Definicja kanonicznego URL
Kanoniczny URL to główna, preferowana lub autorytatywna wersja strony internetowej, którą wyznaczasz, aby wyszukiwarki ją indeksowały, analizowały i pozycjonowały, gdy wiele adresów URL zawiera identyczną lub bardzo podobną treść. Termin „kanoniczny” pochodzi od koncepcji ustalania jednego autorytatywnego źródła spośród wielu wariantów. W kontekście optymalizacji pod kątem wyszukiwarek (SEO) i architektury stron internetowych, kanoniczny URL pełni rolę głównej kopii, która konsoliduje sygnały rankingowe, moc linków i autorytet indeksowania ze wszystkich zduplikowanych lub prawie identycznych wersji tej samej treści. To rozróżnienie jest kluczowe, ponieważ wyszukiwarki takie jak Google, Bing oraz coraz częściej systemy AI, takie jak ChatGPT, Perplexity i Claude, traktują każdy unikalny adres URL jako osobną stronę, nawet jeśli treść jest identyczna. Poprzez jawne wskazanie kanonicznego adresu URL za pomocą znacznika rel="canonical" w HTML lub innych metod kanonizacji, webmasterzy komunikują swoje preferencje wyszukiwarkom, zapewniając, że właściwa wersja otrzyma priorytet indeksowania i korzyści rankingowe.
Kontekst i tło
Koncepcja kanonicznych adresów URL pojawiła się wraz z rozwojem technologii internetowych i coraz większą złożonością stron WWW. W początkach internetu większość stron miała proste struktury adresów URL i niewiele duplikatów. Jednak wraz z rozwojem systemów zarządzania treścią (CMS), platform e-commerce i dynamicznych aplikacji internetowych, problem niezamierzonej duplikacji treści stał się powszechny. Według badań największych platform SEO ponad 30% stron internetowych zawiera istotne problemy z duplikacją treści, często bez wiedzy właściciela. Do tej duplikacji dochodzi na różne sposoby: parametry URL używane do śledzenia i filtrowania, wiele wersji protokołu (HTTP vs HTTPS), warianty domen (www vs bez www), mobilne adresy URL, identyfikatory sesji i parametry paginacji. John Mueller z Google podkreśla, że tagi kanoniczne są kluczowe do komunikowania struktury strony wyszukiwarkom, szczególnie gdy witryna generuje wiele adresów URL dla tej samej treści. Specyfikacja rel="canonical" została oficjalnie wprowadzona przez Google, Yahoo i Microsoft w 2009 roku jako standardowa metoda dla webmasterów do wskazania preferowanych adresów URL. Od tego czasu kanoniczne adresy URL stały się podstawowym elementem technicznego SEO, a ponad 78% dużych serwisów wdraża tagi kanoniczne w ramach swojej strategii SEO. Znaczenie kanonicznych adresów URL wzrosło wraz z rozwojem wyszukiwarek AI i systemów generatywnej AI, które polegają na prawidłowej kanonizacji, by właściwie przypisywać treści i unikać indeksowania duplikatów.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Jak działają kanoniczne adresy URL: proces techniczny
Proces kanonizacji działa według systematycznego schematu, który wyszukiwarki stosują, gdy napotkają wiele adresów URL o identycznej lub podobnej treści. Gdy robot wyszukiwarki odwiedza twoją stronę, identyfikuje podstrony zawierające tę samą lub prawie identyczną treść pod różnymi adresami. Następnie wyszukuje sygnałów kanonizacji, które pozwolą ustalić, która wersja powinna być uznana za główną. Do tych sygnałów należą znacznik HTML rel="canonical" umieszczony w sekcji <head> strony, nagłówki HTTP z informacją kanoniczną, przekierowania 301, schematy linkowania wewnętrznego, wpisy w mapie witryny XML oraz sygnały preferencji HTTPS. Najbardziej jednoznacznym i silnym sygnałem jest element link rel="canonical", który pojawia się w źródle HTML jako: <link rel="canonical" href="https://www.example.com/preferred-url" />. Gdy wyszukiwarki napotykają ten tag, rozumieją, że adres URL podany w atrybucie href jest wersją kanoniczną. Robot konsoliduje wtedy wszystkie sygnały rankingowe – w tym linki zewnętrzne, linkowanie wewnętrzne, metryki zaangażowania użytkowników i autorytet treści – do kanonicznego adresu URL. Ten proces konsolidacji jest kluczowy, bo zapobiega rozproszeniu mocy rankingowej na wiele duplikatów. Na przykład, jeśli twoja strona produktowa jest dostępna przez pięć różnych adresów URL z powodu parametrów śledzących i wariantów domenowych, a każdy z nich otrzymuje niezależne linki, te linki normalnie konkurowałyby ze sobą. Dzięki prawidłowej kanonizacji cała moc linków przepływa do jednego, kanonicznego adresu URL, znacznie wzmacniając jego potencjał rankingowy. Badania wskazują, że prawidłowa kanonizacja może poprawić widoczność w wyszukiwarce o 15-30% w przypadku stron z poważnymi problemami z duplikacją treści.
Kanoniczny URL a powiązane koncepcje: tabela porównawcza
| Aspekt | Kanoniczny URL (rel=“canonical”) | Przekierowanie 301 | Umieszczenie w mapie witryny | Blokowanie przez robots.txt |
|---|
| Cel | Wskazuje preferowaną wersję, zachowując dostępność duplikatów | Na stałe przenosi jeden adres URL na inny | Sugeruje kanoniczne adresy URL wyszukiwarkom | Zapobiega indeksowaniu zduplikowanych stron |
| Doświadczenie użytkownika | Użytkownicy mogą odwiedzać zarówno kanoniczne, jak i zduplikowane adresy | Użytkownicy są automatycznie przekierowywani do nowego adresu | Brak bezpośredniego wpływu na użytkownika | Użytkownicy nie mają dostępu do zablokowanych stron |
| Siła sygnału dla wyszukiwarki | Silny sygnał; konsoliduje moc rankingową | Najsilniejszy sygnał; całkowita konsolidacja adresów | Słaby sygnał; Google musi sam określić duplikaty | Nie zalecane do kanonizacji |
| Złożoność wdrożenia | Średnia; wymaga modyfikacji HTML lub ustawień CMS | Średnia; wymaga konfiguracji serwera | Łatwa; dodanie adresów do mapy witryny | Łatwa; dodanie reguł do robots.txt |
| Najlepszy przypadek użycia | Duplikaty, które powinny pozostać dostępne | Usuwanie starych adresów lub migracje stron | Duże serwisy z wieloma kanonicznymi adresami | Blokowanie środowisk testowych/stagingowych |
| Konsolidacja mocy linków | Tak; sygnały przepływają do kanonicznego URL | Tak; pełny transfer do nowego adresu | Częściowa; zależy od interpretacji Google | Nie; całkowicie blokuje indeksowanie |
| Odwracalność | Tak; można zmienić lub usunąć | Trudna; wymaga nowej konfiguracji przekierowań | Tak; można zaktualizować mapę witryny | Tak; można usunąć z robots.txt |
| Wpływ na budżet indeksowania | Umiarkowany; ogranicza marnowanie indeksowania na duplikaty | Wysoki; eliminuje indeksowanie starych adresów | Niski; nadal indeksuje wszystkie adresy z mapy | Wysoki; zapobiega indeksowaniu duplikatów |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Techniczne wdrożenie kanonicznych adresów URL
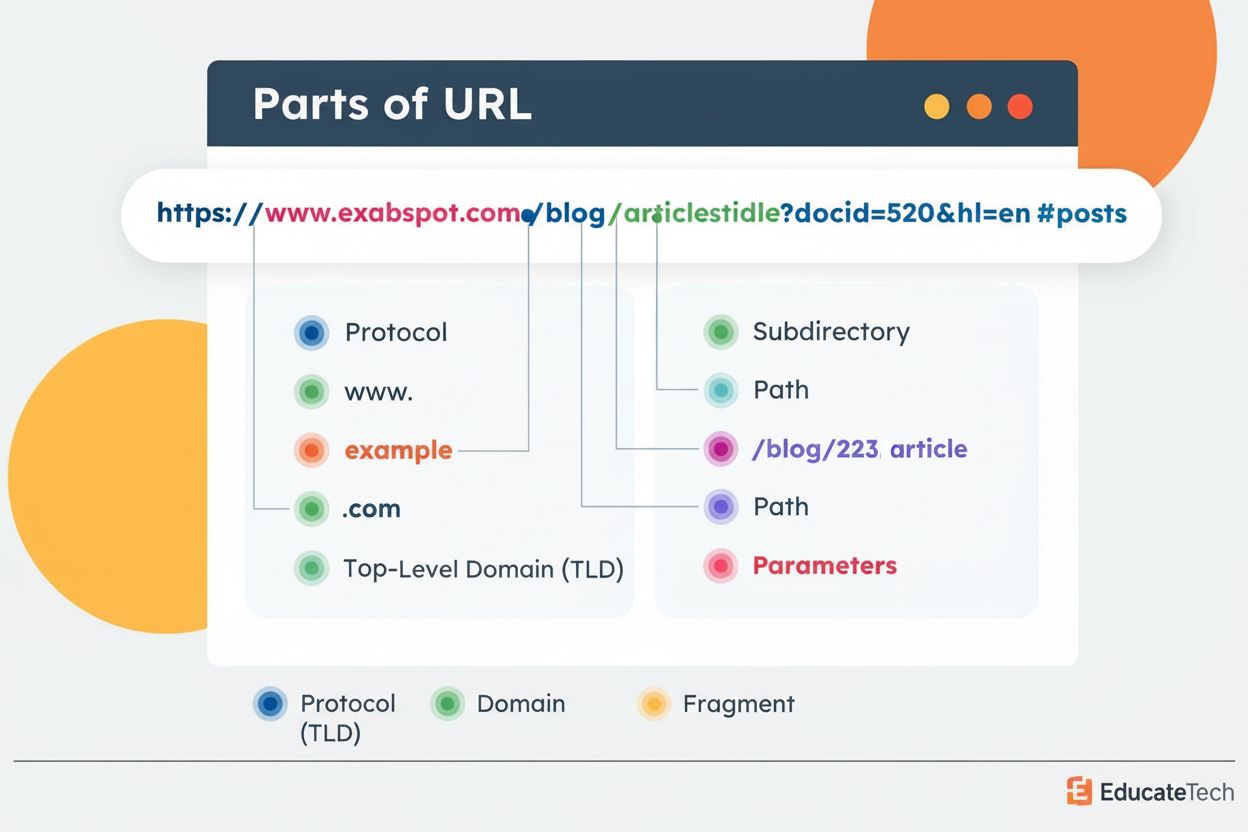
Wdrożenie kanonicznych adresów URL wymaga zrozumienia dostępnych metod i wyboru odpowiedniego podejścia do architektury twojej witryny i systemu zarządzania treścią. Najczęściej stosowaną metodą jest element link rel="canonical", umieszczany bezpośrednio w sekcji <head> HTML zduplikowanych stron. Tag ten powinien wskazywać absolutny adres URL (wraz z protokołem i domeną) wersji kanonicznej. Na przykład, na stronie produktu dostępnej pod wieloma adresami, należy dodać: <link rel="canonical" href="https://www.example.com/products/blue-shoes" /> do wszystkich zduplikowanych wersji. Kanoniczny adres URL powinien być czysty i dostępny – bez parametrów śledzących, identyfikatorów sesji czy zbędnych ciągów zapytań. Samoodnoszące się tagi kanoniczne – gdzie tag kanoniczny strony wskazuje na jej własny adres – są coraz częściej zalecaną praktyką. Podejście to wzmacnia dla wyszukiwarek informację o wersji kanonicznej nawet dla unikalnych stron i zapobiega przypadkowym problemom z kanonizacją. Dla treści innych niż HTML, takich jak PDF, pliki Word czy inne typy plików, bardziej odpowiednia jest metoda nagłówka HTTP rel="canonical". Wymaga to skonfigurowania serwera do wysyłania nagłówka Link w odpowiedzi HTTP: Link: <https://www.example.com/document.pdf>; rel="canonical". Metoda ta jest szczególnie przydatna na stronach publikujących treści w wielu formatach pod różnymi adresami. Dodatkowo, przekierowania 301 stanowią silny sygnał kanonizacyjny, szczególnie gdy chcesz całkowicie skonsolidować adresy URL i usunąć starą wersję z wyników wyszukiwania. Gdy Strona A jest przekierowana kodem 301 na Stronę B, wyszukiwarki rozumieją, że Strona B jest wersją kanoniczną i odpowiednio przekazują wszystkie sygnały rankingowe. Mapy witryn XML dostarczają słabszego, ale wciąż wartościowego sygnału kanonizacyjnego przez uwzględnienie tylko kanonicznych adresów URL do indeksowania. Na koniec, preferencja HTTPS jest automatycznym sygnałem – Google preferuje wersje HTTPS nad HTTP, więc ważne, by adresy kanoniczne używały HTTPS.
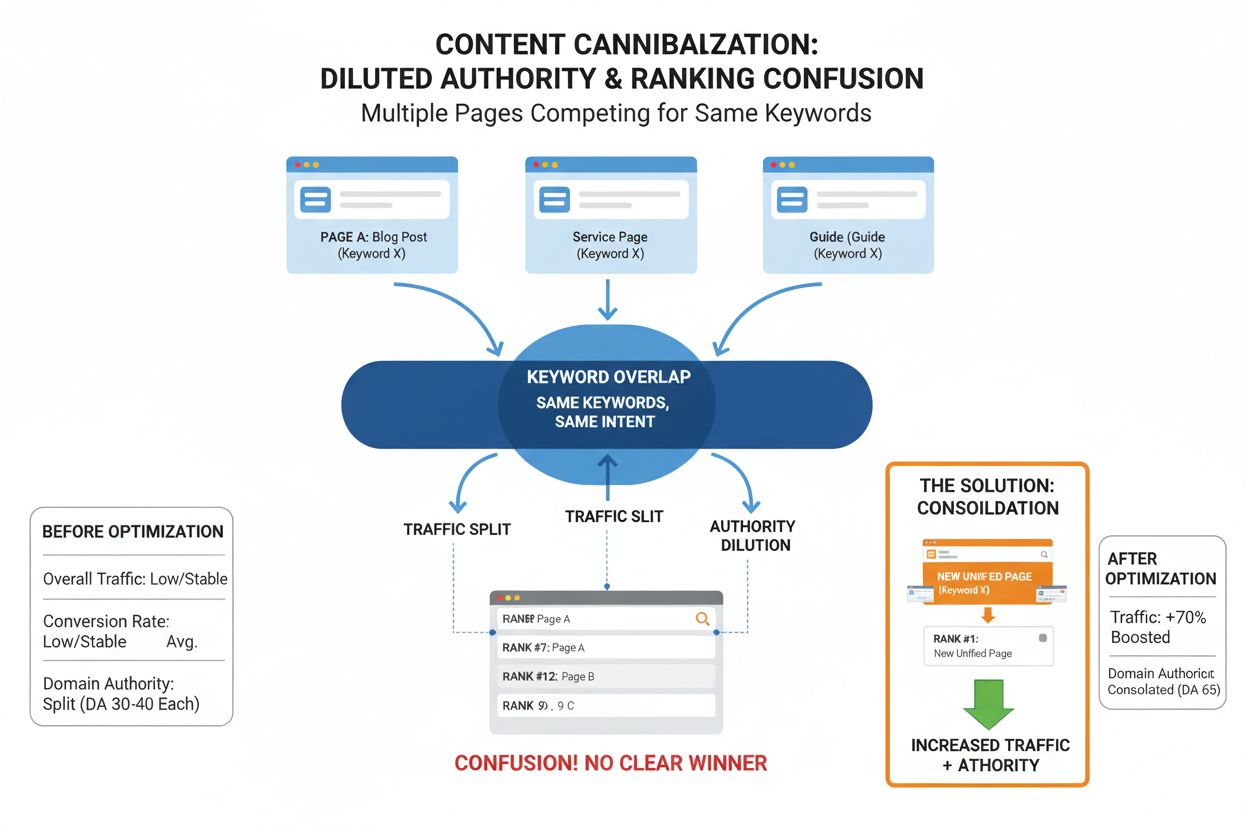
Kanoniczne adresy URL a zapobieganie duplikacji treści
Duplikacja treści to jedno z największych wyzwań współczesnego zarządzania stronami, dotykające około 29% wszystkich zaindeksowanych stron według badań branżowych. Duplikaty powstają na wiele sposobów: serwisy e-commerce z filtrami produktów i sortowaniem generują unikalne adresy URL dla tego samego produktu, blogi z archiwami tagów i kategorii wyświetlają te same artykuły, syndykacja treści na różnych domenach, mobilne adresy URL obok desktopowych, przypadkowe duplikaty z środowisk stagingowych lub testowych. Bez prawidłowej kanonizacji wyszukiwarki muszą same zdecydować, którą wersję zindeksować, często wybierając wbrew twoim celom biznesowym. Może to prowadzić do kanibalizacji słów kluczowych, gdy kilka wersji tej samej treści konkuruje o te same frazy, rozpraszając moc rankingową i obniżając widoczność. Kanoniczne adresy URL rozwiązują ten problem, jasno komunikując wyszukiwarkom twoje preferencje. Gdy wskażesz kanoniczny URL, wyszukiwarki rozumieją, że wszystkie duplikaty powinny być traktowane jako wariant jednej treści, a sygnały rankingowe skonsolidowane do wersji kanonicznej. Ta konsolidacja jest szczególnie ważna dla dystrybucji mocy linków. Jeśli twoja strona otrzymuje linki prowadzące do różnych wariantów tego samego adresu, linki te normalnie liczyłyby się osobno, dzieląc ranking. Dzięki tagom kanonicznym cała moc linków przepływa do kanonicznego adresu, wzmacniając sygnał rankingowy. Na przykład, jeśli strona główna jest dostępna pod https://www.example.com, https://example.com, http://www.example.com i http://example.com, a każda wersja otrzymuje linki, tagi kanoniczne zapewniają konsolidację autorytetu do wybranej wersji. Taka konsolidacja może przynieść 15-30% wzrost pozycji w wyszukiwarce dla stron z poważnymi problemami z duplikacją.
Kanoniczne adresy URL w e-commerce i środowiskach dynamicznych
Serwisy e-commerce stoją przed szczególnie trudnymi wyzwaniami kanonizacyjnymi ze względu na charakter stron produktowych i systemy filtrowania. Jeden produkt może być dostępny pod wieloma adresami: bezpośredni URL produktu, adresy z zastosowanymi filtrami koloru lub rozmiaru, z parametrami sortowania, z kodami śledzącymi z kampanii marketingowych i mobilne adresy URL. Bez prawidłowej kanonizacji wyszukiwarki mogą indeksować dziesiątki wariantów tej samej strony produktowej, marnując budżet indeksowania i rozpraszając moc rankingową. Serwisy e-commerce wdrażające prawidłową kanonizację odnotowują 20-40% wzrost ruchu organicznego dzięki konsolidacji sygnałów rankingowych. Kanoniczny adres produktu powinien być zazwyczaj czystym adresem produktu bez parametrów: https://www.example.com/products/blue-running-shoes. Wszystkie warianty z filtrami, sortowaniem czy śledzeniem powinny zawierać tag kanoniczny wskazujący na ten czysty URL. Systemy CMS takie jak Magento, Shopify i WooCommerce często mają wbudowane funkcje kanonizacji automatycznie generujące odpowiednie tagi. Czasem jednak wymagają one dodatkowej konfiguracji, by działały prawidłowo. W sklepach Shopify tagi kanoniczne są automatycznie dodawane do stron produktów i kolekcji, ale niestandardowe wdrożenia mogą wymagać ręcznej konfiguracji. Magento pozwala włączyć tagi kanoniczne dla produktów i kategorii, jednak kanonizacja kategorii wymaga ostrożności, by nie dopuścić do niezamierzonej konsolidacji. Strony WordPress z wtyczkami SEO jak Yoast SEO czy Rank Math mogą automatycznie generować tagi kanoniczne z opcją ich personalizacji na każdej stronie. Kluczową zasadą dla e-commerce jest zapewnienie, by wszystkie warianty produktu – niezależnie od filtrów, sortowania czy parametrów śledzących – wskazywały jeden kanoniczny adres produktu, co umożliwia poprawne indeksowanie i ranking produktu przy konsolidacji wszystkich sygnałów rankingowych.
Kanoniczne adresy URL a optymalizacja pod AI
Pojawienie się wyszukiwarek AI i systemów generatywnych wprowadziło nowy wymiar znaczenia kanonicznych adresów URL. Platformy takie jak ChatGPT, Perplexity, Claude i Google AI Overviews korzystają z indeksowania sieci do zbierania informacji do generowania odpowiedzi. Gdy systemy AI napotykają wiele adresów URL z tą samą treścią, prawidłowa kanonizacja pomaga wskazać autorytatywne źródło do cytowania. Ponad 60% przedsiębiorstw martwi się dziś o to, jak ich treści pojawiają się w odpowiedziach generowanych przez AI, co czyni zarządzanie kanonicznymi adresami coraz ważniejszym dla widoczności marki i przypisania. Gdy system AI indeksuje twoją stronę i znajduje wiele adresów z tą samą treścią, musi zdecydować, który z nich zacytować jako źródło. Bez tagów kanonicznych AI może zacytować niekanoniczną wersję, kierując użytkownika na mniej optymalną stronę lub nie przypisując poprawnie twojej marce. Dzięki kanonizacji zapewniasz, że systemy AI cytują twój preferowany adres, poprawiając doświadczenie użytkownika i zachowując spójność przypisania marki. Jest to szczególnie ważne dla monitorowania i śledzenia cytowań przez AI, gdzie platformy takie jak AmICited pomagają organizacjom śledzić, jak ich treści pojawiają się w odpowiedziach AI. Poprawne wdrożenie tagów kanonicznych zwiększa prawdopodobieństwo, że preferowany URL pojawi się w cytacjach AI, poprawiając widoczność w świecie wyszukiwania AI. Dodatkowo, kanoniczne adresy pomagają systemom AI rozumieć strukturę twojej strony i hierarchię treści, umożliwiając trafniejsze i dokładniejsze cytacje. Wraz z rozwojem wyszukiwania AI – Perplexity notuje ponad 500 milionów aktywnych użytkowników miesięcznie, a wyszukiwarka ChatGPT się rozrasta – prawidłowa kanonizacja staje się kluczowa dla utrzymania widoczności i przypisania w AI-generowanych treściach.
Najlepsze praktyki wdrożenia kanonicznych adresów URL
Efektywne wdrożenie kanonicznych adresów wymaga przestrzegania najlepszych praktyk, które zapewniają, że wyszukiwarki i systemy AI prawidłowo rozpoznają i respektują sygnały kanonizacji. Używaj adresów absolutnych, nigdy względnych w tagach kanonicznych – zawsze z pełnym protokołem i domeną: <link rel="canonical" href="https://www.example.com/page" /> zamiast <link rel="canonical" href="/page" />. Względne adresy mogą sprawiać problemy, zwłaszcza gdy środowisko testowe zostanie przypadkowo zindeksowane lub zmienia się struktura adresów. Zapewnij spójność wszystkich sygnałów kanonizacji – tagi kanoniczne, linki wewnętrzne, wpisy w mapie witryny i przekierowania 301 muszą wskazywać na ten sam adres. Sprzeczne sygnały mylą wyszukiwarki i osłabiają skuteczność kanonizacji. Unikaj łańcuchów tagów kanonicznych, gdzie Strona A wskazuje na B, a B na C – wyszukiwarki mogą nie śledzić tego poprawnie, prowadząc do błędnej kanonizacji. Nigdy nie wskazuj tagiem kanonicznym stron przekierowanych lub zablokowanych przez robots.txt czy oznaczonych noindex – to rodzi sprzeczne sygnały, z którymi wyszukiwarki sobie nie radzą. Wdrażaj samoodnoszące się tagi kanoniczne na wszystkich stronach, włącznie z kanonicznymi – wzmacnia to informację dla wyszukiwarek o wersji kanonicznej i zapobiega przypadkowym problemom z kanonizacją. Stosuj HTTPS w adresach kanonicznych, jeśli twoja strona go obsługuje, bo wyszukiwarki preferują wersje HTTPS. Dbaj o spójność formatowania adresów – dotyczących ukośników na końcu, prefiksu www i wielkości liter. Zdecyduj, czy adresy kanoniczne mają zawierać ukośnik na końcu (https://example.com/page/) czy nie (https://example.com/page) i stosuj to konsekwentnie. Regularnie audytuj tagi kanoniczne za pomocą narzędzi takich jak Google Search Console, Moz Pro Site Crawl czy Semrush Site Audit, by wykryć brakujące, błędne lub sprzeczne tagi. Testuj wdrożenie przy użyciu narzędzi developerskich przeglądarki lub narzędzi SEO, by upewnić się, że tagi kanoniczne są prawidłowo umieszczone w sekcji head i wskazują poprawne adresy.
Najczęstsze błędy związane z kanonicznymi adresami URL i jak ich unikać
Pomimo znaczenia kanonicznych adresów URL, wiele stron wdraża je nieprawidłowo, przez co tracą one skuteczność, a nawet mogą szkodzić SEO. Jednym z najczęstszych błędów jest wskazywanie tagiem kanonicznym nieistniejących lub błędnych adresów URL. Powoduje to, że wyszukiwarki otrzymują sprzeczne sygnały – tag sugeruje indeksowanie konkretnego adresu, ale ten zwraca błąd 404 lub jest zablokowany przed indeksowaniem. Zawsze sprawdzaj, czy adresy kanoniczne są dostępne, zwracają kod 200 i nie są blokowane przez robots.txt ani oznaczone noindex. Innym częstym błędem jest używanie tagów kanonicznych dla treści niebędących duplikatami. Tagi te powinny być stosowane tylko dla zduplikowanych lub bardzo podobnych treści. Niektórzy specjaliści SEO błędnie próbują konsolidować moc rankingową z różnych stron, np. przekierowując autorytet z wyprzedanych produktów na strony kategorii. Google wyraźnie odradza takie praktyki i prawdopodobnie zignoruje takie tagi. Łańcuchy tagów kanonicznych to kolejny poważny błąd – Strona A wskazuje na B, B na C itd. Wyszukiwarki mogą nie rozpoznać tego prawidłowo i błędnie kanonizować. Tagi kanoniczne zawsze powinny wskazywać bezpośrednio na ostateczny adres kanoniczny. Sprzeczne sygnały kanonizacji pojawiają się, gdy różne metody kanonizacji wskazują różne adresy, np. tag kanoniczny wskazuje jeden adres, a przekierowanie 301 inny – wyszukiwarki otrzymują sprzeczne dane i mogą zignorować oba sygnały. Upewnij się, że wszystkie metody – tagi, przekierowania, mapy witryn i linkowanie – wskazują na ten sam adres. Umieszczanie tagów kanonicznych poza sekcją head HTML uniemożliwia wyszukiwarkom ich odnalezienie – muszą być one w <head>. Użycie adresów względnych zamiast absolutnych może powodować problemy, szczególnie przy zmianach struktury lub przypadkowym indeksowaniu środowisk testowych. Zawsze używaj pełnych adresów z protokołem i domeną. Brak samoodnoszących tagów kanonicznych na stronach kanonicznych może prowadzić do przypadkowej kanonizacji. Każda strona, w tym kanoniczna, powinna mieć tag wskazujący na siebie. Nieprawidłowe łączenie tagów kanonicznych z hreflang na stronach wielojęzycznych może powodować problemy – każda wersja językowa powinna mieć własny tag kanoniczny wskazujący na siebie i hreflang wskazujący na pozostałe wersje.
Kanoniczne adresy URL a optymalizacja budżetu indeksowania
Budżet indeksowania – liczba stron, które wyszukiwarki odwiedzą na twojej stronie w określonym czasie – jest ograniczonym zasobem, szczególnie dla dużych witryn. Strony z dużą liczbą duplikatów mogą marnować 20-40% budżetu indeksowania na podstrony, które nie powinny być indeksowane. Kanoniczne adresy pomagają zoptymalizować ten budżet, sygnalizując wyszukiwarkom, które strony warto zindeksować. Przy prawidłowym wdrożeniu tagów kanonicznych wyszukiwarki rozumieją, że duplikaty nie wymagają tak częstego indeksowania, dzięki czemu mogą przeznaczyć więcej zasobów na unikalne, wartościowe treści. Jest to szczególnie ważne dla dużych sklepów internetowych z tysiącami wariantów produktów, serwisów newsowych z wieloma formatami artykułów i platform z rozległymi archiwami tagów i kategorii. Konsolidując duplikaty poprzez kanonizację, zapewniasz, że roboty wyszukiwarek skupiają się na stronach kluczowych dla twojego biznesu. To może przełożyć się na szybsze indeksowanie nowych treści, częstsze odwiedziny ważnych stron i ogólną poprawę widoczności. Ponadto prawidłowa kanonizacja redukuje liczbę adresów pojawiających się w Google Search Console, ułatwiając monitorowanie i zarządzanie SEO. Dla stron z ograniczonym budżetem indeksowania – zwłaszcza mniejszych witryn lub działających w konkurencyjnych branżach – optymalizacja budżetu przez kanonizację może mieć wymierny wpływ na pozycje i widoczność.
Przyszłość kanonicznych adresów URL w wyszukiwaniu AI
Wraz z rozwojem wyszukiwarek opartych na AI i systemów generatywnych rola kanonicznych adresów URL nabiera coraz większego znaczenia. Rynek wyszukiwania AI ma wzrosnąć z 5,2 mld USD w 2024 do ponad 15 mld USD w 2030, a platformy takie jak Perplexity, ChatGPT i Claude zdobywają istotny udział. Systemy AI opierają się na indeksowaniu sieci podobnie jak tradycyjne wyszukiwarki, dlatego kanoniczne adresy są niezbędne do poprawnego przypisywania treści i widoczności. Przyszłość kanonicznych adresów prawdopodobnie będzie obejmować większą integrację z systemami śledzenia cytowań AI. Platformy takie jak AmICited pioniersko umożliwiają śledzenie, jak twoje treści pojawiają się w odpowiedziach AI, a kanoniczne adresy odegrają