Znaczniki schema dla AI: Które typy mają największe znaczenie dla widoczności w LLM
Dowiedz się, które typy schema mają największy wpływ na widoczność Twojej marki w AI. Odkryj, jak LLM-y interpretują dane strukturalne i wdrażaj strategie znaczników schema, które zapewnią cytowanie Twojej marki w odpowiedziach AI.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
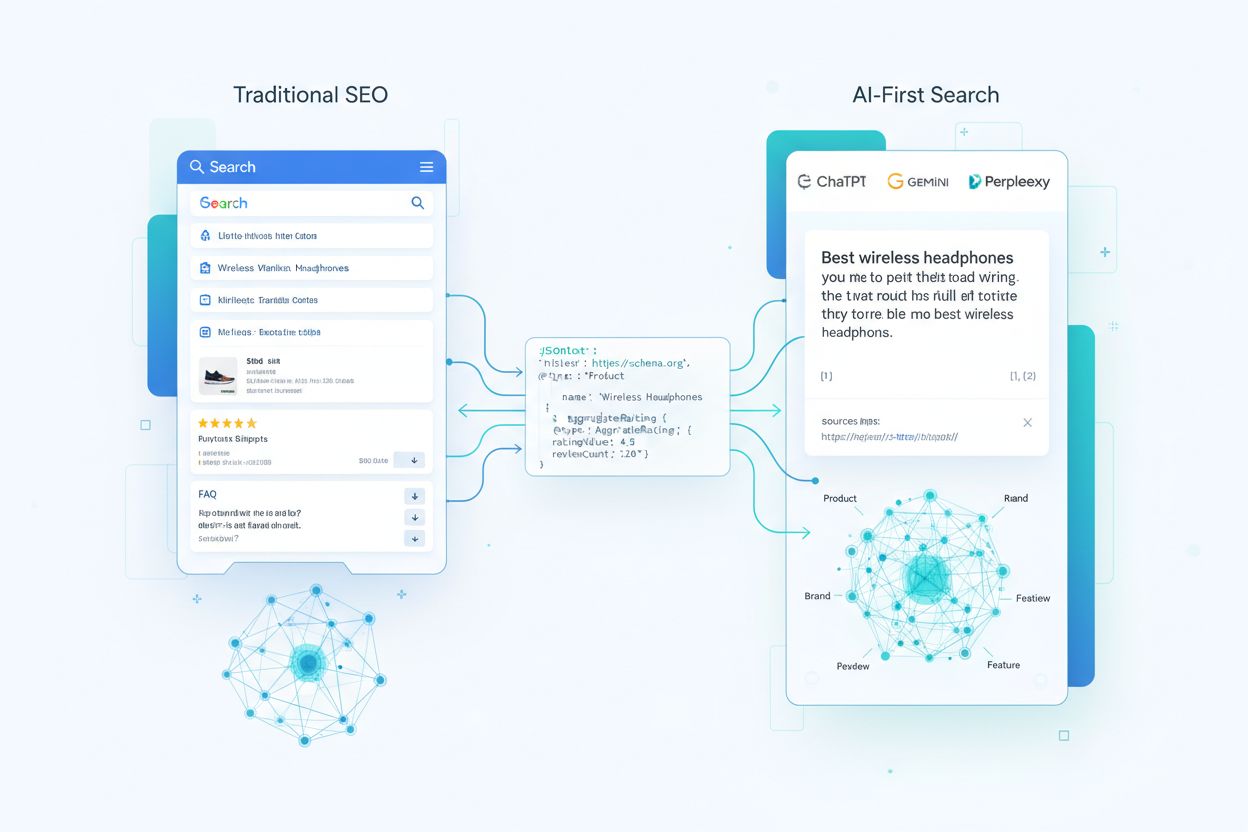
Przesunięcie z bogatych wyników ku widoczności w LLM
Przez lata schema markup służył głównie do zdobywania bogatych wyników — tych przyciągających wzrok ocen gwiazdkowych, kart produktów czy akordeonów FAQ w tradycyjnych wynikach wyszukiwania. Dziś ta strategia staje się przestarzała. Duże modele językowe oraz silniki odpowiedzi AI interpretują schema markup w zupełnie inny sposób — nie jako ozdobnik, lecz jako podstawę budowy grafów wiedzy i rozumienia relacji encji na dużą skalę. Około 45 milionów stron (12,4% wszystkich zarejestrowanych domen) wdrożyło już jakiś rodzaj oznaczeń schema.org, dając AI bezprecedensowy dostęp do danych strukturalnych. To głęboka zmiana: schema markup wpływa teraz na to, czy Twoja marka zostanie zacytowana w odpowiedziach AI, jak dokładnie modele przestawią Twoje produkty i usługi, oraz czy Twoja treść stanie się zaufanym źródłem w świecie wyszukiwania zorientowanego na AI.
Jak systemy AI faktycznie interpretują schema markup
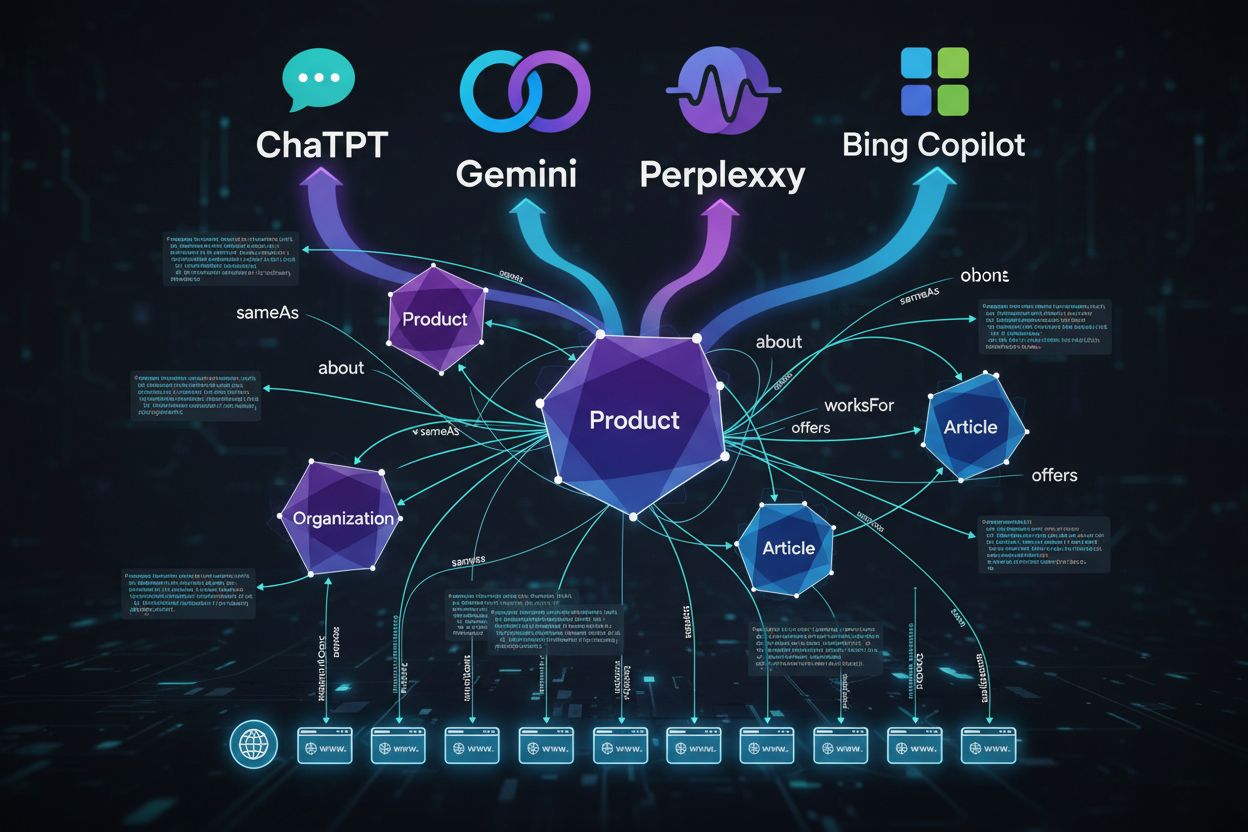
Zrozumienie, jak systemy AI konsumują schema markup, wymaga prześledzenia drogi Twoich danych strukturalnych od pierwszego crawla do odpowiedzi generowanych przez LLM. Gdy crawler odwiedza Twoją stronę, wyciąga bloki JSON-LD, microdata lub RDFa i normalizuje je do indeksu, razem z tekstem i mediami. Te dane strukturalne stają się częścią grafu wiedzy na skalę internetu, gdzie encje łączą się przez relacje i otrzymują embeddingi do wyszukiwania semantycznego. W systemach typu retrieval-augmented generation (RAG) schema może być bezpośrednio dołączona do fragmentów populujących indeksy wektorowe — jeden fragment może zawierać zarówno opis produktu, jak i jego JSON-LD, dzięki czemu modele mają zarówno kontekst narracyjny, jak i uporządkowane atrybuty. Różne architektury LLM konsumują schema na różne sposoby: niektóre nakładają modele na istniejące indeksy i grafy wiedzy, inne korzystają z pipeline’ów pobierających dane ze źródeł strukturalnych i niestrukturalnych. Najważniejsze jest to, że dobrze wdrożony schema działa jak kontrakt z modelem — w bardzo uporządkowanej formie wskazujesz, które fakty na stronie uważasz za kanoniczne i godne zaufania.
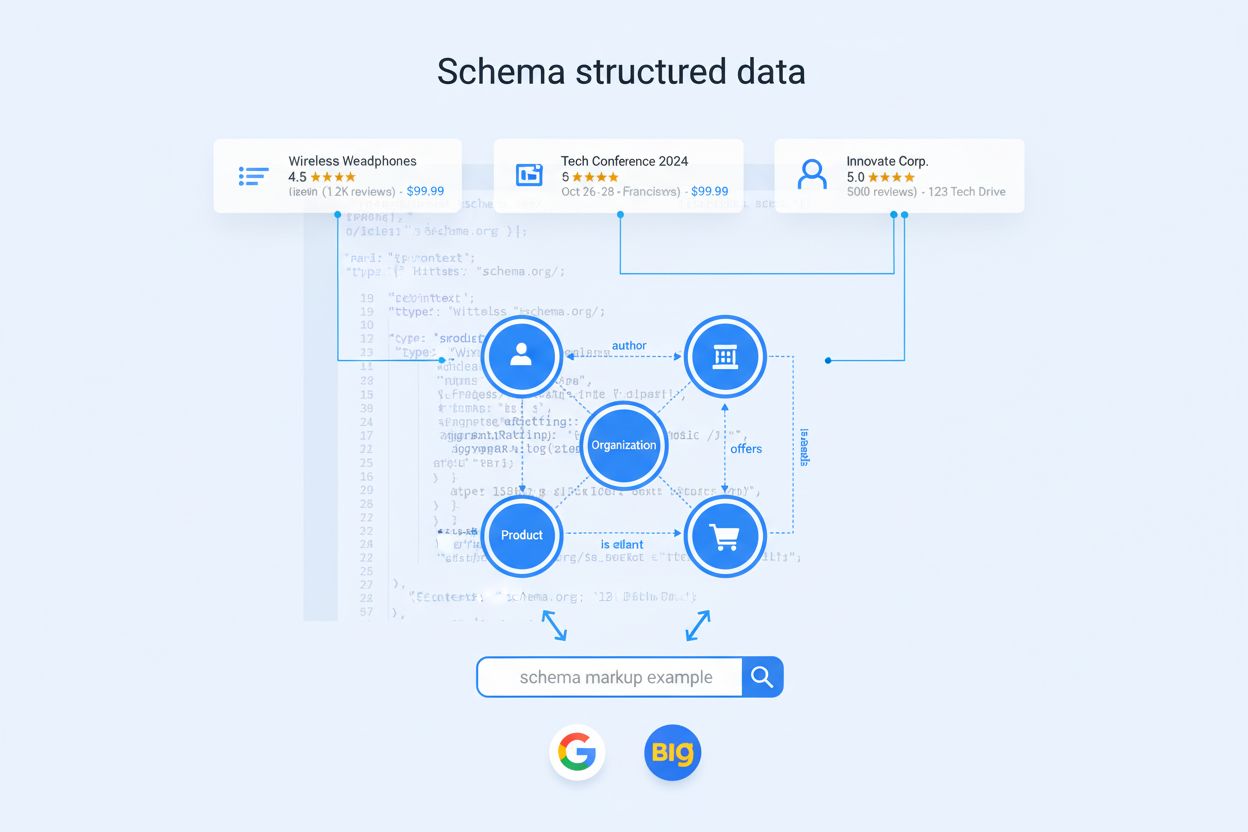
Nie wszystkie typy schema mają jednakową wagę w erze AI. Organization to kotwica całego grafu encji — pomaga modelom rozumieć tożsamość, autorytet i relacje Twojej marki. Product jest kluczowy dla e-commerce i handlu, umożliwiając AI porównywanie cech, cen i ocen między źródłami. Article i BlogPosting pomagają modelom identyfikować treści długie, odpowiednie do wyjaśniających zapytań i budowania pozycji eksperta. Person umożliwia przypisanie autorytetu i wiarygodności autorom w odpowiedziach AI. FAQPage bezpośrednio odwzorowuje się na konwersacyjne zapytania, które AI ma odpowiadać. Dla SaaS i B2B równie ważne są SoftwareApplication oraz Service, często pojawiające się w porównaniach narzędzi i analizie funkcji. Dla biznesów lokalnych i medycznych typy LocalBusiness i MedicalOrganization zapewniają precyzję geograficzną i jasność regulacyjną. Różnicę robią nie tyle podstawowe typy, co zaawansowane właściwości – spójność na stronach, jasne identyfikatory encji i jawne relacje.
Zaawansowane właściwości schema, z których korzystają LLM-y
Podstawowe właściwości, jak name, description czy URL, to już standard — 72,6% stron na pierwszej stronie Google używa jakiejś formy schema. Te, które naprawdę wpływają na widoczność w AI, to właściwości łączące, pomagające modelom rozwiązywać encje, rozumieć relacje i rozróżniać znaczenia. Najważniejsze z nich to:
sameAs: Łączy Twoją encję z kanonicznymi profilami (Wikipedia, LinkedIn, Crunchbase, strony producenta), drastycznie zmniejszając ryzyko pomyłki marki z imiennikiem
about/mentions: Wyjaśnia, na jakich tematach i encjach skupia się strona, pomagając modelom wybrać spośród wielu „istotnych” źródeł przy złożonych pytaniach
@id: Dostarcza stabilnych, unikalnych identyfikatorów, umożliwiając konsekwentne rozpoznawanie encji na stronie i w Internecie
additionalType: Daje bardziej szczegółowe wskazówki o typie niż podstawowy typ schema, pomagając modelom rozumieć niuanse kategoryzacji
additionalProperty: Koduje niestandardowe cechy i specyfikacje, często używane w porównaniach, recenzjach i treściach oceniających
mentions: Wskazuje wprost encje omawiane na stronie, pomagając modelom rozumieć kontekst i relacje
Te właściwości zamieniają schema z prostego pojemnika danych w semantyczną mapę, którą modele mogą przeszukiwać z pewnością. Gdy używasz sameAs, by połączyć organizację z jej stroną na Wikipedii, nie tylko dodajesz metadane — mówisz modelowi: „to jest autorytatywne źródło informacji o nas”. Gdy używasz additionalProperty do zakodowania cech produktu czy usługi, dostarczasz dokładnie tych atrybutów, których AI szuka, aby tworzyć porównania czy rekomendacje.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Strategia wdrożenia schema: od podstaw do optymalizacji pod LLM
Większość firm traktuje schema markup jako jednorazowe wdrożenie, ale przewaga w wyszukiwaniu napędzanym AI wymaga traktowania tego jako ciągłego zarządzania danymi. Pomocny jest czteropoziomowy model dojrzałości, który pokazuje, gdzie jesteś i dokąd powinieneś zmierzać:
Poziom 1 – Podstawowe schema dla bogatych wyników skupia się na minimalnych oznaczeniach wybranych szablonów, głównie w celu uzyskania gwiazdek, kart produktów czy snippetów FAQ. Zarządzanie jest luźne, spójność niska, celem są efekty wizualne, nie semantyczna jasność.
Poziom 2 – Pokrycie zorientowane na encje standaryzuje Organization, Product, Article i Person w kluczowych szablonach, wprowadza spójne @id oraz podstawowe linki sameAs, by zapobiec pomyłkom encji.
Poziom 3 – Schema zintegrowane z grafem wiedzy synchronizuje identyfikatory schema z wewnętrznymi modelami danych (CMS, PIM, CRM), szeroko wykorzystuje about/mentions/additionalType oraz koduje relacje między stronami, by modele rozumiały powiązania wewnątrz i na zewnątrz serwisu.
Poziom 4 – Schema zoptymalizowane pod LLM i RAG celowo strukturyzuje oznaczenia pod zapytania konwersacyjne i formaty snippetów AI, synchronizuje schema z wewnętrznymi pipeline’ami RAG i zawiera pomiar oraz iterację jako kluczowe praktyki.
Większość marek zatrzymuje się na poziomach 1-2, co oznacza, że podstawowe wdrożenie to już higiena, a nie przewaga. Przejście na poziom 3-4 to miejsce, gdzie optymalizacja schema dla LLM staje się trwałą barierą konkurencyjną — modele mogą wtedy konsekwentnie rozpoznawać Twoje encje w wielu wariantach zapytań i miejscach.
Schematy branżowe dla silników odpowiedzi AI
Różne branże mają różne encje, ryzyka i intencje użytkowników, więc zaawansowane wykorzystanie schema nie może być uniwersalne. Kluczowe zasady — jasność encji, modelowanie relacji i zgodność z treścią na stronie — pozostają stałe, ale typy schema i ich właściwości powinny odzwierciedlać realne zachowania szukających w Twojej branży.
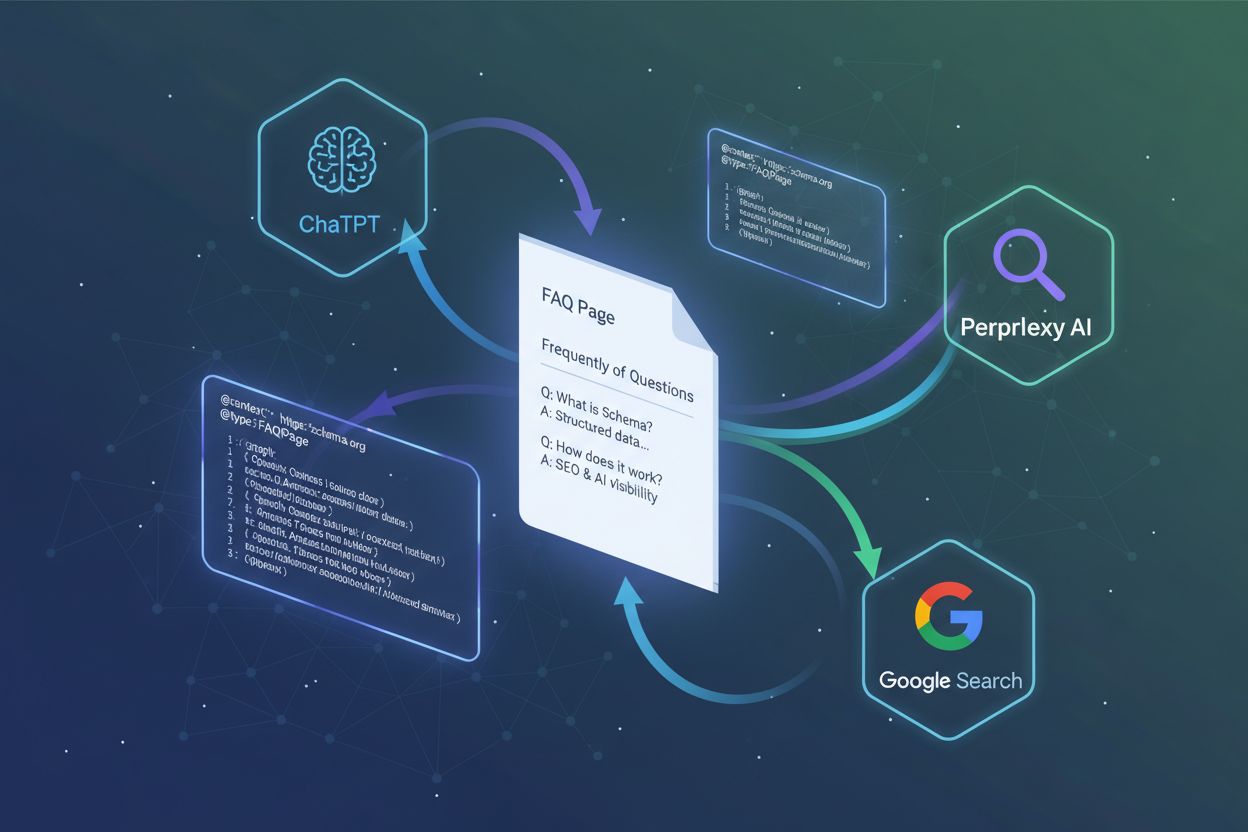
Dla e-commerce i handlu głównymi encjami są Product, Offer, Review i Organization. Każda strona produktu o wysokiej intencji powinna zawierać szczegółowy Product z identyfikatorami (SKU, GTIN), marką, modelem, wymiarami, materiałami oraz wyróżnikami przez additionalProperty. Do tego Offer z ceną i dostępnością oraz AggregateRating dla społecznego dowodu. Zastanów się, jak klienci zadają pytania: „Czy to wodoodporne?”, „Czy jest gwarancja?”, „Jaka polityka zwrotów?”. Zakoduj odpowiedzi jako FAQPage na tej samej stronie i upewnij się, że atrybuty produktowe i FAQ są spójne — to ułatwia cytowanie przez AI.
Dla SaaS i B2B encje są bardziej abstrakcyjne, ale dobrze odwzorowane przez SoftwareApplication, Service i Organization. Każdy produkt lub usługę opisz jako SoftwareApplication lub Service z jasnym opisem kategorii, platform, integracji i modelu cenowego, a cechy wyszczególnij przez additionalProperty, szczególnie te pojawiające się w porównaniach narzędzi. Połącz to z Organization przez provider lub offers, a z ekspertami przez Person. Po stronie treści Article, BlogPosting, FAQPage i HowTo pomagają LLM-om wskazać najlepsze zasoby do zapytań ewaluacyjnych i edukacyjnych.
Dla branż lokalnych, medycznych i regulowanych LocalBusiness, MedicalOrganization i MedicalEntity mogą kodować adresy, obszary obsługi, specjalizacje, akceptowane ubezpieczenia i godziny pracy dużo precyzyjniej niż tekst. To kluczowe, gdy AI pyta np. „znajdź kardiologa dziecięcego w pobliżu, który akceptuje moje ubezpieczenie” lub „poleć czynny punkt opieki doraźnej”. W tych sektorach szczególnie uważaj, by schema nie deklarowało więcej, niż możesz udokumentować — oznaczaj tylko fakty, które mogą być użyte w wielu kontekstach i zapewnij przegląd przez zespół prawny.
Pomiar wpływu schema na widoczność w AI
Zachowanie LLM-ów jest z natury stochastyczne, więc nie uzyskasz perfekcyjnej atrybucji tylko przez schema. Możesz natomiast stworzyć lekki system monitoringu, który cyklicznie sprawdza odpowiedzi AI dla wybranych zapytań. Śledź, które encje są wymieniane, które URL cytowane, jak opisywana jest marka i czy kluczowe fakty (ceny, możliwości, zgodność) są poprawne na różnych platformach: ChatGPT, Gemini, Perplexity, Bing Copilot. Gdy coś jest nie tak — halucynacje, brak cytatów, cytowania agregatorów zamiast Twoich stron — zacznij od sprawdzenia sygnałów. Czy treść na stronie przeczy schema? Czy brakuje linków sameAs lub prowadzą do starych profili? Czy różne strony podają się za kanoniczne dla tej samej encji? Strategicznie planuj przegląd schema co kwartał, by dostosować go do nowych ofert, grup treści i zmian w sposobie prezentacji marki przez AI.
Typowe błędy schema szkodzące widoczności w LLM
Kilka wzorców konsekwentnie osłabia skuteczność schema dla AI. Oznaczanie treści, której nie widać na stronie, buduje deficyt zaufania — modele uczą się pomijać źródła, gdzie schema i treść się rozjeżdżają. Używanie zbyt ogólnych typów, np. „Thing” czy „CreativeWork”, nie daje żadnego sygnału semantycznego — modele potrzebują precyzji. Kopiowanie tego samego schema na wielu stronach bez dopasowania do encji to najczęstszy błąd — jeśli każda strona produktu ma ten sam Organization lub każdy artykuł tego samego autora, modele nie potrafią rozróżnić i mogą obniżyć priorytet Twojej treści jako mało wartościowej. Niespójne identyfikatory encji na stronach (@id dla tej samej organizacji lub produktu) uniemożliwiają rozwiązywanie encji i rozdzielają powiązane treści. Brak linków sameAs do autorytatywnych profili wystawia modele na ryzyko pomyłki marki z imiennikiem. Wreszcie, sprzeczne informacje między schema a treścią podważają wiarygodność — jeśli schema mówi, że produkt jest w magazynie, a strona „brak”, modele nie ufają żadnemu źródłu.
Przyszłość schema i wyszukiwania AI
Schema markup przechodzi od kosmetycznej taktyki SEO do fundamentu dla wyszukiwania zorientowanego na AI. Połączone schema — z jawnie zdefiniowanymi relacjami sameAs, about, mentions — budują grafy wiedzy, które AI może bezpiecznie eksplorować. Przewaga nie leży już w pytaniu „Jaki minimalny schema daje bogaty wynik?”, lecz „Jaka struktura uczyni naszą treść jednoznaczną dla maszyny, nawet poza SERP?”. To przesuwa organizacje ku pełnym, połączonym, encjocentrycznym schematom. W miarę jak AI staje się głównym kanałem odkrywania, optymalizacja schema dla LLM staje się kluczową dyscypliną SEO. Firmy przechodzące od podstawowych oznaczeń do zintegrowanych z grafem wiedzy i zoptymalizowanych pod LLM zbudują trwałe przewagi w AI, zapewniając sobie cytowania i status zaufanego źródła.
Najczęściej zadawane pytania
Czym różni się schema markup dla AI od tradycyjnego SEO?
Tradycyjny schema skupiał się na bogatych wynikach (gwiazdki, fragmenty). Dla AI schema to jasność encji, relacje i grafy wiedzy. Systemy AI używają schema, by rozumieć o czym jest Twoja treść na poziomie semantycznym, nie tylko dla wizualnych ulepszeń.
Które typy schema są najważniejsze dla widoczności w LLM?
Organization, Product, Article, Person i FAQPage to podstawa. Dla SaaS dodaj SoftwareApplication i Service. Dla lokalnych/medycznych dodaj LocalBusiness i MedicalOrganization. Znaczenie zależy od branży i intencji użytkownika.
Czy muszę wdrażać wszystkie typy schema?
Nie. Zacznij od Organization i najważniejszych stron (produkty, usługi, kluczowe artykuły). Stopniowo rozszerzaj zakres w zależności od modelu biznesowego i miejsc, gdzie odpowiedzi AI są najbardziej wartościowe.
Jak długo trwa zobaczenie efektów optymalizacji schema?
Zmiany w schema mogą wpłynąć na cytowania AI w ciągu kilku tygodni, ale relacja jest probabilistyczna. Planuj przeglądy kwartalne i ciągły monitoring na wielu platformach AI, by śledzić wpływ.
Jaka jest różnica między właściwościami sameAs a about?
sameAs łączy Twoją encję z kanonicznymi profilami (Wikipedia, LinkedIn), by uniknąć pomyłek z imiennikami. about/mentions precyzuje, na czym naprawdę skupia się Twoja strona, pomagając modelom rozumieć niuanse i kontekst.
Czy sam schema markup może poprawić widoczność w AI?
Nie. Schema działa najlepiej w połączeniu z wysokiej jakości, dobrze zorganizowaną treścią na stronie. Modele potrzebują zarówno danych strukturalnych, jak i kontekstu narracyjnego, by pewnie cytować Twoje strony.
Jak mierzyć, czy zmiany w schema pomagają w widoczności AI?
Monitoruj odpowiedzi AI na różnych platformach (ChatGPT, Gemini, Perplexity, Bing) dla swoich zapytań. Śledź wzmianki o encjach, cytowania URL, poprawność faktów i opis marki. Obserwuj trendy tygodniami/miesiącami.
Czy do schema markup używać JSON-LD, microdata czy RDFa?
JSON-LD to zalecany format w większości przypadków. Łatwiej go wdrożyć, utrzymać i nie koliduje z HTML. Microdata i RDFa są rzadziej stosowane we współczesnych implementacjach.
Monitoruj swoją markę w odpowiedziach AI
Śledź, jak systemy AI cytują Twoją markę w ChatGPT, Gemini, Perplexity i Google AI Overviews. Uzyskaj wgląd w to, które typy schema napędzają widoczność.
Jaki schemat znaczników pomaga w wyszukiwarce AI? Kompletny przewodnik na 2025 rok
Dowiedz się, które typy znaczników schema zwiększają widoczność w wyszukiwarkach AI, takich jak ChatGPT, Perplexity i Gemini. Poznaj strategie wdrażania JSON-LD...
Schema markup to standaryzowany kod pomagający wyszukiwarkom zrozumieć treść. Dowiedz się, jak strukturalne dane poprawiają SEO, umożliwiają rozbudowane wyniki ...
FAQPage Schema: Najczęściej cytowane dane strukturalne dla odpowiedzi AI
Dowiedz się, dlaczego schema FAQ ma najwyższe wskaźniki cytowań w wyszukiwaniu AI. Kompletny przewodnik po danych strukturalnych FAQPage dla ChatGPT, Perplexity...
12 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.