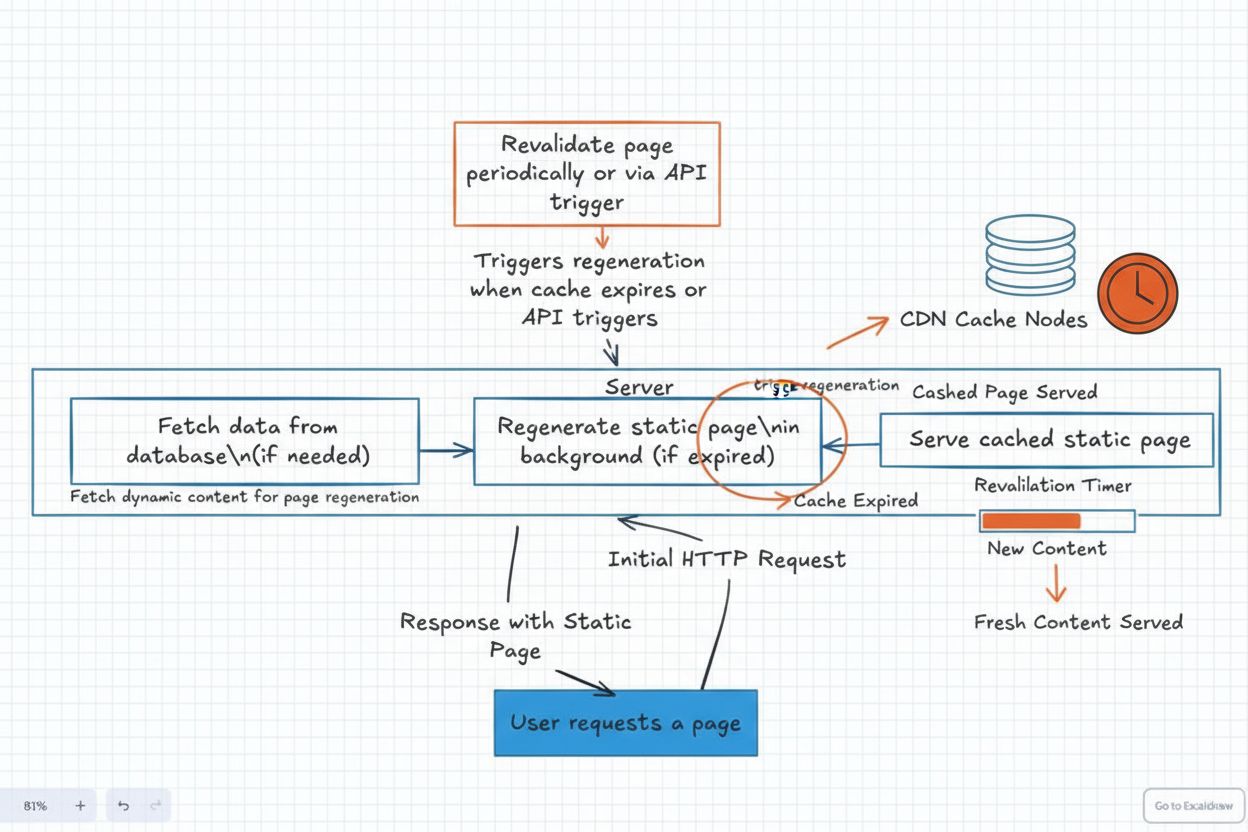
Incremental Static Regeneration (ISR)
Dowiedz się, czym jest Incremental Static Regeneration (ISR), jak działa i dlaczego jest niezbędny dla nowoczesnych aplikacji internetowych. Poznaj rolę ISR w m...
9 min czytania

Nieskończone przewijanie to technika projektowania stron internetowych, w której nowa zawartość ładowana jest automatycznie, gdy użytkownik dociera do końca strony, eliminując potrzebę tradycyjnej paginacji lub przycisków ‘Załaduj więcej’. Ten mechanizm ciągłego ładowania tworzy płynne doświadczenie przeglądania, powszechnie stosowane na platformach społecznościowych, stronach e-commerce i w newsfeedach.
Nieskończone przewijanie to technika projektowania stron internetowych, w której nowa zawartość ładowana jest automatycznie, gdy użytkownik dociera do końca strony, eliminując potrzebę tradycyjnej paginacji lub przycisków 'Załaduj więcej'. Ten mechanizm ciągłego ładowania tworzy płynne doświadczenie przeglądania, powszechnie stosowane na platformach społecznościowych, stronach e-commerce i w newsfeedach.
Nieskończone przewijanie to technika projektowania stron internetowych, w której nowa zawartość ładowana jest automatycznie i nieprzerwanie, gdy użytkownik przewija stronę w dół, eliminując potrzebę tradycyjnej paginacji lub wyraźnych przycisków „Załaduj więcej”. Znane także jako endless scrolling lub continuous scrolling, podejście to zostało wynalezione w 2006 roku i stało się powszechne na nowoczesnych platformach internetowych. Mechanizm działa poprzez wykrywanie momentu, gdy użytkownik zbliża się do końca aktualnie załadowanej zawartości i automatyczne pobieranie oraz wyświetlanie kolejnej partii elementów. Nieskończone przewijanie zapewnia płynne, nieprzerwane doświadczenie przeglądania, które zachęca użytkowników do eksplorowania większej ilości treści bez przeszkód. Ten wzorzec projektowy jest szczególnie popularny na platformach społecznościowych takich jak Instagram, TikTok i Twitter, a także na agregatorach newsów, stronach e-commerce oraz platformach odkrywania treści. Jego główną zaletą jest minimalizowanie przerw w użytkowaniu i utrzymanie zaangażowania poprzez ciągłą prezentację nowych treści, dzięki czemu strumień informacji wydaje się nie mieć końca.
Od momentu wprowadzenia w 2006 roku nieskończone przewijanie odnotowało lawinowy wzrost popularności, szczególnie wraz z rozwojem urządzeń mobilnych i interfejsów dotykowych. Technika ta zyskała na znaczeniu, gdy smartfony stały się podstawowym narzędziem przeglądania dla milionów użytkowników, ponieważ niewielkie ekrany mobilne naturalnie sprzyjają przewijaniu. Badania Nielsen Norman Group udokumentowały, że nieskończone przewijanie minimalizuje przerwy w korzystaniu w porównaniu do paginacji, która wymaga klikania „Dalej” i oczekiwania na załadowanie nowej strony. To ograniczenie tarcia sprawiło, że nieskończone przewijanie stało się domyślnym wzorcem dla newsfeedów społecznościowych, gdzie zaangażowanie i czas spędzony na stronie to kluczowe wskaźniki. Jednak popularność tej techniki ujawniła również poważne wady, szczególnie związane z optymalizacją pod wyszukiwarki, dostępnością i doświadczeniem użytkownika w określonych zastosowaniach. Ponad 78% firm korzysta obecnie z narzędzi AI do monitorowania widoczności treści na różnych platformach, przez co interakcja między nieskończonym przewijaniem a crawlami AI staje się coraz ważniejsza. Ewolucja nieskończonego przewijania doprowadziła do rozwiązań hybrydowych, takich jak połączenie go z paginacją lub wdrożenie przycisków „Załaduj więcej”, by zrównoważyć doświadczenie użytkownika z wymaganiami technicznymi i dostępności.
Nieskończone przewijanie działa poprzez połączenie nasłuchiwaczy zdarzeń JavaScript, wywołań API i manipulacji DOM. Gdy użytkownik przewija stronę w pobliże jej końca, nasłuchiwacz JavaScript wykrywa tę akcję i wywołuje żądanie pobrania dodatkowej zawartości z serwera. Pobrane treści są dynamicznie wstawiane do DOM (Document Object Model), rozszerzając stronę bez pełnego przeładowania. Większość wdrożeń korzysta z Intersection Observer API lub nasłuchiwaczy zdarzeń scroll, by wykryć, kiedy użytkownik zbliża się do końca widocznej treści. Często stosuje się techniki lazy loading, aby zoptymalizować wydajność poprzez renderowanie tylko tych elementów, które są aktualnie widoczne w oknie przeglądarki — praktyka ta znana jest jako wirtualizacja. Zapobiega to gromadzeniu przez przeglądarkę tysięcy elementów DOM w pamięci, co prowadziłoby do znacznego spadku wydajności. Nowoczesne frameworki jak React, Vue czy Angular umożliwiają stosunkowo łatwe wdrożenie nieskończonego przewijania dzięki gotowym bibliotekom i komponentom. Jednak poleganie na JavaScript do ładowania treści stwarza istotny problem: roboty wyszukiwarek oraz crawlerzy AI często nie mają dostępu do dynamicznie ładowanej treści, ponieważ nie wykonują JavaScriptu lub mają bardzo ograniczone możliwości jego obsługi. To ograniczenie techniczne ma poważne konsekwencje dla SEO i widoczności w wyszukiwaniu AI.
| Aspekt | Nieskończone przewijanie | Paginacja | Przycisk Załaduj więcej |
|---|---|---|---|
| Przerwy w korzystaniu | Minimalne; płynne przeglądanie | Duże; wymaga klikania i ładowania stron | Niskie; opcjonalna kontrola użytkownika |
| Koszt interakcji | Bardzo niski; automatyczne ładowanie | Wysoki; wymaga nawigacji | Średni; jedno kliknięcie na partię |
| Przyjazność mobilna | Doskonała; naturalne przewijanie | Dobra; małe cele dotykowe | Dobra; duże przyciski |
| Możliwość crawlowania przez SEO | Słaba bez paginacji | Doskonała; każda strona ma unikalny adres | Dobra; wymaga aktualizacji URL |
| Dostępność | Słaba; problemy z klawiaturą i czytnikami ekranu | Dobra; przejrzysta struktura | Umiarkowana; wymaga ARIA |
| Dostęp do stopki | Utrudniony; ciągłe ładowanie treści | Łatwy; stopka zawsze dostępna | Łatwy; stopka po kliknięciach |
| Ponowne odnajdywanie treści | Bardzo trudne; brak punktów orientacyjnych | Łatwe; numery stron dają kontekst | Trudne; treść się zlewa |
| Wydajność ładowania stron | Może się pogarszać; narastający DOM | Stabilna; stała treść na stronę | Stabilna; kontrolowane ładowanie |
| Najlepsze zastosowania | Media społecznościowe, rozrywka, newsfeed | Katalogi produktów, wyniki wyszukiwania, archiwa | E-commerce, odkrywanie treści, blogi |
| Kompatybilność z crawlerami AI | Bardzo słaba; treść zależna od JS ukryta | Doskonała; statyczne URL i HTML | Dobra; przy poprawnej implementacji |
Nieskończone przewijanie oferuje liczne korzyści w określonych zastosowaniach, szczególnie nastawionych na odkrywanie treści i zaangażowanie użytkowników. Najważniejszą zaletą jest redukcja przerw: badania opublikowane w Information Systems Journal wykazały, że nawet krótkie przerwy — jak kliknięcie „Dalej” — mogą skłonić użytkownika serwisów społecznościowych do porzucenia aktualnego zadania. Eliminując te punkty tarcia, nieskończone przewijanie zapewnia płynne doświadczenie, które zachęca użytkowników do pozostania na stronie i odkrywania kolejnych treści. Jest to szczególnie cenne dla platform społecznościowych, serwisów rozrywkowych i agregatorów newsów, gdzie celem jest maksymalizacja czasu i konsumpcji treści. Nieskończone przewijanie obniża również koszt interakcji, ponieważ użytkownik nie musi aktywnie nawigować między stronami; treści pojawiają się automatycznie podczas przewijania. Dla użytkowników mobilnych to wyjątkowo korzystne, bo małe ekrany naturalnie wymuszają częste przewijanie, a nieskończone przewijanie idealnie wpisuje się w ten sposób korzystania. Badania jednoznacznie wskazują, że nieskończone przewijanie zwiększa czas na stronie, liczbę odsłon na sesję i odkrywanie treści w porównaniu do paginacji. Sklepy internetowe stosujące nieskończone przewijanie notują większą wykrywalność produktów, bo użytkownicy przeglądają więcej elementów bez tarcia związanego z paginacją. Ponadto, nieskończone przewijanie eliminuje „iluzję kompletności”, która może pojawiać się w paginacji, gdy użytkownik myśli, że zobaczył już wszystkie dostępne treści po dotarciu do ostatniej strony.
Pomimo popularności, nieskończone przewijanie niesie ze sobą poważne wyzwania związane z użytecznością, które mogą negatywnie wpływać na doświadczenie użytkownika. Jednym z najważniejszych problemów jest trudność w ponownym odnalezieniu treści: bez punktów orientacyjnych lub przejrzystej struktury nawigacyjnej użytkownicy mają problem ze znalezieniem wcześniej widzianej pozycji i nie mogą łatwo do niej wrócić. Problem nasila się, gdy użytkownik kliknie w element, aby zobaczyć szczegóły, a po użyciu przycisku „wstecz” w przeglądarce trafia na początek nieskończonej listy i musi ponownie przewijać wcześniej widziane treści. Nieskończone przewijanie tworzy też iluzję kompletności, przez co użytkownicy mogą mylnie sądzić, że dotarli do końca strumienia, mimo że kolejne treści ładują się niewidocznie poniżej. Ten problem jest szczególnie dotkliwy, gdy brakuje wyraźnego wskaźnika ładowania. Kolejną poważną wadą jest utrudniony dostęp do stopki: nieustanny napływ nowych treści uniemożliwia dotarcie do ważnych informacji w stopce, takich jak kontakt, regulaminy czy odnośniki do innych sekcji serwisu. Problemy z dostępnością są bardzo poważne, szczególnie dla użytkowników korzystających wyłącznie z klawiatury i czytników ekranu. Użytkownicy klawiatury muszą przejść przez setki elementów, by dotrzeć do stopki, a czytniki ekranu często nie ogłaszają nowo załadowanej treści, przez co użytkownicy nie wiedzą, że pojawiły się kolejne elementy. Wydajność ładowania strony także może znacznie ucierpieć, gdy przeglądarka gromadzi kolejne elementy DOM przy każdym przewinięciu, zużywając coraz więcej pamięci i powodując spowolnienie lub nawet zawieszanie się strony — szczególnie na urządzeniach z ograniczonymi zasobami.
Nieskończone przewijanie stanowi poważne wyzwanie dla optymalizacji pod wyszukiwarki, ponieważ roboty wyszukiwarek nie mogą niezawodnie uzyskać dostępu do treści ukrytej poza początkowym ładowaniem strony. W przeciwieństwie do użytkowników, którzy mogą przewijać i wywoływać ładowanie kolejnych treści, crawlery takie jak Googlebot mają ograniczoną obsługę JavaScriptu i nie zawsze są w stanie odwzorować zachowanie wymagane do pobrania dodatkowych zasobów. Oznacza to, że zawartość pojawiająca się po początkowym ładowaniu strony może nigdy nie zostać zindeksowana, skutkując słabymi wynikami SEO i ograniczoną widocznością w wynikach wyszukiwania. Google wyraźnie zaleca, by strony stosujące nieskończone przewijanie wdrażały paginowaną serię stron składowych z unikalnymi adresami URL, by zapewnić możliwość crawlowania wszystkich treści. Bez takiego rozwiązania wyszukiwarki mogą zindeksować tylko pierwszą partię, faktycznie ukrywając większość Twoich treści przed wynikami wyszukiwania. Powolne ładowanie strony, często występujące przy nieskończonym przewijaniu, także negatywnie wpływa na SEO, ponieważ szybkość ładowania jest potwierdzonym czynnikiem rankingowym. Dodatkowo, nieskończone przewijanie utrudnia śledzenie analityki, bo tradycyjne metryki odsłon są mniej wiarygodne przy dynamicznym ładowaniu zawartości bez przeładowań strony. Google Search Console może wskazywać problemy z indeksacją, a miary takie jak współczynnik odrzuceń stają się mniej miarodajne. Aby rozwiązać te problemy, zaleca się wdrożenie nieskończonego przewijania z paginacją, gdzie każda pozycja przewijania odpowiada unikalnemu adresowi URL, możliwemu do niezależnego crawlowania. Podejście hybrydowe pozwala zachować korzyści użytkowe nieskończonego przewijania przy jednoczesnym zapewnieniu pełnej indeksacji wszystkich treści przez wyszukiwarki.
Rozwój wyszukiwarek AI takich jak ChatGPT, Perplexity i Claude wprowadził nowy wymiar problemu nieskończonego przewijania. W przeciwieństwie do tradycyjnych robotów wyszukiwarek, które mogą (z ograniczeniami) wykonywać JavaScript, crawlerzy AI pokroju GPTBot czy ChatGPT-User w ogóle nie uruchamiają JavaScriptu i rejestrują tylko surowy HTML z początkowego ładowania strony. Oznacza to, że treści ładowane dynamicznie poprzez nieskończone przewijanie są całkowicie niewidoczne dla systemów AI. Badania Oncrawl potwierdzają, że crawlerzy OpenAI nie wykonują JavaScriptu nawet jeśli pobierają pliki .js, przez co zawartość zależna od JS jest faktycznie nieosiągalna. Dla serwisów e-commerce to poważny problem: szczegóły produktów, ceny, dostępność i opinie klientów — często ładowane dynamicznie — pozostają ukryte przed crawlerami AI. Gdy użytkownicy pytają ChatGPT lub Perplexity o rekomendacje produktów lub informacje, strony z nieskończonym przewijaniem mogą nie pojawiać się w wynikach, bo ich zawartość jest niewidoczna dla AI. To poważna konkurencyjna wada, bo odpowiedzi generowane przez AI coraz częściej wpływają na zachowania użytkowników i kierują ruch. Krótkie timeouty (1-5 sekund) stosowane przez crawlerów AI pogłębiają problem, bo mogą pomijać strony, które ładują się zbyt wolno lub wymagają wykonania JavaScriptu. Aby zapewnić widoczność w wynikach wyszukiwania AI, strony muszą wdrażać prerendering lub renderowanie po stronie serwera, by dostarczyć w pełni wyrenderowany HTML dostępny natychmiast bez oczekiwania na uruchomienie JavaScriptu.
Aby zachować korzyści płynące z nieskończonego przewijania dla użytkowników przy jednoczesnym zapewnieniu dostępności dla wyszukiwarek i crawlerów AI, należy stosować kilka najlepszych praktyk. Po pierwsze, wdroż paginowaną serię stron składowych z unikalnymi, pełnymi adresami URL (np. example.com/kategoria?page=1, example.com/kategoria?page=2), które można odwiedzić bez JavaScriptu. Każda taka strona powinna zawierać sensowną ilość treści — zwykle 10-30 elementów — co pozwala zrównoważyć doświadczenie użytkownika z możliwością crawlowania. Upewnij się, że adresy URL paginacji są opisowe i stabilne, unikaj parametrów zmiennych w czasie. Użyj metod pushState i replaceState JavaScriptu, by aktualizować adres przeglądarki podczas przewijania i tworzyć historię stanów paginacji, po których można nawigować. Dzięki temu wyszukiwarki mogą odkryć i zindeksować każdy stan paginacji jako osobną stronę. Udostępnij alternatywną stronę „Wyświetl wszystko”, gdzie cała zawartość prezentowana jest w tradycyjnej paginacji — tak, by crawlery mogły uzyskać dostęp nawet jeśli JavaScript zawiedzie. Wdroż schema markup i dane strukturalne, aby pomóc wyszukiwarkom zrozumieć strukturę treści. Przetestuj, czy każdy adres paginacji działa niezależnie i zwraca właściwą treść bez korzystania z historii użytkownika czy cookies. Sprawdź, czy strony poza zakresem (np. page=999 przy tylko 10 stronach) zwracają kod 404, a nie przekierowują lub wyświetlają stronę błędu. Na koniec zadbaj o dostępność poprzez nawigację klawiaturą, odpowiednie ARIA i wsparcie dla czytników ekranu przy dynamicznym ładowaniu treści.
Współczesne projektowanie stron coraz częściej wykorzystuje rozwiązania hybrydowe, które łączą zalety nieskończonego przewijania z przejrzystością nawigacji paginacji. Popularnym wzorcem jest nieskończone przewijanie z wbudowaną paginacją, gdzie podczas przewijania pojawiają się wskaźniki stron pozwalające na przeskok pomiędzy nimi, przy zachowaniu płynności przewijania. Takie podejście zapewnia punkty orientacyjne, które pomagają użytkownikom odnaleźć się i ponownie znaleźć treść. Innym skutecznym rozwiązaniem hybrydowym jest przycisk „Załaduj więcej”, gdzie treść ładuje się automatycznie podczas początkowego przewijania, ale po osiągnięciu określonego progu pojawia się widoczny przycisk, dając użytkownikowi kontrolę nad ładowaniem kolejnych partii. Takie rozwiązanie zmniejsza zużycie transferu, poprawia dostępność i ułatwia dotarcie do stopki. Niektóre witryny wdrażają nieskończone przewijanie z przyklejonym paskiem paginacji na dole ekranu, pozwalającym na szybki skok do wybranej strony bez przewijania na górę. Google Shopping i Pepper.pl są przykładami takiego podejścia, łącząc automatyczne ładowanie zawartości z wyraźną kontrolą paginacji. Rozwiązania hybrydowe rozwiązują wiele problemów użyteczności i SEO związanych z czystym nieskończonym przewijaniem, zachowując jednocześnie wysoki poziom zaangażowania użytkowników. Kluczowe jest zapewnienie, by każdy stan paginacji miał unikalny, crawlowalny adres URL oraz by treść była dostępna bez JavaScriptu. Łącząc nieskończone przewijanie z paginacją, można zoptymalizować zarówno doświadczenie użytkownika, jak i widoczność w wyszukiwarkach, tworząc bardziej solidne i inkluzywne doświadczenie przeglądania.
Definicja i wdrożenia nieskończonego przewijania wciąż ewoluują wraz z rozwojem technologii webowych i zmianą oczekiwań użytkowników. Decyzja Google o usunięciu nieskończonego przewijania z wyników wyszukiwania w czerwcu 2024 roku sygnalizuje zmianę w postrzeganiu tego wzorca przez największe platformy i sugeruje, że tradycyjna paginacja może wrócić do łask w niektórych zastosowaniach. Jednak nieskończone przewijanie nadal dominuje na platformach społecznościowych i rozrywkowych, gdzie metryki zaangażowania premiują nieprzerwany strumień treści. Wzrost znaczenia wyszukiwarek AI fundamentalnie zmienia sposób wdrażania nieskończonego przewijania, zmuszając deweloperów do priorytetyzowania crawlability przez AI obok doświadczenia użytkownika. Prerendering i renderowanie po stronie serwera stają się standardem dla witryn, które chcą zachować nieskończone przewijanie i jednocześnie być widoczne w wynikach AI. Rozwój lepszych technik wirtualizacji i optymalizacji wydajności czyni nieskończone przewijanie coraz bardziej wykonalnym na wolniejszych łączach i urządzeniach mobilnych. Poprawa dostępności, w tym lepsze wsparcie dla ARIA i nawigacji klawiaturą, stopniowo czyni nieskończone przewijanie bardziej inkluzywnym. Przyszłość najprawdopodobniej przyniesie bardziej zaawansowane rozwiązania hybrydowe, inteligentnie łączące nieskończone przewijanie, paginację i przyciski „Załaduj więcej” w zależności od typu treści, urządzenia i intencji użytkownika. Wraz z rozwojem systemów AI w wyszukiwaniu i odkrywaniu treści, zdolność do łączenia dobrego doświadczenia użytkownika z czytelnością maszynową będzie coraz ważniejsza. Serwisy, które wdrożą nieskończone przewijanie przy pełnej dostępności dla wyszukiwarek i crawlerów AI, uzyskają znac
Nieskończone przewijanie automatycznie ładuje nową zawartość, gdy użytkownik dociera do końca strony, bez potrzeby klikania, podczas gdy paginacja dzieli zawartość na oddzielne strony z ponumerowanymi linkami. Paginacja zapewnia wyraźne punkty nawigacyjne i łatwiejsze ponowne odnalezienie treści, podczas gdy nieskończone przewijanie tworzy płynne, nieprzerwane doświadczenie przeglądania. Paginacja lepiej sprawdza się w zadaniach zorientowanych na cel, a nieskończone przewijanie jest idealne do eksploracyjnego przeglądania na portalach społecznościowych i rozrywkowych.
Nieskończone przewijanie może negatywnie wpływać na SEO, ponieważ roboty wyszukiwarek nie zawsze mają dostęp do zawartości ukrytej poniżej początkowego ładowania strony, zwłaszcza gdy zawartość ładowana jest przez JavaScript. Google zaleca wdrożenie paginowanej serii równolegle z nieskończonym przewijaniem, aby zapewnić możliwość crawlowania całej zawartości. Bez prawidłowej implementacji wyszukiwarki mogą zindeksować tylko pierwszą partię treści, ograniczając widoczność głębszych zasobów i potencjalnie obniżając pozycje całej witryny.
Crawlerzy AI, tacy jak GPTBot i ChatGPT-User, nie wykonują JavaScriptu i rejestrują jedynie surowy HTML przy początkowym ładowaniu strony. Ponieważ nieskończone przewijanie zwykle ładuje treści dynamicznie za pośrednictwem JavaScript, crawlerzy AI całkowicie pomijają tę zawartość. Oznacza to, że szczegóły produktów, recenzje i inne dynamicznie ładowane informacje są niewidoczne dla systemów AI, zmniejszając widoczność w odpowiedziach generowanych przez AI na platformach takich jak ChatGPT czy Perplexity.
Nieskończone przewijanie ogranicza przerwy w korzystaniu przez użytkownika poprzez eliminację kliknięć stron, obniża koszt interakcji i zapewnia płynne doświadczenie, które sprzyja dłuższym sesjom zaangażowania. Jest szczególnie dobrze dostosowane do urządzeń mobilnych, gdzie niewielkie ekrany naturalnie wymuszają przewijanie. Badania pokazują, że nieskończone przewijanie może zwiększyć czas spędzony na stronie i odkrywanie produktów w porównaniu do tradycyjnej paginacji, co czyni je idealnym dla platform społecznościowych, rozrywkowych i e-commerce.
Nieskończone przewijanie powoduje poważne problemy z dostępnością dla użytkowników korzystających wyłącznie z klawiatury i czytników ekranu. Użytkownicy klawiatury muszą przechodzić przez setki pozycji, by dotrzeć do stopki lub innych elementów strony, podczas gdy czytniki ekranu często wykrywają tylko początkową partię treści i nie wywołują ładowania nowych elementów. Rola ARIA 'feed' uzyskała lepsze wsparcie, ale wiele implementacji nadal nie posiada właściwych funkcji dostępności, przez co nieskończone przewijanie jest problematyczne dla osób z niepełnosprawnościami.
Wdroż podejście hybrydowe poprzez utworzenie paginowanej serii stron składowych z unikalnymi, crawlowalnymi adresami URL równolegle z interfejsem nieskończonego przewijania. Użyj metod pushState lub replaceState JavaScriptu do aktualizacji adresu URL podczas przewijania, zapewniając każdemu stanowi strony unikalny adres. Zapewnij stronę zbiorczą 'Wyświetl wszystko', wdroż odpowiednie znaczniki schema i upewnij się, że treść jest dostępna także bez JavaScriptu. Takie podejście równoważy doświadczenie użytkownika z możliwością crawlowania przez wyszukiwarki.
Przycisk 'Załaduj więcej' to rozwiązanie hybrydowe łączące zalety nieskończonego przewijania i paginacji. Treść ładuje się automatycznie podczas początkowego przewijania, lecz po osiągnięciu określonego progu pojawia się widoczny przycisk 'Załaduj więcej'. Pozwala to użytkownikowi kontrolować ładowanie kolejnych treści, zmniejsza zużycie transferu, poprawia dostępność oraz ułatwia dotarcie do stopki. To coraz popularniejsze rozwiązanie na urządzeniach mobilnych i w wynikach wyszukiwania Google.
Nieskończone przewijanie może znacznie wydłużyć czasy ładowania, gdyż przeglądarka nieustannie gromadzi elementy DOM podczas ładowania nowych treści. Może to prowadzić do pogorszenia wydajności, zwłaszcza na urządzeniach mobilnych z ograniczonym transferem lub mocą obliczeniową. Techniki wirtualizacji i lazy loading mogą ograniczyć te problemy poprzez renderowanie tylko widocznych elementów. Słaba wydajność jest szczególnie uciążliwa dla użytkowników z wolnym internetem lub ograniczonym pakietem danych, co może prowadzić do opuszczania strony.
Zacznij śledzić, jak chatboty AI wspominają Twoją markę w ChatGPT, Perplexity i innych platformach. Uzyskaj praktyczne spostrzeżenia, aby poprawić swoją obecność w AI.
Dowiedz się, czym jest Incremental Static Regeneration (ISR), jak działa i dlaczego jest niezbędny dla nowoczesnych aplikacji internetowych. Poznaj rolę ISR w m...

Dowiedz się, jak zaimplementować nieskończone przewijanie przy zachowaniu indeksowalności dla crawlerów AI, ChatGPT, Perplexity i tradycyjnych wyszukiwarek. Poz...
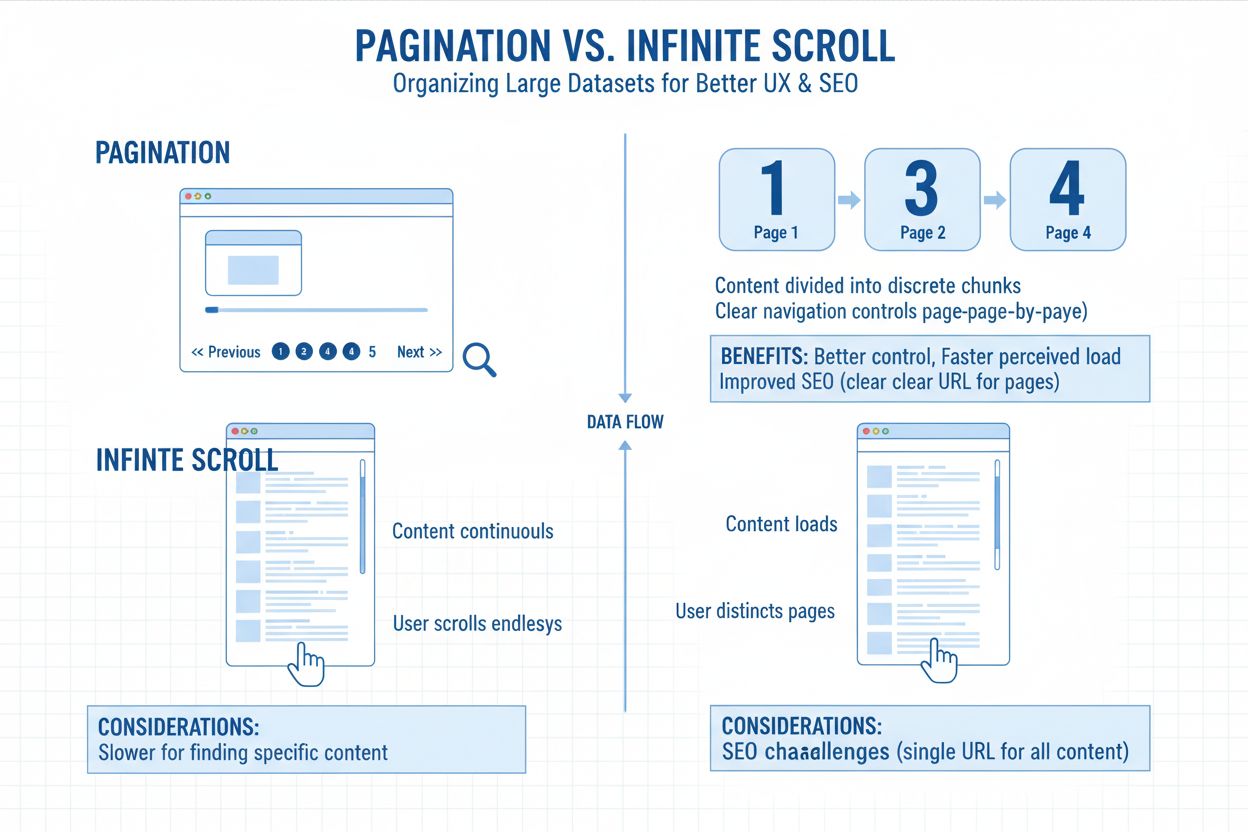
Paginacja dzieli duże zbiory treści na łatwe do zarządzania strony dla lepszego UX i SEO. Dowiedz się, jak działa paginacja, jaki ma wpływ na pozycje w wyszukiw...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.