Paginação
A paginação divide grandes conjuntos de conteúdo em páginas gerenciáveis para melhor UX e SEO. Saiba como a paginação funciona, seu impacto no ranqueamento e as...
10 min de leitura

Saiba como a paginação impacta a visibilidade em IA. Descubra por que a divisão tradicional de páginas ajuda sistemas de IA a encontrar seu conteúdo enquanto a rolagem infinita o esconde, e como otimizar a paginação para geradores de respostas de IA.
Paginação é a prática de dividir grandes conjuntos de conteúdo em várias páginas interligadas. Sim, isso afeta significativamente os sistemas de IA—a paginação cria URLs distintas e rastreáveis que ajudam mecanismos de busca com IA como ChatGPT, Perplexity e o SGE do Google a descobrir e indexar seu conteúdo de forma mais eficaz, enquanto implementações de rolagem infinita frequentemente escondem conteúdo dos robôs de IA.
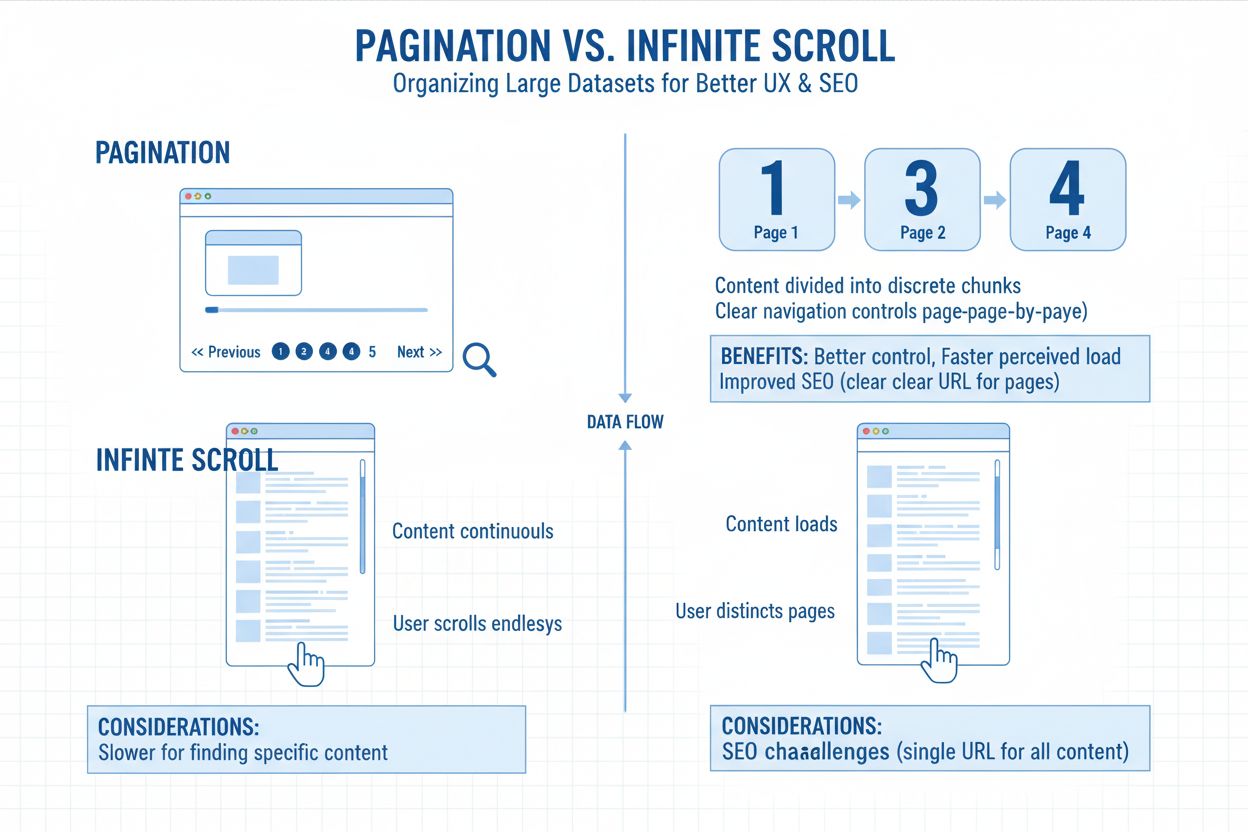
Paginação refere-se à prática de dividir grandes conjuntos de conteúdo em várias páginas interligadas ao invés de exibir tudo em uma única tela infinita. Pense como capítulos de um livro—cada página contém uma parte gerenciável do conteúdo total, conectada por links numerados ou botões de “próximo/anterior”. Essa abordagem estrutural aparece em todo lugar, desde listagens de produtos em lojas virtuais até arquivos de blogs, tópicos de fóruns e resultados de buscas. A estrutura da URL normalmente reflete essa divisão por parâmetros como ?page=2 ou caminhos limpos como /categoria/page/2/, permitindo que usuários e mecanismos de busca entendam sua posição dentro da série de conteúdo. A paginação serve como uma ferramenta organizacional fundamental que equilibra a experiência do usuário com os requisitos técnicos de acessibilidade do conteúdo.
Sites implementam paginação principalmente para otimização de desempenho e organização do conteúdo. Carregar centenas ou milhares de itens simultaneamente sobrecarregaria os recursos do servidor e criaria lentidão no carregamento das páginas, prejudicando especialmente métricas de desempenho que afetam o posicionamento nas buscas. Usuários apreciam poder salvar páginas específicas, pular direto para a página 10 ou entender quanto conteúdo ainda está disponível. Do ponto de vista técnico, dividir o conteúdo cria URLs distintas que os mecanismos de busca podem indexar individualmente, preservando a distribuição de autoridade de links na arquitetura do seu site. Essa clareza estrutural torna-se cada vez mais importante à medida que sistemas de IA evoluem para entender relações de conteúdo e padrões de acessibilidade.
A relação entre paginação e visibilidade em IA representa uma das considerações técnicas de SEO mais críticas no cenário moderno de busca. Mecanismos de busca tradicionais como o Google há muito entendem a paginação ao rastrear links e seguir padrões sequenciais de páginas. No entanto, motores de busca e geradores de respostas baseados em IA operam de forma fundamentalmente diferente, exigindo uma abordagem mais detalhada para organização do conteúdo. Grandes modelos de linguagem como os que alimentam o ChatGPT, Perplexity e o Search Generative Experience (SGE) do Google não necessariamente rastreiam páginas linearmente ou seguem hierarquias tradicionais de navegação. Em vez disso, trabalham tokenizando e resumindo entradas textuais—muitas vezes originadas de dados públicos, APIs ou bancos de dados estruturados ao invés de hierarquias profundas de rastreamento.
Quando seu conteúdo está espalhado por várias páginas minimamente estruturadas, os motores de IA podem pular entradas mais profundas ou interpretar erroneamente sua relação com o conjunto maior de conteúdo. Se houver pouca variação em metadados ou poucos sinais semânticos, seu conteúdo paginado pode parecer redundante—ou ser ignorado totalmente. Isso cria uma lacuna crítica de visibilidade: conteúdo que se posiciona bem na busca tradicional do Google pode permanecer completamente invisível para geradores de respostas de IA. A distinção importa porque sistemas de IA priorizam dados estruturados, completos e facilmente recuperáveis. Eles não estão “rolando” como um usuário. Estão processando código, URLs e metadados para resumir ou citar conteúdo com rapidez e precisão. Se sua página não expõe o conteúdo por URLs rastreáveis ou metadados ricos, motores de IA não podem recuperá-lo para inclusão em respostas geradas.
A escolha entre paginação tradicional e rolagem infinita tornou-se um fator determinante na descobribilidade de conteúdo para IA. Implementações de rolagem infinita carregam conteúdo via JavaScript apenas após interação do usuário, criando um problema fundamental de acessibilidade para rastreadores de IA. A maioria dos setups de rolagem infinita não expõe conteúdo através de URLs distintas—em vez disso, carregam tudo em uma única página por execução dinâmica de JavaScript. Isso significa que rastreadoras de IA, que não simulam comportamento real de usuário como rolar ou clicar, frequentemente perdem tudo além da primeira visualização. Se sua página não expõe esse conteúdo extra por URLs rastreáveis ou metadados, motores de IA não podem recuperá-lo. Você pode ter 200 artigos, 300 produtos ou dezenas de estudos de caso, mas se estiverem escondidos sob eventos de carregamento acionados por JavaScript, a IA só vê 12 itens. Talvez.
A paginação tradicional ainda vence de forma decisiva para indexação por IA porque produz URLs limpas e rastreáveis (ex: /blog/page/4), permitindo que motores acessem e segmentem seu conteúdo por completo. Ela sinaliza estrutura temática por links internos, usando links padronizados como “Próxima Página” ou “Página Anterior” para ajudar motores a enxergarem como os conteúdos se conectam. A paginação limita a dependência de JavaScript, garantindo que seu conteúdo carregue para rastreadores independentemente de como um usuário interage com a página. Essa clareza estrutural se traduz diretamente em melhor visibilidade por IA—quando ChatGPT ou Perplexity rastreiam seu site, conseguem descobrir e indexar o conteúdo paginado muito mais eficazmente do que conteúdo escondido atrás de implementações de rolagem infinita.
| Aspecto | Paginação | Rolagem Infinita |
|---|---|---|
| Acessibilidade ao Rastreamento | URLs únicas permitem indexação profunda | Conteúdo frequentemente escondido atrás de carregamentos JS |
| Descobribilidade por IA | Múltiplas páginas podem ranquear independentemente | Normalmente só uma página é indexada |
| Dados Estruturados | Mais fácil atribuir a páginas individuais | Frequentemente ausentes ou diluídos |
| Vinculação Direta | Fácil de linkar para conteúdo específico | Difícil criar links profundos |
| Compatibilidade com Sitemap | Compatível e completo | Frequentemente omite conteúdo profundo |
| Estrutura de URL | URLs claras e distintas por página | URL única com carregamento dinâmico |
| Visibilidade do Conteúdo | Todo o conteúdo acessível aos rastreadores | Conteúdo requer execução de JS |
A arquitetura técnica da rolagem infinita cria barreiras fundamentais para a descoberta de conteúdo por IA. Quando o conteúdo carrega apenas por JavaScript, e nenhuma URL reflete esse novo conteúdo, motores de IA nunca o veem. Para um rastreador, o resto da sua lista simplesmente não existe. Isso não é uma limitação dos sistemas de IA—é consequência de como a rolagem infinita normalmente é implementada. A maioria dos setups de rolagem infinita prioriza a experiência do usuário em detrimento da acessibilidade técnica, carregando conteúdo dinamicamente sem criar URLs ou metadados correspondentes que sistemas de IA possam processar.
Considere um cenário real: uma varejista global de moda redesenhou o site com uma interface elegante de rolagem infinita. A velocidade do site melhorou, métricas de engajamento pareciam sólidas, mas o tráfego a partir de resumos de IA despencou. Seus SKUs pareciam desaparecer em ferramentas de busca conversacional. Após auditoria da arquitetura, o problema ficou claro: todo o catálogo estava escondido atrás de rolagem infinita sem alternativas rastreáveis. Sem URLs de páginas secundárias. Sem links complementares. Apenas uma longa lista de produtos invisível. Google SGE e ChatGPT não conseguiam acessar nada além da primeira dúzia de produtos por categoria. Por mais bonito que o site estivesse, sua descobribilidade estava quebrada para sistemas de IA.
Implementação adequada de paginação requer atenção a múltiplos fatores técnicos que, juntos, determinam se sistemas de IA podem descobrir e citar seu conteúdo. A base começa com estruturas de URL limpas e lógicas que indicam claramente relações sequenciais. Você pode usar parâmetros de consulta (?page=2) ou estruturas baseadas em caminho (/page/2/), mas a consistência importa mais do que o formato específico escolhido. Ambos funcionam igualmente bem para sistemas de IA quando bem implementados. O importante é que cada URL paginada carregue conteúdo distinto e permaneça acessível por links HTML padrão que não dependam de execução de JavaScript.
Tags canônicas auto-referenciadas representam um ponto crítico na estratégia de paginação. Cada página paginada deve incluir uma tag canônica apontando para si mesma, sinalizando que cada página é a versão preferida de si. Essa abordagem preserva a independência das URLs sequenciais, permitindo que cada uma concorra por posicionamento com base em seu conteúdo específico e relevância para diferentes buscas. Evite a prática ultrapassada de canonizar todas as páginas paginadas para a página um—isso consolida sinais, mas elimina a capacidade de páginas individuais ranquearem independentemente em sistemas de IA. Ao canonizar tudo para a página um, você está explicitamente dizendo aos motores de IA para ignorarem páginas potencialmente valiosas que contêm produtos, conteúdos ou informações únicas.
Metadados únicos para cada página tornam-se essenciais para visibilidade em IA. Não use títulos genéricos como “Página 2” ou descrições duplicadas na sequência. Em vez disso, escreva metadados específicos, ricos em palavras-chave e que reflitam o foco de cada página. Por exemplo, em vez de “Produtos - Página 2”, use “Tênis Femininos até R$100 - Página 2” ou “Tendências de IA no Varejo – Biblioteca de Casos (Página 2)”. Essa clareza impulsiona a visibilidade porque sistemas de IA entendem contexto e podem determinar melhor quando seu conteúdo é relevante para buscas específicas. Cada conjunto de metadados deve seguir princípios de clareza, unicidade e alinhamento de palavras-chave. O objetivo é tornar o propósito de cada página óbvio tanto para sistemas de IA quanto para leitores humanos.
A arquitetura de links internos determina se sistemas de IA podem descobrir e navegar de forma eficiente por páginas sequenciais. Uma estrutura linear (página 1 → 2 → 3) cria caminhos longos de rastreamento onde páginas profundas ficam a muitos cliques da página inicial, podendo deixar conteúdo valioso não descoberto. Implementações inteligentes incluem links complementares como opções “Ver Tudo” ou hubs de categorias que levam diretamente a páginas-chave, reduzindo a profundidade de rastreamento e distribuindo a autoridade de links mais uniformemente. A relação entre navegação facetada e páginas sequenciais adiciona complexidade, já que combinações de filtros podem gerar milhares de variações de URLs. Linkagem interna adequada garante que páginas prioritárias recebam atenção suficiente dos rastreadores enquanto combinações menos críticas são despriorizadas por uso estratégico de tags noindex ou sinais canônicos.
Cadeias estratégicas de links internos do conteúdo pilar para páginas paginadas específicas guiam sistemas de IA pela estrutura do seu conteúdo. Da sua página principal de categoria, link diretamente para páginas paginadas usando texto âncora que oriente o entendimento da IA. Exemplo: “Explore mais cases de sucesso em ecommerce na nossa série de estudos de caso – página 3.” Torne o sinal significativo e fácil de encontrar. Essa abordagem ensina sistemas de IA como seu conteúdo se encaixa e como deve ser descoberto. Quando rastreadores de IA encontram esses links contextuais, eles entendem a relação entre as páginas e podem determinar melhor qual conteúdo é mais relevante para buscas específicas.
Problemas de conteúdo duplicado surgem quando múltiplas URLs exibem conteúdo idêntico ou substancialmente similar sem diferenciação adequada. Isso ocorre quando páginas sequenciais não possuem elementos únicos além dos itens listados, ou quando parâmetros de URL criam múltiplos caminhos para o mesmo conteúdo. Mecanismos de busca e sistemas de IA têm dificuldade para determinar qual versão ranquear, podendo fragmentar a visibilidade por várias URLs. Além disso, se páginas paginadas incluem textos padrão, cabeçalhos e rodapés com pouco conteúdo único, podem ser percebidas como páginas rasas sem valor. Resolver isso exige uso cuidadoso de tags canônicas, descrições meta únicas para cada página e garantir que cada página ofereça valor distinto além de elementos de navegação e seções modeladas.
Implementações somente em JavaScript talvez representem o erro mais comum que esconde conteúdo de sistemas de IA. Se seu site usa frameworks como React ou Angular para renderizar controles de página no cliente sem renderização no servidor, rastreadores de IA podem nunca descobrir conteúdo além da página um. Garanta que links de navegação existam no HTML inicial que sistemas de IA recebem, não apenas gerados por JavaScript após o carregamento da página. Use aprimoramento progressivo—links HTML básicos que o JavaScript pode melhorar com interações e animações mais suaves. Teste sua implementação com ferramentas que mostram exatamente o que rastreadores veem versus o que navegadores com JavaScript exibem. Isso revela lacunas de rastreabilidade que podem estar custando visibilidade em IA.
Acompanhar a eficácia da paginação requer monitoramento de como sistemas de IA interagem com seu conteúdo multipágina. Diferente do SEO tradicional, onde o Google Search Console oferece insights diretos, o monitoramento de visibilidade em IA requer abordagens diferentes. Ferramentas como Screaming Frog SEO Spider podem rastrear seu site de modo semelhante ao acesso feito por sistemas de IA, mapeando estruturas de páginas e identificando páginas órfãs ou problemas de profundidade de rastreamento. DeepCrawl e Sitebulk oferecem análises avançadas com visualização das relações entre páginas. O Google Search Console fornece insights sob a perspectiva do Google, mostrando quais URLs paginadas estão indexadas e padrões de frequência de rastreamento.
Indicadores-chave de desempenho para conteúdo paginado incluem se páginas profundas aparecem em respostas geradas por IA, com que frequência sistemas de IA citam seu conteúdo paginado e se diferentes páginas ranqueiam para diferentes buscas de cauda longa. Monitore menções da sua marca em respostas de IA—se sistemas de IA citam consistentemente sua página um mas nunca mencionam páginas profundas, sua estrutura de paginação pode precisar de ajustes. Acompanhe quais páginas paginadas geram mais tráfego de fontes de IA. Esses dados revelam se sua estratégia de paginação expõe efetivamente o conteúdo para sistemas de IA ou se uma reestruturação é necessária. Auditorias regulares capturam problemas antes de impactarem a visibilidade, especialmente após atualizações no site ou migrações de framework.
O cenário dos motores de busca alimentados por IA continua evoluindo rapidamente, com novos sistemas e capacidades surgindo regularmente. Estratégias de paginação que funcionam hoje devem permanecer eficazes à medida que sistemas de IA se tornam mais sofisticados, mas estar à frente requer entendimento das tendências emergentes. Algoritmos de busca baseados em IA se tornaram cada vez mais sofisticados ao compreender relações de conteúdo e determinar quais páginas paginadas merecem prioridade de indexação. O neural matching do Google e o entendimento baseado em BERT ajudam os motores a reconhecer que a página dois de uma categoria oferece produtos diferentes da página um, mesmo que o texto ao redor seja similar. Essa compreensão aprimorada significa que uma divisão bem estruturada com diferenças significativas entre as páginas se beneficia mais do que nunca de indexação independente.
Por outro lado, a IA também detecta melhor conteúdo realmente raso ou duplicado em páginas paginadas, tornando mais difícil manipular o sistema com páginas pouco diferenciadas. Algoritmos de machine learning predizem a intenção do usuário com mais precisão, podendo exibir páginas profundas de paginação para buscas de cauda longa quando essas páginas melhor correspondem à intenção. A implicação prática é garantir que cada página paginada ofereça valor realmente único—produtos distintos, conteúdo diferente ou variações significativas—em vez de apenas divisões mecânicas de informação idêntica. À medida que os sistemas de IA continuam evoluindo, os princípios básicos permanecem constantes: URLs distintas, links rastreáveis, valor único por página e metadados claros continuarão determinando a eficácia da paginação para visibilidade em IA.
Acompanhe como seu conteúdo aparece em respostas geradas por IA no ChatGPT, Perplexity e outros mecanismos de busca de IA. Garanta que sua marca seja citada quando sistemas de IA responderem perguntas sobre o seu setor.
A paginação divide grandes conjuntos de conteúdo em páginas gerenciáveis para melhor UX e SEO. Saiba como a paginação funciona, seu impacto no ranqueamento e as...
Páginas por Sessão mede a média de páginas visualizadas por visita. Descubra como essa métrica de engajamento impacta o comportamento do usuário, as taxas de co...
Estrutura de navegação é o sistema que organiza páginas e links do site para guiar usuários e rastreadores de IA. Saiba como ela afeta SEO, experiência do usuár...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.