Meta AI
Meta AI to asystent sztucznej inteligencji firmy Meta, zintegrowany z Facebookiem, Instagramem, WhatsAppem i Messengerem. Dowiedz się, jak działa, jakie ma możl...
11 min czytania
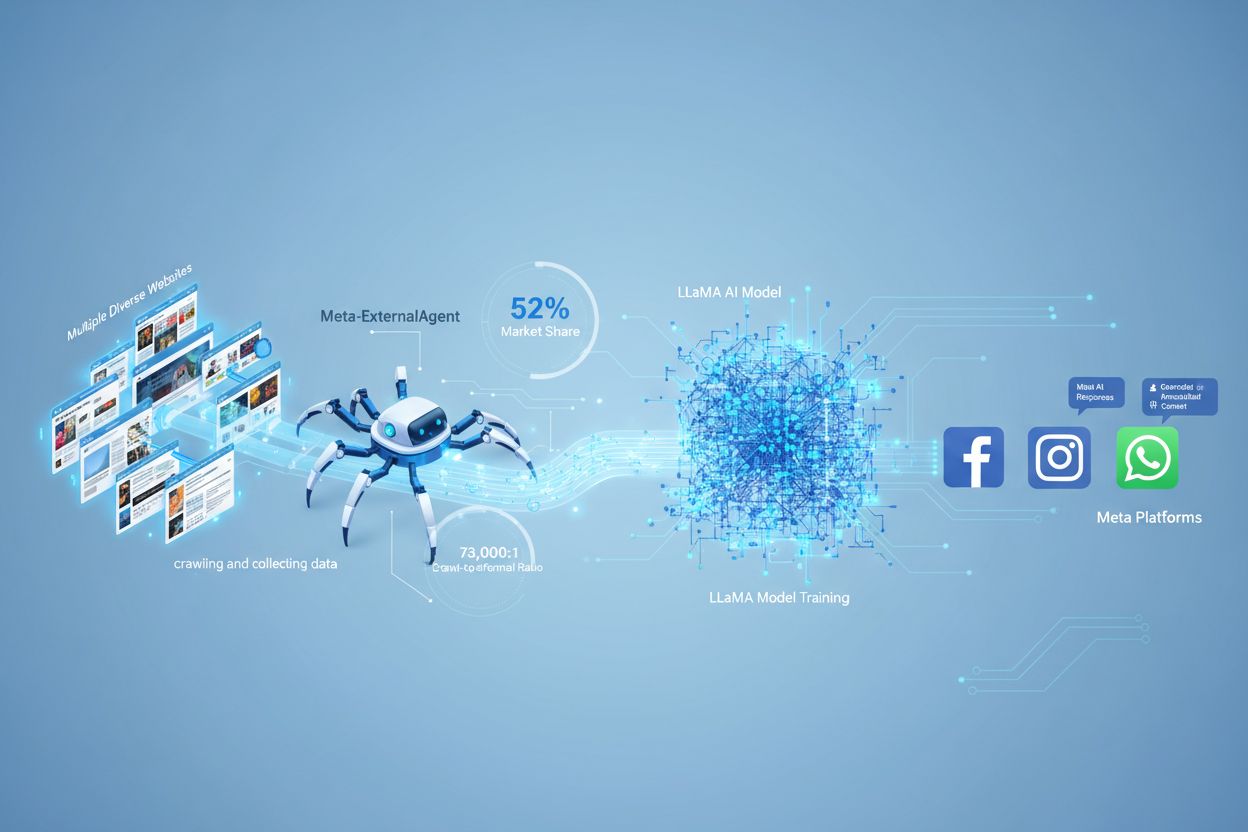
Meta-ExternalAgent to bot indeksujący stronę internetową firmy Meta, uruchomiony w lipcu 2024 roku w celu zbierania publicznie dostępnych treści do trenowania modeli AI takich jak LLaMA. Identyfikuje się poprzez ciąg User-Agent meta-externalagent/1.1 i kontroluje, czy treści pojawiają się w odpowiedziach Meta AI na Facebooku, Instagramie i WhatsAppie. Wydawcy mogą go zablokować przez robots.txt lub konfiguracje serwera, choć przestrzeganie tych blokad jest dobrowolne i nie ma mocy prawnej.
Meta-ExternalAgent to bot indeksujący stronę internetową firmy Meta, uruchomiony w lipcu 2024 roku w celu zbierania publicznie dostępnych treści do trenowania modeli AI takich jak LLaMA. Identyfikuje się poprzez ciąg User-Agent meta-externalagent/1.1 i kontroluje, czy treści pojawiają się w odpowiedziach Meta AI na Facebooku, Instagramie i WhatsAppie. Wydawcy mogą go zablokować przez robots.txt lub konfiguracje serwera, choć przestrzeganie tych blokad jest dobrowolne i nie ma mocy prawnej.
Meta-ExternalAgent to bot indeksujący strony internetowe obsługiwany przez Meta Platforms, uruchomiony w lipcu 2024 roku w celu zbierania danych do trenowania modeli sztucznej inteligencji. Identyfikowany przez User-Agent meta-externalagent/1.1, ten bot różni się od wcześniejszego bota Meta facebookexternalhit, który służył głównie do generowania podglądów linków i funkcji udostępniania w mediach społecznościowych. Meta-ExternalAgent oznacza istotną zmianę w sposobie, w jaki Meta gromadzi dane do swoich inicjatyw AI, w tym modeli językowych LLaMA i chatbota Meta AI zintegrowanego z Facebookiem, Instagramem i WhatsAppem. W przeciwieństwie do poprzednich botów Meta, ten agent działa przy minimalnej transparentności i został wdrożony bez oficjalnego, publicznego ogłoszenia.

Meta-ExternalAgent działa jako zautomatyzowany bot, który systematycznie przeszukuje strony internetowe, aby wyodrębniać tekst i treści do trenowania modeli AI. Bot wysyła żądania HTTP do serwerów, identyfikując się unikalnym nagłówkiem User-Agent i pobierając zawartość stron do dalszego przetwarzania. Po zebraniu treści systemy Meta analizują i tokenizują tekst, przekształcając go w dane treningowe, które pomagają doskonalić możliwości dużych modeli językowych. Bot respektuje plik robots.txt na zasadzie dobrowolności, co jest raczej systemem honorowym niż wymogiem prawnym. Według danych Cloudflare, Meta-ExternalAgent odpowiada za około 52% całego ruchu botów AI w internecie, czyniąc go jednym z najbardziej agresywnych narzędzi zbierania danych w branży AI. Bot działa nieprzerwanie, a niektórzy wydawcy zgłaszają częstotliwość indeksowania sugerującą, że Meta priorytetowo traktuje kompleksowe pokrycie treści internetowych zamiast selektywnego zbierania.
| Nazwa bota | User-Agent String | Główne zastosowanie | Data uruchomienia | Wykorzystanie danych |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | Trenowanie modeli AI (LLaMA, Meta AI) | lipiec 2024 | Dane treningowe do generatywnej AI |
| facebookexternalhit | facebookexternalhit/1.1 | Podglądy linków i udostępnianie społecznościowe | ~2010 | Metadane Open Graph, miniatury |
| Facebot | facebot/1.0 | Weryfikacja treści aplikacji Facebook | ~2015 | Walidacja treści dla aplikacji mobilnych |
| Applebot | Applebot/0.1 | Siri Apple i indeksowanie wyszukiwania | ~2015 | Indeksowanie wyszukiwania i asystent głosowy |
| Googlebot | Googlebot/2.1 | Indeksowanie Google Search | ~1998 | Tworzenie indeksu wyszukiwarki |
Meta-ExternalAgent stanowi poważne wyzwanie dla twórców treści i wydawców, ponieważ działa na niespotykaną dotąd skalę, zapewniając przy tym minimalną widoczność sposobu wykorzystania treści. Według badań Cloudflare, Meta-ExternalAgent odpowiada za 52% całego ruchu botów AI, znacznie wyprzedzając konkurentów takich jak GPTBot OpenAI i boty AI Google. Ta dominacja oznacza, że Meta zbiera więcej danych treningowych niż jakakolwiek inna firma AI, a wydawcy nie otrzymują żadnego wynagrodzenia ani atrybucji, gdy ich treści są używane do trenowania modeli Meta. Stosunek indeksowania do przekierowań 73 000:1 pokazuje, że Meta pobiera ogromne ilości treści, niemal nie kierując ruchu zwrotnego na strony źródłowe — to fundamentalna nierównowaga wartości. Mimo tych obaw, tylko 2% stron aktywnie blokuje Meta-ExternalAgent, podczas gdy 25% blokuje GPTBot, co sugeruje, że wielu wydawców nie jest świadomych obecności bota lub jej konsekwencji. Przy inwestycjach Meta w AI sięgających 40 miliardów dolarów, zaangażowanie firmy w agresywne zbieranie danych najprawdopodobniej będzie rosło, dlatego tak ważne jest, by wydawcy rozumieli i aktywnie zarządzali relacją z tym botem.
Wydawcy mogą kontrolować dostęp Meta-ExternalAgent poprzez plik robots.txt, należy jednak pamiętać, że to narzędzie działa na zasadzie dobrowolności i nie ma mocy prawnej. Aby zablokować Meta-ExternalAgent, dodaj do pliku robots.txt następującą dyrektywę:
User-agent: meta-externalagent
Disallow: /
Alternatywnie, jeśli chcesz dopuścić bota tylko do określonych katalogów, możesz użyć:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Jednak niektórzy wydawcy zgłaszają, że Meta-ExternalAgent nadal indeksuje ich strony mimo wdrożenia blokad w robots.txt, co sugeruje, że Meta nie zawsze respektuje te wytyczne. Dla pełniejszej ochrony wydawcy mogą wdrożyć blokowanie na podstawie nagłówków HTTP lub użyć reguł Content Delivery Network (CDN), by identyfikować i odrzucać żądania od Meta-ExternalAgent na podstawie User-Agent. Dodatkowo, wydawcy mogą monitorować logi serwera pod kątem User-Agent meta-externalagent/1.1, by zweryfikować dostęp bota do ich treści. Narzędzia takie jak AmICited.com pomagają śledzić, czy Twoje treści są cytowane lub wykorzystywane w odpowiedziach Meta AI, zapewniając wgląd w sposób użycia Twojej pracy przez systemy AI firmy Meta.

Gdy użytkownicy korzystają z chatbotów Meta AI na Facebooku, Instagramie czy WhatsAppie, generowane odpowiedzi częściowo opierają się na treściach zebranych przez Meta-ExternalAgent. Jednak odpowiedzi Meta AI zazwyczaj nie zawierają widocznych cytowań ani atrybucji do stron źródłowych, przez co użytkownicy nie wiedzą, których wydawców treści przyczyniły się do uzyskanej odpowiedzi. Brak transparentności stanowi poważne wyzwanie dla twórców treści, którzy chcą zrozumieć wartość, jaką ich praca wnosi do systemów AI Meta. W przeciwieństwie do niektórych konkurentów, którzy zamieszczają cytowania w odpowiedziach AI, podejście Meta przedkłada doświadczenie użytkownika nad atrybucję wydawcy. Brak widocznych cytowań sprawia, że wydawcy nie mogą łatwo śledzić, jak często ich treści wpływają na odpowiedzi Meta AI, co utrudnia ocenę biznesowego wpływu wykorzystania ich treści do trenowania AI. Ta luka w widoczności to jedna z głównych przyczyn rosnącej popularności narzędzi monitorujących wśród wydawców chcących zrozumieć swoją rolę w ekosystemie AI.
Wydawcy mogą weryfikować aktywność Meta-ExternalAgent analizując logi serwera, które ujawniają adresy IP bota, wzorce żądań i częstotliwość dostępu do treści. Przeglądając logi dostępu, można zidentyfikować żądania z User-Agent meta-externalagent/1.1 i określić, które strony są najczęściej indeksowane. Zaawansowane narzędzia monitorujące pozwalają śledzić wzorce indeksowania w czasie, ujawniając, czy Meta priorytetowo traktuje określone typy treści lub sekcje strony. Wydawcy powinni także monitorować zużycie transferu, ponieważ agresywne indeksowanie przez Meta-ExternalAgent może znacząco obciążać serwer, szczególnie w przypadku dużych bibliotek treści. Ponadto, narzędzia takie jak AmICited.com pozwalają monitorować pojawianie się własnych treści w odpowiedziach Meta AI i śledzić wzorce cytowań na platformach Meta. Ustawienie alertów na nietypową aktywność indeksowania pomoże wykryć zmiany w zachowaniu bota i odpowiednio zareagować. Regularne audyty logów serwera powinny być częścią każdej strategii zarządzania botami AI przez wydawcę, by na bieżąco wiedzieć, jak ich treści są wykorzystywane.
Status prawny Meta-ExternalAgent jest przedmiotem sporów, a trwające procesy sądowe ze strony twórców, artystów i wydawców kwestionują prawo firmy Meta do wykorzystywania ich prac do trenowania AI bez wyraźnej zgody czy wynagrodzenia. Meta twierdzi, że indeksowanie stron mieści się w ramach dozwolonego użytku, podczas gdy krytycy argumentują, że skala i komercyjny charakter zbierania danych, połączone z brakiem atrybucji, stanowią naruszenie praw autorskich. Plik robots.txt, choć powszechnie uznawany za standard branżowy, nie ma mocy prawnej, więc Meta nie jest zobowiązana do przestrzegania blokad. W kilku jurysdykcjach powstają regulacje dotyczące zbierania danych do trenowania AI – Akt o AI UE oraz planowane przepisy w innych regionach mogą nałożyć ostrzejsze wymogi na firmy takie jak Meta. Z etycznego punktu widzenia podstawowe pytanie brzmi, czy twórcy treści powinni mieć prawo do kontroli wykorzystania ich pracy do komercyjnego trenowania AI oraz czy obecny system należycie wynagradza ich za wartość, jaką dostarczają. Wydawcy powinni śledzić rozwój przepisów i rozważyć konsultacje prawne dotyczące swoich praw i obowiązków względem botów AI. Równowaga między umożliwianiem innowacji AI a ochroną praw twórców pozostaje nierozstrzygnięta i jest przedmiotem trwających prac legislacyjnych.
Krajobraz zarządzania botami AI szybko się zmienia, gdy wydawcy, regulatorzy i firmy AI negocjują zasady zbierania i wykorzystywania danych. Agresywne wdrożenie Meta-ExternalAgent pokazuje, że największe firmy technologiczne postrzegają treści internetowe jako kluczowy materiał treningowy dla konkurencyjnych systemów AI, a ten trend najprawdopodobniej się nasili, ponieważ możliwości AI stają się kluczowe dla strategii biznesowych. Przyszłość może przynieść silniejsze zabezpieczenia prawne dla twórców, obowiązkowe licencjonowanie danych treningowych dla AI i standardy techniczne ułatwiające wydawcom kontrolę i monetyzację wykorzystania ich treści przez AI. Pojawienie się narzędzi takich jak AmICited.com odzwierciedla rosnące zapotrzebowanie na przejrzystość i rozliczalność w zakresie wykorzystania treści przez systemy AI, co sugeruje, że monitoring i weryfikacja staną się standardem wśród twórców. Wraz z dojrzewaniem branży AI można spodziewać się bardziej zaawansowanych negocjacji między twórcami treści a firmami AI, co może prowadzić do nowych modeli biznesowych zapewniających wydawcom sprawiedliwe wynagrodzenie za wkład w trenowanie AI.
Meta-ExternalAgent to dedykowany do trenowania AI bot firmy Meta, uruchomiony w lipcu 2024 roku i identyfikowany przez User-Agent meta-externalagent/1.1. Różni się od facebookexternalhit, który generuje podglądy linków do udostępniania w mediach społecznościowych. Meta-ExternalAgent zbiera treści wyłącznie do trenowania modeli LLaMA i Meta AI, podczas gdy facebookexternalhit jest używany do funkcji społecznościowych od około 2010 roku.
Możesz zablokować Meta-ExternalAgent, dodając odpowiednie dyrektywy do pliku robots.txt. Dodaj 'User-agent: meta-externalagent' oraz 'Disallow: /', aby całkowicie go zablokować. Dla większej ochrony zastosuj blokowanie na poziomie serwera poprzez .htaccess (Apache) lub reguły konfiguracji Nginx. Jednak robots.txt to system honorowy i nie ma mocy prawnej, więc niektórzy wydawcy zgłaszają kontynuację indeksowania pomimo blokad.
Nie, blokowanie Meta-ExternalAgent nie wpłynie na podglądy linków na Facebooku. Za generowanie podglądów i funkcje społecznościowe odpowiada bot facebookexternalhit. Możesz zablokować meta-externalagent, pozwalając jednocześnie facebookexternalhit generować atrakcyjne podglądy podczas udostępniania Twoich treści na platformach Meta.
Stosunek indeksowania do przekierowań dla Meta-ExternalAgent wynosi około 73 000:1, co oznacza, że Meta pobiera treści na ogromną skalę, niemal nie kierując ruchu zwrotnego na strony źródłowe. To zasadnicza nierównowaga w porównaniu z tradycyjnymi wyszukiwarkami, które indeksują treści w zamian za generowanie ruchu odsyłającego.
robots.txt to system honorowy i nie ma mocy prawnej. Choć wiele botów respektuje dyrektywy robots.txt, niektórzy wydawcy zgłaszają, że Meta-ExternalAgent nadal indeksuje ich strony mimo wyraźnych blokad w robots.txt. Dla gwarantowanej ochrony wdroż blokowanie na poziomie serwera za pomocą nagłówków HTTP, reguł CDN lub konfiguracji zapory sieciowej.
Sprawdź logi dostępowe serwera pod kątem żądań z User-Agent 'meta-externalagent/1.1'. Możesz też korzystać z narzędzi monitorujących, takich jak AmICited.com, aby śledzić obecność swoich treści w odpowiedziach Meta AI. Narzędzia jak Dark Visitors i Cloudflare Analytics dostarczają dodatkowych informacji na temat aktywności botów AI na Twojej stronie.
Według danych Cloudflare, Meta-ExternalAgent odpowiada za około 52% całego ruchu botów AI w internecie, czyniąc go najbardziej agresywną operacją pozyskiwania danych przez AI. To znacznie więcej niż konkurenci, tacy jak GPTBot OpenAI i boty AI Google, co wskazuje na dominującą pozycję Meta w zbieraniu treści internetowych do trenowania AI.
Decyzja zależy od Twoich priorytetów biznesowych. Jeśli ruch z Meta AI jest wartościowy dla Twojej publiczności, możesz go dopuścić. Jednak pamiętaj, że Meta nie zapewnia rekompensaty ani atrybucji za treści wykorzystane do trenowania AI. Wielu wydawców wdraża selektywne strategie blokowania, które uniemożliwiają trenowanie AI, ale zachowują funkcję podglądów linków na potrzeby udostępniania społecznościowego.
Śledź, jak Twoje treści pojawiają się w odpowiedziach Meta AI na Facebooku, Instagramie i WhatsAppie. Zyskaj wgląd w cytowania AI i poznaj obecność swojej marki w odpowiedziach generowanych przez AI.
Meta AI to asystent sztucznej inteligencji firmy Meta, zintegrowany z Facebookiem, Instagramem, WhatsAppem i Messengerem. Dowiedz się, jak działa, jakie ma możl...

Dowiedz się, jak optymalizacja Meta AI zmienia reklamę na Facebooku i Instagramie dzięki automatyzacji napędzanej przez AI, licytacji w czasie rzeczywistym oraz...

Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.