Definicja algorytmu Sonar
Algorytm Sonar to zastrzeżony przez Perplexity system rankingowy retrieval-augmented generation (RAG), który zasila jej silnik odpowiedzi, łącząc hybrydowe wyszukiwanie semantyczne i słowne, neuralny reranking oraz generowanie cytowań w czasie rzeczywistym. W przeciwieństwie do tradycyjnych wyszukiwarek, które klasyfikują strony do wyświetlenia w liście wyników, Sonar szereguje fragmenty treści do syntezy w jedną, ujednoliconą odpowiedź z cytowaniami do dokumentów źródłowych. Algorytm priorytetowo traktuje aktualność treści, trafność semantyczną i możliwość cytowania, aby dostarczyć ugruntowane, poparte źródłami odpowiedzi i minimalizować halucynacje. Sonar to fundamentalna zmiana w sposobie, w jaki systemy AI pozyskują i klasyfikują informacje — przechodząc od sygnałów autorytetu opartych na linkach do metryk użyteczności skupionych na odpowiedziach, które podkreślają, czy treść bezpośrednio zaspokaja intencję użytkownika i może być czysto cytowana w zsyntetyzowanych odpowiedziach. To rozróżnienie jest kluczowe dla zrozumienia, jak widoczność w silnikach odpowiedzi AI różni się od tradycyjnego SEO, ponieważ Sonar ocenia treści nie pod kątem pozycji w liście, lecz zdolności do ekstrakcji, syntezy i przypisania w odpowiedzi generowanej przez AI.
Kontekst i tło: ewolucja rankingów opartych na AI
Pojawienie się algorytmu Sonar odzwierciedla szeroko zakrojony zwrot branży w stronę retrieval-augmented generation jako dominującej architektury dla silników odpowiedzi AI. Gdy Perplexity wystartowało pod koniec 2022 roku, zidentyfikowało kluczową lukę na rynku AI: podczas gdy ChatGPT oferował potężne możliwości konwersacyjne, brakowało mu dostępu do aktualnych informacji i przypisania źródeł, co prowadziło do halucynacji i nieaktualnych odpowiedzi. Zespół założycielski Perplexity, początkowo pracujący nad narzędziem tłumaczącym zapytania bazodanowe, w pełni skoncentrował się na budowie silnika odpowiedzi, który mógłby połączyć wyszukiwanie na żywo z syntezą LLM. Ta decyzja strategiczna ukształtowała architekturę Sonara od samego początku — algorytm zaprojektowano nie do rankingu stron pod kątem przeglądania przez ludzi, lecz do pozyskiwania i klasyfikowania fragmentów treści do syntezy maszynowej i cytowania. Przez ostatnie dwa lata Sonar rozwinął się w jeden z najbardziej zaawansowanych systemów rankingowych w ekosystemie AI, a modele Sonar Perplexity zajęły miejsca 1-4 w Search Arena Evaluation, zdecydowanie wyprzedzając konkurencję z Google i OpenAI. Algorytm przetwarza obecnie ponad 400 milionów zapytań miesięcznie, indeksując ponad 200 miliardów unikalnych URL-i i utrzymując świeżość indeksu dzięki dziesiątkom tysięcy aktualizacji na sekundę. Skala i zaawansowanie Sonara podkreślają jego znaczenie jako definiującego paradygmatu rankingowego ery wyszukiwania AI.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
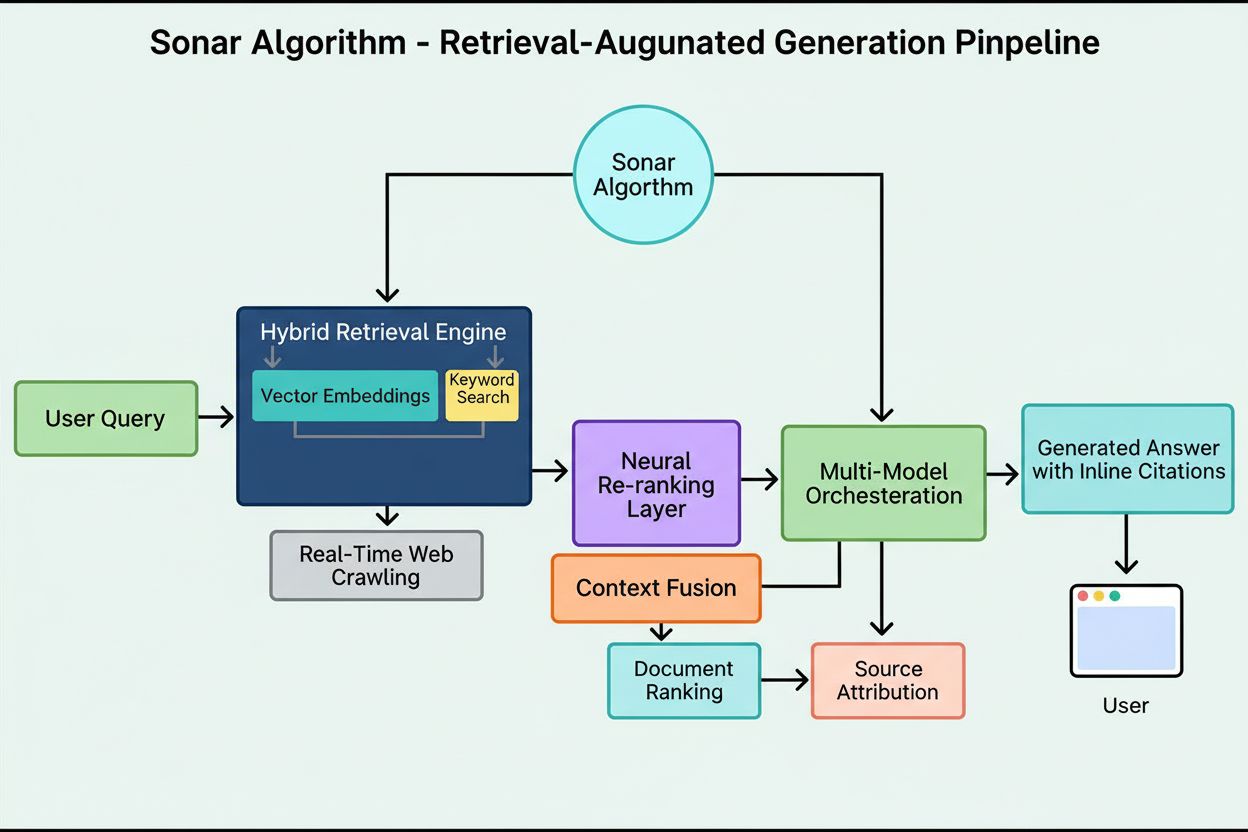
Jak działa algorytm Sonar: wieloetapowy pipeline RAG
System rankingowy Sonara działa poprzez starannie zaplanowany, pięcioetapowy pipeline retrieval-augmented generation, który przekształca zapytania użytkownika w ugruntowane, cytowane odpowiedzi. Pierwszy etap, parsowanie intencji zapytania, wykorzystuje LLM, by wyjść poza proste dopasowanie słów kluczowych i osiągnąć semantyczne zrozumienie tego, o co naprawdę pyta użytkownik — interpretując kontekst, niuanse i ukrytą intencję. Drugi etap, wyszukiwanie na żywo w sieci, wysyła przeparsowane zapytanie do rozproszonego indeksu Perplexity opartego na Vespa AI, który w czasie rzeczywistym przeszukuje sieć w poszukiwaniu odpowiednich stron i dokumentów. System łączy wyszukiwanie gęste (wektorowe z użyciem osadzeń semantycznych) i wyszukiwanie rzadkie (oparte na słowach kluczowych), scalając wyniki do ok. 50 zróżnicowanych dokumentów kandydackich. Trzeci etap, ekstrakcja i kontekstualizacja fragmentów, nie przekazuje modelowi generatywnemu pełnych tekstów stron; zamiast tego algorytmy wydobywają najbardziej istotne fragmenty, akapity lub bloki odnoszące się bezpośrednio do zapytania, agregując je w skoncentrowane okno kontekstowe. Czwarty etap, generowanie zsyntetyzowanej odpowiedzi z cytowaniami, przekazuje ten wyselekcjonowany kontekst do wybranego LLM (z rodziny Sonar Perplexity lub modeli zewnętrznych jak GPT-4 czy Claude), który generuje odpowiedź w naturalnym języku wyłącznie na podstawie pozyskanych informacji. Kluczowe jest, że cytowania w tekście łączą każde twierdzenie z dokumentami źródłowymi, zapewniając przejrzystość i możliwość weryfikacji. Piąty etap, konwersacyjna korekta, utrzymuje kontekst rozmowy przez wiele rund pytań, pozwalając na doprecyzowania i kolejne wyszukiwania. Fundamentalną zasadą pipeline’u jest „nie wolno powiedzieć niczego, czego się nie pozyskało”, co sprawia, że odpowiedzi generowane przez Sonara są ugruntowane w weryfikowalnych źródłach i znacząco ograniczają halucynacje w porównaniu z modelami opartymi wyłącznie na danych treningowych.
Tabela porównawcza: Algorytm Sonar vs. tradycyjne wyszukiwanie i konkurencyjne systemy rankingowe LLM
| Aspekt | Tradycyjne wyszukiwanie (Google) | Algorytm Sonar (Perplexity) | Ranking ChatGPT | Ranking Gemini | Ranking Claude |
|---|
| Jednostka podstawowa | Uszeregowana lista linków | Jedna zsyntetyzowana odpowiedź z cytowaniami | Wzmianki o encjach na podstawie konsensusu | Treść zgodna z E-E-A-T | Neutralne, oparte na faktach źródła |
| Fokus wyszukiwania | Słowa kluczowe, linki, sygnały ML | Hybrydowe wyszukiwanie semantyczne + słowne | Dane treningowe + przeglądanie sieci | Integracja grafu wiedzy | Filtry bezpieczeństwa konstytucyjnego |
| Priorytet aktualności | Query-deserves-freshness (QDF) | Pozyskiwanie na żywo, 37% wzrost w 48h | Niski, zależny od danych treningowych | Umiarkowany, zintegrowany z Google Search | Niski, nacisk na stabilność |
| Sygnały rankingowe | Linki zwrotne, autorytet domeny, CTR | Aktualność treści, trafność semantyczna, cytowalność, wzmocnienia autorytetu | Rozpoznanie encji, wzmianki konsensusu | E-E-A-T, zgodność konwersacyjna, dane strukturalne | Przejrzystość, weryfikowalne cytowania, neutralność |
| Mechanizm cytowań | Fragmenty URL w wynikach | Cytowania w tekście z linkami do źródeł | Implicit, często brak cytowań | Przeglądy AI z atrybucją | Jawne przypisanie źródeł |
| Różnorodność treści | Wiele wyników z różnych stron | Wybrane źródła do syntezy | Synteza z wielu źródeł | Wiele źródeł w przeglądzie | Zbalansowane, neutralne źródła |
| Personalizacja | Subtelna, głównie implicite | Jawne tryby fokusów (Web, Academic, Finance, Writing, Social) | Implicit na podstawie rozmowy | Implicit wg typu zapytania | Minimalna, nacisk na spójność |
| Obsługa PDF | Standardowe indeksowanie | 22% przewaga cytowań nad HTML | Standardowe indeksowanie | Standardowe indeksowanie | Standardowe indeksowanie |
| Wpływ schema markup | FAQ schema w featured snippets | FAQ schema podnosi cytowania o 41%, skraca czas do cytowania o 6h | Minimalny bezpośredni wpływ | Umiarkowany wpływ na graf wiedzy | Minimalny bezpośredni wpływ |
| Optymalizacja opóźnień | Milisekundy dla rankingu | Podsekundowe pozyskanie + generacja | Sekundy dla syntezy | Sekundy dla syntezy | Sekundy dla syntezy |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Architektura techniczna: hybrydowe wyszukiwanie i neuralny reranking
Techniczną podstawą algorytmu Sonar jest hybrydowy silnik wyszukiwania, łączący różne strategie, by zmaksymalizować zarówno recall, jak i precyzję. Wyszukiwanie gęste (wektorowe) wykorzystuje osadzenia semantyczne, by rozumieć koncepcyjne znaczenie zapytań i znajdować kontekstowo podobne dokumenty nawet bez dokładnych dopasowań słów kluczowych. To umożliwiają osadzenia transformerowe, które mapują zapytania i dokumenty w wielowymiarowej przestrzeni wektorowej, gdzie semantycznie podobne treści grupują się razem. Wyszukiwanie rzadkie (słowne) uzupełnia gęste, zapewniając precyzję dla rzadkich terminów, nazw produktów, wewnętrznych identyfikatorów firmowych i specyficznych encji, gdzie niepożądana jest dwuznaczność. System wykorzystuje funkcje rankingowe jak BM25 do ścisłego dopasowania tych krytycznych terminów. Obie metody są łączone i deduplikowane, by uzyskać ok. 50 zróżnicowanych dokumentów kandydackich, zapobiegając dominacji jednej domeny i zapewniając szerokie pokrycie wielu autorytatywnych źródeł. Po początkowym pozyskaniu, warstwa neuralnego rerankingu Sonara stosuje zaawansowane modele ML (np. DeBERTa-v3 cross-encoders), oceniając kandydatów na podstawie bogatego zestawu cech: trafność leksykalna, podobieństwo wektorowe, autorytet dokumentu, sygnały świeżości, zaangażowanie użytkowników i metadane. Ta wieloetapowa architektura rankingu pozwala Sonarowi stopniowo udoskonalać wyniki w ramach napiętych limitów czasowych, zapewniając, że końcowy ranking obejmuje najwyższej jakości, najbardziej trafne źródła do syntezy. Cała infrastruktura wyszukiwania bazuje na Vespa AI — rozproszonej platformie wyszukiwawczej zdolnej do indeksowania na skalę webową (200+ mld URL-i), aktualizacji w czasie rzeczywistym (dziesiątki tysięcy na sekundę) i rozumienia treści dzięki chunkowaniu dokumentów. Dzięki temu zespół Perplexity może skupić się na różnicujących komponentach — orkiestracji RAG, strojenia modeli Sonar i optymalizacji inferencji — zamiast na ponownym wynajdywaniu rozproszonego wyszukiwania.
Aktualność treści jako dominujący czynnik rankingowy
Aktualność treści to jeden z najsilniejszych sygnałów rankingowych Sonara, a badania empiryczne pokazują, że niedawno zaktualizowane strony otrzymują znacznie więcej cytowań. W kontrolowanych testach A/B prowadzonych przez 24 tygodnie na 120 URL-ach, artykuły zaktualizowane w ciągu ostatnich 48 godzin były cytowane o 37% częściej niż identyczne treści ze starszymi datami. Przewaga utrzymywała się na poziomie 14% po dwóch tygodniach, co wskazuje, że aktualność daje trwały, choć malejący z czasem efekt. Mechanizm tego priorytetu wynika z filozofii Sonara: algorytm traktuje przestarzałą treść jako wyższe ryzyko halucynacji, zakładając, że stare informacje mogły zostać zastąpione nowszymi. Infrastruktura Perplexity przetwarza dziesiątki tysięcy żądań aktualizacji indeksu na sekundę, umożliwiając sygnały świeżości w czasie rzeczywistym. Model ML przewiduje, czy URL wymaga ponownego zindeksowania i planuje aktualizacje w zależności od ważności strony i jej historii zmian, dzięki czemu wartościowe treści są odświeżane agresywniej. Nawet drobne kosmetyczne edycje resetują zegar aktualności, jeśli CMS publikuje zmienioną datę. Dla wydawców oznacza to strategiczny imperatyw: albo przejąć tryb newsroomu z cotygodniowymi lub codziennymi aktualizacjami, albo patrzeć, jak evergreen content traci widoczność. Implikacja jest fundamentalna — w erze Sonara tempo treści to nie próżność, lecz warunek przetrwania. Marki, które automatyzują mikroaktualizacje, prowadzą changelogi na żywo lub stale optymalizują treści, zyskają nieproporcjonalnie duży udział cytowań względem konkurencji polegającej na statycznych stronach.
Trafność semantyczna i struktura contentu typu answer-first
Sonar promuje trafność semantyczną ponad gęstość słów kluczowych, nagradzając przede wszystkim treści, które bezpośrednio odpowiadają na zapytania naturalnym, konwersacyjnym językiem. System wyszukiwania wykorzystuje gęste osadzenia wektorowe do dopasowywania zapytań do treści na poziomie koncepcyjnym, co oznacza, że strony używające synonimów, powiązanych terminów lub bogatego kontekstu mogą wyprzedzić nasycone słowami kluczowymi, lecz płytkie semantycznie treści. Ta zmiana z podejścia opartego na słowach kluczowych na zorientowane na znaczenie ma ogromne implikacje dla strategii contentowej. Treści skuteczne w Sonarze mają kilka cech strukturalnych: zaczynają od krótkiego, faktograficznego podsumowania, następnie przechodzą do szczegółów, używają opisowych nagłówków H2/H3 i krótkich akapitów dla łatwej ekstrakcji, zawierają jasne cytowania i linki do źródeł pierwotnych oraz widoczne daty i notki wersji sygnalizujące aktualność. Każdy akapit działa jako atomowa jednostka semantyczna, zoptymalizowana pod copy-paste i zrozumienie przez LLM. Tabele, listy punktowane i podpisane wykresy są szczególnie cenne, bo prezentują informacje w formacie łatwym do cytowania. Algorytm nagradza także oryginalną analizę i unikalne dane ponad samą agregację, ponieważ silnik syntezy Sonara szuka źródeł wnoszących nową wartość, dokumentów pierwotnych czy autorskich wniosków wyróżniających je na tle ogólnych przeglądów. Ten nacisk na bogactwo semantyczne i strukturę answer-first to fundamentalne odejście od klasycznego SEO, gdzie dominowała gęstość słów kluczowych i autorytet linków. W erze Sonara treści muszą być projektowane pod kątem maszynowej ekstrakcji i syntezy, a nie tylko ludzkiego przeglądania.
Hosting PDF jako przewaga strategiczna
Publicznie udostępniane PDF-y to istotna, często niedoceniana przewaga w rankingu Sonara, co potwierdzają testy pokazujące, że wersje PDF tej samej treści otrzymują ok. 22% więcej cytowań niż HTML. Wynika to z faktu, że crawler Sonara preferencyjnie traktuje PDF-y względem stron HTML. PDF-y nie mają banerów cookie, wymagań renderowania JS, paywalli i innych komplikacji HTML utrudniających dostęp do treści. Crawler Sonara czyta PDF-y czysto i przewidywalnie, bez niejednoznaczności parsera typowej dla złożonych struktur HTML. Wydawcy mogą strategicznie wykorzystać tę przewagę, publikując PDF-y w publicznych katalogach, używając semantycznych nazw plików odzwierciedlających temat, oraz sygnalizując PDF jako kanoniczny za pomocą tagów <link rel="alternate" type="application/pdf"> w nagłówku HTML. Tworzy to tzw. „LLM honey-trap” — zasób o wysokiej widoczności, którego skrypty śledzące konkurencji nie wykryją. Dla firm B2B, dostawców SaaS oraz organizacji badawczych ta strategia jest wyjątkowo skuteczna: publikowanie whitepaperów, raportów, case studies i dokumentacji technicznej jako PDF-ów może radykalnie zwiększyć cytowalność w Sonarze. Kluczem jest traktowanie PDF-u nie jako dodatku do pobrania, lecz kanonicznej kopii wartej optymalizacji na równi lub bardziej niż wersja HTML. Takie podejście sprawdza się szczególnie w contentach korporacyjnych, gdzie PDF-y często zawierają bardziej ustrukturyzowane i autorytatywne informacje niż strony www.
FAQ schema markup i optymalizacja danych strukturalnych
Oznaczenie JSON-LD FAQ schema znacząco zwiększa cytowalność w Sonarze, przy czym strony zawierające trzy lub więcej bloków FAQ otrzymują o 41% więcej cytowań niż strony bez schematu. Ten spektakularny wzrost wynika z preferencji Sonara dla ustrukturyzowanych, blokowych treści zgodnych z logiką jego wyszukiwania i syntezy. FAQ schema prezentuje jednostki Q&A, które algorytm może łatwo wyekstrahować, uszeregować i zacytować jako atomowe bloki semantyczne. W przeciwieństwie do klasycznego SEO, gdzie FAQ schema była tylko dodatkiem, Sonar traktuje ustrukturyzowane Q&A jako kluczowy dźwignię rankingową. Co więcej, Sonar często cytuje pytania FAQ jako anchor text, minimalizując ryzyko utraty kontekstu podczas podsumowań losowych fragmentów przez LLM. Schemat również przyspiesza czas do pierwszego cytowania o ok. sześć godzin, co sugeruje, że parser Sonara priorytetowo analizuje struktury Q&A już na wczesnych etapach rankingu. Dla wydawców strategia jest prosta: wstaw 3-5 celowanych bloków FAQ pod główną treścią, używając fraz konwersacyjnych odzwierciedlających realne zapytania użytkowników. Pytania powinny mieć długie ogony i semantycznie pokrywać się z typowymi zapytaniami Sonara. Każda odpowiedź powinna być zwięzła, faktograficzna i bezpośrednia — bez lania wody i marketingowego żargonu. Strategia ta sprawdza się szczególnie w firmach SaaS, klinikach zdrowia i usługach profesjonalnych, gdzie FAQ naturalnie odpowiadają na intencje użytkowników i potrzeby syntezy Sonara.
Czynniki rankingowe i mechanika cytowań: kompleksowe ramy
System rankingowy Sonara integruje wiele sygnałów w jednolite ramy cytowań, a badania wskazują osiem głównych czynników wpływających na selekcję źródeł i częstotliwość cytowań. Po pierwsze, trafność semantyczna do pytania dominuje w wyszukiwaniu — algorytm wybiera treści, które klarownie odpowiadają na zapytanie naturalnym językiem. Po drugie, autorytet i wiarygodność mają duże znaczenie — partnerstwa wydawnicze Perplexity i algorytmiczne wzmocnienia premiują uznane media, instytucje naukowe i ekspertów. Po trzecie, aktualność ma wyjątkową wagę, o czym już mowa — świeże aktualizacje dają wzrost cytowań o 37%. Po czwarte, różnorodność i pokrycie — Sonar promuje wiele źródeł wysokiej jakości zamiast pojedynczych odpowiedzi, ograniczając ryzyko halucynacji przez krzyżową weryfikację. Po piąte, tryb i zakres decydują, które indeksy Sonar przeszukuje — tryby fokusów typu Academic, Finance, Writing czy Social zawężają typy źródeł, a selektory źródeł (Web, Org Files, Web + Org Files, None) regulują, czy wyszukiwanie obejmuje otwartą sieć, dokumenty wewnętrzne czy oba naraz. Po szóste, cytowalność i dostępność — jeśli PerplexityBot może zindeksować treść, łatwiej ją zacytować, więc zgodność z robots.txt i szybkość ładowania są kluczowe. Po siódme, niestandardowe filtry źródeł przez API pozwalają wdrożeniom enterprise ograniczać lub premiować wybrane domeny, zmieniając ranking w obrębie białych list. Po ósme, kontekst rozmowy wpływa