
Adaptacja AI w czasie rzeczywistym
Poznaj adaptację AI w czasie rzeczywistym – technologię umożliwiającą systemom AI ciągłą naukę na podstawie bieżących zdarzeń i danych. Dowiedz się, jak działa ...
7 min czytania

Porównaj optymalizację danych treningowych i strategie pobierania w czasie rzeczywistym dla AI. Dowiedz się, kiedy używać fine-tuningu, a kiedy RAG, jakie są koszty i jak łączyć podejścia dla najlepszej wydajności AI.
Optymalizacja danych treningowych i pobieranie w czasie rzeczywistym to fundamentalnie odmienne podejścia do wyposażania modeli AI w wiedzę. Optymalizacja danych treningowych polega na osadzeniu wiedzy bezpośrednio w parametrach modelu poprzez fine-tuning na dedykowanych zbiorach danych domenowych, co tworzy statyczną wiedzę, pozostającą niezmienna po zakończeniu treningu. Pobieranie w czasie rzeczywistym natomiast utrzymuje wiedzę poza modelem i dynamicznie pobiera odpowiednie informacje podczas wnioskowania, umożliwiając dostęp do dynamicznych danych, które mogą się zmieniać między zapytaniami. Kluczowa różnica polega na tym, kiedy wiedza jest integrowana z modelem: optymalizacja danych treningowych odbywa się przed wdrożeniem, a pobieranie w czasie rzeczywistym – przy każdym wywołaniu wnioskowania. Ta podstawowa różnica wpływa na każdy aspekt wdrożenia, od wymagań infrastrukturalnych, przez charakterystykę dokładności, po aspekty zgodności. Zrozumienie tej różnicy jest kluczowe dla organizacji, które muszą dopasować strategię optymalizacji do swoich potrzeb i ograniczeń.
Optymalizacja danych treningowych polega na systematycznej modyfikacji wewnętrznych parametrów modelu poprzez ekspozycję na wyselekcjonowane, domenowe zbiory danych podczas procesu fine-tuningu. Gdy model wielokrotnie napotyka przykłady treningowe, stopniowo przyswaja wzorce, terminologię i wiedzę ekspercką z danej dziedziny poprzez propagację wsteczną i aktualizację gradientów, które przekształcają mechanizmy uczenia modelu. Pozwala to organizacjom zakodować wiedzę specjalistyczną — od terminologii medycznej, przez ramy prawne, po wewnętrzną logikę biznesową — bezpośrednio w wagach i biasach modelu. Taki model staje się mocno wyspecjalizowany w swojej dziedzinie, często osiągając wydajność porównywalną z dużo większymi modelami; badania Snorkel AI wykazały, że fine-tuning mniejszych modeli może dać efekty porównywalne z modelami 1400 razy większymi. Kluczowe cechy optymalizacji danych treningowych to:
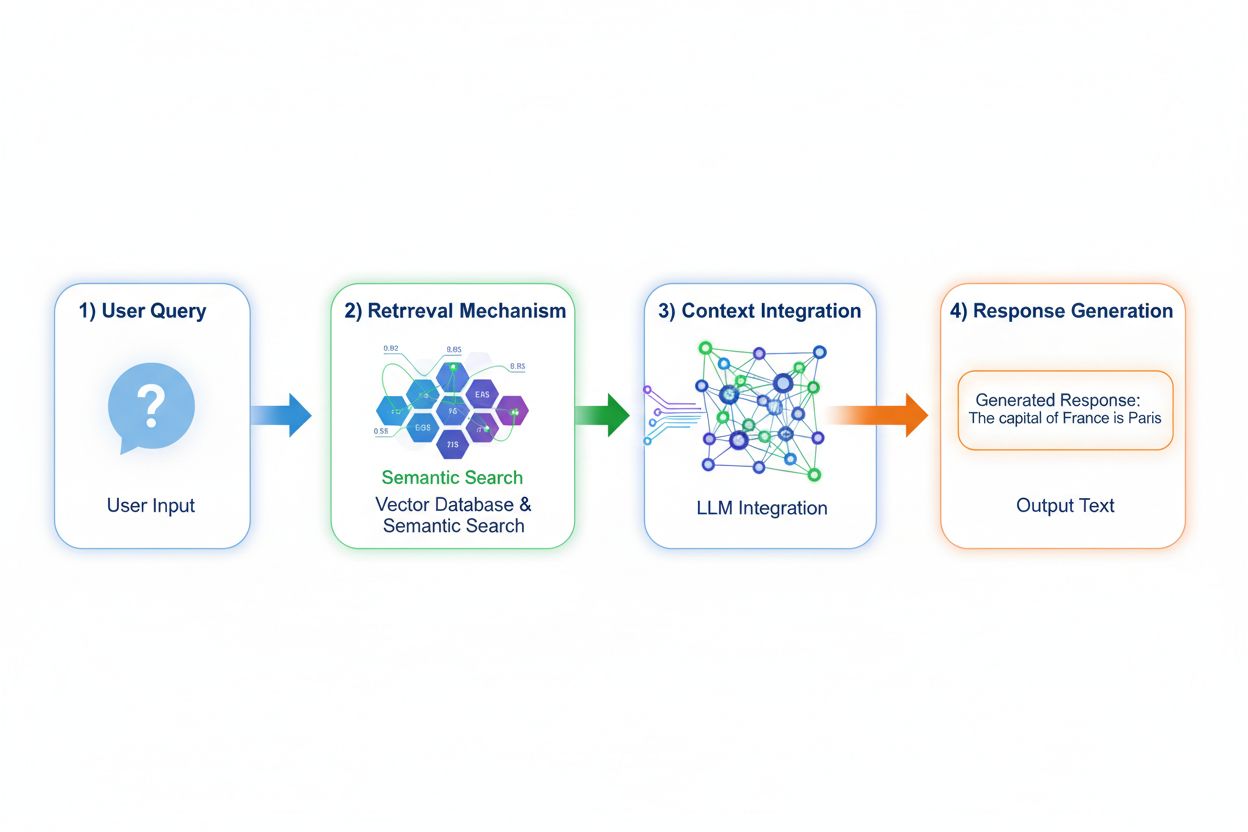
Retrieval Augmented Generation (RAG) zasadniczo zmienia sposób dostępu modeli do wiedzy, wdrażając czterostopniowy proces: kodowanie zapytania, wyszukiwanie semantyczne, ranking kontekstu i generowanie z ugruntowaniem w źródle. Po otrzymaniu zapytania RAG najpierw zamienia je na gęstą reprezentację wektorową przy użyciu modeli embeddingowych, a następnie przeszukuje bazę wektorową zawierającą zindeksowane dokumenty lub źródła wiedzy. Etap pobierania wykorzystuje wyszukiwanie semantyczne do znalezienia kontekstowo trafnych fragmentów, nie ograniczając się do prostego dopasowania słów kluczowych, a wyniki są rangowane wg trafności. Na końcu model generuje odpowiedzi, zachowując jawne odniesienia do pobranych źródeł, co umożliwia ugruntowanie wypowiedzi w rzeczywistych danych zamiast w wyuczonych parametrach. Taka architektura pozwala modelom uzyskiwać dostęp do informacji, które nie istniały w momencie treningu, czyniąc RAG szczególnie wartościowym tam, gdzie potrzebne są aktualne dane, własne zasoby lub często aktualizowana baza wiedzy. Mechanizm RAG przekształca model ze statycznego repozytorium wiedzy w dynamiczny syntezator informacji, który może inkorporować nowe dane bez ponownego treningu.
Profile dokładności i halucynacji dla tych podejść różnią się znacząco i mają wpływ na praktyczne wdrożenia. Optymalizacja danych treningowych daje modele z głębokim zrozumieniem domeny, ale o ograniczonej zdolności do sygnalizowania własnych granic wiedzy; gdy model po fine-tuningu napotyka pytania spoza rozkładu treningowego, może generować pewnie brzmiące, lecz błędne odpowiedzi. RAG istotnie zmniejsza halucynacje, ugruntowując odpowiedzi w pobranych dokumentach — model nie może podawać informacji, których nie ma w materiale źródłowym, co naturalnie ogranicza wymyślanie faktów. Jednak RAG niesie inne ryzyka: jeśli etap pobierania nie znajdzie trafnych źródeł lub wysoko oceni nieistotne dokumenty, model oprze odpowiedź na słabym kontekście. Aktualność danych staje się kluczowa dla systemów RAG; optymalizacja danych treningowych zamraża stan wiedzy z czasu treningu, a RAG ciągle odzwierciedla bieżący stan dokumentów źródłowych. Atrybucja źródeł to kolejna różnica: RAG pozwala na cytowanie i weryfikację twierdzeń, podczas gdy modele po fine-tuningu nie mogą wskazać pochodzenia wiedzy, co utrudnia fact-checking i weryfikację zgodności.
Ekonomia tych podejść wymusza odmienne struktury kosztowe, które organizacje muszą dokładnie ocenić. Optymalizacja danych treningowych wymaga dużych kosztów obliczeniowych na początku: klastry GPU działające przez dni lub tygodnie w celu fine-tuningu, usługi anotacji do przygotowania oznaczonych danych oraz wiedzę inżynierów ML do zaprojektowania skutecznych pipeline’ów treningowych. Po treningu koszty obsługi są niskie, ponieważ wnioskowanie wymaga tylko standardowej infrastruktury serwującej model, bez zewnętrznych zapytań. W systemach RAG proporcje są odwrotne: niższe koszty początkowe (brak fine-tuningu), lecz stałe wydatki infrastrukturalne na utrzymanie baz wektorowych, modeli embeddingowych, usług pobierania i pipeline’ów indeksujących dokumenty. Kluczowe czynniki kosztowe to:
Implikacje bezpieczeństwa i zgodności znacznie się różnią, co ma znaczenie w branżach regulowanych. Modele po fine-tuningu stwarzają wyzwania w zakresie ochrony danych, ponieważ wiedza z treningu jest osadzona w wagach modelu; jej wydobycie lub audyt wymaga zaawansowanych technik, a prywatność jest zagrożona, jeśli poufne dane wpływają na zachowanie modelu. Zgodność z regulacjami typu GDPR jest trudna, bo model „pamięta” dane treningowe w sposób utrudniający ich usunięcie czy modyfikację. RAG oferuje inne profile bezpieczeństwa: wiedza pozostaje w zewnętrznych, audytowalnych źródłach zamiast w parametrach modelu, co ułatwia wprowadzanie kontroli bezpieczeństwa i ograniczeń dostępu. Organizacje mogą wdrożyć szczegółowe uprawnienia do źródeł pobierania, audytować, z jakich dokumentów korzystał model w każdej odpowiedzi, i szybko usuwać poufne dane poprzez aktualizację dokumentów źródłowych bez ponownego treningu. Jednak RAG niesie ryzyka związane z ochroną baz wektorowych, bezpieczeństwem modeli embeddingowych i kontrolą, by pobrane dokumenty nie ujawniały wrażliwych informacji. Organizacje podlegające HIPAA lub GDPR często wybierają RAG ze względu na przejrzystość i możliwość audytu, podczas gdy te, które stawiają na przenośność modelu i działanie offline, preferują fine-tuning.
Wybór między podejściami wymaga analizy ograniczeń organizacyjnych i charakterystyki konkretnego zastosowania. Fine-tuning warto wybrać, gdy wiedza jest stabilna i rzadko się zmienia, gdy kluczowe jest niskie opóźnienie, gdy model musi działać offline lub w środowisku odizolowanym oraz gdy istotna jest spójność stylu i formatowania domenowego. Pobieranie w czasie rzeczywistym sprawdzi się, gdy wiedza regularnie się zmienia, ważna jest atrybucja źródeł i audytowalność dla zgodności, baza wiedzy jest zbyt obszerna, by efektywnie ją zakodować w modelu lub gdy organizacja potrzebuje aktualizować informacje bez ponownego treningu modelu. Przykładowe zastosowania podkreślają te różnice:
Podejścia hybrydowe łączą fine-tuning i RAG, by czerpać korzyści z obu strategii i łagodzić ich ograniczenia. Organizacje mogą dostrajać model do podstaw domeny i wzorców komunikacji, a jednocześnie korzystać z RAG, by pobierać aktualne, szczegółowe informacje — model uczy się jak myśleć o domenie, a RAG dostarcza mu jakie aktualne fakty włączyć do odpowiedzi. Ta strategia łączona szczególnie sprawdza się tam, gdzie potrzebna jest zarówno wiedza ekspercka, jak i bieżące informacje: bot doradztwa finansowego stuningowany na zasadach inwestowania i terminologii może pobierać aktualne dane rynkowe i finansowe firm przez RAG. Przykłady implementacji hybrydowych obejmują systemy opieki zdrowotnej dostrajane na wiedzy medycznej i protokołach, a pobierające dane o pacjencie przez RAG oraz platformy prawnicze, które fine-tunują się na rozumowaniu prawnym, a aktualne orzecznictwo pobierają z zewnątrz. Synergiczne korzyści to m.in. mniejsze halucynacje (gruntowanie w źródłach), lepsze rozumienie domeny (dzięki fine-tuningowi), szybsze odpowiedzi na typowe pytania (wiedza cache’owana), elastyczność aktualizacji informacji bez ponownego treningu. Coraz więcej organizacji wdraża takie optymalizacje wraz z upowszechnieniem zasobów obliczeniowych i rosnącą złożonością zastosowań wymagających zarówno głębi, jak i aktualności wiedzy.
Możliwość monitorowania odpowiedzi AI w czasie rzeczywistym nabiera kluczowego znaczenia, gdy organizacje wdrażają te strategie optymalizacji na szeroką skalę — zwłaszcza dla oceny, które podejście daje lepsze rezultaty w konkretnych zastosowaniach. Systemy monitorowania AI śledzą wyniki modeli, jakość pobierania i satysfakcję użytkowników, pozwalając organizacjom mierzyć, czy lepiej działa fine-tuning, czy RAG. Śledzenie cytowań ujawnia kluczowe różnice: systemy RAG naturalnie generują cytowania i odniesienia do źródeł, budując ścieżkę audytu dokumentującą, co wpłynęło na odpowiedź, podczas gdy modele po fine-tuningu nie dają wbudowanego mechanizmu monitorowania odpowiedzi czy atrybucji. Ma to ogromne znaczenie dla bezpieczeństwa marki i wywiadu konkurencyjnego — organizacje muszą wiedzieć, jak AI cytuje konkurencję, własne produkty czy przypisuje informacje do źródeł. Narzędzia, takie jak AmICited.com, wypełniają tę lukę, monitorując cytowania marek i firm w różnych strategiach optymalizacji i dostarczając monitoring w czasie rzeczywistym wzorców cytowań i ich częstości. Dzięki wdrożeniu kompleksowego monitoringu organizacje mogą sprawdzić, czy wybrana strategia (fine-tuning, RAG lub hybryda) rzeczywiście poprawia dokładność cytowań, redukuje halucynacje dotyczące konkurencji i zapewnia właściwą atrybucję do autorytatywnych źródeł. Takie podejście, oparte na danych, umożliwia ciągłe usprawnianie strategii optymalizacji w oparciu o rzeczywistą wydajność, a nie tylko teoretyczne założenia.
Branża ewoluuje w kierunku bardziej zaawansowanych podejść hybrydowych i adaptacyjnych, które dynamicznie wybierają strategię optymalizacji w zależności od charakterystyki zapytania i wymagań wiedzy. Nowe dobre praktyki obejmują wdrażanie fine-tuningu wspomaganego pobieraniem, gdzie modele są stuningowane pod kątem efektywnego wykorzystania pobranych informacji, a nie zapamiętywania faktów, oraz systemy adaptacyjnego routingu kierujące zapytania do modeli fine-tuningowych dla wiedzy stabilnej i do RAG w przypadku dynamicznych danych. Trendy wskazują na rosnące wdrożenia wyspecjalizowanych modeli embeddingowych oraz baz wektorowych zoptymalizowanych pod konkretne domeny, co umożliwia precyzyjniejsze wyszukiwanie semantyczne i ogranicza szum pobierania. Organizacje rozwijają wzorce ciągłego doskonalenia modeli, łącząc okresowe aktualizacje fine-tuningu z bieżącym uzupełnianiem przez RAG, tworząc systemy, które poprawiają się z czasem, jednocześnie zachowując dostęp do aktualnych informacji. Ewolucja strategii optymalizacji odzwierciedla świadomość branży, że żadne pojedyncze podejście nie zaspokoi wszystkich przypadków użycia; przyszłe systemy prawdopodobnie wdrożą inteligentne mechanizmy wyboru między fine-tuningiem, RAG i hybrydami, dynamicznie dostosowując się do kontekstu zapytania, stabilności wiedzy, oczekiwanego opóźnienia i wymagań zgodności. Wraz z dojrzewaniem tych technologii przewagą konkurencyjną stanie się nie tyle wybór jednego podejścia, ile umiejętne wdrożenie adaptacyjnych systemów wykorzystujących mocne strony każdej strategii.
Optymalizacja danych treningowych osadza wiedzę bezpośrednio w parametrach modelu poprzez fine-tuning, tworząc statyczną wiedzę, która pozostaje niezmienna po zakończeniu treningu. Pobieranie w czasie rzeczywistym utrzymuje wiedzę na zewnątrz i pobiera odpowiednie informacje dynamicznie podczas wnioskowania, umożliwiając dostęp do dynamicznych danych, które mogą się zmieniać między zapytaniami. Kluczowa różnica polega na momencie integracji wiedzy: optymalizacja danych treningowych odbywa się przed wdrożeniem, podczas gdy pobieranie w czasie rzeczywistym – przy każdym wywołaniu wnioskowania.
Fine-tuning stosuj, gdy wiedza jest stabilna i nie zmienia się często, gdy kluczowe jest niskie opóźnienie wnioskowania, gdy modele muszą działać offline lub gdy istotny jest spójny styl i formatowanie specyficzne dla domeny. Fine-tuning najlepiej sprawdza się w zadaniach specjalistycznych, takich jak diagnoza medyczna, analiza dokumentów prawnych czy obsługa klienta z niezmienną informacją o produkcie. Jednak fine-tuning wymaga znacznych początkowych zasobów obliczeniowych i staje się niepraktyczny, gdy informacje często się zmieniają.
Tak, podejścia hybrydowe łączą fine-tuning i RAG, aby czerpać korzyści z obu strategii. Organizacje mogą dostrajać modele do kluczowych podstaw domeny, jednocześnie używając RAG do dostępu do aktualnych, szczegółowych informacji. Takie podejście jest szczególnie skuteczne w aplikacjach wymagających zarówno specjalistycznej ekspertyzy, jak i aktualnych danych, np. boty doradztwa finansowego lub systemy opieki zdrowotnej potrzebujące zarówno wiedzy medycznej, jak i informacji o konkretnym pacjencie.
RAG znacząco ogranicza halucynacje, opierając odpowiedzi na pobranych dokumentach — model nie może podawać informacji, które nie występują w materiale źródłowym, co naturalnie ogranicza wymyślanie faktów. Modele po fine-tuningu z kolei mogą pewnie generować prawdopodobnie brzmiące, ale błędne informacje, gdy napotkają pytania spoza rozkładu treningowego. RAG umożliwia również weryfikację twierdzeń dzięki wskazaniu źródła, podczas gdy modele po fine-tuningu nie potrafią wskazać konkretnego pochodzenia swojej wiedzy.
Fine-tuning wymaga wysokich kosztów początkowych: godzin GPU (10 000–100 000+ USD za model), anotacji danych (0,50–5 USD za przykład) oraz czasu inżynierów. Po treningu koszty obsługi są stosunkowo niskie. Systemy RAG mają niższe koszty początkowe, ale stałe wydatki na infrastrukturę: bazy wektorowe, modele embeddingów i usługi pobierania. Modele po fine-tuningu skalują się liniowo z liczbą zapytań, a systemy RAG – zarówno z liczbą zapytań, jak i wielkością bazy wiedzy.
Systemy RAG naturalnie generują cytowania i wskazania źródeł, tworząc ścieżkę audytu pokazującą, które dokumenty wpłynęły na odpowiedź. Ma to kluczowe znaczenie dla bezpieczeństwa marki i wywiadu konkurencyjnego — organizacje mogą śledzić, jak systemy AI cytują konkurentów i odnoszą się do własnych produktów. Narzędzia takie jak AmICited.com monitorują, jak systemy AI cytują marki w różnych strategiach optymalizacji, umożliwiając śledzenie wzorców i częstotliwości cytowań w czasie rzeczywistym.
RAG jest zazwyczaj lepszy dla branż mocno regulowanych, jak ochrona zdrowia czy finanse. Wiedza pozostaje w zewnętrznych, audytowalnych źródłach danych, a nie w parametrach modelu, co ułatwia wdrażanie zabezpieczeń i kontroli dostępu. Organizacje mogą stosować szczegółowe uprawnienia, audytować, do jakich dokumentów miał dostęp model, i szybko usuwać wrażliwe informacje bez ponownego treningu. Branże objęte HIPAA czy GDPR często wybierają RAG ze względu na transparentność i możliwość audytu.
Wdrażaj systemy monitorowania AI, które śledzą wyniki modeli, jakość pobierania i wskaźniki satysfakcji użytkowników. W systemach RAG monitoruj trafność pobierania i jakość cytowań. W przypadku modeli po fine-tuningu śledź dokładność na zadaniach domenowych i poziom halucynacji. Korzystaj z narzędzi takich jak AmICited.com, aby sprawdzać, jak Twoje systemy AI cytują informacje i porównywać skuteczność różnych strategii optymalizacji na podstawie rzeczywistych wyników.
Śledź cytowania w czasie rzeczywistym w GPTs, Perplexity i Google AI Overviews. Dowiedz się, jakich strategii optymalizacji używa Twoja konkurencja i jak jest przywoływana w odpowiedziach AI.
Poznaj adaptację AI w czasie rzeczywistym – technologię umożliwiającą systemom AI ciągłą naukę na podstawie bieżących zdarzeń i danych. Dowiedz się, jak działa ...

Zrozum różnicę między danymi treningowymi AI a wyszukiwaniem na żywo. Dowiedz się, jak daty graniczne wiedzy, RAG i wyszukiwanie w czasie rzeczywistym wpływają ...
Dowiedz się, jak zoptymalizować swoje treści pod kątem włączenia do danych treningowych AI. Poznaj najlepsze praktyki, dzięki którym Twoja witryna stanie się wi...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.