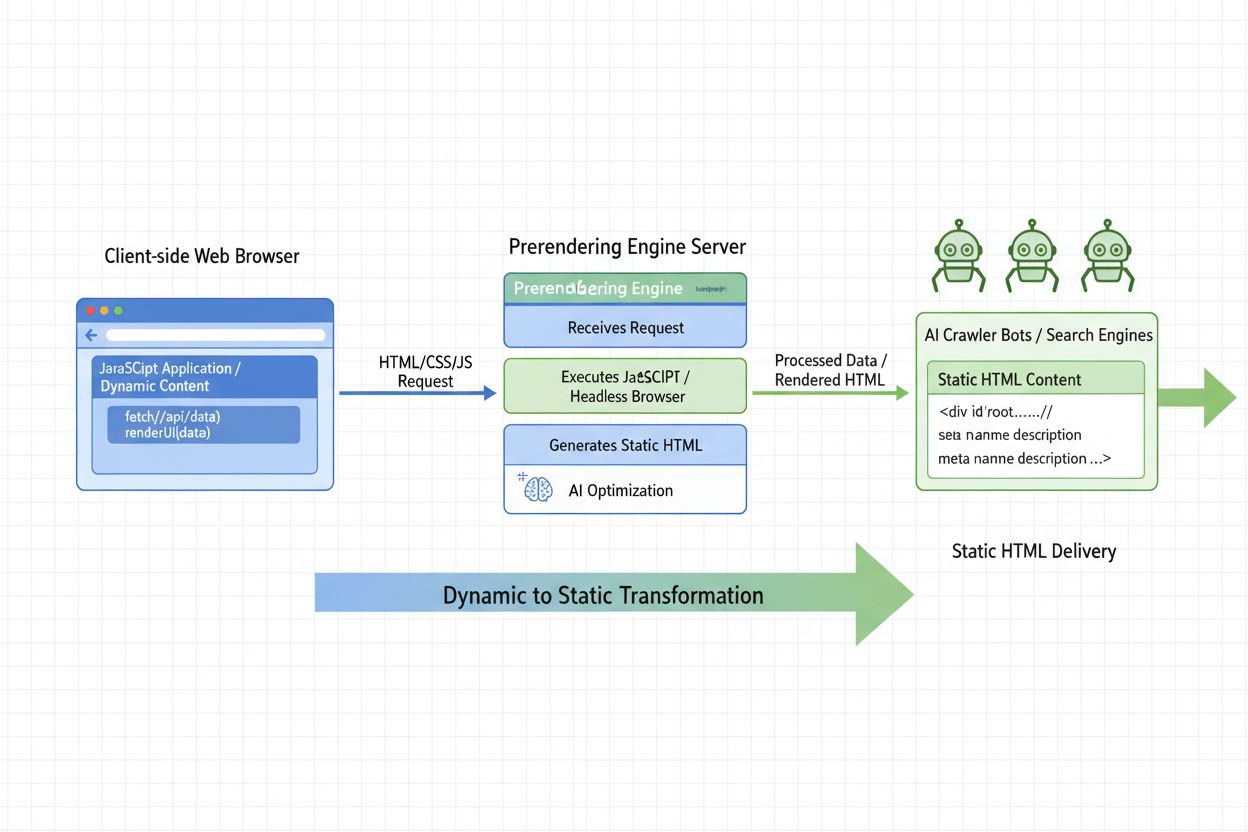
AI Prerendering
Dowiedz się, czym jest AI Prerendering i jak strategie renderowania po stronie serwera optymalizują Twoją stronę pod kątem widoczności dla crawlerów AI. Poznaj ...
5 min czytania

Dowiedz się, jak renderowanie po stronie serwera umożliwia wydajne przetwarzanie AI, wdrażanie modeli oraz inferencję w czasie rzeczywistym dla aplikacji opartych na sztucznej inteligencji i obciążeniach LLM.
Renderowanie po stronie serwera dla AI to podejście architektoniczne, w którym modele sztucznej inteligencji oraz procesy inferencji są wykonywane na serwerze, a nie na urządzeniach klienckich. Umożliwia to efektywne przetwarzanie wymagających obliczeniowo zadań AI, zapewnia spójną wydajność dla wszystkich użytkowników oraz upraszcza wdrażanie i aktualizacje modeli.
Renderowanie po stronie serwera dla AI odnosi się do wzorca architektonicznego, w którym modele sztucznej inteligencji, procesy inferencji oraz zadania obliczeniowe wykonywane są na serwerach backendowych, a nie na urządzeniach klienckich, takich jak przeglądarki czy telefony komórkowe. Takie podejście zasadniczo różni się od tradycyjnego renderowania po stronie klienta, gdzie JavaScript działa w przeglądarce użytkownika, generując treść. W aplikacjach AI renderowanie po stronie serwera oznacza, że duże modele językowe (LLM), inferencja uczenia maszynowego i generowanie treści przez AI odbywają się centralnie na wydajnej infrastrukturze serwerowej, zanim wyniki zostaną przesłane do użytkowników. Ta zmiana architektoniczna zyskuje na znaczeniu wraz ze wzrostem wymagań obliczeniowych AI oraz jej kluczową rolą w nowoczesnych aplikacjach webowych.
Koncepcja ta pojawiła się z potrzeby dopasowania wymagań nowoczesnych aplikacji AI do realnych możliwości urządzeń klienckich. Tradycyjne frameworki webowe, takie jak React, Angular czy Vue.js, spopularyzowały renderowanie po stronie klienta w latach 2010., jednak podejście to stwarza poważne wyzwania w przypadku obciążeń wymagających intensywnej pracy AI. Renderowanie po stronie serwera dla AI rozwiązuje te problemy, wykorzystując wyspecjalizowany sprzęt, scentralizowane zarządzanie modelami oraz zoptymalizowaną infrastrukturę, do której urządzenia klienckie nie mają dostępu. To fundamentalna zmiana paradygmatu w projektowaniu aplikacji opartych na AI.
Wymagania obliczeniowe współczesnych systemów AI sprawiają, że renderowanie po stronie serwera jest nie tylko korzystne, ale często wręcz niezbędne. Urządzenia klienckie, zwłaszcza smartfony i tańsze laptopy, nie dysponują mocą obliczeniową pozwalającą na wydajną inferencję AI w czasie rzeczywistym. Gdy modele AI uruchamiane są na urządzeniach użytkowników, pojawiają się zauważalne opóźnienia, zwiększone zużycie baterii oraz nierówna wydajność w zależności od specyfikacji sprzętu. Renderowanie po stronie serwera eliminuje te problemy, centralizując przetwarzanie AI na infrastrukturze wyposażonej w GPU, TPU i wyspecjalizowane akceleratory AI, które zapewniają wydajność nieosiągalną dla urządzeń konsumenckich.
Poza samą wydajnością, renderowanie po stronie serwera dla AI daje kluczowe korzyści w zakresie zarządzania modelami, bezpieczeństwa i spójności działania. Gdy modele AI działają na serwerach, deweloperzy mogą natychmiastowo aktualizować, dostrajać i wdrażać nowe wersje bez konieczności pobierania aktualizacji przez użytkowników czy zarządzania wieloma wersjami modeli lokalnie. Jest to szczególnie istotne w przypadku dużych modeli językowych i systemów uczenia maszynowego, które szybko ewoluują i wymagają częstych poprawek oraz aktualizacji bezpieczeństwa. Ponadto trzymanie modeli AI na serwerach chroni przed nieautoryzowanym dostępem, wyciekiem modeli i kradzieżą własności intelektualnej, do czego łatwiej dochodzi, gdy modele są dystrybuowane na urządzenia klienckie.
| Aspekt | AI po stronie klienta | AI po stronie serwera |
|---|---|---|
| Miejsce przetwarzania | Przeglądarka lub urządzenie użytkownika | Serwery backendowe |
| Wymagania sprzętowe | Ograniczone do możliwości urządzenia | Wyspecjalizowane GPU, TPU, akceleratory AI |
| Wydajność | Zmienna, zależna od sprzętu | Spójna, zoptymalizowana |
| Aktualizacje modeli | Wymagają pobrania przez użytkownika | Natychmiastowe wdrożenie |
| Bezpieczeństwo | Modele narażone na wyciek | Modele chronione na serwerach |
| Opóźnienia | Zależne od mocy urządzenia | Zoptymalizowana infrastruktura |
| Skalowalność | Ograniczona do pojedynczego urządzenia | Wysoka, dla wielu użytkowników |
| Złożoność rozwoju | Wysoka (fragmentacja urządzeń) | Niższa (centralne zarządzanie) |
Przeciążenie sieci i opóźnienia to istotne wyzwania w aplikacjach AI. Nowoczesne systemy AI wymagają stałej komunikacji z serwerami w celu aktualizacji modeli, pobierania danych treningowych oraz hybrydowego przetwarzania. Paradoksalnie, renderowanie po stronie klienta zwiększa liczbę żądań sieciowych w porównaniu do tradycyjnych aplikacji, ograniczając zyski wydajności, które miało zapewnić przetwarzanie lokalne. Renderowanie po stronie serwera konsoliduje te komunikaty, ogranicza opóźnienia i pozwala na funkcjonowanie funkcji AI w czasie rzeczywistym, takich jak tłumaczenie na żywo, generowanie treści czy przetwarzanie obrazu, bez kar za opóźnienia charakterystycznych dla inferencji po stronie klienta.
Złożoność synchronizacji pojawia się, gdy aplikacje AI muszą utrzymywać spójny stan pomiędzy wieloma usługami AI jednocześnie. Współczesne aplikacje często korzystają z serwisów embeddingów, modeli generatywnych, modeli dostrojonych oraz wyspecjalizowanych silników inferencyjnych, które muszą się ze sobą komunikować. Zarządzanie takim rozproszonym stanem na urządzeniach klienckich wprowadza duże komplikacje i ryzyko niespójności danych, zwłaszcza przy współpracy w czasie rzeczywistym. Renderowanie po stronie serwera centralizuje zarządzanie stanem, zapewniając spójność wyników dla wszystkich użytkowników i eliminując konieczność skomplikowanej synchronizacji po stronie klienta.
Fragmentacja urządzeń to ogromne wyzwanie dla rozwoju AI po stronie klienta. Różne urządzenia dysponują rozmaitymi możliwościami AI, takimi jak jednostki przetwarzania neuronowego, akceleracja GPU, wsparcie WebGL czy ograniczenia pamięci. Zapewnienie spójnych doświadczeń AI w tak zróżnicowanym środowisku wymaga dużego nakładu pracy inżynierskiej, strategii łagodnej degradacji oraz wielu ścieżek kodu dla różnych możliwości urządzeń. Renderowanie po stronie serwera całkowicie eliminuje ten problem, zapewniając wszystkim użytkownikom dostęp do tej samej, zoptymalizowanej infrastruktury AI, niezależnie od specyfikacji urządzenia.
Renderowanie po stronie serwera umożliwia uprościone i łatwiejsze w utrzymaniu architektury aplikacji AI przez centralizację kluczowych funkcjonalności. Zamiast rozpraszać modele AI i logikę inferencji na tysiącach urządzeń klienckich, deweloperzy utrzymują jedną, zoptymalizowaną implementację na serwerze. Centralizacja ta daje natychmiastowe korzyści, takie jak szybsze cykle wdrożeniowe, łatwiejsze debugowanie i prostsza optymalizacja wydajności. Gdy model AI wymaga poprawy lub znaleziono błąd, deweloperzy naprawiają go raz na serwerze, zamiast próbować wypchnąć aktualizacje do milionów urządzeń o różnym tempie adopcji.
Wydajność zasobów znacząco się poprawia dzięki renderowaniu po stronie serwera. Infrastruktura serwerowa pozwala na efektywne współdzielenie zasobów przez wszystkich użytkowników, dzięki pulowaniu połączeń, strategiom cache’owania i równoważeniu obciążenia, które optymalizują wykorzystanie sprzętu. Jeden GPU na serwerze może obsłużyć żądania inferencyjne tysięcy użytkowników sekwencyjnie, podczas gdy zapewnienie tej samej wydajności na urządzeniach klienckich wymagałoby milionów GPU. Ta efektywność przekłada się na niższe koszty operacyjne, mniejsze obciążenie środowiska i lepszą skalowalność w miarę rozwoju aplikacji.
Bezpieczeństwo i ochrona własności intelektualnej są znacznie łatwiejsze do zapewnienia przy renderowaniu po stronie serwera. Modele AI to często efekt dużych inwestycji w badania, dane treningowe i zasoby obliczeniowe. Przechowywanie modeli na serwerze chroni przed atakami na wyciek modeli, nieautoryzowanym dostępem i kradzieżą własności intelektualnej, do których może dojść, gdy modele są dystrybuowane na urządzenia klienckie. Dodatkowo, przetwarzanie po stronie serwera umożliwia precyzyjną kontrolę dostępu, logowanie zdarzeń i monitorowanie zgodności, czego nie da się wyegzekwować na rozproszonych urządzeniach użytkowników.
Nowoczesne frameworki ewoluowały, aby skutecznie wspierać renderowanie po stronie serwera przy obciążeniach AI. Next.js przoduje w tej ewolucji, oferując Server Actions umożliwiające płynne przetwarzanie AI bezpośrednio z komponentów serwerowych. Deweloperzy mogą wywoływać API AI, przetwarzać duże modele językowe i przesyłać odpowiedzi z powrotem do klienta przy minimalnej ilości kodu. Framework zarządza złożonością komunikacji serwer-klient, pozwalając skupić się na logice AI zamiast na infrastrukturze.
SvelteKit oferuje podejście zorientowane na wydajność do renderowania AI po stronie serwera dzięki funkcjom load, wykonywanym na serwerze przed renderowaniem. Umożliwia to wstępne przetwarzanie danych AI, generowanie rekomendacji oraz przygotowanie treści wzbogaconych przez AI przed przesłaniem HTML do klienta. Dzięki temu aplikacje mają minimalny ślad JavaScript, zachowując pełne możliwości AI i zapewniając wyjątkowo szybkie doświadczenia użytkownika.
Specjalistyczne narzędzia, takie jak Vercel AI SDK, upraszczają zarządzanie strumieniowaniem odpowiedzi AI, liczeniem tokenów i obsługą różnych API dostawców AI. Umożliwiają one budowę zaawansowanych aplikacji AI bez konieczności głębokiej wiedzy infrastrukturalnej. Opcje infrastrukturalne, takie jak Vercel Edge Functions, Cloudflare Workers i AWS Lambda, zapewniają globalnie rozproszone przetwarzanie AI po stronie serwera, minimalizując opóźnienia dzięki obsłudze żądań bliżej użytkownika przy jednoczesnym utrzymaniu centralnego zarządzania modelami.
Efektywne renderowanie AI po stronie serwera wymaga zaawansowanych strategii cache’owania, aby kontrolować koszty obliczeniowe i opóźnienia. Cache Redis przechowuje najczęściej żądane odpowiedzi AI oraz sesje użytkowników, eliminując zbędne przetwarzanie przy podobnych zapytaniach. Cache CDN globalnie dystrybuuje statyczne treści generowane przez AI, zapewniając użytkownikom szybki dostęp do odpowiedzi z najbliższych geograficznie serwerów. Strategie cache’owania na krawędzi rozpraszają treści przetworzone przez AI w sieciach edge, zapewniając odpowiedzi o ultraniskich opóźnieniach przy zachowaniu centralnego zarządzania modelem.
Te podejścia cache’ujące współdziałają, by tworzyć wydajne systemy AI skalujące się do milionów użytkowników bez proporcjonalnego wzrostu kosztów obliczeniowych. Poprzez cache’owanie odpowiedzi AI na wielu poziomach, aplikacje mogą obsługiwać większość zapytań z cache’u, a nowe odpowiedzi generować tylko dla naprawdę unikalnych zapytań. To znacząco obniża koszty infrastruktury i poprawia doświadczenie użytkownika dzięki krótszym czasom odpowiedzi.
Ewolucja w kierunku renderowania po stronie serwera oznacza dojrzewanie praktyk web developmentu w odpowiedzi na wymagania AI. Wraz ze wzrostem roli AI w aplikacjach webowych realia obliczeniowe wymuszają architektury skoncentrowane na serwerze. Przyszłość to zaawansowane podejścia hybrydowe, które automatycznie decydują, gdzie renderować treści w zależności od ich rodzaju, możliwości urządzenia, warunków sieciowych i wymagań przetwarzania AI. Frameworki będą stopniowo wzbogacać aplikacje o funkcje AI, zapewniając uniwersalne działanie rdzenia systemu przy jednoczesnej optymalizacji doświadczenia tam, gdzie to możliwe.
Ta zmiana paradygmatu czerpie z doświadczeń ery Single Page Application, jednocześnie odpowiadając na wyzwania aplikacji AI-native. Narzędzia i frameworki są już gotowe, by deweloperzy mogli wykorzystać korzyści renderowania po stronie serwera w erze AI, umożliwiając powstanie nowej generacji inteligentnych, responsywnych i wydajnych aplikacji webowych.
Śledź, jak Twoja domena i marka pojawiają się w odpowiedziach generowanych przez AI w ChatGPT, Perplexity i innych wyszukiwarkach AI. Zyskaj wgląd w czasie rzeczywistym w widoczność swojej marki w AI.
Dowiedz się, czym jest AI Prerendering i jak strategie renderowania po stronie serwera optymalizują Twoją stronę pod kątem widoczności dla crawlerów AI. Poznaj ...
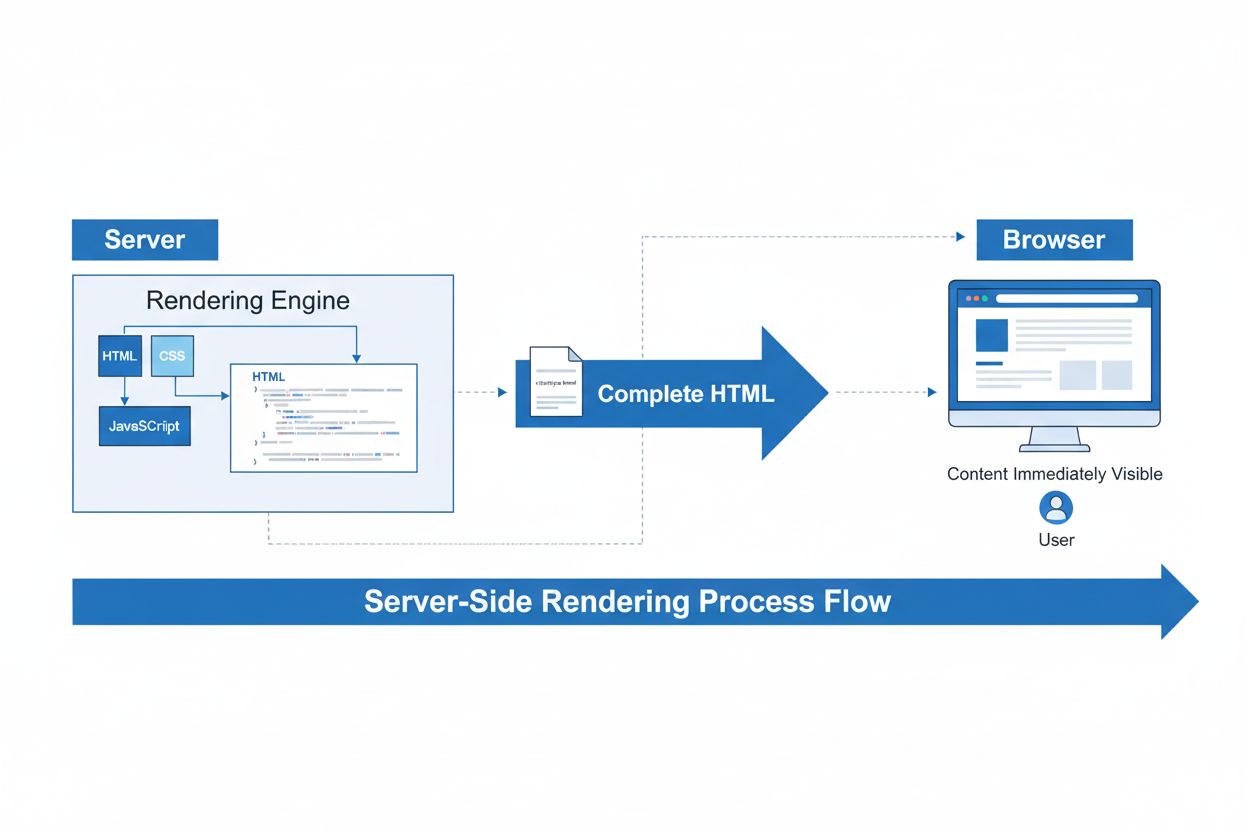
Renderowanie po stronie serwera (SSR) to technika internetowa, w której serwery renderują kompletne strony HTML przed wysłaniem ich do przeglądarki. Dowiedz się...

Dowiedz się, jak renderowanie JavaScript wpływa na widoczność Twojej strony w wyszukiwarkach AI, takich jak ChatGPT, Perplexity i Claude. Odkryj, dlaczego robot...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.