
Embedding
Dowiedz się, czym są osadzenia, jak działają i dlaczego są niezbędne w systemach AI. Odkryj, jak tekst zamienia się w wektory liczbowe oddające znaczenie semant...
11 min czytania

Dowiedz się, jak osadzenia wektorowe umożliwiają systemom AI rozumienie znaczenia semantycznego i dopasowywanie treści do zapytań. Poznaj technologię stojącą za wyszukiwaniem semantycznym i dopasowywaniem treści przez AI.

Osadzenia wektorowe to numeryczna podstawa napędzająca nowoczesne systemy sztucznej inteligencji, przekształcająca surowe dane w matematyczne reprezentacje, które maszyny są w stanie rozumieć i przetwarzać. W istocie osadzenia zamieniają tekst, obrazy, dźwięk i inne typy treści w tablice liczb—zazwyczaj liczące od kilkudziesięciu do kilku tysięcy wymiarów—które uchwytują znaczenie semantyczne oraz kontekstowe zależności w tych danych. Ta numeryczna reprezentacja jest kluczowa dla działania systemów AI w zakresie dopasowywania treści, wyszukiwania semantycznego czy rekomendacji, umożliwiając maszynom nie tylko rozpoznawanie obecności słów czy obrazów, ale również rozumienie ich rzeczywistego znaczenia. Bez osadzeń systemy AI miałyby trudności z uchwyceniem subtelnych relacji pomiędzy pojęciami, co czyni je niezbędną infrastrukturą każdej nowoczesnej aplikacji AI.
Przekształcenie surowych danych w osadzenia wektorowe realizowane jest przez zaawansowane modele sieci neuronowych trenowane na ogromnych zbiorach danych w celu nauczenia się istotnych wzorców i relacji. Gdy wprowadzasz tekst do modelu osadzeń, przechodzi on przez wiele warstw sieci neuronowych, które stopniowo wydobywają informacje semantyczne, ostatecznie tworząc wektor o stałym rozmiarze, odzwierciedlający istotę tej treści. Popularne modele osadzeń takie jak Word2Vec, GloVE czy BERT stosują różne podejścia—Word2Vec wykorzystuje płytkie sieci neuronowe zoptymalizowane pod kątem szybkości, GloVE łączy globalną faktoryzację macierzy z lokalnymi oknami kontekstowymi, podczas gdy BERT opiera się na architekturze transformera do zrozumienia dwukierunkowego kontekstu.
| Model | Typ danych | Liczba wymiarów | Główne zastosowanie | Kluczowa zaleta |
|---|---|---|---|---|
| Word2Vec | Tekst (słowa) | 100-300 | Relacje między słowami | Szybki, wydajny |
| GloVE | Tekst (słowa) | 100-300 | Relacje semantyczne | Łączy kontekst globalny i lokalny |
| BERT | Tekst (zdania/dokumenty) | 768-1024 | Zrozumienie kontekstowe | Dwukierunkowa świadomość kontekstu |
| Sentence-BERT | Tekst (zdania) | 384-768 | Podobieństwo zdań | Zoptymalizowany pod wyszukiwanie semantyczne |
| Universal Sentence Encoder | Tekst (zdania) | 512 | Zadania wielojęzyczne | Niezależny językowo |
Te modele generują wektory o wysokiej liczbie wymiarów (często od 300 do 1 536 wymiarów), gdzie każdy wymiar odzwierciedla inny aspekt znaczenia, od właściwości gramatycznych po relacje koncepcyjne. Piękno tej numerycznej reprezentacji polega na tym, że umożliwia ona operacje matematyczne—możesz dodawać, odejmować i porównywać wektory, odkrywając relacje, które w surowym tekście byłyby niewidoczne. To właśnie ta matematyczna podstawa umożliwia wyszukiwanie semantyczne i inteligentne dopasowywanie treści na wielką skalę.
Prawdziwa siła osadzeń ujawnia się w podobieństwie semantycznym, czyli zdolności do rozpoznawania, że różne słowa lub frazy mogą oznaczać zasadniczo to samo w przestrzeni wektorowej. Gdy osadzenia są tworzone efektywnie, semantycznie podobne pojęcia naturalnie grupują się w przestrzeni o wysokiej liczbie wymiarów—„król” i „królowa” leżą blisko siebie, podobnie jak „samochód” i „pojazd”, mimo że są to różne słowa. Do mierzenia tego podobieństwa systemy AI wykorzystują metryki dystansu, takie jak cosinusowe podobieństwo (mierzące kąt między wektorami) lub iloczyn skalarny (mierzący wielkość i kierunek), które ilościowo określają, jak blisko siebie znajdują się dwa osadzenia. Na przykład zapytanie o „transport samochodowy” będzie miało wysokie podobieństwo cosinusowe do dokumentów o „podróżach autem”, pozwalając systemowi dopasować treści na podstawie znaczenia, a nie dokładnej zgodności słów kluczowych. To semantyczne rozumienie odróżnia nowoczesne wyszukiwanie AI od prostego dopasowania słów kluczowych, umożliwiając systemom rozpoznawanie intencji użytkownika i dostarczanie naprawdę trafnych wyników.
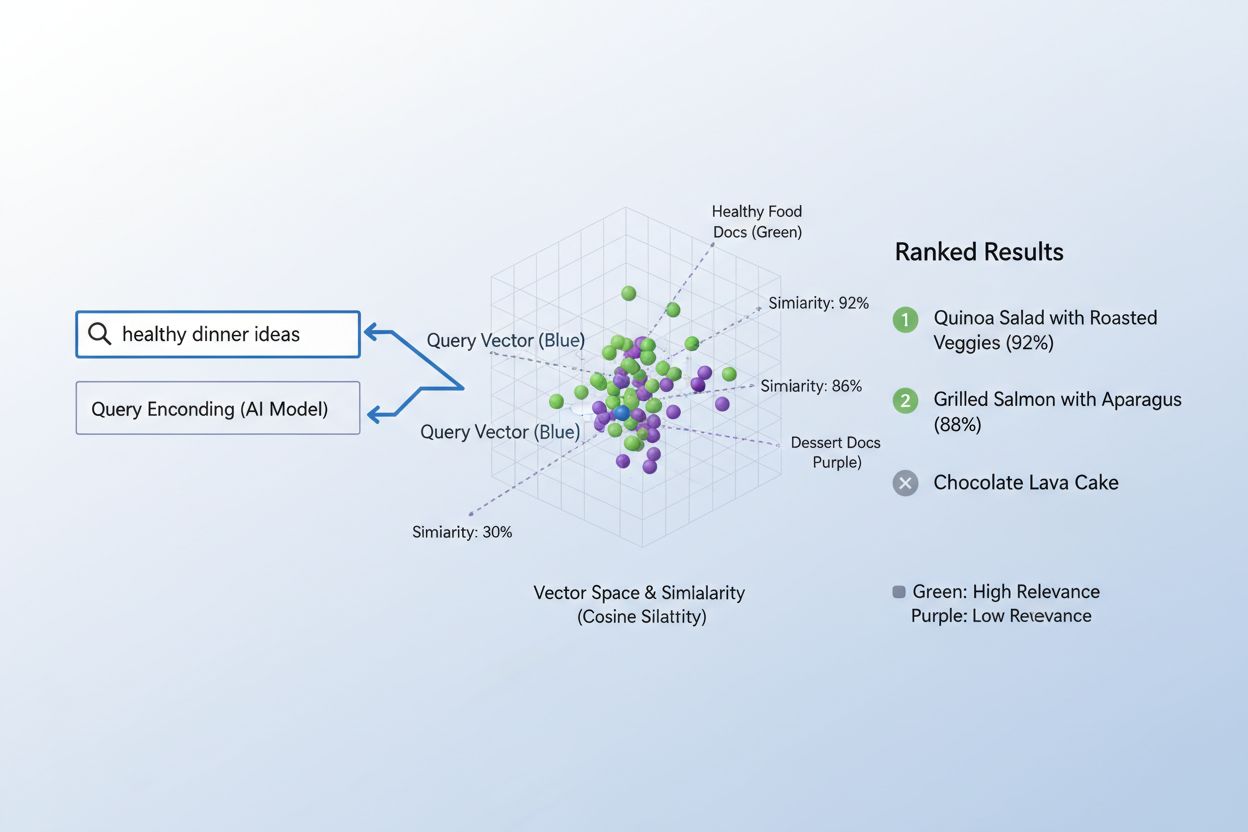
Proces dopasowywania treści do zapytań przy użyciu osadzeń opiera się na eleganckim, dwuetapowym schemacie, który napędza wszystko, od wyszukiwarek po systemy rekomendacji. Najpierw zarówno zapytanie użytkownika, jak i dostępne treści są niezależnie przekształcane w osadzenia przy użyciu tego samego modelu—zapytanie takie jak „najlepsze praktyki uczenia maszynowego” staje się wektorem, podobnie jak każdy artykuł, dokument czy produkt w bazie danych systemu. Następnie system oblicza podobieństwo między osadzeniem zapytania a każdym osadzeniem treści, zwykle używając podobieństwa cosinusowego, które daje wynik wskazujący, jak bardzo dana treść jest relewantna względem zapytania. Wyniki tych podobieństw są następnie sortowane, a treści z najwyższymi wynikami prezentowane użytkownikowi jako najbardziej trafne rezultaty. W rzeczywistym scenariuszu wyszukiwarki, gdy szukasz „jak trenować sieci neuronowe”, system koduje twoje zapytanie, porównuje je z milionami osadzeń dokumentów i zwraca artykuły o deep learningu, optymalizacji modeli i technikach treningowych—wszystko to bez potrzeby dokładnego dopasowania słów kluczowych. Proces ten trwa milisekundy, co czyni go praktycznym dla aplikacji czasu rzeczywistego obsługujących miliony użytkowników jednocześnie.
Różne typy osadzeń służą różnym celom, w zależności od tego, co chcesz dopasować lub zrozumieć. Osadzenia słów uchwytują znaczenie pojedynczych słów i dobrze sprawdzają się w zadaniach wymagających szczegółowego rozumienia semantycznego, podczas gdy osadzenia zdań i osadzenia dokumentów agregują znaczenie na dłuższych fragmentach tekstu, co czyni je idealnymi do dopasowywania całych zapytań do artykułów czy dokumentów. Osadzenia obrazów reprezentują treść wizualną numerycznie, umożliwiając systemom znajdowanie podobnych obrazów lub dopasowywanie obrazów do opisów tekstowych, zaś osadzenia użytkowników i produktów uchwytują wzorce zachowań i cechy, napędzając systemy rekomendacji sugerujące produkty na podstawie preferencji użytkownika. Wybór typu osadzenia to kompromis: osadzenia słów są wydajne obliczeniowo, ale tracą kontekst; osadzenia dokumentów zachowują pełne znaczenie, ale wymagają większej mocy obliczeniowej. Osadzenia domenowe, dostrojone na specjalistycznych zbiorach jak literatura medyczna czy dokumenty prawnicze, często przewyższają modele ogólnego przeznaczenia w zastosowaniach branżowych, choć wymagają dodatkowych danych treningowych i większych zasobów obliczeniowych.
W praktyce osadzenia napędzają jedne z najbardziej wpływowych zastosowań AI, z których korzystamy codziennie—od wyników wyszukiwania, które widzisz, po produkty rekomendowane ci w sieci. Wyszukiwarki semantyczne wykorzystują osadzenia do rozumienia intencji zapytań i prezentowania trafnych treści niezależnie od zgodności słów kluczowych, a systemy rekomendacji w Netflixie, Amazonie czy Spotify wykorzystują osadzenia użytkowników i produktów do przewidywania, co będziesz chciał obejrzeć, kupić lub czego posłuchać. Systemy moderacji treści używają osadzeń do wykrywania szkodliwych wpisów poprzez porównywanie postów użytkowników z osadzeniami znanych naruszeń polityk, a systemy odpowiadające na pytania dopasowują zapytania do odpowiednich artykułów w bazie wiedzy, znajdując semantycznie podobne treści. Silniki personalizacji wykorzystują osadzenia do rozumienia preferencji użytkownika i dostosowywania doświadczeń, a systemy wykrywania anomalii identyfikują nietypowe wzorce, rozpoznając, gdy nowe dane znacznie odbiegają od oczekiwanych klastrów osadzeń. W AmICited wykorzystujemy osadzenia do monitorowania sposobów użycia systemów AI w internecie, dopasowując zapytania użytkowników i treści, by śledzić, gdzie pojawia się treść generowana lub wspierana przez AI, pomagając markom zrozumieć ich ślad AI i zapewnić właściwe przypisanie autorstwa.
Efektywne wdrożenie osadzeń wymaga uwzględnienia kilku istotnych aspektów technicznych wpływających zarówno na wydajność, jak i koszty. Wybór modelu jest kluczowy—trzeba zrównoważyć jakość semantyczną osadzeń z wymaganiami obliczeniowymi; większe modele, jak BERT, tworzą bogatsze reprezentacje, lecz wymagają więcej mocy obliczeniowej niż ich lżejsze alternatywy. Liczba wymiarów to istotny kompromis: osadzenia o większej liczbie wymiarów uchwytują więcej niuansów, ale zużywają więcej pamięci i spowalniają obliczenia podobieństwa; osadzenia o mniejszej liczbie wymiarów są szybsze, ale mogą utracić ważne informacje semantyczne. Do efektywnego dopasowywania na dużą skalę systemy wykorzystują specjalistyczne strategie indeksowania, takie jak FAISS (Facebook AI Similarity Search) czy Annoy (Approximate Nearest Neighbors Oh Yeah), które pozwalają znaleźć podobne osadzenia w milisekundy, organizując wektory w struktury drzewiaste lub stosując schematy haszowania wrażliwego na lokalizację. Dostrajanie modeli osadzeń na danych domenowych znacząco poprawia trafność w zastosowaniach specjalistycznych, choć wymaga oznaczonych danych treningowych i dodatkowych zasobów obliczeniowych. Organizacje muszą nieustannie balansować pomiędzy szybkością a dokładnością, kosztem obliczeniowym a jakością semantyczną oraz modelami ogólnego przeznaczenia a wyspecjalizowanymi rozwiązaniami, zależnie od swoich zastosowań i ograniczeń.
Przyszłość osadzeń zmierza w kierunku większej wyrafinowania, wydajności i integracji z szerszymi systemami AI, obiecując jeszcze potężniejsze możliwości dopasowywania i rozumienia treści. Osadzenia multimodalne, przetwarzające równocześnie tekst, obrazy i dźwięk, zaczynają się pojawiać, umożliwiając systemom dopasowywanie pomiędzy różnymi typami treści—odnajdując obrazy odpowiadające zapytaniom tekstowym lub odwrotnie—co otwiera zupełnie nowe możliwości odkrywania i rozumienia treści. Badacze opracowują coraz bardziej wydajne modele osadzeń, oferujące porównywalną jakość semantyczną przy znacznie mniejszej liczbie parametrów, czyniąc zaawansowane możliwości AI dostępnymi także dla mniejszych firm i urządzeń brzegowych. Integracja osadzeń z dużymi modelami językowymi tworzy systemy, które nie tylko dopasowują treści semantycznie, ale także rozumieją kontekst, niuanse i intencje na niespotykanym dotąd poziomie. W miarę jak systemy AI stają się coraz powszechniejsze w internecie, możliwość śledzenia, monitorowania i rozumienia, jak treści są dopasowywane i wykorzystywane, nabiera coraz większego znaczenia—tu właśnie platformy takie jak AmICited wykorzystują osadzenia, by pomagać organizacjom monitorować obecność marki, śledzić wzorce użycia AI i zapewniać właściwe przypisanie oraz odpowiednie wykorzystanie ich treści. Konwergencja lepszych osadzeń, wydajniejszych modeli i zaawansowanych narzędzi monitorujących tworzy przyszłość, w której systemy AI będą bardziej przejrzyste, odpowiedzialne i zgodne z ludzkimi wartościami.
Osadzenie wektorowe to numeryczna reprezentacja danych (tekstu, obrazów, dźwięku) w przestrzeni o wysokiej liczbie wymiarów, która uchwytuje znaczenie semantyczne oraz relacje. Zamienia abstrakcyjne dane w tablice liczb, które maszyny mogą przetwarzać i analizować matematycznie.
Osadzenia zamieniają abstrakcyjne dane w liczby, które maszyny mogą przetwarzać, co pozwala AI identyfikować wzorce, podobieństwa i relacje pomiędzy różnymi fragmentami treści. Ta matematyczna reprezentacja umożliwia systemom AI rozumienie znaczenia, a nie tylko dopasowywanie słów kluczowych.
Dopasowanie słów kluczowych szuka dokładnych zgodności słów, podczas gdy podobieństwo semantyczne rozumie znaczenie. Pozwala to systemom znajdować powiązane treści nawet bez identycznych słów—na przykład dopasować 'samochód' do 'auto' na podstawie relacji semantycznej, a nie dokładnej zgodności tekstu.
Tak, osadzenia mogą reprezentować tekst, obrazy, dźwięk, profile użytkowników, produkty i więcej. Różne modele osadzeń są zoptymalizowane pod różne typy danych, od Word2Vec dla tekstu, przez CNN do obrazów, po spektrogramy dla dźwięku.
AmICited wykorzystuje osadzenia, by rozumieć, jak systemy AI semantycznie dopasowują i odnoszą się do Twojej marki na różnych platformach i w odpowiedziach AI. Pomaga to śledzić obecność Twoich treści w odpowiedziach generowanych przez sztuczną inteligencję oraz zapewnić właściwe przypisanie autorstwa.
Kluczowe wyzwania to wybór odpowiedniego modelu, zarządzanie kosztami obliczeniowymi, obsługa danych o wysokiej liczbie wymiarów, dostrajanie pod konkretne domeny oraz równoważenie szybkości i dokładności w obliczeniach podobieństwa.
Osadzenia umożliwiają wyszukiwanie semantyczne, które rozumie intencje użytkownika i zwraca trafne wyniki na podstawie znaczenia, a nie tylko zgodności słów kluczowych. Pozwala to systemom wyszukiwania znajdować koncepcyjnie powiązane treści, nawet jeśli nie zawierają dokładnych terminów z zapytania.
Duże modele językowe używają osadzeń wewnętrznie do rozumienia i generowania tekstu. Osadzenia są podstawą tego, jak te modele przetwarzają informacje, dopasowują treści i generują odpowiedzi odpowiednie kontekstowo.
Osadzenia wektorowe napędzają systemy AI takie jak ChatGPT, Perplexity i Google AI Overviews. AmICited śledzi, jak te systemy cytują i odnoszą się do Twoich treści, pomagając Ci zrozumieć obecność Twojej marki w odpowiedziach generowanych przez AI.
Dowiedz się, czym są osadzenia, jak działają i dlaczego są niezbędne w systemach AI. Odkryj, jak tekst zamienia się w wektory liczbowe oddające znaczenie semant...

Dowiedz się, jak wyszukiwanie wektorowe wykorzystuje osadzenia uczenia maszynowego do znajdowania podobnych elementów na podstawie znaczenia, a nie dokładnych s...

Wyszukiwanie wektorowe wykorzystuje matematyczne reprezentacje wektorowe do znajdowania podobnych danych poprzez pomiar relacji semantycznych. Dowiedz się, jak ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.