
Platformy wycofywane i widoczność AI: Zarządzanie przejściami
Dowiedz się, jak zarządzać przejściami platform AI i utrzymać widoczność cytowań podczas wycofywania platform. Strategiczny przewodnik po obsłudze wycofanych pl...
9 min czytania

Dowiedz się, jak dostosować swoją strategię AI, gdy platformy się zmieniają. Poznaj strategie migracji, narzędzia monitorujące i najlepsze praktyki radzenia sobie z wycofaniem i aktualizacjami platform AI.
Wycofanie API GPT-4o firmy OpenAI w 2026 roku to przełomowy moment dla firm opartych na platformach AI — to już nie teoretyczny problem, lecz realny, wymagający strategicznego podejścia. W przeciwieństwie do tradycyjnych wycofań oprogramowania, które często zapewniają długie okresy wsparcia, zmiany na platformach AI mogą być ogłaszane z relatywnie krótkim wyprzedzeniem, zmuszając organizacje do szybkich decyzji dotyczących swojego stosu technologicznego. Platformy wycofują modele z różnych powodów: względów bezpieczeństwa w przypadku starszych systemów niespełniających aktualnych standardów, ochrony przed odpowiedzialnością za możliwe nadużycia lub szkodliwe wyniki, zmieniających się modeli biznesowych promujących nowsze rozwiązania oraz potrzeby konsolidacji zasobów wokół najnowszych badań. Gdy firma głęboko zintegrowała konkretny model ze swoimi działaniami — czy to w aplikacjach dla klientów, analizach wewnętrznych, czy systemach decyzyjnych — ogłoszenie wycofania API natychmiast wymusza migrację, testowanie i walidację alternatyw. Wpływ finansowy wykracza poza same koszty inżynieryjne; pojawia się utrata produktywności podczas migracji, potencjalne przerwy w działaniu usług i ryzyko pogorszenia wydajności, jeśli alternatywne modele nie dorównują oryginałowi. Organizacje nieprzygotowane na taki scenariusz często działają reaktywnie, negocjując wydłużenie wsparcia lub akceptując gorsze alternatywy tylko dlatego, że nie mają spójnej strategii migracji. Kluczowy wniosek brzmi: wycofanie platformy nie jest już rzadkością — to przewidywalna cecha krajobrazu AI, wymagająca proaktywnego planowania.
Tradycyjne ramy ciągłości działania, takie jak ISO 22301, zaprojektowano z myślą o awariach infrastruktury — systemy przestają działać, a Ty odtwarzasz je z kopii zapasowych lub systemów awaryjnych. Te ramy opierają się na wskaźnikach takich jak Recovery Time Objective (RTO) i Recovery Point Objective (RPO), mierzących, jak szybko można przywrócić usługę i ile utraty danych jest akceptowalne. Jednak awarie AI przebiegają zupełnie inaczej — i to jest kluczowe: system nadal działa, generuje wyniki i obsługuje użytkowników, jednocześnie po cichu podejmując błędne decyzje. Model wykrywający oszustwa może coraz częściej akceptować fałszywe transakcje; silnik cenowy może systematycznie zaniżać ceny; system przyznawania kredytów może niepostrzeżenie wprowadzać ukryte uprzedzenia — wszystko przy pozornej normalności. Tradycyjne plany ciągłości nie mają mechanizmów wykrywania takich awarii, bo nie szukają spadku dokładności czy narastających uprzedzeń — szukają awarii systemu i utraty danych. Nowa rzeczywistość wymaga dodatkowych wskaźników: Recovery Accuracy Objective (RAO), określającego akceptowalne progi wydajności, oraz Recovery Fairness Objective (RFO), zapewniającego, że zmiany modelu nie wprowadzają lub nie wzmacniają dyskryminacji. Przykład: firma finansowa wykorzystuje model AI do decyzji kredytowych; jeśli model zacznie systematycznie odrzucać wnioski określonych grup demograficznych, tradycyjny plan ciągłości nie widzi problemu — system działa. Tymczasem firma naraża się na naruszenia regulacji, utratę reputacji i potencjalną odpowiedzialność prawną.
| Aspekt | Tradycyjne awarie infrastruktury | Awarie modeli AI |
|---|---|---|
| Wykrywanie | Natychmiastowe (system nie działa) | Opóźnione (wyniki wydają się poprawne) |
| Widoczność skutków | Jasna i mierzalna | Ukryta w metrykach dokładności |
| Wskaźnik odzyskiwania | RTO/RPO | Potrzebne RAO/RFO |
| Przyczyna | Sprzęt/sieć | Dryf, uprzedzenia, zmiany danych |
| Doświadczenie użytkownika | Brak usługi | Usługa działa, ale błędnie |
| Ryzyko zgodności | Utrata danych, przestój | Dyskryminacja, odpowiedzialność |
Cykle wycofań platform zazwyczaj mają przewidywalny przebieg, choć harmonogram może się znacząco różnić w zależności od dojrzałości platformy i liczby użytkowników. Większość platform ogłasza wycofanie z 12-24-miesięcznym wyprzedzeniem, dając deweloperom czas na migrację — ale ten czas bywa krótszy w przypadku dynamicznie rozwijających się platform AI, gdzie nowe modele to istotny postęp. Samo ogłoszenie wywołuje natychmiastową presję: zespoły muszą ocenić wpływ, rozważyć alternatywy, zaplanować migrację i zapewnić budżet oraz zasoby, jednocześnie utrzymując bieżące działania. Złożoność zarządzania wersjami rośnie znacząco, gdy organizacje utrzymują równolegle kilka modeli podczas przejścia; de facto utrzymujesz dwa równoległe systemy, podwajając testy i monitoring. Harmonogram migracji to nie tylko zamiana wywołań API; to także trenowanie na wynikach nowego modelu, walidacja, czy nowy model spełnia wymagania w Twoich przypadkach użycia, oraz często dostrajanie parametrów zoptymalizowanych pod wycofywany model. Dodatkowe ograniczenia to: procesy regulacyjne wymagające walidacji nowych modeli, zobowiązania umowne wskazujące konkretne wersje modeli czy systemy legacy tak głęboko powiązane z API, że przeprojektowanie wymaga ogromnego nakładu pracy. Zrozumienie tych cykli pozwala przejść od reaktywnego działania do proaktywnego planowania, wpisując migracje w roadmapy produktów, a nie traktując je jako sytuacje awaryjne.
Bezpośrednie koszty migracji platformy są często niedoszacowane i wykraczają daleko poza oczywiste godziny inżynieryjne na zmianę wywołań API i integrację nowych modeli. Praca deweloperska to nie tylko zmiany w kodzie, ale też modyfikacje architektury — jeśli Twój system był zoptymalizowany pod konkretne opóźnienia, limity przepustowości czy formaty wyjściowe wycofywanego modelu, nowa platforma może wymagać poważnego przeprojektowania. Testowanie i walidacja to znaczący ukryty koszt — nie można po prostu wymienić modelu i mieć nadzieję na sukces, zwłaszcza w aplikacjach krytycznych. Każdy przypadek, przypadek brzegowy i punkt integracji muszą być przetestowane pod kątem akceptowalnych wyników nowego modelu. Różnice wydajności mogą być ogromne — nowy model może być szybszy, ale mniej dokładny, tańszy, ale z innym formatem wyjściowym, lub bardziej zaawansowany, ale wymagający innego formatu wejściowego. Dochodzą kwestie zgodności i audytu: jeśli działasz w sektorze regulowanym (finanse, zdrowie, ubezpieczenia), musisz udokumentować migrację, zwalidować, czy nowy model spełnia wymagania i często uzyskać zatwierdzenie przed wdrożeniem. Koszt alternatywny oddelegowania zasobów inżynierskich na migrację jest znaczący — te osoby mogłyby rozwijać nowe funkcje, ulepszać systemy lub redukować dług techniczny. Organizacje często odkrywają, że “nowy” model wymaga innego strojenia hiperparametrów, innego przetwarzania danych czy innego monitoringu, co wydłuża czas i koszty migracji.
Najbardziej odporne organizacje projektują swoje systemy AI z niezależnością od platformy jako kluczową zasadą architektoniczną, wiedząc, że dzisiejszy najnowszy model zostanie kiedyś wycofany. Warstwy abstrakcji i opakowania API to podstawowe narzędzia — zamiast bezpośrednio wywoływać API w kodzie, tworzysz zunifikowany interfejs ukrywający szczegóły dostawcy modelu. Dzięki temu, gdy trzeba migrować między platformami, wystarczy zaktualizować wrapper, a nie zmieniać dziesiątki punktów integracji w systemie. Strategie wielomodelowe dają dodatkową odporność; niektóre organizacje uruchamiają równolegle kilka modeli dla decyzji krytycznych, stosując metody ansamblowe lub utrzymując model zapasowy. To podejście zwiększa złożoność i koszty, ale daje zabezpieczenie — jeśli jeden model zostanie wycofany, drugi już działa produkcyjnie. Mechanizmy awaryjne są równie ważne: jeśli model podstawowy stanie się niedostępny lub generuje podejrzane wyniki, system powinien płynnie przełączyć się na alternatywę, zamiast całkowicie się zatrzymać. Solidne monitorowanie i alertowanie pozwala wykryć spadek wydajności, dryf dokładności czy nieoczekiwane zmiany zachowania, zanim wpłyną one na użytkowników. Dokumentacja i kontrola wersji powinny jasno określać, które modele są używane, kiedy wdrożone i jakie mają cechy wydajnościowe — ta wiedza jest bezcenna, gdy decyzje migracyjne trzeba podejmować szybko. Organizacje inwestujące w takie wzorce architektoniczne traktują zmiany platform jako zarządzalne wydarzenia, nie kryzysy.
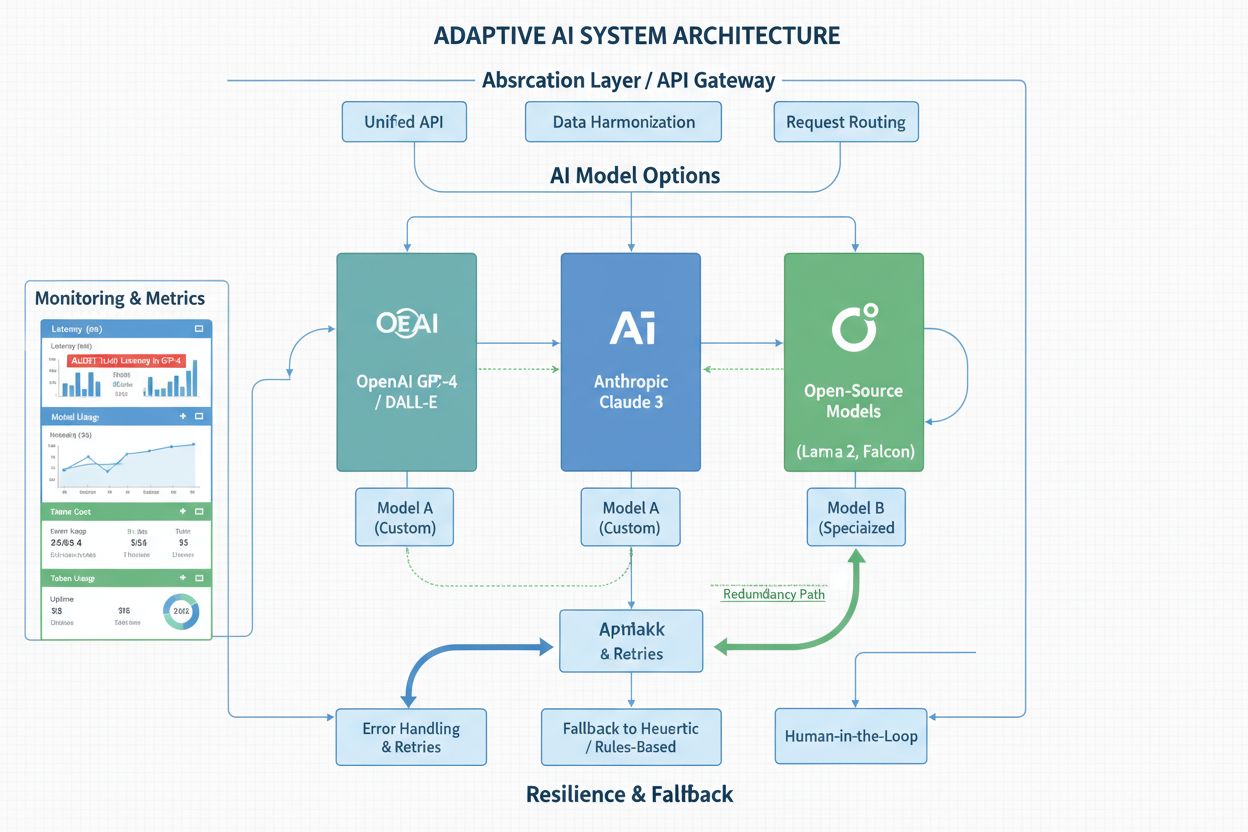
By być na bieżąco z ogłoszeniami platform i powiadomieniami o wycofaniach, potrzebny jest systematyczny monitoring, a nie nadzieja, że ważna wiadomość nie zginie w skrzynce mailowej. Większość głównych platform AI publikuje harmonogramy wycofań na blogach, stronach dokumentacji i portalach deweloperskich, ale łatwo je przeoczyć w natłoku aktualizacji i nowych funkcji. Skonfigurowanie automatycznych alertów dla wybranych platform — przez RSS, subskrypcje mailowe lub dedykowane usługi monitorujące — gwarantuje natychmiastowe powiadomienie o zmianach, zamiast odkrycia ich po miesiącach. Poza oficjalnymi ogłoszeniami, kluczowe jest śledzenie zmian wydajności modeli AI w produkcji; platformy czasem modyfikują modele subtelnie i możesz zauważyć spadek dokładności lub zmianę zachowania przed oficjalnym ogłoszeniem. Narzędzia takie jak AmICited umożliwiają monitorowanie, jak platformy AI odnoszą się do Twojej marki i treści, dostarczając wglądu w zmiany i aktualizacje mogące wpłynąć na Twój biznes. Wywiad konkurencyjny dotyczący zmian platform pomaga przewidzieć trendy i to, które modele mogą być następne do wycofania — jeśli konkurencja już migruje, to sygnał, że zmiany nadchodzą. Niektóre organizacje subskrybują newslettery platform, uczestniczą w społecznościach lub utrzymują kontakt z opiekunami kont, którzy mogą przekazać wczesne ostrzeżenia. Inwestycja w infrastrukturę monitorującą zwraca się, gdy otrzymujesz wcześniejsze powiadomienia o wycofaniu i masz dodatkowe miesiące na planowanie, zamiast działać w pośpiechu.
Dobrze skonstruowany plan reagowania na zmiany platformy zamienia potencjalny chaos w uporządkowany proces z jasnymi fazami i punktami decyzyjnymi. Faza oceny zaczyna się natychmiast po informacji o wycofaniu; zespół ocenia wpływ na wszystkie systemy korzystające z wycofywanego modelu, szacuje nakład migracji oraz identyfikuje ograniczenia regulacyjne lub umowne mogące wpłynąć na harmonogram. Efektem jest szczegółowa inwentaryzacja systemów, ich krytyczności i zależności — to podstawa dalszych decyzji. Faza planowania to opracowanie szczegółowej mapy migracji, przydział zasobów, ustalenie harmonogramu i kolejności migracji (zwykle zaczynając od systemów mniej krytycznych, by zdobyć doświadczenie przed migracją kluczowych aplikacji). Faza testowania to miejsce największego wysiłku: zespoły walidują, czy alternatywne modele spełniają wymagania w konkretnych przypadkach, identyfikują luki wydajnościowe lub różnice zachowania i opracowują obejścia lub optymalizacje. Faza wdrażania polega na stopniowej migracji — zaczynając od canary deployment na małym procencie ruchu, monitorując problemy i stopniowo zwiększając udział nowego modelu. Monitoring po migracji trwa tygodnie lub miesiące, śledząc metryki wydajności, opinie użytkowników i zachowanie systemu, by upewnić się, że migracja się powiodła, a nowy model działa zgodnie z oczekiwaniami. Organizacje stosujące takie podejście raportują płynniejsze migracje z mniejszą liczbą niespodzianek i ograniczonym wpływem na użytkowników.
Wybór nowej platformy lub modelu wymaga systematycznej oceny według kryteriów wyboru platformy odpowiadających specyficznym potrzebom i ograniczeniom organizacji. Właściwości wydajnościowe są oczywiste — dokładność, opóźnienie, przepustowość, koszt — ale równie ważne są mniej oczywiste czynniki: stabilność dostawcy (czy platforma przetrwa 5 lat?), jakość wsparcia, dokumentacja, wielkość społeczności. Dylemat open source vs. rozwiązania zamknięte wymaga namysłu; open source daje niezależność od decyzji dostawcy i możliwość uruchamiania modeli na własnej infrastrukturze, ale wymaga więcej pracy inżynierskiej. Platformy zamknięte są wygodne, regularnie aktualizowane i oferują wsparcie, ale wprowadzają ryzyko uzależnienia od dostawcy — biznes staje się zależny od istnienia platformy i jej polityki cenowej. Analiza kosztów i korzyści powinna uwzględniać całkowity koszt posiadania, nie tylko cenę za wywołanie API; tańszy model wymagający więcej pracy integracyjnej lub dający gorsze wyniki może kosztować więcej w sumie. Długoterminowa stabilność to czynnik często pomijany; wybór modelu z platformy dobrze finansowanej i stabilnej zmniejsza ryzyko przyszłych wycofań, a wybór modelu ze start-upu lub projektu badawczego zwiększa ryzyko zmian. Niektóre organizacje celowo wybierają kilka platform, by ograniczyć zależność od jednego dostawcy, godząc się na większą złożoność w zamian za mniejsze ryzyko zakłóceń. Proces oceny powinien być udokumentowany i okresowo powtarzany, bo krajobraz modeli i platform stale się zmienia.
Organizacje, które osiągają sukces w dynamicznym świecie AI, traktują ciągłą naukę i adaptację jako podstawowe zasady działania, a nie rzadkie reakcje na zakłócenia. Budowanie i utrzymywanie relacji z dostawcami platform — poprzez opiekę nad kontem, udział w radach użytkowników czy regularny kontakt z zespołami produktowymi — daje wcześniejszy dostęp do informacji o nadchodzących zmianach, a czasem możliwość wpłynięcia na harmonogram wycofań. Uczestnictwo w programach beta nowych modeli i platform pozwala ocenić alternatywy, zanim staną się powszechnie dostępne, co daje przewagę w planowaniu migracji w razie wycofania obecnej platformy. Bycie na bieżąco z trendami branżowymi i prognozami pozwala przewidzieć, które modele i platformy zyskają dominację, a które mogą zniknąć; takie spojrzenie w przyszłość umożliwia strategiczne decyzje co do inwestycji w platformy. Budowanie wewnętrznych kompetencji w ocenie modeli AI, wdrażaniu i monitoringu sprawia, że organizacja nie jest zależna od konsultantów czy dostawców przy kluczowych decyzjach o zmianach platform. Kompetencje te obejmują ocenę wydajności modeli, wykrywanie dryfu i uprzedzeń, projektowanie systemów odpornych na zmiany modeli oraz podejmowanie decyzji technicznych w warunkach niepewności. Organizacje inwestujące w te umiejętności traktują zmiany platform jako zarządzalne wyzwania, a nie egzystencjalne zagrożenia, i są lepiej przygotowane do wykorzystania postępu AI, gdy pojawiają się nowe modele i platformy.
Większość platform AI zapewnia 12-24 miesiące powiadomienia przed wycofaniem modelu, choć ten okres może się różnić. Kluczowe jest, aby rozpocząć planowanie natychmiast po ogłoszeniu, a nie czekać do zbliżającego się terminu. Wczesne planowanie daje czas na dokładne przetestowanie alternatyw i unikanie pośpiesznych migracji, które mogą wprowadzić błędy lub problemy z wydajnością.
Wycofanie platformy zazwyczaj oznacza, że model lub wersja API nie otrzymuje już aktualizacji i w końcu zostanie usunięta. Wyłączenie API to ostatni etap, w którym dostęp zostaje całkowicie zamknięty. Zrozumienie tej różnicy pomaga zaplanować harmonogram migracji — możesz mieć kilka miesięcy powiadomienia o wycofaniu przed faktycznym wyłączeniem.
Tak, i wiele organizacji tak robi w przypadku kluczowych aplikacji. Uruchamianie kilku modeli równolegle lub utrzymywanie modelu zapasowego jako zabezpieczenia daje ochronę przed zmianami na platformach. Jednak takie podejście zwiększa złożoność i koszty, dlatego zwykle stosuje się je w systemach o krytycznym znaczeniu, gdzie niezawodność jest najważniejsza.
Zacznij od udokumentowania wszystkich modeli AI i platform używanych w Twojej organizacji, wraz z informacją, które systemy są od nich zależne. Monitoruj oficjalne ogłoszenia platform, subskrybuj powiadomienia o wycofaniu i korzystaj z narzędzi monitorujących, aby śledzić zmiany na platformie. Regularne audyty infrastruktury AI pozwalają być świadomym potencjalnych skutków.
Brak dostosowania się do zmian na platformach może skutkować przerwami w działaniu usług, gdy platformy zamykają dostęp, spadkiem wydajności, jeśli trzeba korzystać z mniej optymalnych alternatyw, naruszeniami przepisów, gdy system przestaje być zgodny, oraz utratą reputacji z powodu przestojów. Proaktywna adaptacja zapobiega tym kosztownym scenariuszom.
Projektuj swoje systemy z warstwami abstrakcji izolującymi kod zależny od platformy, utrzymuj relacje z wieloma dostawcami, rozważaj otwarte alternatywy i dokumentuj architekturę, by ułatwić migracje. Te praktyki zmniejszają zależność od pojedynczego dostawcy i zapewniają elastyczność w razie zmian na platformach.
Narzędzia takie jak AmICited monitorują, jak platformy AI odnoszą się do Twojej marki i śledzą aktualizacje platformy. Dodatkowo subskrybuj oficjalne newslettery platform, ustawiaj RSS na ogłoszenia o wycofaniu, uczestnicz w społecznościach deweloperów i utrzymuj kontakt z opiekunami kont platform, by mieć wcześniejsze ostrzeżenia o zmianach.
Przeglądaj swoją strategię platform AI co najmniej raz na kwartał lub przy każdej informacji o istotnych zmianach na platformie. Częstsze przeglądy (miesięczne) są wskazane, jeśli działasz w szybko zmieniającej się branży lub korzystasz z wielu platform. Regularne przeglądy pozwalają być na bieżąco z ryzykami i planować migracje z wyprzedzeniem.
Monitoruj, jak platformy AI odnoszą się do Twojej marki i śledź kluczowe aktualizacje platformy, zanim wpłyną one na Twój biznes. Otrzymuj powiadomienia w czasie rzeczywistym o wycofaniu i zmianach na platformach.
Dowiedz się, jak zarządzać przejściami platform AI i utrzymać widoczność cytowań podczas wycofywania platform. Strategiczny przewodnik po obsłudze wycofanych pl...

Dowiedz się, jak przygotować swoją organizację na nieznane przyszłe platformy AI. Poznaj ramy gotowości AI, kluczowe filary oraz praktyczne kroki, by pozostać k...

Opanuj strategie zwinnej optymalizacji, aby szybko reagować na zmiany algorytmów platform AI. Naucz się monitorować aktualizacje ChatGPT, Perplexity i Google AI...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.