Dane strukturalne
Dane strukturalne to standaryzowany znacznik, który pomaga wyszukiwarkom zrozumieć zawartość strony internetowej. Dowiedz się, jak JSON-LD, schema.org i microda...
9 min czytania
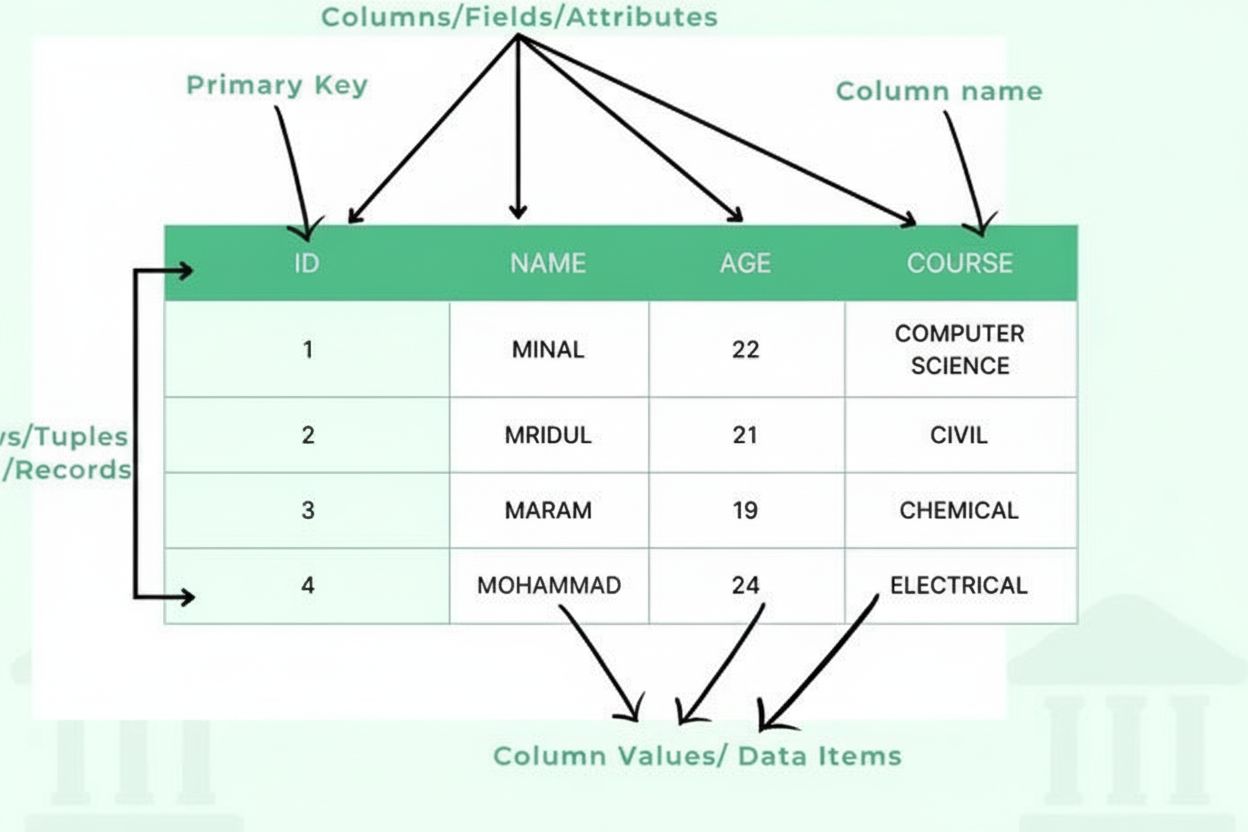
Tabela to metoda strukturalnej organizacji danych, która układa informacje w dwuwymiarowej siatce składającej się z poziomych wierszy i pionowych kolumn, umożliwiając efektywne przechowywanie, wyszukiwanie i analizę danych. Tabele stanowią podstawowy element baz danych relacyjnych, arkuszy kalkulacyjnych oraz systemów prezentacji danych, pozwalając użytkownikom szybko lokalizować i porównywać powiązane informacje w wielu wymiarach.
Tabela to metoda strukturalnej organizacji danych, która układa informacje w dwuwymiarowej siatce składającej się z poziomych wierszy i pionowych kolumn, umożliwiając efektywne przechowywanie, wyszukiwanie i analizę danych. Tabele stanowią podstawowy element baz danych relacyjnych, arkuszy kalkulacyjnych oraz systemów prezentacji danych, pozwalając użytkownikom szybko lokalizować i porównywać powiązane informacje w wielu wymiarach.
Tabela to podstawowa struktura danych, która organizuje informacje w dwuwymiarowej siatce składającej się z poziomych wierszy i pionowych kolumn. W najprostszej formie tabela reprezentuje zbiór powiązanych danych ułożonych w uporządkowany sposób, gdzie każde przecięcie wiersza i kolumny zawiera pojedynczy element danych lub komórkę. Tabele są fundamentem baz danych relacyjnych, arkuszy kalkulacyjnych, hurtowni danych oraz praktycznie każdego systemu wymagającego uporządkowanego przechowywania i wyszukiwania informacji. Siła tabel polega na umożliwieniu szybkiego przeglądania wzrokowego, logicznego porównywania danych w wielu wymiarach i programowego dostępu do konkretnych informacji poprzez standardowe języki zapytań. Niezależnie od tego, czy są używane w analizie biznesowej, badaniach naukowych, czy platformach monitorowania AI, tabele zapewniają powszechnie rozumiany format prezentowania danych strukturalnych, który może być łatwo interpretowany zarówno przez ludzi, jak i maszyny.
Koncepcja organizowania informacji w wierszach i kolumnach wyprzedza współczesną informatykę o wiele wieków. Starożytne cywilizacje używały układów tabelarycznych do zapisywania inwentarzy, transakcji finansowych i obserwacji astronomicznych. Jednak formalizacja struktur tabelarycznych w informatyce pojawiła się wraz z rozwojem teorii baz danych relacyjnych przez Edgara F. Codda w 1970 roku, co zrewolucjonizowało sposób przechowywania i wyszukiwania danych. Model relacyjny ustalił, że dane powinny być organizowane w tabele o jasno określonych relacjach, fundamentalnie zmieniając zasady projektowania baz danych. W latach 80. i 90. arkusze kalkulacyjne, takie jak Lotus 1-2-3 i Microsoft Excel, zdemokratyzowały korzystanie z tabel, czyniąc organizację danych tabelarycznych dostępną dla użytkowników nietechnicznych. Obecnie około 97% organizacji wykorzystuje arkusze kalkulacyjne do zarządzania i analizy danych, co dowodzi trwałego znaczenia organizacji danych opartej na tabelach. Ewolucja trwa nadal wraz z rozwojem nowoczesnych baz kolumnowych, systemów NoSQL i jezior danych, które kwestionują tradycyjne podejścia zorientowane na wiersze, zachowując jednak podstawowe struktury tabelaryczne dla organizowania informacji.
Tabela składa się z kilku podstawowych elementów strukturalnych, które współpracują ze sobą, tworząc uporządkowaną ramę danych. Kolumny (zwane także polami lub atrybutami) przebiegają pionowo i reprezentują kategorie informacji, takie jak „Imię klienta”, „Adres e-mail” czy „Data zakupu”. Każda kolumna ma określony typ danych, który definiuje, jaki rodzaj informacji może zawierać – liczby całkowite, tekst, daty, wartości dziesiętne lub bardziej złożone struktury. Wiersze (zwane również rekordami lub krotkami) przebiegają poziomo i reprezentują poszczególne wpisy lub encje, a każdy wiersz zawiera jeden kompletny rekord. Przecięcie wiersza i kolumny tworzy komórkę lub element danych, który przechowuje pojedynczą wartość. Nagłówki kolumn identyfikują każdą kolumnę i pojawiają się na górze tabeli, nadając kontekst danym poniżej. Klucze główne to specjalne kolumny jednoznacznie identyfikujące każdy wiersz, zapobiegając powielaniu rekordów. Klucze obce ustanawiają relacje między tabelami poprzez odwołania do kluczy głównych w innych tabelach. Ta hierarchiczna organizacja umożliwia bazom danych zachowanie integralności danych, zapobieganie redundancji oraz obsługę złożonych zapytań pobierających informacje na podstawie wielu kryteriów.
| Aspekt | Tabele zorientowane na wiersze | Tabele zorientowane na kolumny | Podejścia hybrydowe |
|---|---|---|---|
| Metoda przechowywania | Dane przechowywane i odczytywane według kompletnych rekordów | Dane przechowywane i odczytywane według poszczególnych kolumn | Łączy zalety obu podejść |
| Wydajność zapytań | Optymalizacja pod zapytania transakcyjne pobierające całe rekordy | Optymalizacja pod zapytania analityczne na wybranych kolumnach | Zrównoważona wydajność dla zróżnicowanych obciążeń |
| Zastosowania | OLTP (przetwarzanie transakcyjne online), operacje biznesowe | OLAP (analityka online), hurtownie danych | Analityka w czasie rzeczywistym, operacyjna inteligencja |
| Przykłady baz danych | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Efektywność kompresji | Niższa kompresja ze względu na różnorodność danych | Wyższa kompresja dla podobnych wartości w kolumnach | Optymalna kompresja dla konkretnych wzorców |
| Wydajność zapisu | Szybki zapis całych rekordów | Wolniejszy zapis wymagający aktualizacji kolumn | Zrównoważona wydajność zapisu |
| Skalowalność | Dobra skalowalność dla liczby transakcji | Dobra skalowalność dla wolumenu danych i złożoności zapytań | Skalowalność dla obu wymiarów |
W relacyjnych systemach zarządzania bazą danych (RDBMS) tabele są implementowane jako uporządkowane zbiory wierszy, z których każdy odpowiada zdefiniowanemu schematowi. Schemat określa strukturę tabeli, definiując nazwy kolumn, typy danych, ograniczenia i relacje. Podczas wstawiania danych do tabeli system zarządzania bazą danych sprawdza, czy każda wartość odpowiada typowi danych kolumny i spełnia zdefiniowane ograniczenia. Na przykład kolumna typu INTEGER nie przyjmie wartości tekstowych, a kolumna oznaczona jako NOT NULL nie zaakceptuje pustych wpisów. Indeksy tworzone na często wyszukiwanych kolumnach przyspieszają pobieranie danych, działając jako uporządkowane odnośniki pozwalające na szybkie lokalizowanie rekordów bez przeszukiwania całej tabeli. Normalizacja to zasada projektowania polegająca na organizowaniu tabel w taki sposób, by minimalizować redundancję i zwiększać integralność danych poprzez podział informacji na powiązane tabele połączone kluczami. Nowoczesne bazy wspierają transakcje, które zapewniają, że wiele operacji na tabelach zakończy się powodzeniem lub porażką jako całość, utrzymując spójność nawet w przypadku awarii systemu. Optymalizator zapytań analizuje zapytania SQL i wybiera najefektywniejszy sposób dostępu do danych w tabeli, uwzględniając dostępne indeksy oraz statystyki tabeli.
Tabele są podstawowym mechanizmem prezentacji danych strukturalnych użytkownikom zarówno w formie cyfrowej, jak i drukowanej. W aplikacjach analityki biznesowej i business intelligence tabele prezentują zagregowane metryki, wskaźniki wydajności oraz szczegółowe zapisy transakcji, umożliwiając decydentom szybkie zrozumienie złożonych zbiorów danych. Badania wskazują, że 83% profesjonalistów biznesowych polega na tabelach jako głównym narzędziu analizy informacji, gdyż pozwalają one na precyzyjne porównywanie wartości i rozpoznawanie wzorców. Tabele HTML na stronach internetowych wykorzystują semantyczne znaczniki <table>, <tr> (wiersz), <td> (dane), <th> (nagłówek) do strukturyzowania danych zarówno dla prezentacji wizualnej, jak i interpretacji przez programy. Arkusze kalkulacyjne jak Microsoft Excel, Google Sheets czy LibreOffice Calc rozszerzają funkcjonalności tabel o formuły, formatowanie warunkowe i tabele przestawne, pozwalając użytkownikom na dynamiczne obliczenia i reorganizację danych. Najlepsze praktyki wizualizacji danych zalecają stosowanie tabel, gdy istotne są dokładne wartości, porównania wielu atrybutów pojedynczych rekordów lub gdy użytkownicy muszą wyszukiwać i przeliczać dane. W3C Web Accessibility Initiative podkreśla, że właściwie zbudowane tabele z przejrzystymi nagłówkami i odpowiednim oznaczeniem są kluczowe dla dostępności danych dla osób z niepełnosprawnościami, w szczególności korzystających z czytników ekranu.
W kontekście platform monitorujących AI, takich jak AmICited, tabele odgrywają kluczową rolę w organizowaniu i prezentowaniu danych o tym, jak treści pojawiają się w różnych systemach sztucznej inteligencji. Tabele monitorujące śledzą metryki takie jak częstotliwość cytowań, daty wystąpień, źródła platform AI (ChatGPT, Perplexity, Google AI Overviews, Claude) i informacje kontekstowe dotyczące tego, w jaki sposób domeny oraz adresy URL są referowane. Dzięki tym tabelom organizacje mogą zrozumieć widoczność marki w odpowiedziach generowanych przez AI oraz zidentyfikować trendy cytowań ich treści przez różne systemy. Strukturalny charakter tabel monitorujących pozwala na filtrowanie, sortowanie i agregowanie danych o cytowaniach, co umożliwia odpowiedzi na pytania typu „Które z naszych adresów URL najczęściej pojawiają się w odpowiedziach Perplexity?” lub „Jak zmieniał się wskaźnik cytowań w ostatnim miesiącu?”. Tabele danych w systemach monitorujących ułatwiają też porównania w wielu wymiarach – np. zestawianie wzorców cytowań między różnymi platformami AI, analizę wzrostu cytowań w czasie czy identyfikację typów treści najczęściej referowanych przez AI. Możliwość eksportu danych monitorujących z tabel do raportów, dashboardów i dalszych narzędzi analitycznych sprawia, że tabele są niezbędne dla organizacji chcących zrozumieć i optymalizować swoją obecność w treściach generowanych przez AI.
Efektywne projektowanie tabel wymaga starannego przemyślenia struktury, konwencji nazewniczych oraz zasad organizacji danych. Nazywanie kolumn powinno być przejrzyste i opisowe, dokładnie oddające zawartość danych, unikając skrótów mogących wprowadzać w błąd użytkowników lub programistów. Dobór typów danych jest kluczowy – odpowiedni wybór zapobiega wprowadzaniu nieprawidłowych danych i umożliwia prawidłowe sortowanie oraz porównania. Definicja klucza głównego zapewnia jednoznaczną identyfikację każdego wiersza, co jest niezbędne dla integralności danych i relacji z innymi tabelami. Normalizacja ogranicza redundancję poprzez organizowanie informacji w powiązane tabele zamiast powielania danych w wielu miejscach. Strategia indeksowania powinna równoważyć wydajność zapytań z narzutem na aktualizację indeksów podczas modyfikacji danych. Dokumentacja struktury tabeli, obejmująca definicje kolumn, typy danych, ograniczenia i relacje, jest niezbędna dla długoterminowej utrzymywalności. Kontrola dostępu powinna być wdrożona, by wrażliwe dane w tabelach były chronione przed nieautoryzowanym dostępem. Optymalizacja wydajności polega na monitorowaniu czasów wykonywania zapytań i dostosowywaniu struktury tabel, indeksów lub samych zapytań w celu zwiększenia efektywności. Procedury backupu i odzyskiwania muszą być ustalone, by chronić dane tabel przed utratą lub uszkodzeniem.
Przyszłość organizacji danych opartych na tabelach ewoluuje, by sprostać coraz bardziej złożonym wymaganiom przy zachowaniu fundamentalnych zasad skuteczności tabel. Formaty przechowywania kolumnowego takie jak Apache Parquet i ORC stają się standardem w środowiskach Big Data, optymalizując tabele pod kątem analityki przy zachowaniu struktury tabelarycznej. Dane semistrukturalne w formatach JSON i XML coraz częściej są przechowywane w kolumnach tabel, pozwalając tabelom łączyć dane strukturalne i elastyczne. Integracja uczenia maszynowego umożliwia bazom danych automatyczną optymalizację struktur tabel i wykonywania zapytań w oparciu o wzorce użycia. Platformy analityki czasu rzeczywistego rozbudowują tabele o obsługę danych strumieniowych i ciągłych aktualizacji, wykraczając poza tradycyjne operacje wsadowe. Bazy danych natywne dla chmury przeprojektowują implementacje tabel, by wykorzystywać rozproszoną moc obliczeniową i skalować się na wiele serwerów i regionów geograficznych. Ramowe systemy zarządzania danymi przykładają coraz większą wagę do metadanych tabel, śledzenia pochodzenia danych i metryk jakości dla zapewnienia wiarygodności. Pojawienie się platform danych wspieranych przez AI tworzy nowe możliwości wykorzystania tabel jako uporządkowanych źródeł do trenowania modeli uczenia maszynowego, a jednocześnie rodzi pytania o projektowanie tabel pod kątem wysokiej jakości danych treningowych. W miarę jak organizacje generują coraz więcej danych, tabele pozostają podstawową strukturą do organizowania, wyszukiwania i analizy informacji, a innowacje skupiają się na poprawie wydajności, skalowalności i integracji z nowoczesnymi technologiami danych.
Wiersz to poziomy układ danych reprezentujący pojedynczy rekord lub encję, podczas gdy kolumna to pionowy układ reprezentujący określony atrybut lub pole wspólne dla wszystkich rekordów. W tabeli bazy danych każdy wiersz zawiera pełne informacje o jednej encji (np. kliencie), a każda kolumna zawiera jeden typ informacji (np. imię klienta lub adres e-mail). Wspólnie wiersze i kolumny tworzą dwuwymiarową strukturę definiującą tabelę.
Tabele stanowią podstawową strukturę organizacyjną w bazach danych relacyjnych, umożliwiając efektywne przechowywanie, wyszukiwanie i przetwarzanie danych. Pozwalają bazom danych zachować integralność danych dzięki zdefiniowanym schematom, wspierają złożone zapytania w wielu wymiarach oraz ułatwiają relacje między różnymi encjami danych poprzez klucze główne i obce. Dzięki tabelom można zorganizować miliony rekordów w sposób zarówno wydajny obliczeniowo, jak i logicznie przejrzysty dla działalności biznesowej.
Tabela składa się z kilku kluczowych elementów: kolumn (pól/atrybutów) definiujących typy i kategorie danych, wierszy (rekordów/krotek) zawierających pojedyncze wpisy, nagłówków identyfikujących każdą kolumnę, elementów danych (komórek) przechowujących rzeczywiste wartości, kluczy głównych jednoznacznie identyfikujących każdy wiersz oraz opcjonalnych kluczy obcych ustanawiających relacje z innymi tabelami. Każdy z tych elementów odgrywa istotną rolę w utrzymaniu organizacji i integralności danych.
W platformach monitorujących AI, takich jak AmICited, tabele są kluczowe dla organizowania i prezentowania danych o wystąpieniach modeli AI, cytowaniach i wzmiankach o markach w różnych systemach sztucznej inteligencji. Tabele pozwalają systemom monitorującym wyświetlać uporządkowane dane o tym, kiedy i gdzie treści pojawiają się w odpowiedziach AI, ułatwiając śledzenie metryk, porównywanie wyników między platformami oraz identyfikowanie trendów dotyczących tego, jak systemy AI cytują lub referują określone domeny i adresy URL.
Bazy danych zorientowane na wiersze (jak tradycyjne bazy relacyjne) przechowują i uzyskują dostęp do danych poprzez kompletne rekordy, co jest wydajne przy operacjach, gdy potrzebne są wszystkie informacje o jednej encji. Bazy zorientowane na kolumny przechowują dane kolumnami, dzięki czemu szybciej realizują zapytania analityczne wymagające konkretnych atrybutów wielu rekordów. Wybór między tymi podejściami zależy od tego, czy głównym zastosowaniem są operacje transakcyjne, czy analityczne.
Dostępne tabele wymagają poprawnego oznaczania HTML z użyciem semantycznych elementów takich jak `
Kolumny tabeli mogą przechowywać różne typy danych, w tym liczby całkowite, liczby zmiennoprzecinkowe, ciągi znaków/teksty, daty i godziny, wartości logiczne (boolean) oraz coraz częściej typy złożone, takie jak JSON czy XML. Każda kolumna ma zdefiniowany typ danych, który ogranicza możliwe wartości, zapewniając spójność danych i umożliwiając prawidłowe sortowanie oraz porównywanie. Niektóre bazy danych obsługują też typy specjalistyczne, takie jak dane geograficzne, tablice czy typy zdefiniowane przez użytkownika.
Zacznij śledzić, jak chatboty AI wspominają Twoją markę w ChatGPT, Perplexity i innych platformach. Uzyskaj praktyczne spostrzeżenia, aby poprawić swoją obecność w AI.
Dane strukturalne to standaryzowany znacznik, który pomaga wyszukiwarkom zrozumieć zawartość strony internetowej. Dowiedz się, jak JSON-LD, schema.org i microda...
Dowiedz się, dlaczego tabele są kluczowe dla optymalizacji wyszukiwania AI. Odkryj, jak uporządkowane dane w tabelach poprawiają zrozumienie przez AI, zwiększaj...
Dowiedz się, czym są wykresy, jakie są ich rodzaje i jak przekształcają surowe dane w praktyczne wnioski. Niezbędny przewodnik po formatach wizualizacji danych ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.