowania w systemach AI i wzmianki marki w GPT, Perplexity oraz Google AI Overviews.
W miarę jak systemy AI stają się głównym kanałem odkrywania marek przez konsumentów, pomiar wpływu marketingu na widoczność marki w odpowiedziach AI staje się kluczowy. Eksperymenty GEO oferują rygorystyczne ramy do testowania różnych strategii treści i ich wpływu na częstotliwość i dokładność cytowań AI. Przeprowadzając eksperymenty, w których niektóre regiony otrzymują zoptymalizowaną treść pod kątem widoczności w AI — ulepszone dane strukturalne, wyraźniejsze komunikaty marki, zoptymalizowane formaty treści — podczas gdy regiony kontrolne utrzymują dotychczasowe praktyki, marketerzy mogą ilościowo określić inkrementalny wpływ na wzmianki AI. To szczególnie cenne, by zrozumieć, jakie formaty treści, komunikaty i struktury informacji preferują systemy AI przy cytowaniu źródeł. AmICited monitoruje takie eksperymenty, śledząc, jak często Twoja marka pojawia się w odpowiedziach AI w różnych regionach i okresach, dostarczając podstawy danych do pomiaru liftu widoczności. Inkrementalność poprawy widoczności można następnie powiązać z wynikami biznesowymi: czy regiony o wyższej częstotliwości cytowań AI notują większy ruch na stronie, wyszukiwania marki lub konwersje? To powiązanie zmienia widoczność AI z „metryki próżności” w mierzalny czynnik napędzający wyniki biznesowe i umożliwia pewną alokację budżetu na inicjatywy związane z widocznością.
Poza prostą analizą różnic w różnicach, pojawiły się zaawansowane metody statystyczne poprawiające dokładność i wiarygodność eksperymentów GEO. Metoda kontroli syntetycznej tworzy ważoną kombinację regionów kontrolnych najlepiej dopasowanych do trajektorii sprzed testu regionów testowych, zapewniając dokładniejszy punkt odniesienia niż jakikolwiek pojedynczy region kontrolny. Ta metoda jest szczególnie skuteczna, gdy dysponujesz wieloma potencjalnymi regionami kontrolnymi i chcesz wykorzystać całość dostępnych danych. Bayesowskie modele strukturalnych szeregów czasowych (BSTS), spopularyzowane przez pakiet CausalImpact Google, rozszerzają kontrolę syntetyczną o kwantyfikację niepewności i prognozowanie probabilistyczne. BSTS uczą się historycznych relacji między regionami testowymi i kontrolnymi w okresie przed testem, a następnie prognozują, jak wyglądałby region testowy bez interwencji. Różnica między wartościami rzeczywistymi a prognozowanymi to szacowany efekt działania, z przedziałem ufności określającym niepewność. Analiza różnic w różnicach (DiD) porównuje zmianę wyników przed i po interwencji w obu grupach, efektywnie eliminując różnice stałe w czasie. Każda metoda ma swoje wady i zalety: kontrola syntetyczna wymaga wielu jednostek kontrolnych, ale nie zakłada równoległych trendów; BSTS oddaje złożone dynamiki czasowe, ale wymaga starannej specyfikacji modelu; DiD jest prosta i intuicyjna, ale wrażliwa na naruszenie założenia równoległych trendów. Nowoczesne platformy, takie jak Lifesight i Haus, automatyzują te metody, umożliwiając marketerom korzystanie z zaawansowanych analiz bez wymogu wiedzy statystycznej.
Wiodące organizacje udowodniły skuteczność eksperymentów GEO imponującymi wynikami. Wayfair opracował podejście optymalizacji całkowitoliczbowej do przydzielania setek jednostek geograficznych do grup testowych i kontrolnych, równoważąc je precyzyjnie na wielu KPI jednocześnie, co umożliwiło prowadzenie bardziej czułych eksperymentów przy mniejszym procencie wyłączeń. Analiza Polar Analytics setek testów GEO wykazała, że metody kontroli syntetycznej dają wyniki ok. 4 razy bardziej precyzyjne niż proste podejścia matched market, a węższe przedziały ufności pozwalają na bardziej pewne decyzje. Haus wprowadził fixed geo tests specjalnie dla kampanii outdoor i retail, gdzie marketerzy nie mogą losowo przydzielać regionów, ale muszą mierzyć wpływ z góry ustalonego rollout’u geograficznego. Ich case study z Jones Road Beauty pokazało, jak fixed geo tests dokładnie mierzą inkrementalny wpływ billboardów w określonych miastach. Lifesight, współpracując z dużymi markami z retailu, CPG i DTC, wykazał, że automatyczne platformy geo testingowe skracają czas testu z 8-12 do 4-6 tygodni, jednocześnie zwiększając precyzję dzięki zaawansowanym algorytmom dopasowującym. Te przykłady pokazują, że właściwie zaprojektowane i przeprowadzone eksperymenty GEO ujawniają zaskakujące wnioski: kanały uznawane za bardzo skuteczne często wykazują niewielką inkrementalność, a niedoinwestowane — silne zwroty inkrementalne, co prowadzi do znaczących możliwości realokacji budżetu.
Przeprowadzenie skutecznego eksperymentu GEO wymaga systematycznej realizacji kilku etapów:
Zdefiniuj jasne cele i KPI: Określ, co chcesz mierzyć (przychód, konwersje, świadomość marki, cytowania AI) i postaw konkretne, mierzalne cele. Zapewnij zgodność z priorytetami biznesowymi i realistyczne oczekiwania co do wielkości efektu.
Wybierz i dopasuj regiony geograficzne: Wybierz regiony reprezentujące Twój rynek docelowy i mające wystarczającą liczbę danych. Użyj algorytmów dopasowujących, by znaleźć regiony kontrolne możliwie najbliższe testowym pod kątem danych historycznych.
Zadbaj o gotowość danych: Upewnij się, że możesz dokładnie śledzić KPI we wszystkich regionach przez cały okres testu. Przeprowadź audyt danych pod kątem jakości, kompletności i spójności.
Zaprojektuj parametry eksperymentu: Określ czas trwania testu (minimum 4-6 tygodni), precyzyjnie zdefiniuj interwencję marketingową i udokumentuj wszystkie założenia oraz kryteria sukcesu przed startem.
Równoczesne prowadzenie kampanii: Uruchom kampanię w regionach testowych i utrzymaj warunki bazowe w regionach kontrolnych w tym samym czasie. Koordynuj działania między zespołami, by zapewnić spójność realizacji.
Monitoruj na bieżąco: Śledź kluczowe wskaźniki codziennie, by szybko identyfikować nieoczekiwane wzorce, zewnętrzne szoki lub problemy wdrożeniowe.
Zbierz i przeanalizuj dane: Zbierz dane ze wszystkich regionów i zastosuj zdefiniowaną wcześniej metodologię analizy. Oblicz lift, przedziały ufności i wskaźniki drugorzędne.
Ostrożnie interpretuj wyniki: Oceń nie tylko istotność statystyczną, ale także praktyczną. Uwzględnij szerokość przedziałów ufności, wielkość efektu i wpływ biznesowy przy wyciąganiu wniosków.
Udokumentuj i podziel się wnioskami: Stwórz kompleksowy raport obejmujący metodologię, wyniki i naukę z eksperymentu. Podziel się wnioskami ze wszystkimi interesariuszami dla przyszłych działań.
Planuj kolejne eksperymenty: Wykorzystaj wnioski do zaplanowania kolejnych testów, budując kulturę ciągłego eksperymentowania i optymalizacji.
Krajobraz eksperymentów GEO mocno się rozwinął — obecnie wyspecjalizowane platformy automatyzują większość złożoności. Haus oferuje GeoLift do standardowych randomizowanych testów geo oraz Fixed Geo Tests do rolloutów geograficznych, ze szczególną specjalizacją w pomiarze omnichannel. Lifesight zapewnia automatyzację end-to-end od projektowania po analizę, z własnymi algorytmami dopasowującymi i metodą kontroli syntetycznej, która skraca czas testu i podnosi precyzję. Polar Analytics skupia się na testach inkrementalności z naciskiem na pomiar causal lift i dokładność przedziałów ufności. Paramark specjalizuje się w modelowaniu miksu marketingowego z walidacją eksperymentami GEO, pomagając skalibrować predykcje MMM testami rzeczywistymi. Wybierając platformę, zwróć uwagę na: automatyczne dopasowywanie i równoważenie regionów, wsparcie dla kanałów cyfrowych i offline, monitoring w czasie rzeczywistym i możliwość wcześniejszego zatrzymania testu, transparentność metodologii i raportowanie przedziałów ufności oraz integrację z istniejącą infrastrukturą danych. AmICited uzupełnia te platformy, dostarczając warstwę pomiaru widoczności — śledząc, jak Twoja marka pojawia się w odpowiedziach AI w grupach testowych i kontrolnych, co umożliwia pomiar inkrementalności działań nastawionych na widoczność.
Skuteczne eksperymentowanie GEO wymaga stosowania sprawdzonych praktyk maksymalizujących wiarygodność i użyteczność wyników:
Zacznij od jasnych hipotez: Zdefiniuj konkretne, testowalne hipotezy przed startem eksperymentu. Unikaj testów wielu zmiennych naraz bez jasnych założeń.
Zainwestuj w właściwe dopasowanie grup: Poświęć czas na zapewnienie rzeczywistej porównywalności grup testowych i kontrolnych. Złe dopasowanie przekreśla całą dalszą analizę i marnuje zasoby.
Prowadź testy wystarczająco długo: Oprzyj się pokusie wcześniejszego zakończenia, gdy wyniki wyglądają obiecująco. Przedwczesne zatrzymanie wprowadza stronniczość i zwiększa liczbę fałszywych pozytywów. Przestrzegaj zaplanowanego czasu trwania.
Monitoruj zmienne zakłócające: Aktywnie śledź wydarzenia zewnętrzne, działania konkurencji i warunki rynkowe przez cały test. Bądź gotowy wydłużyć lub powtórzyć eksperyment w przypadku poważnych zakłóceń.
Dokumentuj wszystko: Prowadź szczegółowe zapisy projektu, realizacji, analizy i wyników testów. Ta dokumentacja umożliwia naukę, powtarzalność i budowanie wiedzy organizacyjnej.
Buduj kulturę testowania: Przejdź od pojedynczych testów do systemowych programów eksperymentowania. Każdy eksperyment powinien informować kolejne, tworząc cykl nauki i optymalizacji.
Łącz eksperymenty z efektami biznesowymi: Upewnij się, że testy mierzą wskaźniki faktycznie wpływające na cele biznesowe. Unikaj metryk próżności nieprzekładających się na przychód lub cele strategiczne.
Eksperymenty GEO testują na poziomie geograficznym/regionalnym, aby mierzyć inkrementalność kampanii, których nie można przetestować na poziomie indywidualnego użytkownika, podczas gdy testy A/B losowo przydzielają użytkowników indywidualnych do optymalizacji cyfrowej. Eksperymenty GEO są lepsze dla mediów offline, kampanii górnego lejka i pomiaru rzeczywistego wpływu przyczynowego, podczas gdy testy A/B świetnie sprawdzają się przy optymalizacji doświadczeń cyfrowych z szybszymi wynikami.
Typowo minimum 4-6 tygodni, choć zależy to od cyklu konwersji i sezonowości. Dłuższe testy dają bardziej wiarygodne wyniki, ale generują wyższe koszty. Czas trwania testu powinien być wystarczająco długi, by objąć całą ścieżkę klienta i uwzględnić opóźnione efekty konwersji.
Nie ma ustalonego minimum, ale potrzebujesz wystarczającej liczby danych, aby osiągnąć istotność statystyczną. Generalnie potrzebujesz tylu regionów i transakcji, by wykryć oczekiwany efekt z odpowiednią mocą statystyczną (zwykle 80% lub więcej). Mniejsze rynki wymagają dłuższych okresów testowych.
Stosuj granice geograficzne minimalizujące krzyżową kontaminację, uwzględniaj wzorce dojazdów i nakładanie się mediów, korzystaj z technologii geofencingu dla precyzyjnej kontroli i wybieraj regiony geograficznie odizolowane. Efekty przenikania pojawiają się, gdy użytkownicy lub ekspozycja na media przekraczają granice testu i kontroli, rozmywając wyniki.
Standardem jest poziom ufności 95% (p < 0,05), co oznacza, że możesz być w 95% pewny, iż zaobserwowany efekt jest rzeczywisty, a nie przypadkowy. Jednak przy ustalaniu progu ufności weź pod uwagę kontekst biznesowy — koszt fałszywie pozytywnych i negatywnych wyników.
Tak, poprzez ankiety, badania podnoszenia świadomości marki i śledzenie cytowań AI. Możesz mierzyć, jak marketing wpływa na świadomość marki, jej postrzeganie, a co najważniejsze — jak często Twoja marka pojawia się w odpowiedziach generowanych przez AI w różnych regionach, umożliwiając pomiar inkrementalności widoczności.
Katastrofy naturalne, kampanie konkurencji, ważne wydarzenia medialne oraz zmiany gospodarcze mogą unieważnić wyniki przez wprowadzenie zmiennych zakłócających. Monitoruj je przez cały czas trwania testu i bądź gotów wydłużyć okres testu lub powtórzyć eksperyment w razie poważnych zakłóceń.
Eksperymenty GEO zwykle zwracają się poprzez zapobieganie marnotrawieniu budżetu na nieskuteczne kanały i umożliwiają pewne przeniesienie środków na skuteczniejsze działania. Dostarczają rzeczywistych danych, które poprawiają wszystkie dalsze pomiary i decyzje, od kalibracji MMM po optymalizację kanałów.
Eksperymenty GEO pokazują, jak Twój marketing wpływa na widoczność. AmICited śledzi, jak systemy AI cytują Twoją markę w GPT, Perplexity i Google AI Overviews, pomagając mierzyć prawdziwą inkrementalność poprawy widoczności.
Dowiedz się, jak mierzyć skuteczność strategii GEO za pomocą wyników widoczności w AI, częstotliwości przypisywania treści, wskaźników zaangażowania oraz analiz...
Odkryj, jak wygląda zaawansowane geotargetowanie we współczesnym marketingu cyfrowym. Poznaj zaawansowane strategie lokalizacyjne, targetowanie behawioralne i d...
Dowiedz się, jak mierzyć sukces GEO dzięki śledzeniu cytowań przez AI, wzmiankom o marce oraz metrykom widoczności w ChatGPT, Perplexity, Google AI Overviews i ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.