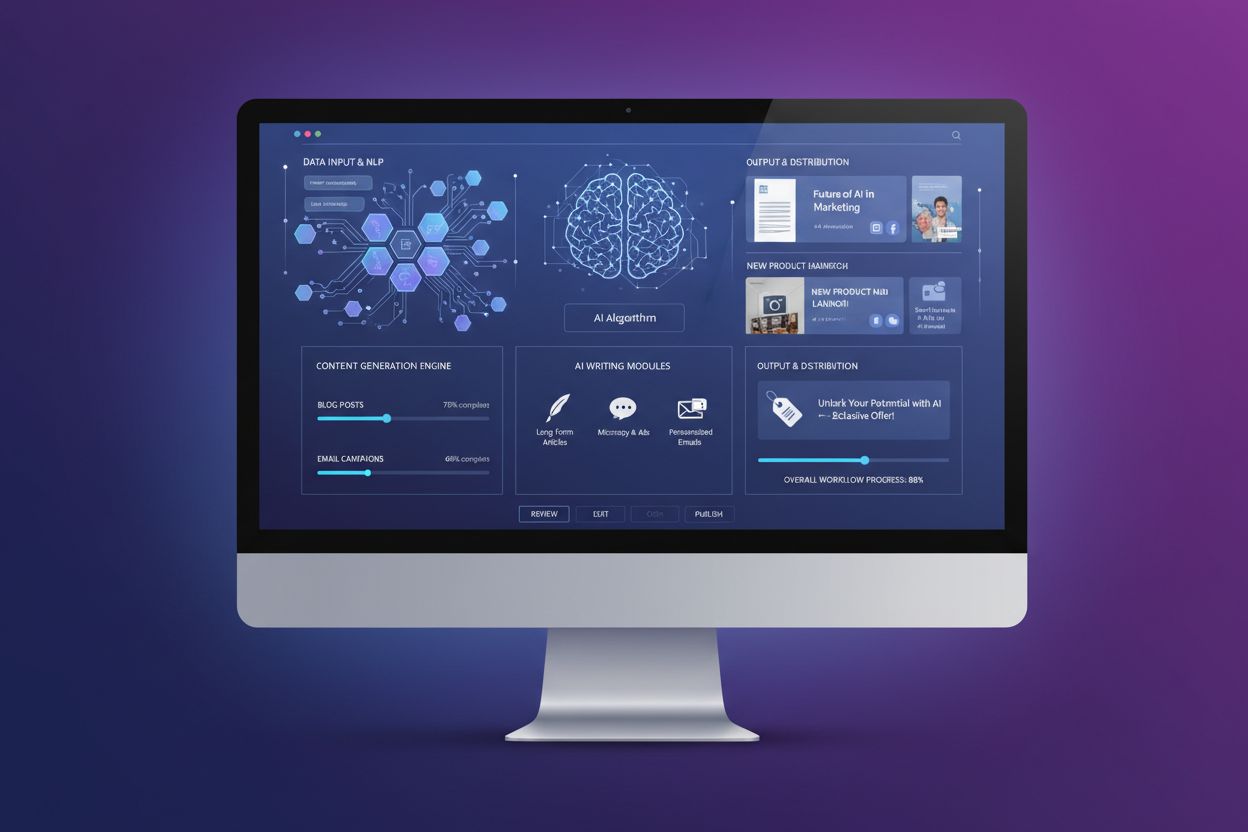
AI Content Generation
Dowiedz się, czym jest generowanie treści AI, jak działa, jakie są jego zalety i wyzwania oraz najlepsze praktyki wykorzystania narzędzi AI do tworzenia treści ...
12 min czytania
Obraz wygenerowany przez AI to cyfrowy obraz stworzony przez algorytmy sztucznej inteligencji oraz modele uczenia maszynowego, a nie przez ludzkich artystów czy fotografów. Obrazy te powstają w wyniku trenowania sieci neuronowych na ogromnych zbiorach danych oznaczonych obrazów, co pozwala AI uczyć się wzorców wizualnych i generować oryginalne, realistyczne wizualizacje na podstawie poleceń tekstowych, szkiców lub innych danych wejściowych.
Obraz wygenerowany przez AI to cyfrowy obraz stworzony przez algorytmy sztucznej inteligencji oraz modele uczenia maszynowego, a nie przez ludzkich artystów czy fotografów. Obrazy te powstają w wyniku trenowania sieci neuronowych na ogromnych zbiorach danych oznaczonych obrazów, co pozwala AI uczyć się wzorców wizualnych i generować oryginalne, realistyczne wizualizacje na podstawie poleceń tekstowych, szkiców lub innych danych wejściowych.
Obraz wygenerowany przez AI to cyfrowy obraz stworzony przez algorytmy sztucznej inteligencji oraz modele uczenia maszynowego, a nie przez ludzkich artystów czy fotografów. Obrazy te powstają przy użyciu zaawansowanych sieci neuronowych trenowanych na ogromnych zbiorach oznaczonych obrazów, co pozwala AI uczyć się wzorców wizualnych, stylów oraz relacji między pojęciami. Technologia ta umożliwia systemom AI generowanie oryginalnych, realistycznych wizualizacji na podstawie różnych danych wejściowych — najczęściej poleceń tekstowych, ale także szkiców, obrazów referencyjnych czy innych źródeł informacji. W przeciwieństwie do tradycyjnej fotografii lub ręcznie tworzonej sztuki, obrazy generowane przez AI mogą przedstawiać wszystko, co wyobrażalne, w tym niemożliwe scenariusze, fantastyczne światy czy abstrakcyjne koncepcje, które nigdy nie istniały w rzeczywistości. Proces ten jest niezwykle szybki, często pozwalając uzyskać wysokiej jakości obrazy w ciągu kilku sekund, co czyni AI przełomową technologią dla branż kreatywnych, marketingu, projektowania produktów i tworzenia treści.
Początki generowania obrazów przez AI sięgają fundamentalnych badań nad uczeniem głębokim i sieciami neuronowymi, jednak technologia ta stała się powszechna dopiero na początku lat 20. XXI wieku. Generatywne Sieci Przeciwstawne (GAN), wprowadzone przez Iana Goodfellowa w 2014 roku, były jednym z pierwszych udanych podejść, wykorzystującym dwie konkurujące ze sobą sieci neuronowe do generowania realistycznych obrazów. Prawdziwy przełom nastąpił jednak wraz z pojawieniem się modeli dyfuzyjnych i architektur opartych na transformatorach, które okazały się bardziej stabilne i zdolne do generowania wyższej jakości efektów. W 2022 roku Stable Diffusion zostało udostępnione jako model open-source, demokratyzując dostęp do generowania obrazów przez AI i wywołując masową adopcję. Niedługo potem DALL-E 2 od OpenAI oraz Midjourney zyskały ogromną popularność, wprowadzając generowanie obrazów przez AI do powszechnej świadomości. Według najnowszych statystyk 71% obrazów w mediach społecznościowych jest obecnie generowanych przez AI, a globalny rynek generatorów obrazów AI został wyceniony na 299,2 miliona dolarów w 2023 roku, z prognozowanym wzrostem 17,4% rocznie do 2030 roku. Ten gwałtowny wzrost odzwierciedla zarówno dojrzewanie technologii, jak i szeroką adopcję biznesową w różnych branżach.
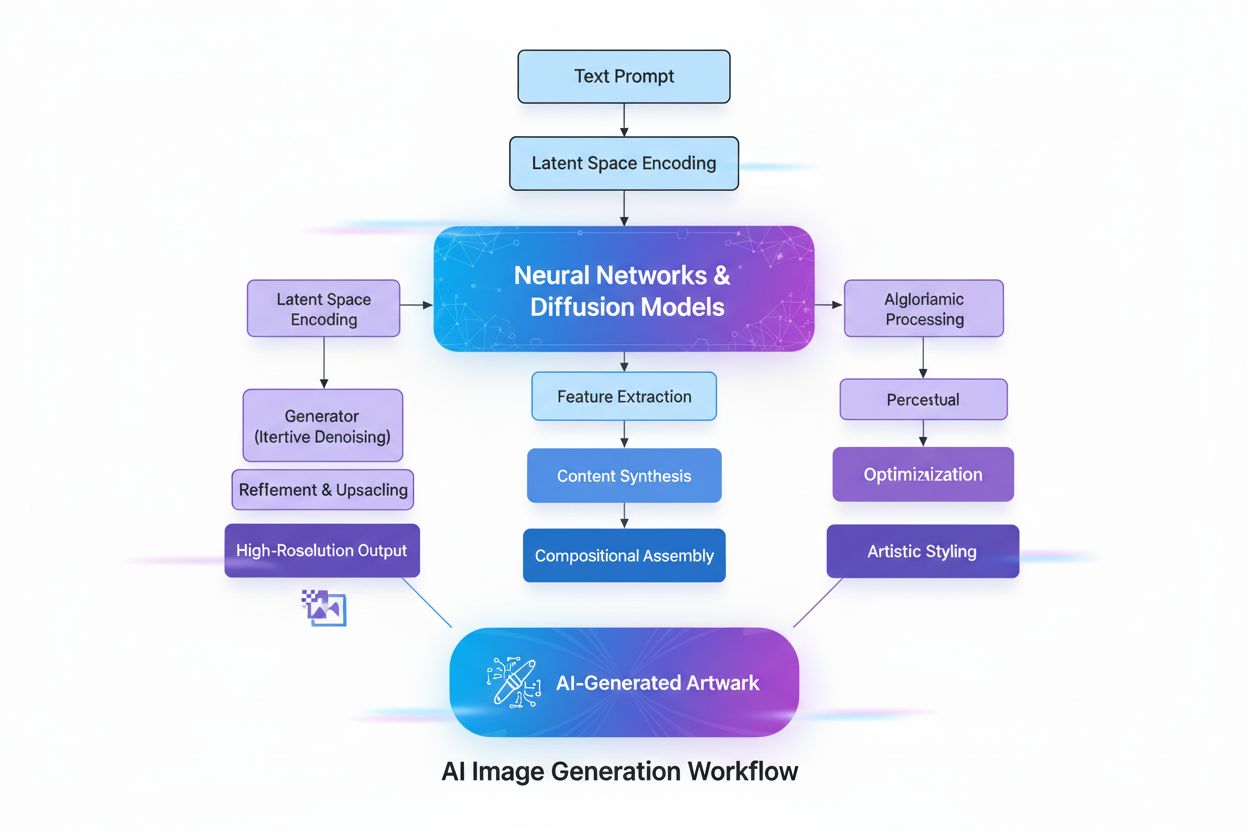
Tworzenie obrazów generowanych przez AI obejmuje szereg zaawansowanych procesów technicznych, które współpracują ze sobą, by przekształcić abstrakcyjne koncepcje w wizualną rzeczywistość. Proces rozpoczyna się od rozumienia tekstu z wykorzystaniem przetwarzania języka naturalnego (NLP), gdzie AI przekształca język ludzki w reprezentacje numeryczne zwane osadzeniami. Modele takie jak CLIP (Contrastive Language-Image Pre-training) kodują polecenia tekstowe w wielowymiarowe wektory, które oddają znaczenie semantyczne i kontekst. Przykładowo, gdy użytkownik wpisze “czerwone jabłko na drzewie”, model NLP rozbija to na współrzędne numeryczne reprezentujące “czerwony”, “jabłko”, “drzewo” i ich relacje przestrzenne. Ta mapa liczbowa kieruje następnie procesem generowania obrazu, pełniąc rolę instrukcji, które elementy powinny się pojawić i jak mają ze sobą współpracować.
Modele dyfuzyjne, które napędzają większość współczesnych generatorów obrazów AI, w tym DALL-E 2 i Stable Diffusion, działają w oparciu o elegancki, iteracyjny proces. Model zaczyna od czystego szumu — czyli chaotycznego układu pikseli — i stopniowo udoskonala go poprzez wielokrotne etapy odszumiania. Podczas treningu model uczy się odwrotnego procesu dodawania szumu do obrazów, czyli “odszumiania” zniekształconych wersji do ich pierwotnej formy. Generując nowe obrazy, model stosuje wyuczone odszumianie w odwrotnej kolejności: zaczyna od szumu i stopniowo przekształca go w spójny obraz. Polecenie tekstowe prowadzi tę transformację na każdym etapie, zapewniając zgodność wyniku z opisem użytkownika. To stopniowe udoskonalanie pozwala na wyjątkową kontrolę i daje niezwykle szczegółowe, wysokiej jakości obrazy.
Generatywne Sieci Przeciwstawne (GAN) stosują zupełnie inne podejście, wywodzące się z teorii gier. GAN składa się z dwóch konkurujących sieci neuronowych: generatora, który tworzy fałszywe obrazy na podstawie losowych danych wejściowych, oraz dyskryminatora, który próbuje odróżnić obrazy prawdziwe od sztucznych. Sieci te rywalizują ze sobą: generator nieustannie doskonali się, by oszukać dyskryminator, a dyskryminator coraz lepiej wykrywa fałszywki. Ta konkurencyjna dynamika prowadzi do coraz lepszych wyników, skutkując obrazami niemal nieodróżnialnymi od prawdziwych fotografii. GAN-y są szczególnie skuteczne w generowaniu fotorealistycznych ludzkich twarzy i transferze stylu, choć mogą być mniej stabilne podczas treningu niż modele dyfuzyjne.
Modele oparte na transformatorach stanowią kolejną ważną architekturę, adaptując technologię transformatorów pierwotnie stworzoną dla NLP. Modele te świetnie radzą sobie z rozumieniem złożonych relacji w poleceniach tekstowych i odwzorowywaniem tokenów językowych na cechy wizualne. Wykorzystują mechanizmy samo-uwagi, by uchwycić kontekst i istotność, umożliwiając obsługę wieloelementowych, szczegółowych poleceń z niezwykłą precyzją. Transformatory potrafią generować obrazy ściśle odpowiadające rozbudowanym opisom tekstowym, co czyni je idealnymi do zastosowań wymagających pełnej kontroli nad cechami wyjściowymi.
| Technologia | Jak działa | Mocne strony | Słabości | Najlepsze zastosowania | Przykładowe narzędzia |
|---|---|---|---|---|---|
| Modele dyfuzyjne | Iteracyjnie odszumiają losowy szum, tworząc ustrukturyzowane obrazy kierowane poleceniami tekstowymi | Wysoka jakość i szczegółowość, doskonałe dopasowanie do tekstu, stabilny trening, precyzyjna kontrola | Wolniejszy proces generowania, większe wymagania sprzętowe | Generowanie obrazów z tekstu, wysokorozdzielcza grafika, wizualizacje naukowe | Stable Diffusion, DALL-E 2, Midjourney |
| GAN-y | Dwie konkurujące sieci neuronowe (generator i dyskryminator) tworzą realistyczne obrazy w procesie uczenia przeciwstawnego | Szybka generacja, fotorealizm, dobre do transferu stylu i poprawy jakości obrazów | Niestabilność treningu, problem zaniku różnorodności (mode collapse), mniejsza precyzja kontroli tekstowej | Fotorealistyczne twarze, transfer stylu, powiększanie obrazów | StyleGAN, Progressive GAN, ArtSmart.ai |
| Transformatory | Przekształcają polecenia tekstowe w obrazy przy użyciu samo-uwagi i osadzeń tokenów | Wyjątkowy przekład tekstu na obraz, obsługa złożonych poleceń, głębokie rozumienie semantyki | Duże wymagania sprzętowe, nowsza technologia, mniej zoptymalizowana | Kreatywne generowanie obrazów z rozbudowanego tekstu, projektowanie i reklama, koncepcyjna sztuka | DALL-E 2, Runway ML, Imagen |
| Transfer stylu neuronowego | Łączy zawartość jednego obrazu z artystycznym stylem innego | Kontrola artystyczna, zachowanie treści przy zastosowaniu stylu, przejrzysty proces | Ograniczone do transferu stylu, wymagają obrazów referencyjnych, mniej elastyczne niż inne metody | Tworzenie obrazów artystycznych, nakładanie stylów, kreatywne wzbogacenie | DeepDream, Prisma, Artbreeder |
Adopcja obrazów generowanych przez AI w sektorach biznesowych następuje niezwykle szybko i ma charakter przełomowy. W e-commerce i handlu detalicznym firmy wykorzystują AI do masowej produkcji zdjęć produktowych, eliminując konieczność kosztownych sesji fotograficznych. Według najnowszych danych 80% menedżerów detalicznych spodziewa się wdrożenia automatyzacji AI w swoich firmach do 2025 roku, a firmy z branży retail wydały 19,71 miliarda dolarów na narzędzia AI w 2023 roku, z czego znaczącą część stanowi generowanie obrazów. Rynek edycji obrazów AI wyceniany jest na 88,7 miliarda dolarów w 2025 roku i ma osiągnąć 8,9 miliarda dolarów do 2034 roku, a użytkownicy biznesowi odpowiadają za około 42% wszystkich wydatków.
W marketingu i reklamie 62% marketerów używa AI do tworzenia nowych zasobów graficznych, a firmy korzystające z AI do generowania treści na media społecznościowe notują 15-25% wzrost zaangażowania. Możliwość szybkiego generowania wielu wariantów kreatywnych pozwala na testowanie A/B na niespotykaną dotąd skalę, umożliwiając marketerom optymalizację kampanii z precyzją opartą na danych. Magazyn Cosmopolitan przeszedł do historii w czerwcu 2022 roku, publikując okładkę w całości wygenerowaną przez DALL-E 2, co było pierwszym takim przypadkiem w dużym wydawnictwie. Użyte polecenie brzmiało: “Szerokokątny kadr z dołu przedstawiający astronautkę o wysportowanej sylwetce kroczącą z pewnością siebie po Marsie w nieskończonym wszechświecie, synthwave, cyfrowa sztuka.”
W obrazowaniu medycznym obrazy generowane przez AI są wykorzystywane do celów diagnostycznych i tworzenia syntetycznych danych. Badania wykazały, że DALL-E 2 potrafi generować realistyczne zdjęcia rentgenowskie na podstawie poleceń tekstowych, a nawet rekonstruować brakujące elementy w obrazach radiologicznych. Ta zdolność ma ogromne znaczenie dla szkolenia medycznego, udostępniania danych z zachowaniem prywatności oraz przyspieszenia rozwoju nowych narzędzi diagnostycznych. Rynek AI w mediach społecznościowych ma wzrosnąć do 12 miliardów dolarów do 2031 roku, z 2,1 miliarda w 2021 roku, co podkreśla centralną rolę tej technologii w tworzeniu treści cyfrowych.
Szybka proliferacja obrazów generowanych przez AI rodzi poważne dylematy etyczne i prawne, z którymi branża i regulatorzy wciąż się mierzą. Prawa autorskie i własność intelektualna to być może najtrudniejszy problem. Większość generatorów obrazów AI jest trenowana na ogromnych zbiorach obrazów pobieranych z internetu, z których wiele stanowi chronione prawem autorskim dzieła artystów i fotografów. W styczniu 2023 roku trzech artystów złożyło przełomowy pozew przeciwko firmom Stability AI, Midjourney i DeviantArt, twierdząc, że firmy te wykorzystywały chronione obrazy do trenowania swoich algorytmów AI bez zgody i wynagrodzenia. Sprawa ta jest przykładem szerszego konfliktu pomiędzy innowacją technologiczną a prawami twórców.
Kwestia własności i praw do obrazów generowanych przez AI pozostaje niejasna prawnie. Gdy obraz wygenerowany przez AI zdobył pierwszą nagrodę na konkursie sztuk pięknych Colorado State Fair w 2022 roku (zgłoszony przez Jasona Allena przy użyciu Midjourney), wywołało to ogromne kontrowersje. Wielu argumentowało, że skoro dzieło stworzyła AI, nie powinno być uznane za oryginalną ludzką twórczość. Amerykański Urząd ds. Praw Autorskich sugeruje, że dzieła stworzone całkowicie przez AI bez ludzkiego wkładu twórczego mogą nie kwalifikować się do ochrony prawnej, choć obszar ten ciągle się rozwija wraz z trwającymi procesami i zmianami regulacyjnymi.
Deepfaki i dezinformacja to kolejne istotne zagrożenie. Generatory obrazów AI potrafią tworzyć bardzo realistyczne obrazy wydarzeń, które nigdy nie miały miejsca, co umożliwia szerzenie fałszywych informacji. W marcu 2023 roku wygenerowane przez AI deepfaki przedstawiające rzekome aresztowanie byłego prezydenta Donalda Trumpa rozprzestrzeniły się w mediach społecznościowych i początkowo były uznawane przez niektórych użytkowników za autentyczne, ukazując potencjał tej technologii do szkodliwego wykorzystania. Skomplikowanie i realizm nowoczesnych obrazów generowanych przez AI utrudniają ich wykrycie, co stanowi wyzwanie dla platform społecznościowych i mediów dbających o autentyczność treści.
Uprzedzenia w danych treningowych to kolejny poważny problem etyczny. Modele AI uczą się na zbiorach danych, które mogą zawierać uprzedzenia kulturowe, płciowe czy rasowe. Projekt Gender Shades prowadzony przez Joy Buolamwini z MIT Media Lab wykazał znaczne uprzedzenia w komercyjnych systemach klasyfikacji płci, gdzie wskaźniki błędów dla kobiet o ciemniejszej karnacji były znacznie wyższe niż dla mężczyzn o jasnej skórze. Podobne uprzedzenia mogą pojawiać się w generowaniu obrazów, utrwalając szkodliwe stereotypy lub niedostatecznie reprezentując pewne grupy. Przeciwdziałanie temu wymaga starannej selekcji danych, różnorodnych zbiorów treningowych i ciągłej oceny efektów działania modeli.
Jakość obrazów generowanych przez AI w dużej mierze zależy od jakości i precyzji polecenia wejściowego. Prompt engineering — sztuka formułowania skutecznych opisów tekstowych — stała się kluczową umiejętnością dla użytkowników dążących do najlepszych efektów. Skuteczne polecenia mają kilka cech wspólnych: są konkretne i szczegółowe zamiast ogólnych, zawierają określenia stylu lub medium (np. “cyfrowy obraz”, “akwarela”, “fotorealistyczny”), uwzględniają informacje o atmosferze i oświetleniu (np. “złota godzina”, “filmowe oświetlenie”, “dramatyczne cienie”) oraz jasno określają relacje między elementami.
Na przykład, zamiast po prostu wpisać “kot”, skuteczniejsze będzie polecenie: “puszysty rudy kot siedzący na parapecie o zachodzie słońca, ciepłe złote światło wpadające przez okno, fotorealistyczny, profesjonalna fotografia”. Taki poziom szczegółowości daje AI konkretne wskazówki dotyczące wyglądu, ustawienia, oświetlenia i oczekiwanego stylu. Badania pokazują, że ustrukturyzowane polecenia z wyraźną hierarchią informacji dają bardziej spójne i satysfakcjonujące efekty. Użytkownicy często stosują takie techniki jak określanie stylów artystycznych, dodawanie przymiotników opisowych, używanie terminologii fotograficznej czy nawet odniesienia do konkretnych artystów lub nurtów, by nakierować AI na pożądany efekt.
Różne platformy generowania obrazów przez AI mają swoje charakterystyczne cechy, mocne strony i zastosowania. DALL-E 2, opracowane przez OpenAI, generuje szczegółowe obrazy na podstawie poleceń tekstowych i oferuje zaawansowane możliwości inpaintingu i edycji. Działa w systemie kredytowym — użytkownicy kupują kredyty na pojedyncze generacje. DALL-E 2 znane jest z uniwersalności i radzenia sobie z bardzo złożonymi poleceniami, co doceniają profesjonaliści i twórcy.
Midjourney skupia się na artystycznym i stylizowanym tworzeniu obrazów, ciesząc się popularnością wśród projektantów i artystów ze względu na unikalną estetykę. Platforma działa poprzez bota na Discordzie, gdzie polecenia wpisuje się za pomocą komendy /imagine. Midjourney znany jest z tworzenia atrakcyjnych, malarskich obrazów z harmonijną kolorystyką, zbalansowanym oświetleniem i wyraźnymi detalami. Platforma oferuje abonamenty od 10 do 120 dolarów miesięcznie, a wyższe pakiety umożliwiają większą liczbę generacji w miesiącu.
Stable Diffusion, rozwijany przez Stability AI, EleutherAI i LAION, to model open-source, który demokratyzuje generowanie obrazów przez AI. Otwarty charakter umożliwia deweloperom i badaczom personalizację i wdrażanie modelu w różnych projektach badawczych i biznesowych. Stable Diffusion opiera się na architekturze latent diffusion, pozwalając na wydajną generację nawet na domowych kartach graficznych. Koszt generacji to konkurencyjne 0,0023 dolara za obraz, a nowi użytkownicy mogą skorzystać z darmowych testów.
Imagen od Google to kolejny znaczący gracz oferujący modele dyfuzyjne tekst-na-obraz o niespotykanym fotorealizmie i zaawansowanym rozumieniu języka. Wszystkie te platformy pokazują różnorodność podejść i modeli biznesowych w obszarze generowania obrazów przez AI, odpowiadając na różne potrzeby i przypadki użycia użytkowników.
Obszar generowania obrazów przez AI rozwija się niezwykle dynamicznie, a kilka kluczowych trendów kształtuje przyszłość tej technologii. Rozwój modeli i efektywności postępuje w zawrotnym tempie — nowe modele generują obrazy w wyższej rozdzielczości, z lepszym dopasowaniem do tekstu i szybciej. Rynek generatorów obrazów AI ma rosnąć w tempie 17,4% rocznie do 2030 roku, co potwierdza stałe inwestycje i innowacje. Pojawiające się trendy to m.in. generowanie wideo z tekstu (AI rozszerza możliwości obrazowania o krótkie klipy wideo), generowanie modeli 3D (tworzenie trójwymiarowych zasobów bezpośrednio przez AI) oraz generowanie w czasie rzeczywistym, co umożliwia interaktywne, kreatywne procesy pracy.
Ramy regulacyjne zaczynają się kształtować na całym świecie — rządy i organizacje branżowe tworzą standardy przejrzystości, ochrony praw autorskich i etycznego wykorzystania. NO FAKES Act i podobne przepisy przewidują obowiązek znakowania treści generowanych przez AI oraz informowania o wykorzystaniu AI w procesie twórczym. 62% globalnych marketerów uważa, że obowiązkowe etykiety dla treści AI miałyby pozytywny wpływ na wyniki w mediach społecznościowych, co świadczy o uznaniu znaczenia przejrzystości.
Integracja z innymi systemami AI przyspiesza, a generowanie obrazów staje się częścią szerszych platform i procesów. Systemy multimodalne AI łączące generowanie tekstu, obrazu, dźwięku i wideo stają się coraz bardziej zaawansowane. Technologia zmierza również w kierunku personalizacji i dostosowania, gdzie modele AI mogą być dopasowywane do konkretnych stylów artystycznych, estetyki marki czy indywidualnych preferencji. Wraz ze wzrostem obecności obrazów generowanych przez AI na platformach cyfrowych rośnie znaczenie monitoringu marki i śledzenia cytowań w odpowiedziach AI, co sprawia, że narzędzia do analizy obecności marki w treściach AI stają się niezbędne dla firm dbających o widoczność i autorytet w erze generatywnej AI.
Obrazy generowane przez AI są tworzone całkowicie przez algorytmy uczenia maszynowego na podstawie poleceń tekstowych lub innych danych wejściowych, podczas gdy tradycyjna fotografia uchwyca rzeczywiste sceny przez obiektyw aparatu. Obrazy AI mogą przedstawiać wszystko, co wyobrażalne, w tym niemożliwe scenariusze, podczas gdy fotografia ogranicza się do tego, co istnieje lub może zostać fizycznie zaaranżowane. Generowanie przez AI jest zazwyczaj szybsze i tańsze niż organizacja sesji zdjęciowych, co czyni je idealnym rozwiązaniem do szybkiego tworzenia treści i prototypowania.
Modele dyfuzyjne działają, zaczynając od czystego szumu i stopniowo udoskonalając go poprzez iteracyjne kroki odszumiania. Polecenie tekstowe jest przekształcane w numeryczne osadzenia, które kierują tym procesem odszumiania, stopniowo przekształcając szum w spójny obraz odpowiadający opisowi. To krok po kroku podejście pozwala na precyzyjną kontrolę i zapewnia wysoką jakość oraz szczegółowość efektu, doskonale dopasowanego do polecenia wejściowego.
Trzy główne technologie to Generatywne Sieci Przeciwstawne (GAN), które wykorzystują konkurujące ze sobą sieci neuronowe do tworzenia realistycznych obrazów; Modele Dyfuzyjne, które iteracyjnie odszumiają losowy szum, tworząc ustrukturyzowane obrazy; oraz Transformatory, które przekształcają polecenia tekstowe w obrazy przy użyciu mechanizmów samo-uwagi. Każda architektura ma swoje mocne strony: GAN-y zapewniają fotorealizm, modele dyfuzyjne generują wyjątkowo szczegółowe obrazy, a transformatory doskonale radzą sobie ze złożonym przekształcaniem tekstu na obraz.
Własność praw autorskich do obrazów generowanych przez AI pozostaje niejasna prawnie i różni się w zależności od jurysdykcji. W wielu przypadkach prawa autorskie mogą należeć do osoby, która stworzyła polecenie, twórcy modelu AI lub potencjalnie do nikogo, jeśli AI działa autonomicznie. Amerykański Urząd ds. Praw Autorskich wskazuje, że utwory stworzone w całości przez AI bez ludzkiego wkładu twórczego mogą nie kwalifikować się do ochrony praw autorskich, choć jest to nadal rozwijający się obszar prawny ze stale toczącymi się procesami sądowymi i zmianami regulacyjnymi.
Obrazy generowane przez AI są szeroko wykorzystywane w e-commerce do fotografii produktowej, w marketingu do tworzenia materiałów kampanijnych i treści na media społecznościowe, w branży gier do tworzenia postaci i zasobów, w obrazowaniu medycznym do wizualizacji diagnostycznych oraz w reklamie do szybkiego testowania koncepcji. Według najnowszych danych 62% marketerów używa AI do tworzenia nowych zasobów graficznych, a rynek edycji obrazów AI wart jest 88,7 miliarda dolarów w 2025 roku, co dowodzi szerokiego wdrożenia tej technologii w różnych branżach.
Obecne generatory obrazów AI mają trudności z generowaniem anatomicznie poprawnych ludzkich dłoni i twarzy, często tworząc nienaturalne cechy, takie jak dodatkowe palce czy asymetryczne elementy twarzy. W dużym stopniu zależą także od jakości danych treningowych, co może prowadzić do powstawania uprzedzeń i ograniczonej różnorodności efektów. Dodatkowo, osiągnięcie konkretnych detali wymaga starannego przygotowania poleceń (prompt engineering), a technologia czasami generuje wyniki nienaturalne lub nieoddające zamierzonego przekazu twórczego.
Większość generatorów obrazów AI jest trenowana na ogromnych zbiorach obrazów pobranych z internetu, z których wiele stanowi chronione prawem autorskim dzieła. To prowadzi do poważnych sporów prawnych – artyści pozwali firmy takie jak Stability AI i Midjourney za wykorzystanie obrazów chronionych prawem autorskim bez zgody czy wynagrodzenia. Niektóre platformy, jak Getty Images czy Shutterstock, zakazały przesyłania obrazów wygenerowanych przez AI z powodu nierozwiązanych problemów prawnych, a ramy regulacyjne są dopiero opracowywane w celu zapewnienia przejrzystości danych i sprawiedliwego wynagrodzenia.
Globalny rynek generatorów obrazów AI został wyceniony na 299,2 miliona dolarów w 2023 roku i prognozuje się jego wzrost na poziomie 17,4% rocznie do 2030 roku. Szeroko pojęty rynek edycji obrazów AI wart jest 88,7 miliarda dolarów w 2025 roku i oczekuje się, że osiągnie 8,9 miliarda dolarów do 2034 roku. Dodatkowo, 71% obrazów w mediach społecznościowych jest obecnie generowanych przez AI, a rynek AI dla mediów społecznościowych ma osiągnąć 12 miliardów dolarów do 2031 roku, co świadczy o gwałtownym wzroście i powszechnej adopcji.
Zacznij śledzić, jak chatboty AI wspominają Twoją markę w ChatGPT, Perplexity i innych platformach. Uzyskaj praktyczne spostrzeżenia, aby poprawić swoją obecność w AI.
Dowiedz się, czym jest generowanie treści AI, jak działa, jakie są jego zalety i wyzwania oraz najlepsze praktyki wykorzystania narzędzi AI do tworzenia treści ...

Dowiedz się, czym jest treść generowana przez użytkowników dla AI, jak wykorzystywana jest do trenowania modeli AI, jej zastosowania w różnych branżach oraz dla...
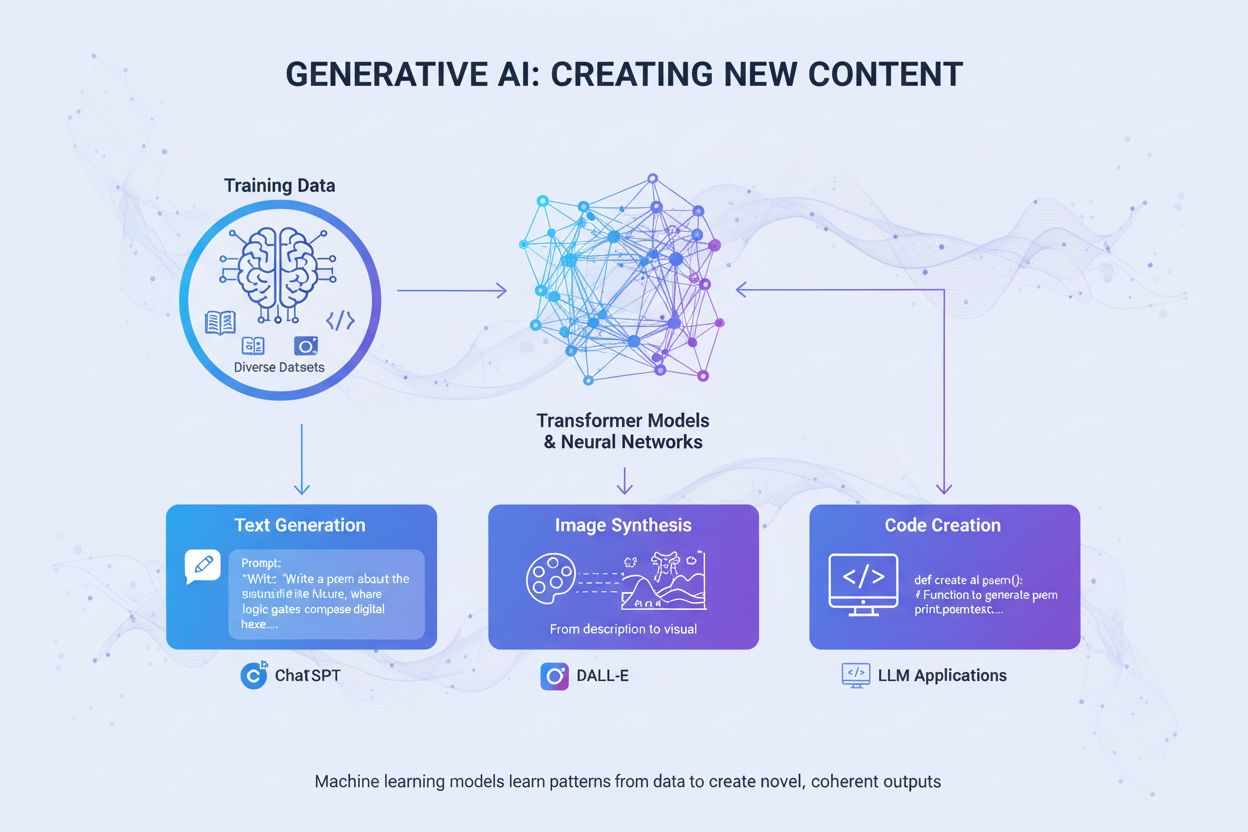
Generatywna SI tworzy nowe treści na podstawie danych treningowych z użyciem sieci neuronowych. Dowiedz się, jak działa, jakie ma zastosowania w ChatGPT i DALL-...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.