
Dane strukturalne
Dane strukturalne to standaryzowany znacznik, który pomaga wyszukiwarkom zrozumieć zawartość strony internetowej. Dowiedz się, jak JSON-LD, schema.org i microda...
9 min czytania

Oznaczenie schematów zaprojektowane specjalnie, aby pomóc systemom AI dokładnie rozumieć i cytować treści. Dane strukturalne wykorzystują ustandaryzowane formaty, takie jak JSON-LD, aby dostarczyć jednoznaczny kontekst na temat zawartości strony, umożliwiając dużym modelom językowym bardziej niezawodne analizowanie informacji i pewniejsze cytowanie źródeł.
Oznaczenie schematów zaprojektowane specjalnie, aby pomóc systemom AI dokładnie rozumieć i cytować treści. Dane strukturalne wykorzystują ustandaryzowane formaty, takie jak JSON-LD, aby dostarczyć jednoznaczny kontekst na temat zawartości strony, umożliwiając dużym modelom językowym bardziej niezawodne analizowanie informacji i pewniejsze cytowanie źródeł.
Dane strukturalne dla AI to uporządkowane, maszynowo czytelne informacje sformatowane według ustandaryzowanych schematów, które umożliwiają systemom sztucznej inteligencji precyzyjne rozumienie, interpretację i wykorzystanie treści. W przeciwieństwie do tekstu nieustrukturyzowanego, który wymaga złożonego przetwarzania języka naturalnego w celu zrozumienia znaczenia, dane strukturalne dostarczają jednoznacznego kontekstu na temat tego, co reprezentują informacje. Ta przejrzystość jest kluczowa, ponieważ systemy AI—zwłaszcza duże modele językowe i wyszukiwarki—przetwarzają codziennie miliardy punktów danych. Gdy treści są strukturyzowane z użyciem standardów takich jak schema.org, JSON-LD czy microdata, AI może natychmiast rozpoznać byty, relacje i atrybuty bez niejednoznaczności. To podejście strukturalne zapewnia 300% większą dokładność rozumienia AI w porównaniu do alternatyw nieustrukturyzowanych. Dla organizacji dążących do widoczności w AI Overviews i innych wynikach generowanych przez AI, dane strukturalne stały się niezbędną infrastrukturą. Przekształcają surowe treści w inteligencję, którą systemy AI mogą pewnie cytować, referować i włączać do swoich odpowiedzi, fundamentalnie zmieniając sposób, w jaki treści cyfrowe stają się odkrywalne w świecie napędzanym przez AI.

Systemy AI przetwarzają dane strukturalne za pomocą zaawansowanego procesu, który zamienia oznaczone treści w użyteczną inteligencję. Kiedy AI napotyka prawidłowo sformatowane dane strukturalne, może natychmiast wyodrębnić kluczowe informacje bez nakładów obliczeniowych wymaganych przez interpretację języka naturalnego. Mechanizm techniczny obejmuje następujące kroki:
Ten proces umożliwia AI osiągnięcie ponad 30% większej widoczności w AI Overviews dla prawidłowo oznaczonych treści. Podejście strukturalne ogranicza ryzyko tzw. halucynacji, kotwicząc odpowiedzi AI w jednoznacznych, weryfikowalnych danych zamiast w probabilistycznym generowaniu tekstu. Organizacje wdrażające kompleksowe strategie danych strukturalnych obserwują wymierną poprawę w zakresie odkrywalności, rozumienia i promocji swoich treści przez systemy AI na różnych platformach i aplikacjach.
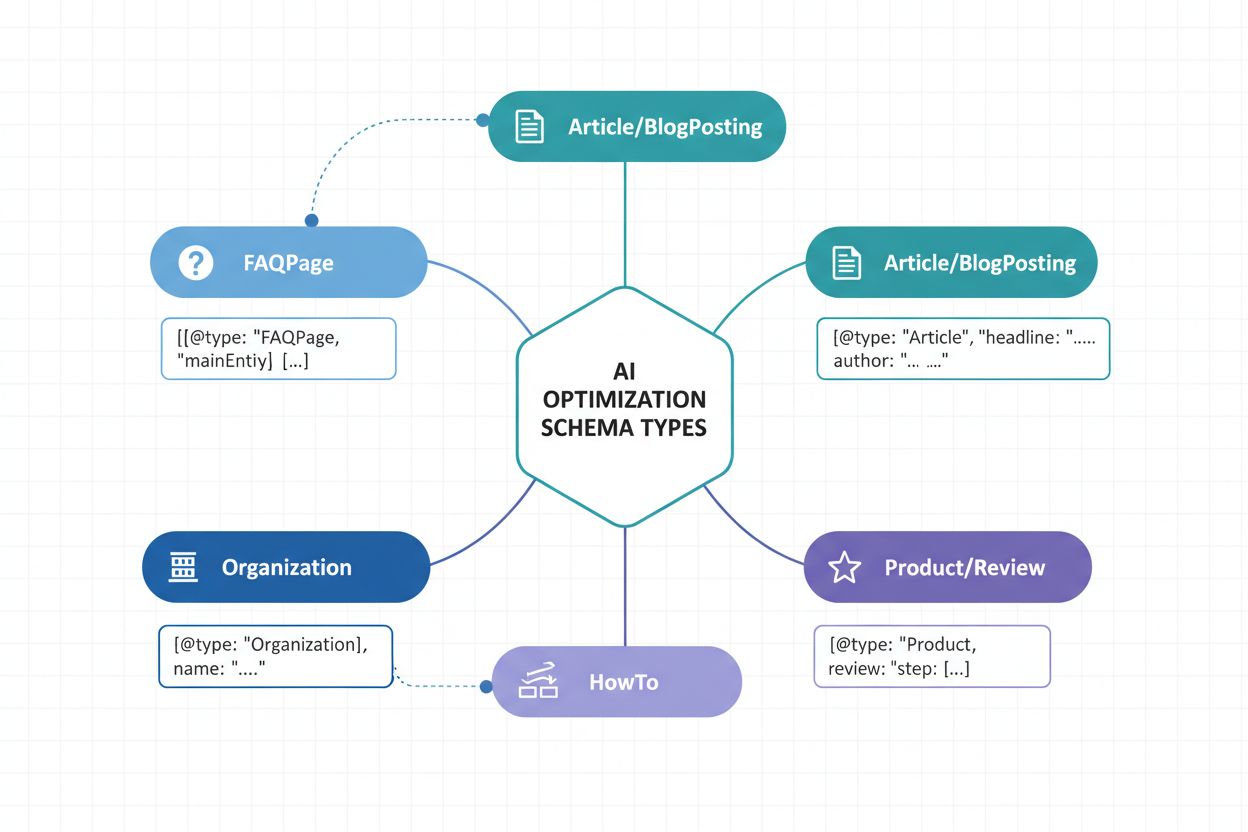
Wdrożenie odpowiednich typów schematów jest podstawą strategii widoczności w AI. Różne typy treści wymagają specyficznych oznaczeń strukturalnych, by przekazać swoją naturę i wartość systemom AI. Oto najważniejsze schematy maksymalizujące rozpoznawalność przez AI:
Article Schema – Oznacza artykuły newsowe, posty blogowe i treści długie z nagłówkiem, autorem, datą publikacji i treścią. Kluczowy dla AI przy identyfikacji autorytatywnych źródeł i budowaniu wiarygodności publikacji.
Organization Schema – Definiuje tożsamość firmy: nazwę, logo, dane kontaktowe i profile społecznościowe. Umożliwia AI poprawną identyfikację i przypisanie treści organizacyjnych.
Product Schema – Strukturyzuje informacje produktowe: nazwa, opis, cena, dostępność i recenzje. Niezbędny dla widoczności e-commerce w asystentach zakupowych AI i systemach rekomendacji.
LocalBusiness Schema – Oznacza lokalizację firmy, godziny otwarcia, kontakt i usługi. Krytyczny dla lokalnych zapytań AI i AI Overviews opartych na lokalizacji.
BreadcrumbList Schema – Definiuje hierarchię nawigacyjną strony, pomagając AI zrozumieć strukturę treści i relacje między stronami w architekturze informacji.
FAQPage Schema – Strukturyzuje często zadawane pytania wraz z odpowiedziami, umożliwiając AI bezpośrednią ekstrakcję i cytowanie konkretnych Q&A w odpowiedziach.
NewsArticle i BlogPosting Schemas – Wyspecjalizowane typy artykułów sygnalizujące kategorię treści systemom AI, poprawiające trafność kategoryzacji.
Event Schema – Oznacza szczegóły wydarzenia, takie jak data, lokalizacja, opis i informacje o rejestracji—kluczowy dla odkrywania wydarzeń przez AI i integracji z kalendarzami.
Obecnie 45 milionów domen korzysta z oznaczeń schema.org, co stanowi 12,4% wszystkich domen na świecie. Organizacje wdrażające wiele typów schematów jednocześnie uzyskują skumulowane korzyści widoczności, ponieważ AI otrzymuje bogatszy kontekst ekosystemu treści.
Skuteczne wdrożenie danych strukturalnych wymaga strategicznego planowania i technicznej precyzji. Organizacje powinny stosować sprawdzone praktyki, aby zmaksymalizować widoczność w AI i zapewnić dokładność danych:
Oto praktyczny przykład JSON-LD dla artykułu:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Structured Data for AI: Strategic Implementation Guide",
"author": {
"@type": "Person",
"name": "Content Author"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Full article text here...",
"publisher": {
"@type": "Organization",
"name": "Your Organization",
"logo": "https://example.com/logo.png"
}
}
Prawidłowe wdrożenie daje 35% wzrost CTR z rich results w tradycyjnym wyszukiwaniu, a dodatkowe korzyści pojawiają się wraz z rozwojem AI Overviews jako głównego kanału odkrywania. Organizacje monitorujące swoje dane strukturalne za pomocą rozwiązań takich jak AmICited.com zyskują przewagę, identyfikując, które typy treści i wdrożenia schematów dają największą widoczność w AI.
Zarówno dane strukturalne, jak i llms.txt służą odkrywalności przez AI, ale działają w zupełnie inny sposób. Dane strukturalne wykorzystują ustandaryzowane schematy (schema.org, JSON-LD) osadzone w HTML do oznaczania konkretnych elementów treści z jednoznacznym znaczeniem semantycznym. Podejście to integruje się bezpośrednio ze stronami, czyniąc informacje natychmiast dostępne zarówno dla wyszukiwarek, jak i systemów AI podczas indeksowania. Umożliwia granularne oznaczanie artykułów, produktów, wydarzeń i organizacji, pozwalając AI precyzyjnie rozumieć relacje i atrybuty.
llms.txt natomiast to plik tekstowy umieszczany w katalogu głównym strony, zawierający instrukcje i wytyczne dla dużych modeli językowych. Działa jako manifest komunikujący preferencje dotyczące interakcji AI z treścią i zasad cytowania. Choć llms.txt określa ogólne zasady korzystania z treści i preferencje dotyczące atrybucji, nie oferuje precyzji semantycznej danych strukturalnych. Dane strukturalne odpowiadają na pytanie „co to za treść?” jednoznaczną odpowiedzią maszynową, podczas gdy llms.txt odpowiada „jak używać tej treści?” jako wytyczna.
Najskuteczniejszą strategią jest połączenie obu podejść: dane strukturalne zapewniają, że systemy AI dokładnie rozumieją i mogą cytować treść, a llms.txt ustanawia jasne zasady użycia i wymagania dotyczące atrybucji. Organizacje wdrażające oba rozwiązania są o 36% bardziej widoczne w podsumowaniach generowanych przez AI niż te, które nie stosują żadnego. Dane strukturalne to fundament zrozumienia przez AI, a llms.txt to ramy zarządzania zapewniające prawidłową atrybucję i zgodność wykorzystania.
Pomiar skuteczności danych strukturalnych wymaga monitorowania konkretnych metryk pokazujących, jak systemy AI odkrywają, rozumieją i cytują Twoje treści. Organizacje powinny śledzić kluczowe wskaźniki wydajności:
AmICited.com dostarcza specjalistyczne monitorowanie wydajności cytowań AI, umożliwiając organizacjom śledzenie, jak ich inwestycje w dane strukturalne przekładają się na rzeczywistą widoczność i atrybucję w AI. Platforma pokazuje, które treści są cytowane przez AI, które zapytania je wywołują oraz jak częstotliwość cytowań wypada na tle konkurencji. Podejście oparte na danych zamienia wdrożenia danych strukturalnych ze „sprawdzonej praktyki” w wymierny efekt biznesowy.
Organizacje wdrażające kompleksowe strategie danych strukturalnych raportują, że 93% zapytań AI jest obsługiwanych bez kliknięć, co czyni widoczność cytowań kluczową dla generowania ruchu. Pomiar efektywności cytowań zapewnia, że inwestycje w dane strukturalne przynoszą wymierne zwroty poprzez poprawę odkrywalności i atrybucji marki w AI.
Skuteczne wdrożenie danych strukturalnych to proces etapowy, który stopniowo zwiększa możliwości i przynosi wymierne efekty na każdym etapie. Organizacje powinny zaplanować harmonogram wdrożenia według poniższych faz:
Faza 1: Fundamenty (miesiące 1-2)
Faza 2: Ekspansja (miesiące 3-4)
Faza 3: Optymalizacja (miesiące 5-6)
Faza 4: Integracja strategiczna (miesiące 7+)
Harmonogram ten pozwala organizacjom osiągnąć znaczącą poprawę widoczności w AI w ciągu 2-3 miesięcy i budować w kierunku kompleksowej, skalowalnej infrastruktury danych strukturalnych. Wczesne wdrożenie daje przewagę konkurencyjną w momencie, gdy AI Overviews stają się głównym kanałem odkrywania treści.
Dane strukturalne przekształciły się z opcjonalnego ulepszenia SEO w niezbędną infrastrukturę strategiczną w cyfrowym krajobrazie napędzanym przez AI. W miarę jak systemy AI coraz częściej pośredniczą w odkrywaniu informacji przez użytkowników, organizacje bez kompleksowych oznaczeń danych strukturalnych napotykają systemowe bariery widoczności. Ta zmiana odzwierciedla fundamentalną ewolucję przepływu informacji: tradycyjne wyszukiwanie wymagało kliknięć na strony, natomiast AI Overviews odpowiadają bezpośrednio na pytania, czyniąc widoczność cytowań nowym polem rywalizacji.
Organizacje wdrażające dane strukturalne strategicznie pozycjonują się do długofalowego sukcesu na wielu platformach AI i w nowych kanałach odkrywania. Inwestycja w infrastrukturę przynosi korzyści wykraczające poza natychmiastową widoczność w AI—dane strukturalne usprawniają zarządzanie treściami, umożliwiają lepszą personalizację, wspierają optymalizację wyszukiwania głosowego i tworzą zasoby cenne dla przyszłych zastosowań AI. Wczesne wdrożenie kompleksowych fundamentów daje przewagę, która kumuluje się w miarę, jak systemy AI coraz bardziej preferują dobrze oznaczone treści.
Nie można przecenić przewagi wczesnych wdrożeń. W miarę jak coraz więcej organizacji dostrzega wagę danych strukturalnych, wdrożenie staje się niezbędne dla widoczności. Organizacje budujące solidną infrastrukturę danych strukturalnych już dziś będą dominować w wynikach generowanych przez AI, gdy te kanały dojrzeją. Natomiast opóźnianie wdrożeń będzie coraz bardziej utrudniało osiągnięcie widoczności, gdy systemy AI nauczą się preferować kompleksowo oznaczone treści. Dane strukturalne to nie tylko wdrożenie techniczne, lecz fundamentalny wybór strategiczny, warunkujący pozostanie odkrywalnym i cytowanym w ekosystemie informacyjnym pośredniczonym przez AI.
Dane strukturalne nie wpływają bezpośrednio na pozycje Google, ale znacząco poprawiają wygląd wyników wyszukiwania poprzez rich snippets, co zwiększa współczynnik kliknięć nawet o 35%. Dla systemów AI dane strukturalne mają bardziej bezpośredni wpływ na to, czy Twoje treści zostaną zacytowane w odpowiedziach generowanych przez AI.
Tak, systemy AI przetwarzają dane strukturalne zarówno podczas treningu, jak i w zapytaniach na żywo. Chociaż OpenAI nie opublikowało oficjalnych informacji, dowody wskazują, że GPTBot i inne crawlery AI analizują oznaczenia JSON-LD. Microsoft oficjalnie potwierdził, że systemy AI Binga wykorzystują schema markup, aby lepiej rozumieć treści.
Zalecanym formatem jest JSON-LD, ponieważ oddziela schemat od treści HTML, co ułatwia wdrożenie i utrzymanie na dużą skalę. Google wyraźnie rekomenduje JSON-LD i jest on mniej podatny na błędy implementacyjne niż Microdata czy RDFa.
Rich snippets mogą pojawić się w ciągu 1-4 tygodni od wdrożenia. Poprawa CTR jest często zauważalna już po 2 tygodniach. W przypadku ulepszeń cytowań AI, na efekty pracy podstawowej należy czekać 4-8 tygodni, a korzyści z budowania autorytetu kumulują się przez 3-6 miesięcy.
Najpierw skup się na schema markup—jest sprawdzony i szeroko wspierany. llms.txt to wciąż powstający standard z ograniczoną adopcją przez crawlery AI. Jeśli jesteś firmą skupioną na deweloperach z dużą ilością dokumentacji, minimalny nakład pracy na stworzenie llms.txt może być opłacalny dla zabezpieczenia na przyszłość.
Zacznij od Organization schema na stronie głównej (z właściwościami sameAs), następnie Article schema na kluczowych stronach z treściami. Następny powinien być FAQPage schema—jest najbardziej przydatny do ekstrakcji przez AI. Potem dodaj HowTo schema do poradników i SoftwareApplication schema do stron produktów.
Tylko nieprawidłowo wdrożone oznaczenia mogą zaszkodzić efektywności. Wytyczne Google są jasne: używaj odpowiednich typów schematów odpowiadających widocznej treści, dbaj o poprawność cen i dat oraz nie oznaczaj treści niewidocznych dla użytkowników. Zawsze weryfikuj wdrożenie narzędziem Google Rich Results Test przed publikacją.
Dane strukturalne dostarczają jednoznacznego kontekstu, który pomaga systemom AI zrozumieć, co reprezentują informacje—byty, relacje, atrybuty. Ta przejrzystość umożliwia AI pewne wydobycie i cytowanie Twojej treści. LLM-y oparte na grafach wiedzy osiągają o 300% większą dokładność w porównaniu do tych, które polegają wyłącznie na nieustrukturyzowanych danych.
Śledź, jak systemy AI cytują Twoje treści w ChatGPT, Perplexity, Google AI Overviews i innych platformach. Uzyskaj podgląd swojej obecności w AI w czasie rzeczywistym.
Dane strukturalne to standaryzowany znacznik, który pomaga wyszukiwarkom zrozumieć zawartość strony internetowej. Dowiedz się, jak JSON-LD, schema.org i microda...
Dowiedz się, jak roboty AI przetwarzają dane strukturalne. Odkryj, dlaczego sposób implementacji JSON-LD ma znaczenie dla widoczności w ChatGPT, Perplexity, Cla...

Dowiedz się, jak struktury treści porównawczej optymalizują informacje dla systemów AI. Odkryj, dlaczego platformy AI preferują tabele porównawcze, macierze i f...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.