
Jak modele AI przetwarzają treści?
Dowiedz się, jak modele AI przetwarzają tekst przez tokenizację, embeddingi, bloki transformerów i sieci neuronowe. Poznaj cały proces od wejścia do wyjścia....
11 min czytania

Dowiedz się, jak limity tokenów wpływają na wydajność AI i poznaj praktyczne strategie optymalizacji treści, w tym RAG, chunking i techniki streszczania.
Tokeny to podstawowe elementy, za pomocą których modele AI przetwarzają i rozumieją informacje. Zamiast pracować na całych słowach lub zdaniach, duże modele językowe rozbijają tekst na mniejsze jednostki zwane tokenami, które – w zależności od algorytmu tokenizacji – mogą być pojedynczymi znakami, podwyrazami lub całymi słowami. Każdy token otrzymuje unikalny identyfikator numeryczny, z którego model korzysta podczas obliczeń. Proces tokenizacji jest kluczowy, ponieważ pozwala systemom AI efektywnie obsługiwać wejścia o zmiennej długości i zapewniać spójne przetwarzanie różnych typów treści. Zrozumienie tokenów jest niezbędne dla każdego, kto pracuje z AI, ponieważ mają one bezpośredni wpływ na wydajność, koszt i jakość uzyskiwanych wyników.
Różne modele AI mają bardzo odmienne limity tokenów, które określają maksymalną ilość informacji, jaką mogą przetworzyć w jednym żądaniu. Limity te dynamicznie ewoluowały w ostatnich latach – nowsze modele obsługują znacznie większe okna kontekstowe. Limit tokenów obejmuje zarówno tokeny wejściowe (Twój prompt i dane), jak i wyjściowe (odpowiedź modelu), tworząc wspólny budżet, którym należy umiejętnie zarządzać. Zrozumienie tych limitów jest kluczowe przy wyborze odpowiedniego modelu do zastosowania oraz planowaniu architektury aplikacji.
| Model | Limit tokenów | Główne zastosowanie | Poziom kosztów |
|---|---|---|---|
| GPT-3.5 Turbo | 4 096 | Krótkie rozmowy, szybkie zadania | Niski |
| GPT-4 | 8 192 | Standardowe aplikacje, umiarkowana złożoność | Średni |
| GPT-4 Turbo | 128 000 | Długie dokumenty, złożone analizy | Wysoki |
| Claude 3.5 Sonnet | 200 000 | Rozbudowane dokumenty, kompleksowa analiza | Wysoki |
| Gemini 1.5 Pro | 1 000 000 | Ogromne zbiory danych, całe książki, analiza wideo | Bardzo wysoki |
Kluczowe kwestie przy ocenie limitów tokenów:
Limity tokenów stanowią istotne ograniczenie, które bezpośrednio wpływa na dokładność, niezawodność i opłacalność aplikacji AI. Po przekroczeniu limitu aplikacja całkowicie przestaje działać – nie ma stopniowego spadku jakości ani częściowego przetwarzania. Nawet mieszcząc się w limicie, proste podejścia, takie jak zwykłe obcinanie, mogą poważnie pogorszyć wyniki poprzez usunięcie kluczowego kontekstu, którego model potrzebuje do wygenerowania trafnych odpowiedzi. Jest to szczególnie problematyczne w takich dziedzinach jak analiza prawna, badania medyczne czy inżynieria oprogramowania, gdzie pominięcie nawet jednego istotnego szczegółu może prowadzić do błędnych wniosków. Wyzwanie jest tym większe, że różne rodzaje treści zużywają różną liczbę tokenów – dane strukturalne, np. kod czy JSON, wymagają znacznie więcej tokenów niż zwykły tekst angielski ze względu na symbole i formatowanie.
Obcinanie (truncation) to najprostsza metoda radzenia sobie z limitami tokenów – po prostu odcinasz nadmiar treści, gdy przekracza ona pojemność modelu. Choć łatwe do wdrożenia, podejście to niesie poważne ryzyko. Odcinając tekst, nieuchronnie tracisz informacje, a model nie ma wiedzy o tym, co zostało usunięte. Może to prowadzić do niepełnych analiz, utraty kontekstu i halucynacji, w których model „wypełnia luki” prawdopodobnie brzmiącymi, lecz błędnymi informacjami.
def truncate_text(text: str, max_tokens: int) -> str:
"""Prosty sposób obcinania – niezalecany produkcyjnie"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Przykład: Obcięcie do 4000 tokenów
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Bardziej zaawansowana strategia obcinania rozróżnia treść kluczową od opcjonalnej. Możesz nadać priorytet najważniejszym elementom, takim jak aktualne zapytanie użytkownika i podstawowe instrukcje, a następnie dodać opcjonalny kontekst (np. historię rozmowy) tylko wtedy, gdy pozwala na to limit. Takie podejście pozwala zachować kluczowe informacje, nadal mieszcząc się w limicie tokenów.
Zamiast obcinania, chunking rozbija treść na mniejsze, łatwiejsze do przetworzenia fragmenty, które mogą być analizowane niezależnie lub selektywnie. Chunking o stałym rozmiarze dzieli tekst na równe segmenty, podczas gdy chunking semantyczny wykorzystuje embeddingi do wyznaczania naturalnych granic na podstawie znaczenia, a nie liczby tokenów. Przesuwane okna z nakładką umożliwiają zachowanie kontekstu między fragmentami, co zapobiega utracie istotnych informacji na granicach chunków.
Hierarchiczny chunking tworzy wiele poziomów abstrakcji – od pojedynczych akapitów, przez sekcje, aż po całe rozdziały. Takie podejście umożliwia zaawansowane strategie wyszukiwania, gdzie szybko można zidentyfikować istotne fragmenty bez potrzeby przetwarzania całego dokumentu. Po połączeniu z wektorowymi bazami danych i semantycznym wyszukiwaniem, chunking staje się potężnym narzędziem do zarządzania dużymi bazami wiedzy z zachowaniem trafności i dokładności.
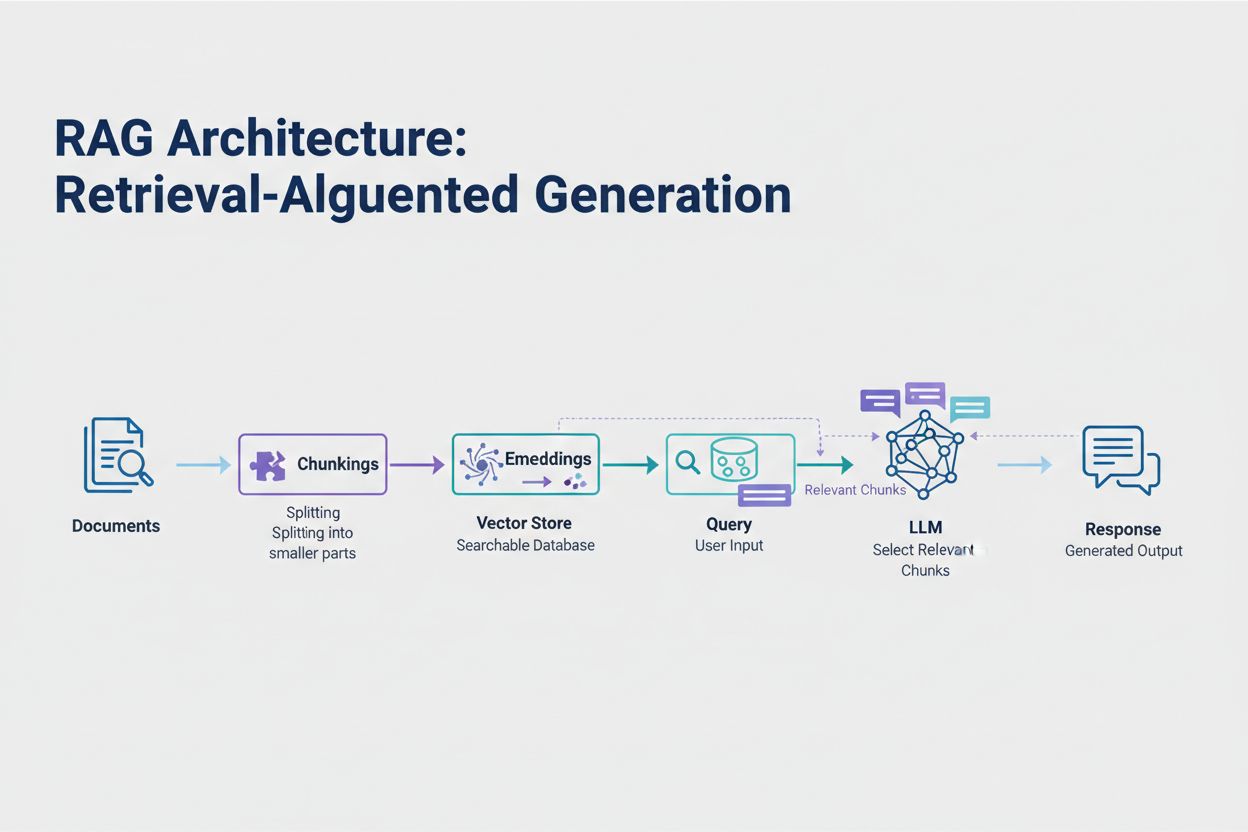
Retrieval-Augmented Generation (RAG) to najskuteczniejsze obecnie podejście do radzenia sobie z limitami tokenów. Zamiast próbować zmieścić całość danych w oknie kontekstowym modelu, RAG pobiera tylko najbardziej istotne informacje w momencie zapytania. Proces zaczyna się od zamiany dokumentów na embeddingi – numeryczne reprezentacje znaczenia semantycznego – które są przechowywane w wektorowej bazie danych umożliwiającej szybkie wyszukiwanie podobieństw.
Gdy użytkownik zadaje pytanie, system zamienia je na embedding i pobiera najbardziej istotne fragmenty dokumentów z bazy. Tylko te fragmenty są wstrzykiwane do promptu wraz z pytaniem użytkownika, co radykalnie ogranicza zużycie tokenów i zwiększa trafność wyników. Przykładowo: analiza 100-stronicowego kontraktu prawnego z użyciem RAG wymaga w promptcie jedynie 3-5 kluczowych klauzul, zamiast tysięcy tokenów potrzebnych na cały dokument.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Krok 1: Załaduj i podziel dokumenty
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Krok 2: Stwórz embeddingi i bazę wektorową
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Krok 3: Utwórz łańcuch RAG
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Krok 4: Zadaj pytanie systemowi
result = qa_chain.run("What are the key terms of this contract?")
Streszczanie skraca długie treści przy zachowaniu kluczowych informacji, skutecznie ograniczając liczbę zużywanych tokenów. Streszczanie ekstrakcyjne wybiera najważniejsze zdania z oryginalnego tekstu, natomiast streszczanie abstrakcyjne generuje nowe, zwięzłe podsumowania oddające główne idee. Streszczanie hierarchiczne pozwala najpierw podsumować poszczególne sekcje, a następnie łączyć je w wyższe poziomy ogólnych streszczeń. To podejście sprawdza się szczególnie dobrze w dokumentach strukturalnych, np. opracowaniach naukowych czy raportach technicznych.
Kompresja kontekstu polega na usuwaniu powtórzeń i treści wypełniającej przy zachowaniu oryginalnego sformułowania. Wykorzystanie grafów wiedzy polega na wydobyciu encji i relacji z tekstu, a następnie odtworzeniu kontekstu tylko z najistotniejszych faktów. Techniki te pozwalają zredukować liczbę tokenów nawet o 40-60% przy zachowaniu poprawności semantycznej, co czyni je wartościowymi narzędziami do optymalizacji kosztów w systemach produkcyjnych.
Zarządzanie tokenami ma bezpośredni wpływ na koszty aplikacji AI. Każdy token zużyty podczas generowania odpowiedzi to koszt, a wydatki rosną liniowo wraz z liczbą tokenów. Monitorowanie zużycia tokenów jest kluczowe dla zrozumienia struktury kosztów i identyfikacji możliwości optymalizacyjnych. Wiele platform AI oferuje obecnie narzędzia do liczenia tokenów i pulpity na żywo śledzące wzorce użycia, pomagając zidentyfikować, które zapytania czy funkcje zużywają najwięcej tokenów.
Efektywny monitoring ujawnia potencjał optymalizacji – być może określone typy zapytań regularnie przekraczają limity lub wybrane funkcje pochłaniają nieproporcjonalnie dużo zasobów. Śledząc te wzorce, możesz podejmować świadome decyzje, którą strategię optymalizacji wdrożyć. W niektórych aplikacjach opłaca się przekierowywać duże żądania do bardziej wydajnych (ale droższych) modeli, inne zyskują najwięcej na wdrożeniu RAG lub streszczania. Kluczowe jest mierzenie rzeczywistej wydajności i kosztów, aby potwierdzić słuszność wybranej strategii.
Wybór odpowiedniej strategii zarządzania tokenami zależy od konkretnego zastosowania, wymagań wydajnościowych i ograniczeń budżetowych. Aplikacje wymagające wysokiej dokładności i odpowiedzi popartych źródłami najbardziej korzystają z RAG, które zachowuje wierność informacji przy efektywnym zarządzaniu tokenami. Długie rozmowy z użytkownikiem najlepiej obsługiwać za pomocą buforowania pamięci i streszczania historii, by zachować decyzje i kontekst. Narzędzia pracujące na wielu dokumentach, jak analiza prawna czy badania naukowe, najwięcej zyskują na hierarchicznych streszczeniach połączonych z chunkingiem semantycznym.
Testowanie i walidacja są kluczowe przed wdrożeniem strategii zarządzania tokenami do produkcji. Twórz przypadki testowe przekraczające limity tokenów modelu i oceń, jak różne strategie wpływają na dokładność, czas odpowiedzi i koszt. Mierz takie wskaźniki jak trafność odpowiedzi, poprawność faktów i efektywność tokenów, by mieć pewność, że wybrane rozwiązanie spełnia Twoje wymagania. Typowe pułapki to zbyt agresywne streszczanie (utrata kluczowych informacji), systemy retrieval pomijające istotne dane czy chunking dzielący treść w nieodpowiednich miejscach.
Limity tokenów stale rosną wraz z postępem modeli i ich wydajności. Nowe techniki, takie jak mechanizmy rzadkiej uwagi czy wydajne transformatory, obniżają koszt obliczeniowy przetwarzania dużych okien kontekstowych. Modele multimodalne, obsługujące jednocześnie tekst, obrazy, dźwięk i wideo, wprowadzają nowe wyzwania i możliwości tokenizacyjne. Tokeny rozumowania – specjalne tokeny służące modelom do „myślenia krok po kroku” – to nowa kategoria zużycia, umożliwiająca bardziej zaawansowane rozwiązywanie problemów, ale wymagająca starannego zarządzania.
Kierunek jest jasny: wraz z rozwojem okien kontekstowych i zwiększaniem efektywności przetwarzania tokenów, wąskim gardłem staje się nie pojemność, lecz inteligentny wybór treści. Przyszłość należy do systemów, które potrafią skutecznie identyfikować i pobierać najistotniejsze informacje z ogromnych baz wiedzy, a nie tylko przetwarzać większe ilości danych. Techniki takie jak RAG i semantyczne wyszukiwanie będą więc coraz ważniejsze w budowie skalowalnych, opłacalnych aplikacji AI.
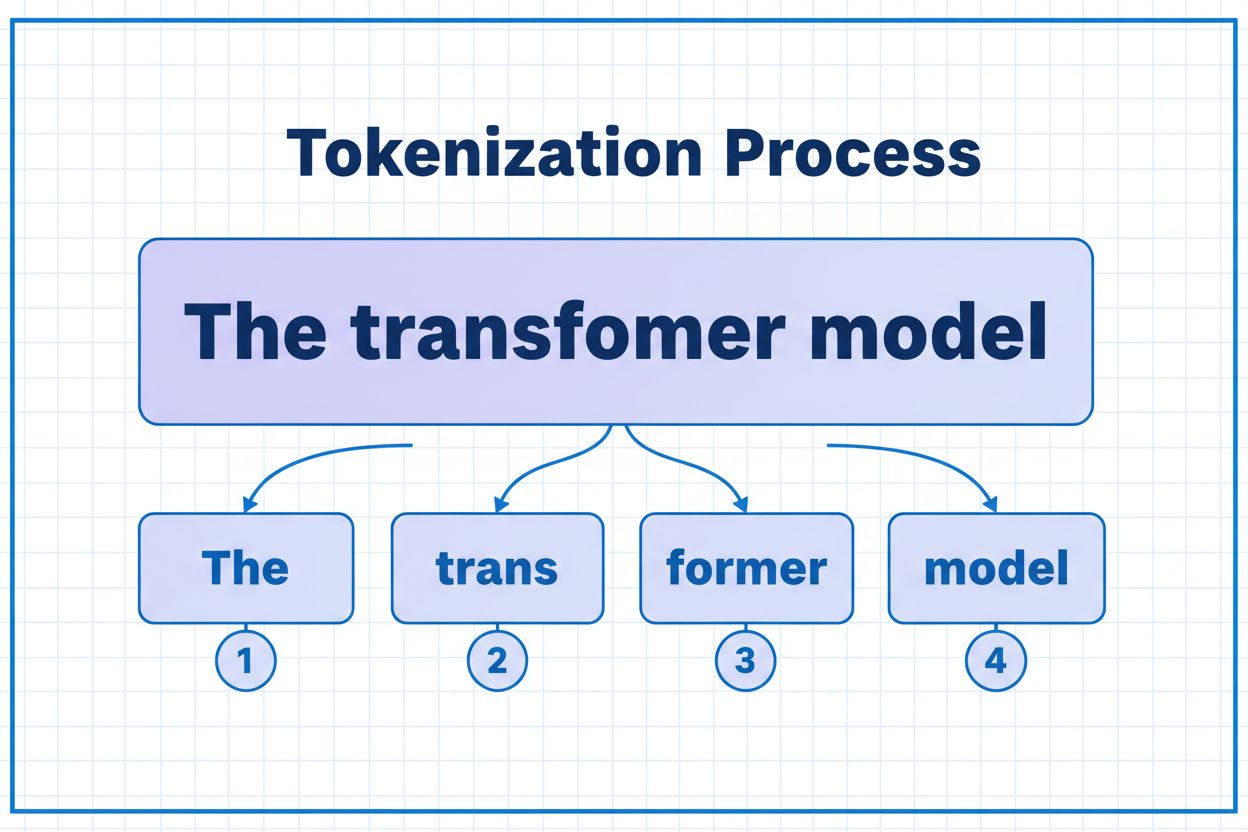
Token to najmniejsza jednostka danych, którą przetwarza model AI. Tokenami mogą być pojedyncze znaki, podwyrazy lub całe słowa – w zależności od zastosowanego algorytmu tokenizacji. Na przykład słowo 'transformer' może zostać podzielone na 'trans' i 'former' jako dwa osobne tokeny. Każdemu tokenowi przypisywany jest unikalny identyfikator numeryczny, z którego model korzysta wewnętrznie w obliczeniach.
Limity tokenów określają maksymalną ilość informacji, jaką model AI może przetworzyć w pojedynczym żądaniu. Po przekroczeniu tego limitu aplikacja całkowicie przestaje działać. Nawet mieszcząc się w limicie, proste podejścia takie jak obcinanie mogą pogarszać dokładność przez usunięcie kluczowego kontekstu. Limity tokenów wpływają też bezpośrednio na koszty, ponieważ zazwyczaj płacisz za każdy zużyty token.
Tokeny wejściowe to tokeny w Twoim promptcie i danych, które wysyłasz do modelu, natomiast tokeny wyjściowe to te, które model generuje w odpowiedzi. Oba typy dzielą wspólny budżet określony przez okno kontekstowe modelu. Jeśli Twoje wejście zajmuje 90% okna 128K tokenów, pozostaje tylko 10% na odpowiedź modelu.
Obcinanie jest łatwe do wdrożenia, ale ryzykowne. Usuwa informacje bez wiedzy modelu, co prowadzi do niepełnej analizy i potencjalnych halucynacji. Choć przydatne jako ostateczność, lepsze podejścia, takie jak RAG, chunking czy streszczanie, pozwalają zachować wierność informacji przy jednoczesnej kontroli zużycia tokenów.
Retrieval-Augmented Generation (RAG) pobiera tylko najbardziej istotne informacje w momencie zapytania, zamiast uwzględniać całe dokumenty. Twoje dokumenty są zamieniane w embeddingi i przechowywane w wektorowej bazie danych. Gdy użytkownik zadaje pytanie, system pobiera tylko odpowiednie fragmenty i wprowadza je do promptu, znacznie ograniczając zużycie tokenów i poprawiając dokładność.
Większość platform AI oferuje narzędzia do liczenia tokenów i pulpity na żywo do śledzenia wzorców użycia. Monitoruj, które zapytania lub funkcje zużywają najwięcej tokenów, a następnie wdrażaj strategie optymalizacyjne, takie jak RAG dla aplikacji opartych na dokumentach, streszczanie dla długich rozmów lub przekierowywanie do większych modeli przy złożonych zadaniach. Mierz rzeczywistą wydajność i koszty, aby potwierdzić trafność swoich wyborów.
Usługi AI zazwyczaj rozliczają się za każdy zużyty token. Koszty rosną liniowo wraz ze zużyciem tokenów, więc optymalizacja tokenów bezpośrednio wpływa na wydatki. Redukcja zużycia o 20% to 20% niższy koszt. Zrozumienie efektywności tokenów pozwala dobrać właściwą strategię optymalizacji pod kątem budżetowym.
Limity tokenów stale się zwiększają wraz z rozwojem modeli. Nowe techniki, takie jak mechanizmy rzadkiej uwagi (sparse attention), obniżają koszty obliczeniowe przetwarzania dużych kontekstów. Przyszłość skupia się na inteligentnym wyborze i pobieraniu treści, a nie tylko na surowej pojemności, dlatego techniki takie jak RAG stają się coraz ważniejsze dla skalowalnych aplikacji AI.
Poznaj efektywność tokenów i śledź, jak modele AI cytują Twoją markę dzięki kompleksowej platformie monitorowania cytowań AI od AmICited.
Dowiedz się, jak modele AI przetwarzają tekst przez tokenizację, embeddingi, bloki transformerów i sieci neuronowe. Poznaj cały proces od wejścia do wyjścia....

Dowiedz się, czym są tokeny w modelach językowych. Tokeny to podstawowe jednostki przetwarzania tekstu w systemach AI, reprezentujące słowa, podsłowa lub znaki ...
Poznaj kluczowe strategie optymalizacji treści wsparcia pod kątem systemów AI, takich jak ChatGPT, Perplexity i Google AI Overviews. Odkryj najlepsze praktyki d...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.