
O que é Coocorrência na Busca por IA?
Saiba como padrões de coocorrência ajudam mecanismos de busca por IA a entender relacionamentos semânticos entre termos, melhorar o ranqueamento de conteúdo e a...
11 min de leitura
Coocorrência refere-se à aparição frequente de dois ou mais termos ou conceitos juntos dentro do mesmo contexto de conteúdo, como em um documento, página da web ou em múltiplas fontes. Esse relacionamento semântico ajuda motores de busca e sistemas de IA a entenderem a relevância contextual e a profundidade do tópico, melhorando a visibilidade do conteúdo e seu potencial de ranqueamento.
Coocorrência refere-se à aparição frequente de dois ou mais termos ou conceitos juntos dentro do mesmo contexto de conteúdo, como em um documento, página da web ou em múltiplas fontes. Esse relacionamento semântico ajuda motores de busca e sistemas de IA a entenderem a relevância contextual e a profundidade do tópico, melhorando a visibilidade do conteúdo e seu potencial de ranqueamento.
Coocorrência é o fenômeno em que dois ou mais termos, conceitos ou entidades aparecem juntos com frequência dentro do mesmo contexto de conteúdo — seja em um único documento, página web ou em múltiplas fontes na internet. No contexto de processamento de linguagem natural (PLN) e otimização para motores de busca (SEO), coocorrência refere-se especificamente à frequência estatística com que termos relacionados se agrupam, sinalizando relevância semântica e profundidade contextual para algoritmos de busca e sistemas de IA. Em vez de exigir correspondência exata de palavras-chave, os padrões de coocorrência ajudam os motores de busca modernos e assistentes de IA a entenderem o verdadeiro significado e escopo do conteúdo, analisando quais palavras se associam naturalmente entre si. Esse conceito se tornou cada vez mais importante à medida que os motores de busca evoluem de simples correspondência de palavras para uma compreensão semântica sofisticada, e à medida que a visibilidade em IA emerge como componente crítico da estratégia digital ao lado do SEO tradicional.
O conceito de coocorrência tem raízes em análises linguísticas e estatísticas que datam de décadas atrás, mas sua aplicação ao marketing digital e SEO é relativamente recente. Os primeiros motores de busca dependiam principalmente da correspondência exata de palavras-chave e da densidade das mesmas, tratando cada termo de forma isolada. No entanto, com a evolução do algoritmo do Google — especialmente com atualizações como Hummingbird (2013) e RankBrain (2015) — o motor de busca passou a priorizar a compreensão semântica e a relevância contextual em vez da simples repetição de palavras-chave. Essa mudança refletiu uma transformação fundamental na forma como algoritmos interpretam conteúdo: em vez de contar ocorrências de palavras-chave, eles agora analisam as relações entre termos e conceitos. Pesquisas das próprias publicações do Google sobre busca semântica demonstraram que entender estatísticas de coocorrência permite aos algoritmos desambiguar significados e corresponder a intenção do usuário com mais precisão. Segundo dados do setor, aproximadamente 78% das empresas já utilizam ferramentas de análise de conteúdo impulsionadas por IA que incorporam métricas de coocorrência para otimizar suas estratégias de conteúdo. O crescimento de sistemas de IA generativa como ChatGPT, Perplexity e Google AI Overviews elevou ainda mais a importância da coocorrência, já que esses sistemas dependem fortemente de padrões estatísticos aprendidos a partir de dados de treinamento para determinar quais fontes e marcas são mais relevantes para mencionar nas respostas.
No essencial, a análise de coocorrência opera por meio da medição estatística de padrões de frequência de palavras dentro de janelas de contexto definidas. Uma matriz de coocorrência é uma representação matemática — normalmente uma grade N×N, onde N representa o número de palavras únicas em um corpus — que captura com que frequência pares de palavras aparecem juntos. Cada célula da matriz contém um valor que representa a frequência de duas palavras aparecerem em uma proximidade específica (frequentemente chamada de “janela de contexto”, geralmente de 2 a 10 palavras). Por exemplo, em um artigo sobre “veículos elétricos”, as palavras “bateria”, “recarga”, “autonomia” e “emissões” terão altos valores de coocorrência, pois aparecem frequentemente próximas ao termo principal. Essa base estatística permite várias aplicações subsequentes: embeddings de palavras como o GloVe (Global Vectors for Word Representation) utilizam matrizes de coocorrência para criar representações densas de palavras, em que termos semanticamente similares possuem valores vetoriais próximos. Sistemas de processamento de linguagem natural aproveitam esses padrões para tarefas como modelagem de tópicos, análise de sentimento e medição de similaridade semântica. A elegância matemática da análise de coocorrência reside em sua capacidade de capturar relações semânticas implícitas sem exigir anotação humana explícita — o algoritmo simplesmente observa quais termos se agrupam e infere suas relações a partir dos padrões de frequência.
| Conceito | Definição | Foco | Aplicação | Impacto no Ranqueamento |
|---|---|---|---|---|
| Coocorrência | Termos relacionados aparecendo juntos frequentemente no conteúdo | Relações semânticas e profundidade | Otimização de conteúdo, clusterização | Moderado a Alto (suporta sinais de relevância) |
| Densidade de Palavras-chave | Percentual de vezes que uma palavra-chave aparece no conteúdo | Frequência e destaque da palavra-chave | SEO tradicional (hoje ultrapassado) | Baixo (penalizado se excessivo) |
| Cocitação | Duas entidades mencionadas juntas por fontes terceiras | Autoridade e associação tópica | Link building e autoridade de marca | Moderado (suporta sinais E-E-A-T) |
| SEO Semântico | Otimização para significado e intenção do usuário, não só palavras | Cobertura abrangente de tópicos | Estratégia e estrutura de conteúdo | Alto (alinha-se a algoritmos modernos) |
| Latent Semantic Indexing (LSI) | Técnica matemática que identifica padrões semânticos ocultos | Relações conceituais no texto | Análise de conteúdo e pesquisa de palavras-chave | Moderado (fundamental, mas menos enfatizado hoje) |
| Reconhecimento de Entidades | Identificação e categorização de entidades nomeadas no texto | Pessoas, lugares, organizações | Grafos de conhecimento e dados estruturados | Alto (crítico para sistemas de IA) |
A busca semântica representa uma mudança fundamental na forma como motores de busca interpretam consultas de usuários e correspondem a conteúdos relevantes. Em vez de tratar a consulta como um conjunto de palavras-chave isoladas, motores de busca semânticos analisam a intenção por trás da busca e as relações conceituais entre termos. Padrões de coocorrência são centrais nesse processo porque fornecem evidências estatísticas de quais conceitos são semanticamente relacionados. Quando o algoritmo do Google encontra conteúdo sobre “moda sustentável”, reconhece que termos como “materiais ecológicos”, “fabricação ética”, “pegada de carbono” e “comércio justo” frequentemente coocorrem com o tema. Esses dados de coocorrência ajudam o algoritmo a perceber que uma página cobre o assunto de forma abrangente e, portanto, é mais relevante para usuários buscando consultas relacionadas. Pesquisas publicadas em periódicos de ciência cognitiva mostram que regularidades estatísticas na coocorrência de palavras são fundamentais para o desenvolvimento da compreensão semântica humana, e sistemas modernos de IA replicam esse processo computacionalmente. A implicação prática para criadores de conteúdo é significativa: em vez de se preocupar com densidade de palavras-chave ou correspondência exata, os redatores devem criar conteúdos que naturalmente incorporem termos semanticamente relacionados. Um artigo bem escrito sobre “aprendizado de máquina” incluirá organicamente termos como “algoritmos”, “redes neurais”, “dados de treinamento”, “acurácia do modelo” e “aprendizado supervisionado” — e essa coocorrência natural sinaliza aos motores de busca que o conteúdo é autoritativo e abrangente.
O surgimento de sistemas de IA generativa como plataformas de descoberta criou uma nova dimensão para a análise de coocorrência. Diferente dos motores de busca tradicionais, que retornam links para páginas web, sistemas de IA como ChatGPT, Perplexity e Google AI Overviews geram respostas textuais originais que citam fontes e mencionam marcas. A frequência e o contexto dessas menções são fortemente influenciados por padrões de coocorrência nos dados de treinamento da IA. Quando uma marca coocorre consistentemente com termos positivos do setor, fontes autoritativas e conceitos relevantes no corpus de treinamento, o sistema de IA tende a mencioná-la mais nas respostas. Isso tem profundas implicações para monitoramento de marca e estratégia de visibilidade em IA. Ferramentas como AmICited rastreiam não apenas se uma marca é mencionada em respostas de IA, mas também os termos contextuais que coocorrem com essas menções. Por exemplo, se sua marca aparece junto a termos como “inovadora”, “líder no setor” e “confiada por empresas”, esse contexto positivo de coocorrência fortalece a percepção da sua marca. Por outro lado, se sua marca coocorre frequentemente com termos negativos ou nomes de concorrentes, isso pode prejudicar seu posicionamento. Pesquisas indicam que aproximadamente 64% dos usuários já utilizam assistentes de IA para descoberta de produtos e tomada de decisão, tornando padrões de coocorrência em dados de treinamento de IA cada vez mais importantes para o posicionamento competitivo. Organizações que compreendem e otimizam a coocorrência em contextos de IA obtêm vantagem significativa nesse cenário emergente.
Implementar a otimização por coocorrência requer uma abordagem estratégica que equilibre considerações algorítmicas com a experiência do usuário. O primeiro passo é a análise competitiva: identifique as páginas melhores ranqueadas para suas palavras-chave alvo e analise quais termos semânticos coocorrem com maior frequência. Ferramentas como Surfer SEO, Clearscope e MarketMuse automatizam essa análise ao extrair frases coocorrentes do conteúdo dos concorrentes e fornecer recomendações. O segundo passo é a integração natural: incorpore os termos coocorrentes identificados ao seu conteúdo de modo orgânico, valorizando a leitura. Por exemplo, se você escreve sobre “marketing de conteúdo” e a análise revela que “engajamento da audiência”, “storytelling”, “voz da marca” e “otimização de conversão” coocorrem frequentemente em conteúdos líderes, você deve costurar esses conceitos naturalmente ao longo do artigo. A principal diferença em relação ao keyword stuffing é que a otimização por coocorrência prioriza a coerência semântica — cada termo deve realmente se relacionar ao tema e agregar valor ao leitor. O terceiro passo é a otimização estrutural: organize seu conteúdo com títulos, subtítulos e seções claras que agrupem conceitos relacionados. Essa estrutura reforça padrões de coocorrência e auxilia tanto usuários quanto algoritmos a entenderem as relações hierárquicas entre ideias. Por fim, monitore e itere: acompanhe seus rankings para palavras-chave principais e relacionadas, e utilize ferramentas como Google Search Console e Ahrefs para identificar quais padrões de coocorrência se correlacionam com melhorias nos rankings. Essa abordagem orientada a dados garante que sua estratégia de coocorrência traga resultados mensuráveis.
Matrizes de coocorrência são estruturas de dados fundamentais em PLN que quantificam relações de palavras em grande escala. Uma matriz típica para um corpus de 10.000 palavras únicas seria uma grade 10.000×10.000 com contagens de frequência para todos os pares possíveis. Embora isso gere desafios computacionais (matrizes esparsas com muitos zeros), os insights obtidos são valiosos. Técnicas de redução de dimensionalidade, como Singular Value Decomposition (SVD), comprimem essas matrizes em representações de menor dimensão que capturam as relações semânticas mais importantes reduzindo a sobrecarga computacional. Essas matrizes reduzidas formam a base dos embeddings de palavras, que representam cada termo como um vetor denso em um espaço semântico. Palavras de significado similar possuem vetores próximos, permitindo que algoritmos realizem cálculos de similaridade semântica. Por exemplo, os vetores de “cachorro”, “filhote” e “canino” estarão próximos, enquanto “cachorro” e “bicicleta” estarão distantes. Essa representação matemática permite que sistemas de IA entendam que “eu tenho um filhote” e “eu tenho um cachorro jovem” transmitem significados similares, mesmo usando palavras diferentes. As aplicações práticas vão além da similaridade: matrizes de coocorrência permitem modelagem de tópicos (identificando agrupamentos de palavras relacionadas que representam temas distintos), desambiguação de sentidos (determinando qual significado de uma palavra polissêmica é pretendido no contexto) e busca semântica (relacionando consultas a documentos com base em relevância conceitual, não só por palavras-chave).
Diferentes plataformas de IA ponderam padrões de coocorrência de formas distintas, de acordo com seus dados de treinamento, arquitetura e objetivos de otimização. ChatGPT, treinado em textos diversos da internet, tende a reconhecer padrões de coocorrência que refletem consenso amplo sobre relações temáticas. Quando você pergunta ao ChatGPT sobre “melhores ferramentas de gestão de projetos”, ele menciona marcas que frequentemente coocorrem com avaliações positivas, reconhecimento do setor e descrições de recursos em seus dados de treinamento. Perplexity, que enfatiza citações de fontes e informações em tempo real, pode ponderar padrões de coocorrência de forma diferente, priorizando fontes que coocorrem com conteúdos recentes e autoritativos. Google AI Overviews integra análise de coocorrência com sinais de ranqueamento já existentes do Google, ou seja, marcas bem posicionadas para palavras-chave relacionadas e que coocorrem com fontes autoritativas têm maior visibilidade em resumos gerados por IA. Claude, assistente da Anthropic, demonstra ponderação distinta baseada em sua abordagem de treinamento, que enfatiza utilidade e ausência de danos. Entender essas diferenças por plataforma é fundamental para a estratégia de GEO (Otimização para Motores Geradores). Uma marca que otimiza para coocorrência com “soluções corporativas”, “escalabilidade” e “segurança” pode ter bom desempenho no ChatGPT e Claude, mas pode precisar de padrões diferentes para ranquear bem no Perplexity, que pode priorizar coocorrência com “inovador”, “amigável para startups” e “custo-benefício”. Essa otimização por plataforma representa a próxima fronteira em estratégias de visibilidade em IA, exigindo que profissionais de marketing compreendam não só quais termos coocorrem, mas como cada sistema de IA valoriza esses padrões.
A importância da coocorrência na estratégia digital continuará a crescer à medida que sistemas de IA se tornem mais sofisticados e prevalentes. Tendências emergentes sugerem como esse conceito vai evoluir. Primeiro, a coocorrência multimodal se torna cada vez mais relevante à medida que sistemas de IA processam não só texto, mas também imagens, vídeos e dados estruturados. Uma marca que coocorre com conteúdo visual de alta qualidade e conteúdo gerado por usuários terá sinais mais fortes do que aquela presente apenas em textos. Segundo, padrões temporais de coocorrência ganham importância — termos que coocorrem com sua marca recentemente podem ter mais peso do que padrões históricos, refletindo a preferência da IA por informações atuais e relevantes. Terceiro, coocorrência sensível ao sentimento emerge como métrica crítica, em que o contexto emocional dos termos coocorrentes importa tanto quanto sua frequência. Uma marca que coocorre com termos de sentimento positivo (“inovadora”, “confiável”, “de confiança”) tem implicações diferentes de outra associada a termos neutros ou negativos. Quarto, a coocorrência em nível de entidade torna-se mais sofisticada, com sistemas de IA reconhecendo não só coocorrência de palavras, mas relações entre entidades nomeadas (pessoas, organizações, locais, produtos). Isso permite compreensão mais refinada do posicionamento da marca em relação a concorrentes, parceiros e influenciadores do setor. Por fim, a análise de coocorrência multiplataforma se tornará prática padrão, com profissionais de marketing acompanhando como suas marcas coocorrem em diferentes sistemas de IA, redes sociais, portais de notícias e sites de avaliações para criar estratégias de visibilidade abrangentes. Organizações que investirem em compreender e otimizar padrões de coocorrência agora terão vantagens competitivas significativas à medida que sistemas de IA continuem a transformar a forma como consumidores descobrem e avaliam marcas.
A coocorrência é o agrupamento natural de termos semanticamente relacionados que fornecem profundidade contextual e melhoram a legibilidade, enquanto o keyword stuffing envolve a repetição artificial e excessiva da mesma palavra-chave para manipular o ranqueamento. A coocorrência ocorre organicamente ao escrever conteúdos abrangentes, ao passo que o keyword stuffing é uma tática de manipulação deliberada punida pelos motores de busca. Algoritmos modernos, como o do Google, priorizam conteúdos significativos com relações naturais entre termos em vez de repetição forçada de palavras-chave.
A coocorrência é fundamental para a visibilidade em IA porque sistemas como ChatGPT, Perplexity e Google AI Overviews utilizam compreensão semântica para gerar respostas. Quando sua marca ou conteúdo aparece junto a termos contextualmente relevantes, isso sinaliza autoridade e relevância para sistemas de IA. Isso aumenta a probabilidade de sua marca ser mencionada em respostas geradas por IA, o que é cada vez mais importante já que mais de 60% dos usuários agora confiam em assistentes de IA para descoberta e tomada de decisão.
Uma matriz de coocorrência é uma representação matemática (normalmente uma grade N×N) onde as linhas e colunas representam palavras únicas em um corpus de texto, e cada célula contém a frequência de pares de palavras aparecendo juntas em uma janela de contexto específica. Em PLN, matrizes de coocorrência são fundamentais para criar embeddings de palavras como GloVe, viabilizando análise semântica, modelagem de tópicos e medições de similaridade textual. Elas ajudam algoritmos a entender quais palavras são semanticamente relacionadas com base em seus padrões estatísticos.
Para otimizar a coocorrência, escreva conteúdos abrangentes que incluam naturalmente termos semanticamente relacionados junto à sua palavra-chave principal. Por exemplo, um artigo sobre 'veículos elétricos' deve incluir termos como 'autonomia da bateria', 'incentivos para EVs', 'infraestrutura de recarga' e 'emissões de carbono'. Utilize ferramentas como Surfer SEO ou Clearscope para identificar frases coocorrentes em conteúdos concorrentes que lideram o ranking e incorpore clusters semânticos semelhantes ao seu próprio conteúdo, mantendo a leitura natural e o foco na intenção do usuário.
A coocorrência é um componente central do SEO semântico, que foca em compreender o significado do conteúdo em vez de apenas corresponder palavras-chave exatas. O SEO semântico utiliza padrões de coocorrência para ajudar motores de busca a captar o contexto completo e a intenção do conteúdo. Ao agrupar termos relacionados de forma natural em seu conteúdo, você sinaliza aos algoritmos que sua página cobre o tema de forma abrangente, melhorando o ranqueamento para a palavra-chave principal e variações semânticas relacionadas.
A coocorrência impacta o monitoramento de marca porque sistemas de IA analisam com que frequência sua marca aparece junto a termos relevantes do setor e nomes de concorrentes. Quando sua marca coocorre consistentemente com termos de contexto positivo (como 'inovadora', 'confiável', 'líder no setor'), isso fortalece sua autoridade percebida. Ferramentas como AmICited acompanham esses padrões de coocorrência em plataformas de IA, revelando como sua marca é posicionada em relação aos concorrentes nas respostas geradas por IA.
Sim, a coocorrência melhora significativamente o ranqueamento para palavras-chave long-tail. Palavras-chave long-tail geralmente têm menor volume de busca, mas maior especificidade de intenção. Ao incluir termos semânticos coocorrentes de forma natural em seu conteúdo, você cria um ambiente contextual rico que ajuda os motores de busca a associar seu conteúdo a diversas variações de consultas long-tail. Essa abordagem é mais eficaz do que o direcionamento tradicional de palavras-chave, pois aborda a intenção do usuário de forma abrangente em vez de focar em palavras isoladas.
Sistemas de IA utilizam estatísticas de coocorrência de seus dados de treinamento para entender relações entre palavras e gerar respostas contextualmente apropriadas. Quando você consulta o ChatGPT ou o Perplexity, esses sistemas dependem de padrões de coocorrência aprendidos para determinar quais fontes e marcas são mais relevantes para mencionar. Frequências mais altas de coocorrência entre sua marca e termos relevantes do setor aumentam a probabilidade de sua marca ser citada em respostas de IA, tornando isso essencial para estratégias de GEO (Otimização para Motores Geradores).
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
Saiba como padrões de coocorrência ajudam mecanismos de busca por IA a entender relacionamentos semânticos entre termos, melhorar o ranqueamento de conteúdo e a...

Co-citação é quando dois sites são mencionados juntos por terceiros, sinalizando relação semântica para mecanismos de busca e sistemas de IA. Aprenda como co-ci...
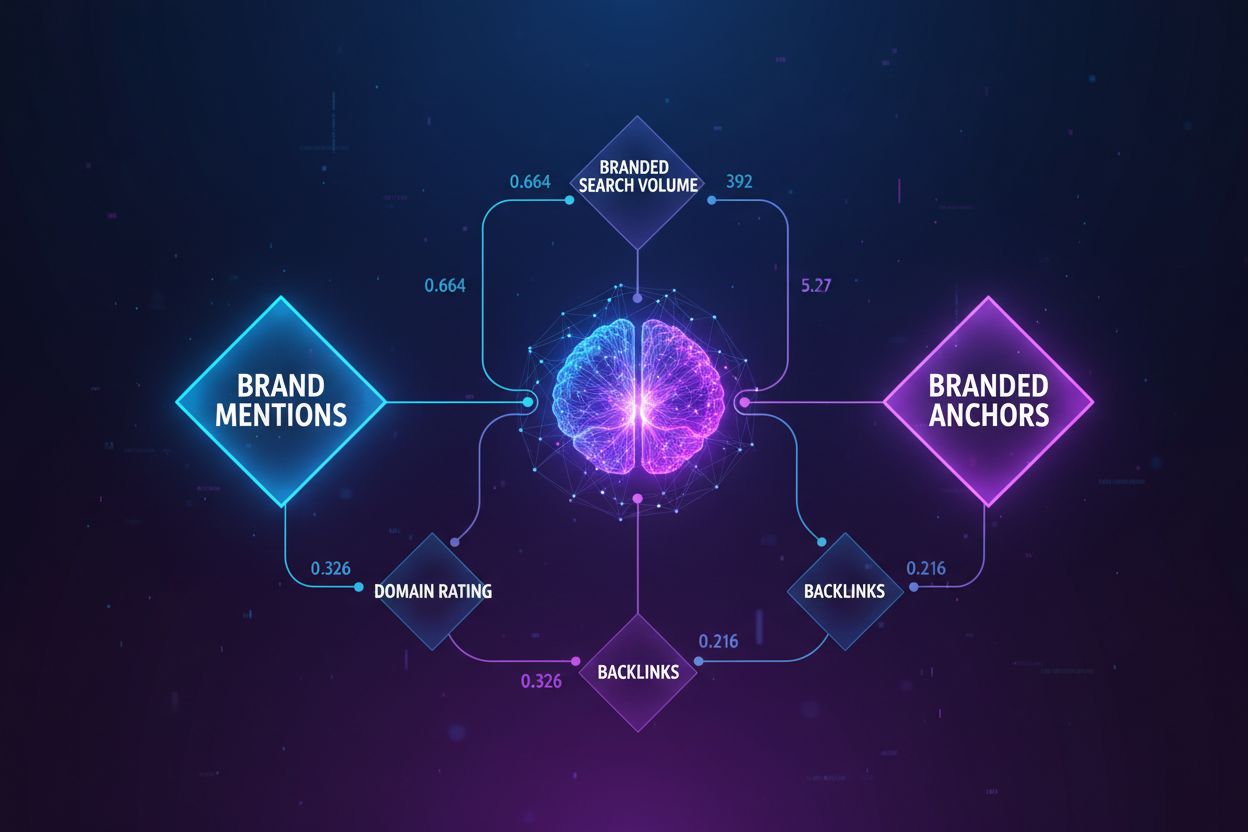
Descubra quais fatores têm a correlação mais forte com a visibilidade em IA. Saiba como menções de marca, volume de buscas e âncoras impulsionam os AI Overviews...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.