
Otimização de Busca por IA
Aprenda estratégias de Otimização de Busca por IA para melhorar a visibilidade da marca no ChatGPT, Google AI Overviews e Perplexity. Otimize o conteúdo para ci...
15 min de leitura
Um mecanismo de atenção é um componente de rede neural que pesa dinamicamente a importância de diferentes elementos de entrada, permitindo que os modelos foquem nas partes mais relevantes dos dados ao fazer previsões. Ele calcula pesos de atenção por meio de transformações aprendidas de consultas, chaves e valores, permitindo que modelos de deep learning capturem dependências de longo alcance e relações sensíveis ao contexto em dados sequenciais.
Um mecanismo de atenção é um componente de rede neural que pesa dinamicamente a importância de diferentes elementos de entrada, permitindo que os modelos foquem nas partes mais relevantes dos dados ao fazer previsões. Ele calcula pesos de atenção por meio de transformações aprendidas de consultas, chaves e valores, permitindo que modelos de deep learning capturem dependências de longo alcance e relações sensíveis ao contexto em dados sequenciais.
Mecanismo de atenção é uma técnica de aprendizado de máquina que direciona modelos de deep learning a priorizar (ou “atender a”) as partes mais relevantes dos dados de entrada ao fazer previsões. Em vez de tratar todos os elementos de entrada igualmente, mecanismos de atenção calculam pesos de atenção que refletem a importância relativa de cada elemento para a tarefa em questão, aplicando esses pesos para enfatizar ou desconsiderar dinamicamente entradas específicas. Essa inovação fundamental se tornou a base das modernas arquiteturas transformer e dos grandes modelos de linguagem (LLMs) como ChatGPT, Claude e Perplexity, permitindo processar dados sequenciais com eficiência e precisão sem precedentes. O mecanismo é inspirado na atenção cognitiva humana — a capacidade de focar seletivamente em detalhes salientes enquanto filtra informações irrelevantes — e traduz esse princípio biológico em um componente de rede neural matematicamente rigoroso e treinável.
O conceito de mecanismos de atenção foi introduzido por Bahdanau e colegas em 2014 para contornar limitações críticas das redes neurais recorrentes (RNNs) usadas em tradução automática. Antes da atenção, os modelos Seq2Seq dependiam de um único vetor de contexto para codificar frases inteiras da fonte, criando um gargalo de informação que limitava fortemente o desempenho em sequências longas. O mecanismo de atenção original permitiu ao decodificador acessar todos os estados ocultos do codificador, e não apenas o final, selecionando dinamicamente quais partes da entrada eram mais relevantes em cada etapa de decodificação. Essa inovação melhorou radicalmente a qualidade da tradução, especialmente para frases mais longas. Em 2015, Luong e colegas introduziram a atenção dot-product, que substituiu a atenção aditiva computacionalmente custosa por multiplicação de matrizes eficiente. O momento decisivo veio em 2017, com a publicação de “Attention is All You Need”, que apresentou a arquitetura transformer eliminando a recorrência em favor de mecanismos de atenção puros. Esse artigo revolucionou o deep learning, possibilitando o desenvolvimento do BERT, dos modelos GPT e de todo o ecossistema moderno de IA generativa. Atualmente, mecanismos de atenção são onipresentes em processamento de linguagem natural, visão computacional e sistemas de IA multimodais, com mais de 85% dos modelos de ponta incorporando algum tipo de arquitetura baseada em atenção.
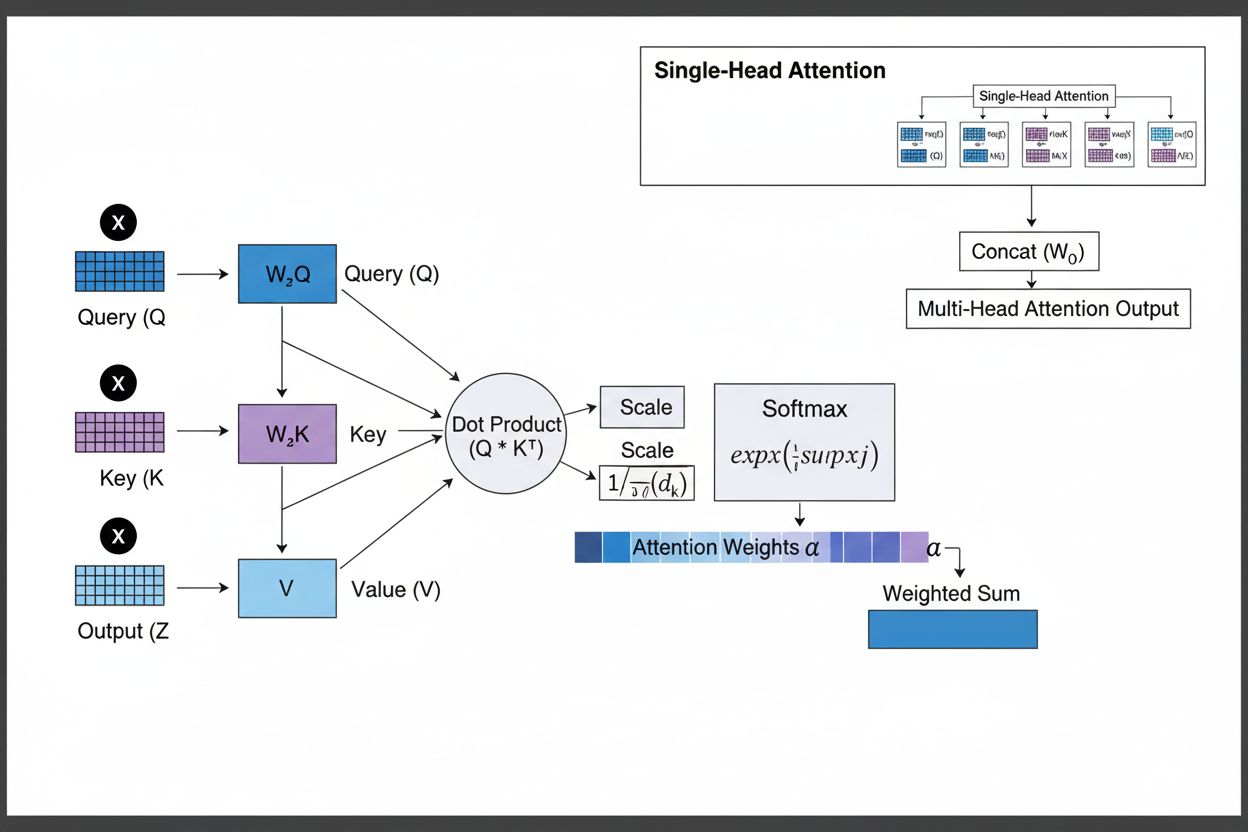
O mecanismo de atenção opera por meio de uma sofisticada interação de três componentes matemáticos principais: queries (Q), keys (K) e values (V). Cada elemento de entrada é transformado nessas três representações através de projeções lineares aprendidas, criando uma estrutura semelhante a um banco de dados relacional, onde as chaves servem como identificadores e os valores contêm a informação real. O mecanismo calcula scores de alinhamento medindo a similaridade entre uma query e todas as keys, geralmente usando a atenção dot-product escalada, onde o score é calculado como QK^T/√d_k. Esses scores brutos são normalizados com a função softmax, que os converte em uma distribuição de probabilidade onde todos os pesos somam 1, garantindo que cada elemento receba um peso entre 0 e 1. O passo final envolve calcular a soma ponderada dos vetores de valor usando esses pesos de atenção, produzindo um vetor de contexto que representa as informações mais relevantes de toda a sequência de entrada. Esse vetor de contexto é então combinado com a entrada original por meio de conexões residuais e passado por camadas feedforward, permitindo que o modelo refine iterativamente sua compreensão da entrada. A elegância matemática desse design — combinando transformações treináveis, cálculos de similaridade e ponderação probabilística — permite que mecanismos de atenção capturem dependências complexas mantendo-se totalmente diferenciáveis para otimização baseada em gradiente.
| Tipo de Atenção | Método de Cálculo | Complexidade Computacional | Melhor Caso de Uso | Vantagem Chave |
|---|---|---|---|---|
| Atenção Aditiva | Rede feedforward + ativação tanh | O(n·d) por query | Sequências curtas, dimensões variáveis | Lida com diferentes dimensões de query/key |
| Atenção Dot-Product | Multiplicação matricial simples | O(n·d) por query | Sequências padrão | Computacionalmente eficiente |
| Dot-Product Escalada | QK^T/√d_k + softmax | O(n·d) por query | Transformers modernos | Previne desaparecimento do gradiente |
| Atenção Multi-Head | Múltiplos heads de atenção paralelos | O(h·n·d) onde h=heads | Relações complexas | Captura aspectos semânticos diversos |
| Self-Attention | Queries, keys, values da mesma sequência | O(n²·d) | Relações intra-sequência | Permite processamento paralelo |
| Cross-Attention | Queries de uma sequência, keys/values de outra | O(n·m·d) | Encoder-decoder, multimodal | Alinha diferentes modalidades |
| Grouped Query Attention | Compartilha keys/values entre heads de query | O(n·d) | Inferência eficiente | Reduz memória e computação |
| Atenção Esparsa | Atenção limitada a posições locais/estratificadas | O(n·√n·d) | Sequências muito longas | Lida com sequências extremamente longas |
O mecanismo de atenção opera por meio de uma sequência precisamente orquestrada de transformações matemáticas que permitem às redes neurais focar dinamicamente nas informações relevantes. Ao processar uma sequência de entrada, cada elemento é primeiro embutido em um espaço vetorial de alta dimensão, capturando informações semânticas e sintáticas. Esses embeddings são então projetados em três espaços separados por matrizes de pesos aprendidas: o espaço de query (representando o que se busca), o espaço de key (o que cada elemento contém de informação) e o espaço de value (com a informação a ser agregada). Para cada posição de query, o mecanismo calcula um score de similaridade com cada key pelo produto escalar, gerando um vetor de scores de alinhamento brutos. Esses scores são escalados dividindo pelo valor da raiz quadrada da dimensão da key (√d_k), passo fundamental para evitar scores excessivamente altos em dimensões grandes, o que causaria desaparecimento do gradiente no backpropagation. Os scores escalados passam por uma função softmax, que exponencia e normaliza para que somem 1, criando uma distribuição de probabilidade sobre todas as posições de entrada. Finalmente, os pesos de atenção são usados para calcular uma média ponderada dos vetores de value, onde posições com maior peso contribuem mais fortemente para o vetor de contexto final. Esse vetor de contexto é então combinado à entrada original por conexões residuais e processado por camadas feedforward, permitindo ao modelo refinar iterativamente suas representações. Todo o processo é diferenciável, possibilitando ao modelo aprender padrões de atenção ideais por descida do gradiente durante o treinamento.
Mecanismos de atenção formam o bloco fundamental das arquiteturas transformer, que se tornaram o paradigma dominante no deep learning. Diferente das RNNs que processam sequências de forma sequencial e das CNNs que operam em janelas locais fixas, transformers usam self-attention para permitir que cada posição acesse diretamente todas as outras posições simultaneamente, promovendo paralelização massiva em GPUs e TPUs. A arquitetura transformer consiste em camadas alternadas de self-attention multi-head e redes feedforward, com cada camada de atenção permitindo ao modelo refinar sua compreensão da entrada ao focar seletivamente em diferentes aspectos. O multi-head attention executa múltiplos mecanismos de atenção em paralelo, com cada head especializando-se em tipos distintos de relações — um pode focar em dependências gramaticais, outro em relações semânticas e um terceiro em coreferências de longa distância. As saídas de todos os heads são concatenadas e projetadas, permitindo ao modelo manter consciência de múltiplos fenômenos linguísticos simultaneamente. Essa arquitetura provou ser extremamente eficaz para grandes modelos de linguagem como GPT-4, Claude 3 e Gemini, que usam arquiteturas transformer apenas de decodificador, onde cada token só pode acessar tokens anteriores (masking causal) para manter a geração autoregressiva. A capacidade do mecanismo de atenção de capturar dependências de longo alcance sem os problemas de gradiente das RNNs foi crucial para permitir que esses modelos processem janelas de contexto com mais de 100.000 tokens, mantendo coerência e consistência em grandes volumes de texto. Pesquisas mostram que aproximadamente 92% dos modelos de NLP de ponta atualmente dependem de arquiteturas transformer impulsionadas por mecanismos de atenção, demonstrando sua importância fundamental para sistemas de IA modernos.
No contexto de plataformas de busca por IA como ChatGPT, Perplexity, Claude e Google AI Overviews, mecanismos de atenção desempenham papel crucial ao determinar quais partes dos documentos recuperados e bases de conhecimento são mais relevantes para as consultas dos usuários. Ao gerar respostas, esses sistemas ponderam dinamicamente diferentes fontes e trechos de acordo com a relevância, permitindo sintetizar respostas coerentes a partir de múltiplas fontes mantendo precisão factual. Os pesos de atenção calculados durante a geração podem ser analisados para compreender quais informações o modelo priorizou, fornecendo insights sobre como sistemas de IA interpretam e respondem às consultas. Para monitoramento de marcas e GEO (Otimização para Motores Geradores), entender mecanismos de atenção é essencial, pois eles determinam quais conteúdos e fontes recebem destaque em respostas geradas por IA. Conteúdos estruturados alinhados à forma como mecanismos de atenção ponderam informações — com definições claras de entidades, fontes autoritativas e relevância contextual — têm maior probabilidade de serem citados e destacados em respostas de IA. O AmICited utiliza insights sobre mecanismos de atenção para rastrear como marcas e domínios aparecem em plataformas de IA, reconhecendo que citações ponderadas por atenção representam as menções mais influentes em conteúdo gerado por IA. À medida que empresas monitoram cada vez mais sua presença em respostas de IA, compreender que mecanismos de atenção direcionam os padrões de citação se torna crítico para otimizar estratégias de conteúdo e garantir visibilidade de marca na era da IA generativa.
O campo dos mecanismos de atenção evolui rapidamente, com pesquisadores desenvolvendo variantes cada vez mais sofisticadas para superar limitações computacionais e melhorar desempenho. Padrões de atenção esparsa limitam a atenção a vizinhanças locais ou posições estratificadas, reduzindo a complexidade de O(n²) para O(n·√n) enquanto mantêm o desempenho em sequências muito longas. Mecanismos de atenção eficiente como o FlashAttention otimizam o acesso à memória durante o cálculo da atenção, atingindo acelerações de 2 a 4 vezes por melhor uso da GPU. Grouped query attention e multi-query attention reduzem o número de heads key-value mantendo o desempenho, diminuindo drasticamente a exigência de memória na inferência — fundamental para deploy de grandes modelos em produção. Arquiteturas Mixture of Experts combinam atenção com roteamento esparso, permitindo escalar modelos a trilhões de parâmetros com eficiência computacional. Pesquisas emergentes exploram padrões de atenção aprendidos que se adaptam dinamicamente às características da entrada, e atenção hierárquica que opera em múltiplos níveis de abstração. A integração de mecanismos de atenção com geração aumentada por recuperação (RAG) permite que modelos acessem dinamicamente conhecimento externo relevante, melhorando a factualidade e reduzindo alucinações. À medida que sistemas de IA são implantados em aplicações críticas, mecanismos de atenção ganham recursos de explicabilidade que fornecem maior clareza nas decisões dos modelos. O futuro provavelmente envolverá arquiteturas híbridas, combinando atenção com mecanismos alternativos como modelos de espaço de estados (exemplificados pelo Mamba), que oferecem complexidade linear com desempenho competitivo. Compreender esses mecanismos de atenção em evolução é essencial para profissionais construindo a próxima geração de sistemas de IA e para organizações monitorando sua presença em conteúdo gerado por IA, já que os mecanismos que determinam padrões de citação e destaque de conteúdo continuam a avançar.
Para organizações que utilizam o AmICited para monitorar a visibilidade da marca em respostas de IA, compreender mecanismos de atenção fornece contexto crucial para interpretar padrões de citação. Quando ChatGPT, Claude ou Perplexity citam seu domínio em suas respostas, os pesos de atenção calculados durante a geração determinaram que seu conteúdo era o mais relevante para a consulta do usuário. Conteúdo de alta qualidade, bem estruturado, que define claramente entidades e oferece informações autoritativas, naturalmente recebe pesos de atenção mais altos, tornando-se mais provável de ser selecionado para citação. Os recursos de visualização da atenção em algumas plataformas de IA revelam quais fontes receberam maior foco durante a geração da resposta, mostrando efetivamente quais citações foram mais influentes. Esse insight permite que organizações otimizem suas estratégias de conteúdo, entendendo que mecanismos de atenção recompensam clareza, relevância e fontes autoritativas. À medida que a busca por IA cresce — com mais de 60% das empresas investindo em iniciativas de IA generativa — a capacidade de entender e otimizar para mecanismos de atenção torna-se cada vez mais valiosa para manter a visibilidade da marca e garantir representação precisa em conteúdo gerado por IA. A interseção entre mecanismos de atenção e monitoramento de marcas representa a nova fronteira do GEO, onde entender os fundamentos matemáticos de como sistemas de IA ponderam e citam informações traduz-se diretamente em maior visibilidade e influência no ecossistema de IA generativa.
RNNs tradicionais processam sequências de forma serial, dificultando a captura de dependências de longo alcance, enquanto CNNs possuem campos receptivos locais fixos que limitam sua capacidade de modelar relações distantes. Mecanismos de atenção superam essas limitações ao calcular relações entre todas as posições de entrada simultaneamente, permitindo processamento paralelo e capturando dependências independentemente da distância. Essa flexibilidade no tempo e no espaço torna os mecanismos de atenção significativamente mais eficientes e eficazes para dados sequenciais e espaciais complexos.
Queries representam a informação que o modelo está buscando no momento, keys representam o conteúdo informacional que cada elemento de entrada possui, e values contêm os dados a serem agregados. O modelo calcula pontuações de similaridade entre queries e keys para determinar quais values devem ter maior peso. Essa terminologia inspirada em bancos de dados, popularizada pelo artigo 'Attention is All You Need', fornece uma estrutura intuitiva para entender como mecanismos de atenção recuperam e combinam seletivamente informações relevantes de sequências de entrada.
Self-attention calcula relações dentro de uma única sequência de entrada, onde queries, keys e values vêm da mesma fonte, permitindo ao modelo compreender como diferentes elementos se relacionam. Cross-attention, por outro lado, utiliza queries de uma sequência e keys/values de outra, permitindo ao modelo alinhar e combinar informações de múltiplas fontes. Cross-attention é essencial em arquiteturas encoder-decoder como tradução automática e em modelos multimodais como o Stable Diffusion que combinam texto e imagem.
A atenção dot-product escalada usa multiplicação em vez de adição para calcular os scores de alinhamento, tornando-a mais eficiente computacionalmente por meio de operações matriciais otimizadas para paralelização em GPU. O fator de escala 1/√dk evita que os produtos escalares se tornem grandes demais quando a dimensão da chave é alta, o que causaria o desaparecimento do gradiente durante o backpropagation. Embora a atenção aditiva às vezes supere a dot-product para dimensões muito grandes, a eficiência computacional e o desempenho prático superiores da dot-product escalada a tornam a escolha padrão em arquiteturas transformer modernas.
O multi-head attention executa múltiplos mecanismos de atenção em paralelo, com cada head aprendendo a focar em diferentes aspectos da entrada, como relações gramaticais, significado semântico ou dependências de longo alcance. Cada head opera em diferentes projeções lineares da entrada, permitindo que o modelo capture simultaneamente diversos tipos de relações. As saídas de todos os heads são concatenadas e projetadas, permitindo ao modelo manter consciência abrangente de múltiplas características linguísticas e contextuais ao mesmo tempo, melhorando significativamente a qualidade das representações e o desempenho em tarefas subsequentes.
O softmax normaliza os scores de alinhamento brutos calculados entre queries e keys em uma distribuição de probabilidade onde todos os pesos somam 1. Essa normalização garante que os pesos de atenção sejam interpretáveis como scores de importância, com valores mais altos indicando maior relevância. A função softmax é diferenciável, permitindo o aprendizado baseado em gradiente do mecanismo de atenção durante o treinamento, e sua natureza exponencial acentua as diferenças entre os scores, tornando o foco do modelo mais seletivo e interpretável.
Mecanismos de atenção permitem que esses modelos ponderem dinamicamente diferentes partes do prompt de entrada com base na relevância para o passo atual de geração. Ao gerar uma resposta, o modelo usa atenção para determinar quais tokens e elementos de entrada anteriores devem influenciar mais fortemente a previsão do próximo token. Esse peso sensível ao contexto permite aos modelos manter coerência, rastrear entidades ao longo de textos longos, resolver ambiguidades e gerar respostas que referenciam adequadamente partes específicas da entrada, tornando as saídas mais precisas e apropriadas ao contexto.
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
Aprenda estratégias de Otimização de Busca por IA para melhorar a visibilidade da marca no ChatGPT, Google AI Overviews e Perplexity. Otimize o conteúdo para ci...
Descubra o que é LLMO, como funciona e por que é importante para a visibilidade em IA. Conheça técnicas de otimização para fazer sua marca aparecer no ChatGPT, ...

Saiba o que são os Sistemas de Alerta de Citação por IA, como funcionam e por que monitorar a presença da sua marca em ChatGPT, Perplexity e outras plataformas ...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.